
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
Ten samouczek zawiera przykłady, jak załadować pandy DataFrames do TensorFlow.
Użyjesz małego zbioru danych o chorobach serca, dostarczonego przez repozytorium UCI Machine Learning. W pliku CSV jest kilkaset wierszy. Każdy wiersz opisuje pacjenta, a każda kolumna opisuje atrybut. Użyjesz tych informacji, aby przewidzieć, czy pacjent ma chorobę serca, co jest zadaniem klasyfikacji binarnej.
Czytaj dane za pomocą pand
import pandas as pd
import tensorflow as tf
SHUFFLE_BUFFER = 500
BATCH_SIZE = 2
Pobierz plik CSV zawierający zbiór danych dotyczących chorób serca:
csv_file = tf.keras.utils.get_file('heart.csv', 'https://storage.googleapis.com/download.tensorflow.org/data/heart.csv')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/data/heart.csv 16384/13273 [=====================================] - 0s 0us/step 24576/13273 [=======================================================] - 0s 0us/step
Przeczytaj plik CSV za pomocą pand:
df = pd.read_csv(csv_file)
Tak wyglądają dane:
df.head()
df.dtypes
age int64 sex int64 cp int64 trestbps int64 chol int64 fbs int64 restecg int64 thalach int64 exang int64 oldpeak float64 slope int64 ca int64 thal object target int64 dtype: object
Zbudujesz modele, aby przewidzieć etykietę zawartą w kolumnie target .
target = df.pop('target')
DataFrame jako tablica
Jeśli twoje dane mają jednolity typ danych lub dtype , możesz użyć pandy DataFrame wszędzie tam, gdzie możesz użyć tablicy NumPy. Działa to, ponieważ klasa pandas.DataFrame obsługuje protokół __array__ , a funkcja tf.convert_to_tensor w tf.convert_to_tensor akceptuje obiekty obsługujące ten protokół.
Weź funkcje numeryczne ze zbioru danych (na razie pomiń funkcje kategoryczne):
numeric_feature_names = ['age', 'thalach', 'trestbps', 'chol', 'oldpeak']
numeric_features = df[numeric_feature_names]
numeric_features.head()
DataFrame można przekonwertować na tablicę NumPy przy użyciu właściwości DataFrame.values lub numpy.array(df) . Aby przekonwertować go na tensor, użyj tf.convert_to_tensor :
tf.convert_to_tensor(numeric_features)
<tf.Tensor: shape=(303, 5), dtype=float64, numpy=
array([[ 63. , 150. , 145. , 233. , 2.3],
[ 67. , 108. , 160. , 286. , 1.5],
[ 67. , 129. , 120. , 229. , 2.6],
...,
[ 65. , 127. , 135. , 254. , 2.8],
[ 48. , 150. , 130. , 256. , 0. ],
[ 63. , 154. , 150. , 407. , 4. ]])>
Ogólnie rzecz biorąc, jeśli obiekt można przekonwertować na tensor za pomocą tf.convert_to_tensor , można go przekazać w dowolnym miejscu, w którym można przekazać tf.Tensor .
Z Model.fit
DataFrame, interpretowane jako pojedynczy tensor, może być używany bezpośrednio jako argument metody Model.fit .
Poniżej znajduje się przykład uczenia modelu na funkcjach numerycznych zbioru danych.
Pierwszym krokiem jest normalizacja zakresów wejściowych. Użyj do tego warstwy tf.keras.layers.Normalization .
Aby ustawić średnią i odchylenie standardowe warstwy przed jej uruchomieniem, należy wywołać metodę Normalization.adapt :
normalizer = tf.keras.layers.Normalization(axis=-1)
normalizer.adapt(numeric_features)
Wywołaj warstwę w pierwszych trzech wierszach elementu DataFrame, aby zwizualizować przykład danych wyjściowych z tej warstwy:
normalizer(numeric_features.iloc[:3])
<tf.Tensor: shape=(3, 5), dtype=float32, numpy=
array([[ 0.93383914, 0.03480718, 0.74578077, -0.26008663, 1.0680453 ],
[ 1.3782105 , -1.7806165 , 1.5923285 , 0.7573877 , 0.38022864],
[ 1.3782105 , -0.87290466, -0.6651321 , -0.33687714, 1.3259765 ]],
dtype=float32)>
Użyj warstwy normalizacji jako pierwszej warstwy prostego modelu:
def get_basic_model():
model = tf.keras.Sequential([
normalizer,
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(1)
])
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
return model
Kiedy przekażesz DataFrame jako argument x do Model.fit , Keras traktuje DataFrame jak tablicę NumPy:
model = get_basic_model()
model.fit(numeric_features, target, epochs=15, batch_size=BATCH_SIZE)
Epoch 1/15 152/152 [==============================] - 1s 2ms/step - loss: 0.6839 - accuracy: 0.7690 Epoch 2/15 152/152 [==============================] - 0s 2ms/step - loss: 0.5789 - accuracy: 0.7789 Epoch 3/15 152/152 [==============================] - 0s 2ms/step - loss: 0.5195 - accuracy: 0.7723 Epoch 4/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4814 - accuracy: 0.7855 Epoch 5/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4566 - accuracy: 0.7789 Epoch 6/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4427 - accuracy: 0.7888 Epoch 7/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4342 - accuracy: 0.7921 Epoch 8/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4290 - accuracy: 0.7855 Epoch 9/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4240 - accuracy: 0.7987 Epoch 10/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4232 - accuracy: 0.7987 Epoch 11/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4208 - accuracy: 0.7987 Epoch 12/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4186 - accuracy: 0.7954 Epoch 13/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4172 - accuracy: 0.8020 Epoch 14/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4156 - accuracy: 0.8020 Epoch 15/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4138 - accuracy: 0.8020 <keras.callbacks.History at 0x7f1ddc27b110>
Z tf.data
Jeśli chcesz zastosować przekształcenia tf.data do DataFrame o jednolitym dtype , Metoda Dataset.from_tensor_slices utworzy zestaw danych, który iteruje po wierszach DataFrame. Każdy wiersz jest początkowo wektorem wartości. Aby wytrenować model, potrzebujesz par (inputs, labels) , więc pass (features, labels) i Dataset.from_tensor_slices zwrócą potrzebne pary wycinków:
numeric_dataset = tf.data.Dataset.from_tensor_slices((numeric_features, target))
for row in numeric_dataset.take(3):
print(row)
(<tf.Tensor: shape=(5,), dtype=float64, numpy=array([ 63. , 150. , 145. , 233. , 2.3])>, <tf.Tensor: shape=(), dtype=int64, numpy=0>) (<tf.Tensor: shape=(5,), dtype=float64, numpy=array([ 67. , 108. , 160. , 286. , 1.5])>, <tf.Tensor: shape=(), dtype=int64, numpy=1>) (<tf.Tensor: shape=(5,), dtype=float64, numpy=array([ 67. , 129. , 120. , 229. , 2.6])>, <tf.Tensor: shape=(), dtype=int64, numpy=0>)
numeric_batches = numeric_dataset.shuffle(1000).batch(BATCH_SIZE)
model = get_basic_model()
model.fit(numeric_batches, epochs=15)
Epoch 1/15 152/152 [==============================] - 1s 2ms/step - loss: 0.7677 - accuracy: 0.6865 Epoch 2/15 152/152 [==============================] - 0s 2ms/step - loss: 0.6319 - accuracy: 0.7591 Epoch 3/15 152/152 [==============================] - 0s 2ms/step - loss: 0.5717 - accuracy: 0.7459 Epoch 4/15 152/152 [==============================] - 0s 2ms/step - loss: 0.5228 - accuracy: 0.7558 Epoch 5/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4820 - accuracy: 0.7624 Epoch 6/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4584 - accuracy: 0.7657 Epoch 7/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4454 - accuracy: 0.7657 Epoch 8/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4379 - accuracy: 0.7789 Epoch 9/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4324 - accuracy: 0.7789 Epoch 10/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4282 - accuracy: 0.7756 Epoch 11/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4273 - accuracy: 0.7789 Epoch 12/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4268 - accuracy: 0.7756 Epoch 13/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4248 - accuracy: 0.7789 Epoch 14/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4235 - accuracy: 0.7855 Epoch 15/15 152/152 [==============================] - 0s 2ms/step - loss: 0.4223 - accuracy: 0.7888 <keras.callbacks.History at 0x7f1ddc406510>
DataFrame jako słownik
Kiedy zaczynasz mieć do czynienia z danymi heterogenicznymi, nie jest już możliwe traktowanie elementu DataFrame jak pojedynczej tablicy. Tensory TensorFlow wymagają, aby wszystkie elementy miały ten sam dtype .
Tak więc w tym przypadku musisz zacząć traktować go jako słownik kolumn, w którym każda kolumna ma jednolity dtype. DataFrame jest bardzo podobna do słownika tablic, więc zazwyczaj wszystko, co musisz zrobić, to rzutować DataFrame na dyktat Pythona. Wiele ważnych interfejsów API TensorFlow obsługuje (zagnieżdżone) słowniki tablic jako danych wejściowych.
Potoki wejściowe tf.data radzą sobie z tym całkiem dobrze. Wszystkie operacje tf.data obsługują słowniki i krotki automatycznie. Tak więc, aby utworzyć zestaw danych z przykładami słownikowymi z DataFrame, po prostu rzuć go na dykt przed pocięciem go za pomocą Dataset.from_tensor_slices :
numeric_dict_ds = tf.data.Dataset.from_tensor_slices((dict(numeric_features), target))
Oto pierwsze trzy przykłady z tego zbioru danych:
for row in numeric_dict_ds.take(3):
print(row)
({'age': <tf.Tensor: shape=(), dtype=int64, numpy=63>, 'thalach': <tf.Tensor: shape=(), dtype=int64, numpy=150>, 'trestbps': <tf.Tensor: shape=(), dtype=int64, numpy=145>, 'chol': <tf.Tensor: shape=(), dtype=int64, numpy=233>, 'oldpeak': <tf.Tensor: shape=(), dtype=float64, numpy=2.3>}, <tf.Tensor: shape=(), dtype=int64, numpy=0>)
({'age': <tf.Tensor: shape=(), dtype=int64, numpy=67>, 'thalach': <tf.Tensor: shape=(), dtype=int64, numpy=108>, 'trestbps': <tf.Tensor: shape=(), dtype=int64, numpy=160>, 'chol': <tf.Tensor: shape=(), dtype=int64, numpy=286>, 'oldpeak': <tf.Tensor: shape=(), dtype=float64, numpy=1.5>}, <tf.Tensor: shape=(), dtype=int64, numpy=1>)
({'age': <tf.Tensor: shape=(), dtype=int64, numpy=67>, 'thalach': <tf.Tensor: shape=(), dtype=int64, numpy=129>, 'trestbps': <tf.Tensor: shape=(), dtype=int64, numpy=120>, 'chol': <tf.Tensor: shape=(), dtype=int64, numpy=229>, 'oldpeak': <tf.Tensor: shape=(), dtype=float64, numpy=2.6>}, <tf.Tensor: shape=(), dtype=int64, numpy=0>)
Słowniki z Keras
Zazwyczaj modele i warstwy Keras oczekują pojedynczego tensora wejściowego, ale te klasy mogą akceptować i zwracać zagnieżdżone struktury słowników, krotek i tensorów. Struktury te są znane jako „gniazda” (szczegóły w module tf.nest ).
Istnieją dwa równoważne sposoby napisania modelu Keras, który akceptuje słownik jako dane wejściowe.
1. Styl podklasy Model
Piszesz podklasę tf.keras.Model (lub tf.keras.Layer ). Bezpośrednio zajmujesz się danymi wejściowymi i tworzysz dane wyjściowe:
def stack_dict(inputs, fun=tf.stack):
values = []
for key in sorted(inputs.keys()):
values.append(tf.cast(inputs[key], tf.float32))
return fun(values, axis=-1)
class MyModel(tf.keras.Model):
def __init__(self):
# Create all the internal layers in init.
super().__init__(self)
self.normalizer = tf.keras.layers.Normalization(axis=-1)
self.seq = tf.keras.Sequential([
self.normalizer,
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(1)
])
def adapt(self, inputs):
# Stach the inputs and `adapt` the normalization layer.
inputs = stack_dict(inputs)
self.normalizer.adapt(inputs)
def call(self, inputs):
# Stack the inputs
inputs = stack_dict(inputs)
# Run them through all the layers.
result = self.seq(inputs)
return result
model = MyModel()
model.adapt(dict(numeric_features))
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'],
run_eagerly=True)
Ten model może akceptować słownik kolumn lub zestaw danych z elementami słownika do uczenia:
model.fit(dict(numeric_features), target, epochs=5, batch_size=BATCH_SIZE)
Epoch 1/5 152/152 [==============================] - 3s 17ms/step - loss: 0.6736 - accuracy: 0.7063 Epoch 2/5 152/152 [==============================] - 3s 17ms/step - loss: 0.5577 - accuracy: 0.7294 Epoch 3/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4869 - accuracy: 0.7591 Epoch 4/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4525 - accuracy: 0.7690 Epoch 5/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4403 - accuracy: 0.7624 <keras.callbacks.History at 0x7f1de4fa9390>
numeric_dict_batches = numeric_dict_ds.shuffle(SHUFFLE_BUFFER).batch(BATCH_SIZE)
model.fit(numeric_dict_batches, epochs=5)
Epoch 1/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4328 - accuracy: 0.7756 Epoch 2/5 152/152 [==============================] - 2s 14ms/step - loss: 0.4297 - accuracy: 0.7888 Epoch 3/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4270 - accuracy: 0.7888 Epoch 4/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4245 - accuracy: 0.8020 Epoch 5/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4240 - accuracy: 0.7921 <keras.callbacks.History at 0x7f1ddc0dba90>
Oto prognozy dla pierwszych trzech przykładów:
model.predict(dict(numeric_features.iloc[:3]))
array([[[0.00565109]],
[[0.60601974]],
[[0.03647463]]], dtype=float32)
2. Funkcjonalny styl Keras
inputs = {}
for name, column in numeric_features.items():
inputs[name] = tf.keras.Input(
shape=(1,), name=name, dtype=tf.float32)
inputs
{'age': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'age')>,
'thalach': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'thalach')>,
'trestbps': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'trestbps')>,
'chol': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'chol')>,
'oldpeak': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'oldpeak')>}
x = stack_dict(inputs, fun=tf.concat)
normalizer = tf.keras.layers.Normalization(axis=-1)
normalizer.adapt(stack_dict(dict(numeric_features)))
x = normalizer(x)
x = tf.keras.layers.Dense(10, activation='relu')(x)
x = tf.keras.layers.Dense(10, activation='relu')(x)
x = tf.keras.layers.Dense(1)(x)
model = tf.keras.Model(inputs, x)
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'],
run_eagerly=True)
tf.keras.utils.plot_model(model, rankdir="LR", show_shapes=True)

Model funkcjonalny można trenować w taki sam sposób, jak podklasę modelu:
model.fit(dict(numeric_features), target, epochs=5, batch_size=BATCH_SIZE)
Epoch 1/5 152/152 [==============================] - 2s 15ms/step - loss: 0.6529 - accuracy: 0.7492 Epoch 2/5 152/152 [==============================] - 2s 15ms/step - loss: 0.5448 - accuracy: 0.7624 Epoch 3/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4935 - accuracy: 0.7756 Epoch 4/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4650 - accuracy: 0.7789 Epoch 5/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4486 - accuracy: 0.7855 <keras.callbacks.History at 0x7f1ddc0d0f90>
numeric_dict_batches = numeric_dict_ds.shuffle(SHUFFLE_BUFFER).batch(BATCH_SIZE)
model.fit(numeric_dict_batches, epochs=5)
Epoch 1/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4398 - accuracy: 0.7855 Epoch 2/5 152/152 [==============================] - 2s 15ms/step - loss: 0.4330 - accuracy: 0.7855 Epoch 3/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4294 - accuracy: 0.7921 Epoch 4/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4271 - accuracy: 0.7888 Epoch 5/5 152/152 [==============================] - 2s 16ms/step - loss: 0.4231 - accuracy: 0.7855 <keras.callbacks.History at 0x7f1d7c5d5d10>
Pełny przykład
Jeśli przekazujesz heterogeniczną DataFrame do Keras, każda kolumna może wymagać unikalnego przetwarzania wstępnego. Możesz wykonać to wstępne przetwarzanie bezpośrednio w DataFrame, ale aby model działał poprawnie, dane wejściowe zawsze muszą być wstępnie przetwarzane w ten sam sposób. Dlatego najlepszym podejściem jest wbudowanie przetwarzania wstępnego w model. Warstwy przetwarzania wstępnego Keras obejmują wiele typowych zadań.
Zbuduj głowicę przetwarzania wstępnego
W tym zestawie danych niektóre cechy „liczby całkowitej” w nieprzetworzonych danych są w rzeczywistości indeksami kategorycznymi. Te indeksy nie są w rzeczywistości uporządkowanymi wartościami liczbowymi (szczegółowe informacje można znaleźć w opisie zestawu danych). Ponieważ są one nieuporządkowane, nie nadają się do bezpośredniego przesyłania do modelu; model zinterpretowałby je jako uporządkowane. Aby użyć tych danych wejściowych, musisz je zakodować, jako wektory z jednym gorącym wektorem lub wektory osadzające. To samo dotyczy cech kategorii ciągów.
Z drugiej strony funkcje binarne zasadniczo nie muszą być kodowane ani normalizowane.
Zacznij od stworzenia listy funkcji, które należą do każdej grupy:
binary_feature_names = ['sex', 'fbs', 'exang']
categorical_feature_names = ['cp', 'restecg', 'slope', 'thal', 'ca']
Następnym krokiem jest zbudowanie modelu przetwarzania wstępnego, który zastosuje odpowiednie przetwarzanie wstępne do każdego wejścia i połączy wyniki.
Ta sekcja używa interfejsu API Keras Functional do implementacji przetwarzania wstępnego. Zaczynasz od utworzenia jednego tf.keras.Input dla każdej kolumny ramki danych:
inputs = {}
for name, column in df.items():
if type(column[0]) == str:
dtype = tf.string
elif (name in categorical_feature_names or
name in binary_feature_names):
dtype = tf.int64
else:
dtype = tf.float32
inputs[name] = tf.keras.Input(shape=(), name=name, dtype=dtype)
inputs
{'age': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'age')>,
'sex': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'sex')>,
'cp': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'cp')>,
'trestbps': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'trestbps')>,
'chol': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'chol')>,
'fbs': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'fbs')>,
'restecg': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'restecg')>,
'thalach': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'thalach')>,
'exang': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'exang')>,
'oldpeak': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'oldpeak')>,
'slope': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'slope')>,
'ca': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'ca')>,
'thal': <KerasTensor: shape=(None,) dtype=string (created by layer 'thal')>}
Dla każdego wejścia zastosujesz pewne przekształcenia za pomocą warstw Keras i operacji TensorFlow. Każda funkcja zaczyna się jako partia skalarów ( shape=(batch,) ). Dane wyjściowe dla każdego powinny być partią wektorów tf.float32 ( shape=(batch, n) ). Ostatni krok połączy wszystkie te wektory razem.
Wejścia binarne
Ponieważ wejścia binarne nie wymagają żadnego przetwarzania wstępnego, wystarczy dodać oś wektora, rzutować je na float32 i dodać do listy wstępnie przetworzonych danych wejściowych:
preprocessed = []
for name in binary_feature_names:
inp = inputs[name]
inp = inp[:, tf.newaxis]
float_value = tf.cast(inp, tf.float32)
preprocessed.append(float_value)
preprocessed
[<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_5')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_6')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_7')>]
Wejścia numeryczne
Podobnie jak we wcześniejszej sekcji, przed użyciem tych danych liczbowych należy przeprowadzić przez warstwę tf.keras.layers.Normalization . Różnica polega na tym, że tym razem są one wprowadzane jako dyktanda. Poniższy kod zbiera funkcje numeryczne z DataFrame, układa je razem i przekazuje do metody Normalization.adapt .
normalizer = tf.keras.layers.Normalization(axis=-1)
normalizer.adapt(stack_dict(dict(numeric_features)))
Poniższy kod zestawia funkcje numeryczne i przepuszcza je przez warstwę normalizacji.
numeric_inputs = {}
for name in numeric_feature_names:
numeric_inputs[name]=inputs[name]
numeric_inputs = stack_dict(numeric_inputs)
numeric_normalized = normalizer(numeric_inputs)
preprocessed.append(numeric_normalized)
preprocessed
[<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_5')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_6')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_7')>, <KerasTensor: shape=(None, 5) dtype=float32 (created by layer 'normalization_3')>]
Cechy kategoryczne
Aby korzystać z funkcji kategorycznych, musisz najpierw zakodować je na wektory binarne lub osadzania. Ponieważ te funkcje zawierają tylko niewielką liczbę kategorii, przekonwertuj dane wejściowe bezpośrednio na wektory o jednym gorącym stanie za pomocą opcji output_mode='one_hot' , obsługiwanej przez warstwy tf.keras.layers.StringLookup i tf.keras.layers.IntegerLookup .
Oto przykład działania tych warstw:
vocab = ['a','b','c']
lookup = tf.keras.layers.StringLookup(vocabulary=vocab, output_mode='one_hot')
lookup(['c','a','a','b','zzz'])
<tf.Tensor: shape=(5, 4), dtype=float32, numpy=
array([[0., 0., 0., 1.],
[0., 1., 0., 0.],
[0., 1., 0., 0.],
[0., 0., 1., 0.],
[1., 0., 0., 0.]], dtype=float32)>
vocab = [1,4,7,99]
lookup = tf.keras.layers.IntegerLookup(vocabulary=vocab, output_mode='one_hot')
lookup([-1,4,1])
<tf.Tensor: shape=(3, 5), dtype=float32, numpy=
array([[1., 0., 0., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 1., 0., 0., 0.]], dtype=float32)>
Aby określić słownictwo dla każdego wejścia, utwórz warstwę, aby przekonwertować to słownictwo na jeden gorący wektor:
for name in categorical_feature_names:
vocab = sorted(set(df[name]))
print(f'name: {name}')
print(f'vocab: {vocab}\n')
if type(vocab[0]) is str:
lookup = tf.keras.layers.StringLookup(vocabulary=vocab, output_mode='one_hot')
else:
lookup = tf.keras.layers.IntegerLookup(vocabulary=vocab, output_mode='one_hot')
x = inputs[name][:, tf.newaxis]
x = lookup(x)
preprocessed.append(x)
name: cp vocab: [0, 1, 2, 3, 4] name: restecg vocab: [0, 1, 2] name: slope vocab: [1, 2, 3] name: thal vocab: ['1', '2', 'fixed', 'normal', 'reversible'] name: ca vocab: [0, 1, 2, 3]
Zamontuj głowicę przetwarzania wstępnego
W tym momencie preprocessed jest tylko lista Pythona wszystkich wyników wstępnego przetwarzania, każdy wynik ma kształt (batch_size, depth) :
preprocessed
[<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_5')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_6')>, <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'tf.cast_7')>, <KerasTensor: shape=(None, 5) dtype=float32 (created by layer 'normalization_3')>, <KerasTensor: shape=(None, 6) dtype=float32 (created by layer 'integer_lookup_1')>, <KerasTensor: shape=(None, 4) dtype=float32 (created by layer 'integer_lookup_2')>, <KerasTensor: shape=(None, 4) dtype=float32 (created by layer 'integer_lookup_3')>, <KerasTensor: shape=(None, 6) dtype=float32 (created by layer 'string_lookup_1')>, <KerasTensor: shape=(None, 5) dtype=float32 (created by layer 'integer_lookup_4')>]
Połącz wszystkie wstępnie przetworzone funkcje wzdłuż osi depth , aby każdy przykład-słownik został przekonwertowany na pojedynczy wektor. Wektor zawiera cechy kategoryczne, cechy numeryczne i jednoczęściowe cechy jakościowe:
preprocesssed_result = tf.concat(preprocessed, axis=-1)
preprocesssed_result
<KerasTensor: shape=(None, 33) dtype=float32 (created by layer 'tf.concat_1')>
Teraz utwórz model z tych obliczeń, aby można go było ponownie wykorzystać:
preprocessor = tf.keras.Model(inputs, preprocesssed_result)
tf.keras.utils.plot_model(preprocessor, rankdir="LR", show_shapes=True)
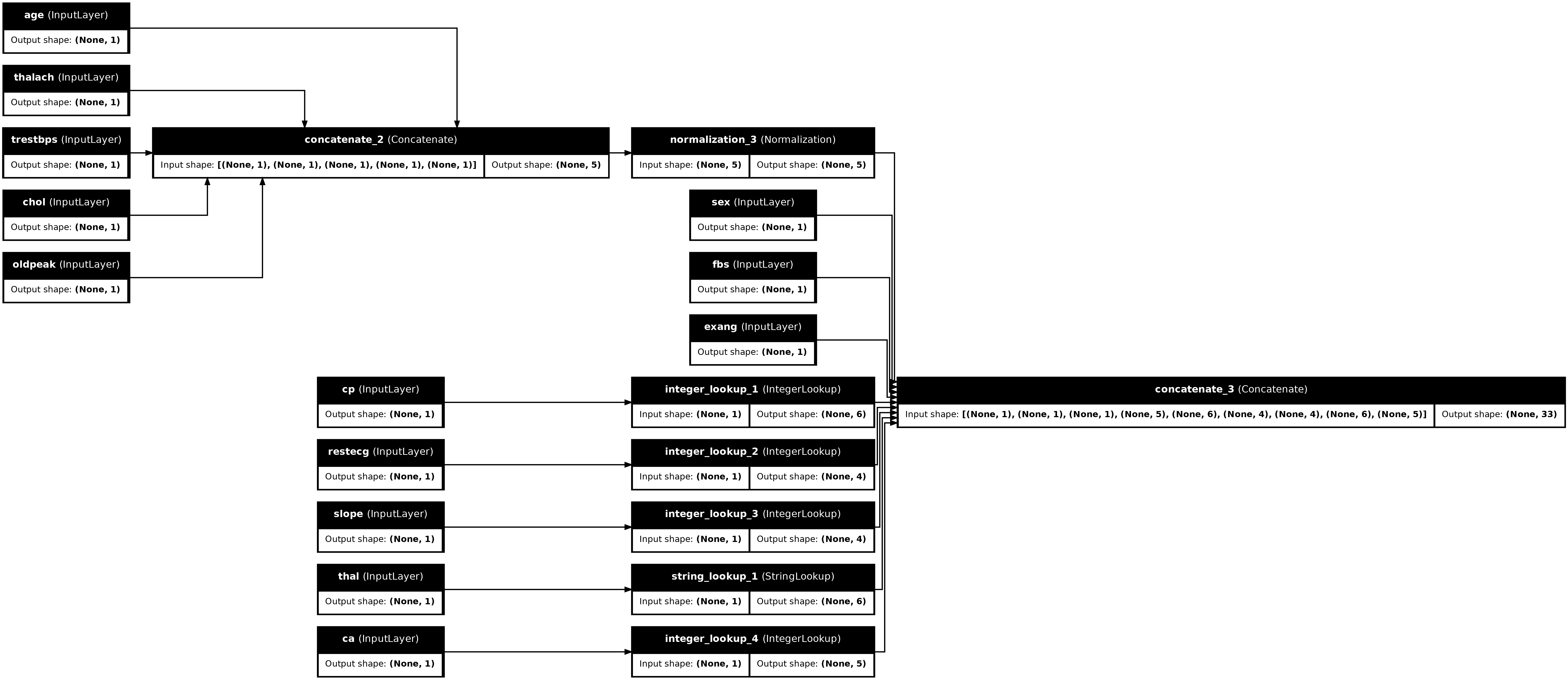
Aby przetestować preprocesor, użyj akcesora DataFrame.iloc , aby wyciąć pierwszy przykład z DataFrame. Następnie przekonwertuj go na słownik i przekaż go do preprocesora. Wynikiem jest pojedynczy wektor zawierający cechy binarne, znormalizowane cechy numeryczne i jednogorące cechy kategorialne, w tej kolejności:
preprocessor(dict(df.iloc[:1]))
<tf.Tensor: shape=(1, 33), dtype=float32, numpy=
array([[ 1. , 1. , 0. , 0.93383914, -0.26008663,
1.0680453 , 0.03480718, 0.74578077, 0. , 0. ,
1. , 0. , 0. , 0. , 0. ,
0. , 0. , 1. , 0. , 0. ,
0. , 1. , 0. , 0. , 0. ,
1. , 0. , 0. , 0. , 1. ,
0. , 0. , 0. ]], dtype=float32)>
Twórz i trenuj model
Teraz zbuduj główny korpus modelu. Użyj tej samej konfiguracji, co w poprzednim przykładzie: kilka warstw rektyfikowanych liniowych Dense i warstwa wyjściowa Dense(1) do klasyfikacji.
body = tf.keras.Sequential([
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(10, activation='relu'),
tf.keras.layers.Dense(1)
])
Teraz połącz te dwie części, używając funkcjonalnego API Keras.
inputs
{'age': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'age')>,
'sex': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'sex')>,
'cp': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'cp')>,
'trestbps': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'trestbps')>,
'chol': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'chol')>,
'fbs': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'fbs')>,
'restecg': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'restecg')>,
'thalach': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'thalach')>,
'exang': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'exang')>,
'oldpeak': <KerasTensor: shape=(None,) dtype=float32 (created by layer 'oldpeak')>,
'slope': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'slope')>,
'ca': <KerasTensor: shape=(None,) dtype=int64 (created by layer 'ca')>,
'thal': <KerasTensor: shape=(None,) dtype=string (created by layer 'thal')>}
x = preprocessor(inputs)
x
<KerasTensor: shape=(None, 33) dtype=float32 (created by layer 'model_1')>
result = body(x)
result
<KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'sequential_3')>
model = tf.keras.Model(inputs, result)
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
Model ten oczekuje słownika danych wejściowych. Najprostszym sposobem przekazania danych jest przekonwertowanie DataFrame na dyktat i przekazanie go jako argumentu x do Model.fit :
history = model.fit(dict(df), target, epochs=5, batch_size=BATCH_SIZE)
Epoch 1/5 152/152 [==============================] - 1s 4ms/step - loss: 0.6911 - accuracy: 0.6997 Epoch 2/5 152/152 [==============================] - 1s 4ms/step - loss: 0.5073 - accuracy: 0.7393 Epoch 3/5 152/152 [==============================] - 1s 4ms/step - loss: 0.4129 - accuracy: 0.7888 Epoch 4/5 152/152 [==============================] - 1s 4ms/step - loss: 0.3663 - accuracy: 0.7921 Epoch 5/5 152/152 [==============================] - 1s 4ms/step - loss: 0.3363 - accuracy: 0.8152
Korzystanie tf.data działa również:
ds = tf.data.Dataset.from_tensor_slices((
dict(df),
target
))
ds = ds.batch(BATCH_SIZE)
import pprint
for x, y in ds.take(1):
pprint.pprint(x)
print()
print(y)
{'age': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([63, 67])>,
'ca': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([0, 3])>,
'chol': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([233, 286])>,
'cp': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([1, 4])>,
'exang': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([0, 1])>,
'fbs': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([1, 0])>,
'oldpeak': <tf.Tensor: shape=(2,), dtype=float64, numpy=array([2.3, 1.5])>,
'restecg': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([2, 2])>,
'sex': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([1, 1])>,
'slope': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([3, 2])>,
'thal': <tf.Tensor: shape=(2,), dtype=string, numpy=array([b'fixed', b'normal'], dtype=object)>,
'thalach': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([150, 108])>,
'trestbps': <tf.Tensor: shape=(2,), dtype=int64, numpy=array([145, 160])>}
tf.Tensor([0 1], shape=(2,), dtype=int64)
history = model.fit(ds, epochs=5)
Epoch 1/5 152/152 [==============================] - 1s 5ms/step - loss: 0.3150 - accuracy: 0.8284 Epoch 2/5 152/152 [==============================] - 1s 5ms/step - loss: 0.2989 - accuracy: 0.8449 Epoch 3/5 152/152 [==============================] - 1s 5ms/step - loss: 0.2870 - accuracy: 0.8449 Epoch 4/5 152/152 [==============================] - 1s 5ms/step - loss: 0.2782 - accuracy: 0.8482 Epoch 5/5 152/152 [==============================] - 1s 5ms/step - loss: 0.2712 - accuracy: 0.8482