
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
यह ट्यूटोरियल डिस्क पर संग्रहीत प्लेन टेक्स्ट फाइलों से शुरू होने वाले टेक्स्ट वर्गीकरण को प्रदर्शित करता है। आप IMDB डेटासेट पर भावना विश्लेषण करने के लिए एक बाइनरी क्लासिफायरियर को प्रशिक्षित करेंगे। नोटबुक के अंत में, आपके लिए प्रयास करने के लिए एक अभ्यास है, जिसमें आप स्टैक ओवरफ़्लो पर प्रोग्रामिंग प्रश्न के लिए टैग की भविष्यवाणी करने के लिए एक बहु-वर्ग क्लासिफायरियर को प्रशिक्षित करेंगे।
import matplotlib.pyplot as plt
import os
import re
import shutil
import string
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import losses
print(tf.__version__)
2.8.0-rc1
भावनाओं का विश्लेषण
यह नोटबुक समीक्षा के पाठ के आधार पर मूवी समीक्षाओं को सकारात्मक या नकारात्मक के रूप में वर्गीकृत करने के लिए एक भावना विश्लेषण मॉडल को प्रशिक्षित करती है। यह बाइनरी -या टू-क्लास-वर्गीकरण का एक उदाहरण है, जो एक महत्वपूर्ण और व्यापक रूप से लागू होने वाली मशीन सीखने की समस्या है।
आप बड़े मूवी समीक्षा डेटासेट का उपयोग करेंगे जिसमें इंटरनेट मूवी डेटाबेस से 50,000 मूवी समीक्षाओं का टेक्स्ट शामिल है। इन्हें प्रशिक्षण के लिए 25,000 समीक्षाओं और परीक्षण के लिए 25,000 समीक्षाओं में विभाजित किया गया है। प्रशिक्षण और परीक्षण सेट संतुलित हैं, जिसका अर्थ है कि उनमें समान संख्या में सकारात्मक और नकारात्मक समीक्षाएं हैं।
IMDB डेटासेट डाउनलोड करें और एक्सप्लोर करें
आइए डेटासेट डाउनलोड करें और निकालें, फिर निर्देशिका संरचना का अन्वेषण करें।
url = "https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
dataset = tf.keras.utils.get_file("aclImdb_v1", url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 6s 0us/step 84140032/84125825 [==============================] - 6s 0us/step
os.listdir(dataset_dir)
['test', 'README', 'imdbEr.txt', 'imdb.vocab', 'train']
train_dir = os.path.join(dataset_dir, 'train')
os.listdir(train_dir)
['neg', 'urls_neg.txt', 'unsup', 'unsupBow.feat', 'urls_unsup.txt', 'urls_pos.txt', 'labeledBow.feat', 'pos']
aclImdb/train/pos और aclImdb/train/neg निर्देशिकाओं में कई टेक्स्ट फ़ाइलें होती हैं, जिनमें से प्रत्येक एक मूवी समीक्षा है। आइए उनमें से एक पर एक नजर डालते हैं।
sample_file = os.path.join(train_dir, 'pos/1181_9.txt')
with open(sample_file) as f:
print(f.read())
Rachel Griffiths writes and directs this award winning short film. A heartwarming story about coping with grief and cherishing the memory of those we've loved and lost. Although, only 15 minutes long, Griffiths manages to capture so much emotion and truth onto film in the short space of time. Bud Tingwell gives a touching performance as Will, a widower struggling to cope with his wife's death. Will is confronted by the harsh reality of loneliness and helplessness as he proceeds to take care of Ruth's pet cow, Tulip. The film displays the grief and responsibility one feels for those they have loved and lost. Good cinematography, great direction, and superbly acted. It will bring tears to all those who have lost a loved one, and survived.
डेटासेट लोड करें
इसके बाद, आप डेटा को डिस्क से लोड करेंगे और इसे प्रशिक्षण के लिए उपयुक्त प्रारूप में तैयार करेंगे। ऐसा करने के लिए, आप सहायक text_dataset_from_directory उपयोगिता का उपयोग करेंगे, जो निम्नानुसार एक निर्देशिका संरचना की अपेक्षा करता है।
main_directory/
...class_a/
......a_text_1.txt
......a_text_2.txt
...class_b/
......b_text_1.txt
......b_text_2.txt
बाइनरी वर्गीकरण के लिए डेटासेट तैयार करने के लिए, आपको डिस्क पर दो फ़ोल्डरों की आवश्यकता होगी, जो कि class_a और class_b के अनुरूप हैं। ये सकारात्मक और नकारात्मक मूवी समीक्षाएं होंगी, जो aclImdb/train/pos और aclImdb/train/neg में पाई जा सकती हैं। चूंकि IMDB डेटासेट में अतिरिक्त फ़ोल्डर होते हैं, आप इस उपयोगिता का उपयोग करने से पहले उन्हें हटा देंगे।
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
इसके बाद, आप एक लेबल tf.data.Dataset बनाने के लिए text_dataset_from_directory उपयोगिता का उपयोग करेंगे। tf.data डेटा के साथ काम करने के लिए उपकरणों का एक शक्तिशाली संग्रह है।
मशीन लर्निंग प्रयोग चलाते समय, अपने डेटासेट को तीन भागों में विभाजित करना सबसे अच्छा अभ्यास है: ट्रेन , सत्यापन , और परीक्षण ।
IMDB डेटासेट को पहले ही ट्रेन और परीक्षण में विभाजित किया जा चुका है, लेकिन इसमें सत्यापन सेट का अभाव है। आइए नीचे दिए गए validation_split तर्क का उपयोग करके प्रशिक्षण डेटा के 80:20 विभाजन का उपयोग करके एक सत्यापन सेट बनाएं।
batch_size = 32
seed = 42
raw_train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='training',
seed=seed)
Found 25000 files belonging to 2 classes. Using 20000 files for training.
जैसा कि आप ऊपर देख सकते हैं, प्रशिक्षण फ़ोल्डर में 25,000 उदाहरण हैं, जिनमें से आप प्रशिक्षण के लिए 80% (या 20,000) का उपयोग करेंगे। जैसा कि आप एक पल में देखेंगे, आप एक डेटासेट को सीधे model.fit पर पास करके एक मॉडल को प्रशिक्षित कर सकते हैं। यदि आप tf.data के लिए नए हैं, तो आप डेटासेट पर पुनरावृति भी कर सकते हैं और कुछ उदाहरण निम्नानुसार प्रिंट कर सकते हैं।
for text_batch, label_batch in raw_train_ds.take(1):
for i in range(3):
print("Review", text_batch.numpy()[i])
print("Label", label_batch.numpy()[i])
Review b'"Pandemonium" is a horror movie spoof that comes off more stupid than funny. Believe me when I tell you, I love comedies. Especially comedy spoofs. "Airplane", "The Naked Gun" trilogy, "Blazing Saddles", "High Anxiety", and "Spaceballs" are some of my favorite comedies that spoof a particular genre. "Pandemonium" is not up there with those films. Most of the scenes in this movie had me sitting there in stunned silence because the movie wasn\'t all that funny. There are a few laughs in the film, but when you watch a comedy, you expect to laugh a lot more than a few times and that\'s all this film has going for it. Geez, "Scream" had more laughs than this film and that was more of a horror film. How bizarre is that?<br /><br />*1/2 (out of four)' Label 0 Review b"David Mamet is a very interesting and a very un-equal director. His first movie 'House of Games' was the one I liked best, and it set a series of films with characters whose perspective of life changes as they get into complicated situations, and so does the perspective of the viewer.<br /><br />So is 'Homicide' which from the title tries to set the mind of the viewer to the usual crime drama. The principal characters are two cops, one Jewish and one Irish who deal with a racially charged area. The murder of an old Jewish shop owner who proves to be an ancient veteran of the Israeli Independence war triggers the Jewish identity in the mind and heart of the Jewish detective.<br /><br />This is were the flaws of the film are the more obvious. The process of awakening is theatrical and hard to believe, the group of Jewish militants is operatic, and the way the detective eventually walks to the final violent confrontation is pathetic. The end of the film itself is Mamet-like smart, but disappoints from a human emotional perspective.<br /><br />Joe Mantegna and William Macy give strong performances, but the flaws of the story are too evident to be easily compensated." Label 0 Review b'Great documentary about the lives of NY firefighters during the worst terrorist attack of all time.. That reason alone is why this should be a must see collectors item.. What shocked me was not only the attacks, but the"High Fat Diet" and physical appearance of some of these firefighters. I think a lot of Doctors would agree with me that,in the physical shape they were in, some of these firefighters would NOT of made it to the 79th floor carrying over 60 lbs of gear. Having said that i now have a greater respect for firefighters and i realize becoming a firefighter is a life altering job. The French have a history of making great documentary\'s and that is what this is, a Great Documentary.....' Label 1प्लेसहोल्डर17
ध्यान दें कि समीक्षाओं में कच्चा पाठ होता है (विराम चिह्न और सामयिक HTML टैग जैसे <br/> के साथ)। आप उन्हें निम्नलिखित अनुभाग में दिखाएंगे कि इन्हें कैसे संभालना है।
लेबल 0 या 1 हैं। यह देखने के लिए कि इनमें से कौन सा सकारात्मक और नकारात्मक मूवी समीक्षाओं के अनुरूप है, आप डेटासेट पर class_names गुण देख सकते हैं।
print("Label 0 corresponds to", raw_train_ds.class_names[0])
print("Label 1 corresponds to", raw_train_ds.class_names[1])
Label 0 corresponds to neg Label 1 corresponds to pos
इसके बाद, आप एक सत्यापन और परीक्षण डेटासेट तैयार करेंगे। आप सत्यापन के लिए प्रशिक्षण सेट से शेष 5,000 समीक्षाओं का उपयोग करेंगे।
raw_val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='validation',
seed=seed)
Found 25000 files belonging to 2 classes. Using 5000 files for validation.
raw_test_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/test',
batch_size=batch_size)
Found 25000 files belonging to 2 classes.
प्रशिक्षण के लिए डेटासेट तैयार करें
इसके बाद, आप सहायक tf.keras.layers.TextVectorization लेयर का उपयोग करके डेटा को मानकीकृत, टोकननाइज़ और वेक्टराइज़ करेंगे।
मानकीकरण टेक्स्ट को प्रीप्रोसेसिंग करने के लिए संदर्भित करता है, आमतौर पर डेटासेट को सरल बनाने के लिए विराम चिह्न या HTML तत्वों को हटाने के लिए। टोकननाइज़ेशन स्ट्रिंग्स को टोकन में विभाजित करने के लिए संदर्भित करता है (उदाहरण के लिए, एक वाक्य को अलग-अलग शब्दों में विभाजित करके, व्हॉट्सएप पर विभाजित करके)। वेक्टराइजेशन टोकन को संख्याओं में परिवर्तित करने को संदर्भित करता है ताकि उन्हें एक तंत्रिका नेटवर्क में फीड किया जा सके। इन सभी कार्यों को इस परत से पूरा किया जा सकता है।
जैसा कि आपने ऊपर देखा, समीक्षाओं में विभिन्न HTML टैग होते हैं जैसे <br /> । ये टैग TextVectorization लेयर में डिफ़ॉल्ट मानककर्ता द्वारा नहीं निकाले जाएंगे (जो टेक्स्ट को लोअरकेस में कनवर्ट करता है और डिफ़ॉल्ट रूप से विराम चिह्नों को स्ट्रिप्स करता है, लेकिन HTML को स्ट्रिप नहीं करता है)। आप HTML को निकालने के लिए एक कस्टम मानकीकरण फ़ंक्शन लिखेंगे।
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, '<br />', ' ')
return tf.strings.regex_replace(stripped_html,
'[%s]' % re.escape(string.punctuation),
'')
इसके बाद, आप एक TextVectorization लेयर बनाएंगे। आप इस परत का उपयोग हमारे डेटा को मानकीकृत करने, टोकन करने और वेक्टराइज़ करने के लिए करेंगे। आप प्रत्येक टोकन के लिए अद्वितीय पूर्णांक सूचकांक बनाने के लिए output_mode को int पर सेट करते हैं।
ध्यान दें कि आप डिफ़ॉल्ट स्प्लिट फ़ंक्शन और ऊपर परिभाषित कस्टम मानकीकरण फ़ंक्शन का उपयोग कर रहे हैं। आप मॉडल के लिए कुछ स्थिरांक भी परिभाषित करेंगे, जैसे कि एक स्पष्ट अधिकतम sequence_length , जो परत को पैड या अनुक्रमों को बिल्कुल sequence_length मानों के लिए छोटा कर देगा।
max_features = 10000
sequence_length = 250
vectorize_layer = layers.TextVectorization(
standardize=custom_standardization,
max_tokens=max_features,
output_mode='int',
output_sequence_length=sequence_length)
इसके बाद, आप प्रीप्रोसेसिंग परत की स्थिति को डेटासेट में फ़िट करने के लिए adapt को कॉल करेंगे। यह मॉडल को पूर्णांकों के लिए स्ट्रिंग्स की अनुक्रमणिका बनाने का कारण बनेगा।
# Make a text-only dataset (without labels), then call adapt
train_text = raw_train_ds.map(lambda x, y: x)
vectorize_layer.adapt(train_text)
आइए कुछ डेटा को प्रीप्रोसेस करने के लिए इस परत का उपयोग करने के परिणाम देखने के लिए एक फ़ंक्शन बनाएं।
def vectorize_text(text, label):
text = tf.expand_dims(text, -1)
return vectorize_layer(text), label
# retrieve a batch (of 32 reviews and labels) from the dataset
text_batch, label_batch = next(iter(raw_train_ds))
first_review, first_label = text_batch[0], label_batch[0]
print("Review", first_review)
print("Label", raw_train_ds.class_names[first_label])
print("Vectorized review", vectorize_text(first_review, first_label))
Review tf.Tensor(b'Great movie - especially the music - Etta James - "At Last". This speaks volumes when you have finally found that special someone.', shape=(), dtype=string)
Label neg
Vectorized review (<tf.Tensor: shape=(1, 250), dtype=int64, numpy=
array([[ 86, 17, 260, 2, 222, 1, 571, 31, 229, 11, 2418,
1, 51, 22, 25, 404, 251, 12, 306, 282, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]])>, <tf.Tensor: shape=(), dtype=int32, numpy=0>)
जैसा कि आप ऊपर देख सकते हैं, प्रत्येक टोकन को एक पूर्णांक से बदल दिया गया है। आप परत पर .get_vocabulary() को कॉल करके उस टोकन (स्ट्रिंग) को देख सकते हैं जिससे प्रत्येक पूर्णांक मेल खाता है।
print("1287 ---> ",vectorize_layer.get_vocabulary()[1287])
print(" 313 ---> ",vectorize_layer.get_vocabulary()[313])
print('Vocabulary size: {}'.format(len(vectorize_layer.get_vocabulary())))
1287 ---> silent 313 ---> night Vocabulary size: 10000
आप अपने मॉडल को प्रशिक्षित करने के लिए लगभग तैयार हैं। अंतिम प्रीप्रोसेसिंग चरण के रूप में, आप ट्रेन, सत्यापन और परीक्षण डेटासेट पर आपके द्वारा पहले बनाई गई TextVectorization परत को लागू करेंगे।
train_ds = raw_train_ds.map(vectorize_text)
val_ds = raw_val_ds.map(vectorize_text)
test_ds = raw_test_ds.map(vectorize_text)
प्रदर्शन के लिए डेटासेट कॉन्फ़िगर करें
ये दो महत्वपूर्ण तरीके हैं जिनका उपयोग आपको डेटा लोड करते समय यह सुनिश्चित करने के लिए करना चाहिए कि I/O अवरुद्ध न हो जाए।
.cache() डिस्क से लोड होने के बाद डेटा को मेमोरी में रखता है। यह सुनिश्चित करेगा कि आपके मॉडल को प्रशिक्षित करते समय डेटासेट एक अड़चन न बने। यदि आपका डेटासेट मेमोरी में फ़िट होने के लिए बहुत बड़ा है, तो आप इस पद्धति का उपयोग एक प्रदर्शनकारी ऑन-डिस्क कैश बनाने के लिए भी कर सकते हैं, जो कई छोटी फ़ाइलों की तुलना में पढ़ने में अधिक कुशल है।
.prefetch() प्रशिक्षण के दौरान डेटा प्रीप्रोसेसिंग और मॉडल निष्पादन को ओवरलैप करता है।
आप दोनों विधियों के साथ-साथ डेटा प्रदर्शन मार्गदर्शिका में डिस्क पर डेटा कैश करने के तरीके के बारे में अधिक जान सकते हैं।
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
test_ds = test_ds.cache().prefetch(buffer_size=AUTOTUNE)
मॉडल बनाएं
आपका तंत्रिका नेटवर्क बनाने का समय आ गया है:
embedding_dim = 16
model = tf.keras.Sequential([
layers.Embedding(max_features + 1, embedding_dim),
layers.Dropout(0.2),
layers.GlobalAveragePooling1D(),
layers.Dropout(0.2),
layers.Dense(1)])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, None, 16) 160016
dropout (Dropout) (None, None, 16) 0
global_average_pooling1d (G (None, 16) 0
lobalAveragePooling1D)
dropout_1 (Dropout) (None, 16) 0
dense (Dense) (None, 1) 17
=================================================================
Total params: 160,033
Trainable params: 160,033
Non-trainable params: 0
_________________________________________________________________
क्लासिफायरियर बनाने के लिए परतों को क्रमिक रूप से ढेर किया जाता है:
- पहली परत एक
Embeddingपरत है। यह परत पूर्णांक-एन्कोडेड समीक्षाओं को लेती है और प्रत्येक शब्द-अनुक्रमणिका के लिए एक एम्बेडिंग वेक्टर की तलाश करती है। इन वैक्टर को मॉडल ट्रेन के रूप में सीखा जाता है। वेक्टर आउटपुट सरणी में एक आयाम जोड़ते हैं। परिणामी आयाम हैं:(batch, sequence, embedding)। एम्बेडिंग के बारे में अधिक जानने के लिए, एम्बेडिंग ट्यूटोरियल शब्द देखें। - इसके बाद, एक
GlobalAveragePooling1Dपरत प्रत्येक उदाहरण के लिए अनुक्रम आयाम पर औसत द्वारा एक निश्चित-लंबाई आउटपुट वेक्टर देता है। यह मॉडल को यथासंभव सरलतम तरीके से परिवर्तनीय लंबाई के इनपुट को संभालने की अनुमति देता है। - यह निश्चित-लंबाई आउटपुट वेक्टर 16 छिपी इकाइयों के साथ पूरी तरह से जुड़ी (
Dense) परत के माध्यम से पाइप किया जाता है। - अंतिम परत एकल आउटपुट नोड के साथ घनी रूप से जुड़ी हुई है।
हानि समारोह और अनुकूलक
एक मॉडल को प्रशिक्षण के लिए एक हानि फ़ंक्शन और एक अनुकूलक की आवश्यकता होती है। चूंकि यह एक द्विआधारी वर्गीकरण समस्या है और मॉडल एक संभाव्यता (एक सिग्मॉइड सक्रियण के साथ एक एकल-इकाई परत) को आउटपुट करता है, आप नुकसान का उपयोग करेंगे। losses.BinaryCrossentropy लॉस फ़ंक्शन।
अब, अनुकूलक और हानि फ़ंक्शन का उपयोग करने के लिए मॉडल को कॉन्फ़िगर करें:
model.compile(loss=losses.BinaryCrossentropy(from_logits=True),
optimizer='adam',
metrics=tf.metrics.BinaryAccuracy(threshold=0.0))
मॉडल को प्रशिक्षित करें
आप dataset ऑब्जेक्ट को फिट विधि में पास करके मॉडल को प्रशिक्षित करेंगे।
epochs = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs)
Epoch 1/10 625/625 [==============================] - 4s 4ms/step - loss: 0.6644 - binary_accuracy: 0.6894 - val_loss: 0.6159 - val_binary_accuracy: 0.7696 Epoch 2/10 625/625 [==============================] - 2s 4ms/step - loss: 0.5494 - binary_accuracy: 0.8020 - val_loss: 0.4993 - val_binary_accuracy: 0.8226 Epoch 3/10 625/625 [==============================] - 2s 3ms/step - loss: 0.4450 - binary_accuracy: 0.8447 - val_loss: 0.4205 - val_binary_accuracy: 0.8466 Epoch 4/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3778 - binary_accuracy: 0.8659 - val_loss: 0.3740 - val_binary_accuracy: 0.8618 Epoch 5/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3357 - binary_accuracy: 0.8785 - val_loss: 0.3451 - val_binary_accuracy: 0.8678 Epoch 6/10 625/625 [==============================] - 2s 3ms/step - loss: 0.3055 - binary_accuracy: 0.8885 - val_loss: 0.3260 - val_binary_accuracy: 0.8700 Epoch 7/10 625/625 [==============================] - 2s 3ms/step - loss: 0.2817 - binary_accuracy: 0.8971 - val_loss: 0.3126 - val_binary_accuracy: 0.8730 Epoch 8/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2616 - binary_accuracy: 0.9034 - val_loss: 0.3037 - val_binary_accuracy: 0.8754 Epoch 9/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2458 - binary_accuracy: 0.9110 - val_loss: 0.2965 - val_binary_accuracy: 0.8788 Epoch 10/10 625/625 [==============================] - 2s 4ms/step - loss: 0.2319 - binary_accuracy: 0.9158 - val_loss: 0.2920 - val_binary_accuracy: 0.8792
मॉडल का मूल्यांकन करें
आइए देखें कि मॉडल कैसा प्रदर्शन करता है। दो मान लौटाए जाएंगे। हानि (एक संख्या जो हमारी त्रुटि का प्रतिनिधित्व करती है, कम मान बेहतर होते हैं), और सटीकता।
loss, accuracy = model.evaluate(test_ds)
print("Loss: ", loss)
print("Accuracy: ", accuracy)
782/782 [==============================] - 2s 2ms/step - loss: 0.3104 - binary_accuracy: 0.8735 Loss: 0.3104138672351837 Accuracy: 0.873520016670227
यह काफी भोला दृष्टिकोण लगभग 86% की सटीकता प्राप्त करता है।
समय के साथ सटीकता और हानि का प्लॉट बनाएं
model.fit() एक History वस्तु देता है जिसमें प्रशिक्षण के दौरान हुई हर चीज के साथ एक शब्दकोश होता है:
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'binary_accuracy', 'val_loss', 'val_binary_accuracy'])
चार प्रविष्टियां हैं: प्रशिक्षण और सत्यापन के दौरान प्रत्येक मॉनिटर किए गए मीट्रिक के लिए एक। आप तुलना के लिए प्रशिक्षण और सत्यापन हानि के साथ-साथ प्रशिक्षण और सत्यापन सटीकता की साजिश रचने के लिए इनका उपयोग कर सकते हैं:
acc = history_dict['binary_accuracy']
val_acc = history_dict['val_binary_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
# "bo" is for "blue dot"
plt.plot(epochs, loss, 'bo', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
plt.show()
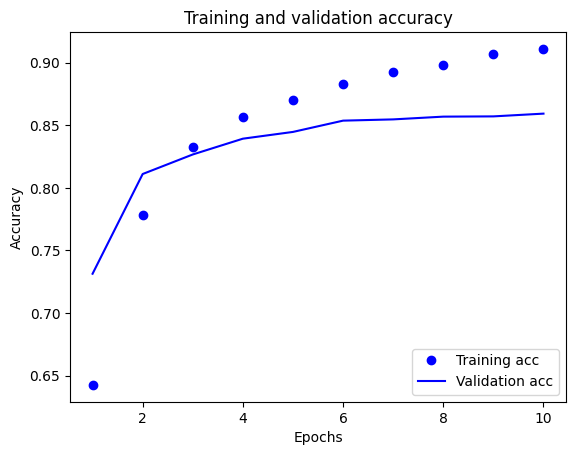
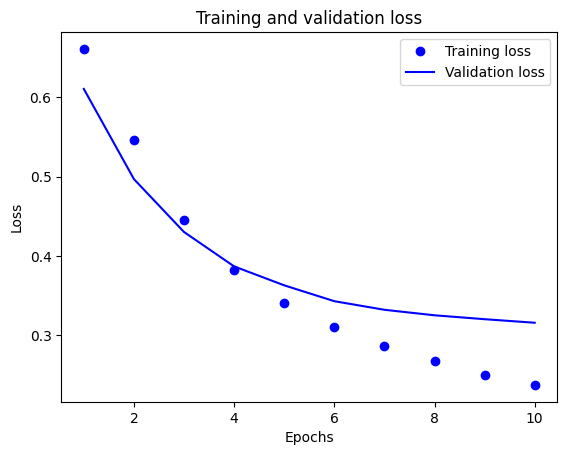
इस साजिश में, बिंदु प्रशिक्षण हानि और सटीकता का प्रतिनिधित्व करते हैं, और ठोस रेखाएं सत्यापन हानि और सटीकता हैं।
ध्यान दें कि प्रत्येक युग के साथ प्रशिक्षण हानि कम हो जाती है और प्रत्येक युग के साथ प्रशिक्षण सटीकता बढ़ जाती है। ग्रेडिएंट डिसेंट ऑप्टिमाइज़ेशन का उपयोग करते समय यह अपेक्षित है - इसे हर पुनरावृत्ति पर वांछित मात्रा को कम करना चाहिए।
सत्यापन हानि और सटीकता के लिए यह मामला नहीं है - वे प्रशिक्षण सटीकता से पहले चरम पर लगते हैं। यह ओवरफिटिंग का एक उदाहरण है: मॉडल प्रशिक्षण डेटा पर उस डेटा की तुलना में बेहतर प्रदर्शन करता है जो उसने पहले कभी नहीं देखा है। इस बिंदु के बाद, मॉडल प्रशिक्षण डेटा के लिए विशिष्ट अभ्यावेदन को ओवर-ऑप्टिमाइज़ करता है और सीखता है जो डेटा का परीक्षण करने के लिए सामान्यीकृत नहीं होता है।
इस विशेष मामले के लिए, जब सत्यापन सटीकता अब नहीं बढ़ रही है, तो आप केवल प्रशिक्षण को रोककर ओवरफिटिंग को रोक सकते हैं। ऐसा करने का एक तरीका tf.keras.callbacks.EarlyStopping कॉलबैक का उपयोग करना है।
मॉडल निर्यात करें
ऊपर दिए गए कोड में, आपने मॉडल को टेक्स्ट फीड करने से पहले डेटासेट पर TextVectorization लेयर लागू किया है। यदि आप अपने मॉडल को कच्चे तारों को संसाधित करने में सक्षम बनाना चाहते हैं (उदाहरण के लिए, इसे तैनात करना आसान बनाने के लिए), तो आप अपने मॉडल के अंदर TextVectorization परत शामिल कर सकते हैं। ऐसा करने के लिए, आप अभी-अभी प्रशिक्षित वज़न का उपयोग करके एक नया मॉडल बना सकते हैं।
export_model = tf.keras.Sequential([
vectorize_layer,
model,
layers.Activation('sigmoid')
])
export_model.compile(
loss=losses.BinaryCrossentropy(from_logits=False), optimizer="adam", metrics=['accuracy']
)
# Test it with `raw_test_ds`, which yields raw strings
loss, accuracy = export_model.evaluate(raw_test_ds)
print(accuracy)
782/782 [==============================] - 3s 4ms/step - loss: 0.3104 - accuracy: 0.8735 0.873520016670227
नए डेटा पर अनुमान
नए उदाहरणों के लिए भविष्यवाणियां प्राप्त करने के लिए, आप बस model.predict() को कॉल कर सकते हैं।
examples = [
"The movie was great!",
"The movie was okay.",
"The movie was terrible..."
]
export_model.predict(examples)
array([[0.60320234],
[0.4262717 ],
[0.34439093]], dtype=float32)
अपने मॉडल के अंदर टेक्स्ट प्रीप्रोसेसिंग लॉजिक को शामिल करना आपको उत्पादन के लिए एक मॉडल निर्यात करने में सक्षम बनाता है जो तैनाती को सरल करता है, और ट्रेन/टेस्ट स्क्यू की संभावना को कम करता है।
अपनी TextVectorization लेयर को कहां लागू करना है, यह चुनते समय ध्यान में रखने के लिए एक प्रदर्शन अंतर है। अपने मॉडल के बाहर इसका उपयोग करने से आप GPU पर प्रशिक्षण के दौरान एसिंक्रोनस सीपीयू प्रोसेसिंग और अपने डेटा की बफरिंग कर सकते हैं। इसलिए, यदि आप अपने मॉडल को GPU पर प्रशिक्षण दे रहे हैं, तो संभवतः आप अपने मॉडल को विकसित करते समय सर्वश्रेष्ठ प्रदर्शन प्राप्त करने के लिए इस विकल्प के साथ जाना चाहते हैं, फिर जब आप परिनियोजन की तैयारी के लिए तैयार हों तो अपने मॉडल के अंदर TextVectorization परत को शामिल करने के लिए स्विच करें। .
मॉडलों को सहेजने के बारे में अधिक जानने के लिए इस ट्यूटोरियल पर जाएं।
अभ्यास: स्टैक ओवरफ्लो प्रश्नों पर बहु-वर्गीय वर्गीकरण
इस ट्यूटोरियल में दिखाया गया है कि IMDB डेटासेट पर एक बाइनरी क्लासिफायरियर को स्क्रैच से कैसे प्रशिक्षित किया जाए। एक अभ्यास के रूप में, आप स्टैक ओवरफ्लो पर प्रोग्रामिंग प्रश्न के टैग की भविष्यवाणी करने के लिए एक बहु-वर्ग क्लासिफायरियर को प्रशिक्षित करने के लिए इस नोटबुक को संशोधित कर सकते हैं।
स्टैक ओवरफ़्लो पर पोस्ट किए गए कई हज़ार प्रोग्रामिंग प्रश्नों (उदाहरण के लिए, "मैं पायथन में मूल्य के आधार पर एक शब्दकोश को कैसे सॉर्ट कर सकता हूं?") का उपयोग करने के लिए एक डेटासेट तैयार किया गया है। इनमें से प्रत्येक को ठीक एक टैग (या तो पायथन, सीशार्प, जावास्क्रिप्ट, या जावा) के साथ लेबल किया गया है। आपका काम एक प्रश्न को इनपुट के रूप में लेना है, और उपयुक्त टैग की भविष्यवाणी करना है, इस मामले में, पायथन।
आप जिस डेटासेट के साथ काम करेंगे, उसमें BigQuery पर बहुत बड़े सार्वजनिक स्टैक ओवरफ़्लो डेटासेट से निकाले गए कई हज़ार प्रश्न हैं, जिसमें 17 मिलियन से अधिक पोस्ट हैं।
डेटासेट डाउनलोड करने के बाद, आप पाएंगे कि इसमें IMDB डेटासेट के समान निर्देशिका संरचना है, जिसके साथ आपने पहले काम किया था:
train/
...python/
......0.txt
......1.txt
...javascript/
......0.txt
......1.txt
...csharp/
......0.txt
......1.txt
...java/
......0.txt
......1.txt
इस अभ्यास को पूरा करने के लिए, आपको निम्नलिखित संशोधन करके इस नोटबुक को स्टैक ओवरफ्लो डेटासेट के साथ काम करने के लिए संशोधित करना चाहिए:
अपनी नोटबुक के शीर्ष पर, पहले से तैयार किए गए स्टैक ओवरफ़्लो डेटासेट को डाउनलोड करने के लिए कोड के साथ IMDB डेटासेट डाउनलोड करने वाले कोड को अपडेट करें। चूंकि स्टैक ओवरफ्लो डेटासेट में एक समान निर्देशिका संरचना होती है, इसलिए आपको कई संशोधन करने की आवश्यकता नहीं होगी।
अपने मॉडल की अंतिम परत को
Dense(4)में संशोधित करें, क्योंकि अब चार आउटपुट वर्ग हैं।मॉडल को संकलित करते समय, नुकसान को
tf.keras.losses.SparseCategoricalCrossentropyमें बदलें। बहु-वर्ग वर्गीकरण समस्या के लिए उपयोग करने के लिए यह सही हानि फ़ंक्शन है, जब प्रत्येक वर्ग के लिए लेबल पूर्णांक होते हैं (इस मामले में, वे 0, 1 , 2 , या 3 हो सकते हैं)। इसके अलावा, मेट्रिक्स कोmetrics=['accuracy']में बदलें, क्योंकि यह एक बहु-वर्ग वर्गीकरण समस्या है (tf.metrics.BinaryAccuracyका उपयोग केवल बाइनरी क्लासिफायर के लिए किया जाता है)।समय के साथ सटीकता की साजिश रचते समय,
binary_accuracyऔरval_binary_accuracyको क्रमशःaccuracyऔरval_accuracyमें बदलें।एक बार ये परिवर्तन पूर्ण हो जाने के बाद, आप एक बहु-वर्ग क्लासिफायरियर को प्रशिक्षित करने में सक्षम होंगे।
और अधिक सीखना
इस ट्यूटोरियल ने स्क्रैच से टेक्स्ट वर्गीकरण की शुरुआत की। सामान्य रूप से टेक्स्ट वर्गीकरण वर्कफ़्लो के बारे में अधिक जानने के लिए, Google डेवलपर्स से टेक्स्ट वर्गीकरण मार्गदर्शिका देखें।
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.