
| | |  Visualizza l'origine su GitHub Visualizza l'origine su GitHub |
Questo tutorial fornisce esempi di come utilizzare i dati CSV con TensorFlow.
Ci sono due parti principali di questo:
- Caricamento dei dati da disco
- Pre-elaborandolo in una forma adatta per l'allenamento.
Questo tutorial si concentra sul caricamento e fornisce alcuni rapidi esempi di preelaborazione. Per un'esercitazione incentrata sull'aspetto della preelaborazione, vedere la guida ai livelli di preelaborazione e l' esercitazione .
Impostare
import pandas as pd
import numpy as np
# Make numpy values easier to read.
np.set_printoptions(precision=3, suppress=True)
import tensorflow as tf
from tensorflow.keras import layers
In memoria dati
Per qualsiasi set di dati CSV di piccole dimensioni, il modo più semplice per addestrare un modello TensorFlow su di esso è caricarlo in memoria come un Dataframe Panda o un array NumPy.
Un esempio relativamente semplice è il dataset abalone .
- Il set di dati è piccolo.
- Tutte le funzioni di input sono tutti valori in virgola mobile a intervallo limitato.
Ecco come scaricare i dati in un Pandas DataFrame :
abalone_train = pd.read_csv(
"https://storage.googleapis.com/download.tensorflow.org/data/abalone_train.csv",
names=["Length", "Diameter", "Height", "Whole weight", "Shucked weight",
"Viscera weight", "Shell weight", "Age"])
abalone_train.head()
Il set di dati contiene una serie di misurazioni di abalone , un tipo di lumaca di mare.

"Conchiglia di abalone" (di Nicki Dugan Pogue , CC BY-SA 2.0)
Il compito nominale per questo set di dati è prevedere l'età dalle altre misurazioni, quindi separare le caratteristiche e le etichette per l'allenamento:
abalone_features = abalone_train.copy()
abalone_labels = abalone_features.pop('Age')
Per questo set di dati tratterai tutte le funzionalità in modo identico. Confeziona le funzionalità in un unico array NumPy.:
abalone_features = np.array(abalone_features)
abalone_features
array([[0.435, 0.335, 0.11 , ..., 0.136, 0.077, 0.097],
[0.585, 0.45 , 0.125, ..., 0.354, 0.207, 0.225],
[0.655, 0.51 , 0.16 , ..., 0.396, 0.282, 0.37 ],
...,
[0.53 , 0.42 , 0.13 , ..., 0.374, 0.167, 0.249],
[0.395, 0.315, 0.105, ..., 0.118, 0.091, 0.119],
[0.45 , 0.355, 0.12 , ..., 0.115, 0.067, 0.16 ]])
Quindi crea un modello di regressione per prevedere l'età. Poiché esiste un solo tensore di input, qui è sufficiente un modello keras.Sequential .
abalone_model = tf.keras.Sequential([
layers.Dense(64),
layers.Dense(1)
])
abalone_model.compile(loss = tf.losses.MeanSquaredError(),
optimizer = tf.optimizers.Adam())
Per addestrare quel modello, passa le caratteristiche e le etichette a Model.fit :
abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 104/104 [==============================] - 1s 2ms/step - loss: 63.0446 Epoch 2/10 104/104 [==============================] - 0s 2ms/step - loss: 11.9429 Epoch 3/10 104/104 [==============================] - 0s 2ms/step - loss: 8.4836 Epoch 4/10 104/104 [==============================] - 0s 2ms/step - loss: 8.0052 Epoch 5/10 104/104 [==============================] - 0s 2ms/step - loss: 7.6073 Epoch 6/10 104/104 [==============================] - 0s 2ms/step - loss: 7.2485 Epoch 7/10 104/104 [==============================] - 0s 2ms/step - loss: 6.9883 Epoch 8/10 104/104 [==============================] - 0s 2ms/step - loss: 6.7977 Epoch 9/10 104/104 [==============================] - 0s 2ms/step - loss: 6.6477 Epoch 10/10 104/104 [==============================] - 0s 2ms/step - loss: 6.5359 <keras.callbacks.History at 0x7f70543c7350>
Hai appena visto il modo più semplice per addestrare un modello utilizzando i dati CSV. Successivamente, imparerai come applicare la preelaborazione per normalizzare le colonne numeriche.
Preelaborazione di base
È buona norma normalizzare gli input nel modello. I livelli di preelaborazione Keras forniscono un modo conveniente per costruire questa normalizzazione nel tuo modello.
Il livello precalcolerà la media e la varianza di ciascuna colonna e le utilizzerà per normalizzare i dati.
Per prima cosa crei il livello:
normalize = layers.Normalization()
Quindi usi il metodo Normalization.adapt() per adattare il livello di normalizzazione ai tuoi dati.
normalize.adapt(abalone_features)
Quindi usa il livello di normalizzazione nel tuo modello:
norm_abalone_model = tf.keras.Sequential([
normalize,
layers.Dense(64),
layers.Dense(1)
])
norm_abalone_model.compile(loss = tf.losses.MeanSquaredError(),
optimizer = tf.optimizers.Adam())
norm_abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 104/104 [==============================] - 0s 2ms/step - loss: 92.5851 Epoch 2/10 104/104 [==============================] - 0s 2ms/step - loss: 55.1199 Epoch 3/10 104/104 [==============================] - 0s 2ms/step - loss: 18.2937 Epoch 4/10 104/104 [==============================] - 0s 2ms/step - loss: 6.2633 Epoch 5/10 104/104 [==============================] - 0s 2ms/step - loss: 5.1257 Epoch 6/10 104/104 [==============================] - 0s 2ms/step - loss: 5.0217 Epoch 7/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9775 Epoch 8/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9730 Epoch 9/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9348 Epoch 10/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9416 <keras.callbacks.History at 0x7f70541b2a50>
Tipi di dati misti
Il set di dati "Titanic" contiene informazioni sui passeggeri del Titanic. Il compito nominale su questo set di dati è prevedere chi è sopravvissuto.

Immagine da Wikimedia
{kind=link}
I dati grezzi possono essere facilmente caricati come Pandas DataFrame , ma non sono immediatamente utilizzabili come input per un modello TensorFlow.
titanic = pd.read_csv("https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic.head()
titanic_features = titanic.copy()
titanic_labels = titanic_features.pop('survived')
A causa dei diversi tipi di dati e intervalli, non puoi semplicemente impilare le funzionalità nell'array NumPy e passarlo a un modello keras.Sequential . Ogni colonna deve essere gestita individualmente.
Come opzione, puoi preelaborare i tuoi dati offline (utilizzando qualsiasi strumento che ti piace) per convertire le colonne categoriali in colonne numeriche, quindi passare l'output elaborato al tuo modello TensorFlow. Lo svantaggio di questo approccio è che se salvi ed esporti il tuo modello, la preelaborazione non viene salvata con esso. I livelli di preelaborazione Keras evitano questo problema perché fanno parte del modello.
In questo esempio creerai un modello che implementa la logica di preelaborazione usando Keras Functional API . Potresti anche farlo sottoclasse .
L'API funzionale opera su tensori "simbolici". I normali tensori "desiderosi" hanno un valore. Al contrario, questi tensori "simbolici" non lo fanno. Al contrario, tengono traccia di quali operazioni vengono eseguite su di essi e creano una rappresentazione del calcolo, che puoi eseguire in seguito. Ecco un rapido esempio:
# Create a symbolic input
input = tf.keras.Input(shape=(), dtype=tf.float32)
# Perform a calculation using the input
result = 2*input + 1
# the result doesn't have a value
result
<KerasTensor: shape=(None,) dtype=float32 (created by layer 'tf.__operators__.add')>
calc = tf.keras.Model(inputs=input, outputs=result)
print(calc(1).numpy())
print(calc(2).numpy())
3.0 5.0
Per creare il modello di preelaborazione, inizia creando un insieme di oggetti simbolici keras.Input , corrispondenti ai nomi e ai tipi di dati delle colonne CSV.
inputs = {}
for name, column in titanic_features.items():
dtype = column.dtype
if dtype == object:
dtype = tf.string
else:
dtype = tf.float32
inputs[name] = tf.keras.Input(shape=(1,), name=name, dtype=dtype)
inputs
{'sex': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'sex')>,
'age': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'age')>,
'n_siblings_spouses': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'n_siblings_spouses')>,
'parch': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'parch')>,
'fare': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'fare')>,
'class': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'class')>,
'deck': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'deck')>,
'embark_town': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'embark_town')>,
'alone': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'alone')>}
Il primo passaggio nella logica di preelaborazione consiste nel concatenare insieme gli input numerici ed eseguirli attraverso un livello di normalizzazione:
numeric_inputs = {name:input for name,input in inputs.items()
if input.dtype==tf.float32}
x = layers.Concatenate()(list(numeric_inputs.values()))
norm = layers.Normalization()
norm.adapt(np.array(titanic[numeric_inputs.keys()]))
all_numeric_inputs = norm(x)
all_numeric_inputs
<KerasTensor: shape=(None, 4) dtype=float32 (created by layer 'normalization_1')>
Raccogliere tutti i risultati simbolici della preelaborazione, per concatenarli successivamente.
preprocessed_inputs = [all_numeric_inputs]
Per gli input di stringa, utilizzare la funzione tf.keras.layers.StringLookup per eseguire il mapping da stringhe a indici interi in un vocabolario. Quindi, usa tf.keras.layers.CategoryEncoding per convertire gli indici in dati float32 appropriati per il modello.
Le impostazioni predefinite per il livello tf.keras.layers.CategoryEncoding creano un vettore one-hot per ogni input. Un layers.Embedding funzionerebbe anche. Per ulteriori informazioni su questo argomento, vedere la guida ai livelli di preelaborazione e l' esercitazione .
for name, input in inputs.items():
if input.dtype == tf.float32:
continue
lookup = layers.StringLookup(vocabulary=np.unique(titanic_features[name]))
one_hot = layers.CategoryEncoding(max_tokens=lookup.vocab_size())
x = lookup(input)
x = one_hot(x)
preprocessed_inputs.append(x)
WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead.
Con la raccolta di inputs e processed_inputs , puoi concatenare tutti gli input preelaborati insieme e creare un modello che gestisca la preelaborazione:
preprocessed_inputs_cat = layers.Concatenate()(preprocessed_inputs)
titanic_preprocessing = tf.keras.Model(inputs, preprocessed_inputs_cat)
tf.keras.utils.plot_model(model = titanic_preprocessing , rankdir="LR", dpi=72, show_shapes=True)
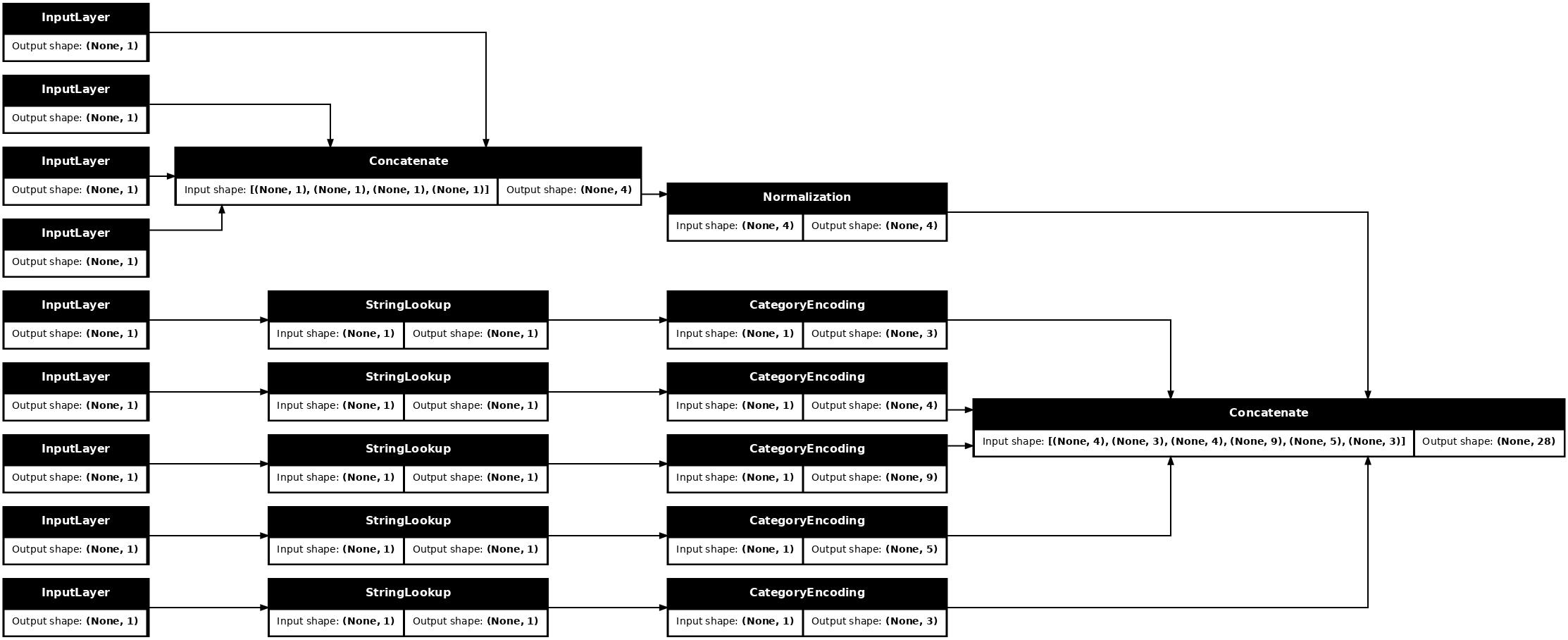
Questo model contiene solo la preelaborazione dell'input. Puoi eseguirlo per vedere cosa fa ai tuoi dati. I modelli Keras non convertono automaticamente Pandas DataFrames perché non è chiaro se debba essere convertito in un tensore o in un dizionario di tensori. Quindi convertilo in un dizionario di tensori:
titanic_features_dict = {name: np.array(value)
for name, value in titanic_features.items()}
Taglia il primo esempio di addestramento e passalo a questo modello di preelaborazione, vedrai le caratteristiche numeriche e le stringhe one-hot tutte concatenate insieme:
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
titanic_preprocessing(features_dict)
<tf.Tensor: shape=(1, 28), dtype=float32, numpy=
array([[-0.61 , 0.395, -0.479, -0.497, 0. , 0. , 1. , 0. ,
0. , 0. , 1. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 1. , 0. , 0. , 0. , 1. ,
0. , 0. , 1. , 0. ]], dtype=float32)>
Ora costruisci il modello su questo:
def titanic_model(preprocessing_head, inputs):
body = tf.keras.Sequential([
layers.Dense(64),
layers.Dense(1)
])
preprocessed_inputs = preprocessing_head(inputs)
result = body(preprocessed_inputs)
model = tf.keras.Model(inputs, result)
model.compile(loss=tf.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.optimizers.Adam())
return model
titanic_model = titanic_model(titanic_preprocessing, inputs)
Quando si addestra il modello, passare il dizionario delle funzioni come x e l'etichetta come y .
titanic_model.fit(x=titanic_features_dict, y=titanic_labels, epochs=10)
Epoch 1/10 20/20 [==============================] - 1s 4ms/step - loss: 0.8017 Epoch 2/10 20/20 [==============================] - 0s 4ms/step - loss: 0.5913 Epoch 3/10 20/20 [==============================] - 0s 5ms/step - loss: 0.5212 Epoch 4/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4841 Epoch 5/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4615 Epoch 6/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4470 Epoch 7/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4367 Epoch 8/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4304 Epoch 9/10 20/20 [==============================] - 0s 4ms/step - loss: 0.4265 Epoch 10/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4239 <keras.callbacks.History at 0x7f70b1f82a50>
Poiché la preelaborazione fa parte del modello, puoi salvare il modello e ricaricarlo da qualche altra parte e ottenere risultati identici:
titanic_model.save('test')
reloaded = tf.keras.models.load_model('test')
2022-01-26 06:36:18.822459: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: test/assets
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
before = titanic_model(features_dict)
after = reloaded(features_dict)
assert (before-after)<1e-3
print(before)
print(after)
tf.Tensor([[-1.791]], shape=(1, 1), dtype=float32) tf.Tensor([[-1.791]], shape=(1, 1), dtype=float32)
Usando tf.data
Nella sezione precedente, durante l'addestramento del modello, ti sei affidato alla mescolanza e al batch dei dati incorporati nel modello.
Se hai bisogno di un maggiore controllo sulla pipeline dei dati di input o devi usare dati che non si adattano facilmente alla memoria: usa tf.data .
Per ulteriori esempi, vedere la guida tf.data .
Dati in memoria attiva
Come primo esempio di applicazione di tf.data ai dati CSV, considera il codice seguente per suddividere manualmente il dizionario delle funzionalità della sezione precedente. Per ogni indice, prende quell'indice per ogni caratteristica:
import itertools
def slices(features):
for i in itertools.count():
# For each feature take index `i`
example = {name:values[i] for name, values in features.items()}
yield example
Esegui questo e stampa il primo esempio:
for example in slices(titanic_features_dict):
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : male age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : Third deck : unknown embark_town : Southampton alone : n
Il più semplice tf.data.Dataset nel caricatore di dati di memoria è il costruttore Dataset.from_tensor_slices . Questo restituisce un tf.data.Dataset che implementa una versione generalizzata della funzione delle slices sopra, in TensorFlow.
features_ds = tf.data.Dataset.from_tensor_slices(titanic_features_dict)
Puoi scorrere un tf.data.Dataset come qualsiasi altro iterabile Python:
for example in features_ds:
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : b'male' age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : b'Third' deck : b'unknown' embark_town : b'Southampton' alone : b'n'
La funzione from_tensor_slices può gestire qualsiasi struttura di dizionari o tuple nidificati. Il codice seguente crea un set di dati di coppie (features_dict, labels) :
titanic_ds = tf.data.Dataset.from_tensor_slices((titanic_features_dict, titanic_labels))
Per addestrare un modello utilizzando questo Dataset di dati , dovrai almeno shuffle e batch i dati.
titanic_batches = titanic_ds.shuffle(len(titanic_labels)).batch(32)
Invece di passare features ed labels a Model.fit , passi il set di dati:
titanic_model.fit(titanic_batches, epochs=5)
Epoch 1/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4230 Epoch 2/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4216 Epoch 3/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4203 Epoch 4/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4198 Epoch 5/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4194 <keras.callbacks.History at 0x7f70b12485d0>
Da un unico file
Finora questo tutorial ha funzionato con i dati in memoria. tf.data è un toolkit altamente scalabile per la creazione di pipeline di dati e fornisce alcune funzioni per gestire il caricamento di file CSV.
titanic_file_path = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
Downloading data from https://storage.googleapis.com/tf-datasets/titanic/train.csv 32768/30874 [===============================] - 0s 0us/step 40960/30874 [=======================================] - 0s 0us/step
Ora leggi i dati CSV dal file e crea un tf.data.Dataset .
(Per la documentazione completa, vedere tf.data.experimental.make_csv_dataset )
titanic_csv_ds = tf.data.experimental.make_csv_dataset(
titanic_file_path,
batch_size=5, # Artificially small to make examples easier to show.
label_name='survived',
num_epochs=1,
ignore_errors=True,)
Questa funzione include molte funzioni utili in modo che i dati siano facili da utilizzare. Ciò comprende:
- Utilizzo delle intestazioni delle colonne come chiavi del dizionario.
- Determinazione automatica del tipo di ciascuna colonna.
for batch, label in titanic_csv_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value}")
print()
print(f"{'label':20s}: {label}")
sex : [b'male' b'male' b'female' b'male' b'male'] age : [27. 18. 15. 46. 50.] n_siblings_spouses : [0 0 0 1 0] parch : [0 0 0 0 0] fare : [ 7.896 7.796 7.225 61.175 13. ] class : [b'Third' b'Third' b'Third' b'First' b'Second'] deck : [b'unknown' b'unknown' b'unknown' b'E' b'unknown'] embark_town : [b'Southampton' b'Southampton' b'Cherbourg' b'Southampton' b'Southampton'] alone : [b'y' b'y' b'y' b'n' b'y'] label : [0 0 1 0 0]
Può anche decomprimere i dati al volo. Ecco un file CSV compresso con gzip contenente il set di dati sul traffico interstatale della metropolitana

Immagine da Wikimedia
{kind=link}
traffic_volume_csv_gz = tf.keras.utils.get_file(
'Metro_Interstate_Traffic_Volume.csv.gz',
"https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz",
cache_dir='.', cache_subdir='traffic')
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz 409600/405373 [==============================] - 1s 1us/step 417792/405373 [==============================] - 1s 1us/step
Imposta l'argomento compression_type da leggere direttamente dal file compresso:
traffic_volume_csv_gz_ds = tf.data.experimental.make_csv_dataset(
traffic_volume_csv_gz,
batch_size=256,
label_name='traffic_volume',
num_epochs=1,
compression_type="GZIP")
for batch, label in traffic_volume_csv_gz_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value[:5]}")
print()
print(f"{'label':20s}: {label[:5]}")
holiday : [b'None' b'None' b'None' b'None' b'None'] temp : [280.56 266.79 281.64 292.71 270.48] rain_1h : [0. 0. 0. 0. 0.] snow_1h : [0. 0. 0. 0. 0.] clouds_all : [46 90 90 0 64] weather_main : [b'Clear' b'Clouds' b'Mist' b'Clear' b'Clouds'] weather_description : [b'sky is clear' b'overcast clouds' b'mist' b'Sky is Clear' b'broken clouds'] date_time : [b'2012-11-05 20:00:00' b'2012-12-17 23:00:00' b'2013-10-06 19:00:00' b'2013-08-23 22:00:00' b'2013-11-11 05:00:00'] label : [2415 966 3459 2633 2576]
Memorizzazione nella cache
C'è un sovraccarico per l'analisi dei dati CSV. Per i modelli piccoli questo può essere il collo di bottiglia nell'allenamento.
A seconda del caso d'uso, potrebbe essere una buona idea utilizzare Dataset.cache o data.experimental.snapshot modo che i dati CSV vengano analizzati solo nella prima epoca.
La principale differenza tra i metodi cache e snapshot è che i file cache possono essere utilizzati solo dal processo TensorFlow che li ha creati, ma i file snapshot possono essere letti da altri processi.
Ad esempio, l'iterazione di traffic_volume_csv_gz_ds 20 volte richiede circa 15 secondi senza memorizzazione nella cache o circa 2 secondi con memorizzazione nella cache.
%%time
for i, (batch, label) in enumerate(traffic_volume_csv_gz_ds.repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 14.9 s, sys: 3.7 s, total: 18.6 s Wall time: 11.2 s
%%time
caching = traffic_volume_csv_gz_ds.cache().shuffle(1000)
for i, (batch, label) in enumerate(caching.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 1.43 s, sys: 173 ms, total: 1.6 s Wall time: 1.28 s
%%time
snapshot = tf.data.experimental.snapshot('titanic.tfsnap')
snapshotting = traffic_volume_csv_gz_ds.apply(snapshot).shuffle(1000)
for i, (batch, label) in enumerate(snapshotting.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
WARNING:tensorflow:From <timed exec>:1: snapshot (from tensorflow.python.data.experimental.ops.snapshot) is deprecated and will be removed in a future version. Instructions for updating: Use `tf.data.Dataset.snapshot(...)`. ............................................................................................... CPU times: user 2.17 s, sys: 460 ms, total: 2.63 s Wall time: 1.6 s
Se il caricamento dei dati viene rallentato dal caricamento di file CSV e la cache e lo snapshot non sono sufficienti per il tuo caso d'uso, prendi in considerazione la ricodifica dei dati in un formato più snello.
File multipli
Tutti gli esempi finora in questa sezione potrebbero essere facilmente eseguiti senza tf.data . Un posto in cui tf.data può davvero semplificare le cose è quando si tratta di raccolte di file.
Ad esempio, il set di dati delle immagini dei caratteri dei caratteri viene distribuito come una raccolta di file CSV, uno per carattere.

Immagine di Willi Heidelbach da Pixabay
Scarica il set di dati e dai un'occhiata ai file all'interno:
fonts_zip = tf.keras.utils.get_file(
'fonts.zip', "https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip",
cache_dir='.', cache_subdir='fonts',
extract=True)
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip 160317440/160313983 [==============================] - 8s 0us/step 160325632/160313983 [==============================] - 8s 0us/step
import pathlib
font_csvs = sorted(str(p) for p in pathlib.Path('fonts').glob("*.csv"))
font_csvs[:10]
['fonts/AGENCY.csv', 'fonts/ARIAL.csv', 'fonts/BAITI.csv', 'fonts/BANKGOTHIC.csv', 'fonts/BASKERVILLE.csv', 'fonts/BAUHAUS.csv', 'fonts/BELL.csv', 'fonts/BERLIN.csv', 'fonts/BERNARD.csv', 'fonts/BITSTREAMVERA.csv']
len(font_csvs)
153
Quando hai a che fare con un mucchio di file puoi passare un file_pattern in stile glob alla funzione experimental.make_csv_dataset . L'ordine dei file viene mescolato a ogni iterazione.
Utilizzare l'argomento num_parallel_reads per impostare quanti file vengono letti in parallelo e intercalati insieme.
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=10, num_epochs=1,
num_parallel_reads=20,
shuffle_buffer_size=10000)
Questi file CSV hanno le immagini appiattite in un'unica riga. I nomi delle colonne sono formattati r{row}c{column} . Ecco il primo lotto:
for features in fonts_ds.take(1):
for i, (name, value) in enumerate(features.items()):
if i>15:
break
print(f"{name:20s}: {value}")
print('...')
print(f"[total: {len(features)} features]")
font : [b'HANDPRINT' b'NIAGARA' b'EUROROMAN' b'NIAGARA' b'CENTAUR' b'NINA' b'GOUDY' b'SITKA' b'BELL' b'SITKA'] fontVariant : [b'scanned' b'NIAGARA SOLID' b'EUROROMAN' b'NIAGARA SOLID' b'CENTAUR' b'NINA' b'GOUDY STOUT' b'SITKA TEXT' b'BELL MT' b'SITKA TEXT'] m_label : [ 49 8482 245 88 174 9643 77 974 117 339] strength : [0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4] italic : [0 0 0 1 0 0 1 0 1 0] orientation : [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] m_top : [ 0 32 24 32 28 57 38 48 51 64] m_left : [ 0 20 24 20 22 24 27 23 25 23] originalH : [20 27 55 47 50 15 51 50 27 34] originalW : [ 4 33 25 33 50 15 116 43 28 53] h : [20 20 20 20 20 20 20 20 20 20] w : [20 20 20 20 20 20 20 20 20 20] r0c0 : [ 1 255 255 1 1 255 1 1 1 1] r0c1 : [ 1 255 255 1 1 255 1 1 1 1] r0c2 : [ 1 217 255 1 1 255 54 1 1 1] r0c3 : [ 1 213 255 1 1 255 255 1 1 64] ... [total: 412 features]
Opzionale: campi di imballaggio
Probabilmente non vuoi lavorare con ogni pixel in colonne separate come questa. Prima di provare a utilizzare questo set di dati, assicurati di impacchettare i pixel in un tensore di immagine.
Ecco il codice che analizza i nomi delle colonne per creare immagini per ogni esempio:
import re
def make_images(features):
image = [None]*400
new_feats = {}
for name, value in features.items():
match = re.match('r(\d+)c(\d+)', name)
if match:
image[int(match.group(1))*20+int(match.group(2))] = value
else:
new_feats[name] = value
image = tf.stack(image, axis=0)
image = tf.reshape(image, [20, 20, -1])
new_feats['image'] = image
return new_feats
Applica quella funzione a ogni batch nel set di dati:
fonts_image_ds = fonts_ds.map(make_images)
for features in fonts_image_ds.take(1):
break
Traccia le immagini risultanti:
from matplotlib import pyplot as plt
plt.figure(figsize=(6,6), dpi=120)
for n in range(9):
plt.subplot(3,3,n+1)
plt.imshow(features['image'][..., n])
plt.title(chr(features['m_label'][n]))
plt.axis('off')

Funzioni di livello inferiore
Finora questo tutorial si è concentrato sulle utilità di livello più alto per la lettura di dati CSV. Ci sono altre due API che possono essere utili per utenti esperti se il tuo caso d'uso non si adatta ai modelli di base.
-
tf.io.decode_csv- una funzione per analizzare le righe di testo in un elenco di tensori di colonna CSV. -
tf.data.experimental.CsvDataset- un costruttore di set di dati CSV di livello inferiore.
Questa sezione ricrea la funzionalità fornita da make_csv_dataset , per dimostrare come è possibile utilizzare questa funzionalità di livello inferiore.
tf.io.decode_csv
Questa funzione decodifica una stringa o un elenco di stringhe in un elenco di colonne.
A differenza make_csv_dataset , questa funzione non tenta di indovinare i tipi di dati delle colonne. Specificare i tipi di colonna fornendo un elenco di record_defaults contenenti un valore del tipo corretto, per ciascuna colonna.
Per leggere i dati del Titanic come stringhe usando decode_csv diresti:
text = pathlib.Path(titanic_file_path).read_text()
lines = text.split('\n')[1:-1]
all_strings = [str()]*10
all_strings
['', '', '', '', '', '', '', '', '', '']
features = tf.io.decode_csv(lines, record_defaults=all_strings)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
Per analizzarli con i loro tipi effettivi, crea un elenco di record_defaults dei tipi corrispondenti:
print(lines[0])
0,male,22.0,1,0,7.25,Third,unknown,Southampton,n
titanic_types = [int(), str(), float(), int(), int(), float(), str(), str(), str(), str()]
titanic_types
[0, '', 0.0, 0, 0, 0.0, '', '', '', '']
features = tf.io.decode_csv(lines, record_defaults=titanic_types)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: int32, shape: (627,) type: string, shape: (627,) type: float32, shape: (627,) type: int32, shape: (627,) type: int32, shape: (627,) type: float32, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
tf.data.experimental.CsvDataset
La classe tf.data.experimental.CsvDataset fornisce un'interfaccia CSV Dataset minima senza le funzioni utili della funzione make_csv_dataset : analisi dell'intestazione di colonna, inferenza del tipo di colonna, mescolamento automatico, interleaving di file.
Questo costruttore segue usa record_defaults allo stesso modo di io.parse_csv :
simple_titanic = tf.data.experimental.CsvDataset(titanic_file_path, record_defaults=titanic_types, header=True)
for example in simple_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
Il codice sopra è sostanzialmente equivalente a:
def decode_titanic_line(line):
return tf.io.decode_csv(line, titanic_types)
manual_titanic = (
# Load the lines of text
tf.data.TextLineDataset(titanic_file_path)
# Skip the header row.
.skip(1)
# Decode the line.
.map(decode_titanic_line)
)
for example in manual_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
File multipli
Per analizzare il set di dati dei caratteri utilizzando experimental.CsvDataset , devi prima determinare i tipi di colonna per record_defaults . Inizia controllando la prima riga di un file:
font_line = pathlib.Path(font_csvs[0]).read_text().splitlines()[1]
print(font_line)
AGENCY,AGENCY FB,64258,0.400000,0,0.000000,35,21,51,22,20,20,1,1,1,21,101,210,255,255,255,255,255,255,255,255,255,255,255,255,255,255,1,1,1,93,255,255,255,176,146,146,146,146,146,146,146,146,216,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,141,141,141,182,255,255,255,172,141,141,141,115,1,1,1,1,163,255,255,255,255,255,255,255,255,255,255,255,255,255,255,209,1,1,1,1,163,255,255,255,6,6,6,96,255,255,255,74,6,6,6,5,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255
Solo i primi due campi sono stringhe, il resto sono int o float e puoi ottenere il numero totale di funzioni contando le virgole:
num_font_features = font_line.count(',')+1
font_column_types = [str(), str()] + [float()]*(num_font_features-2)
Il costruttore CsvDatasaet può prendere un elenco di file di input, ma li legge in sequenza. Il primo file nell'elenco dei CSV è AGENCY.csv :
font_csvs[0]
'fonts/AGENCY.csv'
Quindi, quando si passa l'elenco di file a CsvDataaset , i record da AGENCY.csv vengono letti per primi:
simple_font_ds = tf.data.experimental.CsvDataset(
font_csvs,
record_defaults=font_column_types,
header=True)
for row in simple_font_ds.take(10):
print(row[0].numpy())
b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY'
Per intercalare più file, utilizzare Dataset.interleave .
Ecco un set di dati iniziale che contiene i nomi dei file CSV:
font_files = tf.data.Dataset.list_files("fonts/*.csv")
Questo mescola i nomi dei file ogni epoca:
print('Epoch 1:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
print()
print('Epoch 2:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
Epoch 1:
b'fonts/CORBEL.csv'
b'fonts/GLOUCESTER.csv'
b'fonts/GABRIOLA.csv'
b'fonts/FORTE.csv'
b'fonts/GILL.csv'
...
Epoch 2:
b'fonts/MONEY.csv'
b'fonts/ISOC.csv'
b'fonts/DUTCH801.csv'
b'fonts/CALIBRI.csv'
b'fonts/ROMANTIC.csv'
...
Il metodo interleave accetta una map_func che crea un set di dati Dataset per ogni elemento del set di dati Dataset .
Qui, vuoi creare un CsvDataset da ogni elemento del set di dati dei file:
def make_font_csv_ds(path):
return tf.data.experimental.CsvDataset(
path,
record_defaults=font_column_types,
header=True)
Il Dataset di dati restituito da interleave restituisce elementi scorrendo un numero di set di dati Dataset . Nota, di seguito, come il set di dati scorre su cycle_length=3 tre file di font:
font_rows = font_files.interleave(make_font_csv_ds,
cycle_length=3)
fonts_dict = {'font_name':[], 'character':[]}
for row in font_rows.take(10):
fonts_dict['font_name'].append(row[0].numpy().decode())
fonts_dict['character'].append(chr(row[2].numpy()))
pd.DataFrame(fonts_dict)
Prestazione
In precedenza, è stato notato che io.decode_csv è più efficiente se eseguito su un batch di stringhe.
È possibile sfruttare questo fatto, quando si utilizzano batch di grandi dimensioni, per migliorare le prestazioni di caricamento CSV (ma provare prima a memorizzare nella cache ).
Con il caricatore integrato 20, i lotti di esempio 2048 richiedono circa 17 secondi.
BATCH_SIZE=2048
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=BATCH_SIZE, num_epochs=1,
num_parallel_reads=100)
%%time
for i,batch in enumerate(fonts_ds.take(20)):
print('.',end='')
print()
.................... CPU times: user 24.3 s, sys: 1.46 s, total: 25.7 s Wall time: 10.9 s
Il passaggio di batch di righe di testo a decode_csv viene eseguito più velocemente, in circa 5 secondi:
fonts_files = tf.data.Dataset.list_files("fonts/*.csv")
fonts_lines = fonts_files.interleave(
lambda fname:tf.data.TextLineDataset(fname).skip(1),
cycle_length=100).batch(BATCH_SIZE)
fonts_fast = fonts_lines.map(lambda x: tf.io.decode_csv(x, record_defaults=font_column_types))
%%time
for i,batch in enumerate(fonts_fast.take(20)):
print('.',end='')
print()
.................... CPU times: user 8.77 s, sys: 0 ns, total: 8.77 s Wall time: 1.57 s
Per un altro esempio di aumento delle prestazioni CSV utilizzando batch di grandi dimensioni, vedere l' esercitazione sull'overfit e sull'underfit .
Questo tipo di approccio può funzionare, ma considera altre opzioni come cache e snapshot o ricodifica i tuoi dati in un formato più snello.