
| | |  Visualizza l'origine su GitHub Visualizza l'origine su GitHub | |
Questa guida addestra un modello di rete neurale per classificare le immagini di abbigliamento, come scarpe da ginnastica e magliette. Va bene se non capisci tutti i dettagli; questa è una panoramica veloce di un programma TensorFlow completo con i dettagli spiegati man mano.
Questa guida utilizza tf.keras , un'API di alto livello per creare e addestrare modelli in TensorFlow.
# TensorFlow and tf.keras
import tensorflow as tf
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
print(tf.__version__)
2.8.0
Importa il set di dati Fashion MNIST
Questa guida utilizza il set di dati Fashion MNIST che contiene 70.000 immagini in scala di grigi in 10 categorie. Le immagini mostrano singoli capi di abbigliamento a bassa risoluzione (28 x 28 pixel), come si vede qui:
| Figura 1. Campioni Fashion-MNIST (di Zalando, licenza MIT). |
Fashion MNIST è inteso come un sostituto drop-in per il classico set di dati MNIST , spesso utilizzato come "Hello, World" dei programmi di apprendimento automatico per la visione artificiale. Il set di dati MNIST contiene immagini di cifre scritte a mano (0, 1, 2, ecc.) in un formato identico a quello degli articoli di abbigliamento che utilizzerai qui.
Questa guida utilizza Fashion MNIST per varietà e perché è un problema leggermente più impegnativo rispetto al normale MNIST. Entrambi i set di dati sono relativamente piccoli e vengono utilizzati per verificare che un algoritmo funzioni come previsto. Sono buoni punti di partenza per testare ed eseguire il debug del codice.
Qui, 60.000 immagini vengono utilizzate per addestrare la rete e 10.000 immagini per valutare con quanta precisione la rete ha imparato a classificare le immagini. Puoi accedere al Fashion MNIST direttamente da TensorFlow. Importa e carica i dati Fashion MNIST direttamente da TensorFlow:
fashion_mnist = tf.keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 32768/29515 [=================================] - 0s 0us/step 40960/29515 [=========================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26427392/26421880 [==============================] - 0s 0us/step 26435584/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 16384/5148 [===============================================================================================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4423680/4422102 [==============================] - 0s 0us/step 4431872/4422102 [==============================] - 0s 0us/step
Il caricamento del set di dati restituisce quattro array NumPy:
- Gli array
train_imagesetrain_labelssono il set di addestramento , ovvero i dati che il modello utilizza per apprendere. - Il modello viene testato rispetto agli array test set ,
test_imagesetest_labels.
Le immagini sono array NumPy 28x28, con valori di pixel compresi tra 0 e 255. Le etichette sono un array di numeri interi, compresi tra 0 e 9. Questi corrispondono alla classe di abbigliamento rappresentata dall'immagine:
| Etichetta | Classe |
|---|---|
| 0 | T-shirt/top |
| 1 | Pantaloni |
| 2 | Maglione |
| 3 | Vestire |
| 4 | Cappotto |
| 5 | Sandalo |
| 6 | Camicia |
| 7 | Sneaker |
| 8 | Borsa |
| 9 | Stivaletto |
Ogni immagine è mappata su una singola etichetta. Poiché i nomi delle classi non sono inclusi nel set di dati, archiviali qui per utilizzarli in seguito durante la stampa delle immagini:
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
Esplora i dati
Esaminiamo il formato del set di dati prima di eseguire il training del modello. Quanto segue mostra che ci sono 60.000 immagini nel set di addestramento, con ciascuna immagine rappresentata come 28 x 28 pixel:
train_images.shape
(60000, 28, 28)
Allo stesso modo, ci sono 60.000 etichette nel set di formazione:
len(train_labels)
60000
Ogni etichetta è un numero intero compreso tra 0 e 9:
train_labels
array([9, 0, 0, ..., 3, 0, 5], dtype=uint8)
Ci sono 10.000 immagini nel set di prova. Anche in questo caso, ogni immagine è rappresentata come 28 x 28 pixel:
test_images.shape
(10000, 28, 28)
E il set di test contiene 10.000 etichette di immagini:
len(test_labels)
10000
Preelabora i dati
I dati devono essere preelaborati prima dell'addestramento della rete. Se esamini la prima immagine nel set di addestramento, vedrai che i valori dei pixel rientrano nell'intervallo da 0 a 255:
plt.figure()
plt.imshow(train_images[0])
plt.colorbar()
plt.grid(False)
plt.show()
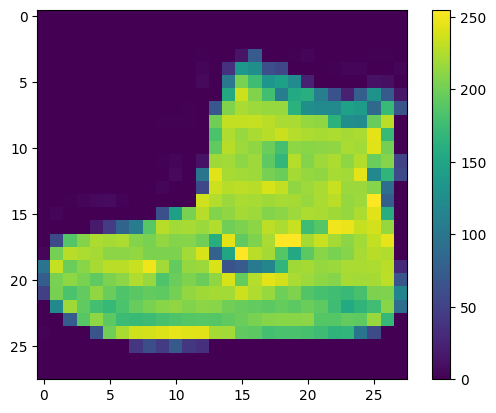
Ridimensiona questi valori in un intervallo da 0 a 1 prima di inviarli al modello di rete neurale. Per fare ciò, dividi i valori per 255. È importante che il set di addestramento e il set di test siano preelaborati allo stesso modo:
train_images = train_images / 255.0
test_images = test_images / 255.0
Per verificare che i dati siano nel formato corretto e che tu sia pronto per costruire e addestrare la rete, visualizziamo le prime 25 immagini dal set di formazione e mostriamo il nome della classe sotto ogni immagine.
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[train_labels[i]])
plt.show()

Costruisci il modello
La costruzione della rete neurale richiede la configurazione dei livelli del modello, quindi la compilazione del modello.
Prepara i livelli
L'elemento costitutivo di base di una rete neurale è il livello . I livelli estraggono le rappresentazioni dai dati inseriti in essi. Si spera che queste rappresentazioni siano significative per il problema in questione.
La maggior parte del deep learning consiste nel concatenare insieme semplici livelli. La maggior parte dei livelli, ad esempio tf.keras.layers.Dense , ha parametri che vengono appresi durante l'allenamento.
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(10)
])
Il primo livello di questa rete, tf.keras.layers.Flatten , trasforma il formato delle immagini da una matrice bidimensionale (di 28 x 28 pixel) a una matrice unidimensionale (di 28 * 28 = 784 pixel). Pensa a questo livello come al disimpilamento di righe di pixel nell'immagine e al loro allineamento. Questo livello non ha parametri da apprendere; riformatta solo i dati.
Dopo che i pixel sono stati appiattiti, la rete è costituita da una sequenza di due livelli tf.keras.layers.Dense . Questi sono strati neurali densamente collegati o completamente connessi. Il primo strato Dense ha 128 nodi (o neuroni). Il secondo (e ultimo) livello restituisce un array logit con lunghezza 10. Ogni nodo contiene un punteggio che indica che l'immagine corrente appartiene a una delle 10 classi.
Compila il modello
Prima che il modello sia pronto per l'addestramento, sono necessarie alcune impostazioni in più. Questi vengono aggiunti durante la fase di compilazione del modello:
- Funzione di perdita: misura la precisione del modello durante l'allenamento. Si desidera ridurre al minimo questa funzione per "guidare" il modello nella giusta direzione.
- Ottimizzatore : ecco come viene aggiornato il modello in base ai dati che vede e alla sua funzione di perdita.
- Metriche : utilizzate per monitorare le fasi di formazione e test. L'esempio seguente utilizza precision , la frazione delle immagini classificate correttamente.
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Allena il modello
L'addestramento del modello di rete neurale richiede i seguenti passaggi:
- Invia i dati di addestramento al modello. In questo esempio, i dati di addestramento si trovano negli array
train_imagesetrain_labels. - Il modello impara ad associare immagini ed etichette.
- Chiedi al modello di fare previsioni su un set di test, in questo esempio l'array
test_images. - Verifica che le previsioni corrispondano alle etichette dell'array
test_labels.
Dai da mangiare al modello
Per iniziare l'addestramento, chiama il metodo model.fit , così chiamato perché "adatta" il modello ai dati di addestramento:
model.fit(train_images, train_labels, epochs=10)
Epoch 1/10 1875/1875 [==============================] - 4s 2ms/step - loss: 0.4986 - accuracy: 0.8253 Epoch 2/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3751 - accuracy: 0.8651 Epoch 3/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3364 - accuracy: 0.8769 Epoch 4/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.3124 - accuracy: 0.8858 Epoch 5/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2949 - accuracy: 0.8913 Epoch 6/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2776 - accuracy: 0.8977 Epoch 7/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2669 - accuracy: 0.9022 Epoch 8/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2552 - accuracy: 0.9046 Epoch 9/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2463 - accuracy: 0.9089 Epoch 10/10 1875/1875 [==============================] - 3s 2ms/step - loss: 0.2376 - accuracy: 0.9117 <keras.callbacks.History at 0x7f5f2c785110>
Mentre il modello si allena, vengono visualizzate le metriche di perdita e precisione. Questo modello raggiunge una precisione di circa 0,91 (o 91%) sui dati di addestramento.
Valuta l'accuratezza
Quindi, confronta le prestazioni del modello sul set di dati di test:
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)
313/313 - 1s - loss: 0.3176 - accuracy: 0.8895 - 553ms/epoch - 2ms/step Test accuracy: 0.8895000219345093
Si scopre che l'accuratezza del set di dati di test è leggermente inferiore all'accuratezza del set di dati di addestramento. Questo divario tra l'accuratezza dell'allenamento e l'accuratezza del test rappresenta un overfitting . L'overfitting si verifica quando un modello di machine learning ha prestazioni peggiori con input nuovi e non visti in precedenza rispetto ai dati di addestramento. Un modello sovradimensionato "memorizza" il rumore e i dettagli nel set di dati di addestramento al punto in cui ha un impatto negativo sulle prestazioni del modello sui nuovi dati. Per ulteriori informazioni, vedere quanto segue:
Fare previsioni
Con il modello addestrato, puoi usarlo per fare previsioni su alcune immagini. Allega un livello softmax per convertire gli output lineari del modello - logit - in probabilità, che dovrebbero essere più facili da interpretare.
probability_model = tf.keras.Sequential([model,
tf.keras.layers.Softmax()])
predictions = probability_model.predict(test_images)
Qui, il modello ha previsto l'etichetta per ogni immagine nel set di test. Diamo un'occhiata alla prima previsione:
predictions[0]
array([1.3835326e-08, 2.7011181e-11, 2.6019606e-10, 5.6872784e-11,
1.2070331e-08, 4.1874609e-04, 1.1151612e-08, 5.7000564e-03,
8.1178889e-08, 9.9388099e-01], dtype=float32)
Una previsione è una matrice di 10 numeri. Rappresentano la "fiducia" della modella che l'immagine corrisponda a ciascuno dei 10 diversi capi di abbigliamento. Puoi vedere quale etichetta ha il valore di confidenza più alto:
np.argmax(predictions[0])
9
Quindi, il modello è più sicuro che questa immagine sia uno stivaletto o class_names[9] . L'esame dell'etichetta del test mostra che questa classificazione è corretta:
test_labels[0]
9
Disegna questo grafico per esaminare l'insieme completo di 10 previsioni di classe.
def plot_image(i, predictions_array, true_label, img):
true_label, img = true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
true_label = true_label[i]
plt.grid(False)
plt.xticks(range(10))
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')
Verifica le previsioni
Con il modello addestrato, puoi usarlo per fare previsioni su alcune immagini.
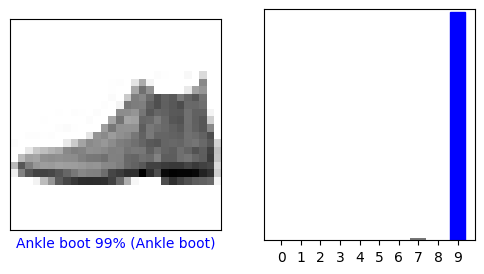
Diamo un'occhiata all'immagine 0, alle previsioni e all'array di previsione. Le etichette di previsione corretta sono blu e le etichette di previsione errata sono rosse. Il numero fornisce la percentuale (su 100) per l'etichetta prevista.
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
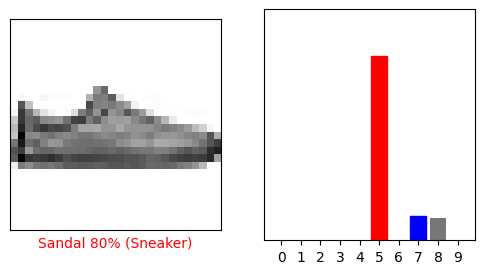
i = 12
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()
Tracciamo diverse immagini con le loro previsioni. Nota che il modello può essere sbagliato anche quando è molto sicuro.
# Plot the first X test images, their predicted labels, and the true labels.
# Color correct predictions in blue and incorrect predictions in red.
num_rows = 5
num_cols = 3
num_images = num_rows*num_cols
plt.figure(figsize=(2*2*num_cols, 2*num_rows))
for i in range(num_images):
plt.subplot(num_rows, 2*num_cols, 2*i+1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(num_rows, 2*num_cols, 2*i+2)
plot_value_array(i, predictions[i], test_labels)
plt.tight_layout()
plt.show()

Usa il modello addestrato
Infine, usa il modello addestrato per fare una previsione su una singola immagine.
# Grab an image from the test dataset.
img = test_images[1]
print(img.shape)
(28, 28)
I modelli tf.keras sono ottimizzati per fare previsioni su un batch o una raccolta di esempi contemporaneamente. Di conseguenza, anche se stai utilizzando una singola immagine, devi aggiungerla a un elenco:
# Add the image to a batch where it's the only member.
img = (np.expand_dims(img,0))
print(img.shape)
(1, 28, 28)
Ora prevedi l'etichetta corretta per questa immagine:
predictions_single = probability_model.predict(img)
print(predictions_single)
[[8.26038831e-06 1.10213664e-13 9.98591125e-01 1.16777841e-08 1.29609776e-03 2.54965649e-11 1.04560357e-04 7.70050608e-19 4.55051066e-11 3.53864888e-17]]
plot_value_array(1, predictions_single[0], test_labels)
_ = plt.xticks(range(10), class_names, rotation=45)
plt.show()
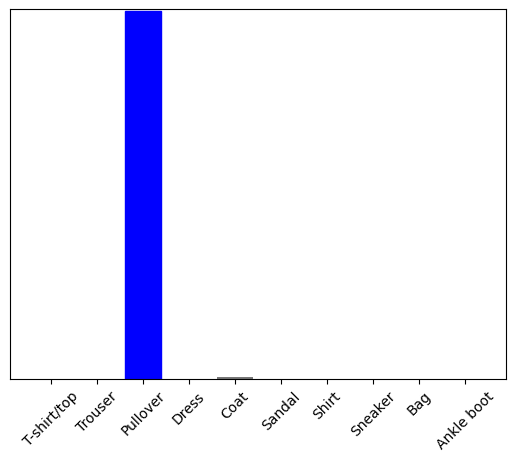
tf.keras.Model.predict restituisce un elenco di elenchi, un elenco per ogni immagine nel batch di dati. Prendi le previsioni per la nostra (unica) immagine nel batch:
np.argmax(predictions_single[0])
2
E il modello prevede un'etichetta come previsto.
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.