
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
Ten samouczek pokazuje, jak załadować i wstępnie przetworzyć zestaw danych obrazu na trzy sposoby:
- Najpierw użyjesz wysokopoziomowych narzędzi przetwarzania wstępnego Keras (takich jak
tf.keras.utils.image_dataset_from_directory) i warstw (takich jaktf.keras.layers.Rescaling) do odczytania katalogu obrazów na dysku. - Następnie napiszesz swój własny potok wejściowy od podstaw , używając tf.data .
- Na koniec pobierzesz zestaw danych z dużego katalogu dostępnego w TensorFlow Datasets .
Ustawiać
import numpy as np
import os
import PIL
import PIL.Image
import tensorflow as tf
import tensorflow_datasets as tfds
print(tf.__version__)
2.8.0-rc1
Pobierz zbiór danych o kwiatach
Ten samouczek wykorzystuje zbiór danych zawierający kilka tysięcy zdjęć kwiatów. Zbiór danych kwiaty zawiera pięć podkatalogów, po jednym na klasę:
flowers_photos/
daisy/
dandelion/
roses/
sunflowers/
tulips/
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file(origin=dataset_url,
fname='flower_photos',
untar=True)
data_dir = pathlib.Path(data_dir)
Po pobraniu (218 MB) powinieneś mieć teraz dostępną kopię zdjęć kwiatów. Łącznie jest 3670 obrazów:
image_count = len(list(data_dir.glob('*/*.jpg')))
print(image_count)
3670
Każdy katalog zawiera obrazy tego typu kwiatów. Oto kilka róż:
roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[0]))

roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[1]))

Załaduj dane za pomocą narzędzia Keras
Załadujmy te obrazy z dysku za pomocą przydatnego narzędzia tf.keras.utils.image_dataset_from_directory .
Utwórz zbiór danych
Zdefiniuj kilka parametrów modułu ładującego:
batch_size = 32
img_height = 180
img_width = 180
Dobrą praktyką jest używanie podziału walidacji podczas opracowywania modelu. 80% obrazów wykorzystasz do szkolenia, a 20% do walidacji.
train_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 2936 files for training.
val_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 734 files for validation.
Nazwy klas można znaleźć w atrybucie class_names w tych zestawach danych.
class_names = train_ds.class_names
print(class_names)
['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']
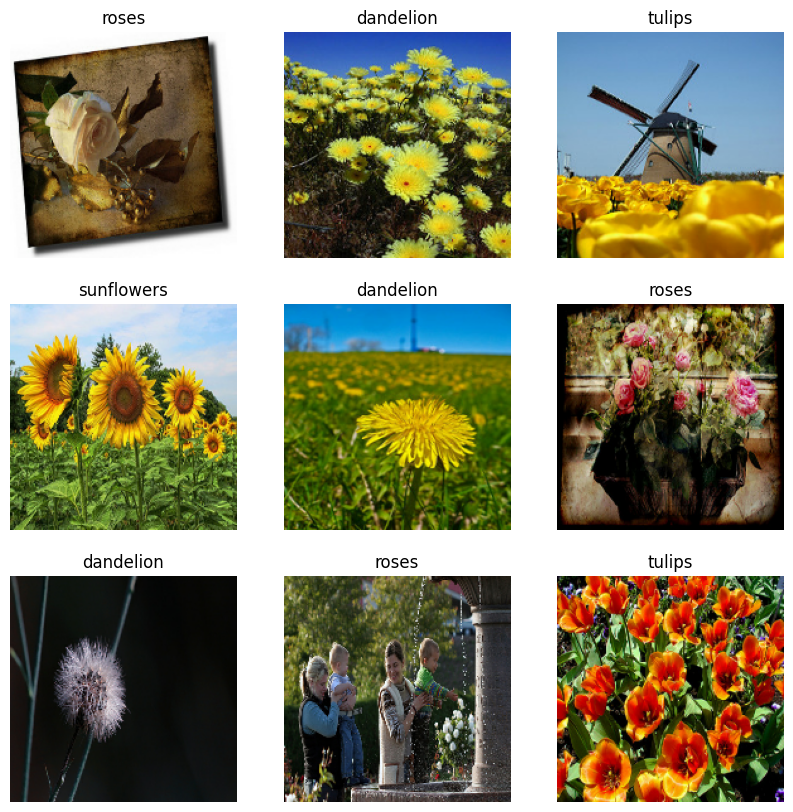
Wizualizuj dane
Oto pierwsze dziewięć obrazów ze zbioru danych treningowych.
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
Możesz trenować model przy użyciu tych zestawów danych, przekazując je do model.fit (pokazanego w dalszej części tego samouczka). Jeśli chcesz, możesz również ręcznie iterować zestaw danych i pobierać partie obrazów:
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
(32, 180, 180, 3) (32,)
image_batch to tensor kształtu (32, 180, 180, 3) . Jest to partia 32 obrazów o kształcie 180x180x3 (ostatni wymiar dotyczy kanałów kolorów RGB). label_batch jest tensorem kształtu (32,) , są to etykiety odpowiadające 32 obrazom.
Możesz wywołać .numpy() na jednym z tych tensorów, aby przekonwertować je na numpy.ndarray .
Standaryzuj dane
Wartości kanałów RGB mieszczą się w zakresie [0, 255] . Nie jest to idealne rozwiązanie dla sieci neuronowej; ogólnie powinieneś starać się, aby twoje wartości wejściowe były małe.
Tutaj ustandaryzujesz wartości tak, aby mieściły się w zakresie [0, 1] , używając tf.keras.layers.Rescaling :
normalization_layer = tf.keras.layers.Rescaling(1./255)
Istnieją dwa sposoby wykorzystania tej warstwy. Możesz zastosować go do zestawu danych, wywołując Dataset.map :
normalized_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(normalized_ds))
first_image = image_batch[0]
# Notice the pixel values are now in `[0,1]`.
print(np.min(first_image), np.max(first_image))
0.0 0.96902645
Możesz też dołączyć warstwę do definicji modelu, aby uprościć wdrażanie. Tutaj skorzystasz z drugiego podejścia.
Skonfiguruj zbiór danych pod kątem wydajności
Upewnij się, że używasz buforowanego pobierania z wyprzedzeniem, aby móc uzyskiwać dane z dysku bez blokowania operacji we/wy. Oto dwie ważne metody, których powinieneś użyć podczas ładowania danych:
-
Dataset.cacheprzechowuje obrazy w pamięci po ich załadowaniu z dysku w pierwszej epoce. Zapewni to, że zestaw danych nie stanie się wąskim gardłem podczas trenowania modelu. Jeśli zestaw danych jest zbyt duży, aby zmieścić się w pamięci, możesz również użyć tej metody do utworzenia wydajnej pamięci podręcznej na dysku. -
Dataset.prefetchnakłada się na wstępne przetwarzanie danych i wykonywanie modelu podczas uczenia.
Zainteresowani czytelnicy mogą dowiedzieć się więcej o obu metodach, a także o buforowaniu danych na dysku w sekcji Pobieranie z wyprzedzeniem w przewodniku Lepsza wydajność z przewodnikiem po interfejsie API tf.data .
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
Wytrenuj modelkę
Aby uzyskać kompletność, pokażesz, jak wytrenować prosty model przy użyciu właśnie przygotowanych zestawów danych.
Model sekwencyjny składa się z trzech bloków konwolucji ( tf.keras.layers.Conv2D ) z maksymalną warstwą puli ( tf.keras.layers.MaxPooling2D ) w każdym z nich. Istnieje w pełni połączona warstwa ( tf.keras.layers.Dense ) z 128 jednostkami na wierzchu, która jest aktywowana przez funkcję aktywacji ReLU ( 'relu' ). Ten model nie został w żaden sposób dostrojony — celem jest pokazanie mechaniki przy użyciu właśnie utworzonych zestawów danych. Aby dowiedzieć się więcej o klasyfikacji obrazów, zapoznaj się z samouczkiem dotyczącym klasyfikacji obrazów .
num_classes = 5
model = tf.keras.Sequential([
tf.keras.layers.Rescaling(1./255),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(num_classes)
])
Wybierz tf.keras.optimizers.Adam Optimizer i tf.keras.losses.SparseCategoricalCrossentropy funkcję utraty. Aby wyświetlić dokładność uczenia i walidacji dla każdej epoki uczenia, przekaż argument metrics do Model.compile .
model.compile(
optimizer='adam',
loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(
train_ds,
validation_data=val_ds,
epochs=3
)
Epoch 1/3 92/92 [==============================] - 4s 21ms/step - loss: 1.3091 - accuracy: 0.4281 - val_loss: 1.0982 - val_accuracy: 0.5599 Epoch 2/3 92/92 [==============================] - 1s 12ms/step - loss: 1.0196 - accuracy: 0.5879 - val_loss: 0.9572 - val_accuracy: 0.6213 Epoch 3/3 92/92 [==============================] - 1s 12ms/step - loss: 0.8455 - accuracy: 0.6775 - val_loss: 0.8839 - val_accuracy: 0.6512 <keras.callbacks.History at 0x7ff10c168850>
Możesz zauważyć, że dokładność walidacji jest niska w porównaniu z dokładnością treningu, co wskazuje na przesadne dopasowanie modelu. Możesz dowiedzieć się więcej o overfittingu i sposobach jego zmniejszenia w tym samouczku .
Używanie tf.data do lepszej kontroli
Powyższe narzędzie do przetwarzania wstępnego Keras — tf.keras.utils.image_dataset_from_directory — to wygodny sposób na utworzenie tf.data.Dataset z katalogu obrazów.
Aby uzyskać lepszą kontrolę ziarna, możesz napisać własny potok wejściowy za pomocą tf.data . Ta sekcja pokazuje, jak to zrobić, zaczynając od ścieżek plików z pobranego wcześniej pliku TGZ.
list_ds = tf.data.Dataset.list_files(str(data_dir/'*/*'), shuffle=False)
list_ds = list_ds.shuffle(image_count, reshuffle_each_iteration=False)
for f in list_ds.take(5):
print(f.numpy())
b'/home/kbuilder/.keras/datasets/flower_photos/roses/14267691818_301aceda07.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/daisy/2641151167_3bf1349606_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/6495554833_86eb8faa8e_n.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/tulips/4578030672_e6aefd45af.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/144686365_d7e96941ee_n.jpg'
Strukturę drzewa plików można wykorzystać do skompilowania listy class_names .
class_names = np.array(sorted([item.name for item in data_dir.glob('*') if item.name != "LICENSE.txt"]))
print(class_names)
['daisy' 'dandelion' 'roses' 'sunflowers' 'tulips']
Podziel zbiór danych na zbiory uczące i walidacyjne:
val_size = int(image_count * 0.2)
train_ds = list_ds.skip(val_size)
val_ds = list_ds.take(val_size)
Możesz wydrukować długość każdego zestawu danych w następujący sposób:
print(tf.data.experimental.cardinality(train_ds).numpy())
print(tf.data.experimental.cardinality(val_ds).numpy())
2936 734
Napisz krótką funkcję, która konwertuje ścieżkę pliku na parę (img, label) :
def get_label(file_path):
# Convert the path to a list of path components
parts = tf.strings.split(file_path, os.path.sep)
# The second to last is the class-directory
one_hot = parts[-2] == class_names
# Integer encode the label
return tf.argmax(one_hot)
def decode_img(img):
# Convert the compressed string to a 3D uint8 tensor
img = tf.io.decode_jpeg(img, channels=3)
# Resize the image to the desired size
return tf.image.resize(img, [img_height, img_width])
def process_path(file_path):
label = get_label(file_path)
# Load the raw data from the file as a string
img = tf.io.read_file(file_path)
img = decode_img(img)
return img, label
Użyj Dataset.map , aby utworzyć zestaw danych image, label :
# Set `num_parallel_calls` so multiple images are loaded/processed in parallel.
train_ds = train_ds.map(process_path, num_parallel_calls=AUTOTUNE)
val_ds = val_ds.map(process_path, num_parallel_calls=AUTOTUNE)
for image, label in train_ds.take(1):
print("Image shape: ", image.numpy().shape)
print("Label: ", label.numpy())
Image shape: (180, 180, 3) Label: 1
Skonfiguruj zbiór danych pod kątem wydajności
Aby wytrenować model z tym zestawem danych, potrzebujesz danych:
- Być dobrze przetasowanym.
- Do grupowania.
- Partie mają być dostępne jak najszybciej.
Te funkcje można dodać za pomocą interfejsu API tf.data . Aby uzyskać więcej informacji, odwiedź przewodnik dotyczący wydajności potoku danych wejściowych .
def configure_for_performance(ds):
ds = ds.cache()
ds = ds.shuffle(buffer_size=1000)
ds = ds.batch(batch_size)
ds = ds.prefetch(buffer_size=AUTOTUNE)
return ds
train_ds = configure_for_performance(train_ds)
val_ds = configure_for_performance(val_ds)
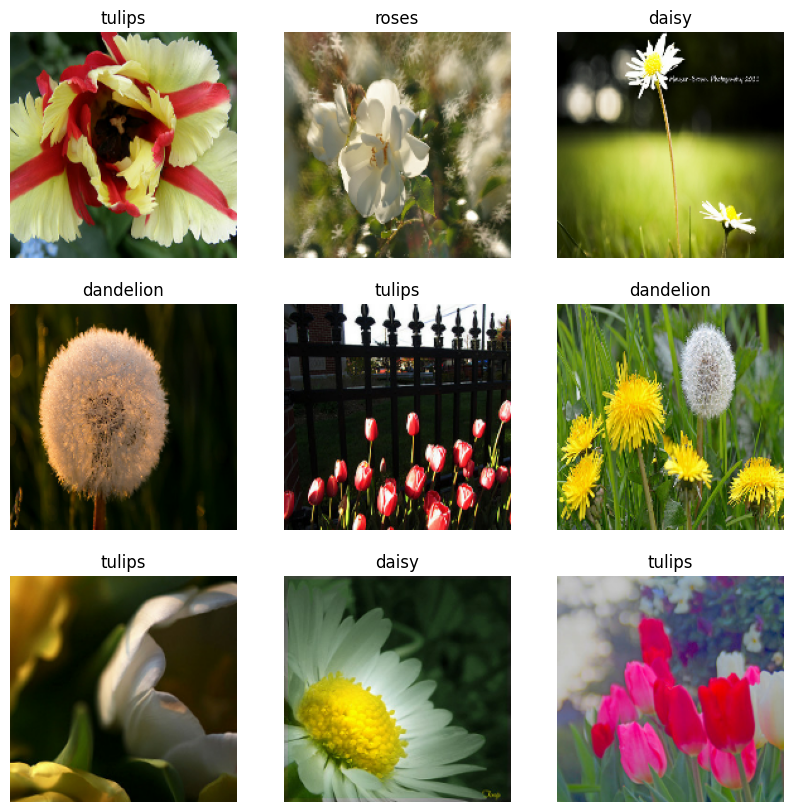
Wizualizuj dane
Możesz wizualizować ten zbiór danych podobnie do tego, który utworzyłeś wcześniej:
image_batch, label_batch = next(iter(train_ds))
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image_batch[i].numpy().astype("uint8"))
label = label_batch[i]
plt.title(class_names[label])
plt.axis("off")
2022-01-26 06:29:45.209901: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
Kontynuuj szkolenie modelu
Teraz ręcznie zbudowałeś podobny tf.data.Dataset do tego utworzonego przez tf.keras.utils.image_dataset_from_directory powyżej. Za jego pomocą możesz dalej trenować model. Tak jak poprzednio, będziesz trenować tylko przez kilka epok, aby czas biegu był krótki.
model.fit(
train_ds,
validation_data=val_ds,
epochs=3
)
Epoch 1/3 92/92 [==============================] - 3s 21ms/step - loss: 0.7305 - accuracy: 0.7245 - val_loss: 0.7311 - val_accuracy: 0.7139 Epoch 2/3 92/92 [==============================] - 1s 13ms/step - loss: 0.5279 - accuracy: 0.8069 - val_loss: 0.7021 - val_accuracy: 0.7316 Epoch 3/3 92/92 [==============================] - 1s 13ms/step - loss: 0.3739 - accuracy: 0.8644 - val_loss: 0.8266 - val_accuracy: 0.6948 <keras.callbacks.History at 0x7ff0ee071f10>
Korzystanie ze zbiorów danych TensorFlow
Jak dotąd ten samouczek koncentrował się na ładowaniu danych z dysku. Zestaw danych do użycia można również znaleźć, przeglądając obszerny katalog łatwych do pobrania zestawów danych w TensorFlow Datasets .
Ponieważ wcześniej załadowałeś zestaw danych Flowers z dysku, zaimportujmy go teraz za pomocą zestawów danych TensorFlow.
Pobierz zestaw danych Flowers za pomocą zestawów danych TensorFlow:
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
Zbiór danych o kwiatach ma pięć klas:
num_classes = metadata.features['label'].num_classes
print(num_classes)
5
Pobierz obraz z zestawu danych:
get_label_name = metadata.features['label'].int2str
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 06:29:54.281352: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

Tak jak poprzednio, pamiętaj, aby wsadowo, tasować i konfigurować zestawy uczące, walidacyjne i testowe pod kątem wydajności:
train_ds = configure_for_performance(train_ds)
val_ds = configure_for_performance(val_ds)
test_ds = configure_for_performance(test_ds)
Pełny przykład pracy z zestawem danych Flowers i zestawami danych TensorFlow można znaleźć w samouczku dotyczącym rozszerzania danych .
Następne kroki
Ten samouczek pokazał dwa sposoby ładowania obrazów z dysku. Po pierwsze, dowiedziałeś się, jak ładować i wstępnie przetwarzać zestaw danych obrazu za pomocą warstw i narzędzi przetwarzania wstępnego Keras. Następnie nauczyłeś się pisać od podstaw potok wejściowy za pomocą tf.data . Wreszcie dowiedziałeś się, jak pobrać zestaw danych z zestawów danych TensorFlow.
Kolejne kroki:
- Możesz dowiedzieć się , jak dodać rozszerzenie danych .
- Aby dowiedzieć się więcej o
tf.data, możesz odwiedzić przewodnik tf.data: Budowanie potoków wejściowych TensorFlow .