
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
Bu öğretici, bir görüntü veri kümesinin nasıl yükleneceğini ve önişlemden geçirileceğini üç şekilde gösterir:
- İlk olarak, diskteki bir görüntü dizinini okumak için yüksek seviyeli Keras ön işleme yardımcı programlarını (
tf.keras.utils.image_dataset_from_directorygibi) ve katmanları (tf.keras.layers.Rescalinggibi) kullanacaksınız. - Ardından, tf.data kullanarak kendi girdi işlem hattınızı sıfırdan yazacaksınız.
- Son olarak, TensorFlow Datasets'te bulunan geniş katalogdan bir veri seti indireceksiniz.
Kurmak
import numpy as np
import os
import PIL
import PIL.Image
import tensorflow as tf
import tensorflow_datasets as tfds
print(tf.__version__)
2.8.0-rc1
Çiçekler veri setini indirin
Bu öğretici, birkaç bin çiçek fotoğrafından oluşan bir veri kümesi kullanır. Çiçekler veri kümesi, sınıf başına bir tane olmak üzere beş alt dizin içerir:
flowers_photos/
daisy/
dandelion/
roses/
sunflowers/
tulips/
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file(origin=dataset_url,
fname='flower_photos',
untar=True)
data_dir = pathlib.Path(data_dir)
İndirdikten sonra (218MB), şimdi mevcut çiçek fotoğraflarının bir kopyasına sahip olmalısınız. Toplam 3.670 resim var:
image_count = len(list(data_dir.glob('*/*.jpg')))
print(image_count)
3670
Her dizin, o çiçek türünün resimlerini içerir. İşte bazı güller:
roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[0]))

roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[1]))

Keras yardımcı programını kullanarak verileri yükleyin
Yardımcı tf.keras.utils.image_dataset_from_directory yardımcı programını kullanarak bu görüntüleri diskten yükleyelim.
Veri kümesi oluşturun
Yükleyici için bazı parametreleri tanımlayın:
batch_size = 32
img_height = 180
img_width = 180
Modelinizi geliştirirken bir doğrulama bölmesi kullanmak iyi bir uygulamadır. Görsellerin %80'ini eğitim için ve %20'sini doğrulama için kullanacaksınız.
train_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 2936 files for training.yer tutucu12 l10n-yer
val_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 734 files for validation.
Sınıf adlarını bu veri kümelerinde class_names özniteliğinde bulabilirsiniz.
class_names = train_ds.class_names
print(class_names)
['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']
Verileri görselleştirin
İşte eğitim veri setinden ilk dokuz görüntü.
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
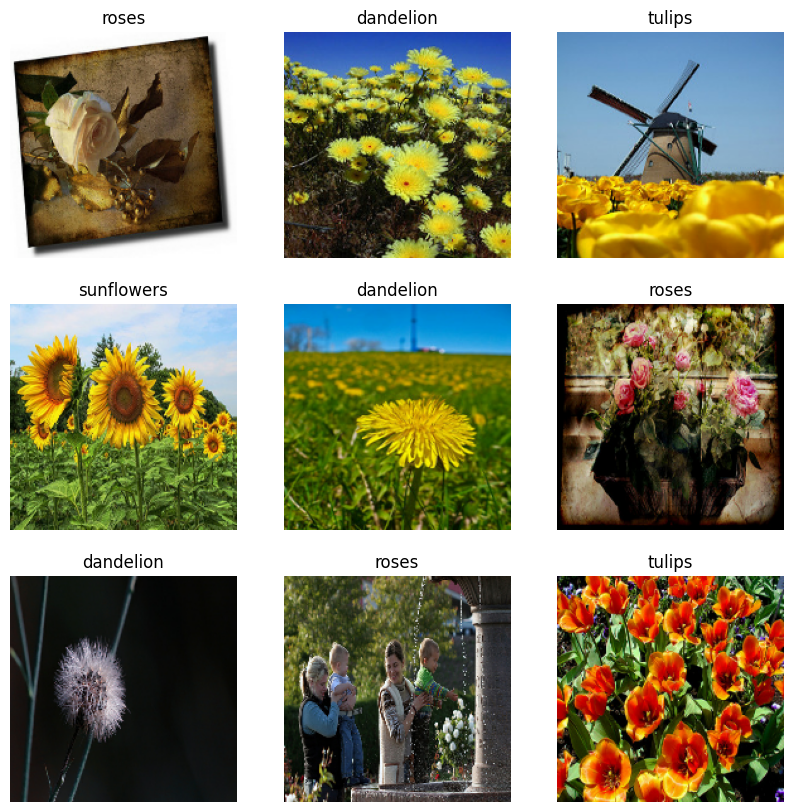
Bu veri kümelerini model.fit geçirerek (bu öğreticide daha sonra gösterilmektedir) kullanarak bir modeli eğitebilirsiniz. İsterseniz, veri kümesini manuel olarak yineleyebilir ve toplu görüntü alabilirsiniz:
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
(32, 180, 180, 3) (32,)
image_batch , (32, 180, 180, 3) şeklinin bir tensörüdür. Bu, 180x180x3 şeklinde 32 görüntüden oluşan bir toplu işlemdir (son boyut, RGB renk kanallarını ifade eder). label_batch , şeklin (32,) bir tensörüdür, bunlar 32 görüntüye karşılık gelen etiketlerdir.
Onları bir numpy.ndarray dönüştürmek için bu tensörlerden herhangi birinde .numpy() öğesini çağırabilirsiniz.
Verileri standartlaştırın
RGB kanal değerleri [0, 255] aralığındadır. Bu bir sinir ağı için ideal değildir; genel olarak girdi değerlerinizi küçük yapmaya çalışmalısınız.
Burada, tf.keras.layers.Rescaling kullanarak değerleri [0, 1] aralığında olacak şekilde standartlaştıracaksınız:
normalization_layer = tf.keras.layers.Rescaling(1./255)
Bu katmanı kullanmanın iki yolu vardır. Dataset.map arayarak veri kümesine uygulayabilirsiniz:
normalized_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(normalized_ds))
first_image = image_batch[0]
# Notice the pixel values are now in `[0,1]`.
print(np.min(first_image), np.max(first_image))
0.0 0.96902645
Veya dağıtımı basitleştirmek için katmanı model tanımınıza dahil edebilirsiniz. Burada ikinci yaklaşımı kullanacaksınız.
Performans için veri kümesini yapılandırın
G/Ç'nin bloke olmasına gerek kalmadan diskten veri alabilmeniz için arabelleğe alınmış önceden getirmeyi kullandığınızdan emin olalım. Bunlar, verileri yüklerken kullanmanız gereken iki önemli yöntemdir:
-
Dataset.cache, görüntüleri ilk dönem boyunca diskten yüklendikten sonra bellekte tutar. Bu, modelinizi eğitirken veri setinin bir darboğaz haline gelmemesini sağlayacaktır. Veri kümeniz belleğe sığmayacak kadar büyükse, bu yöntemi, performanslı bir disk önbelleği oluşturmak için de kullanabilirsiniz. -
Dataset.prefetch, eğitim sırasında veri ön işleme ve model yürütme ile çakışır.
İlgilenen okuyucular , tf.data API kılavuzu ile daha iyi performans'ın Önceden Getirme bölümünde verilerin diske nasıl önbelleğe alınacağının yanı sıra her iki yöntem hakkında daha fazla bilgi edinebilir.
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
Model eğit
Tamlık için, az önce hazırladığınız veri kümelerini kullanarak basit bir modelin nasıl eğitileceğini göstereceksiniz.
Sıralı model, her birinde bir maksimum havuzlama katmanına ( tf.keras.layers.MaxPooling2D ) sahip üç evrişim bloğundan ( tf.keras.layers.Conv2D ) oluşur. Üstünde bir ReLU etkinleştirme işlevi ( 'relu' ) tarafından etkinleştirilen 128 birimlik tam bağlı bir katman ( tf.keras.layers.Dense ) vardır. Bu model hiçbir şekilde ayarlanmamıştır; amaç, az önce oluşturduğunuz veri kümelerini kullanarak size mekaniği göstermektir. Görüntü sınıflandırması hakkında daha fazla bilgi edinmek için Görüntü sınıflandırma öğreticisini ziyaret edin.
num_classes = 5
model = tf.keras.Sequential([
tf.keras.layers.Rescaling(1./255),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(num_classes)
])
tf.keras.optimizers.Adam optimizer ve tf.keras.losses.SparseCategoricalCrossentropy kaybı işlevini seçin. Her eğitim dönemi için eğitim ve doğrulama doğruluğunu görüntülemek için, metrics bağımsız değişkenini Model.compile .
model.compile(
optimizer='adam',
loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(
train_ds,
validation_data=val_ds,
epochs=3
)
Epoch 1/3 92/92 [==============================] - 4s 21ms/step - loss: 1.3091 - accuracy: 0.4281 - val_loss: 1.0982 - val_accuracy: 0.5599 Epoch 2/3 92/92 [==============================] - 1s 12ms/step - loss: 1.0196 - accuracy: 0.5879 - val_loss: 0.9572 - val_accuracy: 0.6213 Epoch 3/3 92/92 [==============================] - 1s 12ms/step - loss: 0.8455 - accuracy: 0.6775 - val_loss: 0.8839 - val_accuracy: 0.6512 <keras.callbacks.History at 0x7ff10c168850>
Doğrulama doğruluğunun eğitim doğruluğuna kıyasla düşük olduğunu fark edebilirsiniz, bu da modelinizin fazla uyumlu olduğunu gösterir. Bu eğitimde fazla takma ve nasıl azaltılacağı hakkında daha fazla bilgi edinebilirsiniz.
Daha hassas kontrol için tf.data kullanma
Yukarıdaki Keras ön işleme yardımcı programı — tf.keras.utils.image_dataset_from_directory — bir görüntü dizininden tf.data.Dataset oluşturmanın uygun bir yoludur.
Daha hassas tahıl kontrolü için tf.data kullanarak kendi girdi işlem hattınızı yazabilirsiniz. Bu bölüm, daha önce indirdiğiniz TGZ dosyasındaki dosya yollarından başlayarak tam da bunun nasıl yapılacağını gösterir.
list_ds = tf.data.Dataset.list_files(str(data_dir/'*/*'), shuffle=False)
list_ds = list_ds.shuffle(image_count, reshuffle_each_iteration=False)
for f in list_ds.take(5):
print(f.numpy())
b'/home/kbuilder/.keras/datasets/flower_photos/roses/14267691818_301aceda07.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/daisy/2641151167_3bf1349606_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/6495554833_86eb8faa8e_n.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/tulips/4578030672_e6aefd45af.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/144686365_d7e96941ee_n.jpg'
Dosyaların ağaç yapısı, bir class_names listesi derlemek için kullanılabilir.
class_names = np.array(sorted([item.name for item in data_dir.glob('*') if item.name != "LICENSE.txt"]))
print(class_names)
['daisy' 'dandelion' 'roses' 'sunflowers' 'tulips']
Veri kümesini eğitim ve doğrulama kümelerine ayırın:
val_size = int(image_count * 0.2)
train_ds = list_ds.skip(val_size)
val_ds = list_ds.take(val_size)
Her veri kümesinin uzunluğunu aşağıdaki gibi yazdırabilirsiniz:
print(tf.data.experimental.cardinality(train_ds).numpy())
print(tf.data.experimental.cardinality(val_ds).numpy())
2936 734
Bir dosya yolunu bir (img, label) çiftine dönüştüren kısa bir fonksiyon yazın:
def get_label(file_path):
# Convert the path to a list of path components
parts = tf.strings.split(file_path, os.path.sep)
# The second to last is the class-directory
one_hot = parts[-2] == class_names
# Integer encode the label
return tf.argmax(one_hot)
def decode_img(img):
# Convert the compressed string to a 3D uint8 tensor
img = tf.io.decode_jpeg(img, channels=3)
# Resize the image to the desired size
return tf.image.resize(img, [img_height, img_width])
def process_path(file_path):
label = get_label(file_path)
# Load the raw data from the file as a string
img = tf.io.read_file(file_path)
img = decode_img(img)
return img, label
image, label çiftlerinden oluşan bir veri kümesi oluşturmak için Dataset.map kullanın:
# Set `num_parallel_calls` so multiple images are loaded/processed in parallel.
train_ds = train_ds.map(process_path, num_parallel_calls=AUTOTUNE)
val_ds = val_ds.map(process_path, num_parallel_calls=AUTOTUNE)
for image, label in train_ds.take(1):
print("Image shape: ", image.numpy().shape)
print("Label: ", label.numpy())
Image shape: (180, 180, 3) Label: 1
Performans için veri kümesini yapılandırın
Bu veri kümesiyle bir modeli eğitmek için aşağıdaki verileri isteyeceksiniz:
- İyice karıştırılmak.
- Toplu olarak.
- Partiler mümkün olan en kısa sürede hazır olacak.
Bu özellikler tf.data API kullanılarak eklenebilir. Daha fazla ayrıntı için Giriş İşlem Hattı Performansı kılavuzunu ziyaret edin.
def configure_for_performance(ds):
ds = ds.cache()
ds = ds.shuffle(buffer_size=1000)
ds = ds.batch(batch_size)
ds = ds.prefetch(buffer_size=AUTOTUNE)
return ds
train_ds = configure_for_performance(train_ds)
val_ds = configure_for_performance(val_ds)
Verileri görselleştirin
Bu veri kümesini daha önce oluşturduğunuza benzer şekilde görselleştirebilirsiniz:
image_batch, label_batch = next(iter(train_ds))
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image_batch[i].numpy().astype("uint8"))
label = label_batch[i]
plt.title(class_names[label])
plt.axis("off")
2022-01-26 06:29:45.209901: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
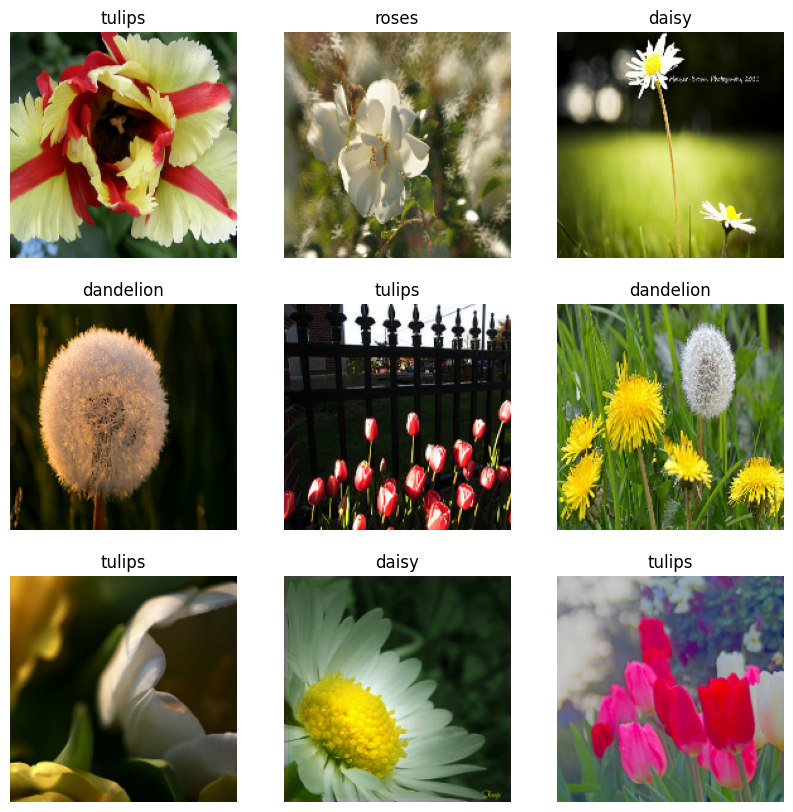
Modeli eğitmeye devam edin
Şimdi, yukarıdaki tf.keras.utils.image_dataset_from_directory tarafından oluşturulana benzer bir tf.data.Dataset manuel olarak oluşturdunuz. Modeli onunla eğitmeye devam edebilirsiniz. Daha önce olduğu gibi, koşu süresini kısa tutmak için sadece birkaç dönem için antrenman yapacaksınız.
model.fit(
train_ds,
validation_data=val_ds,
epochs=3
)
Epoch 1/3 92/92 [==============================] - 3s 21ms/step - loss: 0.7305 - accuracy: 0.7245 - val_loss: 0.7311 - val_accuracy: 0.7139 Epoch 2/3 92/92 [==============================] - 1s 13ms/step - loss: 0.5279 - accuracy: 0.8069 - val_loss: 0.7021 - val_accuracy: 0.7316 Epoch 3/3 92/92 [==============================] - 1s 13ms/step - loss: 0.3739 - accuracy: 0.8644 - val_loss: 0.8266 - val_accuracy: 0.6948 <keras.callbacks.History at 0x7ff0ee071f10>
TensorFlow Veri Kümelerini Kullanma
Şimdiye kadar, bu eğitim diskten veri yüklemeye odaklandı. Ayrıca TensorFlow Veri Kümeleri'nde indirilmesi kolay veri kümelerinin geniş kataloğunu keşfederek kullanmak için bir veri kümesi bulabilirsiniz.
Flowers veri kümesini daha önce diskten yüklediğiniz için, şimdi onu TensorFlow Veri Kümeleri ile içe aktaralım.
TensorFlow Veri Kümelerini kullanarak Flowers veri kümesini indirin:
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
Çiçekler veri kümesinin beş sınıfı vardır:
num_classes = metadata.features['label'].num_classes
print(num_classes)
5
Veri kümesinden bir görüntü alın:
get_label_name = metadata.features['label'].int2str
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 06:29:54.281352: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

Daha önce olduğu gibi, performans için eğitim, doğrulama ve test setlerini gruplamayı, karıştırmayı ve yapılandırmayı unutmayın:
train_ds = configure_for_performance(train_ds)
val_ds = configure_for_performance(val_ds)
test_ds = configure_for_performance(test_ds)
Veri büyütme eğitimini ziyaret ederek Flowers veri kümesi ve TensorFlow Veri Kümeleri ile çalışmanın eksiksiz bir örneğini bulabilirsiniz.
Sonraki adımlar
Bu öğretici, görüntüleri diskten yüklemenin iki yolunu gösterdi. İlk olarak, Keras ön işleme katmanlarını ve yardımcı programlarını kullanarak bir görüntü veri kümesinin nasıl yükleneceğini ve önişlemden geçirileceğini öğrendiniz. Ardından, tf.data kullanarak sıfırdan bir girdi ardışık düzenini nasıl yazacağınızı öğrendiniz. Son olarak, TensorFlow Veri Kümelerinden bir veri kümesini nasıl indireceğinizi öğrendiniz.
Sonraki adımlarınız için:
- Veri büyütmeyi nasıl ekleyeceğinizi öğrenebilirsiniz.
-
tf.datahakkında daha fazla bilgi edinmek için tf.data: TensorFlow giriş işlem hatları oluşturma kılavuzunu ziyaret edebilirsiniz.