
| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
يوضح هذا البرنامج التعليمي كيفية تحميل مجموعة بيانات الصورة ومعالجتها مسبقًا بثلاث طرق:
- أولاً ، ستستخدم أدوات معالجة مسبقة عالية المستوى من Keras (مثل
tf.keras.utils.image_dataset_from_directory) والطبقات (مثلtf.keras.layers.Rescaling) لقراءة دليل للصور على القرص. - بعد ذلك ، ستكتب خط أنابيب الإدخال الخاص بك من البداية باستخدام tf.data .
- أخيرًا ، ستقوم بتنزيل مجموعة بيانات من الكتالوج الكبير المتاح في مجموعات بيانات TensorFlow .
يثبت
import numpy as np
import os
import PIL
import PIL.Image
import tensorflow as tf
import tensorflow_datasets as tfds
print(tf.__version__)
2.8.0-rc1
قم بتنزيل مجموعة بيانات الزهور
يستخدم هذا البرنامج التعليمي مجموعة بيانات من عدة آلاف من صور الزهور. تحتوي مجموعة بيانات الزهور على خمسة أدلة فرعية ، واحد لكل فصل:
flowers_photos/
daisy/
dandelion/
roses/
sunflowers/
tulips/
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file(origin=dataset_url,
fname='flower_photos',
untar=True)
data_dir = pathlib.Path(data_dir)
بعد تنزيل (218 ميجابايت) ، يجب أن يكون لديك الآن نسخة من صور الزهور المتاحة. هناك 3670 صورة إجمالية:
image_count = len(list(data_dir.glob('*/*.jpg')))
print(image_count)
3670
يحتوي كل دليل على صور من هذا النوع من الزهور. إليك بعض الورود:
roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[0]))

roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[1]))

تحميل البيانات باستخدام أداة Keras
لنقم بتحميل هذه الصور من القرص باستخدام الأداة المساعدة tf.keras.utils.image_dataset_from_directory .
أنشئ مجموعة بيانات
حدد بعض المعلمات للمحمل:
batch_size = 32
img_height = 180
img_width = 180
من الممارسات الجيدة استخدام تقسيم التحقق عند تطوير نموذجك. ستستخدم 80٪ من الصور للتدريب و 20٪ للتحقق.
train_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 2936 files for training.
val_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 734 files for validation.
يمكنك العثور على أسماء الفئات في سمة class_names في مجموعات البيانات هذه.
class_names = train_ds.class_names
print(class_names)
['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']
تصور البيانات
فيما يلي الصور التسع الأولى من مجموعة بيانات التدريب.
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
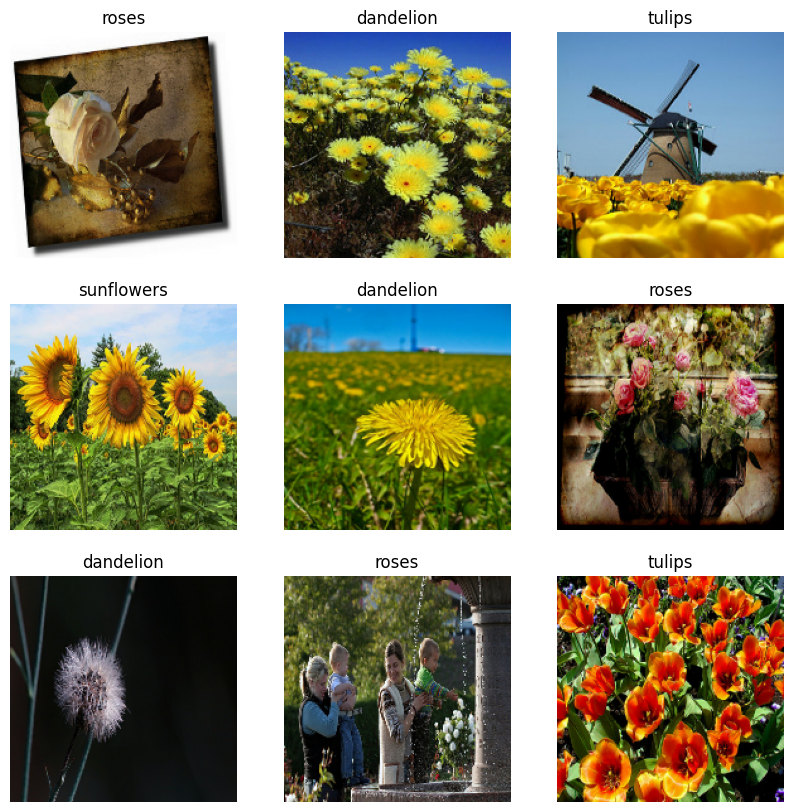
يمكنك تدريب نموذج باستخدام مجموعات البيانات هذه عن طريق تمريرها إلى model.fit (كما هو موضح لاحقًا في هذا البرنامج التعليمي). إذا كنت ترغب في ذلك ، يمكنك أيضًا التكرار يدويًا عبر مجموعة البيانات واسترداد مجموعات الصور:
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
(32, 180, 180, 3) (32,)
image_batch هو موتر للشكل (32, 180, 180, 3) . هذه دفعة من 32 صورة للشكل 180x180x3 (يشير البعد الأخير إلى قنوات الألوان RGB). label_batch هي موتر للشكل (32,) ، هذه تسميات مطابقة للصور الـ 32.
يمكنك استدعاء .numpy() على أي من هذه الموترات لتحويلها إلى numpy.ndarray .
توحيد البيانات
قيم قناة RGB تقع في النطاق [0, 255] . هذا ليس مثاليًا للشبكة العصبية ؛ بشكل عام يجب أن تسعى إلى جعل قيم المدخلات الخاصة بك صغيرة.
هنا ، ستقوم بتوحيد القيم لتكون في النطاق [0, 1] باستخدام tf.keras.layers.Rescaling :
normalization_layer = tf.keras.layers.Rescaling(1./255)
هناك طريقتان لاستخدام هذه الطبقة. يمكنك تطبيقه على مجموعة البيانات عن طريق استدعاء Dataset.map :
normalized_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(normalized_ds))
first_image = image_batch[0]
# Notice the pixel values are now in `[0,1]`.
print(np.min(first_image), np.max(first_image))
0.0 0.96902645
أو يمكنك تضمين الطبقة داخل تعريف النموذج لتبسيط عملية النشر. ستستخدم الطريقة الثانية هنا.
تكوين مجموعة البيانات للأداء
دعنا نتأكد من استخدام الجلب المسبق المخزن حتى تتمكن من إنتاج البيانات من القرص دون أن يصبح الإدخال / الإخراج محظورًا. هاتان طريقتان مهمتان يجب عليك استخدامهما عند تحميل البيانات:
- يحتفظ
Dataset.cacheبالصور في الذاكرة بعد تحميلها خارج القرص خلال المرحلة الأولى. سيضمن ذلك عدم تحول مجموعة البيانات إلى عنق زجاجة أثناء تدريب نموذجك. إذا كانت مجموعة البيانات الخاصة بك كبيرة جدًا بحيث لا يمكن وضعها في الذاكرة ، فيمكنك أيضًا استخدام هذه الطريقة لإنشاء ذاكرة تخزين مؤقت على القرص. -
Dataset.prefetchيتداخل مع المعالجة المسبقة للبيانات وتنفيذ النموذج أثناء التدريب.
يمكن للقراء المهتمين معرفة المزيد حول كلتا الطريقتين ، بالإضافة إلى كيفية تخزين البيانات مؤقتًا على القرص في قسم الجلب المسبق للأداء الأفضل باستخدام دليل tf.data API .
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
تدريب نموذج
للتأكد من اكتمالها ، سوف توضح كيفية تدريب نموذج بسيط باستخدام مجموعات البيانات التي أعددتها للتو.
يتكون النموذج التسلسلي من ثلاث كتل التفاف ( tf.keras.layers.Conv2D ) مع أقصى طبقة تجميع ( tf.keras.layers.MaxPooling2D ) في كل منها. هناك طبقة متصلة بالكامل ( tf.keras.layers.Dense ) مع 128 وحدة فوقها يتم تنشيطها بواسطة وظيفة تنشيط ReLU ( 'relu' ). لم يتم ضبط هذا النموذج بأي شكل من الأشكال - الهدف هو إظهار الآليات التي تستخدم مجموعات البيانات التي أنشأتها للتو. لمعرفة المزيد حول تصنيف الصور ، قم بزيارة البرنامج التعليمي لتصنيف الصور .
num_classes = 5
model = tf.keras.Sequential([
tf.keras.layers.Rescaling(1./255),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(32, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(num_classes)
])
اختر وظيفة محسن tf.keras.optimizers.Adam و tf.keras.losses.SparseCategoricalCrossentropy . لعرض دقة التدريب والتحقق من الصحة لكل فترة تدريب ، قم بتمرير وسيطة metrics إلى Model.compile .
model.compile(
optimizer='adam',
loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(
train_ds,
validation_data=val_ds,
epochs=3
)
Epoch 1/3 92/92 [==============================] - 4s 21ms/step - loss: 1.3091 - accuracy: 0.4281 - val_loss: 1.0982 - val_accuracy: 0.5599 Epoch 2/3 92/92 [==============================] - 1s 12ms/step - loss: 1.0196 - accuracy: 0.5879 - val_loss: 0.9572 - val_accuracy: 0.6213 Epoch 3/3 92/92 [==============================] - 1s 12ms/step - loss: 0.8455 - accuracy: 0.6775 - val_loss: 0.8839 - val_accuracy: 0.6512 <keras.callbacks.History at 0x7ff10c168850>
قد تلاحظ أن دقة التحقق منخفضة مقارنةً بدقة التدريب ، مما يشير إلى أن نموذجك يتناسب بشكل زائد. يمكنك معرفة المزيد حول التجهيز الزائد وكيفية تقليله في هذا البرنامج التعليمي .
استخدام tf.data للتحكم الدقيق
تعتبر أداة Keras السابقة للمعالجة المسبقة - tf.keras.utils.image_dataset_from_directory - طريقة ملائمة لإنشاء tf.data.Dataset من دليل للصور.
للتحكم الدقيق في الحبوب ، يمكنك كتابة خط أنابيب الإدخال الخاص بك باستخدام tf.data . يوضح هذا القسم كيفية القيام بذلك ، بدءًا من مسارات الملفات من ملف TGZ الذي قمت بتنزيله مسبقًا.
list_ds = tf.data.Dataset.list_files(str(data_dir/'*/*'), shuffle=False)
list_ds = list_ds.shuffle(image_count, reshuffle_each_iteration=False)
for f in list_ds.take(5):
print(f.numpy())
b'/home/kbuilder/.keras/datasets/flower_photos/roses/14267691818_301aceda07.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/daisy/2641151167_3bf1349606_m.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/sunflowers/6495554833_86eb8faa8e_n.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/tulips/4578030672_e6aefd45af.jpg' b'/home/kbuilder/.keras/datasets/flower_photos/dandelion/144686365_d7e96941ee_n.jpg'
يمكن استخدام هيكل الشجرة للملفات لتجميع قائمة class_names .
class_names = np.array(sorted([item.name for item in data_dir.glob('*') if item.name != "LICENSE.txt"]))
print(class_names)
['daisy' 'dandelion' 'roses' 'sunflowers' 'tulips']
قسّم مجموعة البيانات إلى مجموعات تدريب وتحقق:
val_size = int(image_count * 0.2)
train_ds = list_ds.skip(val_size)
val_ds = list_ds.take(val_size)
يمكنك طباعة طول كل مجموعة بيانات على النحو التالي:
print(tf.data.experimental.cardinality(train_ds).numpy())
print(tf.data.experimental.cardinality(val_ds).numpy())
2936 734
اكتب دالة قصيرة تحول مسار ملف إلى زوج (img, label) :
def get_label(file_path):
# Convert the path to a list of path components
parts = tf.strings.split(file_path, os.path.sep)
# The second to last is the class-directory
one_hot = parts[-2] == class_names
# Integer encode the label
return tf.argmax(one_hot)
def decode_img(img):
# Convert the compressed string to a 3D uint8 tensor
img = tf.io.decode_jpeg(img, channels=3)
# Resize the image to the desired size
return tf.image.resize(img, [img_height, img_width])
def process_path(file_path):
label = get_label(file_path)
# Load the raw data from the file as a string
img = tf.io.read_file(file_path)
img = decode_img(img)
return img, label
استخدم Dataset.map لإنشاء مجموعة بيانات image, label :
# Set `num_parallel_calls` so multiple images are loaded/processed in parallel.
train_ds = train_ds.map(process_path, num_parallel_calls=AUTOTUNE)
val_ds = val_ds.map(process_path, num_parallel_calls=AUTOTUNE)
for image, label in train_ds.take(1):
print("Image shape: ", image.numpy().shape)
print("Label: ", label.numpy())
Image shape: (180, 180, 3) Label: 1
تكوين مجموعة البيانات للأداء
لتدريب نموذج باستخدام مجموعة البيانات هذه ، ستحتاج إلى البيانات:
- ليتم خلطها بشكل جيد.
- على دفعات.
- ستكون الدُفعات متاحة في أقرب وقت ممكن.
يمكن إضافة هذه الميزات باستخدام tf.data API. لمزيد من التفاصيل ، قم بزيارة دليل أداء خط أنابيب الإدخال .
def configure_for_performance(ds):
ds = ds.cache()
ds = ds.shuffle(buffer_size=1000)
ds = ds.batch(batch_size)
ds = ds.prefetch(buffer_size=AUTOTUNE)
return ds
train_ds = configure_for_performance(train_ds)
val_ds = configure_for_performance(val_ds)
تصور البيانات
يمكنك تصور مجموعة البيانات هذه بشكل مشابه لتلك التي قمت بإنشائها مسبقًا:
image_batch, label_batch = next(iter(train_ds))
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image_batch[i].numpy().astype("uint8"))
label = label_batch[i]
plt.title(class_names[label])
plt.axis("off")
2022-01-26 06:29:45.209901: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
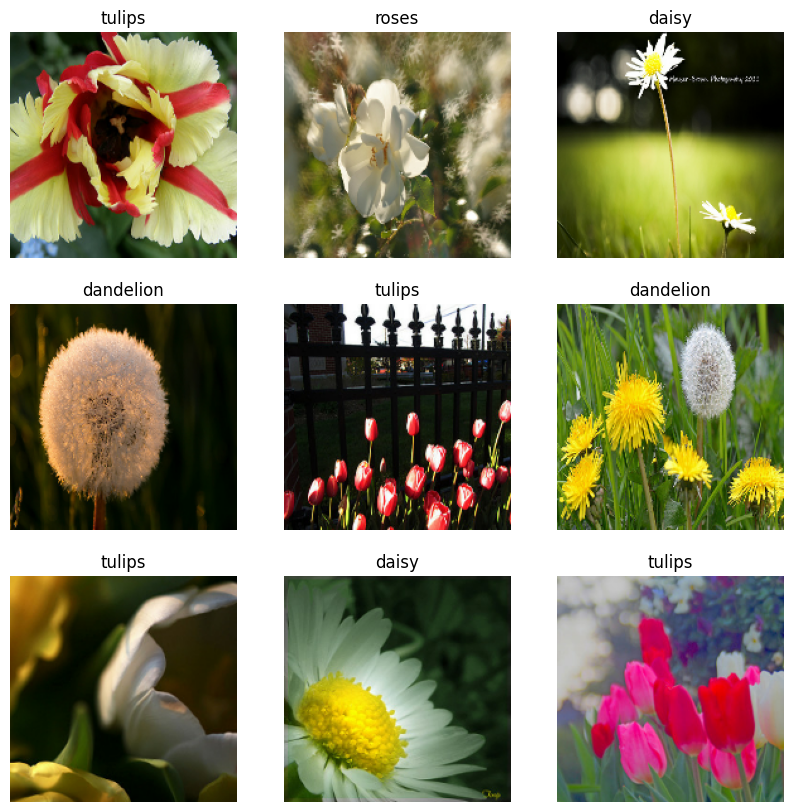
استمر في تدريب النموذج
لقد قمت الآن بإنشاء tf.data.Dataset مشابه يدويًا لتلك التي تم إنشاؤها بواسطة tf.keras.utils.image_dataset_from_directory أعلاه. يمكنك متابعة تدريب النموذج به. كما كان من قبل ، سوف تتدرب على فترات قليلة فقط لجعل وقت الجري قصيرًا.
model.fit(
train_ds,
validation_data=val_ds,
epochs=3
)
Epoch 1/3 92/92 [==============================] - 3s 21ms/step - loss: 0.7305 - accuracy: 0.7245 - val_loss: 0.7311 - val_accuracy: 0.7139 Epoch 2/3 92/92 [==============================] - 1s 13ms/step - loss: 0.5279 - accuracy: 0.8069 - val_loss: 0.7021 - val_accuracy: 0.7316 Epoch 3/3 92/92 [==============================] - 1s 13ms/step - loss: 0.3739 - accuracy: 0.8644 - val_loss: 0.8266 - val_accuracy: 0.6948 <keras.callbacks.History at 0x7ff0ee071f10>
استخدام مجموعات بيانات TensorFlow
حتى الآن ، ركز هذا البرنامج التعليمي على تحميل البيانات من القرص. يمكنك أيضًا العثور على مجموعة بيانات لاستخدامها من خلال استكشاف الكتالوج الكبير لمجموعات البيانات سهلة التنزيل في مجموعات بيانات TensorFlow .
نظرًا لأنك قمت مسبقًا بتحميل مجموعة بيانات الزهور من القرص ، فلنقم الآن باستيرادها باستخدام مجموعات بيانات TensorFlow.
قم بتنزيل مجموعة بيانات الزهور باستخدام مجموعات بيانات TensorFlow:
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
تتكون مجموعة بيانات الزهور من خمس فئات:
num_classes = metadata.features['label'].num_classes
print(num_classes)
5
استرجع صورة من مجموعة البيانات:
get_label_name = metadata.features['label'].int2str
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 06:29:54.281352: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

كما كان من قبل ، تذكر تجميع مجموعات التدريب والتحقق والاختبار للأداء وتعديلها عشوائيًا وتكوينها:
train_ds = configure_for_performance(train_ds)
val_ds = configure_for_performance(val_ds)
test_ds = configure_for_performance(test_ds)
يمكنك العثور على مثال كامل للعمل مع مجموعة بيانات Flowers و TensorFlow Datasets من خلال زيارة البرنامج التعليمي لزيادة البيانات .
الخطوات التالية
أظهر هذا البرنامج التعليمي طريقتين لتحميل الصور من القرص. أولاً ، تعلمت كيفية تحميل مجموعة بيانات الصورة ومعالجتها مسبقًا باستخدام طبقات وأدوات معالجة Keras المسبقة. بعد ذلك ، تعلمت كيفية كتابة مسار إدخال من البداية باستخدام tf.data . أخيرًا ، تعلمت كيفية تنزيل مجموعة بيانات من مجموعات بيانات TensorFlow.
لخطواتك التالية:
- يمكنك معرفة كيفية إضافة البيانات المعززة .
- لمعرفة المزيد حول
tf.data، يمكنك زيارة tf.data: دليل إنشاء خطوط أنابيب الإدخال TensorFlow .