
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
این راهنما یک مدل شبکه عصبی را برای طبقهبندی تصاویر لباسها مانند کفشهای کتانی و پیراهن آموزش میدهد. اشکالی ندارد اگر همه جزئیات را درک نکنید. این یک نمای کلی سریع از یک برنامه کامل TensorFlow است که در حین رفتن جزئیات آن توضیح داده شده است.
این راهنما از tf.keras ، یک API سطح بالا برای ساخت و آموزش مدلها در TensorFlow استفاده میکند.
# TensorFlow and tf.keras
import tensorflow as tf
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)
2.8.0-rc1
مجموعه داده Fashion MNIST را وارد کنید
این راهنما از مجموعه داده های Fashion MNIST استفاده می کند که شامل 70000 تصویر خاکستری در 10 دسته است. تصاویر تک تک لباس ها را با وضوح پایین (28 در 28 پیکسل) نشان می دهند، همانطور که در اینجا مشاهده می کنید:
| شکل 1. نمونه های Fashion-MNIST (توسط Zalando، MIT License). |
Fashion MNIST به عنوان جایگزینی برای مجموعه داده کلاسیک MNIST در نظر گرفته شده است - که اغلب به عنوان "Hello, World" برنامه های یادگیری ماشین برای بینایی کامپیوتر استفاده می شود. مجموعه داده MNIST حاوی تصاویری از ارقام دست نویس (0، 1، 2، و غیره) در قالبی مشابه با قالب مقالات لباسی است که در اینجا استفاده می کنید.
این راهنما از Fashion MNIST برای تنوع استفاده می کند، و به دلیل اینکه مشکل کمی چالش برانگیزتر از MNIST معمولی است. هر دو مجموعه داده نسبتا کوچک هستند و برای تأیید اینکه یک الگوریتم همانطور که انتظار می رود کار می کند استفاده می شود. آنها نقطه شروع خوبی برای آزمایش و اشکال زدایی کد هستند.
در اینجا، 60000 تصویر برای آموزش شبکه و 10000 تصویر برای ارزیابی میزان دقت شبکه برای طبقه بندی تصاویر استفاده می شود. می توانید مستقیماً از TensorFlow به Fashion MNIST دسترسی پیدا کنید. داده های Fashion MNIST را مستقیماً از TensorFlow وارد و بارگذاری کنید :
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
بارگیری مجموعه داده چهار آرایه NumPy را برمی گرداند:
- آرایههای
train_imagesوtrain_labelsمجموعه آموزشی هستند - دادههایی که مدل برای یادگیری استفاده میکند. - مدل در برابر مجموعه تست ، آرایه
test_imagesوtest_labelsمی شود.
تصاویر آرایههای NumPy 28x28، با مقادیر پیکسلی از 0 تا 255 هستند. برچسبها آرایهای از اعداد صحیح هستند که از 0 تا 9 متغیر است. اینها با کلاس لباسی که تصویر نشان میدهد مطابقت دارد:
| برچسب | کلاس |
|---|---|
| 0 | تی شرت/تاپ |
| 1 | شلوار |
| 2 | پلیور |
| 3 | لباس پوشیدن |
| 4 | کت |
| 5 | کفش راحتی |
| 6 | پیراهن |
| 7 | کفش ورزشی |
| 8 | کیسه |
| 9 | نیم بوت |
هر تصویر به یک برچسب نگاشت می شود. از آنجایی که نام کلاس ها در مجموعه داده گنجانده نشده است، آنها را در اینجا ذخیره کنید تا بعداً هنگام ترسیم تصاویر از آنها استفاده کنید:
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
داده ها را کاوش کنید
بیایید قبل از آموزش مدل، قالب مجموعه داده را بررسی کنیم. موارد زیر نشان می دهد که 60000 تصویر در مجموعه آموزشی وجود دارد که هر تصویر به صورت 28 x 28 پیکسل نمایش داده می شود:
train_images.shape
(60000, 28, 28)
به همین ترتیب، 60000 برچسب در مجموعه آموزشی وجود دارد:
len(train_labels)
60000
هر برچسب یک عدد صحیح بین 0 و 9 است:
train_labels
array([9, 0, 0, ..., 3, 0, 5], dtype=uint8)
10000 تصویر در مجموعه تست وجود دارد. باز هم، هر تصویر به صورت 28 x 28 پیکسل نمایش داده می شود:
test_images.shape
(10000, 28, 28)
و مجموعه آزمایشی شامل 10000 برچسب تصویر است:
len(test_labels)
10000
داده ها را از قبل پردازش کنید
داده ها باید قبل از آموزش شبکه پیش پردازش شوند. اگر اولین تصویر را در مجموعه آموزشی بررسی کنید، خواهید دید که مقادیر پیکسل در محدوده 0 تا 255 قرار می گیرند:
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()
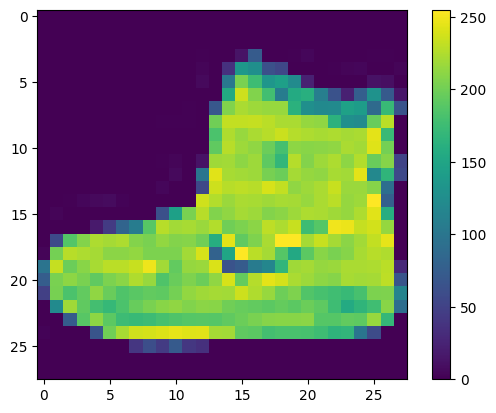
این مقادیر را قبل از وارد کردن آنها به مدل شبکه عصبی در محدوده 0 تا 1 مقیاس کنید. برای انجام این کار، مقادیر را بر 255 تقسیم کنید. مهم است که مجموعه آموزشی و مجموعه آزمایشی به همین ترتیب پیش پردازش شوند:
train_images = train_images / 255.0
test_images = test_images / 255.0
برای اطمینان از اینکه داده ها در فرمت صحیح هستند و آماده ساختن و آموزش شبکه هستید، بیایید 25 تصویر اول از مجموعه آموزشی را نمایش دهیم و نام کلاس را در زیر هر تصویر نمایش دهیم.
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()

مدل را بسازید
ساخت شبکه عصبی مستلزم پیکربندی لایه های مدل و سپس کامپایل مدل است.
لایه ها را تنظیم کنید
بلوک اصلی یک شبکه عصبی لایه است. لایه ها نمایش هایی را از داده های وارد شده به آنها استخراج می کنند. امیدواریم که این بازنمایی ها برای مشکل مورد نظر معنادار باشند.
بیشتر یادگیری عمیق شامل زنجیر کردن لایه های ساده است. اکثر لایه ها مانند tf.keras.layers.Dense دارای پارامترهایی هستند که در طول آموزش یاد می گیرند.
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10)
])
اولین لایه در این شبکه، tf.keras.layers.Flatten ، فرمت تصاویر را از یک آرایه دو بعدی (28 در 28 پیکسل) به یک آرایه یک بعدی (28 * 28 = 784 پیکسل) تبدیل می کند. این لایه را بهعنوان جدا کردن ردیفهایی از پیکسلها در تصویر و ردیف کردن آنها در نظر بگیرید. این لایه هیچ پارامتری برای یادگیری ندارد. فقط داده ها را دوباره فرمت می کند.
بعد از اینکه پیکسل ها مسطح شدند، شبکه از دنباله ای از دو لایه tf.keras.layers.Dense تشکیل می شود. این لایههای عصبی بهطور متراکم یا کاملاً متصل هستند. اولین لایه Dense دارای 128 گره (یا نورون) است. لایه دوم (و آخرین) یک آرایه logits با طول 10 را برمی گرداند. هر گره دارای امتیازی است که نشان می دهد تصویر فعلی متعلق به یکی از 10 کلاس است.
مدل را کامپایل کنید
قبل از اینکه مدل برای آموزش آماده شود، به چند تنظیمات دیگر نیاز دارد. اینها در مرحله کامپایل مدل اضافه می شوند:
- عملکرد از دست دادن - این میزان دقت مدل را در طول تمرین اندازه گیری می کند. شما می خواهید این عملکرد را به حداقل برسانید تا مدل را در جهت درست "هدایت" کنید.
- بهینه ساز — به این ترتیب مدل بر اساس داده هایی که می بیند و عملکرد از دست دادن آن به روز می شود.
- متریک - برای نظارت بر مراحل آموزش و آزمایش استفاده می شود. مثال زیر از دقت ، کسری از تصاویری که به درستی طبقه بندی شده اند استفاده می کند.
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
مدل را آموزش دهید
آموزش مدل شبکه عصبی به مراحل زیر نیاز دارد:
- داده های آموزشی را به مدل تغذیه کنید. در این مثال، داده های آموزشی در آرایه های
train_imagesوtrain_labelsقرار دارند. - مدل یاد می گیرد که تصاویر و برچسب ها را به هم مرتبط کند.
- شما از مدل میخواهید درباره یک مجموعه آزمایشی پیشبینی کند - در این مثال، آرایه
test_images. - بررسی کنید که پیشبینیها با برچسبهای آرایه
test_labelsدارند.
مدل را تغذیه کنید
برای شروع آموزش، متد model.fit را فراخوانی کنید - به این دلیل که مدل را با داده های آموزشی "تطبیق" می کند:
model.fit(train_images, train_labels, epochs=10)
Epoch 1/10 1875/1875 [==============================] - 4s 2ms/step - loss: 0.5014 - accuracy: 0.8232 Epoch 2/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3770 - accuracy: 0.8636 Epoch 3/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3376 - accuracy: 0.8770 Epoch 4/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3148 - accuracy: 0.8841 Epoch 5/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2973 - accuracy: 0.8899 Epoch 6/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2807 - accuracy: 0.8955 Epoch 7/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2707 - accuracy: 0.9002 Epoch 8/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2592 - accuracy: 0.9042 Epoch 9/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2506 - accuracy: 0.9070 Epoch 10/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2419 - accuracy: 0.9090 <keras.callbacks.History at 0x7f730da81c50>
همانطور که مدل آموزش می بیند، معیارهای از دست دادن و دقت نمایش داده می شود. این مدل در داده های آموزشی به دقت حدود 0.91 (یا 91٪) می رسد.
دقت را ارزیابی کنید
سپس، نحوه عملکرد مدل را در مجموعه داده آزمایشی مقایسه کنید:
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)
313/313 - 1s - loss: 0.3347 - accuracy: 0.8837 - 593ms/epoch - 2ms/step Test accuracy: 0.8837000131607056
به نظر می رسد که دقت در مجموعه داده آزمایشی کمی کمتر از دقت در مجموعه داده آموزشی است. این شکاف بین دقت تمرین و دقت آزمون نشان دهنده بیش از حد برازش است. تطبیق بیش از حد زمانی اتفاق میافتد که یک مدل یادگیری ماشینی در ورودیهای جدید و قبلاً دیده نشده بدتر از دادههای آموزشی عمل میکند. یک مدل بیش از حد برازش شده، نویز و جزئیات موجود در مجموعه داده آموزشی را تا حدی به خاطر میسپارد که بر عملکرد مدل در دادههای جدید تأثیر منفی میگذارد. برای اطلاعات بیشتر به ادامه مطلب مراجعه کنید:
پیش بینی کنید
با مدل آموزش داده شده، می توانید از آن برای پیش بینی برخی از تصاویر استفاده کنید. خروجی های خطی مدل، logits . یک لایه softmax را برای تبدیل logit ها به احتمالات وصل کنید که تفسیر آنها آسان تر است.
probability_model = tf.keras.Sequential([model,
tf.keras.layers.Softmax()])
predictions = probability_model.predict(test_images)
در اینجا، مدل برچسب را برای هر تصویر در مجموعه آزمایشی پیش بینی کرده است. بیایید نگاهی به پیش بینی اول بیندازیم:
predictions[0]
array([6.5094389e-07, 1.5681711e-10, 9.0262159e-10, 8.3779689e-10,
9.4969926e-07, 6.7454423e-03, 3.7524345e-08, 1.6792126e-02,
9.9967767e-09, 9.7646081e-01], dtype=float32)
پیش بینی آرایه ای از 10 عدد است. آنها نشان دهنده "اطمینان" مدل هستند که تصویر مربوط به هر یک از 10 لباس مختلف است. می توانید ببینید کدام برچسب دارای بالاترین ارزش اطمینان است:
np.argmax(predictions[0])
9
بنابراین، مدل بسیار مطمئن است که این تصویر یک بوت مچ پا یا class_names[9] است. بررسی برچسب تست نشان می دهد که این طبقه بندی صحیح است:
test_labels[0]
9
برای مشاهده مجموعه کامل 10 پیش بینی کلاس، این نمودار را ترسیم کنید.
def plot_image(i, predictions_array, true_label, img):
true_label, img = true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
true_label = true_label[i]
plt.grid(False)
plt.xticks(range(10))
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
پیش بینی ها را تأیید کنید
با مدل آموزش داده شده، می توانید از آن برای پیش بینی برخی از تصاویر استفاده کنید.
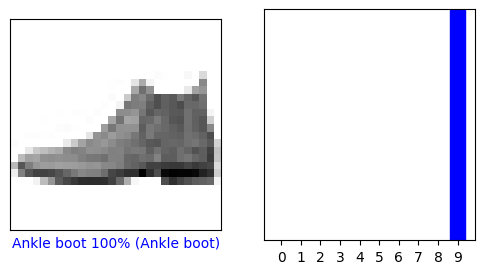
بیایید به تصویر 0، پیش بینی ها و آرایه پیش بینی نگاه کنیم. برچسبهای پیشبینی صحیح آبی و برچسبهای پیشبینی نادرست قرمز هستند. این عدد درصد (از 100) را برای برچسب پیش بینی شده نشان می دهد.
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
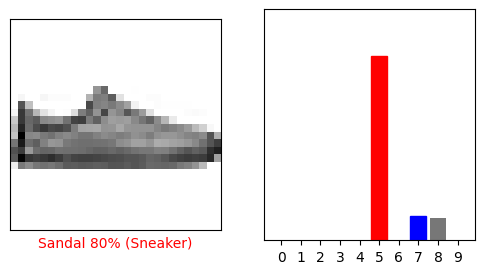
i = 12
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
بیایید چندین تصویر را با پیش بینی آنها ترسیم کنیم. توجه داشته باشید که مدل حتی زمانی که بسیار مطمئن است ممکن است اشتباه باشد.
# Plot the first X test images, their predicted labels, and the true labels.
# Color correct predictions in blue and incorrect predictions in red.
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions[i], test_labels)
plt.tight_layout()
plt.show()

از مدل آموزش دیده استفاده کنید
در نهایت، از مدل آموزش دیده برای پیش بینی یک تصویر استفاده کنید.
# Grab an image from the test dataset.
img = test_images[1]
print(img.shape)
(28, 28)
مدلهای tf.keras برای پیشبینی یک دسته یا مجموعهای از نمونهها بهطور همزمان بهینهسازی شدهاند. بر این اساس، حتی اگر از یک تصویر استفاده می کنید، باید آن را به یک لیست اضافه کنید:
# Add the image to a batch where it's the only member.
img = (np.expand_dims(img,0))
print(img.shape)
(1, 28, 28)
اکنون برچسب صحیح را برای این تصویر پیش بینی کنید:
predictions_single = probability_model.predict(img)
print(predictions_single)
[[5.2901622e-05 1.1112720e-14 9.9954790e-01 3.9485815e-10 2.0636957e-04 7.8756333e-12 1.9278938e-04 2.9756516e-16 2.2718803e-08 4.3763088e-15]]
plot_value_array(1, predictions_single[0], test_labels)
_ = plt.xticks(range(10), class_names, rotation=45)
plt.show()
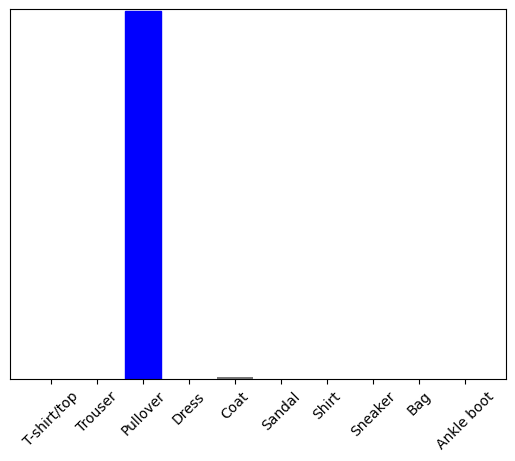
tf.keras.Model.predict فهرستی از لیست ها را برمی گرداند—یک لیست برای هر تصویر در دسته داده ها. پیشبینیهای مربوط به تصویر (تنها) ما را در دسته دریافت کنید:
np.argmax(predictions_single[0])
2
و مدل همانطور که انتظار می رود یک برچسب را پیش بینی می کند.
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.