
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
यह ट्यूटोरियल दर्शाता है कि ओपन एआई जिम कार्टपोल-वी0 पर्यावरण पर एजेंट को प्रशिक्षित करने के लिए टेंसरफ्लो का उपयोग करके अभिनेता-आलोचक विधि को कैसे कार्यान्वित किया जाए। यह माना जाता है कि पाठक को सुदृढीकरण सीखने की नीति ढाल विधियों से कुछ परिचित है।
अभिनेता-आलोचक तरीके
अभिनेता-आलोचक विधियां अस्थायी अंतर (टीडी) सीखने के तरीके हैं जो मूल्य फ़ंक्शन से स्वतंत्र नीति कार्य का प्रतिनिधित्व करते हैं।
एक पॉलिसी फ़ंक्शन (या पॉलिसी) उन कार्यों पर एक संभाव्यता वितरण देता है जो एजेंट दिए गए राज्य के आधार पर ले सकता है। एक मूल्य फ़ंक्शन किसी एजेंट के लिए किसी दिए गए राज्य से शुरू होने और एक विशेष नीति के अनुसार हमेशा के लिए कार्य करने के लिए अपेक्षित रिटर्न निर्धारित करता है।
अभिनेता-आलोचक पद्धति में, नीति को अभिनेता के रूप में संदर्भित किया जाता है जो एक राज्य को दिए गए संभावित कार्यों के एक सेट का प्रस्ताव करता है, और अनुमानित मूल्य फ़ंक्शन को आलोचक के रूप में संदर्भित किया जाता है, जो दी गई नीति के आधार पर अभिनेता द्वारा की गई कार्रवाइयों का मूल्यांकन करता है। .
इस ट्यूटोरियल में, एक्टर और क्रिटिक दोनों को दो आउटपुट के साथ एक न्यूरल नेटवर्क का उपयोग करके दर्शाया जाएगा।
कार्टपोल-v0
CartPole-v0 वातावरण में, घर्षण रहित ट्रैक के साथ चलती गाड़ी से एक पोल जुड़ा होता है। खंभा सीधा शुरू होता है और एजेंट का लक्ष्य गाड़ी पर -1 या +1 का बल लगाकर इसे गिरने से रोकना है। हर बार जब ध्रुव सीधा रहता है तो +1 का इनाम दिया जाता है। एक प्रकरण समाप्त होता है जब (1) खंभा ऊर्ध्वाधर से 15 डिग्री से अधिक होता है या (2) गाड़ी केंद्र से 2.4 इकाई से अधिक चलती है।
समस्या को "समाधान" माना जाता है जब एपिसोड के लिए औसत कुल इनाम लगातार 100 से अधिक परीक्षणों में 195 तक पहुंच जाता है।
सेट अप
आवश्यक पैकेज आयात करें और वैश्विक सेटिंग्स कॉन्फ़िगर करें।
pip install gympip install pyglet
# Install additional packages for visualizationsudo apt-get install -y xvfb python-opengl > /dev/null 2>&1pip install pyvirtualdisplay > /dev/null 2>&1pip install git+https://github.com/tensorflow/docs > /dev/null 2>&1
import collections
import gym
import numpy as np
import statistics
import tensorflow as tf
import tqdm
from matplotlib import pyplot as plt
from tensorflow.keras import layers
from typing import Any, List, Sequence, Tuple
# Create the environment
env = gym.make("CartPole-v0")
# Set seed for experiment reproducibility
seed = 42
env.seed(seed)
tf.random.set_seed(seed)
np.random.seed(seed)
# Small epsilon value for stabilizing division operations
eps = np.finfo(np.float32).eps.item()
नमूना
अभिनेता और आलोचक को एक तंत्रिका नेटवर्क का उपयोग करके मॉडलिंग की जाएगी जो क्रमशः क्रिया संभावनाएं और आलोचक मूल्य उत्पन्न करता है। यह ट्यूटोरियल मॉडल को परिभाषित करने के लिए मॉडल सबक्लासिंग का उपयोग करता है।
फॉरवर्ड पास के दौरान, मॉडल राज्य में इनपुट के रूप में लेगा और एक्शन संभावनाओं और आलोचक मूल्य \(V\)दोनों को आउटपुट करेगा, जो राज्य-निर्भर मान फ़ंक्शन को मॉडल करता है। लक्ष्य एक ऐसे मॉडल को प्रशिक्षित करना है जो एक नीति \(\pi\) आधार पर कार्रवाइयां चुनता है जो अपेक्षित रिटर्न को अधिकतम करता है।
कार्टपोल-v0 के लिए, राज्य का प्रतिनिधित्व करने वाले चार मान हैं: गाड़ी की स्थिति, गाड़ी-वेग, ध्रुव कोण और ध्रुव वेग क्रमशः। एजेंट गाड़ी को क्रमशः बाएँ (0) और दाएँ (1) धकेलने के लिए दो क्रियाएँ कर सकता है।
अधिक जानकारी के लिए OpenAI जिम का CartPole-v0 विकी पेज देखें।
class ActorCritic(tf.keras.Model):
"""Combined actor-critic network."""
def __init__(
self,
num_actions: int,
num_hidden_units: int):
"""Initialize."""
super().__init__()
self.common = layers.Dense(num_hidden_units, activation="relu")
self.actor = layers.Dense(num_actions)
self.critic = layers.Dense(1)
def call(self, inputs: tf.Tensor) -> Tuple[tf.Tensor, tf.Tensor]:
x = self.common(inputs)
return self.actor(x), self.critic(x)
num_actions = env.action_space.n # 2
num_hidden_units = 128
model = ActorCritic(num_actions, num_hidden_units)
प्रशिक्षण
एजेंट को प्रशिक्षित करने के लिए, आप इन चरणों का पालन करेंगे:
- प्रति एपिसोड प्रशिक्षण डेटा एकत्र करने के लिए एजेंट को पर्यावरण पर चलाएं।
- हर समय कदम पर अपेक्षित रिटर्न की गणना करें।
- संयुक्त अभिनेता-आलोचक मॉडल के लिए नुकसान की गणना करें।
- ग्रेडिएंट की गणना करें और नेटवर्क पैरामीटर अपडेट करें।
- सफलता मानदंड या अधिकतम एपिसोड तक पहुंचने तक 1-4 दोहराएं।
1. प्रशिक्षण डेटा एकत्र करना
पर्यवेक्षित शिक्षण की तरह, अभिनेता-आलोचक मॉडल को प्रशिक्षित करने के लिए, आपके पास प्रशिक्षण डेटा होना चाहिए। हालांकि, इस तरह के डेटा को इकट्ठा करने के लिए, मॉडल को पर्यावरण में "चलाने" की आवश्यकता होगी।
प्रत्येक एपिसोड के लिए प्रशिक्षण डेटा एकत्र किया जाता है। फिर हर समय कदम पर, मॉडल के वजन के आधार पर मौजूदा नीति के आधार पर कार्रवाई की संभावनाएं और आलोचक मूल्य उत्पन्न करने के लिए मॉडल का फॉरवर्ड पास पर्यावरण की स्थिति पर चलाया जाएगा।
अगली कार्रवाई को मॉडल द्वारा उत्पन्न कार्रवाई संभावनाओं से नमूना लिया जाएगा, जिसे तब पर्यावरण पर लागू किया जाएगा, जिससे अगला राज्य और इनाम उत्पन्न होगा।
इस प्रक्रिया को run_episode फ़ंक्शन में कार्यान्वित किया जाता है, जो TensorFlow संचालन का उपयोग करता है ताकि इसे बाद में तेजी से प्रशिक्षण के लिए एक TensorFlow ग्राफ में संकलित किया जा सके। ध्यान दें कि tf.TensorArray s का उपयोग चर लंबाई सरणियों पर Tensor पुनरावृत्ति का समर्थन करने के लिए किया गया था।
# Wrap OpenAI Gym's `env.step` call as an operation in a TensorFlow function.
# This would allow it to be included in a callable TensorFlow graph.
def env_step(action: np.ndarray) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:
"""Returns state, reward and done flag given an action."""
state, reward, done, _ = env.step(action)
return (state.astype(np.float32),
np.array(reward, np.int32),
np.array(done, np.int32))
def tf_env_step(action: tf.Tensor) -> List[tf.Tensor]:
return tf.numpy_function(env_step, [action],
[tf.float32, tf.int32, tf.int32])
def run_episode(
initial_state: tf.Tensor,
model: tf.keras.Model,
max_steps: int) -> Tuple[tf.Tensor, tf.Tensor, tf.Tensor]:
"""Runs a single episode to collect training data."""
action_probs = tf.TensorArray(dtype=tf.float32, size=0, dynamic_size=True)
values = tf.TensorArray(dtype=tf.float32, size=0, dynamic_size=True)
rewards = tf.TensorArray(dtype=tf.int32, size=0, dynamic_size=True)
initial_state_shape = initial_state.shape
state = initial_state
for t in tf.range(max_steps):
# Convert state into a batched tensor (batch size = 1)
state = tf.expand_dims(state, 0)
# Run the model and to get action probabilities and critic value
action_logits_t, value = model(state)
# Sample next action from the action probability distribution
action = tf.random.categorical(action_logits_t, 1)[0, 0]
action_probs_t = tf.nn.softmax(action_logits_t)
# Store critic values
values = values.write(t, tf.squeeze(value))
# Store log probability of the action chosen
action_probs = action_probs.write(t, action_probs_t[0, action])
# Apply action to the environment to get next state and reward
state, reward, done = tf_env_step(action)
state.set_shape(initial_state_shape)
# Store reward
rewards = rewards.write(t, reward)
if tf.cast(done, tf.bool):
break
action_probs = action_probs.stack()
values = values.stack()
rewards = rewards.stack()
return action_probs, values, rewards
2. अपेक्षित रिटर्न की गणना
एक एपिसोड के दौरान एकत्र किए गए प्रत्येक टाइमस्टेप \(t\)3 , \(\{r_{t}\}^{T}_{t=1}\) प्लेसहोल्डर4 के लिए पुरस्कारों का क्रम अपेक्षित रिटर्न \(\{G_{t}\}^{T}_{t=1}\) 5 के अनुक्रम में परिवर्तित किया जाता है जिसमें पुरस्कारों का योग वर्तमान टाइमस्टेप \(t\) 6 से \(T\) प्लेसहोल्डर7 में लिया जाता है और प्रत्येक इनाम को तेजी से घटते छूट कारक \(\gamma\)से गुणा किया जाता है:
\[G_{t} = \sum^{T}_{t'=t} \gamma^{t'-t}r_{t'}\]
\(\gamma\in(0,1)\)बाद से, वर्तमान समय-चरण से आगे के पुरस्कारों को कम महत्व दिया जाता है।
सहज रूप से, अपेक्षित प्रतिफल का सीधा सा अर्थ है कि अब पुरस्कार बाद के पुरस्कारों से बेहतर हैं। गणितीय अर्थ में, यह सुनिश्चित करना है कि पुरस्कारों का योग अभिसरण हो।
प्रशिक्षण को स्थिर करने के लिए, रिटर्न के परिणामी अनुक्रम को भी मानकीकृत किया जाता है (अर्थात शून्य माध्य और इकाई मानक विचलन)।
def get_expected_return(
rewards: tf.Tensor,
gamma: float,
standardize: bool = True) -> tf.Tensor:
"""Compute expected returns per timestep."""
n = tf.shape(rewards)[0]
returns = tf.TensorArray(dtype=tf.float32, size=n)
# Start from the end of `rewards` and accumulate reward sums
# into the `returns` array
rewards = tf.cast(rewards[::-1], dtype=tf.float32)
discounted_sum = tf.constant(0.0)
discounted_sum_shape = discounted_sum.shape
for i in tf.range(n):
reward = rewards[i]
discounted_sum = reward + gamma * discounted_sum
discounted_sum.set_shape(discounted_sum_shape)
returns = returns.write(i, discounted_sum)
returns = returns.stack()[::-1]
if standardize:
returns = ((returns - tf.math.reduce_mean(returns)) /
(tf.math.reduce_std(returns) + eps))
return returns
3. अभिनेता-आलोचक का नुकसान
चूंकि एक हाइब्रिड अभिनेता-आलोचक मॉडल का उपयोग किया जाता है, इसलिए चुना गया नुकसान फ़ंक्शन प्रशिक्षण के लिए अभिनेता और आलोचक के नुकसान का एक संयोजन है, जैसा कि नीचे दिखाया गया है:
\[L = L_{actor} + L_{critic}\]
अभिनेता का नुकसान
अभिनेता का नुकसान राज्य पर निर्भर आधार रेखा के रूप में आलोचक के साथ नीतिगत ढाल पर आधारित है और एकल-नमूना (प्रति-एपिसोड) अनुमानों के साथ गणना की जाती है।
\[L_{actor} = -\sum^{T}_{t=1} \log\pi_{\theta}(a_{t} | s_{t})[G(s_{t}, a_{t}) - V^{\pi}_{\theta}(s_{t})]\]
कहाँ पे:
- \(T\): प्रति एपिसोड टाइमस्टेप्स की संख्या, जो प्रति एपिसोड अलग-अलग हो सकती है
- \(s_{t}\): समय पर स्थिति \(t\)
- \(a_{t}\): टाइमस्टेप पर चुनी गई कार्रवाई \(t\) 17 दी गई स्थिति \(s\)
- \(\pi_{\theta}\): l10n- \(\theta\). द्वारा निर्धारित नीति (अभिनेता) है
- \(V^{\pi}_{\theta}\): मान फ़ंक्शन (आलोचक) भी \(\theta\)द्वारा परिचालित किया गया है
- \(G = G_{t}\): किसी दिए गए राज्य के लिए अपेक्षित रिटर्न, टाइमस्टेप \(t\)पर एक्शन पेयर
योग में एक नकारात्मक शब्द जोड़ा जाता है क्योंकि विचार संयुक्त नुकसान को कम करके उच्च पुरस्कार देने वाले कार्यों की संभावनाओं को अधिकतम करना है।
लाभ
हमारे \(L_{actor}\) फॉर्मूलेशन में \(G - V\) शब्द को एडवांटेज कहा जाता है, जो इंगित करता है कि किसी विशेष स्थिति को उस राज्य के लिए नीति \(\pi\) के अनुसार चुनी गई रैंडम एक्शन की तुलना में कितना बेहतर दिया जाता है।
हालांकि आधार रेखा को बाहर करना संभव है, इसके परिणामस्वरूप प्रशिक्षण के दौरान उच्च भिन्नता हो सकती है। और आलोचक \(V\) को आधार रेखा के रूप में चुनने के बारे में अच्छी बात यह है कि यह जितना संभव हो सके \(G\)के करीब होने के लिए प्रशिक्षित होता है, जिससे कम विचरण होता है।
इसके अलावा, आलोचक के बिना, एल्गोरिथ्म अपेक्षित रिटर्न के आधार पर किसी विशेष राज्य पर की गई कार्रवाइयों के लिए संभावनाओं को बढ़ाने की कोशिश करेगा, जो कि बहुत अंतर नहीं कर सकता है यदि क्रियाओं के बीच सापेक्ष संभावनाएं समान रहती हैं।
उदाहरण के लिए, मान लीजिए कि किसी दिए गए राज्य के लिए दो कार्रवाइयां समान अपेक्षित प्रतिफल प्राप्त करेंगी। आलोचक के बिना, एल्गोरिथ्म \(J\)उद्देश्य के आधार पर इन कार्यों की संभावना को बढ़ाने का प्रयास करेगा। आलोचक के साथ, यह पता चल सकता है कि कोई फायदा नहीं है (\(G - V = 0\)) और इस प्रकार क्रियाओं की संभावनाओं को बढ़ाने में कोई लाभ नहीं हुआ और एल्गोरिथ्म ग्रेडिएंट को शून्य पर सेट कर देगा।
आलोचनात्मक नुकसान
प्रशिक्षण \(V\) को \(G\) -placeholder33 के जितना संभव हो सके, निम्न हानि फ़ंक्शन के साथ प्रतिगमन समस्या के रूप में स्थापित किया जा सकता है:
\[L_{critic} = L_{\delta}(G, V^{\pi}_{\theta})\]
जहां \(L_{\delta}\) ह्यूबर लॉस है, जो स्क्वेर्ड-एरर लॉस की तुलना में डेटा में आउटलेर्स के प्रति कम संवेदनशील है।
huber_loss = tf.keras.losses.Huber(reduction=tf.keras.losses.Reduction.SUM)
def compute_loss(
action_probs: tf.Tensor,
values: tf.Tensor,
returns: tf.Tensor) -> tf.Tensor:
"""Computes the combined actor-critic loss."""
advantage = returns - values
action_log_probs = tf.math.log(action_probs)
actor_loss = -tf.math.reduce_sum(action_log_probs * advantage)
critic_loss = huber_loss(values, returns)
return actor_loss + critic_loss
4. मापदंडों को अद्यतन करने के लिए प्रशिक्षण चरण को परिभाषित करना
उपरोक्त सभी चरणों को एक प्रशिक्षण चरण में संयोजित किया जाता है जो प्रत्येक एपिसोड को चलाया जाता है। स्वत: विभेदन को सक्षम करने के लिए हानि फ़ंक्शन तक ले जाने वाले सभी चरणों को tf.GradientTape संदर्भ के साथ निष्पादित किया जाता है।
यह ट्यूटोरियल मॉडल मापदंडों पर ग्रेडिएंट लागू करने के लिए एडम ऑप्टिमाइज़र का उपयोग करता है।
बिना छूट वाले पुरस्कारों के episode_reward की गणना भी इस चरण में की जाती है। इस मान का उपयोग बाद में मूल्यांकन करने के लिए किया जाएगा कि सफलता मानदंड पूरा हुआ है या नहीं।
tf.function संदर्भ को train_step फ़ंक्शन पर लागू किया जाता है ताकि इसे कॉल करने योग्य TensorFlow ग्राफ़ में संकलित किया जा सके, जिससे प्रशिक्षण में 10x स्पीडअप हो सकता है।
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
@tf.function
def train_step(
initial_state: tf.Tensor,
model: tf.keras.Model,
optimizer: tf.keras.optimizers.Optimizer,
gamma: float,
max_steps_per_episode: int) -> tf.Tensor:
"""Runs a model training step."""
with tf.GradientTape() as tape:
# Run the model for one episode to collect training data
action_probs, values, rewards = run_episode(
initial_state, model, max_steps_per_episode)
# Calculate expected returns
returns = get_expected_return(rewards, gamma)
# Convert training data to appropriate TF tensor shapes
action_probs, values, returns = [
tf.expand_dims(x, 1) for x in [action_probs, values, returns]]
# Calculating loss values to update our network
loss = compute_loss(action_probs, values, returns)
# Compute the gradients from the loss
grads = tape.gradient(loss, model.trainable_variables)
# Apply the gradients to the model's parameters
optimizer.apply_gradients(zip(grads, model.trainable_variables))
episode_reward = tf.math.reduce_sum(rewards)
return episode_reward
5. प्रशिक्षण लूप चलाएँ
प्रशिक्षण चरण को तब तक चलाकर प्रशिक्षण दिया जाता है जब तक कि सफलता मानदंड या एपिसोड की अधिकतम संख्या तक नहीं पहुंच जाती।
एपिसोड पुरस्कारों का एक चालू रिकॉर्ड एक कतार में रखा जाता है। एक बार 100 परीक्षणों तक पहुंचने के बाद, सबसे पुराना इनाम कतार के बाएं (पूंछ) छोर पर हटा दिया जाता है और सबसे नया इनाम सिर (दाएं) में जोड़ा जाता है। कम्प्यूटेशनल दक्षता के लिए पुरस्कारों का एक रनिंग योग भी बनाए रखा जाता है।
आपके रनटाइम के आधार पर, प्रशिक्षण एक मिनट से भी कम समय में समाप्त हो सकता है।
%%time
min_episodes_criterion = 100
max_episodes = 10000
max_steps_per_episode = 1000
# Cartpole-v0 is considered solved if average reward is >= 195 over 100
# consecutive trials
reward_threshold = 195
running_reward = 0
# Discount factor for future rewards
gamma = 0.99
# Keep last episodes reward
episodes_reward: collections.deque = collections.deque(maxlen=min_episodes_criterion)
with tqdm.trange(max_episodes) as t:
for i in t:
initial_state = tf.constant(env.reset(), dtype=tf.float32)
episode_reward = int(train_step(
initial_state, model, optimizer, gamma, max_steps_per_episode))
episodes_reward.append(episode_reward)
running_reward = statistics.mean(episodes_reward)
t.set_description(f'Episode {i}')
t.set_postfix(
episode_reward=episode_reward, running_reward=running_reward)
# Show average episode reward every 10 episodes
if i % 10 == 0:
pass # print(f'Episode {i}: average reward: {avg_reward}')
if running_reward > reward_threshold and i >= min_episodes_criterion:
break
print(f'\nSolved at episode {i}: average reward: {running_reward:.2f}!')
Episode 361: 4%|▎ | 361/10000 [01:13<32:33, 4.93it/s, episode_reward=182, running_reward=195] Solved at episode 361: average reward: 195.14! CPU times: user 2min 46s, sys: 35.4 s, total: 3min 21s Wall time: 1min 13s
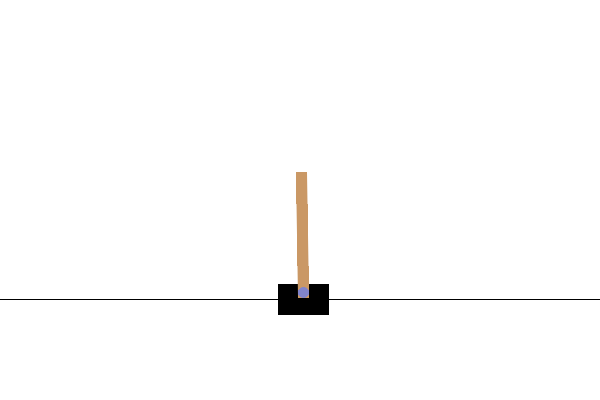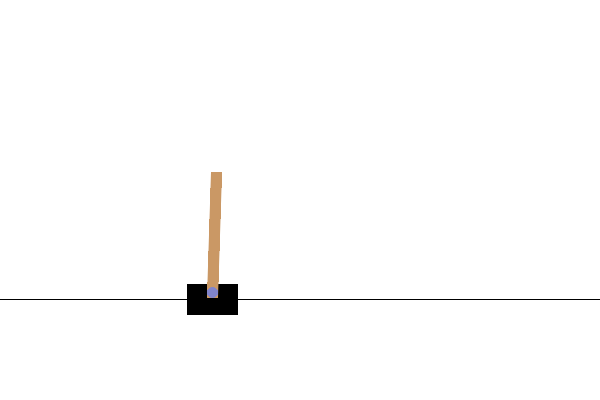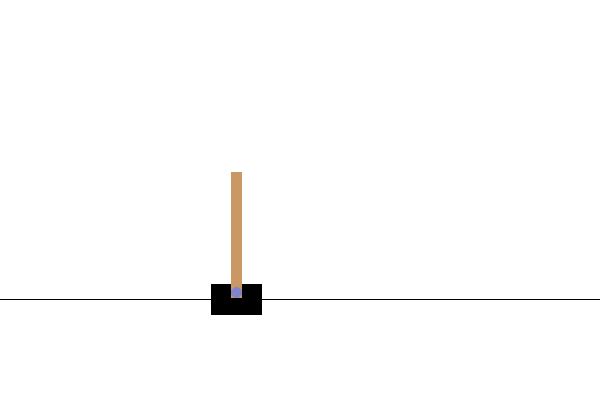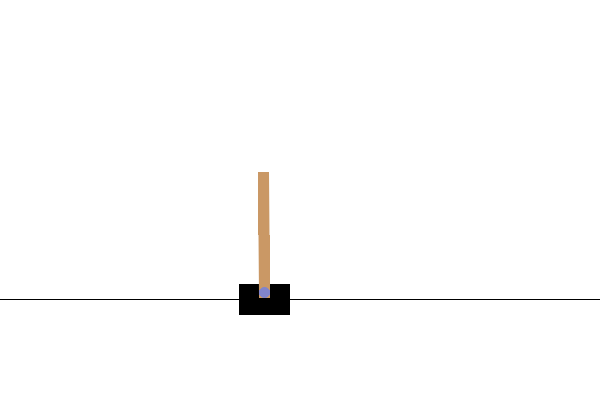
VISUALIZATION
प्रशिक्षण के बाद, यह कल्पना करना अच्छा होगा कि मॉडल पर्यावरण में कैसा प्रदर्शन करता है। मॉडल के एक एपिसोड रन का GIF एनिमेशन जेनरेट करने के लिए आप नीचे दिए गए सेल चला सकते हैं। ध्यान दें कि कोलाब में पर्यावरण की छवियों को सही ढंग से प्रस्तुत करने के लिए ओपनएआई जिम के लिए अतिरिक्त पैकेज स्थापित करने की आवश्यकता है।
# Render an episode and save as a GIF file
from IPython import display as ipythondisplay
from PIL import Image
from pyvirtualdisplay import Display
display = Display(visible=0, size=(400, 300))
display.start()
def render_episode(env: gym.Env, model: tf.keras.Model, max_steps: int):
screen = env.render(mode='rgb_array')
im = Image.fromarray(screen)
images = [im]
state = tf.constant(env.reset(), dtype=tf.float32)
for i in range(1, max_steps + 1):
state = tf.expand_dims(state, 0)
action_probs, _ = model(state)
action = np.argmax(np.squeeze(action_probs))
state, _, done, _ = env.step(action)
state = tf.constant(state, dtype=tf.float32)
# Render screen every 10 steps
if i % 10 == 0:
screen = env.render(mode='rgb_array')
images.append(Image.fromarray(screen))
if done:
break
return images
# Save GIF image
images = render_episode(env, model, max_steps_per_episode)
image_file = 'cartpole-v0.gif'
# loop=0: loop forever, duration=1: play each frame for 1ms
images[0].save(
image_file, save_all=True, append_images=images[1:], loop=0, duration=1)
import tensorflow_docs.vis.embed as embed
embed.embed_file(image_file)
अगले कदम
इस ट्यूटोरियल ने प्रदर्शित किया कि Tensorflow का उपयोग करके अभिनेता-आलोचक पद्धति को कैसे लागू किया जाए।
अगले चरण के रूप में, आप OpenAI जिम में एक अलग वातावरण पर एक मॉडल को प्रशिक्षित करने का प्रयास कर सकते हैं।
अभिनेता-आलोचक विधियों और कार्टपोल-v0 समस्या के बारे में अतिरिक्त जानकारी के लिए, आप निम्नलिखित संसाधनों का उल्लेख कर सकते हैं:
- अभिनेता समालोचक विधि
- अभिनेता समालोचक व्याख्यान (सीएएल)
- कार्टपोल लर्निंग कंट्रोल प्रॉब्लम [बार्टो, एट अल। 1983]
TensorFlow में अधिक सुदृढीकरण सीखने के उदाहरणों के लिए, आप निम्नलिखित संसाधनों की जाँच कर सकते हैं: