
| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
Tutorial ini menunjukkan cara menerapkan metode Actor-Critic menggunakan TensorFlow untuk melatih agen di lingkungan Open AI Gym CartPole-V0. Pembaca diasumsikan memiliki beberapa keakraban dengan metode gradien kebijakan pembelajaran penguatan.
Metode Aktor-Kritik
Metode Actor-Critic adalah metode pembelajaran perbedaan temporal (TD) yang merepresentasikan fungsi kebijakan yang tidak bergantung pada fungsi nilai.
Fungsi kebijakan (atau kebijakan) mengembalikan distribusi probabilitas atas tindakan yang dapat dilakukan agen berdasarkan status yang diberikan. Fungsi nilai menentukan pengembalian yang diharapkan untuk agen mulai dari keadaan tertentu dan bertindak sesuai dengan kebijakan tertentu selamanya.
Dalam metode Actor-Critic, kebijakan disebut sebagai aktor yang mengusulkan serangkaian kemungkinan tindakan yang diberikan suatu keadaan, dan fungsi nilai taksiran disebut sebagai kritik , yang mengevaluasi tindakan yang diambil oleh aktor berdasarkan kebijakan yang diberikan. .
Dalam tutorial ini, baik Aktor dan Kritikus akan direpresentasikan menggunakan satu jaringan saraf dengan dua keluaran.
CartPole-v0
Di lingkungan CartPole-v0 , sebuah tiang dipasang pada kereta yang bergerak di sepanjang lintasan tanpa gesekan. Tiang mulai tegak dan tujuan agen adalah untuk mencegahnya jatuh dengan menerapkan gaya -1 atau +1 ke gerobak. Hadiah +1 diberikan untuk setiap langkah tiang tetap tegak. Sebuah episode berakhir ketika (1) tiang lebih dari 15 derajat dari vertikal atau (2) kereta bergerak lebih dari 2,4 unit dari pusat.
Masalah dianggap "terpecahkan" ketika total hadiah rata-rata untuk episode tersebut mencapai 195 lebih dari 100 percobaan berturut-turut.
Mempersiapkan
Impor paket yang diperlukan dan konfigurasikan pengaturan global.
pip install gympip install pyglet
# Install additional packages for visualizationsudo apt-get install -y xvfb python-opengl > /dev/null 2>&1pip install pyvirtualdisplay > /dev/null 2>&1pip install git+https://github.com/tensorflow/docs > /dev/null 2>&1
import collections
import gym
import numpy as np
import statistics
import tensorflow as tf
import tqdm
from matplotlib import pyplot as plt
from tensorflow.keras import layers
from typing import Any, List, Sequence, Tuple
# Create the environment
env = gym.make("CartPole-v0")
# Set seed for experiment reproducibility
seed = 42
env.seed(seed)
tf.random.set_seed(seed)
np.random.seed(seed)
# Small epsilon value for stabilizing division operations
eps = np.finfo(np.float32).eps.item()
Model
Aktor dan Kritik akan dimodelkan menggunakan satu jaringan saraf yang menghasilkan probabilitas aksi dan nilai kritik masing-masing. Tutorial ini menggunakan model subclassing untuk mendefinisikan model.
Selama forward pass, model akan mengambil status sebagai input dan akan menampilkan probabilitas aksi dan nilai kritik \(V\), yang memodelkan fungsi nilai yang bergantung pada status . Tujuannya adalah untuk melatih model yang memilih tindakan berdasarkan kebijakan \(\pi\) yang memaksimalkan pengembalian yang diharapkan .
Untuk Cartpole-v0, ada empat nilai yang mewakili keadaan: posisi gerobak, kecepatan gerobak, sudut kutub dan kecepatan kutub masing-masing. Agen dapat mengambil dua tindakan untuk masing-masing mendorong gerobak ke kiri (0) dan ke kanan (1).
Lihat halaman wiki CartPole-v0 OpenAI Gym untuk informasi lebih lanjut.
class ActorCritic(tf.keras.Model):
"""Combined actor-critic network."""
def __init__(
self,
num_actions: int,
num_hidden_units: int):
"""Initialize."""
super().__init__()
self.common = layers.Dense(num_hidden_units, activation="relu")
self.actor = layers.Dense(num_actions)
self.critic = layers.Dense(1)
def call(self, inputs: tf.Tensor) -> Tuple[tf.Tensor, tf.Tensor]:
x = self.common(inputs)
return self.actor(x), self.critic(x)
num_actions = env.action_space.n # 2
num_hidden_units = 128
model = ActorCritic(num_actions, num_hidden_units)
Pelatihan
Untuk melatih agen, Anda akan mengikuti langkah-langkah berikut:
- Jalankan agen di lingkungan untuk mengumpulkan data pelatihan per episode.
- Hitung pengembalian yang diharapkan pada setiap langkah waktu.
- Hitung kerugian untuk model gabungan aktor-kritik.
- Hitung gradien dan perbarui parameter jaringan.
- Ulangi 1-4 hingga kriteria sukses atau episode maksimal tercapai.
1. Mengumpulkan data pelatihan
Seperti dalam pembelajaran terawasi, untuk melatih model kritik aktor, Anda perlu memiliki data pelatihan. Namun, untuk mengumpulkan data seperti itu, model perlu "dijalankan" di lingkungan.
Data pelatihan dikumpulkan untuk setiap episode. Kemudian pada setiap langkah waktu, model forward pass akan dijalankan pada keadaan lingkungan untuk menghasilkan probabilitas tindakan dan nilai kritik berdasarkan kebijakan saat ini yang diparameterisasi oleh bobot model.
Tindakan selanjutnya akan diambil sampelnya dari probabilitas tindakan yang dihasilkan oleh model, yang kemudian akan diterapkan ke lingkungan, menyebabkan keadaan dan hadiah berikutnya dihasilkan.
Proses ini diimplementasikan dalam fungsi run_episode , yang menggunakan operasi TensorFlow sehingga nantinya dapat dikompilasi menjadi grafik TensorFlow untuk pelatihan yang lebih cepat. Perhatikan bahwa tf.TensorArray s digunakan untuk mendukung iterasi Tensor pada array panjang variabel.
# Wrap OpenAI Gym's `env.step` call as an operation in a TensorFlow function.
# This would allow it to be included in a callable TensorFlow graph.
def env_step(action: np.ndarray) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:
"""Returns state, reward and done flag given an action."""
state, reward, done, _ = env.step(action)
return (state.astype(np.float32),
np.array(reward, np.int32),
np.array(done, np.int32))
def tf_env_step(action: tf.Tensor) -> List[tf.Tensor]:
return tf.numpy_function(env_step, [action],
[tf.float32, tf.int32, tf.int32])
def run_episode(
initial_state: tf.Tensor,
model: tf.keras.Model,
max_steps: int) -> Tuple[tf.Tensor, tf.Tensor, tf.Tensor]:
"""Runs a single episode to collect training data."""
action_probs = tf.TensorArray(dtype=tf.float32, size=0, dynamic_size=True)
values = tf.TensorArray(dtype=tf.float32, size=0, dynamic_size=True)
rewards = tf.TensorArray(dtype=tf.int32, size=0, dynamic_size=True)
initial_state_shape = initial_state.shape
state = initial_state
for t in tf.range(max_steps):
# Convert state into a batched tensor (batch size = 1)
state = tf.expand_dims(state, 0)
# Run the model and to get action probabilities and critic value
action_logits_t, value = model(state)
# Sample next action from the action probability distribution
action = tf.random.categorical(action_logits_t, 1)[0, 0]
action_probs_t = tf.nn.softmax(action_logits_t)
# Store critic values
values = values.write(t, tf.squeeze(value))
# Store log probability of the action chosen
action_probs = action_probs.write(t, action_probs_t[0, action])
# Apply action to the environment to get next state and reward
state, reward, done = tf_env_step(action)
state.set_shape(initial_state_shape)
# Store reward
rewards = rewards.write(t, reward)
if tf.cast(done, tf.bool):
break
action_probs = action_probs.stack()
values = values.stack()
rewards = rewards.stack()
return action_probs, values, rewards
2. Menghitung pengembalian yang diharapkan
Urutan hadiah untuk setiap langkah waktu \(t\), \(\{r_{t}\}^{T}_{t=1}\) dikumpulkan selama satu episode diubah menjadi urutan pengembalian yang diharapkan \(\{G_{t}\}^{T}_{t=1}\) di mana jumlah hadiah diambil dari langkah waktu saat ini \(t\) ke \(T\) dan masing-masing hadiah dikalikan dengan faktor diskon yang menurun secara eksponensial \(\gamma\):
\[G_{t} = \sum^{T}_{t'=t} \gamma^{t'-t}r_{t'}\]
Sejak \(\gamma\in(0,1)\), hadiah lebih jauh dari timestep saat ini diberi bobot lebih sedikit.
Secara intuitif, pengembalian yang diharapkan hanya menyiratkan bahwa imbalan sekarang lebih baik daripada imbalan nanti. Dalam arti matematis, ini adalah untuk memastikan bahwa jumlah dari hadiahnya konvergen.
Untuk menstabilkan pelatihan, urutan pengembalian yang dihasilkan juga distandarisasi (yaitu memiliki mean nol dan standar deviasi unit).
def get_expected_return(
rewards: tf.Tensor,
gamma: float,
standardize: bool = True) -> tf.Tensor:
"""Compute expected returns per timestep."""
n = tf.shape(rewards)[0]
returns = tf.TensorArray(dtype=tf.float32, size=n)
# Start from the end of `rewards` and accumulate reward sums
# into the `returns` array
rewards = tf.cast(rewards[::-1], dtype=tf.float32)
discounted_sum = tf.constant(0.0)
discounted_sum_shape = discounted_sum.shape
for i in tf.range(n):
reward = rewards[i]
discounted_sum = reward + gamma * discounted_sum
discounted_sum.set_shape(discounted_sum_shape)
returns = returns.write(i, discounted_sum)
returns = returns.stack()[::-1]
if standardize:
returns = ((returns - tf.math.reduce_mean(returns)) /
(tf.math.reduce_std(returns) + eps))
return returns
3. Kerugian aktor-kritikus
Karena model hybrid aktor-kritik digunakan, fungsi kerugian yang dipilih adalah kombinasi dari kerugian aktor dan kritikus untuk pelatihan, seperti yang ditunjukkan di bawah ini:
\[L = L_{actor} + L_{critic}\]
Kehilangan aktor
Kerugian aktor didasarkan pada gradien kebijakan dengan pengkritik sebagai baseline yang bergantung pada negara bagian dan dihitung dengan estimasi sampel tunggal (per episode).
\[L_{actor} = -\sum^{T}_{t=1} \log\pi_{\theta}(a_{t} | s_{t})[G(s_{t}, a_{t}) - V^{\pi}_{\theta}(s_{t})]\]
di mana:
- \(T\): jumlah langkah waktu per episode, yang dapat bervariasi per episode
- \(s_{t}\): status pada timestep \(t\)
- \(a_{t}\): tindakan yang dipilih pada langkah waktu \(t\) diberikan status \(s\)
- \(\pi_{\theta}\): adalah kebijakan (aktor) yang diparameterisasi oleh \(\theta\)
- \(V^{\pi}_{\theta}\): adalah fungsi nilai (kritikus) yang juga diparameterisasi oleh \(\theta\)
- \(G = G_{t}\): pengembalian yang diharapkan untuk keadaan tertentu, pasangan aksi pada timestep \(t\)
Sebuah istilah negatif ditambahkan ke jumlah karena idenya adalah untuk memaksimalkan probabilitas tindakan menghasilkan imbalan yang lebih tinggi dengan meminimalkan kerugian gabungan.
Keuntungan
Istilah \(G - V\) \(L_{actor}\) dalam formulasi l10n-placeholder26 kami disebut keuntungan , yang menunjukkan seberapa jauh lebih baik suatu tindakan diberikan keadaan tertentu daripada tindakan acak yang dipilih menurut kebijakan \(\pi\) untuk keadaan itu.
Meskipun mungkin untuk mengecualikan baseline, hal ini dapat mengakibatkan varians yang tinggi selama pelatihan. Dan hal yang menyenangkan tentang memilih kritikus \(V\) sebagai dasar adalah bahwa ia dilatih untuk sedekat mungkin dengan \(G\), yang mengarah ke varians yang lebih rendah.
Selain itu, tanpa kritik, algoritme akan mencoba meningkatkan probabilitas untuk tindakan yang diambil pada keadaan tertentu berdasarkan pengembalian yang diharapkan, yang mungkin tidak membuat banyak perbedaan jika probabilitas relatif antara tindakan tetap sama.
Misalnya, anggaplah bahwa dua tindakan untuk keadaan tertentu akan menghasilkan pengembalian yang diharapkan yang sama. Tanpa kritik, algoritme akan mencoba meningkatkan kemungkinan tindakan ini berdasarkan tujuan \(J\). Dengan kritik, mungkin ternyata tidak ada keuntungan (\(G - V = 0\)) dan dengan demikian tidak ada manfaat yang diperoleh dalam meningkatkan probabilitas tindakan dan algoritme akan mengatur gradien ke nol.
Kerugian kritik
Melatih \(V\) agar sedekat mungkin dengan \(G\) dapat diatur sebagai masalah regresi dengan fungsi kerugian berikut:
\[L_{critic} = L_{\delta}(G, V^{\pi}_{\theta})\]
di mana \(L_{\delta}\) adalah kerugian Huber , yang kurang sensitif terhadap outlier dalam data daripada kerugian kesalahan kuadrat.
huber_loss = tf.keras.losses.Huber(reduction=tf.keras.losses.Reduction.SUM)
def compute_loss(
action_probs: tf.Tensor,
values: tf.Tensor,
returns: tf.Tensor) -> tf.Tensor:
"""Computes the combined actor-critic loss."""
advantage = returns - values
action_log_probs = tf.math.log(action_probs)
actor_loss = -tf.math.reduce_sum(action_log_probs * advantage)
critic_loss = huber_loss(values, returns)
return actor_loss + critic_loss
4. Menentukan langkah pelatihan untuk memperbarui parameter
Semua langkah di atas digabungkan menjadi langkah pelatihan yang dijalankan setiap episode. Semua langkah yang mengarah ke fungsi kerugian dijalankan dengan konteks tf.GradientTape untuk mengaktifkan diferensiasi otomatis.
Tutorial ini menggunakan pengoptimal Adam untuk menerapkan gradien ke parameter model.
Jumlah hadiah yang tidak didiskon, episode_reward , juga dihitung dalam langkah ini. Nilai ini nantinya akan digunakan untuk mengevaluasi apakah kriteria keberhasilan terpenuhi.
Konteks tf.function diterapkan ke fungsi train_step sehingga dapat dikompilasi menjadi grafik TensorFlow yang dapat dipanggil, yang dapat menghasilkan 10x percepatan dalam pelatihan.
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
@tf.function
def train_step(
initial_state: tf.Tensor,
model: tf.keras.Model,
optimizer: tf.keras.optimizers.Optimizer,
gamma: float,
max_steps_per_episode: int) -> tf.Tensor:
"""Runs a model training step."""
with tf.GradientTape() as tape:
# Run the model for one episode to collect training data
action_probs, values, rewards = run_episode(
initial_state, model, max_steps_per_episode)
# Calculate expected returns
returns = get_expected_return(rewards, gamma)
# Convert training data to appropriate TF tensor shapes
action_probs, values, returns = [
tf.expand_dims(x, 1) for x in [action_probs, values, returns]]
# Calculating loss values to update our network
loss = compute_loss(action_probs, values, returns)
# Compute the gradients from the loss
grads = tape.gradient(loss, model.trainable_variables)
# Apply the gradients to the model's parameters
optimizer.apply_gradients(zip(grads, model.trainable_variables))
episode_reward = tf.math.reduce_sum(rewards)
return episode_reward
5. Jalankan loop pelatihan
Pelatihan dijalankan dengan menjalankan langkah pelatihan sampai kriteria keberhasilan atau jumlah episode maksimum tercapai.
Catatan hadiah episode yang berjalan disimpan dalam antrian. Setelah 100 percobaan tercapai, hadiah tertua dihapus di ujung kiri (ekor) antrian dan yang terbaru ditambahkan di kepala (kanan). Sejumlah hadiah juga dipertahankan untuk efisiensi komputasi.
Tergantung pada runtime Anda, pelatihan dapat selesai dalam waktu kurang dari satu menit.
%%time
min_episodes_criterion = 100
max_episodes = 10000
max_steps_per_episode = 1000
# Cartpole-v0 is considered solved if average reward is >= 195 over 100
# consecutive trials
reward_threshold = 195
running_reward = 0
# Discount factor for future rewards
gamma = 0.99
# Keep last episodes reward
episodes_reward: collections.deque = collections.deque(maxlen=min_episodes_criterion)
with tqdm.trange(max_episodes) as t:
for i in t:
initial_state = tf.constant(env.reset(), dtype=tf.float32)
episode_reward = int(train_step(
initial_state, model, optimizer, gamma, max_steps_per_episode))
episodes_reward.append(episode_reward)
running_reward = statistics.mean(episodes_reward)
t.set_description(f'Episode {i}')
t.set_postfix(
episode_reward=episode_reward, running_reward=running_reward)
# Show average episode reward every 10 episodes
if i % 10 == 0:
pass # print(f'Episode {i}: average reward: {avg_reward}')
if running_reward > reward_threshold and i >= min_episodes_criterion:
break
print(f'\nSolved at episode {i}: average reward: {running_reward:.2f}!')
Episode 361: 4%|▎ | 361/10000 [01:13<32:33, 4.93it/s, episode_reward=182, running_reward=195] Solved at episode 361: average reward: 195.14! CPU times: user 2min 46s, sys: 35.4 s, total: 3min 21s Wall time: 1min 13s
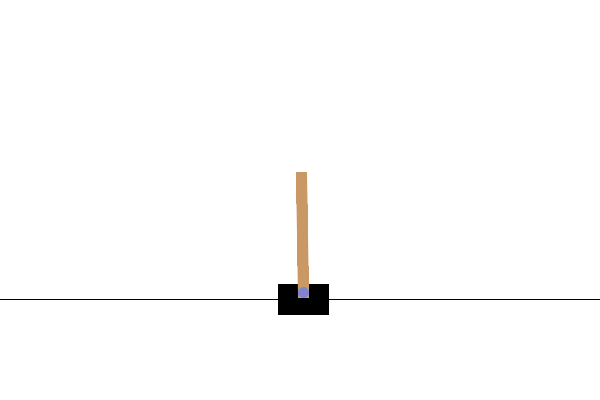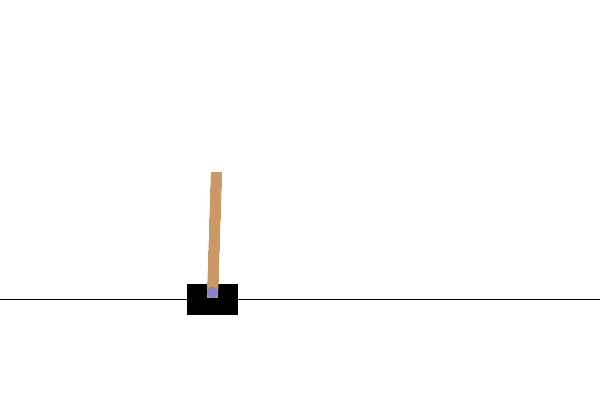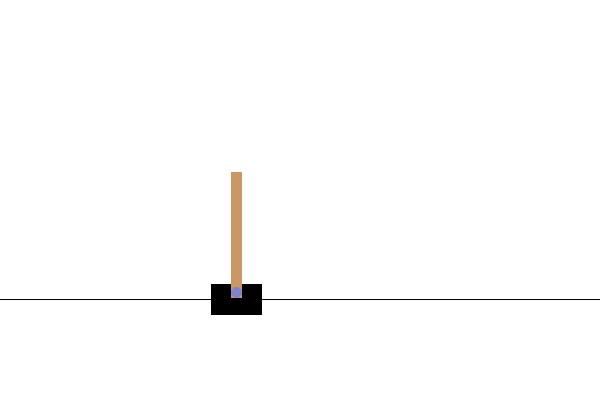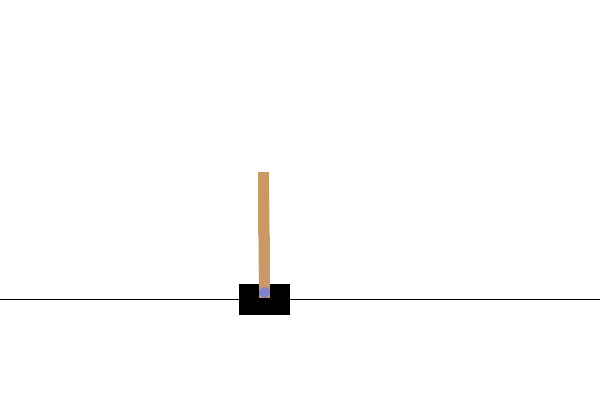
visualisasi
Setelah pelatihan, akan baik untuk memvisualisasikan bagaimana model tampil di lingkungan. Anda dapat menjalankan sel di bawah ini untuk menghasilkan animasi GIF dari satu episode menjalankan model. Perhatikan bahwa paket tambahan perlu diinstal untuk OpenAI Gym agar dapat merender gambar lingkungan dengan benar di Colab.
# Render an episode and save as a GIF file
from IPython import display as ipythondisplay
from PIL import Image
from pyvirtualdisplay import Display
display = Display(visible=0, size=(400, 300))
display.start()
def render_episode(env: gym.Env, model: tf.keras.Model, max_steps: int):
screen = env.render(mode='rgb_array')
im = Image.fromarray(screen)
images = [im]
state = tf.constant(env.reset(), dtype=tf.float32)
for i in range(1, max_steps + 1):
state = tf.expand_dims(state, 0)
action_probs, _ = model(state)
action = np.argmax(np.squeeze(action_probs))
state, _, done, _ = env.step(action)
state = tf.constant(state, dtype=tf.float32)
# Render screen every 10 steps
if i % 10 == 0:
screen = env.render(mode='rgb_array')
images.append(Image.fromarray(screen))
if done:
break
return images
# Save GIF image
images = render_episode(env, model, max_steps_per_episode)
image_file = 'cartpole-v0.gif'
# loop=0: loop forever, duration=1: play each frame for 1ms
images[0].save(
image_file, save_all=True, append_images=images[1:], loop=0, duration=1)
import tensorflow_docs.vis.embed as embed
embed.embed_file(image_file)
Langkah selanjutnya
Tutorial ini menunjukkan cara mengimplementasikan metode aktor-kritik menggunakan Tensorflow.
Sebagai langkah selanjutnya, Anda dapat mencoba melatih model di lingkungan yang berbeda di OpenAI Gym.
Untuk informasi tambahan mengenai metode aktor-kritik dan masalah Cartpole-v0, Anda dapat merujuk ke sumber daya berikut:
- Metode Kritik Aktor
- Kuliah Kritik Aktor (CAL)
- Masalah kontrol pembelajaran carpole [Barto, et al. 1983]
Untuk contoh pembelajaran penguatan lainnya di TensorFlow, Anda dapat memeriksa referensi berikut: