
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
מדריך זה מספק דוגמאות כיצד לטעון פנדה DataFrames לתוך TensorFlow.
אתה תשתמש במערך נתונים קטן של מחלות לב המסופק על ידי UCI Machine Learning Repository. יש כמה מאות שורות ב-CSV. כל שורה מתארת מטופל, וכל עמודה מתארת תכונה. אתה תשתמש במידע זה כדי לחזות אם למטופל יש מחלת לב, שהיא משימת סיווג בינארי.
קרא נתונים באמצעות פנדות
import pandas as pd
import tensorflow as tf
SHUFFLE_BUFFER = 500
BATCH_SIZE = 2
הורד את קובץ ה-CSV המכיל את מערך הנתונים של מחלות לב:
csv_file = tf.keras.utils.get_file('heart.csv', 'https://storage.googleapis.com/download.tensorflow.org/data/heart.csv')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/heart.csv 16384/13273 [=====================================] - 0s 0us/step 24576/13273 [=======================================================] - 0s 0us/step
קרא את קובץ ה-CSV באמצעות פנדות:
df = pd.read_csv(csv_file)
כך נראים הנתונים:
df.head()
df.dtypes
age int64 sex int64 cp int64 trestbps int64 chol int64 fbs int64 restecg int64 thalach int64 exang int64 oldpeak float64 slope int64 ca int64 thal object target int64 dtype: object
אתה תבנה מודלים כדי לחזות את התווית הכלולה בעמודת target .
target = df.pop('target')
DataFrame כמערך
אם לנתונים שלך יש סוג נתונים אחיד, או dtype , אפשר להשתמש ב-Pandas DataFrame בכל מקום שבו תוכל להשתמש במערך NumPy. זה עובד מכיוון pandas.DataFrame תומכת בפרוטוקול __array__ , והפונקציה tf.convert_to_tensor מקבלת אובייקטים התומכים בפרוטוקול.
קח את התכונות המספריות ממערך הנתונים (דלג על התכונות הקטגוריות לעת עתה):
numeric_feature_names = ['age', 'thalach', 'trestbps', 'chol', 'oldpeak']
numeric_features = df[numeric_feature_names]
numeric_features.head()
ניתן להמיר את ה-DataFrame למערך DataFrame.values באמצעות המאפיין DataFrame.values או numpy.array(df) . כדי להמיר אותו לטנסור, השתמש ב- tf.convert_to_tensor :
tf.convert_to_tensor(numeric_features)
<tf.Tensor: shape=(303, 5), dtype=float64, numpy=
array([[ 63. , 150. , 145. , 233. , 2.3],
[ 67. , 108. , 160. , 286. , 1.5],
[ 67. , 129. , 120. , 229. , 2.6],
...,
[ 65. , 127. , 135. , 254. , 2.8],
[ 48. , 150. , 130. , 256. , 0. ],
[ 63. , 154. , 150. , 407. , 4. ]])>
באופן כללי, אם ניתן להמיר אובייקט לטנסור עם tf.convert_to_tensor ניתן להעביר אותו בכל מקום בו ניתן להעביר tf.Tensor .
עם Model.fit
DataFrame, המתפרש כטנזור בודד, יכול לשמש ישירות כארגומנט לשיטת Model.fit .
להלן דוגמה לאימון מודל על התכונות המספריות של מערך הנתונים.
הצעד הראשון הוא לנרמל את טווחי הקלט. השתמש בשכבת tf.keras.layers.Normalization בשביל זה.
כדי להגדיר את הממוצע ואת סטיית התקן של השכבה לפני הפעלתה, הקפד לקרוא לשיטת Normalization.adapt :
normalizer = tf.keras.layers.Normalization(axis=-1)
normalizer.adapt(numeric_features)
קרא לשכבה בשלוש השורות הראשונות של ה-DataFrame כדי לדמיין דוגמה של הפלט משכבה זו:
normalizer(numeric_features.iloc[:3])
<tf.Tensor: shape=(3, 5), dtype=float32, numpy=
array([[ 0.93383914, 0.03480718, 0.74578077, -0.26008663, 1.0680453 ],
[ 1.3782105 , -1.7806165 , 1.5923285 , 0.7573877 , 0.38022864],
[ 1.3782105 , -0.87290466, -0.6651321 , -0.33687714, 1.3259765 ]],
dtype=float32)>
השתמש בשכבת הנורמליזציה כשכבה הראשונה של מודל פשוט:
def get_basic_model():
model = tf.keras.Sequential([
normalizer,
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(1)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
return model
כאשר אתה מעביר את ה-DataFrame כארגומנט x ל- Model.fit , Keras מתייחס ל-DataFrame כפי שהוא מתייחס למערך NumPy:
model = get_basic_model()
model.fit(numeric_features, target, epochs=15, batch_size=BATCH_SIZE)
Epoch 1/15 152/152 [==============================] - 1s 2ms/step - loss: 0.6839 - accuracy: 0.7690 Epoch 2/15 152/152 [==============================] - 0s 2ms/step - loss: 0.5789 - accuracy: 0.7789 Epoch 3/15 152/152 [==============================] - 0s 2ms/step - loss: 0.5195 - accuracy: 0.7723 Epoch 4/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4814 - accuracy: 0.7855 Epoch 5/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4566 - accuracy: 0.7789 Epoch 6/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4427 - accuracy: 0.7888 Epoch 7/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4342 - accuracy: 0.7921 Epoch 8/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4290 - accuracy: 0.7855 Epoch 9/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4240 - accuracy: 0.7987 Epoch 10/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4232 - accuracy: 0.7987 Epoch 11/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4208 - accuracy: 0.7987 Epoch 12/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4186 - accuracy: 0.7954 Epoch 13/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4172 - accuracy: 0.8020 Epoch 14/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4156 - accuracy: 0.8020 Epoch 15/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4138 - accuracy: 0.8020 <keras.callbacks.History at 0x7f1ddc27b110>
עם tf.data
אם ברצונך להחיל טרנספורמציות tf.data על DataFrame מסוג dtype אחיד, שיטת Dataset.from_tensor_slices תיצור מערך נתונים שחוזר על פני השורות של ה-DataFrame. כל שורה היא בתחילה וקטור של ערכים. כדי להכשיר מודל, אתה צריך (inputs, labels) זוגות, אז העבר (features, labels) ו- Dataset.from_tensor_slices יחזיר את זוגות הפרוסות הדרושים:
numeric_dataset = tf.data.Dataset.from_tensor_slices((numeric_features, target))
for row in numeric_dataset.take(3):
print(row)
(<tf.Tensor: shape=(5,), dtype=float64, numpy=array([ 63. , 150. , 145. , 233. , 2.3])>, <tf.Tensor: shape=(), dtype=int64, numpy=0>) (<tf.Tensor: shape=(5,), dtype=float64, numpy=array([ 67. , 108. , 160. , 286. , 1.5])>, <tf.Tensor: shape=(), dtype=int64, numpy=1>) (<tf.Tensor: shape=(5,), dtype=float64, numpy=array([ 67. , 129. , 120. , 229. , 2.6])>, <tf.Tensor: shape=(), dtype=int64, numpy=0>)
numeric_batches = numeric_dataset.shuffle(1000).batch(BATCH_SIZE)
model = get_basic_model()
model.fit(numeric_batches, epochs=15)
Epoch 1/15 152/152 [==============================] - 1s 2ms/step - loss: 0.7677 - accuracy: 0.6865 Epoch 2/15 152/152 [==============================] - 0s 2ms/step - loss: 0.6319 - accuracy: 0.7591 Epoch 3/15 152/152 [==============================] - 0s 2ms/step - loss: 0.5717 - accuracy: 0.7459 Epoch 4/15 152/152 [==============================] - 0s 2ms/step - loss: 0.5228 - accuracy: 0.7558 Epoch 5/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4820 - accuracy: 0.7624 Epoch 6/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4584 - accuracy: 0.7657 Epoch 7/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4454 - accuracy: 0.7657 Epoch 8/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4379 - accuracy: 0.7789 Epoch 9/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4324 - accuracy: 0.7789 Epoch 10/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4282 - accuracy: 0.7756 Epoch 11/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4273 - accuracy: 0.7789 Epoch 12/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4268 - accuracy: 0.7756 Epoch 13/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4248 - accuracy: 0.7789 Epoch 14/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4235 - accuracy: 0.7855 Epoch 15/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4223 - accuracy: 0.7888 <keras.callbacks.History at 0x7f1ddc406510>
DataFrame כמילון
כאשר מתחילים להתעסק בנתונים הטרוגניים, כבר לא ניתן להתייחס ל-DataFrame כאילו היה מערך בודד. טנסור TensorFlow דורשים שלכל האלמנטים יהיה אותו dtype .
אז, במקרה זה, אתה צריך להתחיל להתייחס לזה כאל מילון של עמודות, שבו לכל עמודה יש dtype אחיד. DataFrame דומה מאוד למילון של מערכים, כך שבדרך כלל כל מה שאתה צריך לעשות הוא להטיל את ה-DataFrame ל-Python dict. ממשקי API חשובים רבים של TensorFlow תומכים במילונים (מקוננים) של מערכים כקלט.
צינורות קלט tf.data מטפלים בזה די טוב. כל פעולות tf.data מטפלות במילונים ובטפלים באופן אוטומטי. לכן, כדי ליצור מערך נתונים של דוגמאות מילון מ-DataFrame, פשוט העבירו אותו ל-dict לפני שתחתכו אותו עם Dataset.from_tensor_slices :
numeric_dict_ds = tf.data.Dataset.from_tensor_slices((dict(numeric_features), target))
להלן שלוש הדוגמאות הראשונות מאותו מערך נתונים:
for row in numeric_dict_ds.take(3):
print(row)
({'age': <tf.Tensor: shape=(), dtype=int64, numpy=63>, 'thalach': <tf.Tensor: shape=(), dtype=int64, numpy=150>, 'trestbps': <tf.Tensor: shape=(), dtype=int64, numpy=145>, 'chol': <tf.Tensor: shape=(), dtype=int64, numpy=233>, 'oldpeak': <tf.Tensor: shape=(), dtype=float64, numpy=2.3>}, <tf.Tensor: shape=(), dtype=int64, numpy=0>)
({'age': <tf.Tensor: shape=(), dtype=int64, numpy=67>, 'thalach': <tf.Tensor: shape=(), dtype=int64, numpy=108>, 'trestbps': <tf.Tensor: shape=(), dtype=int64, numpy=160>, 'chol': <tf.Tensor: shape=(), dtype=int64, numpy=286>, 'oldpeak': <tf.Tensor: shape=(), dtype=float64, numpy=1.5>}, <tf.Tensor: shape=(), dtype=int64, numpy=1>)
({'age': <tf.Tensor: shape=(), dtype=int64, numpy=67>, 'thalach': <tf.Tensor: shape=(), dtype=int64, numpy=129>, 'trestbps': <tf.Tensor: shape=(), dtype=int64, numpy=120>, 'chol': <tf.Tensor: shape=(), dtype=int64, numpy=229>, 'oldpeak': <tf.Tensor: shape=(), dtype=float64, numpy=2.6>}, <tf.Tensor: shape=(), dtype=int64, numpy=0>)
מילונים עם קרס
בדרך כלל, מודלים ושכבות של Keras מצפים לטנזור קלט יחיד, אך מחלקות אלו יכולות לקבל ולהחזיר מבנים מקוננים של מילונים, tuples וטנזורים. מבנים אלו ידועים כ"קנים" (עיין במודול tf.nest לפרטים).
ישנן שתי דרכים מקבילות שבהן אתה יכול לכתוב מודל Keras שמקבל מילון כקלט.
1. סגנון ה-Model-subclass
אתה כותב תת-מחלקה של tf.keras.Model (או tf.keras.Layer ). אתה מטפל ישירות בקלטים ויוצר את הפלטים:
def stack_dict(inputs, fun=tf.stack):
values = []
for key in sorted(inputs.keys()):
values.append(tf.cast(inputs[key], tf.float32))
return fun(values, axis=-1)
class MyModel(tf.keras.Model):
def __init__(self):
# Create all the internal layers in init.
super().__init__(self)
self.normalizer = tf.keras.layers.Normalization(axis=-1)
self.seq = tf.keras.Sequential([
self.normalizer,
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(1)
])
def adapt(self, inputs):
# Stach the inputs and `adapt` the normalization layer.
inputs = stack_dict(inputs)
self.normalizer.adapt(inputs)
def call(self, inputs):
# Stack the inputs
inputs = stack_dict(inputs)
# Run them through all the layers.
result = self.seq(inputs)
return result
model = MyModel()
model.adapt(dict(numeric_features))
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'],
run_eagerly=True)
מודל זה יכול לקבל מילון של עמודות או מערך נתונים של רכיבי מילון להדרכה:
model.fit(dict(numeric_features), target, epochs=5, batch_size=BATCH_SIZE)
Epoch 1/5 152/152 [==============================] - 3s 17ms/step - loss: 0.6736 - accuracy: 0.7063 Epoch 2/5 152/152 [==============================] - 3s 17ms/step - loss: 0.5577 - accuracy: 0.7294 Epoch 3/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4869 - accuracy: 0.7591 Epoch 4/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4525 - accuracy: 0.7690 Epoch 5/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4403 - accuracy: 0.7624 <keras.callbacks.History at 0x7f1de4fa9390>
numeric_dict_batches = numeric_dict_ds.shuffle(SHUFFLE_BUFFER).batch(BATCH_SIZE)
model.fit(numeric_dict_batches, epochs=5)
Epoch 1/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4328 - accuracy: 0.7756 Epoch 2/5 152/152 [==============================] - 2s 14ms/step - loss: 0.4297 - accuracy: 0.7888 Epoch 3/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4270 - accuracy: 0.7888 Epoch 4/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4245 - accuracy: 0.8020 Epoch 5/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4240 - accuracy: 0.7921 <keras.callbacks.History at 0x7f1ddc0dba90>
להלן התחזיות לשלוש הדוגמאות הראשונות:
model.predict(dict(numeric_features.iloc[:3]))
array([[[0.00565109]],
[[0.60601974]],
[[0.03647463]]], dtype=float32)
2. הסגנון הפונקציונלי של Keras
inputs = {}
for name, column in numeric_features.items():
inputs[name] = tf.keras.Input(
shape=(1,), name=name, dtype=tf.float32)
inputs
{'age': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'age')>,
'thalach': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'thalach')>,
'trestbps': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'trestbps')>,
'chol': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'chol')>,
'oldpeak': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'oldpeak')>}
x = stack_dict(inputs, fun=tf.concat)
normalizer = tf.keras.layers.Normalization(axis=-1)
normalizer.adapt(stack_dict(dict(numeric_features)))
x = normalizer(x)
x = tf.keras.layers.Dense(10, activation='relu')(x)
x = tf.keras.layers.Dense(10, activation='relu')(x)
x = tf.keras.layers.Dense(1)(x)
model = tf.keras.Model(inputs, x)
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'],
run_eagerly=True)
tf.keras.utils.plot_model(model, rankdir="LR", show_shapes=True)

אתה יכול לאמן את המודל הפונקציונלי באותו אופן כמו תת-מחלקת המודל:
model.fit(dict(numeric_features), target, epochs=5, batch_size=BATCH_SIZE)
Epoch 1/5 152/152 [==============================] - 2s 15ms/step - loss: 0.6529 - accuracy: 0.7492 Epoch 2/5 152/152 [==============================] - 2s 15ms/step - loss: 0.5448 - accuracy: 0.7624 Epoch 3/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4935 - accuracy: 0.7756 Epoch 4/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4650 - accuracy: 0.7789 Epoch 5/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4486 - accuracy: 0.7855 <keras.callbacks.History at 0x7f1ddc0d0f90>
numeric_dict_batches = numeric_dict_ds.shuffle(SHUFFLE_BUFFER).batch(BATCH_SIZE)
model.fit(numeric_dict_batches, epochs=5)
Epoch 1/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4398 - accuracy: 0.7855 Epoch 2/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4330 - accuracy: 0.7855 Epoch 3/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4294 - accuracy: 0.7921 Epoch 4/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4271 - accuracy: 0.7888 Epoch 5/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4231 - accuracy: 0.7855 <keras.callbacks.History at 0x7f1d7c5d5d10>
דוגמה מלאה
אם אתה מעביר DataFrame הטרוגנית ל-Keras, כל עמודה עשויה להזדקק לעיבוד מוקדם ייחודי. אתה יכול לעשות את העיבוד המקדים הזה ישירות ב-DataFrame, אבל כדי שמודל יעבוד כמו שצריך, תמיד יש לעבד קלט מראש באותו אופן. לכן, הגישה הטובה ביותר היא לבנות את העיבוד המקדים לתוך המודל. שכבות עיבוד מקדים של Keras מכסות משימות נפוצות רבות.
בנה את ראש העיבוד המקדים
במערך הנתונים הזה חלק מתכונות ה"מספר השלם" בנתונים הגולמיים הם למעשה מדדים קטגוריים. מדדים אלה אינם באמת ערכים מספריים מסודרים (עיין בתיאור מערך הנתונים לפרטים). מכיוון שאלו אינם מסודרים, הם אינם מתאימים להזנה ישירות לדגם; הדגם יפרש אותם כמוזמינים. כדי להשתמש בכניסות אלה תצטרך לקודד אותן, או כווקטורים חדים או כווקטורים הטמעים. אותו הדבר חל על תכונות קטגוריות מחרוזות.
תכונות בינאריות לעומת זאת אינן צריכות בדרך כלל להיות מקודדות או מנורמלות.
התחל ביצירת רשימה של התכונות הנכללות בכל קבוצה:
binary_feature_names = ['sex', 'fbs', 'exang']
categorical_feature_names = ['cp', 'restecg', 'slope', 'thal', 'ca']
השלב הבא הוא בניית מודל עיבוד מקדים שיחיל עיבוד מקדים הולם על כל קלט ושרשר את התוצאות.
סעיף זה משתמש ב- Keras Functional API כדי ליישם את העיבוד המקדים. אתה מתחיל ביצירת tf.keras.Input אחד עבור כל עמודה של מסגרת הנתונים:
inputs = {}
for name, column in df.items():
if type(column[0]) == str:
dtype = tf.string
elif (name in categorical_feature_names or
name in binary_feature_names):
dtype = tf.int64
else:
dtype = tf.float32
inputs[name] = tf.keras.Input(shape=(), name=name, dtype=dtype)
inputs
{'age': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'age')>,
'sex': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'sex')>,
'cp': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'cp')>,
'trestbps': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'trestbps')>,
'chol': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'chol')>,
'fbs': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'fbs')>,
'restecg': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'restecg')>,
'thalach': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'thalach')>,
'exang': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'exang')>,
'oldpeak': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'oldpeak')>,
'slope': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'slope')>,
'ca': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'ca')>,
'thal': <KerasTensor: shape=(None,) dtype=string (created by layer 'thal')>}
עבור כל קלט תחיל כמה טרנספורמציות באמצעות שכבות Keras ו-TensorFlow ops. כל תכונה מתחילה בתור אצווה של סקלרים ( shape=(batch,) ). הפלט עבור כל אחד מהם צריך להיות אצווה של וקטורים tf.float32 ( shape=(batch, n) ). השלב האחרון ישרשר את כל הוקטורים הללו יחד.
כניסות בינאריות
מכיוון שהכניסות הבינאריות אינן זקוקות לעיבוד מקדים, פשוט הוסף את ציר הווקטור, הטיל אותן ל- float32 והוסף אותן לרשימת התשומות המעובדות מראש:
preprocessed = []
for name in binary_feature_names:
inp = inputs[name]
inp = inp[:, tf.newaxis]
float_value = tf.cast(inp, tf.float32)
preprocessed.append(float_value)
preprocessed
[<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_5')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_6')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_7')>]
כניסות מספריות
כמו בסעיף הקודם, תרצה להריץ את הקלט המספרי הזה דרך שכבת tf.keras.layers.Normalization לפני השימוש בהם. ההבדל הוא שהפעם הם מוקלטים ככתיב. הקוד שלהלן אוסף את התכונות המספריות מה-DataFrame, מערם אותן יחד ומעביר אותן לשיטת Normalization.adapt .
normalizer = tf.keras.layers.Normalization(axis=-1)
normalizer.adapt(stack_dict(dict(numeric_features)))
הקוד שלהלן מערם את התכונות המספריות ומריץ אותן בשכבת הנורמליזציה.
numeric_inputs = {}
for name in numeric_feature_names:
numeric_inputs[name]=inputs[name]
numeric_inputs = stack_dict(numeric_inputs)
numeric_normalized = normalizer(numeric_inputs)
preprocessed.append(numeric_normalized)
preprocessed
[<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_5')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_6')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_7')>, <KerasTensor: shape=(None, 5) dtype=float32 (created by layer 'normalization_3')>]
תכונות קטגוריות
כדי להשתמש בתכונות קטגוריות תחילה תצטרך לקודד אותן לוקטורים בינאריים או להטמעות. מכיוון שתכונות אלו מכילות רק מספר קטן של קטגוריות, המר את הקלט ישירות לוקטורים חדים באמצעות האפשרות output_mode='one_hot' , הנתמכת הן על ידי שכבות tf.keras.layers.StringLookup והן tf.keras.layers.IntegerLookup .
הנה דוגמה לאופן שבו שכבות אלו פועלות:
vocab = ['a','b','c']
lookup = tf.keras.layers.StringLookup(vocabulary=vocab, output_mode='one_hot')
lookup(['c','a','a','b','zzz'])
<tf.Tensor: shape=(5, 4), dtype=float32, numpy=
array([[0., 0., 0., 1.],
[0., 1., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[1., 0., 0., 0.]], dtype=float32)>
vocab = [1,4,7,99]
lookup = tf.keras.layers.IntegerLookup(vocabulary=vocab, output_mode='one_hot')
lookup([-1,4,1])
<tf.Tensor: shape=(3, 5), dtype=float32, numpy=
array([[1., 0., 0., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 1., 0., 0., 0.]], dtype=float32)>
כדי לקבוע את אוצר המילים עבור כל קלט, צור שכבה כדי להמיר את אוצר המילים לוקטור חם אחד:
for name in categorical_feature_names:
vocab = sorted(set(df[name]))
print(f'name: {name}')
print(f'vocab: {vocab}\n')
if type(vocab[0]) is str:
lookup = tf.keras.layers.StringLookup(vocabulary=vocab, output_mode='one_hot')
else:
lookup = tf.keras.layers.IntegerLookup(vocabulary=vocab, output_mode='one_hot')
x = inputs[name][:, tf.newaxis]
x = lookup(x)
preprocessed.append(x)
name: cp vocab: [0, 1, 2, 3, 4] name: restecg vocab: [0, 1, 2] name: slope vocab: [1, 2, 3] name: thal vocab: ['1', '2', 'fixed', 'normal', 'reversible'] name: ca vocab: [0, 1, 2, 3]
הרכיבו את ראש העיבוד המקדים
בשלב זה preprocessed הוא רק רשימת Python של כל תוצאות העיבוד המקדים, לכל תוצאה יש צורה של (batch_size, depth) :
preprocessed
[<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_5')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_6')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_7')>, <KerasTensor: shape=(None, 5) dtype=float32 (created by layer 'normalization_3')>, <KerasTensor: shape=(None, 6) dtype=float32 (created by layer 'integer_lookup_1')>, <KerasTensor: shape=(None, 4) dtype=float32 (created by layer 'integer_lookup_2')>, <KerasTensor: shape=(None, 4) dtype=float32 (created by layer 'integer_lookup_3')>, <KerasTensor: shape=(None, 6) dtype=float32 (created by layer 'string_lookup_1')>, <KerasTensor: shape=(None, 5) dtype=float32 (created by layer 'integer_lookup_4')>]
שרשור את כל התכונות המעובדות מראש לאורך ציר depth , כך שכל דוגמה של מילון מומרת לוקטור בודד. הווקטור מכיל תכונות קטגוריות, תכונות מספריות ותכונות קטגוריות חדות:
preprocesssed_result = tf.concat(preprocessed, axis=-1)
preprocesssed_result
<KerasTensor: shape=(None, 33) dtype=float32 (created by layer 'tf.concat_1')>
כעת צור מודל מתוך החישוב הזה כדי שניתן יהיה לעשות בו שימוש חוזר:
preprocessor = tf.keras.Model(inputs, preprocesssed_result)
tf.keras.utils.plot_model(preprocessor, rankdir="LR", show_shapes=True)
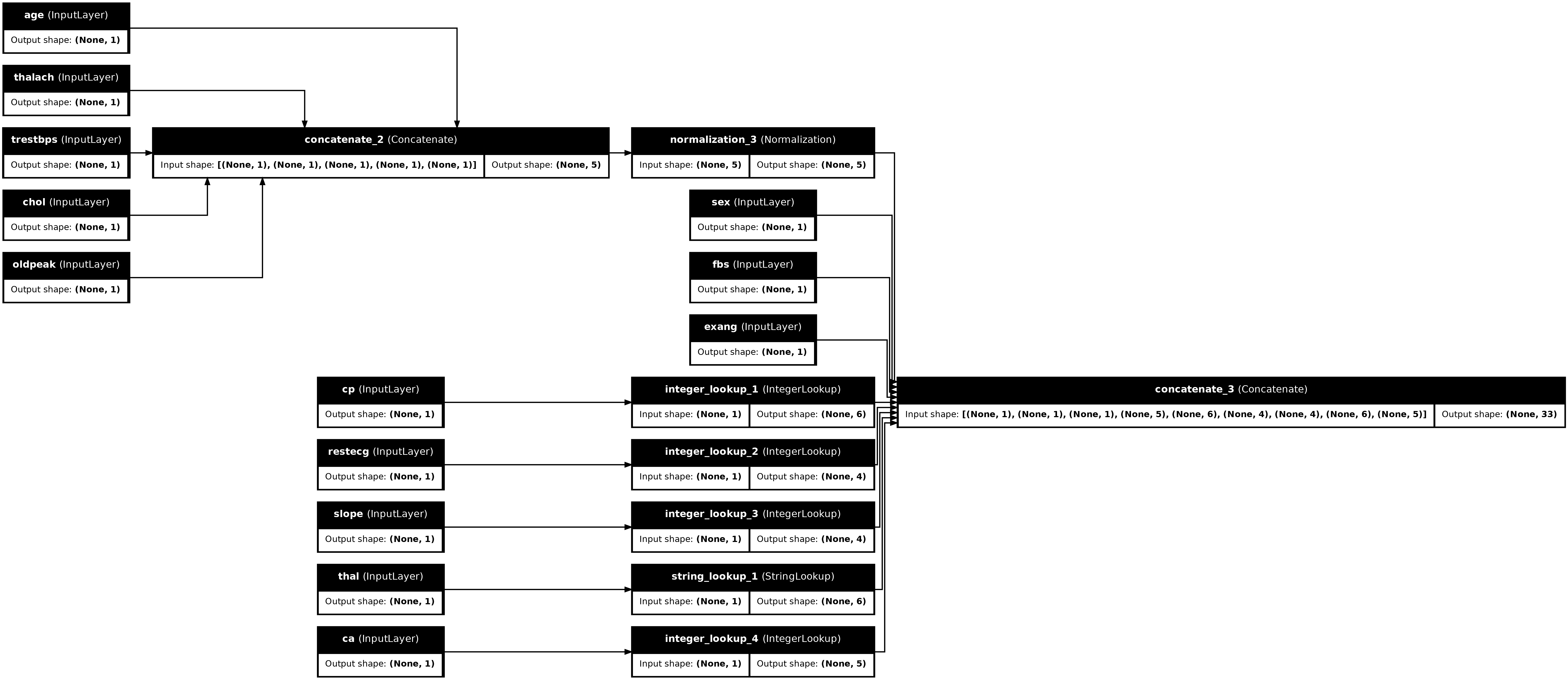
כדי לבדוק את המעבד המקדים, השתמש במסגר DataFrame.iloc כדי לחתוך את הדוגמה הראשונה מה-DataFrame. לאחר מכן המירו אותו למילון והעבירו את המילון למעבד המקדים. התוצאה היא וקטור יחיד המכיל את התכונות הבינאריות, התכונות המספריות המנורמלות והתכונות הקטגוריות החמות, בסדר זה:
preprocessor(dict(df.iloc[:1]))
<tf.Tensor: shape=(1, 33), dtype=float32, numpy=
array([[ 1. , 1. , 0. , 0.93383914, -0.26008663,
1.0680453 , 0.03480718, 0.74578077, 0. , 0. ,
1. , 0. , 0. , 0. , 0. ,
0. , 0. , 1. , 0. , 0. ,
0. , 1. , 0. , 0. , 0. ,
1. , 0. , 0. , 0. , 1. ,
0. , 0. , 0. ]], dtype=float32)>
צור והכשיר מודל
כעת בנה את הגוף הראשי של הדגם. השתמש באותה תצורה כמו בדוגמה הקודמת: כמה שכבות Dense מתוקשרות-לינאריות ושכבת פלט Dense(1) עבור הסיווג.
body = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(1)
])
כעת חבר את שני החלקים יחד באמצעות ה-API הפונקציונלי של Keras.
inputs
{'age': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'age')>,
'sex': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'sex')>,
'cp': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'cp')>,
'trestbps': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'trestbps')>,
'chol': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'chol')>,
'fbs': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'fbs')>,
'restecg': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'restecg')>,
'thalach': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'thalach')>,
'exang': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'exang')>,
'oldpeak': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'oldpeak')>,
'slope': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'slope')>,
'ca': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'ca')>,
'thal': <KerasTensor: shape=(None,) dtype=string (created by layer 'thal')>}
x = preprocessor(inputs)
x
<KerasTensor: shape=(None, 33) dtype=float32 (created by layer 'model_1')>
result = body(x)
result
<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'sequential_3')>
model = tf.keras.Model(inputs, result)
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
מודל זה מצפה למילון תשומות. הדרך הפשוטה ביותר להעביר לו את הנתונים היא להמיר את ה-DataFrame ל-dict ולהעביר את ה-dict כארגומנט x ל- Model.fit :
history = model.fit(dict(df), target, epochs=5, batch_size=BATCH_SIZE)
Epoch 1/5 152/152 [==============================] - 1s 4ms/step - loss: 0.6911 - accuracy: 0.6997 Epoch 2/5 152/152 [==============================] - 1s 4ms/step - loss: 0.5073 - accuracy: 0.7393 Epoch 3/5 152/152 [==============================] - 1s 4ms/step - loss: 0.4129 - accuracy: 0.7888 Epoch 4/5 152/152 [==============================] - 1s 4ms/step - loss: 0.3663 - accuracy: 0.7921 Epoch 5/5 152/152 [==============================] - 1s 4ms/step - loss: 0.3363 - accuracy: 0.8152
השימוש ב- tf.data עובד גם כן:
ds = tf.data.Dataset.from_tensor_slices((
dict(df),
target
))
ds = ds.batch(BATCH_SIZE)
import pprint
for x, y in ds.take(1):
pprint.pprint(x)
print()
print(y)
{'age': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([63, 67])>,
'ca': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([0, 3])>,
'chol': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([233, 286])>,
'cp': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([1, 4])>,
'exang': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([0, 1])>,
'fbs': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([1, 0])>,
'oldpeak': <tf.Tensor: shape=(2,), dtype=float64, numpy=array([2.3, 1.5])>,
'restecg': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([2, 2])>,
'sex': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([1, 1])>,
'slope': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([3, 2])>,
'thal': <tf.Tensor: shape=(2,), dtype=string, numpy=array([b'fixed', b'normal'], dtype=object)>,
'thalach': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([150, 108])>,
'trestbps': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([145, 160])>}
tf.Tensor([0 1], shape=(2,), dtype=int64)
history = model.fit(ds, epochs=5)
Epoch 1/5 152/152 [==============================] - 1s 5ms/step - loss: 0.3150 - accuracy: 0.8284 Epoch 2/5 152/152 [==============================] - 1s 5ms/step - loss: 0.2989 - accuracy: 0.8449 Epoch 3/5 152/152 [==============================] - 1s 5ms/step - loss: 0.2870 - accuracy: 0.8449 Epoch 4/5 152/152 [==============================] - 1s 5ms/step - loss: 0.2782 - accuracy: 0.8482 Epoch 5/5 152/152 [==============================] - 1s 5ms/step - loss: 0.2712 - accuracy: 0.8482