
| | |  عرض المصدر على جيثب عرض المصدر على جيثب |
يقدم هذا البرنامج التعليمي أمثلة على كيفية استخدام بيانات CSV مع TensorFlow.
هناك جزئين رئيسيين لهذا:
- تحميل البيانات من القرص
- معالجتها مسبقًا في شكل مناسب للتدريب.
يركز هذا البرنامج التعليمي على التحميل ، ويقدم بعض الأمثلة السريعة للمعالجة المسبقة. للحصول على برنامج تعليمي يركز على جانب المعالجة المسبقة ، راجع دليل طبقات المعالجة المسبقة والبرنامج التعليمي .
يثبت
import pandas as pd
import numpy as np
# Make numpy values easier to read.
np.set_printoptions(precision=3, suppress=True)
import tensorflow as tf
from tensorflow.keras import layers
في بيانات الذاكرة
بالنسبة إلى أي مجموعة بيانات CSV صغيرة ، فإن أبسط طريقة لتدريب نموذج TensorFlow عليه هي تحميله في الذاكرة كإطار بيانات الباندا أو مصفوفة NumPy.
مثال بسيط نسبيًا هو مجموعة بيانات أذن البحر .
- مجموعة البيانات صغيرة.
- جميع ميزات الإدخال جميعها عبارة عن قيم فاصلة عائمة ذات نطاق محدود.
إليك كيفية تنزيل البيانات في Pandas DataFrame :
abalone_train = pd.read_csv(
"https://storage.googleapis.com/download.tensorflow.org/data/abalone_train.csv",
names=["Length", "Diameter", "Height", "Whole weight", "Shucked weight",
"Viscera weight", "Shell weight", "Age"])
abalone_train.head()
تحتوي مجموعة البيانات على مجموعة من قياسات أذن البحر ، وهو نوع من الحلزون البحري.

"صدفة أذن البحر" (بواسطة Nicki Dugan Pogue ، CC BY-SA 2.0)
تتمثل المهمة الاسمية لمجموعة البيانات هذه في توقع العمر من القياسات الأخرى ، لذلك افصل الميزات والتسميات للتدريب:
abalone_features = abalone_train.copy()
abalone_labels = abalone_features.pop('Age')
بالنسبة لمجموعة البيانات هذه ، ستتعامل مع جميع الميزات بشكل متماثل. قم بتجميع الميزات في مصفوفة NumPy واحدة:
abalone_features = np.array(abalone_features)
abalone_features
array([[0.435, 0.335, 0.11 , ..., 0.136, 0.077, 0.097],
[0.585, 0.45 , 0.125, ..., 0.354, 0.207, 0.225],
[0.655, 0.51 , 0.16 , ..., 0.396, 0.282, 0.37 ],
...,
[0.53 , 0.42 , 0.13 , ..., 0.374, 0.167, 0.249],
[0.395, 0.315, 0.105, ..., 0.118, 0.091, 0.119],
[0.45 , 0.355, 0.12 , ..., 0.115, 0.067, 0.16 ]])
بعد ذلك ، اجعل نموذج الانحدار يتنبأ بالعمر. نظرًا لوجود موتر إدخال واحد فقط ، فإن نموذج keras.Sequential يكفي هنا.
abalone_model = tf.keras.Sequential([
layers.Dense(64),
layers.Dense(1)
])
abalone_model.compile(loss = tf.losses.MeanSquaredError(),
optimizer = tf.optimizers.Adam())
لتدريب هذا النموذج ، قم بتمرير الميزات والتسميات إلى Model.fit :
abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 104/104 [==============================] - 1s 2ms/step - loss: 63.0446 Epoch 2/10 104/104 [==============================] - 0s 2ms/step - loss: 11.9429 Epoch 3/10 104/104 [==============================] - 0s 2ms/step - loss: 8.4836 Epoch 4/10 104/104 [==============================] - 0s 2ms/step - loss: 8.0052 Epoch 5/10 104/104 [==============================] - 0s 2ms/step - loss: 7.6073 Epoch 6/10 104/104 [==============================] - 0s 2ms/step - loss: 7.2485 Epoch 7/10 104/104 [==============================] - 0s 2ms/step - loss: 6.9883 Epoch 8/10 104/104 [==============================] - 0s 2ms/step - loss: 6.7977 Epoch 9/10 104/104 [==============================] - 0s 2ms/step - loss: 6.6477 Epoch 10/10 104/104 [==============================] - 0s 2ms/step - loss: 6.5359 <keras.callbacks.History at 0x7f70543c7350>
لقد رأيت للتو الطريقة الأساسية لتدريب نموذج باستخدام بيانات CSV. بعد ذلك ، سوف تتعلم كيفية تطبيق المعالجة المسبقة لتسوية الأعمدة الرقمية.
المعالجة الأساسية
إنها ممارسة جيدة لتطبيع المدخلات في النموذج الخاص بك. توفر طبقات المعالجة المسبقة لـ Keras طريقة ملائمة لبناء هذا التطبيع في نموذجك.
ستحسب الطبقة مسبقًا المتوسط والتباين لكل عمود ، وتستخدمهما لتسوية البيانات.
تقوم أولاً بإنشاء الطبقة:
normalize = layers.Normalization()
ثم تستخدم طريقة Normalization.adapt() لتكييف طبقة التسوية مع بياناتك.
normalize.adapt(abalone_features)
ثم استخدم طبقة التسوية في نموذجك:
norm_abalone_model = tf.keras.Sequential([
normalize,
layers.Dense(64),
layers.Dense(1)
])
norm_abalone_model.compile(loss = tf.losses.MeanSquaredError(),
optimizer = tf.optimizers.Adam())
norm_abalone_model.fit(abalone_features, abalone_labels, epochs=10)
Epoch 1/10 104/104 [==============================] - 0s 2ms/step - loss: 92.5851 Epoch 2/10 104/104 [==============================] - 0s 2ms/step - loss: 55.1199 Epoch 3/10 104/104 [==============================] - 0s 2ms/step - loss: 18.2937 Epoch 4/10 104/104 [==============================] - 0s 2ms/step - loss: 6.2633 Epoch 5/10 104/104 [==============================] - 0s 2ms/step - loss: 5.1257 Epoch 6/10 104/104 [==============================] - 0s 2ms/step - loss: 5.0217 Epoch 7/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9775 Epoch 8/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9730 Epoch 9/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9348 Epoch 10/10 104/104 [==============================] - 0s 2ms/step - loss: 4.9416 <keras.callbacks.History at 0x7f70541b2a50>
أنواع البيانات المختلطة
تحتوي مجموعة البيانات "تايتانيك" على معلومات حول ركاب تيتانيك. المهمة الاسمية في مجموعة البيانات هذه هي التنبؤ بمن نجا.

صورة من ويكيميديا
{kind=link}
يمكن تحميل البيانات الأولية بسهولة كإطار DataFrame ، ولكن لا يمكن استخدامها على الفور كمدخلات لنموذج TensorFlow.
titanic = pd.read_csv("https://storage.googleapis.com/tf-datasets/titanic/train.csv")
titanic.head()
titanic_features = titanic.copy()
titanic_labels = titanic_features.pop('survived')
نظرًا لأنواع البيانات والنطاقات المختلفة ، لا يمكنك ببساطة تكديس الميزات في مصفوفة NumPy وتمريرها إلى نموذج keras.Sequential . يجب معالجة كل عمود على حدة.
كخيار واحد ، يمكنك معالجة بياناتك مسبقًا دون اتصال بالإنترنت (باستخدام أي أداة تريدها) لتحويل الأعمدة الفئوية إلى أعمدة رقمية ، ثم تمرير الإخراج المعالج إلى نموذج TensorFlow الخاص بك. عيب هذا النهج هو أنه إذا قمت بحفظ النموذج الخاص بك وتصديره ، فلن يتم حفظ المعالجة المسبقة به. تتجنب طبقات المعالجة المسبقة Keras هذه المشكلة لأنها جزء من النموذج.
في هذا المثال ، ستنشئ نموذجًا يطبق منطق المعالجة المسبقة باستخدام واجهة برمجة تطبيقات Keras الوظيفية . يمكنك أيضًا القيام بذلك عن طريق التصنيف الفرعي .
تعمل واجهة برمجة التطبيقات الوظيفية على موترات "رمزية". موترات عادية "حريصة" لها قيمة. على النقيض من ذلك ، فإن هذه الموترات "الرمزية" لا تفعل ذلك. وبدلاً من ذلك ، فإنهم يتتبعون العمليات التي يتم إجراؤها عليهم ، ويبنون تمثيلاً للحسابات التي يمكنك إجراؤها لاحقًا. إليك مثال سريع:
# Create a symbolic input
input = tf.keras.Input(shape=(), dtype=tf.float32)
# Perform a calculation using the input
result = 2*input + 1
# the result doesn't have a value
result
<KerasTensor: shape=(None,) dtype=float32 (created by layer 'tf.__operators__.add')>
calc = tf.keras.Model(inputs=input, outputs=result)
print(calc(1).numpy())
print(calc(2).numpy())
3.0 5.0
لبناء نموذج المعالجة المسبقة ، ابدأ ببناء مجموعة من keras.Input الرمزية. أدخل كائنات تطابق أسماء وأنواع بيانات أعمدة CSV.
inputs = {}
for name, column in titanic_features.items():
dtype = column.dtype
if dtype == object:
dtype = tf.string
else:
dtype = tf.float32
inputs[name] = tf.keras.Input(shape=(1,), name=name, dtype=dtype)
inputs
{'sex': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'sex')>,
'age': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'age')>,
'n_siblings_spouses': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'n_siblings_spouses')>,
'parch': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'parch')>,
'fare': <KerasTensor: shape=(None, 1) dtype=float32 (created by layer 'fare')>,
'class': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'class')>,
'deck': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'deck')>,
'embark_town': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'embark_town')>,
'alone': <KerasTensor: shape=(None, 1) dtype=string (created by layer 'alone')>}
تتمثل الخطوة الأولى في منطق المعالجة المسبقة في تجميع المدخلات الرقمية معًا وتشغيلها عبر طبقة تسوية:
numeric_inputs = {name:input for name,input in inputs.items()
if input.dtype==tf.float32}
x = layers.Concatenate()(list(numeric_inputs.values()))
norm = layers.Normalization()
norm.adapt(np.array(titanic[numeric_inputs.keys()]))
all_numeric_inputs = norm(x)
all_numeric_inputs
<KerasTensor: shape=(None, 4) dtype=float32 (created by layer 'normalization_1')>
اجمع كل نتائج المعالجة المسبقة الرمزية ، لتسلسلها لاحقًا.
preprocessed_inputs = [all_numeric_inputs]
بالنسبة لمدخلات السلسلة ، استخدم الدالة tf.keras.layers.StringLookup من السلاسل إلى فهارس الأعداد الصحيحة في المفردات. بعد ذلك ، استخدم tf.keras.layers.CategoryEncoding لتحويل الفهارس إلى بيانات float32 مناسبة للنموذج.
الإعدادات الافتراضية لطبقة tf.keras.layers.CategoryEncoding تخلق متجهًا واحدًا ساخنًا لكل إدخال. طبقات ، كما أن عملية layers.Embedding أيضًا. راجع دليل طبقات المعالجة المسبقة والبرنامج التعليمي لمزيد من المعلومات حول هذا الموضوع.
for name, input in inputs.items():
if input.dtype == tf.float32:
continue
lookup = layers.StringLookup(vocabulary=np.unique(titanic_features[name]))
one_hot = layers.CategoryEncoding(max_tokens=lookup.vocab_size())
x = lookup(input)
x = one_hot(x)
preprocessed_inputs.append(x)
WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead. WARNING:tensorflow:vocab_size is deprecated, please use vocabulary_size. WARNING:tensorflow:max_tokens is deprecated, please use num_tokens instead.
من خلال مجموعة inputs processed_inputs ، يمكنك ربط جميع المدخلات المعالجة مسبقًا معًا ، وبناء نموذج يتعامل مع المعالجة المسبقة:
preprocessed_inputs_cat = layers.Concatenate()(preprocessed_inputs)
titanic_preprocessing = tf.keras.Model(inputs, preprocessed_inputs_cat)
tf.keras.utils.plot_model(model = titanic_preprocessing , rankdir="LR", dpi=72, show_shapes=True)
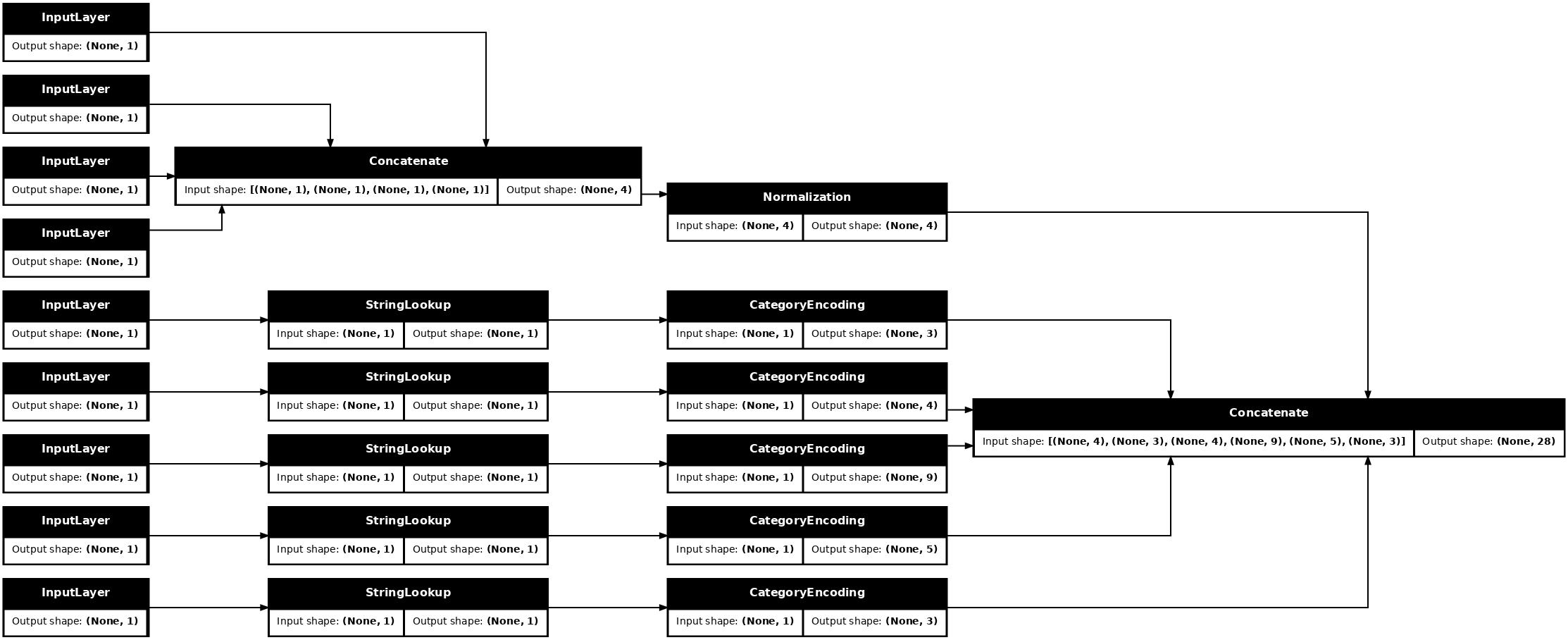
يحتوي هذا model فقط على مدخلات المعالجة المسبقة. يمكنك تشغيله لمعرفة ما يفعله ببياناتك. لا تقوم نماذج Keras تلقائيًا بتحويل Pandas DataFrames لأنه ليس من الواضح ما إذا كان يجب تحويلها إلى موتر واحد أم إلى قاموس موتر. لذا قم بتحويله إلى قاموس موترات:
titanic_features_dict = {name: np.array(value)
for name, value in titanic_features.items()}
قم بتقطيع المثال التدريبي الأول وقم بتمريره إلى نموذج المعالجة المسبقة هذا ، سترى الميزات الرقمية وسلسلة التسخين الواحد متسلسلة معًا:
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
titanic_preprocessing(features_dict)
<tf.Tensor: shape=(1, 28), dtype=float32, numpy=
array([[-0.61 , 0.395, -0.479, -0.497, 0. , 0. , 1. , 0. ,
0. , 0. , 1. , 0. , 0. , 0. , 0. , 0. ,
0. , 0. , 0. , 1. , 0. , 0. , 0. , 1. ,
0. , 0. , 1. , 0. ]], dtype=float32)>
الآن قم ببناء النموذج فوق هذا:
def titanic_model(preprocessing_head, inputs):
body = tf.keras.Sequential([
layers.Dense(64),
layers.Dense(1)
])
preprocessed_inputs = preprocessing_head(inputs)
result = body(preprocessed_inputs)
model = tf.keras.Model(inputs, result)
model.compile(loss=tf.losses.BinaryCrossentropy(from_logits=True),
optimizer=tf.optimizers.Adam())
return model
titanic_model = titanic_model(titanic_preprocessing, inputs)
عند تدريب النموذج ، مرر قاموس الميزات كـ x ، والتسمية كـ y .
titanic_model.fit(x=titanic_features_dict, y=titanic_labels, epochs=10)
Epoch 1/10 20/20 [==============================] - 1s 4ms/step - loss: 0.8017 Epoch 2/10 20/20 [==============================] - 0s 4ms/step - loss: 0.5913 Epoch 3/10 20/20 [==============================] - 0s 5ms/step - loss: 0.5212 Epoch 4/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4841 Epoch 5/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4615 Epoch 6/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4470 Epoch 7/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4367 Epoch 8/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4304 Epoch 9/10 20/20 [==============================] - 0s 4ms/step - loss: 0.4265 Epoch 10/10 20/20 [==============================] - 0s 5ms/step - loss: 0.4239 <keras.callbacks.History at 0x7f70b1f82a50>
نظرًا لأن المعالجة المسبقة جزء من النموذج ، يمكنك حفظ النموذج وإعادة تحميله في مكان آخر والحصول على نتائج متطابقة:
titanic_model.save('test')
reloaded = tf.keras.models.load_model('test')
2022-01-26 06:36:18.822459: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: test/assets
features_dict = {name:values[:1] for name, values in titanic_features_dict.items()}
before = titanic_model(features_dict)
after = reloaded(features_dict)
assert (before-after)<1e-3
print(before)
print(after)
tf.Tensor([[-1.791]], shape=(1, 1), dtype=float32) tf.Tensor([[-1.791]], shape=(1, 1), dtype=float32)
باستخدام tf.data
في القسم السابق ، اعتمدت على خلط البيانات المضمنة في النموذج وتجميعها أثناء تدريب النموذج.
إذا كنت بحاجة إلى مزيد من التحكم في خط أنابيب بيانات الإدخال أو كنت بحاجة إلى استخدام بيانات لا تتناسب بسهولة مع الذاكرة: استخدم tf.data .
لمزيد من الأمثلة ، راجع دليل tf.data .
تشغيل في بيانات الذاكرة
كمثال أولي لتطبيق tf.data على بيانات CSV ، ضع في اعتبارك الكود التالي لتقطيع قاموس الميزات يدويًا من القسم السابق. لكل فهرس ، يأخذ هذا الفهرس لكل ميزة:
import itertools
def slices(features):
for i in itertools.count():
# For each feature take index `i`
example = {name:values[i] for name, values in features.items()}
yield example
قم بتشغيل هذا واطبع المثال الأول:
for example in slices(titanic_features_dict):
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : male age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : Third deck : unknown embark_town : Southampton alone : n
تعتبر مجموعة البيانات الأساسية tf.data.Dataset في أداة تحميل بيانات الذاكرة هي مُنشئ Dataset.from_tensor_slices . يؤدي هذا إلى إرجاع tf.data.Dataset الذي يقوم بتنفيذ إصدار معمم من وظيفة slices أعلاه ، في TensorFlow.
features_ds = tf.data.Dataset.from_tensor_slices(titanic_features_dict)
يمكنك التكرار عبر tf.data.Dataset مثل أي Python أخرى قابلة للتكرار:
for example in features_ds:
for name, value in example.items():
print(f"{name:19s}: {value}")
break
sex : b'male' age : 22.0 n_siblings_spouses : 1 parch : 0 fare : 7.25 class : b'Third' deck : b'unknown' embark_town : b'Southampton' alone : b'n'
يمكن للدالة from_tensor_slices معالجة أي بنية من القواميس أو المجموعات المتداخلة. يُنشئ الكود التالي مجموعة بيانات من أزواج (features_dict, labels) :
titanic_ds = tf.data.Dataset.from_tensor_slices((titanic_features_dict, titanic_labels))
لتدريب نموذج باستخدام batch Dataset هذه ، ستحتاج على الأقل إلى تبديل البيانات shuffle بشكل عشوائي.
titanic_batches = titanic_ds.shuffle(len(titanic_labels)).batch(32)
بدلاً من تمرير features labels إلى Model.fit ، يمكنك تمرير مجموعة البيانات:
titanic_model.fit(titanic_batches, epochs=5)
Epoch 1/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4230 Epoch 2/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4216 Epoch 3/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4203 Epoch 4/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4198 Epoch 5/5 20/20 [==============================] - 0s 5ms/step - loss: 0.4194 <keras.callbacks.History at 0x7f70b12485d0>
من ملف واحد
لقد عمل هذا البرنامج التعليمي حتى الآن مع البيانات الموجودة في الذاكرة. tf.data عبارة عن مجموعة أدوات قابلة للتوسع بشكل كبير لبناء خطوط أنابيب البيانات ، وتوفر بعض الوظائف للتعامل مع تحميل ملفات CSV.
titanic_file_path = tf.keras.utils.get_file("train.csv", "https://storage.googleapis.com/tf-datasets/titanic/train.csv")
Downloading data from https://storage.googleapis.com/tf-datasets/titanic/train.csv 32768/30874 [===============================] - 0s 0us/step 40960/30874 [=======================================] - 0s 0us/step
اقرأ الآن بيانات CSV من الملف وأنشئ ملف tf.data.Dataset .
(للحصول على الوثائق الكاملة ، راجع tf.data.experimental.make_csv_dataset )
titanic_csv_ds = tf.data.experimental.make_csv_dataset(
titanic_file_path,
batch_size=5, # Artificially small to make examples easier to show.
label_name='survived',
num_epochs=1,
ignore_errors=True,)
تتضمن هذه الوظيفة العديد من الميزات الملائمة بحيث يسهل التعامل مع البيانات. هذا يتضمن:
- استخدام رؤوس الأعمدة كمفاتيح القاموس.
- تحديد نوع كل عمود تلقائيًا.
for batch, label in titanic_csv_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value}")
print()
print(f"{'label':20s}: {label}")
sex : [b'male' b'male' b'female' b'male' b'male'] age : [27. 18. 15. 46. 50.] n_siblings_spouses : [0 0 0 1 0] parch : [0 0 0 0 0] fare : [ 7.896 7.796 7.225 61.175 13. ] class : [b'Third' b'Third' b'Third' b'First' b'Second'] deck : [b'unknown' b'unknown' b'unknown' b'E' b'unknown'] embark_town : [b'Southampton' b'Southampton' b'Cherbourg' b'Southampton' b'Southampton'] alone : [b'y' b'y' b'y' b'n' b'y'] label : [0 0 1 0 0]
يمكنه أيضًا فك ضغط البيانات أثناء التنقل. إليك ملف CSV مضغوط بتنسيق gz يحتوي على مجموعة بيانات حركة مرور المترو بين الولايات

صورة من ويكيميديا
{kind=link}
traffic_volume_csv_gz = tf.keras.utils.get_file(
'Metro_Interstate_Traffic_Volume.csv.gz',
"https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz",
cache_dir='.', cache_subdir='traffic')
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00492/Metro_Interstate_Traffic_Volume.csv.gz 409600/405373 [==============================] - 1s 1us/step 417792/405373 [==============================] - 1s 1us/step
قم بتعيين الوسيطة compression_type للقراءة مباشرة من الملف المضغوط:
traffic_volume_csv_gz_ds = tf.data.experimental.make_csv_dataset(
traffic_volume_csv_gz,
batch_size=256,
label_name='traffic_volume',
num_epochs=1,
compression_type="GZIP")
for batch, label in traffic_volume_csv_gz_ds.take(1):
for key, value in batch.items():
print(f"{key:20s}: {value[:5]}")
print()
print(f"{'label':20s}: {label[:5]}")
holiday : [b'None' b'None' b'None' b'None' b'None'] temp : [280.56 266.79 281.64 292.71 270.48] rain_1h : [0. 0. 0. 0. 0.] snow_1h : [0. 0. 0. 0. 0.] clouds_all : [46 90 90 0 64] weather_main : [b'Clear' b'Clouds' b'Mist' b'Clear' b'Clouds'] weather_description : [b'sky is clear' b'overcast clouds' b'mist' b'Sky is Clear' b'broken clouds'] date_time : [b'2012-11-05 20:00:00' b'2012-12-17 23:00:00' b'2013-10-06 19:00:00' b'2013-08-23 22:00:00' b'2013-11-11 05:00:00'] label : [2415 966 3459 2633 2576]
التخزين المؤقت
يوجد بعض الحمل الزائد لتحليل بيانات csv. بالنسبة للنماذج الصغيرة ، يمكن أن يكون هذا هو عنق الزجاجة في التدريب.
اعتمادًا على حالة الاستخدام الخاصة بك ، قد يكون من الجيد استخدام Dataset.cache أو data.experimental.snapshot بحيث يتم تحليل بيانات csv في المرحلة الأولى فقط.
يتمثل الاختلاف الرئيسي بين طرق cache وطريقة snapshot في أنه لا يمكن استخدام ملفات cache إلا بواسطة عملية TensorFlow التي أنشأتها ، ولكن يمكن قراءة ملفات snapshot بواسطة عمليات أخرى.
على سبيل المثال ، يستغرق التكرار عبر traffic_volume_csv_gz_ds 20 مرة حوالي 15 ثانية بدون تخزين مؤقت أو ~ 2 ثانية مع التخزين المؤقت.
%%time
for i, (batch, label) in enumerate(traffic_volume_csv_gz_ds.repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 14.9 s, sys: 3.7 s, total: 18.6 s Wall time: 11.2 s
%%time
caching = traffic_volume_csv_gz_ds.cache().shuffle(1000)
for i, (batch, label) in enumerate(caching.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
............................................................................................... CPU times: user 1.43 s, sys: 173 ms, total: 1.6 s Wall time: 1.28 s
%%time
snapshot = tf.data.experimental.snapshot('titanic.tfsnap')
snapshotting = traffic_volume_csv_gz_ds.apply(snapshot).shuffle(1000)
for i, (batch, label) in enumerate(snapshotting.shuffle(1000).repeat(20)):
if i % 40 == 0:
print('.', end='')
print()
WARNING:tensorflow:From <timed exec>:1: snapshot (from tensorflow.python.data.experimental.ops.snapshot) is deprecated and will be removed in a future version. Instructions for updating: Use `tf.data.Dataset.snapshot(...)`. ............................................................................................... CPU times: user 2.17 s, sys: 460 ms, total: 2.63 s Wall time: 1.6 s
إذا كان تحميل البيانات بطيئًا عن طريق تحميل ملفات csv ، وكانت cache snapshot غير كافيتين لحالة الاستخدام ، ففكر في إعادة تشفير بياناتك إلى تنسيق أكثر انسيابية.
ملفات متعددة
يمكن بسهولة تنفيذ جميع الأمثلة في هذا القسم حتى الآن بدون tf.data . أحد الأماكن التي يمكن أن تبسط فيها tf.data الأشياء حقًا هو التعامل مع مجموعات من الملفات.
على سبيل المثال ، يتم توزيع مجموعة بيانات صور خط الأحرف كمجموعة من ملفات csv ، واحد لكل خط.

صورة ويلي هايدلباخ من بيكساباي
قم بتنزيل مجموعة البيانات ، وإلقاء نظرة على الملفات الموجودة بداخلها:
fonts_zip = tf.keras.utils.get_file(
'fonts.zip', "https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip",
cache_dir='.', cache_subdir='fonts',
extract=True)
Downloading data from https://archive.ics.uci.edu/ml/machine-learning-databases/00417/fonts.zip 160317440/160313983 [==============================] - 8s 0us/step 160325632/160313983 [==============================] - 8s 0us/step
import pathlib
font_csvs = sorted(str(p) for p in pathlib.Path('fonts').glob("*.csv"))
font_csvs[:10]
['fonts/AGENCY.csv', 'fonts/ARIAL.csv', 'fonts/BAITI.csv', 'fonts/BANKGOTHIC.csv', 'fonts/BASKERVILLE.csv', 'fonts/BAUHAUS.csv', 'fonts/BELL.csv', 'fonts/BERLIN.csv', 'fonts/BERNARD.csv', 'fonts/BITSTREAMVERA.csv']
len(font_csvs)
153
عند التعامل مع مجموعة من الملفات ، يمكنك تمرير file_pattern بنمط الكرة الأرضية إلى الوظيفة experimental.make_csv_dataset .make_csv_dataset. يتم ترتيب الملفات عشوائيًا في كل تكرار.
استخدم الوسيطة num_parallel_reads لتعيين عدد الملفات المقروءة بالتوازي والمتداخلة معًا.
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=10, num_epochs=1,
num_parallel_reads=20,
shuffle_buffer_size=10000)
تحتوي ملفات csv هذه على الصور مسطحة في صف واحد. تم تنسيق أسماء الأعمدة r{row}c{column} . ها هي الدفعة الأولى:
for features in fonts_ds.take(1):
for i, (name, value) in enumerate(features.items()):
if i>15:
break
print(f"{name:20s}: {value}")
print('...')
print(f"[total: {len(features)} features]")
font : [b'HANDPRINT' b'NIAGARA' b'EUROROMAN' b'NIAGARA' b'CENTAUR' b'NINA' b'GOUDY' b'SITKA' b'BELL' b'SITKA'] fontVariant : [b'scanned' b'NIAGARA SOLID' b'EUROROMAN' b'NIAGARA SOLID' b'CENTAUR' b'NINA' b'GOUDY STOUT' b'SITKA TEXT' b'BELL MT' b'SITKA TEXT'] m_label : [ 49 8482 245 88 174 9643 77 974 117 339] strength : [0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.4] italic : [0 0 0 1 0 0 1 0 1 0] orientation : [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] m_top : [ 0 32 24 32 28 57 38 48 51 64] m_left : [ 0 20 24 20 22 24 27 23 25 23] originalH : [20 27 55 47 50 15 51 50 27 34] originalW : [ 4 33 25 33 50 15 116 43 28 53] h : [20 20 20 20 20 20 20 20 20 20] w : [20 20 20 20 20 20 20 20 20 20] r0c0 : [ 1 255 255 1 1 255 1 1 1 1] r0c1 : [ 1 255 255 1 1 255 1 1 1 1] r0c2 : [ 1 217 255 1 1 255 54 1 1 1] r0c3 : [ 1 213 255 1 1 255 255 1 1 64] ... [total: 412 features]
اختياري: حقول التعبئة
ربما لا ترغب في العمل مع كل بكسل في أعمدة منفصلة مثل هذه. قبل محاولة استخدام مجموعة البيانات هذه ، تأكد من حزم وحدات البكسل في موتر الصورة.
إليك رمز يوزع أسماء الأعمدة لإنشاء صور لكل مثال:
import re
def make_images(features):
image = [None]*400
new_feats = {}
for name, value in features.items():
match = re.match('r(\d+)c(\d+)', name)
if match:
image[int(match.group(1))*20+int(match.group(2))] = value
else:
new_feats[name] = value
image = tf.stack(image, axis=0)
image = tf.reshape(image, [20, 20, -1])
new_feats['image'] = image
return new_feats
طبق هذه الوظيفة على كل دفعة في مجموعة البيانات:
fonts_image_ds = fonts_ds.map(make_images)
for features in fonts_image_ds.take(1):
break
ارسم الصور الناتجة:
from matplotlib import pyplot as plt
plt.figure(figsize=(6,6), dpi=120)
for n in range(9):
plt.subplot(3,3,n+1)
plt.imshow(features['image'][..., n])
plt.title(chr(features['m_label'][n]))
plt.axis('off')

وظائف المستوى الأدنى
حتى الآن ، ركز هذا البرنامج التعليمي على أعلى مستوى من الأدوات المساعدة لقراءة بيانات csv. هناك نوعان من واجهات برمجة التطبيقات الأخرى التي قد تكون مفيدة للمستخدمين المتقدمين إذا كانت حالة الاستخدام الخاصة بك لا تتناسب مع الأنماط الأساسية.
-
tf.io.decode_csv- وظيفة لتحليل سطور النص في قائمة موترات عمود CSV. -
tf.data.experimental.CsvDataset- مُنشئ مجموعة بيانات csv منخفض المستوى.
يعيد هذا القسم إنشاء الوظائف التي توفرها make_csv_dataset ، لتوضيح كيفية استخدام وظيفة المستوى الأدنى هذه.
tf.io.decode_csv
تقوم هذه الوظيفة بفك تشفير سلسلة أو قائمة سلاسل في قائمة أعمدة.
على عكس make_csv_dataset ، لا تحاول هذه الوظيفة تخمين أنواع بيانات العمود. يمكنك تحديد أنواع الأعمدة من خلال توفير قائمة record_defaults تحتوي على قيمة من النوع الصحيح لكل عمود.
لقراءة بيانات تيتانيك كسلاسل باستخدام decode_csv ، ستقول:
text = pathlib.Path(titanic_file_path).read_text()
lines = text.split('\n')[1:-1]
all_strings = [str()]*10
all_strings
['', '', '', '', '', '', '', '', '', '']
features = tf.io.decode_csv(lines, record_defaults=all_strings)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
لتحليلها بأنواعها الفعلية ، قم بإنشاء قائمة من record_defaults للأنواع المقابلة:
print(lines[0])
0,male,22.0,1,0,7.25,Third,unknown,Southampton,n
titanic_types = [int(), str(), float(), int(), int(), float(), str(), str(), str(), str()]
titanic_types
[0, '', 0.0, 0, 0, 0.0, '', '', '', '']
features = tf.io.decode_csv(lines, record_defaults=titanic_types)
for f in features:
print(f"type: {f.dtype.name}, shape: {f.shape}")
type: int32, shape: (627,) type: string, shape: (627,) type: float32, shape: (627,) type: int32, shape: (627,) type: int32, shape: (627,) type: float32, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,) type: string, shape: (627,)
tf.data.experimental.CsvDataset
توفر فئة tf.data.experimental.CsvDataset الحد الأدنى من واجهة Dataset CSV دون الميزات الملائمة لوظيفة make_csv_dataset : تحليل رأس العمود ، واستدلال نوع العمود ، والخلط التلقائي ، وتشذير الملفات.
يتبع هذا المُنشئ استخدام record_defaults بنفس طريقة io.parse_csv :
simple_titanic = tf.data.experimental.CsvDataset(titanic_file_path, record_defaults=titanic_types, header=True)
for example in simple_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
الكود أعلاه يعادل في الأساس:
def decode_titanic_line(line):
return tf.io.decode_csv(line, titanic_types)
manual_titanic = (
# Load the lines of text
tf.data.TextLineDataset(titanic_file_path)
# Skip the header row.
.skip(1)
# Decode the line.
.map(decode_titanic_line)
)
for example in manual_titanic.take(1):
print([e.numpy() for e in example])
[0, b'male', 22.0, 1, 0, 7.25, b'Third', b'unknown', b'Southampton', b'n']
ملفات متعددة
لتحليل مجموعة بيانات الخطوط باستخدام experimental.CsvDataset .CsvDataset ، تحتاج أولاً إلى تحديد أنواع الأعمدة record_defaults . ابدأ بفحص الصف الأول من ملف واحد:
font_line = pathlib.Path(font_csvs[0]).read_text().splitlines()[1]
print(font_line)
AGENCY,AGENCY FB,64258,0.400000,0,0.000000,35,21,51,22,20,20,1,1,1,21,101,210,255,255,255,255,255,255,255,255,255,255,255,255,255,255,1,1,1,93,255,255,255,176,146,146,146,146,146,146,146,146,216,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,141,141,141,182,255,255,255,172,141,141,141,115,1,1,1,1,163,255,255,255,255,255,255,255,255,255,255,255,255,255,255,209,1,1,1,1,163,255,255,255,6,6,6,96,255,255,255,74,6,6,6,5,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255,1,1,1,93,255,255,255,70,1,1,1,1,1,1,1,1,163,255,255,255
أول حقلين فقط عبارة عن سلاسل ، والباقي عبارة عن ints أو عائم ، ويمكنك الحصول على العدد الإجمالي للميزات عن طريق حساب الفواصل:
num_font_features = font_line.count(',')+1
font_column_types = [str(), str()] + [float()]*(num_font_features-2)
يمكن CsvDatasaet أخذ قائمة بملفات الإدخال ، ولكن يقرأها بالتسلسل. الملف الأول في قائمة ملفات CSV هو AGENCY.csv :
font_csvs[0]
'fonts/AGENCY.csv'
لذلك عند تمرير قائمة الملفات إلى CsvDataaset ، تتم قراءة السجلات من AGENCY.csv أولاً:
simple_font_ds = tf.data.experimental.CsvDataset(
font_csvs,
record_defaults=font_column_types,
header=True)
for row in simple_font_ds.take(10):
print(row[0].numpy())
b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY' b'AGENCY'
لدمج ملفات متعددة ، استخدم Dataset.interleave .
فيما يلي مجموعة بيانات أولية تحتوي على أسماء ملفات csv:
font_files = tf.data.Dataset.list_files("fonts/*.csv")
يؤدي هذا إلى خلط أسماء الملفات في كل فترة:
print('Epoch 1:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
print()
print('Epoch 2:')
for f in list(font_files)[:5]:
print(" ", f.numpy())
print(' ...')
Epoch 1:
b'fonts/CORBEL.csv'
b'fonts/GLOUCESTER.csv'
b'fonts/GABRIOLA.csv'
b'fonts/FORTE.csv'
b'fonts/GILL.csv'
...
Epoch 2:
b'fonts/MONEY.csv'
b'fonts/ISOC.csv'
b'fonts/DUTCH801.csv'
b'fonts/CALIBRI.csv'
b'fonts/ROMANTIC.csv'
...
تأخذ طريقة interleave map_func الذي يُنشئ مجموعة Dataset فرعية لكل عنصر من Dataset الأصل.
هنا ، تريد إنشاء CsvDataset من كل عنصر من عناصر مجموعة بيانات الملفات:
def make_font_csv_ds(path):
return tf.data.experimental.CsvDataset(
path,
record_defaults=font_column_types,
header=True)
Dataset التي تم إرجاعها بواسطة عناصر إرجاع متداخلة عن طريق التدوير على عدد من Dataset . لاحظ ، أدناه ، كيف تدور مجموعة البيانات خلال cycle_length=3 ملفات الخطوط الثلاثة:
font_rows = font_files.interleave(make_font_csv_ds,
cycle_length=3)
fonts_dict = {'font_name':[], 'character':[]}
for row in font_rows.take(10):
fonts_dict['font_name'].append(row[0].numpy().decode())
fonts_dict['character'].append(chr(row[2].numpy()))
pd.DataFrame(fonts_dict)
أداء
في وقت سابق ، لوحظ أن io.decode_csv يكون أكثر كفاءة عند تشغيله على مجموعة من السلاسل.
من الممكن الاستفادة من هذه الحقيقة ، عند استخدام أحجام دُفعات كبيرة ، لتحسين أداء تحميل ملف CSV (ولكن حاول التخزين المؤقت أولاً).
مع اللودر المدمج 20 ، 2048 مثال للدفعات يستغرق حوالي 17 ثانية.
BATCH_SIZE=2048
fonts_ds = tf.data.experimental.make_csv_dataset(
file_pattern = "fonts/*.csv",
batch_size=BATCH_SIZE, num_epochs=1,
num_parallel_reads=100)
%%time
for i,batch in enumerate(fonts_ds.take(20)):
print('.',end='')
print()
.................... CPU times: user 24.3 s, sys: 1.46 s, total: 25.7 s Wall time: 10.9 s
يتم تمرير مجموعات من سطور النص إلى decode_csv بشكل أسرع ، في حوالي 5 ثوانٍ:
fonts_files = tf.data.Dataset.list_files("fonts/*.csv")
fonts_lines = fonts_files.interleave(
lambda fname:tf.data.TextLineDataset(fname).skip(1),
cycle_length=100).batch(BATCH_SIZE)
fonts_fast = fonts_lines.map(lambda x: tf.io.decode_csv(x, record_defaults=font_column_types))
%%time
for i,batch in enumerate(fonts_fast.take(20)):
print('.',end='')
print()
.................... CPU times: user 8.77 s, sys: 0 ns, total: 8.77 s Wall time: 1.57 s
للحصول على مثال آخر لزيادة أداء csv باستخدام دفعات كبيرة ، راجع البرنامج التعليمي overfit and underfit .
قد ينجح هذا النوع من النهج ، ولكن ضع في اعتبارك خيارات أخرى مثل cache snapshot ، أو إعادة تشفير بياناتك إلى تنسيق أكثر انسيابية.