
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
Ten przewodnik szkoli model sieci neuronowej do klasyfikowania obrazów ubrań, takich jak trampki i koszule. W porządku, jeśli nie rozumiesz wszystkich szczegółów; jest to szybki przegląd kompletnego programu TensorFlow ze szczegółami wyjaśnionymi na bieżąco.
Ten przewodnik wykorzystuje tf.keras , wysokopoziomowy interfejs API do budowania i trenowania modeli w TensorFlow.
# TensorFlow and tf.keras
import tensorflow as tf
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)
2.8.0
Zaimportuj zestaw danych Fashion MNIST
Ten przewodnik korzysta z zestawu danych Fashion MNIST , który zawiera 70 000 obrazów w skali szarości w 10 kategoriach. Zdjęcia przedstawiają poszczególne artykuły odzieżowe w niskiej rozdzielczości (28 na 28 pikseli), jak widać tutaj:
| Rysunek 1. Próbki Fashion-MNIST (firma Zalando, licencja MIT). |
Fashion MNIST ma zastąpić klasyczny zbiór danych MNIST — często używany jako „Hello, World” programów uczenia maszynowego do widzenia komputerowego. Zbiór danych MNIST zawiera obrazy odręcznych cyfr (0, 1, 2 itd.) w formacie identycznym z używanymi tutaj artykułami odzieżowymi.
Ten przewodnik wykorzystuje Fashion MNIST dla urozmaicenia i ponieważ jest to nieco trudniejszy problem niż zwykły MNIST. Oba zestawy danych są stosunkowo małe i służą do weryfikacji, czy algorytm działa zgodnie z oczekiwaniami. Są dobrym punktem wyjścia do testowania i debugowania kodu.
W tym przypadku 60 000 obrazów jest używanych do trenowania sieci, a 10 000 obrazów do oceny, jak dokładnie sieć nauczyła się klasyfikować obrazy. Możesz uzyskać dostęp do Fashion MNIST bezpośrednio z TensorFlow. Importuj i ładuj dane Fashion MNIST bezpośrednio z TensorFlow:
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step 40960/29515 [=========================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step 26435584/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 16384/5148 [===============================================================================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step 4431872/4422102 [==============================] - 0s 0us/step
Załadowanie zestawu danych zwraca cztery tablice NumPy:
-
train_imagesitrain_labelssą zbiorem uczącym — danymi, których model używa do uczenia się. - Model jest testowany względem tablic test set ,
test_imagesitest_labels.
Obrazy są tablicami 28x28 NumPy, z wartościami pikseli w zakresie od 0 do 255. Etykiety są tablicami liczb całkowitych z zakresu od 0 do 9. Odpowiadają one klasie odzieży, którą reprezentuje obraz:
| Etykieta | Klasa |
|---|---|
| 0 | T-shirt/top |
| 1 | Spodnie |
| 2 | Zjechać na pobocze |
| 3 | Sukienka |
| 4 | Płaszcz |
| 5 | Sandał |
| 6 | Koszula |
| 7 | tenisówki |
| 8 | Torba |
| 9 | Buty za kostkę |
Każdy obraz jest mapowany na pojedynczą etykietę. Ponieważ nazwy klas nie są dołączone do zestawu danych, zapisz je tutaj, aby użyć później podczas kreślenia obrazów:
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
Przeglądaj dane
Przyjrzyjmy się formatowi zestawu danych przed trenowaniem modelu. Poniżej pokazano, że w zestawie uczącym znajduje się 60 000 obrazów, a każdy obraz jest reprezentowany jako 28 x 28 pikseli:
train_images.shape
(60000, 28, 28)
Podobnie w zestawie szkoleniowym znajduje się 60 000 etykiet:
len(train_labels)
60000
Każda etykieta jest liczbą całkowitą od 0 do 9:
train_labels
array([9, 0, 0, ..., 3, 0, 5], dtype=uint8)
W zestawie testowym znajduje się 10 000 obrazów. Ponownie, każdy obraz jest reprezentowany jako 28 x 28 pikseli:
test_images.shape
(10000, 28, 28)
A zestaw testowy zawiera 10 000 etykiet obrazów:
len(test_labels)
10000
Wstępnie przetworzyć dane
Dane muszą być wstępnie przetworzone przed uczeniem sieci. Jeśli przyjrzysz się pierwszemu obrazowi w zestawie uczącym, zobaczysz, że wartości pikseli mieszczą się w zakresie od 0 do 255:
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()
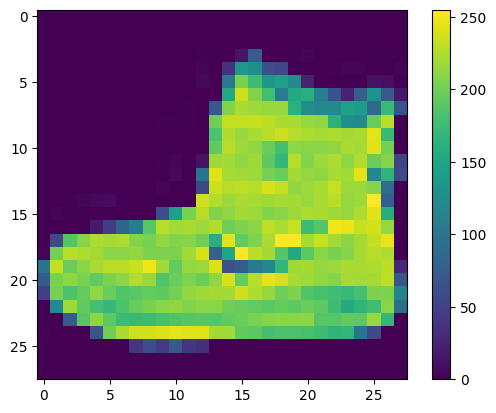
Przeskaluj te wartości do zakresu od 0 do 1 przed wprowadzeniem ich do modelu sieci neuronowej. Aby to zrobić, podziel wartości przez 255. Ważne jest, aby zestaw uczący i zestaw testowy zostały wstępnie przetworzone w ten sam sposób:
train_images = train_images / 255.0
test_images = test_images / 255.0
Aby sprawdzić, czy dane są w poprawnym formacie i czy jesteś gotowy do zbudowania i trenowania sieci, wyświetlmy pierwszych 25 obrazów z zestawu szkoleniowego i wyświetlmy nazwę klasy pod każdym obrazem.
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()

Zbuduj model
Budowanie sieci neuronowej wymaga skonfigurowania warstw modelu, a następnie skompilowania modelu.
Skonfiguruj warstwy
Podstawowym budulcem sieci neuronowej jest warstwa . Warstwy wyodrębniają reprezentacje z wprowadzonych do nich danych. Miejmy nadzieję, że te reprezentacje mają znaczenie dla omawianego problemu.
Większość uczenia głębokiego polega na łączeniu prostych warstw. Większość warstw, takich jak tf.keras.layers.Dense , ma parametry, których uczymy się podczas treningu.
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10)
])
Pierwsza warstwa w tej sieci, tf.keras.layers.Flatten , przekształca format obrazów z dwuwymiarowej tablicy (o wymiarach 28 na 28 pikseli) na jednowymiarową (o 28 * 28 = 784 piksele). Pomyśl o tej warstwie jako o rozłożeniu rzędów pikseli na obrazie i wyrównaniu ich. Ta warstwa nie ma parametrów do nauki; tylko formatuje dane.
Po spłaszczeniu pikseli sieć składa się z sekwencji dwóch warstw tf.keras.layers.Dense . Są to gęsto połączone lub w pełni połączone warstwy neuronowe. Pierwsza warstwa Dense ma 128 węzłów (lub neuronów). Druga (i ostatnia) warstwa zwraca tablicę logits o długości 10. Każdy węzeł zawiera wynik wskazujący, że bieżący obraz należy do jednej z 10 klas.
Skompiluj model
Zanim model będzie gotowy do trenowania, potrzebuje kilku dodatkowych ustawień. Są one dodawane podczas kroku kompilacji modelu:
- Funkcja straty — mierzy dokładność modelu podczas uczenia. Chcesz zminimalizować tę funkcję, aby „sterować” modelem we właściwym kierunku.
- Optymalizator — w ten sposób model jest aktualizowany na podstawie danych, które widzi i jego funkcji utraty.
- Metryki — używane do monitorowania etapów uczenia i testowania. Poniższy przykład wykorzystuje dokładność , część obrazów, które są poprawnie sklasyfikowane.
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Trenuj modelkę
Uczenie modelu sieci neuronowej wymaga wykonania następujących kroków:
- Wprowadź dane szkoleniowe do modelu. W tym przykładzie dane szkoleniowe znajdują się w
train_imagesitrain_labels. - Model uczy się kojarzyć obrazy i etykiety.
- Poprosisz model, aby przewidział zestaw testowy — w tym przykładzie tablicę
test_images. - Sprawdź, czy prognozy są zgodne z etykietami z tablicy
test_labels.
Nakarm modelkę
Aby rozpocząć trenowanie, wywołaj metodę model.fit — nazywaną tak, ponieważ „dopasowuje” model do danych szkoleniowych:
model.fit(train_images, train_labels, epochs=10)
Epoch 1/10 1875/1875 [==============================] - 4s 2ms/step - loss: 0.4986 - accuracy: 0.8253 Epoch 2/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3751 - accuracy: 0.8651 Epoch 3/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3364 - accuracy: 0.8769 Epoch 4/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3124 - accuracy: 0.8858 Epoch 5/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2949 - accuracy: 0.8913 Epoch 6/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2776 - accuracy: 0.8977 Epoch 7/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2669 - accuracy: 0.9022 Epoch 8/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2552 - accuracy: 0.9046 Epoch 9/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2463 - accuracy: 0.9089 Epoch 10/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2376 - accuracy: 0.9117 <keras.callbacks.History at 0x7f5f2c785110>
W miarę trenowania modelu wyświetlane są metryki strat i dokładności. Model ten osiąga dokładność około 0,91 (lub 91%) na danych treningowych.
Oceń dokładność
Następnie porównaj, jak model działa na testowym zbiorze danych:
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)
313/313 - 1s - loss: 0.3176 - accuracy: 0.8895 - 553ms/epoch - 2ms/step Test accuracy: 0.8895000219345093
Okazuje się, że dokładność zestawu danych testowych jest nieco mniejsza niż dokładność zestawu danych treningowych. Ta luka między dokładnością treningu a dokładnością testu oznacza przesadne dopasowanie . Overfitting ma miejsce, gdy model uczenia maszynowego działa gorzej na nowych, wcześniej niewidocznych danych wejściowych niż na danych szkoleniowych. Przesadnie dopasowany model „zapamiętuje” szum i szczegóły w uczącym zestawie danych do punktu, w którym negatywnie wpływa na wydajność modelu na nowych danych. Aby uzyskać więcej informacji, zobacz następujące:
Prognozować
Po przeszkoleniu modelu można go używać do przewidywania niektórych obrazów. Dołącz warstwę softmax, aby przekonwertować liniowe dane wyjściowe modelu — logity — na prawdopodobieństwa, które powinny być łatwiejsze do zinterpretowania.
probability_model = tf.keras.Sequential([model,
tf.keras.layers.Softmax()])
predictions = probability_model.predict(test_images)
Tutaj model przewidział etykietę dla każdego obrazu w zestawie testowym. Przyjrzyjmy się pierwszej prognozie:
predictions[0]
array([1.3835326e-08, 2.7011181e-11, 2.6019606e-10, 5.6872784e-11,
1.2070331e-08, 4.1874609e-04, 1.1151612e-08, 5.7000564e-03,
8.1178889e-08, 9.9388099e-01], dtype=float32)
Przewidywanie to tablica 10 liczb. Reprezentują „pewność” modelki, że obraz odpowiada każdemu z 10 różnych artykułów garderoby. Możesz zobaczyć, która etykieta ma najwyższą wartość ufności:
np.argmax(predictions[0])
9
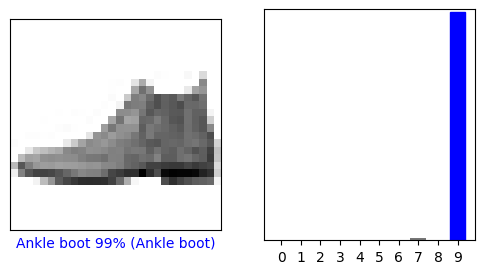
Tak więc model jest najbardziej przekonany, że ten obraz to but do kostki, czyli class_names[9] . Badanie etykiety testowej pokazuje, że ta klasyfikacja jest prawidłowa:
test_labels[0]
9
Narysuj ten wykres, aby zobaczyć pełny zestaw 10 prognoz klas.
def plot_image(i, predictions_array, true_label, img):
true_label, img = true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
true_label = true_label[i]
plt.grid(False)
plt.xticks(range(10))
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
Sprawdź prognozy
Po przeszkoleniu modelu można go używać do przewidywania niektórych obrazów.
Spójrzmy na zerowy obraz, przewidywania i tablicę przewidywań. Prawidłowe etykiety prognozy są niebieskie, a nieprawidłowe etykiety prognoz są czerwone. Liczba podaje procent (ze 100) dla przewidywanej etykiety.
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
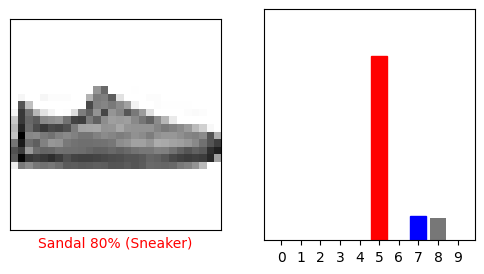
i = 12
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
Narysujmy kilka obrazów z ich przewidywaniami. Pamiętaj, że model może się mylić, nawet jeśli jest bardzo pewny siebie.
# Plot the first X test images, their predicted labels, and the true labels.
# Color correct predictions in blue and incorrect predictions in red.
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions[i], test_labels)
plt.tight_layout()
plt.show()

Użyj wyszkolonego modelu
Na koniec użyj wytrenowanego modelu, aby dokonać prognozy dotyczącej pojedynczego obrazu.
# Grab an image from the test dataset.
img = test_images[1]
print(img.shape)
(28, 28)
Modele tf.keras są zoptymalizowane pod kątem jednoczesnego przewidywania partii lub kolekcji przykładów. W związku z tym, nawet jeśli używasz pojedynczego obrazu, musisz dodać go do listy:
# Add the image to a batch where it's the only member.
img = (np.expand_dims(img,0))
print(img.shape)
(1, 28, 28)
Teraz wytypuj poprawną etykietę dla tego obrazu:
predictions_single = probability_model.predict(img)
print(predictions_single)
[[8.26038831e-06 1.10213664e-13 9.98591125e-01 1.16777841e-08 1.29609776e-03 2.54965649e-11 1.04560357e-04 7.70050608e-19 4.55051066e-11 3.53864888e-17]]
plot_value_array(1, predictions_single[0], test_labels)
_ = plt.xticks(range(10), class_names, rotation=45)
plt.show()
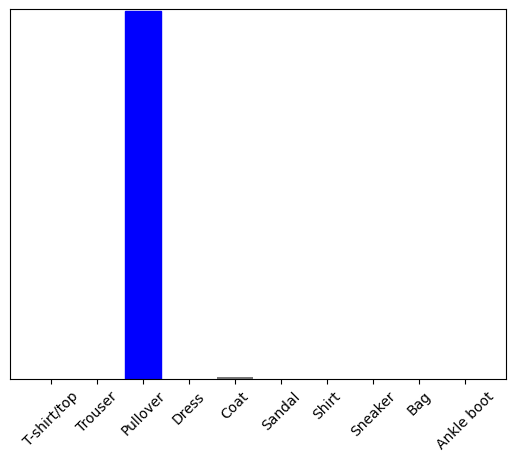
tf.keras.Model.predict zwraca listę list — jedną listę dla każdego obrazu w partii danych. Pobierz prognozy dla naszego (tylko) obrazu w partii:
np.argmax(predictions_single[0])
2
A model przewiduje etykietę zgodnie z oczekiwaniami.
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.