
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
מדריך זה מכשיר מודל של רשת עצבית כדי לסווג תמונות של בגדים, כמו נעלי ספורט וחולצות. זה בסדר אם אתה לא מבין את כל הפרטים; זוהי סקירה מהירה של תוכנית TensorFlow שלמה עם הפרטים המוסברים תוך כדי תנועה.
מדריך זה משתמש ב- tf.keras , ממשק API ברמה גבוהה כדי לבנות ולהכשיר מודלים ב-TensorFlow.
# TensorFlow and tf.keras
import tensorflow as tf
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)
2.8.0-rc1
ייבא את מערך הנתונים של Fashion MNIST
מדריך זה משתמש במערך הנתונים של Fashion MNIST המכיל 70,000 תמונות בגווני אפור ב-10 קטגוריות. התמונות מציגות פריטי לבוש בודדים ברזולוציה נמוכה (28 על 28 פיקסלים), כפי שניתן לראות כאן:
| איור 1. דגימות Fashion-MNIST (על ידי Zalando, MIT License). |
אופנה MNIST מיועדת כתחליף נפוץ למערך הנתונים הקלאסי של MNIST - משמש לעתים קרובות כ"שלום, עולם" של תוכניות למידת מכונה לראייה ממוחשבת. מערך הנתונים של MNIST מכיל תמונות של ספרות בכתב יד (0, 1, 2 וכו') בפורמט זהה לזה של פריטי הלבוש שבהם תשתמשו כאן.
מדריך זה משתמש ב- Fashion MNIST למגוון, ובגלל שזו בעיה קצת יותר מאתגרת מ-MNIST רגילה. שני מערכי הנתונים קטנים יחסית ומשמשים כדי לוודא שאלגוריתם פועל כצפוי. הן נקודות התחלה טובות לבדיקה וניפוי באגים בקוד.
כאן, 60,000 תמונות משמשות לאימון הרשת ו-10,000 תמונות כדי להעריך באיזו מידה למדה הרשת לסווג תמונות. אתה יכול לגשת ל- Fashion MNIST ישירות מ- TensorFlow. ייבא וטען את נתוני Fashion MNIST ישירות מ-TensorFlow:
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
טעינת מערך הנתונים מחזירה ארבעה מערכי NumPy:
- מערכי ה-
train_imagesו-train_labelsהם מערך ההדרכה - הנתונים שהמודל משתמש בו כדי ללמוד. - המודל נבדק מול מערך הבדיקה , ה-
test_imagesומערכיםtest_labels.
התמונות הן מערכי NumPy בגודל 28x28, עם ערכי פיקסלים הנעים בין 0 ל-255. התוויות הן מערך של מספרים שלמים, הנעים בין 0 ל-9. אלה תואמים לסוג הלבוש שהתמונה מייצגת:
| תווית | מעמד |
|---|---|
| 0 | חולצה/טופ |
| 1 | מכנסיים |
| 2 | תעצור בצד |
| 3 | שמלה |
| 4 | מעיל |
| 5 | סַנְדָל |
| 6 | חוּלצָה |
| 7 | נַעַל הִתעַמְלוּת |
| 8 | תיק |
| 9 | מגף קרסול |
כל תמונה ממופה לתווית אחת. מכיוון ששמות המחלקות אינם כלולים במערך הנתונים, אחסן אותם כאן כדי להשתמש בהם מאוחר יותר בעת תכנון התמונות:
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
חקור את הנתונים
בואו נחקור את הפורמט של מערך הנתונים לפני אימון המודל. להלן מראה שיש 60,000 תמונות בערכת ההדרכה, כאשר כל תמונה מיוצגת כ-28 על 28 פיקסלים:
train_images.shape
(60000, 28, 28)
כמו כן, יש 60,000 תוויות בערכת ההדרכה:
len(train_labels)
60000
כל תווית היא מספר שלם בין 0 ל-9:
train_labels
array([9, 0, 0, ..., 3, 0, 5], dtype=uint8)
יש 10,000 תמונות בערכת הבדיקה. שוב, כל תמונה מיוצגת כ-28 x 28 פיקסלים:
test_images.shape
(10000, 28, 28)
וערכת הבדיקה מכילה 10,000 תוויות תמונות:
len(test_labels)
10000
עבד מראש את הנתונים
יש לעבד את הנתונים לפני אימון הרשת. אם תבדוק את התמונה הראשונה בערכת האימונים, תראה שערכי הפיקסלים נופלים בטווח של 0 עד 255:
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()
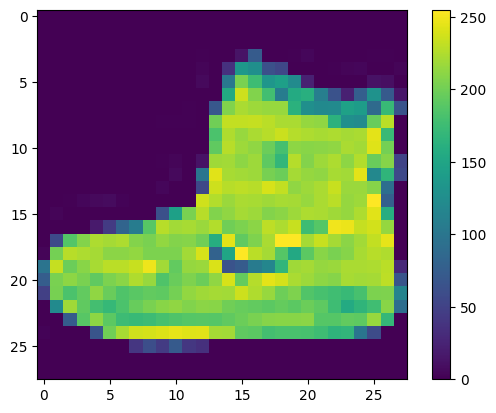
קנה קנה מידה של ערכים אלה לטווח של 0 עד 1 לפני הזנתם למודל הרשת העצבית. כדי לעשות זאת, חלקו את הערכים ב-255. חשוב שמערכת ההדרכה וערכת הבדיקות יעובדו מראש באותו אופן:
train_images = train_images / 255.0
test_images = test_images / 255.0
כדי לוודא שהנתונים בפורמט הנכון ושאתם מוכנים לבנות ולהכשיר את הרשת, בואו נציג את 25 התמונות הראשונות ממערך ההדרכה ונציג את שם הכיתה מתחת לכל תמונה.
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()

בנה את הדגם
בניית הרשת העצבית דורשת קביעת תצורה של שכבות המודל, ולאחר מכן קומפילציה של המודל.
הגדר את השכבות
אבן הבניין הבסיסית של רשת עצבית היא השכבה . שכבות מחלצות ייצוגים מהנתונים המוזנים אליהן. יש לקוות שהייצוגים הללו הם בעלי משמעות לבעיה שעל הפרק.
רוב הלמידה העמוקה מורכבת משרשור שכבות פשוטות. לרוב השכבות, כגון tf.keras.layers.Dense , יש פרמטרים שנלמדים במהלך האימון.
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10)
])
השכבה הראשונה ברשת זו, tf.keras.layers.Flatten , הופכת את הפורמט של התמונות ממערך דו מימדי (של 28 על 28 פיקסלים) למערך חד מימדי (של 28*28 = 784 פיקסלים). חשבו על שכבה זו כעל ביטול הערימה של שורות של פיקסלים בתמונה והסדרתן. לשכבה זו אין פרמטרים ללמוד; זה רק מפרמט מחדש את הנתונים.
לאחר שיטוח הפיקסלים, הרשת מורכבת מרצף של שתי שכבות tf.keras.layers.Dense . אלו שכבות עצביות מחוברות בצפיפות, או מחוברות במלואן. בשכבה Dense הראשונה יש 128 צמתים (או נוירונים). השכבה השנייה (והאחרונה) מחזירה מערך לוגיטים באורך 10. כל צומת מכיל ציון המציין שהתמונה הנוכחית שייכת לאחת מ-10 המחלקות.
הרכיב את המודל
לפני שהדגם מוכן לאימון, הוא צריך עוד כמה הגדרות. אלה מתווספים במהלך שלב ההידור של המודל:
- פונקציית הפסד - זה מודד עד כמה המודל מדויק במהלך האימון. אתה רוצה למזער את הפונקציה הזו כדי "לנווט" את הדגם בכיוון הנכון.
- אופטימיזציה - כך המודל מתעדכן על סמך הנתונים שהוא רואה ופונקציית האובדן שלו.
- מדדים - משמש לניטור שלבי ההדרכה והבדיקה. הדוגמה הבאה משתמשת בדיוק , החלק של התמונות שמסווגות נכון.
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
אימון הדגם
אימון מודל הרשת העצבית דורש את השלבים הבאים:
- הזינו את נתוני האימון למודל. בדוגמה זו, נתוני האימון נמצאים במערכי
train_imagesו-train_labels. - המודל לומד לקשר תמונות ותוויות.
- אתה מבקש מהמודל לבצע תחזיות לגבי מערך בדיקה - בדוגמה זו, מערך
test_images. - ודא שהתחזיות תואמות את התוויות ממערך
test_labels.
האכילו את הדגם
כדי להתחיל אימון, קרא לשיטת model.fit - כך נקראת מכיוון שהיא "מתאימה" את המודל לנתוני האימון:
model.fit(train_images, train_labels, epochs=10)
Epoch 1/10 1875/1875 [==============================] - 4s 2ms/step - loss: 0.5014 - accuracy: 0.8232 Epoch 2/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3770 - accuracy: 0.8636 Epoch 3/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3376 - accuracy: 0.8770 Epoch 4/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3148 - accuracy: 0.8841 Epoch 5/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2973 - accuracy: 0.8899 Epoch 6/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2807 - accuracy: 0.8955 Epoch 7/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2707 - accuracy: 0.9002 Epoch 8/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2592 - accuracy: 0.9042 Epoch 9/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2506 - accuracy: 0.9070 Epoch 10/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2419 - accuracy: 0.9090 <keras.callbacks.History at 0x7f730da81c50>
כאשר הדגם מתאמן, מוצגים מדדי ההפסד והדיוק. מודל זה מגיע לדיוק של כ-0.91 (או 91%) בנתוני האימון.
הערכת דיוק
לאחר מכן, השווה את ביצועי המודל במערך הנתונים של הבדיקה:
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)
313/313 - 1s - loss: 0.3347 - accuracy: 0.8837 - 593ms/epoch - 2ms/step Test accuracy: 0.8837000131607056
מסתבר שהדיוק במערך הנתונים של הבדיקה הוא קצת פחות מהדיוק במערך האימון. הפער הזה בין דיוק האימון לדיוק הבדיקה מייצג התאמת יתר . התאמת יתר מתרחשת כאשר מודל למידת מכונה מציג ביצועים גרועים יותר בתשומות חדשות שלא נראו בעבר מאשר בנתוני האימון. מודל מצויד יתר על המידה "משנן" את הרעש והפרטים במערך הנתונים לאימון עד לנקודה שבה הוא משפיע לרעה על ביצועי המודל על הנתונים החדשים. למידע נוסף, ראה את הפרטים הבאים:
לעשות תחזיות
עם המודל מאומן, אתה יכול להשתמש בו כדי ליצור תחזיות לגבי כמה תמונות. הפלטים הליניאריים של המודל, לוגיטים . צרף שכבת softmax כדי להמיר את הלוגיטים להסתברויות, שקל יותר לפרש.
probability_model = tf.keras.Sequential([model,
tf.keras.layers.Softmax()])
predictions = probability_model.predict(test_images)
כאן, המודל חזה את התווית עבור כל תמונה בערכת הבדיקות. בואו נסתכל על התחזית הראשונה:
predictions[0]
array([6.5094389e-07, 1.5681711e-10, 9.0262159e-10, 8.3779689e-10,
9.4969926e-07, 6.7454423e-03, 3.7524345e-08, 1.6792126e-02,
9.9967767e-09, 9.7646081e-01], dtype=float32)
חיזוי הוא מערך של 10 מספרים. הם מייצגים את ה"ביטחון" של הדוגמנית שהתמונה מתאימה לכל אחד מ-10 פריטי הלבוש השונים. אתה יכול לראות לאיזו תווית יש את ערך הביטחון הגבוה ביותר:
np.argmax(predictions[0])
9
אז, הדוגמנית בטוחה ביותר שהתמונה הזו היא מגף קרסול, או class_names[9] . בחינת תווית הבדיקה מראה שסיווג זה נכון:
test_labels[0]
9
גרף את זה כדי להסתכל על הסט המלא של 10 תחזיות הכיתה.
def plot_image(i, predictions_array, true_label, img):
true_label, img = true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
true_label = true_label[i]
plt.grid(False)
plt.xticks(range(10))
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
אמת את התחזיות
עם המודל מאומן, אתה יכול להשתמש בו כדי ליצור תחזיות לגבי כמה תמונות.
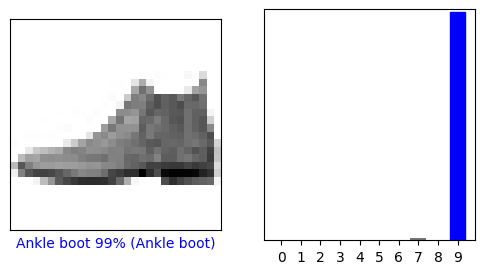
בואו נסתכל על התמונה ה-0, התחזיות ומערך החיזוי. תוויות חיזוי נכונות הן כחולות ותוויות חיזוי לא נכונות הן אדומות. המספר נותן את האחוז (מתוך 100) עבור התווית החזויה.
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
i = 12
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
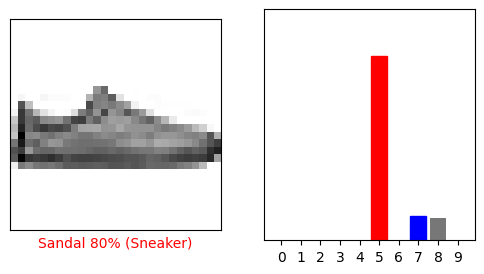
בואו נתווה מספר תמונות עם התחזיות שלהם. שימו לב שהדגם יכול לטעות גם כאשר הוא מאוד בטוח.
# Plot the first X test images, their predicted labels, and the true labels.
# Color correct predictions in blue and incorrect predictions in red.
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions[i], test_labels)
plt.tight_layout()
plt.show()

השתמש בדגם המיומן
לבסוף, השתמש במודל המאומן כדי ליצור תחזית לגבי תמונה בודדת.
# Grab an image from the test dataset.
img = test_images[1]
print(img.shape)
(28, 28)
מודלים tf.keras מותאמים לביצוע תחזיות על אצווה , או אוסף, של דוגמאות בבת אחת. בהתאם לכך, למרות שאתה משתמש בתמונה בודדת, עליך להוסיף אותה לרשימה:
# Add the image to a batch where it's the only member.
img = (np.expand_dims(img,0))
print(img.shape)
(1, 28, 28)
כעת חזה את התווית הנכונה עבור התמונה הזו:
predictions_single = probability_model.predict(img)
print(predictions_single)
[[5.2901622e-05 1.1112720e-14 9.9954790e-01 3.9485815e-10 2.0636957e-04 7.8756333e-12 1.9278938e-04 2.9756516e-16 2.2718803e-08 4.3763088e-15]]
plot_value_array(1, predictions_single[0], test_labels)
_ = plt.xticks(range(10), class_names, rotation=45)
plt.show()
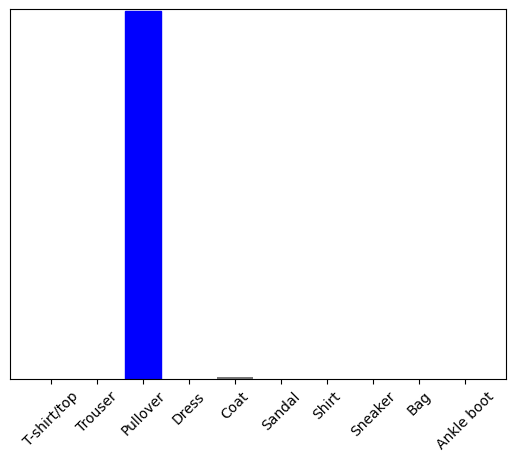
tf.keras.Model.predict מחזיר רשימה של רשימות - רשימה אחת לכל תמונה בקבוצת הנתונים. קח את התחזיות לתמונה (היחידה) שלנו באצווה:
np.argmax(predictions_single[0])
2
והדגם חוזה תווית כצפוי.
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.