
| | |  Ver fuente en GitHub Ver fuente en GitHub |
Este tutorial proporciona ejemplos de cómo usar datos CSV con TensorFlow.
Hay dos partes principales en esto:
- Cargando los datos fuera del disco
- Preprocesarlo en una forma adecuada para el entrenamiento.
Este tutorial se centra en la carga y ofrece algunos ejemplos rápidos de preprocesamiento. Para ver un tutorial que se centra en el aspecto del preprocesamiento, consulte la guía y el tutorial de capas de preprocesamiento .
Configuración
import pandas as pd
import numpy as np
# Make numpy values easier to read.
np.set_printoptions(precision=3, suppress=True)
import tensorflow as tf
from tensorflow.keras import layers
En datos de memoria
Para cualquier conjunto de datos CSV pequeño, la forma más sencilla de entrenar un modelo de TensorFlow en él es cargarlo en la memoria como un marco de datos de pandas o una matriz NumPy.
Un ejemplo relativamente simple es el conjunto de datos de abulón .
- El conjunto de datos es pequeño.
- Todas las entidades de entrada son valores de punto flotante de rango limitado.
Aquí se explica cómo descargar los datos en un Pandas DataFrame :
abalone_train = pd.read_csv(
"https://storage.googleapis.com/download.tensorflow.org/data/abalone_train.csv",
names=["Length", "Diameter", "Height", "Whole weight", "Shucked weight",
"Viscera weight", "Shell weight", "Age"])
abalone_train.head()
El conjunto de datos contiene un conjunto de medidas de abulón , un tipo de caracol de mar.

“Concha de abulón” (por Nicki Dugan Pogue , CC BY-SA 2.0)
La tarea nominal de este conjunto de datos es predecir la edad a partir de las otras medidas, así que separe las características y las etiquetas para el entrenamiento:
abalone_features = abalone_train.copy()
abalone_labels = abalone_features.pop('Age')
Para este conjunto de datos, tratará todas las características de manera idéntica. Empaque las características en una sola matriz NumPy.:
abalone_features = np.array(abalone_features)
abalone_features
array([[0.435, 0.335, 0.11 , ..., 0.136, 0.077, 0.097],
[0.585, 0.45 , 0.125, ..., 0.354, 0.207, 0.225],
[0.655, 0.51 , 0.16 , ..., 0.396, 0.282, 0.37 ],
...,
[0.53 , 0.42 , 0.13 , ..., 0.374, 0.167, 0.249],
[0.395, 0.315, 0.105, ..., 0.118, 0.091, 0.119],
[0.45 , 0.355, 0.12 , ..., 0.115, 0.067, 0.16 ]])
A continuación, haga un modelo de regresión para predecir la edad. Dado que solo hay un tensor de entrada único, un modelo keras.Sequential es suficiente aquí.
abalone_model = tf.keras.Sequential([
layers.Dense(64),
layers.Dense(1)
])
abalone_model.compile(loss = tf.losses.MeanSquaredError(),
optimizer = tf.optimizers.Adam())
Para entrenar ese modelo, pase las características y las etiquetas a Model.fit :
abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 104/104 [==============================] - 1s 2ms/step - loss: 63.0446 Epoch 2/10 104/104 [==============================] - 0s 2ms/step - loss: 11.9429 Epoch 3/10 104/104 [==============================] - 0s 2ms/step - loss: 8.4836 Epoch 4/10 104/104 [==============================] - 0s 2ms/step - loss: 8.0052 Epoch 5/10 104/104 [==============================] - 0s 2ms/step - loss: 7.6073 Epoch 6/10 104/104 [==============================] - 0s 2ms/step - loss: 7.2485 Epoch 7/10 104/104 [==============================] - 0s 2ms/step - loss: 6.9883 Epoch 8/10 104/104 [==============================] - 0s 2ms/step - loss: 6.7977 Epoch 9/10 104/104 [==============================] - 0s 2ms/step - loss: 6.6477 Epoch 10/10 104/104 [==============================] - 0s 2ms/step - loss: 6.5359 <keras.callbacks.History at 0x7f70543c7350>
Acaba de ver la forma más básica de entrenar un modelo utilizando datos CSV. A continuación, aprenderá a aplicar el preprocesamiento para normalizar columnas numéricas.
Preprocesamiento básico
Es una buena práctica normalizar las entradas a su modelo. Las capas de preprocesamiento de Keras brindan una forma conveniente de incorporar esta normalización en su modelo.
La capa calculará previamente la media y la varianza de cada columna y las utilizará para normalizar los datos.
Primero creas la capa:
normalize = layers.Normalization()
Luego usa el método Normalization.adapt() para adaptar la capa de normalización a sus datos.
normalize.adapt(abalone_features)
Luego use la capa de normalización en su modelo:
norm_abalone_model = tf.keras.Sequential([
normalize,
layers.Dense(64),
layers.Dense(1)
])
norm_abalone_model.compile(loss = tf.losses.MeanSquaredError(),
optimizer = tf.optimizers.Adam())
norm_abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 104/104 [==============================] - 0s 2ms/step - loss: 92.5851 Epoch 2/10 104/104 [==============================] - 0s 2ms/step - loss: 55.1199 Epoch 3/10 104/104 [==============================] - 0s 2ms/step - loss: 18.2937 Epoch 4/10 104/104 [==============================] - 0s 2ms/step - loss: 6.2633 Epoch 5/10 104/104 [==============================] - 0s 2ms/step - loss: 5.1257 Epoch 6/10 104/104 [==============================] - 0s 2ms/step - loss: 5.0217 Epoch 7/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9775 Epoch 8/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9730 Epoch 9/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9348 Epoch 10/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9416 <keras.callbacks.History at 0x7f70541b2a50>
Tipos de datos mixtos
El conjunto de datos "Titanic" contiene información sobre los pasajeros del Titanic. La tarea nominal en este conjunto de datos es predecir quién sobrevivió.

Imagen de Wikimedia
{kind=link}
Los datos sin procesar se pueden cargar fácilmente como Pandas DataFrame , pero no se pueden usar de inmediato como entrada para un modelo de TensorFlow.
titanic = pd.read_csv("https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic.head()
titanic_features = titanic.copy()
titanic_labels = titanic_features.pop('survived')
Debido a los diferentes tipos y rangos de datos, no puede simplemente apilar las funciones en la matriz NumPy y pasarla a un modelo keras.Sequential . Cada columna debe manejarse individualmente.
Como una opción, podría preprocesar sus datos sin conexión (usando cualquier herramienta que desee) para convertir columnas categóricas en columnas numéricas y luego pasar la salida procesada a su modelo de TensorFlow. La desventaja de ese enfoque es que si guarda y exporta su modelo, el preprocesamiento no se guarda con él. Las capas de preprocesamiento de Keras evitan este problema porque son parte del modelo.
En este ejemplo, creará un modelo que implementa la lógica de preprocesamiento mediante la API funcional de Keras . También podrías hacerlo subclasificando .
La API funcional opera sobre tensores "simbólicos". Los tensores "ansiosos" normales tienen un valor. Por el contrario, estos tensores "simbólicos" no lo hacen. En cambio, realizan un seguimiento de las operaciones que se ejecutan en ellos y crean una representación del cálculo, que puede ejecutar más tarde. He aquí un ejemplo rápido:
# Create a symbolic input
input = tf.keras.Input(shape=(), dtype=tf.float32)
# Perform a calculation using the input
result = 2*input + 1
# the result doesn't have a value
result
<KerasTensor: shape=(None,) dtype=float32 (created by layer 'tf.__operators__.add')>
calc = tf.keras.Model(inputs=input, outputs=result)
print(calc(1).numpy())
print(calc(2).numpy())
3.0 5.0
Para construir el modelo de preprocesamiento, comience por construir un conjunto de objetos keras.Input simbólicos, que coincidan con los nombres y tipos de datos de las columnas CSV.
inputs = {}
for name, column in titanic_features.items():
dtype = column.dtype
if dtype == object:
dtype = tf.string
else:
dtype = tf.float32
inputs[name] = tf.keras.Input(shape=(1,), name=name, dtype=dtype)
inputs
{'sex': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'sex')>,
'age': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'age')>,
'n_siblings_spouses': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'n_siblings_spouses')>,
'parch': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'parch')>,
'fare': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'fare')>,
'class': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'class')>,
'deck': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'deck')>,
'embark_town': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'embark_town')>,
'alone': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'alone')>}
El primer paso en su lógica de preprocesamiento es concatenar las entradas numéricas y ejecutarlas a través de una capa de normalización:
numeric_inputs = {name:input for name,input in inputs.items()
if input.dtype==tf.float32}
x = layers.Concatenate()(list(numeric_inputs.values()))
norm = layers.Normalization()
norm.adapt(np.array(titanic[numeric_inputs.keys()]))
all_numeric_inputs = norm(x)
all_numeric_inputs
<KerasTensor: shape=(None, 4) dtype=float32 (created by layer 'normalization_1')>
Recopile todos los resultados del preprocesamiento simbólico, para concatenarlos más tarde.
preprocessed_inputs = [all_numeric_inputs]
Para las entradas de cadenas, utilice la función tf.keras.layers.StringLookup para asignar cadenas a índices enteros en un vocabulario. A continuación, utilice tf.keras.layers.CategoryEncoding para convertir los índices en datos float32 apropiados para el modelo.
La configuración predeterminada para la capa tf.keras.layers.CategoryEncoding crea un vector único para cada entrada. Una capa. La layers.Embedding también funcionaría. Consulte la guía y el tutorial de capas de preprocesamiento para obtener más información sobre este tema.
for name, input in inputs.items():
if input.dtype == tf.float32:
continue
lookup = layers.StringLookup(vocabulary=np.unique(titanic_features[name]))
one_hot = layers.CategoryEncoding(max_tokens=lookup.vocab_size())
x = lookup(input)
x = one_hot(x)
preprocessed_inputs.append(x)
WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead.
Con la colección de inputs y las entradas processed_inputs , puede concatenar todas las entradas preprocesadas y crear un modelo que maneje el preprocesamiento:
preprocessed_inputs_cat = layers.Concatenate()(preprocessed_inputs)
titanic_preprocessing = tf.keras.Model(inputs, preprocessed_inputs_cat)
tf.keras.utils.plot_model(model = titanic_preprocessing , rankdir="LR", dpi=72, show_shapes=True)
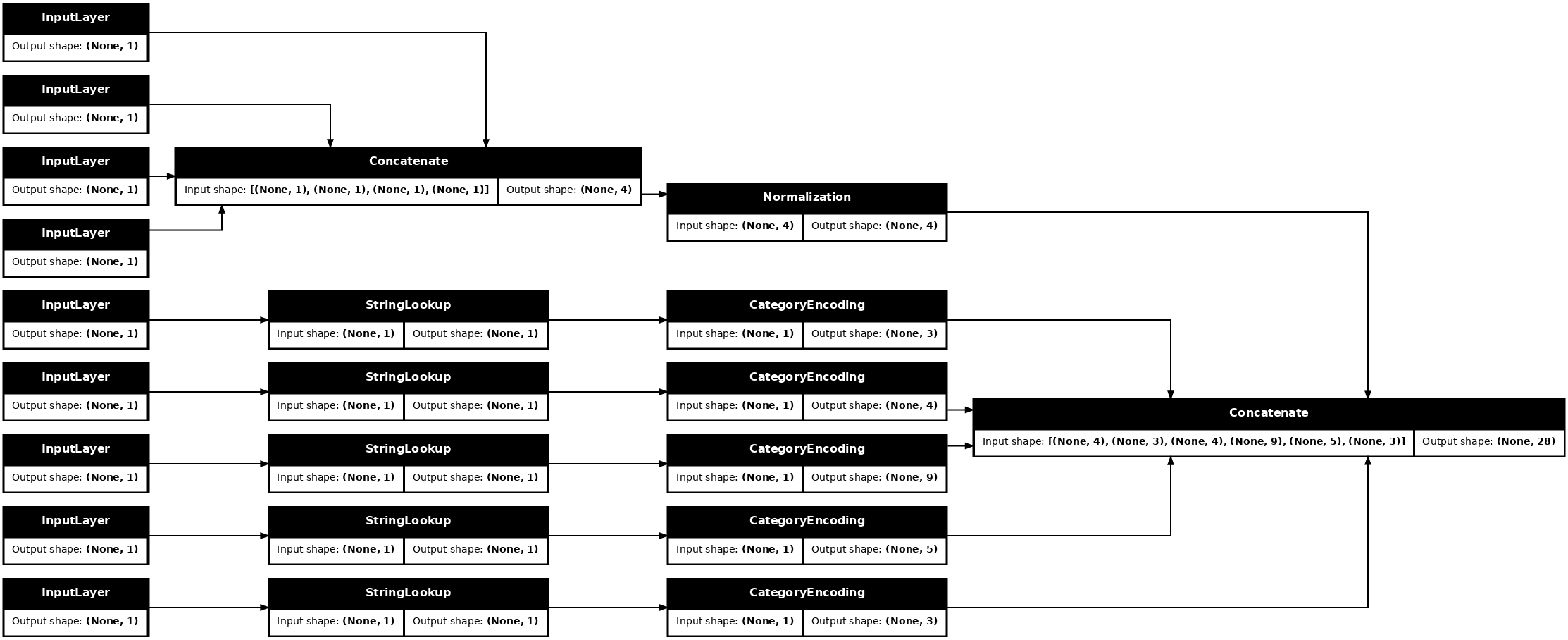
Este model solo contiene el preprocesamiento de entrada. Puede ejecutarlo para ver qué hace con sus datos. Los modelos de Keras no convierten automáticamente Pandas DataFrames porque no está claro si se debe convertir a un tensor o a un diccionario de tensores. Así que conviértelo en un diccionario de tensores:
titanic_features_dict = {name: np.array(value)
for name, value in titanic_features.items()}
Rebane el primer ejemplo de entrenamiento y páselo a este modelo de preprocesamiento, verá las características numéricas y la cadena one-hots todas concatenadas juntas:
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
titanic_preprocessing(features_dict)
<tf.Tensor: shape=(1, 28), dtype=float32, numpy=
array([[-0.61 , 0.395, -0.479, -0.497, 0. , 0. , 1. , 0. ,
0. , 0. , 1. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 1. , 0. , 0. , 0. , 1. ,
0. , 0. , 1. , 0. ]], dtype=float32)>
Ahora construye el modelo encima de esto:
def titanic_model(preprocessing_head, inputs):
body = tf.keras.Sequential([
layers.Dense(64),
layers.Dense(1)
])
preprocessed_inputs = preprocessing_head(inputs)
result = body(preprocessed_inputs)
model = tf.keras.Model(inputs, result)
model.compile(loss=tf.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.optimizers.Adam())
return model
titanic_model = titanic_model(titanic_preprocessing, inputs)
Cuando entrene el modelo, pase el diccionario de características como x y la etiqueta como y .
titanic_model.fit(x=titanic_features_dict, y=titanic_labels, epochs=10)
Epoch 1/10 20/20 [==============================] - 1s 4ms/step - loss: 0.8017 Epoch 2/10 20/20 [==============================] - 0s 4ms/step - loss: 0.5913 Epoch 3/10 20/20 [==============================] - 0s 5ms/step - loss: 0.5212 Epoch 4/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4841 Epoch 5/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4615 Epoch 6/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4470 Epoch 7/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4367 Epoch 8/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4304 Epoch 9/10 20/20 [==============================] - 0s 4ms/step - loss: 0.4265 Epoch 10/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4239 <keras.callbacks.History at 0x7f70b1f82a50>
Dado que el procesamiento previo es parte del modelo, puede guardar el modelo y volver a cargarlo en otro lugar y obtener resultados idénticos:
titanic_model.save('test')
reloaded = tf.keras.models.load_model('test')
2022-01-26 06:36:18.822459: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: test/assets
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
before = titanic_model(features_dict)
after = reloaded(features_dict)
assert (before-after)<1e-3
print(before)
print(after)
tf.Tensor([[-1.791]], shape=(1, 1), dtype=float32) tf.Tensor([[-1.791]], shape=(1, 1), dtype=float32)
Usando tf.data
En la sección anterior, se basó en la combinación y el procesamiento por lotes de datos integrados del modelo mientras entrenaba el modelo.
Si necesita más control sobre la canalización de datos de entrada o necesita usar datos que no caben fácilmente en la memoria: use tf.data .
Para obtener más ejemplos, consulte la guía tf.data .
En los datos de la memoria
Como primer ejemplo de cómo aplicar tf.data a datos CSV, considere el siguiente código para dividir manualmente el diccionario de características de la sección anterior. Para cada índice, toma ese índice para cada función:
import itertools
def slices(features):
for i in itertools.count():
# For each feature take index `i`
example = {name:values[i] for name, values in features.items()}
yield example
Ejecuta esto e imprime el primer ejemplo:
for example in slices(titanic_features_dict):
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : male age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : Third deck : unknown embark_town : Southampton alone : n
El tf.data.Dataset más básico en el cargador de datos de memoria es el constructor Dataset.from_tensor_slices . Esto devuelve un tf.data.Dataset que implementa una versión generalizada de la función de slices anterior, en TensorFlow.
features_ds = tf.data.Dataset.from_tensor_slices(titanic_features_dict)
Puede iterar sobre un tf.data.Dataset como cualquier otro iterable de Python:
for example in features_ds:
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : b'male' age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : b'Third' deck : b'unknown' embark_town : b'Southampton' alone : b'n'
La función from_tensor_slices puede manejar cualquier estructura de diccionarios anidados o tuplas. El siguiente código crea un conjunto de datos de (features_dict, labels) pares:
titanic_ds = tf.data.Dataset.from_tensor_slices((titanic_features_dict, titanic_labels))
Para entrenar un modelo con este conjunto de Dataset , deberá al menos shuffle y procesar por batch los datos.
titanic_batches = titanic_ds.shuffle(len(titanic_labels)).batch(32)
En lugar de pasar features y labels a Model.fit , pasa el conjunto de datos:
titanic_model.fit(titanic_batches, epochs=5)
Epoch 1/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4230 Epoch 2/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4216 Epoch 3/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4203 Epoch 4/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4198 Epoch 5/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4194 <keras.callbacks.History at 0x7f70b12485d0>
De un solo archivo
Hasta ahora, este tutorial ha funcionado con datos en memoria. tf.data es un conjunto de herramientas altamente escalable para construir canalizaciones de datos y proporciona algunas funciones para manejar la carga de archivos CSV.
titanic_file_path = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
Downloading data from https://storage.googleapis.com/tf-datasets/titanic/train.csv 32768/30874 [===============================] - 0s 0us/step 40960/30874 [=======================================] - 0s 0us/step
Ahora lea los datos CSV del archivo y cree un tf.data.Dataset .
(Para obtener la documentación completa, consulte tf.data.experimental.make_csv_dataset )
titanic_csv_ds = tf.data.experimental.make_csv_dataset(
titanic_file_path,
batch_size=5, # Artificially small to make examples easier to show.
label_name='survived',
num_epochs=1,
ignore_errors=True,)
Esta función incluye muchas características convenientes para que sea fácil trabajar con los datos. Esto incluye:
- Uso de los encabezados de columna como claves de diccionario.
- Determinando automáticamente el tipo de cada columna.
for batch, label in titanic_csv_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value}")
print()
print(f"{'label':20s}: {label}")
sex : [b'male' b'male' b'female' b'male' b'male'] age : [27. 18. 15. 46. 50.] n_siblings_spouses : [0 0 0 1 0] parch : [0 0 0 0 0] fare : [ 7.896 7.796 7.225 61.175 13. ] class : [b'Third' b'Third' b'Third' b'First' b'Second'] deck : [b'unknown' b'unknown' b'unknown' b'E' b'unknown'] embark_town : [b'Southampton' b'Southampton' b'Cherbourg' b'Southampton' b'Southampton'] alone : [b'y' b'y' b'y' b'n' b'y'] label : [0 0 1 0 0]
También puede descomprimir los datos sobre la marcha. Aquí hay un archivo CSV comprimido con gzip que contiene el conjunto de datos de tráfico interestatal metropolitano

Imagen de Wikimedia
{kind=link}
traffic_volume_csv_gz = tf.keras.utils.get_file(
'Metro_Interstate_Traffic_Volume.csv.gz',
"https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz",
cache_dir='.', cache_subdir='traffic')
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz 409600/405373 [==============================] - 1s 1us/step 417792/405373 [==============================] - 1s 1us/step
Configure el argumento compression_type para leer directamente desde el archivo comprimido:
traffic_volume_csv_gz_ds = tf.data.experimental.make_csv_dataset(
traffic_volume_csv_gz,
batch_size=256,
label_name='traffic_volume',
num_epochs=1,
compression_type="GZIP")
for batch, label in traffic_volume_csv_gz_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value[:5]}")
print()
print(f"{'label':20s}: {label[:5]}")
holiday : [b'None' b'None' b'None' b'None' b'None'] temp : [280.56 266.79 281.64 292.71 270.48] rain_1h : [0. 0. 0. 0. 0.] snow_1h : [0. 0. 0. 0. 0.] clouds_all : [46 90 90 0 64] weather_main : [b'Clear' b'Clouds' b'Mist' b'Clear' b'Clouds'] weather_description : [b'sky is clear' b'overcast clouds' b'mist' b'Sky is Clear' b'broken clouds'] date_time : [b'2012-11-05 20:00:00' b'2012-12-17 23:00:00' b'2013-10-06 19:00:00' b'2013-08-23 22:00:00' b'2013-11-11 05:00:00'] label : [2415 966 3459 2633 2576]
almacenamiento en caché
Hay algunos gastos generales para analizar los datos csv. Para modelos pequeños, esto puede ser un cuello de botella en el entrenamiento.
Dependiendo de su caso de uso, puede ser una buena idea usar Dataset.cache o data.experimental.snapshot para que los datos csv solo se analicen en la primera época.
La principal diferencia entre los métodos de cache e snapshot es que los archivos de cache solo pueden ser utilizados por el proceso de TensorFlow que los creó, pero otros procesos pueden leer los archivos de snapshot .
Por ejemplo, iterar sobre traffic_volume_csv_gz_ds 20 veces toma ~15 segundos sin almacenamiento en caché, o ~2 segundos con almacenamiento en caché.
%%time
for i, (batch, label) in enumerate(traffic_volume_csv_gz_ds.repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 14.9 s, sys: 3.7 s, total: 18.6 s Wall time: 11.2 s
%%time
caching = traffic_volume_csv_gz_ds.cache().shuffle(1000)
for i, (batch, label) in enumerate(caching.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 1.43 s, sys: 173 ms, total: 1.6 s Wall time: 1.28 s
%%time
snapshot = tf.data.experimental.snapshot('titanic.tfsnap')
snapshotting = traffic_volume_csv_gz_ds.apply(snapshot).shuffle(1000)
for i, (batch, label) in enumerate(snapshotting.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
WARNING:tensorflow:From <timed exec>:1: snapshot (from tensorflow.python.data.experimental.ops.snapshot) is deprecated and will be removed in a future version. Instructions for updating: Use `tf.data.Dataset.snapshot(...)`. ............................................................................................... CPU times: user 2.17 s, sys: 460 ms, total: 2.63 s Wall time: 1.6 s
Si la carga de datos se ralentiza al cargar archivos csv, y el cache y la snapshot son insuficientes para su caso de uso, considere volver a codificar sus datos en un formato más optimizado.
Múltiples archivos
Todos los ejemplos hasta ahora en esta sección podrían realizarse fácilmente sin tf.data . Un lugar donde tf.data realmente puede simplificar las cosas es cuando se trata de colecciones de archivos.
Por ejemplo, el conjunto de datos de imágenes de fuentes de caracteres se distribuye como una colección de archivos csv, uno por fuente.

Imagen de Willi Heidelbach en Pixabay
Descargue el conjunto de datos y eche un vistazo a los archivos que contiene:
fonts_zip = tf.keras.utils.get_file(
'fonts.zip', "https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip",
cache_dir='.', cache_subdir='fonts',
extract=True)
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip 160317440/160313983 [==============================] - 8s 0us/step 160325632/160313983 [==============================] - 8s 0us/step
import pathlib
font_csvs = sorted(str(p) for p in pathlib.Path('fonts').glob("*.csv"))
font_csvs[:10]
['fonts/AGENCY.csv', 'fonts/ARIAL.csv', 'fonts/BAITI.csv', 'fonts/BANKGOTHIC.csv', 'fonts/BASKERVILLE.csv', 'fonts/BAUHAUS.csv', 'fonts/BELL.csv', 'fonts/BERLIN.csv', 'fonts/BERNARD.csv', 'fonts/BITSTREAMVERA.csv']
len(font_csvs)
153
Cuando se trata de un montón de archivos, puede pasar un patrón de archivo de estilo file_pattern a la función experimental.make_csv_dataset . El orden de los archivos se baraja en cada iteración.
Utilice el argumento num_parallel_reads para establecer cuántos archivos se leen en paralelo y se intercalan juntos.
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=10, num_epochs=1,
num_parallel_reads=20,
shuffle_buffer_size=10000)
Estos archivos csv tienen las imágenes aplanadas en una sola fila. Los nombres de las columnas tienen el formato r{row}c{column} . Aquí está el primer lote:
for features in fonts_ds.take(1):
for i, (name, value) in enumerate(features.items()):
if i>15:
break
print(f"{name:20s}: {value}")
print('...')
print(f"[total: {len(features)} features]")
font : [b'HANDPRINT' b'NIAGARA' b'EUROROMAN' b'NIAGARA' b'CENTAUR' b'NINA' b'GOUDY' b'SITKA' b'BELL' b'SITKA'] fontVariant : [b'scanned' b'NIAGARA SOLID' b'EUROROMAN' b'NIAGARA SOLID' b'CENTAUR' b'NINA' b'GOUDY STOUT' b'SITKA TEXT' b'BELL MT' b'SITKA TEXT'] m_label : [ 49 8482 245 88 174 9643 77 974 117 339] strength : [0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4] italic : [0 0 0 1 0 0 1 0 1 0] orientation : [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] m_top : [ 0 32 24 32 28 57 38 48 51 64] m_left : [ 0 20 24 20 22 24 27 23 25 23] originalH : [20 27 55 47 50 15 51 50 27 34] originalW : [ 4 33 25 33 50 15 116 43 28 53] h : [20 20 20 20 20 20 20 20 20 20] w : [20 20 20 20 20 20 20 20 20 20] r0c0 : [ 1 255 255 1 1 255 1 1 1 1] r0c1 : [ 1 255 255 1 1 255 1 1 1 1] r0c2 : [ 1 217 255 1 1 255 54 1 1 1] r0c3 : [ 1 213 255 1 1 255 255 1 1 64] ... [total: 412 features]
Opcional: Campos de embalaje
Probablemente no quiera trabajar con cada píxel en columnas separadas como esta. Antes de intentar usar este conjunto de datos, asegúrese de empaquetar los píxeles en un tensor de imagen.
Aquí hay un código que analiza los nombres de las columnas para crear imágenes para cada ejemplo:
import re
def make_images(features):
image = [None]*400
new_feats = {}
for name, value in features.items():
match = re.match('r(\d+)c(\d+)', name)
if match:
image[int(match.group(1))*20+int(match.group(2))] = value
else:
new_feats[name] = value
image = tf.stack(image, axis=0)
image = tf.reshape(image, [20, 20, -1])
new_feats['image'] = image
return new_feats
Aplique esa función a cada lote en el conjunto de datos:
fonts_image_ds = fonts_ds.map(make_images)
for features in fonts_image_ds.take(1):
break
Trazar las imágenes resultantes:
from matplotlib import pyplot as plt
plt.figure(figsize=(6,6), dpi=120)
for n in range(9):
plt.subplot(3,3,n+1)
plt.imshow(features['image'][..., n])
plt.title(chr(features['m_label'][n]))
plt.axis('off')

Funciones de nivel inferior
Hasta ahora, este tutorial se ha centrado en las utilidades de más alto nivel para leer datos csv. Hay otras dos API que pueden ser útiles para usuarios avanzados si su caso de uso no se ajusta a los patrones básicos.
-
tf.io.decode_csv: una función para analizar líneas de texto en una lista de tensores de columna CSV. -
tf.data.experimental.CsvDataset: un constructor de conjuntos de datos csv de nivel inferior.
Esta sección recrea la funcionalidad proporcionada por make_csv_dataset para demostrar cómo se puede usar esta funcionalidad de nivel inferior.
tf.io.decode_csv
Esta función decodifica una cadena o una lista de cadenas en una lista de columnas.
A diferencia make_csv_dataset , esta función no intenta adivinar los tipos de datos de las columnas. Los tipos de columna se especifican proporcionando una lista de record_defaults que contiene un valor del tipo correcto para cada columna.
Para leer los datos del Titanic como cadenas usando decode_csv diría:
text = pathlib.Path(titanic_file_path).read_text()
lines = text.split('\n')[1:-1]
all_strings = [str()]*10
all_strings
['', '', '', '', '', '', '', '', '', '']
features = tf.io.decode_csv(lines, record_defaults=all_strings)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
Para analizarlos con sus tipos reales, cree una lista de record_defaults de los tipos correspondientes:
print(lines[0])
0,male,22.0,1,0,7.25,Third,unknown,Southampton,n
titanic_types = [int(), str(), float(), int(), int(), float(), str(), str(), str(), str()]
titanic_types
[0, '', 0.0, 0, 0, 0.0, '', '', '', '']
features = tf.io.decode_csv(lines, record_defaults=titanic_types)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: int32, shape: (627,) type: string, shape: (627,) type: float32, shape: (627,) type: int32, shape: (627,) type: int32, shape: (627,) type: float32, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
tf.data.experimental.CsvDataset
La clase tf.data.experimental.CsvDataset proporciona una interfaz de conjunto de Dataset CSV mínima sin las características convenientes de la función make_csv_dataset : análisis de encabezado de columna, inferencia de tipo de columna, barajado automático, intercalado de archivos.
Este constructor usa record_defaults de la misma manera que io.parse_csv :
simple_titanic = tf.data.experimental.CsvDataset(titanic_file_path, record_defaults=titanic_types, header=True)
for example in simple_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
El código anterior es básicamente equivalente a:
def decode_titanic_line(line):
return tf.io.decode_csv(line, titanic_types)
manual_titanic = (
# Load the lines of text
tf.data.TextLineDataset(titanic_file_path)
# Skip the header row.
.skip(1)
# Decode the line.
.map(decode_titanic_line)
)
for example in manual_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
Múltiples archivos
Para analizar el conjunto de datos de fuentes mediante experimental.CsvDataset , primero debe determinar los tipos de columna para record_defaults . Comience por inspeccionar la primera fila de un archivo:
font_line = pathlib.Path(font_csvs[0]).read_text().splitlines()[1]
print(font_line)
AGENCY,AGENCY FB,64258,0.400000,0,0.000000,35,21,51,22,20,20,1,1,1,21,101,210,255,255,255,255,255,255,255,255,255,255,255,255,255,255,1,1,1,93,255,255,255,176,146,146,146,146,146,146,146,146,216,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,141,141,141,182,255,255,255,172,141,141,141,115,1,1,1,1,163,255,255,255,255,255,255,255,255,255,255,255,255,255,255,209,1,1,1,1,163,255,255,255,6,6,6,96,255,255,255,74,6,6,6,5,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255
Solo los primeros dos campos son cadenas, el resto son enteros o flotantes, y puede obtener el número total de características contando las comas:
num_font_features = font_line.count(',')+1
font_column_types = [str(), str()] + [float()]*(num_font_features-2)
El constructor CsvDatasaet puede tomar una lista de archivos de entrada, pero los lee secuencialmente. El primer archivo en la lista de CSV es AGENCY.csv :
font_csvs[0]
'fonts/AGENCY.csv'
Entonces, cuando pasa la lista de archivos a CsvDataaset , los registros de AGENCY.csv se leen primero:
simple_font_ds = tf.data.experimental.CsvDataset(
font_csvs,
record_defaults=font_column_types,
header=True)
for row in simple_font_ds.take(10):
print(row[0].numpy())
b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY'
Para intercalar varios archivos, use Dataset.interleave .
Aquí hay un conjunto de datos inicial que contiene los nombres de los archivos csv:
font_files = tf.data.Dataset.list_files("fonts/*.csv")
Esto mezcla los nombres de los archivos en cada época:
print('Epoch 1:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
print()
print('Epoch 2:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
Epoch 1:
b'fonts/CORBEL.csv'
b'fonts/GLOUCESTER.csv'
b'fonts/GABRIOLA.csv'
b'fonts/FORTE.csv'
b'fonts/GILL.csv'
...
Epoch 2:
b'fonts/MONEY.csv'
b'fonts/ISOC.csv'
b'fonts/DUTCH801.csv'
b'fonts/CALIBRI.csv'
b'fonts/ROMANTIC.csv'
...
El método interleave toma un map_func que crea un conjunto de Dataset secundario para cada elemento del conjunto de Dataset principal.
Aquí, desea crear un CsvDataset a partir de cada elemento del conjunto de datos de archivos:
def make_font_csv_ds(path):
return tf.data.experimental.CsvDataset(
path,
record_defaults=font_column_types,
header=True)
El conjunto de Dataset devuelto por la intercalación devuelve elementos al pasar por varios conjuntos de Dataset secundarios. Observe, a continuación, cómo el conjunto de datos se desplaza por cycle_length=3 tres archivos de fuente:
font_rows = font_files.interleave(make_font_csv_ds,
cycle_length=3)
fonts_dict = {'font_name':[], 'character':[]}
for row in font_rows.take(10):
fonts_dict['font_name'].append(row[0].numpy().decode())
fonts_dict['character'].append(chr(row[2].numpy()))
pd.DataFrame(fonts_dict)
Rendimiento
Anteriormente, se señaló que io.decode_csv es más eficiente cuando se ejecuta en un lote de cadenas.
Es posible aprovechar este hecho, cuando se utilizan lotes de gran tamaño, para mejorar el rendimiento de carga de CSV (pero intente almacenar en caché primero).
Con el cargador integrado 20, los lotes de 2048 ejemplos tardan unos 17 s.
BATCH_SIZE=2048
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=BATCH_SIZE, num_epochs=1,
num_parallel_reads=100)
%%time
for i,batch in enumerate(fonts_ds.take(20)):
print('.',end='')
print()
.................... CPU times: user 24.3 s, sys: 1.46 s, total: 25.7 s Wall time: 10.9 s
Pasar lotes de líneas de texto a decode_csv se ejecuta más rápido, en aproximadamente 5 segundos:
fonts_files = tf.data.Dataset.list_files("fonts/*.csv")
fonts_lines = fonts_files.interleave(
lambda fname:tf.data.TextLineDataset(fname).skip(1),
cycle_length=100).batch(BATCH_SIZE)
fonts_fast = fonts_lines.map(lambda x: tf.io.decode_csv(x, record_defaults=font_column_types))
%%time
for i,batch in enumerate(fonts_fast.take(20)):
print('.',end='')
print()
.................... CPU times: user 8.77 s, sys: 0 ns, total: 8.77 s Wall time: 1.57 s
Para ver otro ejemplo de cómo aumentar el rendimiento de csv mediante el uso de lotes grandes, consulte el tutorial sobreajuste y ajuste insuficiente .
Este tipo de enfoque puede funcionar, pero considere otras opciones, como cache e snapshot , o volver a codificar sus datos en un formato más simplificado.