
| | |  गिटहब पर देखें गिटहब पर देखें | |
एआई अनुप्रयोगों में जो सुरक्षा-महत्वपूर्ण हैं (उदाहरण के लिए, चिकित्सा निर्णय लेने और स्वायत्त ड्राइविंग) या जहां डेटा स्वाभाविक रूप से शोर है (उदाहरण के लिए, प्राकृतिक भाषा समझ), एक गहन क्लासिफायरियर के लिए इसकी अनिश्चितता को विश्वसनीय रूप से मापने के लिए महत्वपूर्ण है। डीप क्लासिफायरियर को अपनी सीमाओं के बारे में पता होना चाहिए और इसे मानव विशेषज्ञों को कब सौंपना चाहिए। यह ट्यूटोरियल दिखाता है कि स्पेक्ट्रल-नॉर्मलाइज्ड न्यूरल गॉसियन प्रोसेस ( एसएनजीपी ) नामक तकनीक का उपयोग करके अनिश्चितता को मापने में एक गहरी क्लासिफायरियर की क्षमता में सुधार कैसे करें।
एसएनजीपी का मूल विचार नेटवर्क में सरल संशोधनों को लागू करके एक गहन क्लासिफायरियर की दूरी जागरूकता में सुधार करना है। एक मॉडल की दूरी जागरूकता इस बात का माप है कि इसकी भविष्य कहनेवाला संभावना परीक्षण उदाहरण और प्रशिक्षण डेटा के बीच की दूरी को कैसे दर्शाती है। यह एक वांछनीय संपत्ति है जो सोने के मानक संभाव्य मॉडल (उदाहरण के लिए, आरबीएफ कर्नेल के साथ गाऊसी प्रक्रिया ) के लिए सामान्य है, लेकिन गहरे तंत्रिका नेटवर्क वाले मॉडल में कमी है। एसएनजीपी इस गाऊसी-प्रक्रिया व्यवहार को एक गहरे क्लासिफायरियर में इंजेक्ट करने का एक आसान तरीका प्रदान करता है, जबकि इसकी भविष्यवाणी सटीकता को बनाए रखता है।
यह ट्यूटोरियल दो मून्स डेटासेट पर एक गहरे अवशिष्ट नेटवर्क (ResNet)-आधारित SNGP मॉडल को लागू करता है, और इसकी अनिश्चितता की सतह की तुलना दो अन्य लोकप्रिय अनिश्चितता दृष्टिकोणों - मोंटे कार्लो ड्रॉपआउट और डीप एन्सेम्बल से करता है।
यह ट्यूटोरियल खिलौना 2D डेटासेट पर SNGP मॉडल को दिखाता है। BERT-बेस का उपयोग करके वास्तविक दुनिया की प्राकृतिक भाषा समझने के कार्य में SNGP को लागू करने के उदाहरण के लिए, कृपया SNGP-BERT ट्यूटोरियल देखें। बेंचमार्क डेटासेट (जैसे, CIFAR-100 , इमेजनेट , आरा विषाक्तता का पता लगाने , आदि) की एक विस्तृत विविधता पर SNGP मॉडल (और कई अन्य अनिश्चितता विधियों) के उच्च गुणवत्ता वाले कार्यान्वयन के लिए, कृपया अनिश्चितता बेसलाइन बेंचमार्क देखें।
एसएनजीपी के बारे में
स्पेक्ट्रल-नॉर्मलाइज्ड न्यूरल गॉसियन प्रोसेस (एसएनजीपी) एक समान स्तर की सटीकता और विलंबता को बनाए रखते हुए एक गहरी क्लासिफायरियर की अनिश्चितता गुणवत्ता में सुधार करने का एक सरल तरीका है। एक गहरे अवशिष्ट नेटवर्क को देखते हुए, SNGP मॉडल में दो साधारण परिवर्तन करता है:
- यह छिपी हुई अवशिष्ट परतों के लिए वर्णक्रमीय सामान्यीकरण लागू करता है।
- यह घने आउटपुट परत को गाऊसी प्रक्रिया परत से बदल देता है।
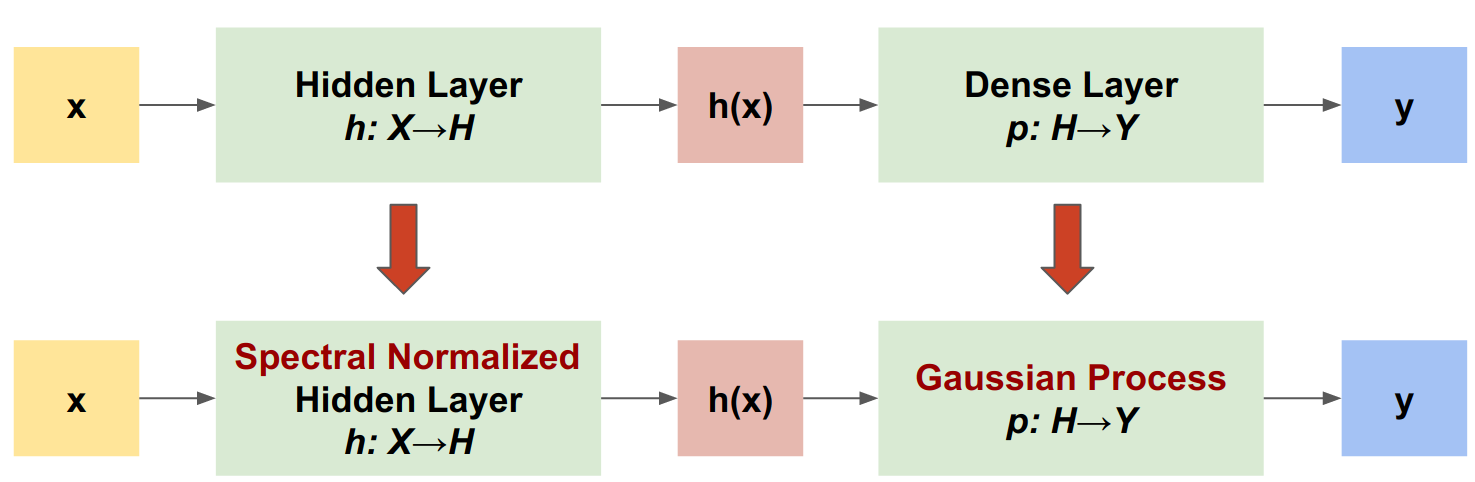
अन्य अनिश्चितता दृष्टिकोण (जैसे, मोंटे कार्लो ड्रॉपआउट या डीप पहनावा) की तुलना में, एसएनजीपी के कई फायदे हैं:
- यह अत्याधुनिक अवशिष्ट-आधारित आर्किटेक्चर (जैसे, (वाइड) रेसनेट, डेंसनेट, बीईआरटी, आदि) की एक विस्तृत श्रृंखला के लिए काम करता है।
- यह एक एकल-मॉडल विधि है (अर्थात, पहनावा औसत पर निर्भर नहीं करता है)। इसलिए एसएनजीपी में एकल नियतात्मक नेटवर्क के समान विलंबता का स्तर है, और इसे इमेजनेट और आरा टॉक्सिक कमेंट्स वर्गीकरण जैसे बड़े डेटासेट में आसानी से बढ़ाया जा सकता है।
- डिस्टेंस-अवेयरनेस प्रॉपर्टी के कारण इसका आउट-ऑफ-डोमेन डिटेक्शन परफॉर्मेंस मजबूत है।
इस पद्धति के नुकसान हैं:
एसएनजीपी की भविष्य कहनेवाला अनिश्चितता की गणना लाप्लास सन्निकटन का उपयोग करके की जाती है। इसलिए सैद्धांतिक रूप से, एसएनजीपी की पश्च अनिश्चितता एक सटीक गाऊसी प्रक्रिया से अलग है।
एसएनजीपी प्रशिक्षण को एक नए युग की शुरुआत में एक सहप्रसरण रीसेट चरण की आवश्यकता है। यह एक प्रशिक्षण पाइपलाइन में अतिरिक्त जटिलता की एक छोटी राशि जोड़ सकता है। यह ट्यूटोरियल केरस कॉलबैक का उपयोग करके इसे लागू करने का एक आसान तरीका दिखाता है।
सेट अप
pip install --use-deprecated=legacy-resolver tf-models-official
# refresh pkg_resources so it takes the changes into account.
import pkg_resources
import importlib
importlib.reload(pkg_resources)
<module 'pkg_resources' from '/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py'>
import matplotlib.pyplot as plt
import matplotlib.colors as colors
import sklearn.datasets
import numpy as np
import tensorflow as tf
import official.nlp.modeling.layers as nlp_layers
विज़ुअलाइज़ेशन मैक्रोज़ को परिभाषित करें
plt.rcParams['figure.dpi'] = 140
DEFAULT_X_RANGE = (-3.5, 3.5)
DEFAULT_Y_RANGE = (-2.5, 2.5)
DEFAULT_CMAP = colors.ListedColormap(["#377eb8", "#ff7f00"])
DEFAULT_NORM = colors.Normalize(vmin=0, vmax=1,)
DEFAULT_N_GRID = 100
दो चाँद डेटासेट
टू मून डेटासेट से प्रशिक्षण और मूल्यांकन डेटासेट बनाएं।
def make_training_data(sample_size=500):
"""Create two moon training dataset."""
train_examples, train_labels = sklearn.datasets.make_moons(
n_samples=2 * sample_size, noise=0.1)
# Adjust data position slightly.
train_examples[train_labels == 0] += [-0.1, 0.2]
train_examples[train_labels == 1] += [0.1, -0.2]
return train_examples, train_labels
संपूर्ण 2D इनपुट स्थान पर मॉडल के भविष्य कहनेवाला व्यवहार का मूल्यांकन करें।
def make_testing_data(x_range=DEFAULT_X_RANGE, y_range=DEFAULT_Y_RANGE, n_grid=DEFAULT_N_GRID):
"""Create a mesh grid in 2D space."""
# testing data (mesh grid over data space)
x = np.linspace(x_range[0], x_range[1], n_grid)
y = np.linspace(y_range[0], y_range[1], n_grid)
xv, yv = np.meshgrid(x, y)
return np.stack([xv.flatten(), yv.flatten()], axis=-1)
मॉडल अनिश्चितता का मूल्यांकन करने के लिए, एक आउट-ऑफ-डोमेन (OOD) डेटासेट जोड़ें जो किसी तृतीय श्रेणी से संबंधित हो। प्रशिक्षण के दौरान मॉडल इन OOD उदाहरणों को कभी नहीं देखता है।
def make_ood_data(sample_size=500, means=(2.5, -1.75), vars=(0.01, 0.01)):
return np.random.multivariate_normal(
means, cov=np.diag(vars), size=sample_size)
# Load the train, test and OOD datasets.
train_examples, train_labels = make_training_data(
sample_size=500)
test_examples = make_testing_data()
ood_examples = make_ood_data(sample_size=500)
# Visualize
pos_examples = train_examples[train_labels == 0]
neg_examples = train_examples[train_labels == 1]
plt.figure(figsize=(7, 5.5))
plt.scatter(pos_examples[:, 0], pos_examples[:, 1], c="#377eb8", alpha=0.5)
plt.scatter(neg_examples[:, 0], neg_examples[:, 1], c="#ff7f00", alpha=0.5)
plt.scatter(ood_examples[:, 0], ood_examples[:, 1], c="red", alpha=0.1)
plt.legend(["Postive", "Negative", "Out-of-Domain"])
plt.ylim(DEFAULT_Y_RANGE)
plt.xlim(DEFAULT_X_RANGE)
plt.show()

यहां नीला और नारंगी सकारात्मक और नकारात्मक वर्गों का प्रतिनिधित्व करता है, और लाल OOD डेटा का प्रतिनिधित्व करता है। एक मॉडल जो अनिश्चितता को अच्छी तरह से निर्धारित करता है, जब प्रशिक्षण डेटा के करीब (यानी, \(p(x_{test})\) 0 या 1 के करीब), और प्रशिक्षण डेटा क्षेत्रों से बहुत दूर होने पर अनिश्चित होने की उम्मीद है (यानी, \(p(x_{test})\) 0.5 के करीब) )
नियतात्मक मॉडल
मॉडल को परिभाषित करें
(बेसलाइन) नियतात्मक मॉडल से शुरू करें: ड्रॉपआउट नियमितीकरण के साथ एक बहु-परत अवशिष्ट नेटवर्क (ResNet)।
class DeepResNet(tf.keras.Model):
"""Defines a multi-layer residual network."""
def __init__(self, num_classes, num_layers=3, num_hidden=128,
dropout_rate=0.1, **classifier_kwargs):
super().__init__()
# Defines class meta data.
self.num_hidden = num_hidden
self.num_layers = num_layers
self.dropout_rate = dropout_rate
self.classifier_kwargs = classifier_kwargs
# Defines the hidden layers.
self.input_layer = tf.keras.layers.Dense(self.num_hidden, trainable=False)
self.dense_layers = [self.make_dense_layer() for _ in range(num_layers)]
# Defines the output layer.
self.classifier = self.make_output_layer(num_classes)
def call(self, inputs):
# Projects the 2d input data to high dimension.
hidden = self.input_layer(inputs)
# Computes the resnet hidden representations.
for i in range(self.num_layers):
resid = self.dense_layers[i](hidden)
resid = tf.keras.layers.Dropout(self.dropout_rate)(resid)
hidden += resid
return self.classifier(hidden)
def make_dense_layer(self):
"""Uses the Dense layer as the hidden layer."""
return tf.keras.layers.Dense(self.num_hidden, activation="relu")
def make_output_layer(self, num_classes):
"""Uses the Dense layer as the output layer."""
return tf.keras.layers.Dense(
num_classes, **self.classifier_kwargs)
यह ट्यूटोरियल 128 छिपी हुई इकाइयों के साथ 6-लेयर रेसनेट का उपयोग करता है।
resnet_config = dict(num_classes=2, num_layers=6, num_hidden=128)
resnet_model = DeepResNet(**resnet_config)
resnet_model.build((None, 2))
resnet_model.summary()
Model: "deep_res_net"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) multiple 384
dense_1 (Dense) multiple 16512
dense_2 (Dense) multiple 16512
dense_3 (Dense) multiple 16512
dense_4 (Dense) multiple 16512
dense_5 (Dense) multiple 16512
dense_6 (Dense) multiple 16512
dense_7 (Dense) multiple 258
=================================================================
Total params: 99,714
Trainable params: 99,330
Non-trainable params: 384
_________________________________________________________________
ट्रेन मॉडल
नुकसान फ़ंक्शन और एडम ऑप्टिमाइज़र के रूप में SparseCategoricalCrossentropy का उपयोग करने के लिए प्रशिक्षण मापदंडों को कॉन्फ़िगर करें।
loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
metrics = tf.keras.metrics.SparseCategoricalAccuracy(),
optimizer = tf.keras.optimizers.Adam(learning_rate=1e-4)
train_config = dict(loss=loss, metrics=metrics, optimizer=optimizer)
बैच आकार 128 के साथ 100 युगों के लिए मॉडल को प्रशिक्षित करें।
fit_config = dict(batch_size=128, epochs=100)
resnet_model.compile(**train_config)
resnet_model.fit(train_examples, train_labels, **fit_config)
Epoch 1/100 8/8 [==============================] - 1s 4ms/step - loss: 1.1251 - sparse_categorical_accuracy: 0.5050 Epoch 2/100 8/8 [==============================] - 0s 3ms/step - loss: 0.5538 - sparse_categorical_accuracy: 0.6920 Epoch 3/100 8/8 [==============================] - 0s 3ms/step - loss: 0.2881 - sparse_categorical_accuracy: 0.9160 Epoch 4/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1923 - sparse_categorical_accuracy: 0.9370 Epoch 5/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1550 - sparse_categorical_accuracy: 0.9420 Epoch 6/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1403 - sparse_categorical_accuracy: 0.9450 Epoch 7/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1269 - sparse_categorical_accuracy: 0.9430 Epoch 8/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1208 - sparse_categorical_accuracy: 0.9460 Epoch 9/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1158 - sparse_categorical_accuracy: 0.9510 Epoch 10/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1103 - sparse_categorical_accuracy: 0.9490 Epoch 11/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1051 - sparse_categorical_accuracy: 0.9510 Epoch 12/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1053 - sparse_categorical_accuracy: 0.9510 Epoch 13/100 8/8 [==============================] - 0s 3ms/step - loss: 0.1013 - sparse_categorical_accuracy: 0.9450 Epoch 14/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0967 - sparse_categorical_accuracy: 0.9500 Epoch 15/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0991 - sparse_categorical_accuracy: 0.9530 Epoch 16/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0984 - sparse_categorical_accuracy: 0.9500 Epoch 17/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0982 - sparse_categorical_accuracy: 0.9480 Epoch 18/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0918 - sparse_categorical_accuracy: 0.9510 Epoch 19/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0903 - sparse_categorical_accuracy: 0.9500 Epoch 20/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0883 - sparse_categorical_accuracy: 0.9510 Epoch 21/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0870 - sparse_categorical_accuracy: 0.9530 Epoch 22/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0884 - sparse_categorical_accuracy: 0.9560 Epoch 23/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0850 - sparse_categorical_accuracy: 0.9540 Epoch 24/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0808 - sparse_categorical_accuracy: 0.9580 Epoch 25/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0773 - sparse_categorical_accuracy: 0.9560 Epoch 26/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0801 - sparse_categorical_accuracy: 0.9590 Epoch 27/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0779 - sparse_categorical_accuracy: 0.9580 Epoch 28/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0807 - sparse_categorical_accuracy: 0.9580 Epoch 29/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0820 - sparse_categorical_accuracy: 0.9570 Epoch 30/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0730 - sparse_categorical_accuracy: 0.9600 Epoch 31/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0782 - sparse_categorical_accuracy: 0.9590 Epoch 32/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0704 - sparse_categorical_accuracy: 0.9600 Epoch 33/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0709 - sparse_categorical_accuracy: 0.9610 Epoch 34/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0758 - sparse_categorical_accuracy: 0.9580 Epoch 35/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0702 - sparse_categorical_accuracy: 0.9610 Epoch 36/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0688 - sparse_categorical_accuracy: 0.9600 Epoch 37/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0675 - sparse_categorical_accuracy: 0.9630 Epoch 38/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0636 - sparse_categorical_accuracy: 0.9690 Epoch 39/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0677 - sparse_categorical_accuracy: 0.9610 Epoch 40/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0702 - sparse_categorical_accuracy: 0.9650 Epoch 41/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0614 - sparse_categorical_accuracy: 0.9690 Epoch 42/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0663 - sparse_categorical_accuracy: 0.9680 Epoch 43/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0626 - sparse_categorical_accuracy: 0.9740 Epoch 44/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0590 - sparse_categorical_accuracy: 0.9760 Epoch 45/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0573 - sparse_categorical_accuracy: 0.9780 Epoch 46/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0568 - sparse_categorical_accuracy: 0.9770 Epoch 47/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0595 - sparse_categorical_accuracy: 0.9780 Epoch 48/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0482 - sparse_categorical_accuracy: 0.9840 Epoch 49/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0515 - sparse_categorical_accuracy: 0.9820 Epoch 50/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0525 - sparse_categorical_accuracy: 0.9830 Epoch 51/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0507 - sparse_categorical_accuracy: 0.9790 Epoch 52/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0433 - sparse_categorical_accuracy: 0.9850 Epoch 53/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0511 - sparse_categorical_accuracy: 0.9820 Epoch 54/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0501 - sparse_categorical_accuracy: 0.9820 Epoch 55/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0440 - sparse_categorical_accuracy: 0.9890 Epoch 56/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0438 - sparse_categorical_accuracy: 0.9850 Epoch 57/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0438 - sparse_categorical_accuracy: 0.9880 Epoch 58/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0416 - sparse_categorical_accuracy: 0.9860 Epoch 59/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0479 - sparse_categorical_accuracy: 0.9860 Epoch 60/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0434 - sparse_categorical_accuracy: 0.9860 Epoch 61/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0414 - sparse_categorical_accuracy: 0.9880 Epoch 62/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0402 - sparse_categorical_accuracy: 0.9870 Epoch 63/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0376 - sparse_categorical_accuracy: 0.9890 Epoch 64/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0337 - sparse_categorical_accuracy: 0.9900 Epoch 65/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0309 - sparse_categorical_accuracy: 0.9910 Epoch 66/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0336 - sparse_categorical_accuracy: 0.9910 Epoch 67/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0389 - sparse_categorical_accuracy: 0.9870 Epoch 68/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0333 - sparse_categorical_accuracy: 0.9920 Epoch 69/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0331 - sparse_categorical_accuracy: 0.9890 Epoch 70/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0346 - sparse_categorical_accuracy: 0.9900 Epoch 71/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0367 - sparse_categorical_accuracy: 0.9880 Epoch 72/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0283 - sparse_categorical_accuracy: 0.9920 Epoch 73/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0315 - sparse_categorical_accuracy: 0.9930 Epoch 74/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0271 - sparse_categorical_accuracy: 0.9900 Epoch 75/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0257 - sparse_categorical_accuracy: 0.9920 Epoch 76/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0289 - sparse_categorical_accuracy: 0.9900 Epoch 77/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0264 - sparse_categorical_accuracy: 0.9900 Epoch 78/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0272 - sparse_categorical_accuracy: 0.9910 Epoch 79/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0336 - sparse_categorical_accuracy: 0.9880 Epoch 80/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0249 - sparse_categorical_accuracy: 0.9900 Epoch 81/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0216 - sparse_categorical_accuracy: 0.9930 Epoch 82/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0279 - sparse_categorical_accuracy: 0.9890 Epoch 83/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0261 - sparse_categorical_accuracy: 0.9920 Epoch 84/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0235 - sparse_categorical_accuracy: 0.9920 Epoch 85/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0236 - sparse_categorical_accuracy: 0.9930 Epoch 86/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0219 - sparse_categorical_accuracy: 0.9920 Epoch 87/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0196 - sparse_categorical_accuracy: 0.9920 Epoch 88/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0215 - sparse_categorical_accuracy: 0.9900 Epoch 89/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0223 - sparse_categorical_accuracy: 0.9900 Epoch 90/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0200 - sparse_categorical_accuracy: 0.9950 Epoch 91/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0250 - sparse_categorical_accuracy: 0.9900 Epoch 92/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0160 - sparse_categorical_accuracy: 0.9940 Epoch 93/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0203 - sparse_categorical_accuracy: 0.9930 Epoch 94/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0203 - sparse_categorical_accuracy: 0.9930 Epoch 95/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0172 - sparse_categorical_accuracy: 0.9960 Epoch 96/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0209 - sparse_categorical_accuracy: 0.9940 Epoch 97/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0179 - sparse_categorical_accuracy: 0.9920 Epoch 98/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0195 - sparse_categorical_accuracy: 0.9940 Epoch 99/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0165 - sparse_categorical_accuracy: 0.9930 Epoch 100/100 8/8 [==============================] - 0s 3ms/step - loss: 0.0170 - sparse_categorical_accuracy: 0.9950 <keras.callbacks.History at 0x7ff7ac5c8fd0>
अनिश्चितता की कल्पना करें
def plot_uncertainty_surface(test_uncertainty, ax, cmap=None):
"""Visualizes the 2D uncertainty surface.
For simplicity, assume these objects already exist in the memory:
test_examples: Array of test examples, shape (num_test, 2).
train_labels: Array of train labels, shape (num_train, ).
train_examples: Array of train examples, shape (num_train, 2).
Arguments:
test_uncertainty: Array of uncertainty scores, shape (num_test,).
ax: A matplotlib Axes object that specifies a matplotlib figure.
cmap: A matplotlib colormap object specifying the palette of the
predictive surface.
Returns:
pcm: A matplotlib PathCollection object that contains the palette
information of the uncertainty plot.
"""
# Normalize uncertainty for better visualization.
test_uncertainty = test_uncertainty / np.max(test_uncertainty)
# Set view limits.
ax.set_ylim(DEFAULT_Y_RANGE)
ax.set_xlim(DEFAULT_X_RANGE)
# Plot normalized uncertainty surface.
pcm = ax.imshow(
np.reshape(test_uncertainty, [DEFAULT_N_GRID, DEFAULT_N_GRID]),
cmap=cmap,
origin="lower",
extent=DEFAULT_X_RANGE + DEFAULT_Y_RANGE,
vmin=DEFAULT_NORM.vmin,
vmax=DEFAULT_NORM.vmax,
interpolation='bicubic',
aspect='auto')
# Plot training data.
ax.scatter(train_examples[:, 0], train_examples[:, 1],
c=train_labels, cmap=DEFAULT_CMAP, alpha=0.5)
ax.scatter(ood_examples[:, 0], ood_examples[:, 1], c="red", alpha=0.1)
return pcm
अब नियतात्मक मॉडल की भविष्यवाणियों की कल्पना करें। पहले वर्ग की संभावना को प्लॉट करें:
\[p(x) = softmax(logit(x))\]
resnet_logits = resnet_model(test_examples)
resnet_probs = tf.nn.softmax(resnet_logits, axis=-1)[:, 0] # Take the probability for class 0.
_, ax = plt.subplots(figsize=(7, 5.5))
pcm = plot_uncertainty_surface(resnet_probs, ax=ax)
plt.colorbar(pcm, ax=ax)
plt.title("Class Probability, Deterministic Model")
plt.show()

इस भूखंड में, पीले और बैंगनी दो वर्गों के लिए भविष्य कहनेवाला संभावनाएं हैं। नियतात्मक मॉडल ने दो ज्ञात वर्गों (नीला और नारंगी) को एक गैर-रेखीय निर्णय सीमा के साथ वर्गीकृत करने में अच्छा काम किया। हालांकि, यह दूरी-जागरूक नहीं है, और कभी न देखे गए रेड आउट-ऑफ-डोमेन (OOD) उदाहरणों को आत्मविश्वास से नारंगी वर्ग के रूप में वर्गीकृत करता है।
भविष्य कहनेवाला विचरण की गणना करके मॉडल अनिश्चितता की कल्पना करें:
\[var(x) = p(x) * (1 - p(x))\]
resnet_uncertainty = resnet_probs * (1 - resnet_probs)
_, ax = plt.subplots(figsize=(7, 5.5))
pcm = plot_uncertainty_surface(resnet_uncertainty, ax=ax)
plt.colorbar(pcm, ax=ax)
plt.title("Predictive Uncertainty, Deterministic Model")
plt.show()

इस भूखंड में, पीला उच्च अनिश्चितता को इंगित करता है, और बैंगनी कम अनिश्चितता को इंगित करता है। नियतात्मक ResNet की अनिश्चितता केवल परीक्षण उदाहरणों की निर्णय सीमा से दूरी पर निर्भर करती है। यह प्रशिक्षण डोमेन से बाहर होने पर मॉडल को अति-आत्मविश्वास की ओर ले जाता है। अगला खंड दिखाता है कि एसएनजीपी इस डेटासेट पर अलग तरह से कैसे व्यवहार करता है।
एसएनजीपी मॉडल
एसएनजीपी मॉडल को परिभाषित करें
आइए अब एसएनजीपी मॉडल लागू करें। दोनों SNGP घटक, SpectralNormalization और RandomFeatureGaussianProcess , tensorflow_model की अंतर्निर्मित परतों पर उपलब्ध हैं।
आइए इन दो घटकों को अधिक विस्तार से देखें। (पूर्ण मॉडल को कैसे लागू किया जाता है, यह देखने के लिए आप एसएनजीपी मॉडल अनुभाग पर भी जा सकते हैं।)
वर्णक्रमीय सामान्यीकरण आवरण
SpectralNormalization सामान्यीकरण एक केरस परत आवरण है। इसे मौजूदा Dense लेयर पर इस तरह लागू किया जा सकता है:
dense = tf.keras.layers.Dense(units=10)
dense = nlp_layers.SpectralNormalization(dense, norm_multiplier=0.9)
वर्णक्रमीय सामान्यीकरण छिपे हुए भार \(W\) को धीरे-धीरे इसके वर्णक्रमीय मानदंड (यानी, \(W\)का सबसे बड़ा eigenvalue) को लक्ष्य मान norm_multiplier की ओर निर्देशित करके नियमित करता है।
गाऊसी प्रक्रिया (जीपी) परत
RandomFeatureGaussianProcess एक गाऊसी प्रक्रिया मॉडल के लिए एक यादृच्छिक-सुविधा आधारित सन्निकटन लागू करता है जो एक गहरे तंत्रिका नेटवर्क के साथ एंड-टू-एंड प्रशिक्षण योग्य है। हुड के तहत, गाऊसी प्रक्रिया परत दो-परत नेटवर्क को लागू करती है:
\[logits(x) = \Phi(x) \beta, \quad \Phi(x)=\sqrt{\frac{2}{M} } * cos(Wx + b)\]
यहाँ \(x\) इनपुट है, और \(W\) और \(b\) क्रमशः गाऊसी और समान वितरण से बेतरतीब ढंग से आरंभ किए गए जमे हुए वजन हैं। (इसलिए \(\Phi(x)\) को "यादृच्छिक विशेषताएं" कहा जाता है।) \(\beta\) एक सघन परत के समान सीखने योग्य कर्नेल भार है।
batch_size = 32
input_dim = 1024
num_classes = 10
gp_layer = nlp_layers.RandomFeatureGaussianProcess(units=num_classes,
num_inducing=1024,
normalize_input=False,
scale_random_features=True,
gp_cov_momentum=-1)
जीपी परतों के मुख्य पैरामीटर हैं:
-
units: आउटपुट का आयाम लॉग करता है। -
num_inducing: छिपे हुए भार का आयाम \(M\) \(W\)। 1024 के लिए डिफ़ॉल्ट। -
normalize_input: इनपुट \(x\)पर लेयर नॉर्मलाइजेशन लागू करना है या नहीं। -
scale_random_features: क्या स्केल l10n- \(\sqrt{2/M}\) 16 को हिडन आउटपुट पर लागू करना है।
-
gp_cov_momentumनियंत्रित करता है कि मॉडल सहप्रसरण की गणना कैसे की जाती है। यदि एक सकारात्मक मान (जैसे, 0.999) पर सेट किया जाता है, तो कॉन्वर्सिस मैट्रिक्स की गणना गति-आधारित चलती औसत अद्यतन (बैच सामान्यीकरण के समान) का उपयोग करके की जाती है। यदि -1 पर सेट किया जाता है, तो कॉन्वर्सिस मैट्रिक्स बिना संवेग के अद्यतन किया जाता है।
आकार (batch_size, input_dim) के साथ एक बैच इनपुट को देखते हुए, जीपी परत भविष्यवाणी के लिए एक logits टेंसर (आकृति (batch_size, num_classes) ) देता है, और covmat टेंसर (आकार (batch_size, batch_size) बैच_साइज़, बैच_साइज़)) भी देता है, जो कि पोस्टीरियर कॉन्वर्सिस मैट्रिक्स है। बैच लॉग।
embedding = tf.random.normal(shape=(batch_size, input_dim))
logits, covmat = gp_layer(embedding)
सैद्धांतिक रूप से, विभिन्न वर्गों के लिए अलग-अलग भिन्नता मूल्यों की गणना करने के लिए एल्गोरिदम का विस्तार करना संभव है (जैसा कि मूल एसएनजीपी पेपर में पेश किया गया है)। हालांकि, बड़े आउटपुट स्पेस (जैसे, इमेजनेट या भाषा मॉडलिंग) के साथ समस्याओं को मापना मुश्किल है।
पूर्ण SNGP मॉडल
बेस क्लास DeepResNet को देखते हुए, एसएनजीपी मॉडल को अवशिष्ट नेटवर्क की छिपी और आउटपुट परतों को संशोधित करके आसानी से लागू किया जा सकता है। model.fit() एपीआई के साथ संगतता के लिए, मॉडल की call() विधि को भी संशोधित करें ताकि यह केवल प्रशिक्षण के दौरान logits को आउटपुट करे।
class DeepResNetSNGP(DeepResNet):
def __init__(self, spec_norm_bound=0.9, **kwargs):
self.spec_norm_bound = spec_norm_bound
super().__init__(**kwargs)
def make_dense_layer(self):
"""Applies spectral normalization to the hidden layer."""
dense_layer = super().make_dense_layer()
return nlp_layers.SpectralNormalization(
dense_layer, norm_multiplier=self.spec_norm_bound)
def make_output_layer(self, num_classes):
"""Uses Gaussian process as the output layer."""
return nlp_layers.RandomFeatureGaussianProcess(
num_classes,
gp_cov_momentum=-1,
**self.classifier_kwargs)
def call(self, inputs, training=False, return_covmat=False):
# Gets logits and covariance matrix from GP layer.
logits, covmat = super().call(inputs)
# Returns only logits during training.
if not training and return_covmat:
return logits, covmat
return logits
नियतात्मक मॉडल के समान वास्तुकला का उपयोग करें।
resnet_config
{'num_classes': 2, 'num_layers': 6, 'num_hidden': 128}
sngp_model = DeepResNetSNGP(**resnet_config)
sngp_model.build((None, 2))
sngp_model.summary()
Model: "deep_res_net_sngp"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_9 (Dense) multiple 384
spectral_normalization_1 (S multiple 16768
pectralNormalization)
spectral_normalization_2 (S multiple 16768
pectralNormalization)
spectral_normalization_3 (S multiple 16768
pectralNormalization)
spectral_normalization_4 (S multiple 16768
pectralNormalization)
spectral_normalization_5 (S multiple 16768
pectralNormalization)
spectral_normalization_6 (S multiple 16768
pectralNormalization)
random_feature_gaussian_pro multiple 1182722
cess (RandomFeatureGaussian
Process)
=================================================================
Total params: 1,283,714
Trainable params: 101,120
Non-trainable params: 1,182,594
_________________________________________________________________
एक नए युग की शुरुआत में सहप्रसरण मैट्रिक्स को रीसेट करने के लिए एक केरस कॉलबैक लागू करें।
class ResetCovarianceCallback(tf.keras.callbacks.Callback):
def on_epoch_begin(self, epoch, logs=None):
"""Resets covariance matrix at the begining of the epoch."""
if epoch > 0:
self.model.classifier.reset_covariance_matrix()
इस कॉलबैक को DeepResNetSNGP मॉडल क्लास में जोड़ें।
class DeepResNetSNGPWithCovReset(DeepResNetSNGP):
def fit(self, *args, **kwargs):
"""Adds ResetCovarianceCallback to model callbacks."""
kwargs["callbacks"] = list(kwargs.get("callbacks", []))
kwargs["callbacks"].append(ResetCovarianceCallback())
return super().fit(*args, **kwargs)
ट्रेन मॉडल
मॉडल को प्रशिक्षित करने के लिए tf.keras.model.fit का उपयोग करें।
sngp_model = DeepResNetSNGPWithCovReset(**resnet_config)
sngp_model.compile(**train_config)
sngp_model.fit(train_examples, train_labels, **fit_config)
Epoch 1/100 8/8 [==============================] - 2s 5ms/step - loss: 0.6223 - sparse_categorical_accuracy: 0.9570 Epoch 2/100 8/8 [==============================] - 0s 4ms/step - loss: 0.5310 - sparse_categorical_accuracy: 0.9980 Epoch 3/100 8/8 [==============================] - 0s 4ms/step - loss: 0.4766 - sparse_categorical_accuracy: 0.9990 Epoch 4/100 8/8 [==============================] - 0s 5ms/step - loss: 0.4346 - sparse_categorical_accuracy: 0.9980 Epoch 5/100 8/8 [==============================] - 0s 5ms/step - loss: 0.4015 - sparse_categorical_accuracy: 0.9980 Epoch 6/100 8/8 [==============================] - 0s 5ms/step - loss: 0.3757 - sparse_categorical_accuracy: 0.9990 Epoch 7/100 8/8 [==============================] - 0s 4ms/step - loss: 0.3525 - sparse_categorical_accuracy: 0.9990 Epoch 8/100 8/8 [==============================] - 0s 4ms/step - loss: 0.3305 - sparse_categorical_accuracy: 0.9990 Epoch 9/100 8/8 [==============================] - 0s 5ms/step - loss: 0.3144 - sparse_categorical_accuracy: 0.9980 Epoch 10/100 8/8 [==============================] - 0s 5ms/step - loss: 0.2975 - sparse_categorical_accuracy: 0.9990 Epoch 11/100 8/8 [==============================] - 0s 4ms/step - loss: 0.2832 - sparse_categorical_accuracy: 0.9990 Epoch 12/100 8/8 [==============================] - 0s 5ms/step - loss: 0.2707 - sparse_categorical_accuracy: 0.9990 Epoch 13/100 8/8 [==============================] - 0s 4ms/step - loss: 0.2568 - sparse_categorical_accuracy: 0.9990 Epoch 14/100 8/8 [==============================] - 0s 4ms/step - loss: 0.2470 - sparse_categorical_accuracy: 0.9970 Epoch 15/100 8/8 [==============================] - 0s 4ms/step - loss: 0.2361 - sparse_categorical_accuracy: 0.9990 Epoch 16/100 8/8 [==============================] - 0s 5ms/step - loss: 0.2271 - sparse_categorical_accuracy: 0.9990 Epoch 17/100 8/8 [==============================] - 0s 5ms/step - loss: 0.2182 - sparse_categorical_accuracy: 0.9990 Epoch 18/100 8/8 [==============================] - 0s 4ms/step - loss: 0.2097 - sparse_categorical_accuracy: 0.9990 Epoch 19/100 8/8 [==============================] - 0s 4ms/step - loss: 0.2018 - sparse_categorical_accuracy: 0.9990 Epoch 20/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1940 - sparse_categorical_accuracy: 0.9980 Epoch 21/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1892 - sparse_categorical_accuracy: 0.9990 Epoch 22/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1821 - sparse_categorical_accuracy: 0.9980 Epoch 23/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1768 - sparse_categorical_accuracy: 0.9990 Epoch 24/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1702 - sparse_categorical_accuracy: 0.9980 Epoch 25/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1664 - sparse_categorical_accuracy: 0.9990 Epoch 26/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1604 - sparse_categorical_accuracy: 0.9990 Epoch 27/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1565 - sparse_categorical_accuracy: 0.9990 Epoch 28/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1517 - sparse_categorical_accuracy: 0.9990 Epoch 29/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1469 - sparse_categorical_accuracy: 0.9990 Epoch 30/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1431 - sparse_categorical_accuracy: 0.9980 Epoch 31/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1385 - sparse_categorical_accuracy: 0.9980 Epoch 32/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1351 - sparse_categorical_accuracy: 0.9990 Epoch 33/100 8/8 [==============================] - 0s 5ms/step - loss: 0.1312 - sparse_categorical_accuracy: 0.9980 Epoch 34/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1289 - sparse_categorical_accuracy: 0.9990 Epoch 35/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1254 - sparse_categorical_accuracy: 0.9980 Epoch 36/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1223 - sparse_categorical_accuracy: 0.9980 Epoch 37/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1180 - sparse_categorical_accuracy: 0.9990 Epoch 38/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1167 - sparse_categorical_accuracy: 0.9990 Epoch 39/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1132 - sparse_categorical_accuracy: 0.9980 Epoch 40/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1110 - sparse_categorical_accuracy: 0.9990 Epoch 41/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1075 - sparse_categorical_accuracy: 0.9990 Epoch 42/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1067 - sparse_categorical_accuracy: 0.9990 Epoch 43/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1034 - sparse_categorical_accuracy: 0.9990 Epoch 44/100 8/8 [==============================] - 0s 4ms/step - loss: 0.1006 - sparse_categorical_accuracy: 0.9990 Epoch 45/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0991 - sparse_categorical_accuracy: 0.9990 Epoch 46/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0963 - sparse_categorical_accuracy: 0.9990 Epoch 47/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0943 - sparse_categorical_accuracy: 0.9980 Epoch 48/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0925 - sparse_categorical_accuracy: 0.9990 Epoch 49/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0905 - sparse_categorical_accuracy: 0.9990 Epoch 50/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0889 - sparse_categorical_accuracy: 0.9990 Epoch 51/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0863 - sparse_categorical_accuracy: 0.9980 Epoch 52/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0847 - sparse_categorical_accuracy: 0.9990 Epoch 53/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0831 - sparse_categorical_accuracy: 0.9980 Epoch 54/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0818 - sparse_categorical_accuracy: 0.9990 Epoch 55/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0799 - sparse_categorical_accuracy: 0.9990 Epoch 56/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0780 - sparse_categorical_accuracy: 0.9990 Epoch 57/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0768 - sparse_categorical_accuracy: 0.9990 Epoch 58/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0751 - sparse_categorical_accuracy: 0.9990 Epoch 59/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0748 - sparse_categorical_accuracy: 0.9990 Epoch 60/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0723 - sparse_categorical_accuracy: 0.9990 Epoch 61/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0712 - sparse_categorical_accuracy: 0.9990 Epoch 62/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0701 - sparse_categorical_accuracy: 0.9990 Epoch 63/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0701 - sparse_categorical_accuracy: 0.9990 Epoch 64/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0683 - sparse_categorical_accuracy: 0.9990 Epoch 65/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0665 - sparse_categorical_accuracy: 0.9990 Epoch 66/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0661 - sparse_categorical_accuracy: 0.9990 Epoch 67/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0636 - sparse_categorical_accuracy: 0.9990 Epoch 68/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0631 - sparse_categorical_accuracy: 0.9990 Epoch 69/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0620 - sparse_categorical_accuracy: 0.9990 Epoch 70/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0606 - sparse_categorical_accuracy: 0.9990 Epoch 71/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0601 - sparse_categorical_accuracy: 0.9980 Epoch 72/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0590 - sparse_categorical_accuracy: 0.9990 Epoch 73/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0586 - sparse_categorical_accuracy: 0.9990 Epoch 74/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0574 - sparse_categorical_accuracy: 0.9990 Epoch 75/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0565 - sparse_categorical_accuracy: 1.0000 Epoch 76/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0559 - sparse_categorical_accuracy: 0.9990 Epoch 77/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0549 - sparse_categorical_accuracy: 0.9990 Epoch 78/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0534 - sparse_categorical_accuracy: 1.0000 Epoch 79/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0532 - sparse_categorical_accuracy: 0.9990 Epoch 80/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0519 - sparse_categorical_accuracy: 1.0000 Epoch 81/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0511 - sparse_categorical_accuracy: 1.0000 Epoch 82/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0508 - sparse_categorical_accuracy: 0.9990 Epoch 83/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0499 - sparse_categorical_accuracy: 1.0000 Epoch 84/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0490 - sparse_categorical_accuracy: 1.0000 Epoch 85/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0490 - sparse_categorical_accuracy: 0.9990 Epoch 86/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0470 - sparse_categorical_accuracy: 1.0000 Epoch 87/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0468 - sparse_categorical_accuracy: 1.0000 Epoch 88/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0468 - sparse_categorical_accuracy: 1.0000 Epoch 89/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0453 - sparse_categorical_accuracy: 1.0000 Epoch 90/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0448 - sparse_categorical_accuracy: 1.0000 Epoch 91/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0441 - sparse_categorical_accuracy: 1.0000 Epoch 92/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0434 - sparse_categorical_accuracy: 1.0000 Epoch 93/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0431 - sparse_categorical_accuracy: 1.0000 Epoch 94/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0424 - sparse_categorical_accuracy: 1.0000 Epoch 95/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0420 - sparse_categorical_accuracy: 1.0000 Epoch 96/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0415 - sparse_categorical_accuracy: 1.0000 Epoch 97/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0409 - sparse_categorical_accuracy: 1.0000 Epoch 98/100 8/8 [==============================] - 0s 4ms/step - loss: 0.0401 - sparse_categorical_accuracy: 1.0000 Epoch 99/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0396 - sparse_categorical_accuracy: 1.0000 Epoch 100/100 8/8 [==============================] - 0s 5ms/step - loss: 0.0392 - sparse_categorical_accuracy: 1.0000 <keras.callbacks.History at 0x7ff7ac0f83d0>
अनिश्चितता की कल्पना करें
पहले भविष्य कहनेवाला लॉग और प्रसरण की गणना करें।
sngp_logits, sngp_covmat = sngp_model(test_examples, return_covmat=True)
sngp_variance = tf.linalg.diag_part(sngp_covmat)[:, None]
अब पश्चवर्ती भविष्य कहनेवाला संभाव्यता की गणना करें। एक संभाव्य मॉडल की भविष्य कहनेवाला संभावना की गणना के लिए क्लासिक विधि मोंटे कार्लो नमूनाकरण का उपयोग करना है, अर्थात,
\[E(p(x)) = \frac{1}{M} \sum_{m=1}^M logit_m(x), \]
जहां \(M\) नमूना आकार है, और \(logit_m(x)\) SNGP पोस्टीरियर l10n- \(MultivariateNormal\)23 ( sngp_logits , sngp_covmat ) से यादृच्छिक नमूने हैं। हालांकि, स्वायत्त ड्राइविंग या रीयल-टाइम बोली-प्रक्रिया जैसे विलंबता-संवेदनशील अनुप्रयोगों के लिए यह दृष्टिकोण धीमा हो सकता है। इसके बजाय, माध्य-फ़ील्ड विधि का उपयोग करके \(E(p(x))\) का अनुमान लगा सकते हैं:
\[E(p(x)) \approx softmax(\frac{logit(x)}{\sqrt{1+ \lambda * \sigma^2(x)} })\]
जहां \(\sigma^2(x)\) SNGP विचरण है, और \(\lambda\) को अक्सर \(\pi/8\) या \(3/\pi^2\)के रूप में चुना जाता है।
sngp_logits_adjusted = sngp_logits / tf.sqrt(1. + (np.pi / 8.) * sngp_variance)
sngp_probs = tf.nn.softmax(sngp_logits_adjusted, axis=-1)[:, 0]
यह माध्य-क्षेत्र विधि एक अंतर्निहित फ़ंक्शन के रूप में कार्यान्वित की जाती है layers.gaussian_process.mean_field_logits :
def compute_posterior_mean_probability(logits, covmat, lambda_param=np.pi / 8.):
# Computes uncertainty-adjusted logits using the built-in method.
logits_adjusted = nlp_layers.gaussian_process.mean_field_logits(
logits, covmat, mean_field_factor=lambda_param)
return tf.nn.softmax(logits_adjusted, axis=-1)[:, 0]
sngp_logits, sngp_covmat = sngp_model(test_examples, return_covmat=True)
sngp_probs = compute_posterior_mean_probability(sngp_logits, sngp_covmat)
एसएनजीपी सारांश
def plot_predictions(pred_probs, model_name=""):
"""Plot normalized class probabilities and predictive uncertainties."""
# Compute predictive uncertainty.
uncertainty = pred_probs * (1. - pred_probs)
# Initialize the plot axes.
fig, axs = plt.subplots(1, 2, figsize=(14, 5))
# Plots the class probability.
pcm_0 = plot_uncertainty_surface(pred_probs, ax=axs[0])
# Plots the predictive uncertainty.
pcm_1 = plot_uncertainty_surface(uncertainty, ax=axs[1])
# Adds color bars and titles.
fig.colorbar(pcm_0, ax=axs[0])
fig.colorbar(pcm_1, ax=axs[1])
axs[0].set_title(f"Class Probability, {model_name}")
axs[1].set_title(f"(Normalized) Predictive Uncertainty, {model_name}")
plt.show()
सब कुछ एक साथ रखो। पूरी प्रक्रिया (प्रशिक्षण, मूल्यांकन और अनिश्चितता की गणना) सिर्फ पांच पंक्तियों में की जा सकती है:
def train_and_test_sngp(train_examples, test_examples):
sngp_model = DeepResNetSNGPWithCovReset(**resnet_config)
sngp_model.compile(**train_config)
sngp_model.fit(train_examples, train_labels, verbose=0, **fit_config)
sngp_logits, sngp_covmat = sngp_model(test_examples, return_covmat=True)
sngp_probs = compute_posterior_mean_probability(sngp_logits, sngp_covmat)
return sngp_probs
sngp_probs = train_and_test_sngp(train_examples, test_examples)
एसएनजीपी मॉडल की वर्ग संभावना (बाएं) और भविष्य कहनेवाला अनिश्चितता (दाएं) की कल्पना करें।
plot_predictions(sngp_probs, model_name="SNGP")

याद रखें कि वर्ग प्रायिकता प्लॉट (बाएं) में, पीला और बैंगनी वर्ग प्रायिकताएं हैं। जब प्रशिक्षण डेटा डोमेन के करीब, एसएनजीपी उच्च आत्मविश्वास के साथ उदाहरणों को सही ढंग से वर्गीकृत करता है (यानी, 0 या 1 संभावना के करीब असाइन करना)। प्रशिक्षण डेटा से दूर होने पर, एसएनजीपी धीरे-धीरे कम आत्मविश्वासी हो जाता है, और इसकी भविष्य कहनेवाला संभावना 0.5 के करीब हो जाती है जबकि (सामान्यीकृत) मॉडल अनिश्चितता बढ़कर 1 हो जाती है।
इसकी तुलना नियतात्मक मॉडल की अनिश्चितता सतह से करें:
plot_predictions(resnet_probs, model_name="Deterministic")

जैसा कि पहले उल्लेख किया गया है, एक नियतात्मक मॉडल दूरी-जागरूक नहीं है। इसकी अनिश्चितता को निर्णय सीमा से परीक्षण उदाहरण की दूरी से परिभाषित किया जाता है। यह मॉडल को आउट-ऑफ-डोमेन उदाहरणों (लाल) के लिए अति-आत्मविश्वास पूर्वानुमान उत्पन्न करने के लिए प्रेरित करता है।
अन्य अनिश्चितता दृष्टिकोणों के साथ तुलना
यह खंड एसएनजीपी की अनिश्चितता की तुलना मोंटे कार्लो ड्रॉपआउट और डीप एसेम्बल से करता है।
ये दोनों तरीके मोंटे कार्लो पर आधारित हैं, जो नियतात्मक मॉडल के कई फॉरवर्ड पास के औसत हैं। पहले पहनावा आकार \(M\)सेट करें।
num_ensemble = 10
मोंटे कार्लो ड्रॉपआउट
ड्रॉपआउट परतों के साथ एक प्रशिक्षित तंत्रिका नेटवर्क को देखते हुए, मोंटे कार्लो ड्रॉपआउट औसत भविष्य कहनेवाला संभावना की गणना करता है
\[E(p(x)) = \frac{1}{M}\sum_{m=1}^M softmax(logit_m(x))\]
एकाधिक ड्रॉपआउट-सक्षम फॉरवर्ड पास \(\{logit_m(x)\}_{m=1}^M\)पर औसत से।
def mc_dropout_sampling(test_examples):
# Enable dropout during inference.
return resnet_model(test_examples, training=True)
# Monte Carlo dropout inference.
dropout_logit_samples = [mc_dropout_sampling(test_examples) for _ in range(num_ensemble)]
dropout_prob_samples = [tf.nn.softmax(dropout_logits, axis=-1)[:, 0] for dropout_logits in dropout_logit_samples]
dropout_probs = tf.reduce_mean(dropout_prob_samples, axis=0)
dropout_probs = tf.reduce_mean(dropout_prob_samples, axis=0)
plot_predictions(dropout_probs, model_name="MC Dropout")

गहरा पहनावा
गहन शिक्षण अनिश्चितता के लिए डीप एसेम्बल एक अत्याधुनिक (लेकिन महंगी) विधि है। एक डीप पहनावा को प्रशिक्षित करने के लिए, पहले \(M\) कलाकारों की टुकड़ी को प्रशिक्षित करें।
# Deep ensemble training
resnet_ensemble = []
for _ in range(num_ensemble):
resnet_model = DeepResNet(**resnet_config)
resnet_model.compile(optimizer=optimizer, loss=loss, metrics=metrics)
resnet_model.fit(train_examples, train_labels, verbose=0, **fit_config)
resnet_ensemble.append(resnet_model)
लघुगणक एकत्र करें और माध्य पूर्वानुमानित प्रायिकता \(E(p(x)) = \frac{1}{M}\sum_{m=1}^M softmax(logit_m(x))\)परिकलित करें।
# Deep ensemble inference
ensemble_logit_samples = [model(test_examples) for model in resnet_ensemble]
ensemble_prob_samples = [tf.nn.softmax(logits, axis=-1)[:, 0] for logits in ensemble_logit_samples]
ensemble_probs = tf.reduce_mean(ensemble_prob_samples, axis=0)
plot_predictions(ensemble_probs, model_name="Deep ensemble")

MC ड्रॉपआउट और डीप पहनावा दोनों निर्णय सीमा को कम निश्चित करके एक मॉडल की अनिश्चितता क्षमता में सुधार करते हैं। हालांकि, वे दोनों दूरी जागरूकता की कमी में नियतात्मक गहरे नेटवर्क की सीमा को प्राप्त करते हैं।
सारांश
इस ट्यूटोरियल में, आपके पास है:
- अपनी दूरी जागरूकता में सुधार के लिए एक डीप क्लासिफायर पर एक एसएनजीपी मॉडल लागू किया।
-
model.fit()एपीआई का उपयोग करके एसएनजीपी मॉडल को एंड-टू-एंड प्रशिक्षित किया। - SNGP के अनिश्चितता व्यवहार की कल्पना की।
- एसएनजीपी, मोंटे कार्लो ड्रॉपआउट और गहरे पहनावा मॉडल के बीच अनिश्चितता के व्यवहार की तुलना।
संसाधन और आगे पढ़ना
- अनिश्चितता-जागरूक प्राकृतिक भाषा समझ के लिए बीईआरटी मॉडल पर एसएनजीपी लागू करने के उदाहरण के लिए एसएनजीपी-बीईआरटी ट्यूटोरियल देखें।
- बेंचमार्क डेटासेट (जैसे, सीआईएफएआर , इमेजनेट , आरा विषाक्तता का पता लगाने , आदि) की एक विस्तृत विविधता पर एसएनजीपी मॉडल (और कई अन्य अनिश्चितता विधियों) के कार्यान्वयन के लिए अनिश्चितता आधार रेखा देखें।
- एसएनजीपी पद्धति की गहरी समझ के लिए, दूरस्थ जागरूकता के माध्यम से नियतात्मक गहन शिक्षण के साथ सरल और सैद्धांतिक अनिश्चितता अनुमान पेपर देखें।