
| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
يوضح هذا البرنامج التعليمي كيفية تنفيذ طريقة Actor-Critic باستخدام TensorFlow لتدريب وكيل على بيئة Open AI Gym CartPole-V0. من المفترض أن يكون لدى القارئ بعض الإلمام بأساليب التدرج السياسي للتعلم المعزز.
طرق الممثل الناقد
طرق الناقد الفاعل هي طرق تعلم الفروق الزمنية (TD) التي تمثل وظيفة السياسة المستقلة عن وظيفة القيمة.
تقوم وظيفة (أو سياسة) السياسة بإرجاع توزيع احتمالي على الإجراءات التي يمكن أن يتخذها الوكيل بناءً على الحالة المحددة. تحدد دالة القيمة العائد المتوقع لوكيل يبدأ في حالة معينة ويتصرف وفقًا لسياسة معينة إلى الأبد بعد ذلك.
في طريقة الممثل الناقد ، يشار إلى السياسة على أنها الفاعل الذي يقترح مجموعة من الإجراءات المحتملة في حالة ما ، ويشار إلى وظيفة القيمة المقدرة باسم الناقد ، الذي يقيم الإجراءات التي يتخذها الممثل بناءً على السياسة المحددة .
في هذا البرنامج التعليمي ، سيتم تمثيل كل من الممثل والناقد باستخدام شبكة عصبية واحدة بمخرجين.
عربة التسوق CartPole-v0.0
في بيئة CartPole-v0 ، يتم إرفاق عمود بعربة تتحرك على طول مسار غير احتكاك. يبدأ العمود في وضع مستقيم ويهدف العامل إلى منعه من السقوط من خلال تطبيق قوة مقدارها -1 أو +1 على العربة. يتم منح مكافأة +1 لكل خطوة يظل فيها العمود في وضع مستقيم. تنتهي الحلقة عندما (1) يكون القطب أكثر من 15 درجة من الوضع الرأسي أو (2) تتحرك العربة بأكثر من 2.4 وحدة من المركز.
تعتبر المشكلة "محلولة" عندما يصل متوسط المكافأة الإجمالية للحلقة إلى 195 على 100 تجربة متتالية.
يثبت
استيراد الحزم الضرورية وتكوين الإعدادات العامة.
pip install gympip install pyglet
# Install additional packages for visualizationsudo apt-get install -y xvfb python-opengl > /dev/null 2>&1pip install pyvirtualdisplay > /dev/null 2>&1pip install git+https://github.com/tensorflow/docs > /dev/null 2>&1
import collections
import gym
import numpy as np
import statistics
import tensorflow as tf
import tqdm
from matplotlib import pyplot as plt
from tensorflow.keras import layers
from typing import Any, List, Sequence, Tuple
# Create the environment
env = gym.make("CartPole-v0")
# Set seed for experiment reproducibility
seed = 42
env.seed(seed)
tf.random.set_seed(seed)
np.random.seed(seed)
# Small epsilon value for stabilizing division operations
eps = np.finfo(np.float32).eps.item()
نموذج
سيتم تصميم الممثل والناقد باستخدام شبكة عصبية واحدة تولد احتمالات الإجراء وقيمة النقد على التوالي. يستخدم هذا البرنامج التعليمي تصنيفًا فرعيًا للنموذج لتحديد النموذج.
أثناء التمرير إلى الأمام ، سيأخذ النموذج في الحالة كمدخل وسيخرج كلاً من احتمالات الإجراء وقيمة النقد \(V\)، الذي يصوغ دالة القيمة المعتمدة على الحالة. الهدف هو تدريب نموذج يختار الإجراءات بناءً على سياسة \(\pi\) التي تزيد من العائد المتوقع.
بالنسبة إلى Cartpole-v0 ، توجد أربع قيم تمثل الحالة: موضع العربة وسرعة العربة وزاوية القطب وسرعة القطب على التوالي. يمكن للوكيل اتخاذ إجراءين لدفع العربة يسارًا (0) ويمينًا (1) على التوالي.
راجع صفحة CartPole-v0 wiki الخاصة بـ OpenAI Gym للحصول على مزيد من المعلومات.
class ActorCritic(tf.keras.Model):
"""Combined actor-critic network."""
def __init__(
self,
num_actions: int,
num_hidden_units: int):
"""Initialize."""
super().__init__()
self.common = layers.Dense(num_hidden_units, activation="relu")
self.actor = layers.Dense(num_actions)
self.critic = layers.Dense(1)
def call(self, inputs: tf.Tensor) -> Tuple[tf.Tensor, tf.Tensor]:
x = self.common(inputs)
return self.actor(x), self.critic(x)
num_actions = env.action_space.n # 2
num_hidden_units = 128
model = ActorCritic(num_actions, num_hidden_units)
تمرين
لتدريب الوكيل عليك اتباع الخطوات التالية:
- قم بتشغيل الوكيل على البيئة لجمع بيانات التدريب لكل حلقة.
- حساب العائد المتوقع في كل خطوة زمنية.
- احسب الخسارة لنموذج الممثل-الناقد المشترك.
- حساب التدرجات وتحديث معلمات الشبكة.
- كرر 1-4 حتى يتم الوصول إلى معيار النجاح أو الحد الأقصى للحلقات.
1. جمع بيانات التدريب
كما هو الحال في التعلم الخاضع للإشراف ، من أجل تدريب نموذج الممثل الناقد ، يجب أن يكون لديك بيانات تدريب. ومع ذلك ، من أجل جمع مثل هذه البيانات ، يجب "تشغيل" النموذج في البيئة.
يتم جمع بيانات التدريب لكل حلقة. ثم في كل خطوة زمنية ، سيتم تشغيل التمرير الأمامي للنموذج على حالة البيئة من أجل إنشاء احتمالات الإجراء وقيمة النقد بناءً على السياسة الحالية المحددة بواسطة أوزان النموذج.
سيتم أخذ عينات من الإجراء التالي من احتمالات الإجراء التي تم إنشاؤها بواسطة النموذج ، والتي سيتم بعد ذلك تطبيقها على البيئة ، مما يؤدي إلى إنشاء الحالة التالية والمكافأة.
يتم تنفيذ هذه العملية في وظيفة run_episode ، والتي تستخدم عمليات TensorFlow بحيث يمكن تجميعها لاحقًا في رسم بياني TensorFlow للحصول على تدريب أسرع. لاحظ أنه تم استخدام tf.TensorArray s لدعم تكرار Tensor على مصفوفات متغيرة الطول.
# Wrap OpenAI Gym's `env.step` call as an operation in a TensorFlow function.
# This would allow it to be included in a callable TensorFlow graph.
def env_step(action: np.ndarray) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:
"""Returns state, reward and done flag given an action."""
state, reward, done, _ = env.step(action)
return (state.astype(np.float32),
np.array(reward, np.int32),
np.array(done, np.int32))
def tf_env_step(action: tf.Tensor) -> List[tf.Tensor]:
return tf.numpy_function(env_step, [action],
[tf.float32, tf.int32, tf.int32])
def run_episode(
initial_state: tf.Tensor,
model: tf.keras.Model,
max_steps: int) -> Tuple[tf.Tensor, tf.Tensor, tf.Tensor]:
"""Runs a single episode to collect training data."""
action_probs = tf.TensorArray(dtype=tf.float32, size=0, dynamic_size=True)
values = tf.TensorArray(dtype=tf.float32, size=0, dynamic_size=True)
rewards = tf.TensorArray(dtype=tf.int32, size=0, dynamic_size=True)
initial_state_shape = initial_state.shape
state = initial_state
for t in tf.range(max_steps):
# Convert state into a batched tensor (batch size = 1)
state = tf.expand_dims(state, 0)
# Run the model and to get action probabilities and critic value
action_logits_t, value = model(state)
# Sample next action from the action probability distribution
action = tf.random.categorical(action_logits_t, 1)[0, 0]
action_probs_t = tf.nn.softmax(action_logits_t)
# Store critic values
values = values.write(t, tf.squeeze(value))
# Store log probability of the action chosen
action_probs = action_probs.write(t, action_probs_t[0, action])
# Apply action to the environment to get next state and reward
state, reward, done = tf_env_step(action)
state.set_shape(initial_state_shape)
# Store reward
rewards = rewards.write(t, reward)
if tf.cast(done, tf.bool):
break
action_probs = action_probs.stack()
values = values.stack()
rewards = rewards.stack()
return action_probs, values, rewards
2. حساب العوائد المتوقعة
يتم تحويل تسلسل المكافآت لكل خطوة زمنية \(t\)و \(\{r_{t}\}^{T}_{t=1}\) التي تم جمعها خلال حلقة واحدة إلى سلسلة من المرتجعات المتوقعة \(\{G_{t}\}^{T}_{t=1}\) حيث يتم أخذ مجموع المكافآت من الخطوة الزمنية الحالية \(t\) إلى \(T\) وكل تتضاعف المكافأة بعامل خصم \(\gamma\)المتحلل بشكل كبير:
\[G_{t} = \sum^{T}_{t'=t} \gamma^{t'-t}r_{t'}\]
منذ \(\gamma\in(0,1)\)، يتم إعطاء المكافآت البعيدة عن الخطوة الزمنية الحالية وزناً أقل.
بشكل حدسي ، يشير العائد المتوقع ببساطة إلى أن المكافآت الآن أفضل من المكافآت لاحقًا. بالمعنى الرياضي ، يجب التأكد من أن مجموع المكافآت يتقارب.
لتحقيق الاستقرار في التدريب ، يتم أيضًا توحيد تسلسل العوائد الناتج (أي أن يكون له متوسط صفري وانحراف معياري للوحدة).
def get_expected_return(
rewards: tf.Tensor,
gamma: float,
standardize: bool = True) -> tf.Tensor:
"""Compute expected returns per timestep."""
n = tf.shape(rewards)[0]
returns = tf.TensorArray(dtype=tf.float32, size=n)
# Start from the end of `rewards` and accumulate reward sums
# into the `returns` array
rewards = tf.cast(rewards[::-1], dtype=tf.float32)
discounted_sum = tf.constant(0.0)
discounted_sum_shape = discounted_sum.shape
for i in tf.range(n):
reward = rewards[i]
discounted_sum = reward + gamma * discounted_sum
discounted_sum.set_shape(discounted_sum_shape)
returns = returns.write(i, discounted_sum)
returns = returns.stack()[::-1]
if standardize:
returns = ((returns - tf.math.reduce_mean(returns)) /
(tf.math.reduce_std(returns) + eps))
return returns
3. الفاعل الناقد الخسارة
نظرًا لاستخدام نموذج الممثل-الناقد المختلط ، فإن وظيفة الخسارة المختارة هي مزيج من خسائر الممثل والناقد للتدريب ، كما هو موضح أدناه:
\[L = L_{actor} + L_{critic}\]
خسارة الفاعل
تستند خسارة الممثل على التدرجات السياسية مع الناقد كخط أساس يعتمد على الحالة ويتم حسابه باستخدام تقديرات عينة واحدة (لكل حلقة).
\[L_{actor} = -\sum^{T}_{t=1} \log\pi_{\theta}(a_{t} | s_{t})[G(s_{t}, a_{t}) - V^{\pi}_{\theta}(s_{t})]\]
أين:
- \(T\): عدد الخطوات الزمنية لكل حلقة ، والتي يمكن أن تختلف لكل حلقة
- \(s_{t}\): الحالة في الخطوة الزمنية \(t\)
- \(a_{t}\): الإجراء المختار في الخطوة الزمنية \(t\) إعطاء الحالة \(s\)
- \(\pi_{\theta}\): هي السياسة (الفاعل) التي تم تحديد معلماتها بواسطة \(\theta\)
- \(V^{\pi}_{\theta}\): هي دالة القيمة (الناقد) مُحددة أيضًا بواسطة \(\theta\)
- \(G = G_{t}\): العائد المتوقع لحالة معينة ، زوج عمل في الخطوة الزمنية \(t\)
يضاف مصطلح سلبي إلى المجموع لأن الفكرة هي تعظيم احتمالات الإجراءات التي تسفر عن مكافآت أعلى عن طريق تقليل الخسارة المجمعة.
ميزة
يُطلق على المصطلح \(G - V\) في \(L_{actor}\) الميزة ، والتي تشير إلى مدى أفضلية إعطاء حالة معينة لإجراء معين على إجراء عشوائي يتم اختياره وفقًا للسياسة \(\pi\) لتلك الحالة.
في حين أنه من الممكن استبعاد خط الأساس ، فقد يؤدي ذلك إلى تباين كبير أثناء التدريب. والشيء الجميل في اختيار الناقد \(V\) كخط أساس هو أنه تم تدريبه ليكون أقرب ما يمكن إلى \(G\)، مما يؤدي إلى تباين أقل.
بالإضافة إلى ذلك ، بدون الناقد ، ستحاول الخوارزمية زيادة احتمالات الإجراءات المتخذة في حالة معينة بناءً على العائد المتوقع ، والذي قد لا يحدث فرقًا كبيرًا إذا ظلت الاحتمالات النسبية بين الإجراءات كما هي.
على سبيل المثال ، افترض أن إجراءين لحالة معينة سيحققان نفس العائد المتوقع. بدون الناقد ، ستحاول الخوارزمية رفع احتمالية هذه الإجراءات بناءً على \(J\). مع الناقد ، قد يتضح أنه لا توجد ميزة (\(G - V = 0\)) وبالتالي لا توجد فائدة مكتسبة في زيادة احتمالات الإجراءات وستقوم الخوارزمية بتعيين التدرجات إلى الصفر.
خسارة نقدية
يمكن إعداد تدريب \(V\) ليكون أقرب ما يمكن إلى \(G\) كمشكلة انحدار مع وظيفة الخسارة التالية:
\[L_{critic} = L_{\delta}(G, V^{\pi}_{\theta})\]
حيث \(L_{\delta}\) هي خسارة Huber ، وهي أقل حساسية للقيم المتطرفة في البيانات من خسارة الخطأ التربيعي.
huber_loss = tf.keras.losses.Huber(reduction=tf.keras.losses.Reduction.SUM)
def compute_loss(
action_probs: tf.Tensor,
values: tf.Tensor,
returns: tf.Tensor) -> tf.Tensor:
"""Computes the combined actor-critic loss."""
advantage = returns - values
action_log_probs = tf.math.log(action_probs)
actor_loss = -tf.math.reduce_sum(action_log_probs * advantage)
critic_loss = huber_loss(values, returns)
return actor_loss + critic_loss
4. تحديد خطوة التدريب لتحديث المعلمات
يتم دمج جميع الخطوات المذكورة أعلاه في خطوة تدريب يتم تشغيلها في كل حلقة. يتم تنفيذ جميع الخطوات المؤدية إلى وظيفة الخسارة باستخدام سياق tf.GradientTape لتمكين التمايز التلقائي.
يستخدم هذا البرنامج التعليمي مُحسِّن Adam لتطبيق التدرجات اللونية على معلمات النموذج.
يتم أيضًا حساب مجموع المكافآت غير المخصومة ، episode_reward ، في هذه الخطوة. سيتم استخدام هذه القيمة لاحقًا لتقييم ما إذا تم استيفاء معيار النجاح.
يتم تطبيق سياق الدالة train_step tf.function يمكن تجميعها في رسم بياني TensorFlow قابل للاستدعاء ، والذي يمكن أن يؤدي إلى تسريع 10x في التدريب.
optimizer = tf.keras.optimizers.Adam(learning_rate=0.01)
@tf.function
def train_step(
initial_state: tf.Tensor,
model: tf.keras.Model,
optimizer: tf.keras.optimizers.Optimizer,
gamma: float,
max_steps_per_episode: int) -> tf.Tensor:
"""Runs a model training step."""
with tf.GradientTape() as tape:
# Run the model for one episode to collect training data
action_probs, values, rewards = run_episode(
initial_state, model, max_steps_per_episode)
# Calculate expected returns
returns = get_expected_return(rewards, gamma)
# Convert training data to appropriate TF tensor shapes
action_probs, values, returns = [
tf.expand_dims(x, 1) for x in [action_probs, values, returns]]
# Calculating loss values to update our network
loss = compute_loss(action_probs, values, returns)
# Compute the gradients from the loss
grads = tape.gradient(loss, model.trainable_variables)
# Apply the gradients to the model's parameters
optimizer.apply_gradients(zip(grads, model.trainable_variables))
episode_reward = tf.math.reduce_sum(rewards)
return episode_reward
5. قم بتشغيل حلقة التدريب
يتم تنفيذ التدريب عن طريق تشغيل خطوة التدريب حتى يتم الوصول إلى معيار النجاح أو الحد الأقصى لعدد الحلقات.
يتم الاحتفاظ بسجل مستمر لمكافآت الحلقة في قائمة انتظار. بمجرد الوصول إلى 100 تجربة ، تتم إزالة أقدم مكافأة في الطرف الأيسر (الذيل) من قائمة الانتظار ويتم إضافة المكافأة الأحدث في الرأس (على اليمين). يتم أيضًا الاحتفاظ بمجموع تشغيل للمكافآت من أجل الكفاءة الحسابية.
اعتمادًا على وقت التشغيل الخاص بك ، يمكن أن ينتهي التدريب في أقل من دقيقة.
%%time
min_episodes_criterion = 100
max_episodes = 10000
max_steps_per_episode = 1000
# Cartpole-v0 is considered solved if average reward is >= 195 over 100
# consecutive trials
reward_threshold = 195
running_reward = 0
# Discount factor for future rewards
gamma = 0.99
# Keep last episodes reward
episodes_reward: collections.deque = collections.deque(maxlen=min_episodes_criterion)
with tqdm.trange(max_episodes) as t:
for i in t:
initial_state = tf.constant(env.reset(), dtype=tf.float32)
episode_reward = int(train_step(
initial_state, model, optimizer, gamma, max_steps_per_episode))
episodes_reward.append(episode_reward)
running_reward = statistics.mean(episodes_reward)
t.set_description(f'Episode {i}')
t.set_postfix(
episode_reward=episode_reward, running_reward=running_reward)
# Show average episode reward every 10 episodes
if i % 10 == 0:
pass # print(f'Episode {i}: average reward: {avg_reward}')
if running_reward > reward_threshold and i >= min_episodes_criterion:
break
print(f'\nSolved at episode {i}: average reward: {running_reward:.2f}!')
Episode 361: 4%|▎ | 361/10000 [01:13<32:33, 4.93it/s, episode_reward=182, running_reward=195] Solved at episode 361: average reward: 195.14! CPU times: user 2min 46s, sys: 35.4 s, total: 3min 21s Wall time: 1min 13s
التصور
بعد التدريب ، سيكون من الجيد تصور كيفية أداء النموذج في البيئة. يمكنك تشغيل الخلايا أدناه لإنشاء رسم متحرك بتنسيق GIF لتشغيل حلقة واحدة من النموذج. لاحظ أنه يلزم تثبيت حزم إضافية لـ OpenAI Gym لعرض صور البيئة بشكل صحيح في Colab.
# Render an episode and save as a GIF file
from IPython import display as ipythondisplay
from PIL import Image
from pyvirtualdisplay import Display
display = Display(visible=0, size=(400, 300))
display.start()
def render_episode(env: gym.Env, model: tf.keras.Model, max_steps: int):
screen = env.render(mode='rgb_array')
im = Image.fromarray(screen)
images = [im]
state = tf.constant(env.reset(), dtype=tf.float32)
for i in range(1, max_steps + 1):
state = tf.expand_dims(state, 0)
action_probs, _ = model(state)
action = np.argmax(np.squeeze(action_probs))
state, _, done, _ = env.step(action)
state = tf.constant(state, dtype=tf.float32)
# Render screen every 10 steps
if i % 10 == 0:
screen = env.render(mode='rgb_array')
images.append(Image.fromarray(screen))
if done:
break
return images
# Save GIF image
images = render_episode(env, model, max_steps_per_episode)
image_file = 'cartpole-v0.gif'
# loop=0: loop forever, duration=1: play each frame for 1ms
images[0].save(
image_file, save_all=True, append_images=images[1:], loop=0, duration=1)
import tensorflow_docs.vis.embed as embed
embed.embed_file(image_file)
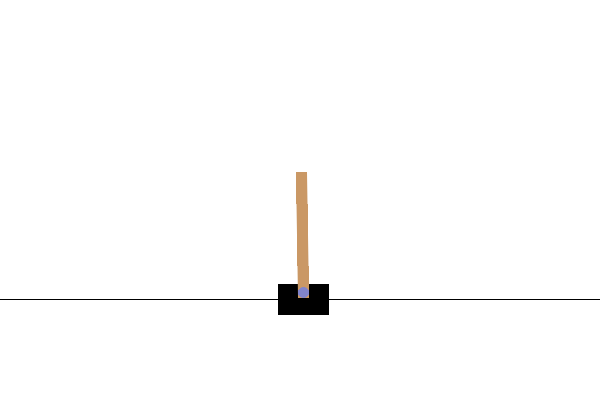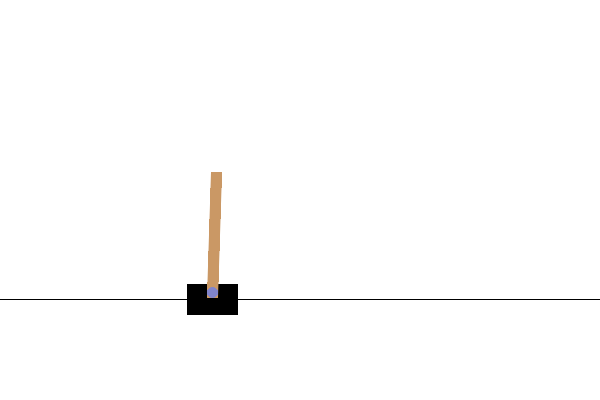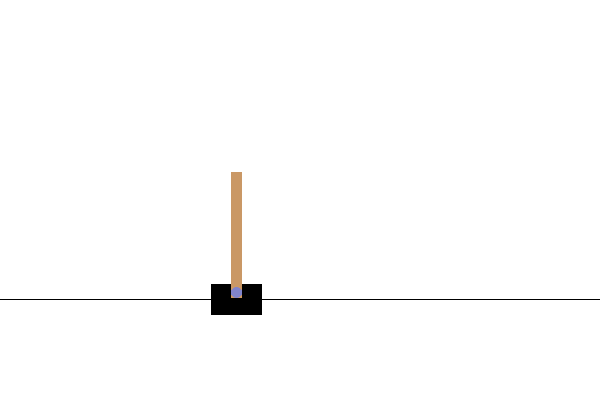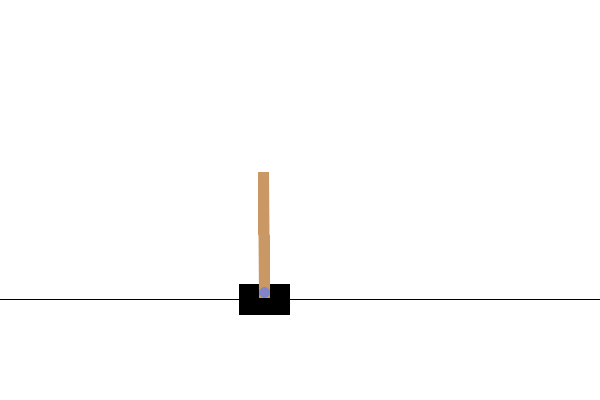
الخطوات التالية
يوضح هذا البرنامج التعليمي كيفية تنفيذ طريقة الممثل-الناقد باستخدام Tensorflow.
كخطوة تالية ، يمكنك تجربة تدريب نموذج على بيئة مختلفة في OpenAI Gym.
للحصول على معلومات إضافية بخصوص طرق الممثل-النقد ومشكلة Cartpole-v0 ، يمكنك الرجوع إلى الموارد التالية:
لمزيد من أمثلة التعلم المعزز في TensorFlow ، يمكنك التحقق من الموارد التالية: