
| | |  ดูแหล่งที่มาบน GitHub ดูแหล่งที่มาบน GitHub |
บทช่วยสอนนี้แสดงตัวอย่างวิธีใช้ข้อมูล CSV กับ TensorFlow
มีสองส่วนหลักในเรื่องนี้:
- กำลังโหลดข้อมูลออกจากดิสก์
- ก่อนแปรรูปให้อยู่ในรูปแบบที่เหมาะสมกับการฝึกหัด
บทช่วยสอนนี้เน้นที่การโหลด และให้ตัวอย่างสั้นๆ ของการประมวลผลล่วงหน้า สำหรับบทช่วยสอนที่เน้นด้านการประมวลผลล่วงหน้า โปรดดูคู่มือและบทช่วย สอน ของเลเยอร์การประมวลผลล่วงหน้า
ติดตั้ง
import pandas as pd
import numpy as np
# Make numpy values easier to read.
np.set_printoptions(precision=3, suppress=True)
import tensorflow as tf
from tensorflow.keras import layers
ในข้อมูลหน่วยความจำ
สำหรับชุดข้อมูล CSV ขนาดเล็ก วิธีที่ง่ายที่สุดในการฝึกโมเดล TensorFlow คือโหลดลงในหน่วยความจำเป็นดาต้าเฟรมแพนด้าหรืออาร์เรย์ NumPy
ตัวอย่างที่ค่อนข้างง่ายคือ ชุดข้อมูลหอยเป๋าฮื้อ
- ชุดข้อมูลมีขนาดเล็ก
- คุณสมบัติอินพุตทั้งหมดเป็นค่าทศนิยมแบบจำกัดช่วงทั้งหมด
นี่คือวิธีการดาวน์โหลดข้อมูลลงใน Pandas DataFrame :
abalone_train = pd.read_csv(
"https://storage.googleapis.com/download.tensorflow.org/data/abalone_train.csv",
names=["Length", "Diameter", "Height", "Whole weight", "Shucked weight",
"Viscera weight", "Shell weight", "Age"])
abalone_train.head()
ชุดข้อมูลประกอบด้วยชุดการวัดของ หอยเป๋าฮื้อ ซึ่งเป็นชนิดของหอยทากทะเล

“หอยเป๋าฮื้อ” (โดย Nicki Dugan Pogue , CC BY-SA 2.0)
งานเล็กน้อยสำหรับชุดข้อมูลนี้คือการคาดการณ์อายุจากการวัดอื่นๆ ดังนั้นให้แยกคุณลักษณะและป้ายกำกับสำหรับการฝึกอบรม:
abalone_features = abalone_train.copy()
abalone_labels = abalone_features.pop('Age')
สำหรับชุดข้อมูลนี้ คุณจะปฏิบัติต่อคุณลักษณะทั้งหมดเหมือนกัน บรรจุคุณลักษณะลงในอาร์เรย์ NumPy เดียว:
abalone_features = np.array(abalone_features)
abalone_features
array([[0.435, 0.335, 0.11 , ..., 0.136, 0.077, 0.097],
[0.585, 0.45 , 0.125, ..., 0.354, 0.207, 0.225],
[0.655, 0.51 , 0.16 , ..., 0.396, 0.282, 0.37 ],
...,
[0.53 , 0.42 , 0.13 , ..., 0.374, 0.167, 0.249],
[0.395, 0.315, 0.105, ..., 0.118, 0.091, 0.119],
[0.45 , 0.355, 0.12 , ..., 0.115, 0.067, 0.16 ]])
ต่อไปทำแบบจำลองการถดถอยทำนายอายุ เนื่องจากมีเทนเซอร์อินพุตเพียงตัวเดียว โมเดล keras.Sequential ก็เพียงพอแล้วที่นี่
abalone_model = tf.keras.Sequential([
layers.Dense(64),
layers.Dense(1)
])
abalone_model.compile(loss = tf.losses.MeanSquaredError(),
optimizer = tf.optimizers.Adam())
ในการฝึกโมเดลนั้น ให้ส่งคุณสมบัติและป้ายกำกับไปที่ Model.fit :
abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 104/104 [==============================] - 1s 2ms/step - loss: 63.0446 Epoch 2/10 104/104 [==============================] - 0s 2ms/step - loss: 11.9429 Epoch 3/10 104/104 [==============================] - 0s 2ms/step - loss: 8.4836 Epoch 4/10 104/104 [==============================] - 0s 2ms/step - loss: 8.0052 Epoch 5/10 104/104 [==============================] - 0s 2ms/step - loss: 7.6073 Epoch 6/10 104/104 [==============================] - 0s 2ms/step - loss: 7.2485 Epoch 7/10 104/104 [==============================] - 0s 2ms/step - loss: 6.9883 Epoch 8/10 104/104 [==============================] - 0s 2ms/step - loss: 6.7977 Epoch 9/10 104/104 [==============================] - 0s 2ms/step - loss: 6.6477 Epoch 10/10 104/104 [==============================] - 0s 2ms/step - loss: 6.5359 <keras.callbacks.History at 0x7f70543c7350>
คุณเพิ่งเห็นวิธีพื้นฐานที่สุดในการฝึกโมเดลโดยใช้ข้อมูล CSV ต่อไป คุณจะได้เรียนรู้วิธีใช้การประมวลผลล่วงหน้าเพื่อทำให้คอลัมน์ตัวเลขเป็นปกติ
การประมวลผลเบื้องต้นเบื้องต้น
แนวทางปฏิบัติที่ดีในการทำให้อินพุตเป็นปกติของโมเดลของคุณ เลเยอร์การประมวลผลล่วงหน้าของ Keras เป็นวิธีที่สะดวกในการสร้างการทำให้เป็นมาตรฐานในแบบจำลองของคุณ
เลเยอร์จะคำนวณค่ากลางและความแปรปรวนของแต่ละคอลัมน์ล่วงหน้า และใช้สิ่งเหล่านี้เพื่อทำให้ข้อมูลเป็นมาตรฐาน
ขั้นแรกคุณต้องสร้างเลเยอร์:
normalize = layers.Normalization()
จากนั้นคุณใช้เมธอด Normalization.adapt() เพื่อปรับเลเยอร์การทำให้เป็นมาตรฐานกับข้อมูลของคุณ
normalize.adapt(abalone_features)
จากนั้นใช้เลเยอร์การทำให้เป็นมาตรฐานในแบบจำลองของคุณ:
norm_abalone_model = tf.keras.Sequential([
normalize,
layers.Dense(64),
layers.Dense(1)
])
norm_abalone_model.compile(loss = tf.losses.MeanSquaredError(),
optimizer = tf.optimizers.Adam())
norm_abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 104/104 [==============================] - 0s 2ms/step - loss: 92.5851 Epoch 2/10 104/104 [==============================] - 0s 2ms/step - loss: 55.1199 Epoch 3/10 104/104 [==============================] - 0s 2ms/step - loss: 18.2937 Epoch 4/10 104/104 [==============================] - 0s 2ms/step - loss: 6.2633 Epoch 5/10 104/104 [==============================] - 0s 2ms/step - loss: 5.1257 Epoch 6/10 104/104 [==============================] - 0s 2ms/step - loss: 5.0217 Epoch 7/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9775 Epoch 8/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9730 Epoch 9/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9348 Epoch 10/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9416 <keras.callbacks.History at 0x7f70541b2a50>
ชนิดข้อมูลผสม
ชุดข้อมูล "ไททานิค" มีข้อมูลเกี่ยวกับผู้โดยสารบนไททานิค งานเล็กน้อยในชุดข้อมูลนี้คือการคาดการณ์ว่าใครรอดชีวิต

ภาพ จากวิกิมีเดีย
{kind=link}
ข้อมูลดิบสามารถโหลดได้อย่างง่ายดายเป็น Pandas DataFrame แต่ไม่สามารถใช้เป็นอินพุตในโมเดล TensorFlow ในทันที
titanic = pd.read_csv("https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic.head()
titanic_features = titanic.copy()
titanic_labels = titanic_features.pop('survived')
เนื่องจากประเภทข้อมูลและช่วงข้อมูลที่แตกต่างกัน คุณจึงไม่สามารถซ้อนคุณลักษณะลงในอาร์เรย์ NumPy และส่งผ่านไปยังโมเดล keras.Sequential ไม่ได้ แต่ละคอลัมน์จะต้องได้รับการจัดการเป็นรายบุคคล
คุณสามารถประมวลผลข้อมูลของคุณล่วงหน้าแบบออฟไลน์ (โดยใช้เครื่องมือใดก็ได้ที่คุณต้องการ) เพื่อแปลงคอลัมน์ตามหมวดหมู่เป็นคอลัมน์ตัวเลข จากนั้นส่งเอาต์พุตที่ประมวลผลไปยังโมเดล TensorFlow ของคุณ ข้อเสียของแนวทางนี้คือ หากคุณบันทึกและส่งออกโมเดลของคุณ การประมวลผลล่วงหน้าจะไม่ถูกบันทึกด้วย เลเยอร์การประมวลผลล่วงหน้าของ Keras หลีกเลี่ยงปัญหานี้เนื่องจากเป็นส่วนหนึ่งของโมเดล
ในตัวอย่างนี้ คุณจะต้องสร้างโมเดลที่ใช้ตรรกะก่อนการประมวลผลโดยใช้ Keras functional API คุณสามารถทำได้โดยการจัด คลาสย่อย
API การทำงานทำงานบนเทนเซอร์ "สัญลักษณ์" เทนเซอร์ "กระตือรือร้น" ปกติมีค่า ในทางตรงกันข้าม "สัญลักษณ์" เทนเซอร์เหล่านี้ไม่ทำ แต่จะติดตามว่าการดำเนินการใดที่เรียกใช้ และสร้างการแสดงการคำนวณ ซึ่งคุณสามารถเรียกใช้ในภายหลังได้ นี่คือตัวอย่างด่วน:
# Create a symbolic input
input = tf.keras.Input(shape=(), dtype=tf.float32)
# Perform a calculation using the input
result = 2*input + 1
# the result doesn't have a value
result
<KerasTensor: shape=(None,) dtype=float32 (created by layer 'tf.__operators__.add')>
calc = tf.keras.Model(inputs=input, outputs=result)
print(calc(1).numpy())
print(calc(2).numpy())
3.0 5.0
ในการสร้างโมเดลการประมวลผลล่วงหน้า ให้เริ่มต้นด้วยการสร้างชุดของสัญลักษณ์ keras.Input อ็อบเจ็กต์ จับคู่ชื่อและประเภทข้อมูลของคอลัมน์ CSV
inputs = {}
for name, column in titanic_features.items():
dtype = column.dtype
if dtype == object:
dtype = tf.string
else:
dtype = tf.float32
inputs[name] = tf.keras.Input(shape=(1,), name=name, dtype=dtype)
inputs
{'sex': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'sex')>,
'age': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'age')>,
'n_siblings_spouses': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'n_siblings_spouses')>,
'parch': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'parch')>,
'fare': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'fare')>,
'class': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'class')>,
'deck': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'deck')>,
'embark_town': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'embark_town')>,
'alone': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'alone')>}
ขั้นตอนแรกในตรรกะการประมวลผลล่วงหน้าของคุณคือการต่อข้อมูลอินพุตที่เป็นตัวเลขเข้าด้วยกัน และเรียกใช้ผ่านเลเยอร์การทำให้เป็นมาตรฐาน:
numeric_inputs = {name:input for name,input in inputs.items()
if input.dtype==tf.float32}
x = layers.Concatenate()(list(numeric_inputs.values()))
norm = layers.Normalization()
norm.adapt(np.array(titanic[numeric_inputs.keys()]))
all_numeric_inputs = norm(x)
all_numeric_inputs
<KerasTensor: shape=(None, 4) dtype=float32 (created by layer 'normalization_1')>ตัวยึดตำแหน่ง23
รวบรวมผลการประมวลผลล่วงหน้าเชิงสัญลักษณ์ทั้งหมด เพื่อรวมเข้าด้วยกันในภายหลัง
preprocessed_inputs = [all_numeric_inputs]
สำหรับอินพุตสตริง ให้ใช้ฟังก์ชัน tf.keras.layers.StringLookup เพื่อจับคู่จากสตริงเป็นดัชนีจำนวนเต็มในคำศัพท์ ถัดไป ใช้ tf.keras.layers.CategoryEncoding เพื่อแปลงดัชนีเป็นข้อมูล float32 ที่เหมาะสมกับโมเดล
การตั้งค่าเริ่มต้นสำหรับเลเยอร์ tf.keras.layers.CategoryEncoding จะสร้างเวกเตอร์ยอดนิยมสำหรับแต่ละอินพุต layers.Embedding การฝังก็ใช้ได้เช่นกัน ดูคำแนะนำและบทช่วย สอน ของเลเยอร์การประมวลผลล่วงหน้า สำหรับข้อมูลเพิ่มเติมในหัวข้อนี้
for name, input in inputs.items():
if input.dtype == tf.float32:
continue
lookup = layers.StringLookup(vocabulary=np.unique(titanic_features[name]))
one_hot = layers.CategoryEncoding(max_tokens=lookup.vocab_size())
x = lookup(input)
x = one_hot(x)
preprocessed_inputs.append(x)
WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead.
ด้วยคอลเล็กชันของ inputs และ processed_inputs คุณสามารถเชื่อมอินพุตที่ประมวลผลล่วงหน้าทั้งหมดเข้าด้วยกัน และสร้างแบบจำลองที่จัดการการประมวลผลล่วงหน้า:
preprocessed_inputs_cat = layers.Concatenate()(preprocessed_inputs)
titanic_preprocessing = tf.keras.Model(inputs, preprocessed_inputs_cat)
tf.keras.utils.plot_model(model = titanic_preprocessing , rankdir="LR", dpi=72, show_shapes=True)
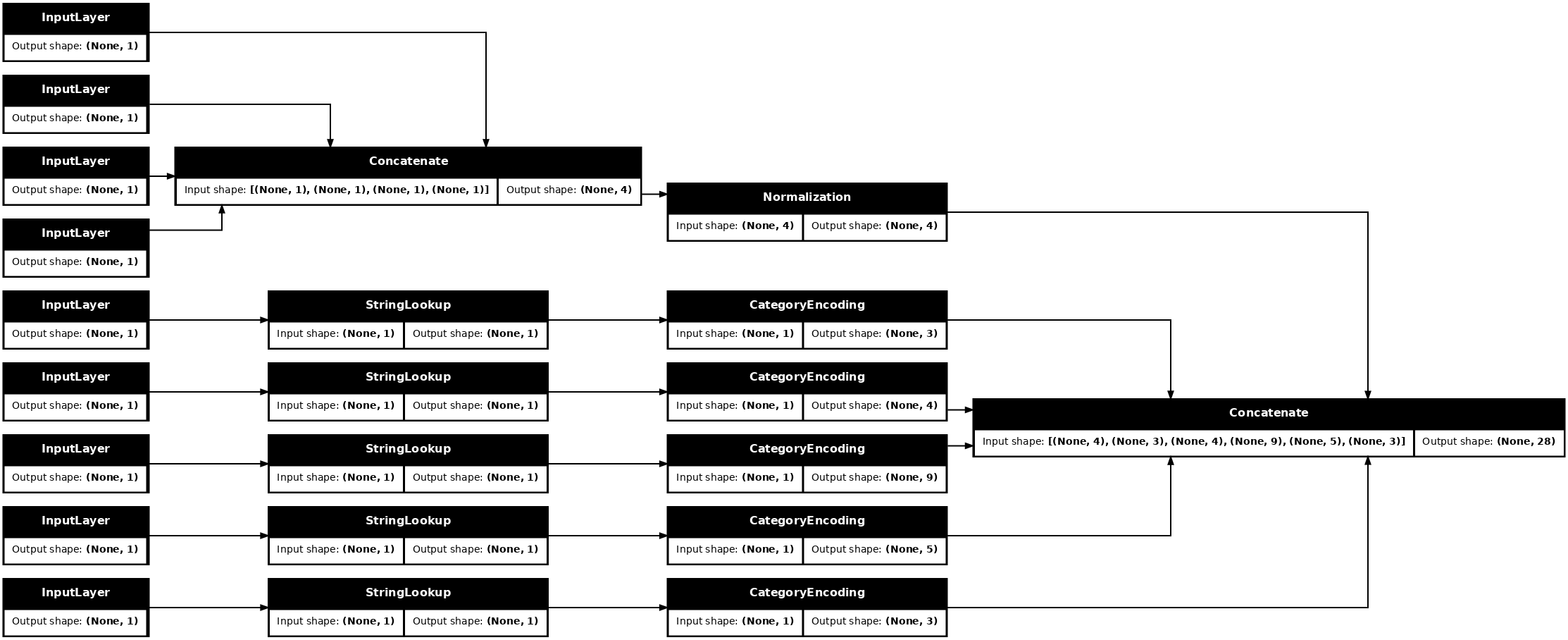
model นี้ประกอบด้วยการประมวลผลล่วงหน้าของอินพุต คุณสามารถเรียกใช้เพื่อดูว่ามันทำอะไรกับข้อมูลของคุณ โมเดล Keras จะไม่แปลง Pandas DataFrames โดยอัตโนมัติ เนื่องจากยังไม่ชัดเจนว่าควรแปลงเป็นเมตริกซ์เดียวหรือเป็นพจนานุกรมของเมตริกซ์ ดังนั้นให้แปลงเป็นพจนานุกรมเทนเซอร์:
titanic_features_dict = {name: np.array(value)
for name, value in titanic_features.items()}
แยกตัวอย่างการฝึกอบรมแรกออกและส่งต่อไปยังโมเดลการประมวลผลล่วงหน้านี้ คุณจะเห็นคุณลักษณะที่เป็นตัวเลขและสตริง one-hots ที่เชื่อมต่อกันทั้งหมด:
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
titanic_preprocessing(features_dict)
<tf.Tensor: shape=(1, 28), dtype=float32, numpy=
array([[-0.61 , 0.395, -0.479, -0.497, 0. , 0. , 1. , 0. ,
0. , 0. , 1. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 1. , 0. , 0. , 0. , 1. ,
0. , 0. , 1. , 0. ]], dtype=float32)>
ตอนนี้สร้างแบบจำลองจากสิ่งนี้:
def titanic_model(preprocessing_head, inputs):
body = tf.keras.Sequential([
layers.Dense(64),
layers.Dense(1)
])
preprocessed_inputs = preprocessing_head(inputs)
result = body(preprocessed_inputs)
model = tf.keras.Model(inputs, result)
model.compile(loss=tf.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.optimizers.Adam())
return model
titanic_model = titanic_model(titanic_preprocessing, inputs)
เมื่อคุณฝึกโมเดล ให้ส่งพจนานุกรมของคุณสมบัติเป็น x และป้ายกำกับเป็น y
titanic_model.fit(x=titanic_features_dict, y=titanic_labels, epochs=10)
Epoch 1/10 20/20 [==============================] - 1s 4ms/step - loss: 0.8017 Epoch 2/10 20/20 [==============================] - 0s 4ms/step - loss: 0.5913 Epoch 3/10 20/20 [==============================] - 0s 5ms/step - loss: 0.5212 Epoch 4/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4841 Epoch 5/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4615 Epoch 6/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4470 Epoch 7/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4367 Epoch 8/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4304 Epoch 9/10 20/20 [==============================] - 0s 4ms/step - loss: 0.4265 Epoch 10/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4239 <keras.callbacks.History at 0x7f70b1f82a50>ตัวยึดตำแหน่ง33
เนื่องจากการประมวลผลล่วงหน้าเป็นส่วนหนึ่งของโมเดล คุณสามารถบันทึกโมเดลและโหลดซ้ำที่อื่นและได้ผลลัพธ์ที่เหมือนกัน:
titanic_model.save('test')
reloaded = tf.keras.models.load_model('test')
2022-01-26 06:36:18.822459: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: test/assets
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
before = titanic_model(features_dict)
after = reloaded(features_dict)
assert (before-after)<1e-3
print(before)
print(after)
tf.Tensor([[-1.791]], shape=(1, 1), dtype=float32) tf.Tensor([[-1.791]], shape=(1, 1), dtype=float32)
ใช้ tf.data
ในส่วนก่อนหน้านี้ คุณต้องอาศัยการสับเปลี่ยนข้อมูลในตัวของโมเดลและการแบ่งกลุ่มขณะฝึกโมเดล
หากคุณต้องการการควบคุมเพิ่มเติมสำหรับไปป์ไลน์ข้อมูลอินพุตหรือต้องการใช้ข้อมูลที่ไม่พอดีกับหน่วยความจำ: ใช้ tf.data
สำหรับตัวอย่างเพิ่มเติม โปรดดูที่ คู่มือ tf.data
เปิดในข้อมูลหน่วยความจำ
เป็นตัวอย่างแรกของการใช้ tf.data กับข้อมูล CSV ให้พิจารณาโค้ดต่อไปนี้เพื่อแบ่งส่วนพจนานุกรมของคุณลักษณะจากส่วนก่อนหน้าด้วยตนเอง สำหรับแต่ละดัชนี จะใช้ดัชนีนั้นสำหรับแต่ละคุณลักษณะ:
import itertools
def slices(features):
for i in itertools.count():
# For each feature take index `i`
example = {name:values[i] for name, values in features.items()}
yield example
รันสิ่งนี้และพิมพ์ตัวอย่างแรก:
for example in slices(titanic_features_dict):
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : male age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : Third deck : unknown embark_town : Southampton alone : n
tf.data.Dataset พื้นฐานที่สุดในตัวโหลดข้อมูลหน่วยความจำคือตัวสร้าง Dataset.from_tensor_slices ซึ่งจะส่งคืน tf.data.Dataset ที่ใช้เวอร์ชันทั่วไปของฟังก์ชันสไลซ์ด้านบนใน slices
features_ds = tf.data.Dataset.from_tensor_slices(titanic_features_dict)
คุณสามารถวนซ้ำบน tf.data.Dataset เหมือนกับ python iterable อื่น ๆ :
for example in features_ds:
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : b'male' age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : b'Third' deck : b'unknown' embark_town : b'Southampton' alone : b'n'ตัวยึดตำแหน่ง43
ฟังก์ชัน from_tensor_slices สามารถจัดการโครงสร้างของพจนานุกรมหรือทูเพิลที่ซ้อนกันได้ รหัสต่อไปนี้สร้างชุดข้อมูลของคู่ (features_dict, labels) :
titanic_ds = tf.data.Dataset.from_tensor_slices((titanic_features_dict, titanic_labels))
ในการฝึกโมเดลโดยใช้ Dataset นี้ คุณจะต้อง shuffle และจัด batch ข้อมูลเป็นอย่างน้อย
titanic_batches = titanic_ds.shuffle(len(titanic_labels)).batch(32)
แทนที่จะส่ง features และ labels ไปที่ Model.fit คุณส่งชุดข้อมูล:
titanic_model.fit(titanic_batches, epochs=5)
Epoch 1/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4230 Epoch 2/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4216 Epoch 3/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4203 Epoch 4/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4198 Epoch 5/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4194 <keras.callbacks.History at 0x7f70b12485d0>
จากไฟล์เดียว
จนถึงตอนนี้บทช่วยสอนนี้ใช้ได้กับข้อมูลในหน่วยความจำแล้ว tf.data เป็นชุดเครื่องมือที่ปรับขนาดได้สูงสำหรับการสร้างไปป์ไลน์ข้อมูล และมีฟังก์ชันบางอย่างสำหรับจัดการกับการโหลดไฟล์ CSV
titanic_file_path = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
Downloading data from https://storage.googleapis.com/tf-datasets/titanic/train.csv 32768/30874 [===============================] - 0s 0us/step 40960/30874 [=======================================] - 0s 0us/step
ตอนนี้อ่านข้อมูล CSV จากไฟล์และสร้าง tf.data.Dataset
(สำหรับเอกสารฉบับเต็ม โปรดดู tf.data.experimental.make_csv_dataset )
titanic_csv_ds = tf.data.experimental.make_csv_dataset(
titanic_file_path,
batch_size=5, # Artificially small to make examples easier to show.
label_name='survived',
num_epochs=1,
ignore_errors=True,)
ฟังก์ชันนี้มีคุณลักษณะที่สะดวกสบายมากมาย ข้อมูลจึงง่ายต่อการใช้งาน ซึ่งรวมถึง:
- การใช้ส่วนหัวของคอลัมน์เป็นคีย์พจนานุกรม
- กำหนดประเภทของแต่ละคอลัมน์โดยอัตโนมัติ
for batch, label in titanic_csv_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value}")
print()
print(f"{'label':20s}: {label}")
sex : [b'male' b'male' b'female' b'male' b'male'] age : [27. 18. 15. 46. 50.] n_siblings_spouses : [0 0 0 1 0] parch : [0 0 0 0 0] fare : [ 7.896 7.796 7.225 61.175 13. ] class : [b'Third' b'Third' b'Third' b'First' b'Second'] deck : [b'unknown' b'unknown' b'unknown' b'E' b'unknown'] embark_town : [b'Southampton' b'Southampton' b'Cherbourg' b'Southampton' b'Southampton'] alone : [b'y' b'y' b'y' b'n' b'y'] label : [0 0 1 0 0]ตัวยึดตำแหน่ง52
นอกจากนี้ยังสามารถขยายข้อมูลได้ทันที นี่คือไฟล์ CSV gzipped ที่มี ชุดข้อมูลการรับส่งข้อมูลระหว่างรัฐ ในเมืองใหญ่

ภาพ จากวิกิมีเดีย
{kind=link}
traffic_volume_csv_gz = tf.keras.utils.get_file(
'Metro_Interstate_Traffic_Volume.csv.gz',
"https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz",
cache_dir='.', cache_subdir='traffic')
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz 409600/405373 [==============================] - 1s 1us/step 417792/405373 [==============================] - 1s 1us/step
ตั้งค่าอาร์กิวเมนต์ compression_type ให้อ่านโดยตรงจากไฟล์บีบอัด:
traffic_volume_csv_gz_ds = tf.data.experimental.make_csv_dataset(
traffic_volume_csv_gz,
batch_size=256,
label_name='traffic_volume',
num_epochs=1,
compression_type="GZIP")
for batch, label in traffic_volume_csv_gz_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value[:5]}")
print()
print(f"{'label':20s}: {label[:5]}")
holiday : [b'None' b'None' b'None' b'None' b'None'] temp : [280.56 266.79 281.64 292.71 270.48] rain_1h : [0. 0. 0. 0. 0.] snow_1h : [0. 0. 0. 0. 0.] clouds_all : [46 90 90 0 64] weather_main : [b'Clear' b'Clouds' b'Mist' b'Clear' b'Clouds'] weather_description : [b'sky is clear' b'overcast clouds' b'mist' b'Sky is Clear' b'broken clouds'] date_time : [b'2012-11-05 20:00:00' b'2012-12-17 23:00:00' b'2013-10-06 19:00:00' b'2013-08-23 22:00:00' b'2013-11-11 05:00:00'] label : [2415 966 3459 2633 2576]
เก็บเอาไว้
มีค่าใช้จ่ายบางส่วนในการแยกวิเคราะห์ข้อมูล csv สำหรับรุ่นเล็ก นี่อาจเป็นคอขวดในการฝึก
ขึ้นอยู่กับกรณีการใช้งานของคุณ อาจเป็นความคิดที่ดีที่จะใช้ Dataset.cache หรือ data.experimental.snapshot เพื่อให้ข้อมูล csv แยกวิเคราะห์ในยุคแรกเท่านั้น
ความแตกต่างหลักระหว่างวิธี cache และส snapshot อตคือไฟล์ cache สามารถใช้ได้โดยกระบวนการ TensorFlow ที่สร้างไฟล์เหล่านี้เท่านั้น แต่กระบวนการอื่นสามารถอ่านไฟล์ส snapshot อตได้
ตัวอย่างเช่น การวนซ้ำ traffic_volume_csv_gz_ds 20 ครั้ง ใช้เวลา ~15 วินาทีโดยไม่มีการแคช หรือประมาณ 2 วินาทีด้วยการแคช
%%time
for i, (batch, label) in enumerate(traffic_volume_csv_gz_ds.repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 14.9 s, sys: 3.7 s, total: 18.6 s Wall time: 11.2 s
%%time
caching = traffic_volume_csv_gz_ds.cache().shuffle(1000)
for i, (batch, label) in enumerate(caching.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 1.43 s, sys: 173 ms, total: 1.6 s Wall time: 1.28 sตัวยึดตำแหน่ง60
%%time
snapshot = tf.data.experimental.snapshot('titanic.tfsnap')
snapshotting = traffic_volume_csv_gz_ds.apply(snapshot).shuffle(1000)
for i, (batch, label) in enumerate(snapshotting.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
WARNING:tensorflow:From <timed exec>:1: snapshot (from tensorflow.python.data.experimental.ops.snapshot) is deprecated and will be removed in a future version. Instructions for updating: Use `tf.data.Dataset.snapshot(...)`. ............................................................................................... CPU times: user 2.17 s, sys: 460 ms, total: 2.63 s Wall time: 1.6 s
หากการโหลดข้อมูลของคุณช้าลงโดยการโหลดไฟล์ csv และ cache และส snapshot อตไม่เพียงพอสำหรับกรณีการใช้งานของคุณ ให้พิจารณาเข้ารหัสข้อมูลของคุณใหม่ให้อยู่ในรูปแบบที่มีความคล่องตัวมากขึ้น
หลายไฟล์
ตัวอย่างทั้งหมดในส่วนนี้สามารถทำได้ง่ายๆ โดยไม่ต้องใช้ tf.data ที่แห่งหนึ่งที่ tf.data สามารถทำให้สิ่งต่าง ๆ ง่ายขึ้นได้จริง ๆ คือเมื่อต้องจัดการกับคอลเลกชันของไฟล์
ตัวอย่างเช่น ชุดข้อมูล ภาพฟอนต์อักขระ ถูกแจกจ่ายเป็นคอลเลกชันของไฟล์ csv หนึ่งไฟล์ต่อฟอนต์

ภาพโดย Willi Heidelbach จาก Pixabay
ดาวน์โหลดชุดข้อมูลและดูไฟล์ภายใน:
fonts_zip = tf.keras.utils.get_file(
'fonts.zip', "https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip",
cache_dir='.', cache_subdir='fonts',
extract=True)
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip 160317440/160313983 [==============================] - 8s 0us/step 160325632/160313983 [==============================] - 8s 0us/step
import pathlib
font_csvs = sorted(str(p) for p in pathlib.Path('fonts').glob("*.csv"))
font_csvs[:10]
['fonts/AGENCY.csv', 'fonts/ARIAL.csv', 'fonts/BAITI.csv', 'fonts/BANKGOTHIC.csv', 'fonts/BASKERVILLE.csv', 'fonts/BAUHAUS.csv', 'fonts/BELL.csv', 'fonts/BERLIN.csv', 'fonts/BERNARD.csv', 'fonts/BITSTREAMVERA.csv']
len(font_csvs)
153
เมื่อจัดการกับไฟล์จำนวนมาก คุณสามารถส่ง file_pattern แบบ glob-style ไปยังฟังก์ชัน experimental.make_csv_dataset ลำดับของไฟล์จะสับเปลี่ยนการวนซ้ำแต่ละครั้ง
ใช้อาร์กิวเมนต์ num_parallel_reads เพื่อกำหนดจำนวนไฟล์ที่จะอ่านแบบคู่ขนานและเรียงสลับกัน
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=10, num_epochs=1,
num_parallel_reads=20,
shuffle_buffer_size=10000)
ไฟล์ csv เหล่านี้มีภาพที่แบนออกเป็นแถวเดียว ชื่อคอลัมน์มีรูปแบบ r{row}c{column} นี่คือชุดแรก:
for features in fonts_ds.take(1):
for i, (name, value) in enumerate(features.items()):
if i>15:
break
print(f"{name:20s}: {value}")
print('...')
print(f"[total: {len(features)} features]")
font : [b'HANDPRINT' b'NIAGARA' b'EUROROMAN' b'NIAGARA' b'CENTAUR' b'NINA' b'GOUDY' b'SITKA' b'BELL' b'SITKA'] fontVariant : [b'scanned' b'NIAGARA SOLID' b'EUROROMAN' b'NIAGARA SOLID' b'CENTAUR' b'NINA' b'GOUDY STOUT' b'SITKA TEXT' b'BELL MT' b'SITKA TEXT'] m_label : [ 49 8482 245 88 174 9643 77 974 117 339] strength : [0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4] italic : [0 0 0 1 0 0 1 0 1 0] orientation : [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] m_top : [ 0 32 24 32 28 57 38 48 51 64] m_left : [ 0 20 24 20 22 24 27 23 25 23] originalH : [20 27 55 47 50 15 51 50 27 34] originalW : [ 4 33 25 33 50 15 116 43 28 53] h : [20 20 20 20 20 20 20 20 20 20] w : [20 20 20 20 20 20 20 20 20 20] r0c0 : [ 1 255 255 1 1 255 1 1 1 1] r0c1 : [ 1 255 255 1 1 255 1 1 1 1] r0c2 : [ 1 217 255 1 1 255 54 1 1 1] r0c3 : [ 1 213 255 1 1 255 255 1 1 64] ... [total: 412 features]
ไม่บังคับ: ช่องบรรจุ
คุณอาจไม่ต้องการทำงานกับแต่ละพิกเซลในคอลัมน์แยกกันเช่นนี้ ก่อนลองใช้ชุดข้อมูลนี้ อย่าลืมแพ็คพิกเซลลงในอิมเมจ-เทนเซอร์
นี่คือรหัสที่แยกวิเคราะห์ชื่อคอลัมน์เพื่อสร้างรูปภาพสำหรับแต่ละตัวอย่าง:
import re
def make_images(features):
image = [None]*400
new_feats = {}
for name, value in features.items():
match = re.match('r(\d+)c(\d+)', name)
if match:
image[int(match.group(1))*20+int(match.group(2))] = value
else:
new_feats[name] = value
image = tf.stack(image, axis=0)
image = tf.reshape(image, [20, 20, -1])
new_feats['image'] = image
return new_feats
ใช้ฟังก์ชันนั้นกับแต่ละแบตช์ในชุดข้อมูล:
fonts_image_ds = fonts_ds.map(make_images)
for features in fonts_image_ds.take(1):
break
พล็อตภาพที่ได้:
from matplotlib import pyplot as plt
plt.figure(figsize=(6,6), dpi=120)
for n in range(9):
plt.subplot(3,3,n+1)
plt.imshow(features['image'][..., n])
plt.title(chr(features['m_label'][n]))
plt.axis('off')

ฟังก์ชั่นระดับล่าง
จนถึงตอนนี้ บทช่วยสอนนี้ได้เน้นที่ยูทิลิตี้ระดับสูงสุดสำหรับการอ่านข้อมูล csv มี API อีกสองรายการที่อาจเป็นประโยชน์สำหรับผู้ใช้ขั้นสูง หากกรณีการใช้งานของคุณไม่เหมาะกับรูปแบบพื้นฐาน
-
tf.io.decode_csv- ฟังก์ชันสำหรับแยกบรรทัดของข้อความในรายการเทนเซอร์ของคอลัมน์ CSV -
tf.data.experimental.CsvDataset- ตัวสร้างชุดข้อมูล csv ระดับล่าง
ส่วนนี้จะสร้างฟังก์ชันการทำงานขึ้นใหม่โดย make_csv_dataset เพื่อสาธิตวิธีการใช้ฟังก์ชันระดับล่างนี้
tf.io.decode_csv
ฟังก์ชันนี้จะถอดรหัสสตริงหรือรายการสตริงลงในรายการคอลัมน์
ไม่เหมือนกับ make_csv_dataset ฟังก์ชันนี้จะไม่พยายามเดาประเภทข้อมูลของคอลัมน์ คุณระบุประเภทคอลัมน์โดยระบุรายการของ record_defaults ที่มีค่าประเภทที่ถูกต้องสำหรับแต่ละคอลัมน์
หากต้องการอ่านข้อมูลไททานิค เป็นสตริง โดยใช้ decode_csv คุณจะต้องพูดว่า:
text = pathlib.Path(titanic_file_path).read_text()
lines = text.split('\n')[1:-1]
all_strings = [str()]*10
all_strings
['', '', '', '', '', '', '', '', '', '']
features = tf.io.decode_csv(lines, record_defaults=all_strings)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
หากต้องการแยกวิเคราะห์ด้วยประเภทที่แท้จริง ให้สร้างรายการ record_defaults ของประเภทที่เกี่ยวข้องกัน:
print(lines[0])
0,male,22.0,1,0,7.25,Third,unknown,Southampton,n
titanic_types = [int(), str(), float(), int(), int(), float(), str(), str(), str(), str()]
titanic_types
[0, '', 0.0, 0, 0, 0.0, '', '', '', '']
features = tf.io.decode_csv(lines, record_defaults=titanic_types)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: int32, shape: (627,) type: string, shape: (627,) type: float32, shape: (627,) type: int32, shape: (627,) type: int32, shape: (627,) type: float32, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
tf.data.experimental.CsvDataset
คลาส tf.data.experimental.CsvDataset จัดเตรียมอินเทอร์เฟซ Dataset CSV ขั้นต่ำโดยไม่มีฟีเจอร์อำนวยความสะดวกของฟังก์ชัน make_csv_dataset : การแยกวิเคราะห์ส่วนหัวของคอลัมน์ การอนุมานประเภทคอลัมน์ การสับเปลี่ยนอัตโนมัติ การแทรกไฟล์
ตัวสร้างนี้ติดตามใช้ record_defaults เช่นเดียวกับ io.parse_csv :
simple_titanic = tf.data.experimental.CsvDataset(titanic_file_path, record_defaults=titanic_types, header=True)
for example in simple_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
รหัสข้างต้นนั้นเทียบเท่ากับ:
def decode_titanic_line(line):
return tf.io.decode_csv(line, titanic_types)
manual_titanic = (
# Load the lines of text
tf.data.TextLineDataset(titanic_file_path)
# Skip the header row.
.skip(1)
# Decode the line.
.map(decode_titanic_line)
)
for example in manual_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
หลายไฟล์
หากต้องการแยกวิเคราะห์ชุดข้อมูลฟอนต์โดยใช้ experimental.CsvDataset คุณต้องกำหนดประเภทคอลัมน์สำหรับ record_defaults ก่อน เริ่มต้นด้วยการตรวจสอบแถวแรกของไฟล์เดียว:
font_line = pathlib.Path(font_csvs[0]).read_text().splitlines()[1]
print(font_line)
AGENCY,AGENCY FB,64258,0.400000,0,0.000000,35,21,51,22,20,20,1,1,1,21,101,210,255,255,255,255,255,255,255,255,255,255,255,255,255,255,1,1,1,93,255,255,255,176,146,146,146,146,146,146,146,146,216,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,141,141,141,182,255,255,255,172,141,141,141,115,1,1,1,1,163,255,255,255,255,255,255,255,255,255,255,255,255,255,255,209,1,1,1,1,163,255,255,255,6,6,6,96,255,255,255,74,6,6,6,5,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255
เฉพาะสองฟิลด์แรกเท่านั้นที่เป็นสตริง ส่วนที่เหลือเป็น int หรือ float และคุณสามารถรับจำนวนคุณลักษณะทั้งหมดได้โดยการนับเครื่องหมายจุลภาค:
num_font_features = font_line.count(',')+1
font_column_types = [str(), str()] + [float()]*(num_font_features-2)
ตัวสร้าง CsvDatasaet สามารถรับรายการไฟล์อินพุตได้ แต่จะอ่านตามลำดับ ไฟล์แรกในรายการ CSV คือ AGENCY.csv :
font_csvs[0]
'fonts/AGENCY.csv'ตัวยึดตำแหน่ง93
ดังนั้นเมื่อคุณส่งรายการไฟล์ไปยัง CsvDataaset เร็กคอร์ดจาก AGENCY.csv จะถูกอ่านก่อน:
simple_font_ds = tf.data.experimental.CsvDataset(
font_csvs,
record_defaults=font_column_types,
header=True)
for row in simple_font_ds.take(10):
print(row[0].numpy())
b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY'
หากต้องการแทรกหลายไฟล์ ให้ใช้ Dataset.interleave
นี่คือชุดข้อมูลเริ่มต้นที่มีชื่อไฟล์ csv:
font_files = tf.data.Dataset.list_files("fonts/*.csv")
สิ่งนี้จะสับเปลี่ยนชื่อไฟล์ในแต่ละยุค:
print('Epoch 1:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
print()
print('Epoch 2:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
Epoch 1:
b'fonts/CORBEL.csv'
b'fonts/GLOUCESTER.csv'
b'fonts/GABRIOLA.csv'
b'fonts/FORTE.csv'
b'fonts/GILL.csv'
...
Epoch 2:
b'fonts/MONEY.csv'
b'fonts/ISOC.csv'
b'fonts/DUTCH801.csv'
b'fonts/CALIBRI.csv'
b'fonts/ROMANTIC.csv'
...
เมธอด interleave ใช้ map_func ที่สร้าง Dataset ย่อยสำหรับแต่ละองค์ประกอบของ Dataset หลัก
ที่นี่ คุณต้องการสร้าง CsvDataset จากแต่ละองค์ประกอบของชุดข้อมูลของไฟล์:
def make_font_csv_ds(path):
return tf.data.experimental.CsvDataset(
path,
record_defaults=font_column_types,
header=True)
Dataset ที่ส่งคืนโดย interleave จะคืนค่าองค์ประกอบโดยการวนรอบ Dataset ย่อยจำนวนหนึ่ง หมายเหตุ ด้านล่าง วิธีที่ชุดข้อมูลวนรอบ cycle_length=3 ไฟล์ฟอนต์ 3 ไฟล์:
font_rows = font_files.interleave(make_font_csv_ds,
cycle_length=3)
fonts_dict = {'font_name':[], 'character':[]}
for row in font_rows.take(10):
fonts_dict['font_name'].append(row[0].numpy().decode())
fonts_dict['character'].append(chr(row[2].numpy()))
pd.DataFrame(fonts_dict)
ประสิทธิภาพ
ก่อนหน้านี้ มีข้อสังเกตว่า io.decode_csv นั้นมีประสิทธิภาพมากกว่าเมื่อรันบนชุดของสตริง
เป็นไปได้ที่จะใช้ประโยชน์จากข้อเท็จจริงนี้ เมื่อใช้ขนาดแบทช์ขนาดใหญ่ เพื่อปรับปรุงประสิทธิภาพการโหลด CSV (แต่ลอง แคช ก่อน)
ด้วยตัวโหลด 20 ในตัว แบทช์ตัวอย่าง 2048 ใช้เวลาประมาณ 17 วินาที
BATCH_SIZE=2048
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=BATCH_SIZE, num_epochs=1,
num_parallel_reads=100)
%%time
for i,batch in enumerate(fonts_ds.take(20)):
print('.',end='')
print()
.................... CPU times: user 24.3 s, sys: 1.46 s, total: 25.7 s Wall time: 10.9 s
การส่งชุดข้อความ ไปยัง decode_csv จะทำงานเร็วขึ้น ในเวลาประมาณ 5 วินาที:
fonts_files = tf.data.Dataset.list_files("fonts/*.csv")
fonts_lines = fonts_files.interleave(
lambda fname:tf.data.TextLineDataset(fname).skip(1),
cycle_length=100).batch(BATCH_SIZE)
fonts_fast = fonts_lines.map(lambda x: tf.io.decode_csv(x, record_defaults=font_column_types))
%%time
for i,batch in enumerate(fonts_fast.take(20)):
print('.',end='')
print()
.................... CPU times: user 8.77 s, sys: 0 ns, total: 8.77 s Wall time: 1.57 s
สำหรับตัวอย่างอื่นของการเพิ่มประสิทธิภาพ csv โดยใช้แบตช์จำนวนมาก โปรดดู บทช่วยสอนเรื่องชุดและชุด ที่ไม่เหมาะสม
วิธีการประเภทนี้อาจใช้ได้ แต่ให้พิจารณาตัวเลือกอื่นๆ เช่น cache และ snapshot หรือเข้ารหัสข้อมูลของคุณใหม่ให้อยู่ในรูปแบบที่มีความคล่องตัวมากขึ้น