
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
در این آموزش نحوه طبقه بندی تصاویر گربه ها و سگ ها را با استفاده از آموزش انتقال از یک شبکه از پیش آموزش دیده یاد خواهید گرفت.
یک مدل از پیش آموزشدیده، یک شبکه ذخیرهشده است که قبلاً روی یک مجموعه داده بزرگ، معمولاً در یک کار طبقهبندی تصویر در مقیاس بزرگ، آموزش داده شده است. شما یا از مدل از پیش آموزش دیده استفاده می کنید یا از آموزش انتقال برای سفارشی کردن این مدل برای یک کار خاص استفاده می کنید.
شهود پشت یادگیری انتقال برای طبقه بندی تصویر این است که اگر یک مدل بر روی یک مجموعه داده بزرگ و کلی به اندازه کافی آموزش داده شود، این مدل به طور موثر به عنوان یک مدل عمومی از دنیای بصری عمل خواهد کرد. سپس می توانید با آموزش یک مدل بزرگ بر روی یک مجموعه داده بزرگ، از این نقشه های ویژگی های آموخته شده بدون نیاز به شروع از ابتدا استفاده کنید.
در این نوت بوک، دو روش را برای سفارشی کردن یک مدل از پیش آموزش دیده امتحان خواهید کرد:
استخراج ویژگی: از بازنمایی های آموخته شده توسط شبکه قبلی برای استخراج ویژگی های معنی دار از نمونه های جدید استفاده کنید. شما به سادگی یک طبقهبندیکننده جدید را که از ابتدا آموزش داده میشود، در بالای مدل از پیش آموزش دیده اضافه میکنید تا بتوانید نقشههای ویژگیهایی که قبلاً آموختهاید را برای مجموعه دادهها تغییر دهید.
شما نیازی به (دوباره) آموزش کل مدل ندارید. شبکه کانولوشن پایه از قبل دارای ویژگی هایی است که به طور کلی برای طبقه بندی تصاویر مفید هستند. با این حال، بخش نهایی و طبقهبندی مدل از پیش آموزشدیده، مختص کار طبقهبندی اصلی است و متعاقباً به مجموعه کلاسهایی که مدل بر روی آنها آموزش داده شده است.
تنظیم دقیق: تعدادی از لایههای بالای پایه مدل فریز شده را از حالت انجماد خارج کنید و به طور مشترک لایههای طبقهبندیکننده جدید و آخرین لایههای مدل پایه را آموزش دهید. این به ما این امکان را میدهد که نمایشهای ویژگیهای مرتبه بالاتر را در مدل پایه "تنظیم دقیق" کنیم تا آنها را برای کار خاص مرتبط تر کنیم.
شما روند کلی کار یادگیری ماشین را دنبال خواهید کرد.
- داده ها را بررسی و درک کنید
- یک خط لوله ورودی بسازید، در این مورد با استفاده از Keras ImageDataGenerator
- مدل را بنویسید
- بار در مدل پایه از پیش آموزش دیده (و وزنه های از پیش آموزش دیده)
- لایه های طبقه بندی را در بالا قرار دهید
- مدل را آموزش دهید
- مدل را ارزیابی کنید
import matplotlib.pyplot as plt
import numpy as np
import os
import tensorflow as tf
پیش پردازش داده ها
دانلود داده ها
در این آموزش از مجموعه داده ای حاوی چندین هزار تصویر از گربه ها و سگ ها استفاده خواهید کرد. یک فایل فشرده حاوی تصاویر را دانلود و استخراج کنید، سپس یک tf.data.Dataset برای آموزش و اعتبار سنجی با استفاده از ابزار tf.keras.utils.image_dataset_from_directory کنید. در این آموزش می توانید در مورد بارگذاری تصاویر بیشتر بیاموزید.
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
path_to_zip = tf.keras.utils.get_file('cats_and_dogs.zip', origin=_URL, extract=True)
PATH = os.path.join(os.path.dirname(path_to_zip), 'cats_and_dogs_filtered')
train_dir = os.path.join(PATH, 'train')
validation_dir = os.path.join(PATH, 'validation')
BATCH_SIZE = 32
IMG_SIZE = (160, 160)
train_dataset = tf.keras.utils.image_dataset_from_directory(train_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
Downloading data from https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip 68608000/68606236 [==============================] - 1s 0us/step 68616192/68606236 [==============================] - 1s 0us/step Found 2000 files belonging to 2 classes.
validation_dataset = tf.keras.utils.image_dataset_from_directory(validation_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
Found 1000 files belonging to 2 classes.
نمایش نه تصویر اول و برچسب از مجموعه آموزشی:
class_names = train_dataset.class_names
plt.figure(figsize=(10, 10))
for images, labels in train_dataset.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")

از آنجایی که مجموعه داده اصلی شامل مجموعه آزمایشی نیست، شما یکی را ایجاد خواهید کرد. برای انجام این کار، با استفاده از tf.data.experimental.cardinality تعیین کنید که چند دسته داده در مجموعه اعتبارسنجی موجود است، سپس 20٪ از آنها را به یک مجموعه آزمایشی منتقل کنید.
val_batches = tf.data.experimental.cardinality(validation_dataset)
test_dataset = validation_dataset.take(val_batches // 5)
validation_dataset = validation_dataset.skip(val_batches // 5)
print('Number of validation batches: %d' % tf.data.experimental.cardinality(validation_dataset))
print('Number of test batches: %d' % tf.data.experimental.cardinality(test_dataset))
Number of validation batches: 26 Number of test batches: 6
مجموعه داده را برای عملکرد پیکربندی کنید
از واکشی اولیه بافر برای بارگیری تصاویر از دیسک بدون مسدود شدن I/O استفاده کنید. برای کسب اطلاعات بیشتر در مورد این روش به راهنمای عملکرد داده مراجعه کنید.
AUTOTUNE = tf.data.AUTOTUNE
train_dataset = train_dataset.prefetch(buffer_size=AUTOTUNE)
validation_dataset = validation_dataset.prefetch(buffer_size=AUTOTUNE)
test_dataset = test_dataset.prefetch(buffer_size=AUTOTUNE)
از افزایش داده ها استفاده کنید
هنگامی که مجموعه داده تصویری بزرگی ندارید، این تمرین خوبی است که به طور مصنوعی تنوع نمونه را با اعمال تغییرات تصادفی و در عین حال واقعی در تصاویر آموزشی مانند چرخش و چرخش افقی معرفی کنید. این کمک می کند که مدل در معرض جنبه های مختلف داده های آموزشی قرار گیرد و اضافه برازش کاهش یابد. در این آموزش میتوانید درباره افزایش دادهها اطلاعات بیشتری کسب کنید.
data_augmentation = tf.keras.Sequential([
tf.keras.layers.RandomFlip('horizontal'),
tf.keras.layers.RandomRotation(0.2),
])
بیایید بارها و بارها این لایه ها را روی همان تصویر اعمال کنیم و نتیجه را ببینیم.
for image, _ in train_dataset.take(1):
plt.figure(figsize=(10, 10))
first_image = image[0]
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
augmented_image = data_augmentation(tf.expand_dims(first_image, 0))
plt.imshow(augmented_image[0] / 255)
plt.axis('off')

مقیاس مجدد مقادیر پیکسل
در یک لحظه، tf.keras.applications.MobileNetV2 را برای استفاده به عنوان مدل پایه خود دانلود خواهید کرد. این مدل مقادیر پیکسل را در [-1, 1] انتظار دارد، اما در این مرحله، مقادیر پیکسل در تصاویر شما در [0, 255] هستند. برای تغییر مقیاس آنها، از روش پیش پردازش ارائه شده با مدل استفاده کنید.
preprocess_input = tf.keras.applications.mobilenet_v2.preprocess_input
rescale = tf.keras.layers.Rescaling(1./127.5, offset=-1)
مدل پایه را از convnet های از پیش آموزش دیده ایجاد کنید
شما مدل پایه را از مدل MobileNet V2 توسعه یافته در Google ایجاد خواهید کرد. این از قبل بر روی مجموعه داده ImageNet آموزش داده شده است، مجموعه داده بزرگی متشکل از 1.4 میلیون تصویر و 1000 کلاس. ImageNet یک مجموعه داده آموزشی تحقیقاتی با طیف گسترده ای از دسته بندی ها مانند jackfruit و syringe است. این پایه دانش به ما کمک می کند تا گربه ها و سگ ها را از مجموعه داده های خاص خود طبقه بندی کنیم.
ابتدا باید انتخاب کنید از کدام لایه MobileNet V2 برای استخراج ویژگی استفاده کنید. آخرین لایه طبقه بندی (در "بالا"، زیرا بیشتر نمودارهای مدل های یادگیری ماشینی از پایین به بالا می روند) چندان مفید نیست. درعوض، شما از رویه رایج برای وابستگی به آخرین لایه قبل از عملیات مسطح پیروی خواهید کرد. این لایه "لایه گلوگاه" نامیده می شود. ویژگی های لایه گلوگاه عمومیت بیشتری نسبت به لایه نهایی/بالایی دارند.
ابتدا، یک مدل MobileNet V2 از پیش بارگذاری شده با وزنه های آموزش دیده در ImageNet را نمونه سازی کنید. با مشخص کردن آرگومان include_top=False ، شبکهای را بارگذاری میکنید که لایههای طبقهبندی در بالا را شامل نمیشود، که برای استخراج ویژگی ایدهآل است.
# Create the base model from the pre-trained model MobileNet V2
IMG_SHAPE = IMG_SIZE + (3,)
base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_160_no_top.h5 9412608/9406464 [==============================] - 0s 0us/step 9420800/9406464 [==============================] - 0s 0us/step
این استخراج کننده ویژگی هر تصویر 160x160x3 را به یک بلوک 5x5x1280 از ویژگی ها تبدیل می کند. بیایید ببینیم با یک دسته نمونه از تصاویر چه می کند:
image_batch, label_batch = next(iter(train_dataset))
feature_batch = base_model(image_batch)
print(feature_batch.shape)
(32, 5, 5, 1280)
استخراج ویژگی
در این مرحله، پایه کانولوشن ایجاد شده از مرحله قبل را منجمد کرده و به عنوان استخراج کننده ویژگی استفاده می کنید. علاوه بر این، یک طبقهبندیکننده در بالای آن اضافه میکنید و طبقهبندیکننده سطح بالا را آموزش میدهید.
پایه کانولوشن را فریز کنید
قبل از کامپایل و آموزش مدل، فریز کردن پایه کانولوشن مهم است. انجماد (با تنظیم layer.trainable = False) از به روز رسانی وزنه های یک لایه در طول تمرین جلوگیری می کند. MobileNet V2 لایههای زیادی دارد، بنابراین با تنظیم پرچم trainable کل مدل روی False، همه آنها مسدود میشوند.
base_model.trainable = False
نکته مهم در مورد لایه های BatchNormalization
بسیاری از مدل ها حاوی لایه های tf.keras.layers.BatchNormalization هستند. این لایه یک مورد خاص است و همانطور که در ادامه این آموزش نشان داده شده است، باید در زمینه تنظیم دقیق اقدامات احتیاطی انجام شود.
وقتی layer.trainable = False را تنظیم می کنید، لایه BatchNormalization در حالت استنتاج اجرا می شود و آمار میانگین و واریانس خود را به روز نمی کند.
هنگامی که یک مدل حاوی لایه های BatchNormalization را از حالت انجماد خارج می کنید تا تنظیم دقیق انجام شود، باید لایه های BatchNormalization را در حالت استنتاج با عبور دادن training = False هنگام فراخوانی مدل پایه نگه دارید. در غیر این صورت، بهروزرسانیهای اعمالشده در وزنهای غیرقابل آموزش، آنچه را که مدل آموخته است، از بین میبرد.
برای جزئیات بیشتر، به راهنمای یادگیری انتقال مراجعه کنید.
# Let's take a look at the base model architecture
base_model.summary()
Model: "mobilenetv2_1.00_160"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 160, 160, 3 0 []
)]
Conv1 (Conv2D) (None, 80, 80, 32) 864 ['input_1[0][0]']
bn_Conv1 (BatchNormalization) (None, 80, 80, 32) 128 ['Conv1[0][0]']
Conv1_relu (ReLU) (None, 80, 80, 32) 0 ['bn_Conv1[0][0]']
expanded_conv_depthwise (Depth (None, 80, 80, 32) 288 ['Conv1_relu[0][0]']
wiseConv2D)
expanded_conv_depthwise_BN (Ba (None, 80, 80, 32) 128 ['expanded_conv_depthwise[0][0]']
tchNormalization)
expanded_conv_depthwise_relu ( (None, 80, 80, 32) 0 ['expanded_conv_depthwise_BN[0][0
ReLU) ]']
expanded_conv_project (Conv2D) (None, 80, 80, 16) 512 ['expanded_conv_depthwise_relu[0]
[0]']
expanded_conv_project_BN (Batc (None, 80, 80, 16) 64 ['expanded_conv_project[0][0]']
hNormalization)
block_1_expand (Conv2D) (None, 80, 80, 96) 1536 ['expanded_conv_project_BN[0][0]'
]
block_1_expand_BN (BatchNormal (None, 80, 80, 96) 384 ['block_1_expand[0][0]']
ization)
block_1_expand_relu (ReLU) (None, 80, 80, 96) 0 ['block_1_expand_BN[0][0]']
block_1_pad (ZeroPadding2D) (None, 81, 81, 96) 0 ['block_1_expand_relu[0][0]']
block_1_depthwise (DepthwiseCo (None, 40, 40, 96) 864 ['block_1_pad[0][0]']
nv2D)
block_1_depthwise_BN (BatchNor (None, 40, 40, 96) 384 ['block_1_depthwise[0][0]']
malization)
block_1_depthwise_relu (ReLU) (None, 40, 40, 96) 0 ['block_1_depthwise_BN[0][0]']
block_1_project (Conv2D) (None, 40, 40, 24) 2304 ['block_1_depthwise_relu[0][0]']
block_1_project_BN (BatchNorma (None, 40, 40, 24) 96 ['block_1_project[0][0]']
lization)
block_2_expand (Conv2D) (None, 40, 40, 144) 3456 ['block_1_project_BN[0][0]']
block_2_expand_BN (BatchNormal (None, 40, 40, 144) 576 ['block_2_expand[0][0]']
ization)
block_2_expand_relu (ReLU) (None, 40, 40, 144) 0 ['block_2_expand_BN[0][0]']
block_2_depthwise (DepthwiseCo (None, 40, 40, 144) 1296 ['block_2_expand_relu[0][0]']
nv2D)
block_2_depthwise_BN (BatchNor (None, 40, 40, 144) 576 ['block_2_depthwise[0][0]']
malization)
block_2_depthwise_relu (ReLU) (None, 40, 40, 144) 0 ['block_2_depthwise_BN[0][0]']
block_2_project (Conv2D) (None, 40, 40, 24) 3456 ['block_2_depthwise_relu[0][0]']
block_2_project_BN (BatchNorma (None, 40, 40, 24) 96 ['block_2_project[0][0]']
lization)
block_2_add (Add) (None, 40, 40, 24) 0 ['block_1_project_BN[0][0]',
'block_2_project_BN[0][0]']
block_3_expand (Conv2D) (None, 40, 40, 144) 3456 ['block_2_add[0][0]']
block_3_expand_BN (BatchNormal (None, 40, 40, 144) 576 ['block_3_expand[0][0]']
ization)
block_3_expand_relu (ReLU) (None, 40, 40, 144) 0 ['block_3_expand_BN[0][0]']
block_3_pad (ZeroPadding2D) (None, 41, 41, 144) 0 ['block_3_expand_relu[0][0]']
block_3_depthwise (DepthwiseCo (None, 20, 20, 144) 1296 ['block_3_pad[0][0]']
nv2D)
block_3_depthwise_BN (BatchNor (None, 20, 20, 144) 576 ['block_3_depthwise[0][0]']
malization)
block_3_depthwise_relu (ReLU) (None, 20, 20, 144) 0 ['block_3_depthwise_BN[0][0]']
block_3_project (Conv2D) (None, 20, 20, 32) 4608 ['block_3_depthwise_relu[0][0]']
block_3_project_BN (BatchNorma (None, 20, 20, 32) 128 ['block_3_project[0][0]']
lization)
block_4_expand (Conv2D) (None, 20, 20, 192) 6144 ['block_3_project_BN[0][0]']
block_4_expand_BN (BatchNormal (None, 20, 20, 192) 768 ['block_4_expand[0][0]']
ization)
block_4_expand_relu (ReLU) (None, 20, 20, 192) 0 ['block_4_expand_BN[0][0]']
block_4_depthwise (DepthwiseCo (None, 20, 20, 192) 1728 ['block_4_expand_relu[0][0]']
nv2D)
block_4_depthwise_BN (BatchNor (None, 20, 20, 192) 768 ['block_4_depthwise[0][0]']
malization)
block_4_depthwise_relu (ReLU) (None, 20, 20, 192) 0 ['block_4_depthwise_BN[0][0]']
block_4_project (Conv2D) (None, 20, 20, 32) 6144 ['block_4_depthwise_relu[0][0]']
block_4_project_BN (BatchNorma (None, 20, 20, 32) 128 ['block_4_project[0][0]']
lization)
block_4_add (Add) (None, 20, 20, 32) 0 ['block_3_project_BN[0][0]',
'block_4_project_BN[0][0]']
block_5_expand (Conv2D) (None, 20, 20, 192) 6144 ['block_4_add[0][0]']
block_5_expand_BN (BatchNormal (None, 20, 20, 192) 768 ['block_5_expand[0][0]']
ization)
block_5_expand_relu (ReLU) (None, 20, 20, 192) 0 ['block_5_expand_BN[0][0]']
block_5_depthwise (DepthwiseCo (None, 20, 20, 192) 1728 ['block_5_expand_relu[0][0]']
nv2D)
block_5_depthwise_BN (BatchNor (None, 20, 20, 192) 768 ['block_5_depthwise[0][0]']
malization)
block_5_depthwise_relu (ReLU) (None, 20, 20, 192) 0 ['block_5_depthwise_BN[0][0]']
block_5_project (Conv2D) (None, 20, 20, 32) 6144 ['block_5_depthwise_relu[0][0]']
block_5_project_BN (BatchNorma (None, 20, 20, 32) 128 ['block_5_project[0][0]']
lization)
block_5_add (Add) (None, 20, 20, 32) 0 ['block_4_add[0][0]',
'block_5_project_BN[0][0]']
block_6_expand (Conv2D) (None, 20, 20, 192) 6144 ['block_5_add[0][0]']
block_6_expand_BN (BatchNormal (None, 20, 20, 192) 768 ['block_6_expand[0][0]']
ization)
block_6_expand_relu (ReLU) (None, 20, 20, 192) 0 ['block_6_expand_BN[0][0]']
block_6_pad (ZeroPadding2D) (None, 21, 21, 192) 0 ['block_6_expand_relu[0][0]']
block_6_depthwise (DepthwiseCo (None, 10, 10, 192) 1728 ['block_6_pad[0][0]']
nv2D)
block_6_depthwise_BN (BatchNor (None, 10, 10, 192) 768 ['block_6_depthwise[0][0]']
malization)
block_6_depthwise_relu (ReLU) (None, 10, 10, 192) 0 ['block_6_depthwise_BN[0][0]']
block_6_project (Conv2D) (None, 10, 10, 64) 12288 ['block_6_depthwise_relu[0][0]']
block_6_project_BN (BatchNorma (None, 10, 10, 64) 256 ['block_6_project[0][0]']
lization)
block_7_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_6_project_BN[0][0]']
block_7_expand_BN (BatchNormal (None, 10, 10, 384) 1536 ['block_7_expand[0][0]']
ization)
block_7_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_7_expand_BN[0][0]']
block_7_depthwise (DepthwiseCo (None, 10, 10, 384) 3456 ['block_7_expand_relu[0][0]']
nv2D)
block_7_depthwise_BN (BatchNor (None, 10, 10, 384) 1536 ['block_7_depthwise[0][0]']
malization)
block_7_depthwise_relu (ReLU) (None, 10, 10, 384) 0 ['block_7_depthwise_BN[0][0]']
block_7_project (Conv2D) (None, 10, 10, 64) 24576 ['block_7_depthwise_relu[0][0]']
block_7_project_BN (BatchNorma (None, 10, 10, 64) 256 ['block_7_project[0][0]']
lization)
block_7_add (Add) (None, 10, 10, 64) 0 ['block_6_project_BN[0][0]',
'block_7_project_BN[0][0]']
block_8_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_7_add[0][0]']
block_8_expand_BN (BatchNormal (None, 10, 10, 384) 1536 ['block_8_expand[0][0]']
ization)
block_8_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_8_expand_BN[0][0]']
block_8_depthwise (DepthwiseCo (None, 10, 10, 384) 3456 ['block_8_expand_relu[0][0]']
nv2D)
block_8_depthwise_BN (BatchNor (None, 10, 10, 384) 1536 ['block_8_depthwise[0][0]']
malization)
block_8_depthwise_relu (ReLU) (None, 10, 10, 384) 0 ['block_8_depthwise_BN[0][0]']
block_8_project (Conv2D) (None, 10, 10, 64) 24576 ['block_8_depthwise_relu[0][0]']
block_8_project_BN (BatchNorma (None, 10, 10, 64) 256 ['block_8_project[0][0]']
lization)
block_8_add (Add) (None, 10, 10, 64) 0 ['block_7_add[0][0]',
'block_8_project_BN[0][0]']
block_9_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_8_add[0][0]']
block_9_expand_BN (BatchNormal (None, 10, 10, 384) 1536 ['block_9_expand[0][0]']
ization)
block_9_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_9_expand_BN[0][0]']
block_9_depthwise (DepthwiseCo (None, 10, 10, 384) 3456 ['block_9_expand_relu[0][0]']
nv2D)
block_9_depthwise_BN (BatchNor (None, 10, 10, 384) 1536 ['block_9_depthwise[0][0]']
malization)
block_9_depthwise_relu (ReLU) (None, 10, 10, 384) 0 ['block_9_depthwise_BN[0][0]']
block_9_project (Conv2D) (None, 10, 10, 64) 24576 ['block_9_depthwise_relu[0][0]']
block_9_project_BN (BatchNorma (None, 10, 10, 64) 256 ['block_9_project[0][0]']
lization)
block_9_add (Add) (None, 10, 10, 64) 0 ['block_8_add[0][0]',
'block_9_project_BN[0][0]']
block_10_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_9_add[0][0]']
block_10_expand_BN (BatchNorma (None, 10, 10, 384) 1536 ['block_10_expand[0][0]']
lization)
block_10_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_10_expand_BN[0][0]']
block_10_depthwise (DepthwiseC (None, 10, 10, 384) 3456 ['block_10_expand_relu[0][0]']
onv2D)
block_10_depthwise_BN (BatchNo (None, 10, 10, 384) 1536 ['block_10_depthwise[0][0]']
rmalization)
block_10_depthwise_relu (ReLU) (None, 10, 10, 384) 0 ['block_10_depthwise_BN[0][0]']
block_10_project (Conv2D) (None, 10, 10, 96) 36864 ['block_10_depthwise_relu[0][0]']
block_10_project_BN (BatchNorm (None, 10, 10, 96) 384 ['block_10_project[0][0]']
alization)
block_11_expand (Conv2D) (None, 10, 10, 576) 55296 ['block_10_project_BN[0][0]']
block_11_expand_BN (BatchNorma (None, 10, 10, 576) 2304 ['block_11_expand[0][0]']
lization)
block_11_expand_relu (ReLU) (None, 10, 10, 576) 0 ['block_11_expand_BN[0][0]']
block_11_depthwise (DepthwiseC (None, 10, 10, 576) 5184 ['block_11_expand_relu[0][0]']
onv2D)
block_11_depthwise_BN (BatchNo (None, 10, 10, 576) 2304 ['block_11_depthwise[0][0]']
rmalization)
block_11_depthwise_relu (ReLU) (None, 10, 10, 576) 0 ['block_11_depthwise_BN[0][0]']
block_11_project (Conv2D) (None, 10, 10, 96) 55296 ['block_11_depthwise_relu[0][0]']
block_11_project_BN (BatchNorm (None, 10, 10, 96) 384 ['block_11_project[0][0]']
alization)
block_11_add (Add) (None, 10, 10, 96) 0 ['block_10_project_BN[0][0]',
'block_11_project_BN[0][0]']
block_12_expand (Conv2D) (None, 10, 10, 576) 55296 ['block_11_add[0][0]']
block_12_expand_BN (BatchNorma (None, 10, 10, 576) 2304 ['block_12_expand[0][0]']
lization)
block_12_expand_relu (ReLU) (None, 10, 10, 576) 0 ['block_12_expand_BN[0][0]']
block_12_depthwise (DepthwiseC (None, 10, 10, 576) 5184 ['block_12_expand_relu[0][0]']
onv2D)
block_12_depthwise_BN (BatchNo (None, 10, 10, 576) 2304 ['block_12_depthwise[0][0]']
rmalization)
block_12_depthwise_relu (ReLU) (None, 10, 10, 576) 0 ['block_12_depthwise_BN[0][0]']
block_12_project (Conv2D) (None, 10, 10, 96) 55296 ['block_12_depthwise_relu[0][0]']
block_12_project_BN (BatchNorm (None, 10, 10, 96) 384 ['block_12_project[0][0]']
alization)
block_12_add (Add) (None, 10, 10, 96) 0 ['block_11_add[0][0]',
'block_12_project_BN[0][0]']
block_13_expand (Conv2D) (None, 10, 10, 576) 55296 ['block_12_add[0][0]']
block_13_expand_BN (BatchNorma (None, 10, 10, 576) 2304 ['block_13_expand[0][0]']
lization)
block_13_expand_relu (ReLU) (None, 10, 10, 576) 0 ['block_13_expand_BN[0][0]']
block_13_pad (ZeroPadding2D) (None, 11, 11, 576) 0 ['block_13_expand_relu[0][0]']
block_13_depthwise (DepthwiseC (None, 5, 5, 576) 5184 ['block_13_pad[0][0]']
onv2D)
block_13_depthwise_BN (BatchNo (None, 5, 5, 576) 2304 ['block_13_depthwise[0][0]']
rmalization)
block_13_depthwise_relu (ReLU) (None, 5, 5, 576) 0 ['block_13_depthwise_BN[0][0]']
block_13_project (Conv2D) (None, 5, 5, 160) 92160 ['block_13_depthwise_relu[0][0]']
block_13_project_BN (BatchNorm (None, 5, 5, 160) 640 ['block_13_project[0][0]']
alization)
block_14_expand (Conv2D) (None, 5, 5, 960) 153600 ['block_13_project_BN[0][0]']
block_14_expand_BN (BatchNorma (None, 5, 5, 960) 3840 ['block_14_expand[0][0]']
lization)
block_14_expand_relu (ReLU) (None, 5, 5, 960) 0 ['block_14_expand_BN[0][0]']
block_14_depthwise (DepthwiseC (None, 5, 5, 960) 8640 ['block_14_expand_relu[0][0]']
onv2D)
block_14_depthwise_BN (BatchNo (None, 5, 5, 960) 3840 ['block_14_depthwise[0][0]']
rmalization)
block_14_depthwise_relu (ReLU) (None, 5, 5, 960) 0 ['block_14_depthwise_BN[0][0]']
block_14_project (Conv2D) (None, 5, 5, 160) 153600 ['block_14_depthwise_relu[0][0]']
block_14_project_BN (BatchNorm (None, 5, 5, 160) 640 ['block_14_project[0][0]']
alization)
block_14_add (Add) (None, 5, 5, 160) 0 ['block_13_project_BN[0][0]',
'block_14_project_BN[0][0]']
block_15_expand (Conv2D) (None, 5, 5, 960) 153600 ['block_14_add[0][0]']
block_15_expand_BN (BatchNorma (None, 5, 5, 960) 3840 ['block_15_expand[0][0]']
lization)
block_15_expand_relu (ReLU) (None, 5, 5, 960) 0 ['block_15_expand_BN[0][0]']
block_15_depthwise (DepthwiseC (None, 5, 5, 960) 8640 ['block_15_expand_relu[0][0]']
onv2D)
block_15_depthwise_BN (BatchNo (None, 5, 5, 960) 3840 ['block_15_depthwise[0][0]']
rmalization)
block_15_depthwise_relu (ReLU) (None, 5, 5, 960) 0 ['block_15_depthwise_BN[0][0]']
block_15_project (Conv2D) (None, 5, 5, 160) 153600 ['block_15_depthwise_relu[0][0]']
block_15_project_BN (BatchNorm (None, 5, 5, 160) 640 ['block_15_project[0][0]']
alization)
block_15_add (Add) (None, 5, 5, 160) 0 ['block_14_add[0][0]',
'block_15_project_BN[0][0]']
block_16_expand (Conv2D) (None, 5, 5, 960) 153600 ['block_15_add[0][0]']
block_16_expand_BN (BatchNorma (None, 5, 5, 960) 3840 ['block_16_expand[0][0]']
lization)
block_16_expand_relu (ReLU) (None, 5, 5, 960) 0 ['block_16_expand_BN[0][0]']
block_16_depthwise (DepthwiseC (None, 5, 5, 960) 8640 ['block_16_expand_relu[0][0]']
onv2D)
block_16_depthwise_BN (BatchNo (None, 5, 5, 960) 3840 ['block_16_depthwise[0][0]']
rmalization)
block_16_depthwise_relu (ReLU) (None, 5, 5, 960) 0 ['block_16_depthwise_BN[0][0]']
block_16_project (Conv2D) (None, 5, 5, 320) 307200 ['block_16_depthwise_relu[0][0]']
block_16_project_BN (BatchNorm (None, 5, 5, 320) 1280 ['block_16_project[0][0]']
alization)
Conv_1 (Conv2D) (None, 5, 5, 1280) 409600 ['block_16_project_BN[0][0]']
Conv_1_bn (BatchNormalization) (None, 5, 5, 1280) 5120 ['Conv_1[0][0]']
out_relu (ReLU) (None, 5, 5, 1280) 0 ['Conv_1_bn[0][0]']
==================================================================================================
Total params: 2,257,984
Trainable params: 0
Non-trainable params: 2,257,984
__________________________________________________________________________________________________
یک سر طبقه بندی اضافه کنید
برای ایجاد پیشبینیها از بلوک ویژگیها، با استفاده از یک لایه 5x5 ، برای تبدیل ویژگیها به یک بردار 1280 عنصری در هر تصویر، tf.keras.layers.GlobalAveragePooling2D را در مکانهای فضایی 5×5 فضایی انجام دهید.
global_average_layer = tf.keras.layers.GlobalAveragePooling2D()
feature_batch_average = global_average_layer(feature_batch)
print(feature_batch_average.shape)
(32, 1280)
یک لایه tf.keras.layers.Dense را اعمال کنید تا این ویژگی ها را به یک پیش بینی در هر تصویر تبدیل کنید. در اینجا به یک تابع فعال سازی نیاز ندارید زیرا این پیش بینی به عنوان یک logit یا یک مقدار پیش بینی خام در نظر گرفته می شود. اعداد مثبت کلاس 1 را پیش بینی می کنند و اعداد منفی کلاس 0 را پیش بینی می کنند.
prediction_layer = tf.keras.layers.Dense(1)
prediction_batch = prediction_layer(feature_batch_average)
print(prediction_batch.shape)
(32, 1)
با استفاده از Keras Functional API ، یک مدل را با زنجیرهای کردن لایههای تقویت داده، مقیاسگذاری مجدد، base_model و استخراج ویژگیها با هم بسازید. همانطور که قبلا ذکر شد، از training=False استفاده کنید زیرا مدل ما حاوی یک لایه BatchNormalization است.
inputs = tf.keras.Input(shape=(160, 160, 3))
x = data_augmentation(inputs)
x = preprocess_input(x)
x = base_model(x, training=False)
x = global_average_layer(x)
x = tf.keras.layers.Dropout(0.2)(x)
outputs = prediction_layer(x)
model = tf.keras.Model(inputs, outputs)
مدل را کامپایل کنید
قبل از آموزش مدل را کامپایل کنید. از آنجایی که دو کلاس وجود دارد، از ضرر tf.keras.losses.BinaryCrossentropy با from_logits=True استفاده کنید زیرا مدل یک خروجی خطی ارائه می دهد.
base_learning_rate = 0.0001
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=base_learning_rate),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 160, 160, 3)] 0
sequential (Sequential) (None, 160, 160, 3) 0
tf.math.truediv (TFOpLambda (None, 160, 160, 3) 0
)
tf.math.subtract (TFOpLambd (None, 160, 160, 3) 0
a)
mobilenetv2_1.00_160 (Funct (None, 5, 5, 1280) 2257984
ional)
global_average_pooling2d (G (None, 1280) 0
lobalAveragePooling2D)
dropout (Dropout) (None, 1280) 0
dense (Dense) (None, 1) 1281
=================================================================
Total params: 2,259,265
Trainable params: 1,281
Non-trainable params: 2,257,984
_________________________________________________________________
2.5 میلیون پارامتر در MobileNet ثابت هستند، اما 1.2 هزار پارامتر قابل آموزش در لایه متراکم وجود دارد. این ها بین دو شیء tf.Variable تقسیم می شوند، وزن ها و بایاس ها.
len(model.trainable_variables)
2
مدل را آموزش دهید
پس از آموزش به مدت 10 دوره، باید دقت 94% را در مجموعه اعتبارسنجی مشاهده کنید.
initial_epochs = 10
loss0, accuracy0 = model.evaluate(validation_dataset)
26/26 [==============================] - 2s 16ms/step - loss: 0.7428 - accuracy: 0.5186
print("initial loss: {:.2f}".format(loss0))
print("initial accuracy: {:.2f}".format(accuracy0))
initial loss: 0.74 initial accuracy: 0.52
history = model.fit(train_dataset,
epochs=initial_epochs,
validation_data=validation_dataset)
Epoch 1/10 63/63 [==============================] - 4s 23ms/step - loss: 0.6804 - accuracy: 0.5680 - val_loss: 0.4981 - val_accuracy: 0.7054 Epoch 2/10 63/63 [==============================] - 1s 22ms/step - loss: 0.5044 - accuracy: 0.7170 - val_loss: 0.3598 - val_accuracy: 0.8144 Epoch 3/10 63/63 [==============================] - 1s 21ms/step - loss: 0.4109 - accuracy: 0.7845 - val_loss: 0.2810 - val_accuracy: 0.8861 Epoch 4/10 63/63 [==============================] - 1s 21ms/step - loss: 0.3285 - accuracy: 0.8445 - val_loss: 0.2256 - val_accuracy: 0.9208 Epoch 5/10 63/63 [==============================] - 1s 21ms/step - loss: 0.3108 - accuracy: 0.8555 - val_loss: 0.1986 - val_accuracy: 0.9307 Epoch 6/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2659 - accuracy: 0.8855 - val_loss: 0.1703 - val_accuracy: 0.9418 Epoch 7/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2459 - accuracy: 0.8935 - val_loss: 0.1495 - val_accuracy: 0.9517 Epoch 8/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2315 - accuracy: 0.8950 - val_loss: 0.1454 - val_accuracy: 0.9542 Epoch 9/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2204 - accuracy: 0.9030 - val_loss: 0.1326 - val_accuracy: 0.9592 Epoch 10/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2180 - accuracy: 0.9115 - val_loss: 0.1215 - val_accuracy: 0.9604
منحنی های یادگیری
بیایید نگاهی به منحنیهای یادگیری دقت/از دست دادن آموزش و اعتبارسنجی در هنگام استفاده از مدل پایه MobileNetV2 به عنوان استخراجکننده ویژگیهای ثابت بیندازیم.
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.ylim([min(plt.ylim()),1])
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.ylim([0,1.0])
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
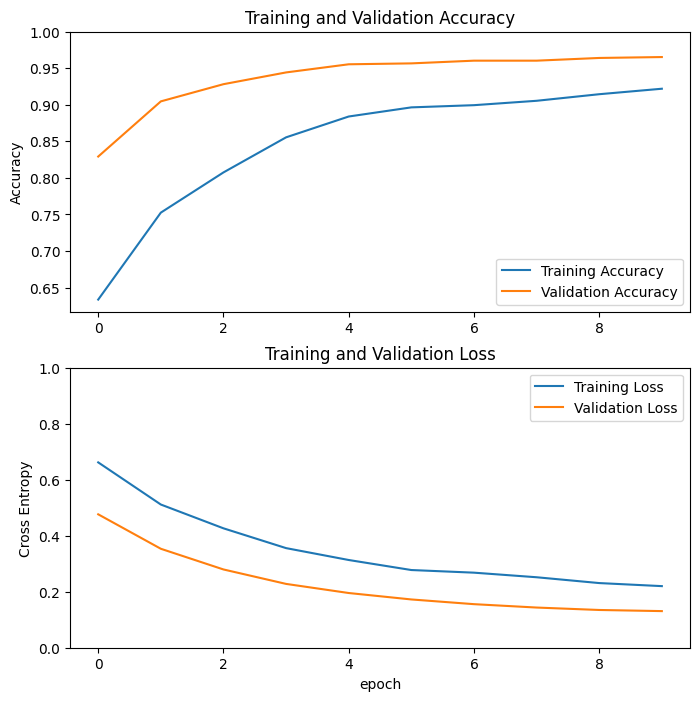
تا حدی به این دلیل است که معیارهای آموزشی میانگین را برای یک دوره گزارش میکنند، در حالی که معیارهای اعتبارسنجی بعد از دوره ارزیابی میشوند، بنابراین معیارهای اعتبارسنجی مدلی را مشاهده میکنند که کمی طولانیتر آموزش دیده است.
تنظیم دقیق
در آزمایش استخراج ویژگی، شما فقط چند لایه را در بالای یک مدل پایه MobileNetV2 آموزش میدادید. اوزان شبکه از پیش آموزش دیده در طول تمرین به روز نشد .
یکی از راههای افزایش عملکرد بیشتر، آموزش (یا "تنظیم دقیق") وزنههای لایههای بالایی مدل از پیش آموزشدیده در کنار آموزش طبقهبندیکنندهای است که اضافه کردهاید. فرآیند آموزش وزن ها را مجبور می کند که از نقشه ویژگی های عمومی به ویژگی های مرتبط با مجموعه داده تنظیم شوند.
همچنین، شما باید سعی کنید تعداد کمی از لایه های بالایی را به جای کل مدل MobileNet تنظیم کنید. در اکثر شبکه های کانولوشن، هر چه یک لایه بالاتر باشد، تخصصی تر است. چند لایه اول ویژگی های بسیار ساده و عمومی را یاد می گیرند که تقریباً به همه انواع تصاویر تعمیم می یابد. هرچه بالاتر می روید، ویژگی ها به طور فزاینده ای به مجموعه داده ای که مدل بر روی آن آموزش داده شده است، خاص تر می شود. هدف از تنظیم دقیق، تطبیق این ویژگی های تخصصی برای کار با مجموعه داده جدید است، به جای بازنویسی یادگیری عمومی.
لایه های بالایی مدل را از حالت یخ خارج کنید
تنها کاری که باید انجام دهید این است که base_model را از حالت انجماد خارج کنید و لایه های پایینی را غیرقابل آموزش تنظیم کنید. سپس، باید مدل را دوباره کامپایل کنید (برای اعمال این تغییرات لازم است)، و آموزش را از سر بگیرید.
base_model.trainable = True
# Let's take a look to see how many layers are in the base model
print("Number of layers in the base model: ", len(base_model.layers))
# Fine-tune from this layer onwards
fine_tune_at = 100
# Freeze all the layers before the `fine_tune_at` layer
for layer in base_model.layers[:fine_tune_at]:
layer.trainable = False
Number of layers in the base model: 154
مدل را کامپایل کنید
از آنجایی که شما در حال تمرین یک مدل بسیار بزرگتر هستید و می خواهید وزنه های از پیش تمرین شده را دوباره تنظیم کنید، مهم است که در این مرحله از نرخ یادگیری پایین تری استفاده کنید. در غیر این صورت، مدل شما می تواند خیلی سریع بیش از حد قرار بگیرد.
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer = tf.keras.optimizers.RMSprop(learning_rate=base_learning_rate/10),
metrics=['accuracy'])
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 160, 160, 3)] 0
sequential (Sequential) (None, 160, 160, 3) 0
tf.math.truediv (TFOpLambda (None, 160, 160, 3) 0
)
tf.math.subtract (TFOpLambd (None, 160, 160, 3) 0
a)
mobilenetv2_1.00_160 (Funct (None, 5, 5, 1280) 2257984
ional)
global_average_pooling2d (G (None, 1280) 0
lobalAveragePooling2D)
dropout (Dropout) (None, 1280) 0
dense (Dense) (None, 1) 1281
=================================================================
Total params: 2,259,265
Trainable params: 1,862,721
Non-trainable params: 396,544
_________________________________________________________________
len(model.trainable_variables)
56
به آموزش مدل ادامه دهید
اگر زودتر برای همگرایی آموزش دیده اید، این مرحله دقت شما را چند درصد افزایش می دهد.
fine_tune_epochs = 10
total_epochs = initial_epochs + fine_tune_epochs
history_fine = model.fit(train_dataset,
epochs=total_epochs,
initial_epoch=history.epoch[-1],
validation_data=validation_dataset)
Epoch 10/20 63/63 [==============================] - 7s 40ms/step - loss: 0.1545 - accuracy: 0.9335 - val_loss: 0.0531 - val_accuracy: 0.9864 Epoch 11/20 63/63 [==============================] - 2s 28ms/step - loss: 0.1161 - accuracy: 0.9540 - val_loss: 0.0500 - val_accuracy: 0.9814 Epoch 12/20 63/63 [==============================] - 2s 28ms/step - loss: 0.1125 - accuracy: 0.9525 - val_loss: 0.0379 - val_accuracy: 0.9876 Epoch 13/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0891 - accuracy: 0.9625 - val_loss: 0.0472 - val_accuracy: 0.9889 Epoch 14/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0844 - accuracy: 0.9680 - val_loss: 0.0478 - val_accuracy: 0.9889 Epoch 15/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0857 - accuracy: 0.9645 - val_loss: 0.0354 - val_accuracy: 0.9839 Epoch 16/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0785 - accuracy: 0.9690 - val_loss: 0.0449 - val_accuracy: 0.9864 Epoch 17/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0669 - accuracy: 0.9740 - val_loss: 0.0375 - val_accuracy: 0.9839 Epoch 18/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0701 - accuracy: 0.9695 - val_loss: 0.0324 - val_accuracy: 0.9864 Epoch 19/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0636 - accuracy: 0.9760 - val_loss: 0.0465 - val_accuracy: 0.9790 Epoch 20/20 63/63 [==============================] - 2s 29ms/step - loss: 0.0585 - accuracy: 0.9765 - val_loss: 0.0392 - val_accuracy: 0.9851
بیایید به منحنیهای یادگیری دقت/از دست دادن آموزش و اعتبارسنجی هنگام تنظیم دقیق چند لایه آخر مدل پایه MobileNetV2 و آموزش طبقهبندی کننده در بالای آن نگاهی بیندازیم. ضرر اعتبار سنجی بسیار بیشتر از ضرر تمرین است، بنابراین ممکن است مقداری بیش از حد برازش داشته باشید.
همچنین ممکن است از آنجایی که مجموعه آموزشی جدید نسبتا کوچک و شبیه به مجموعه داده های اصلی MobileNetV2 است، مقداری بیش از حد برازش داشته باشید.
پس از تنظیم دقیق، دقت مدل تقریباً به 98٪ در مجموعه اعتبار سنجی می رسد.
acc += history_fine.history['accuracy']
val_acc += history_fine.history['val_accuracy']
loss += history_fine.history['loss']
val_loss += history_fine.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.ylim([0.8, 1])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.ylim([0, 1.0])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
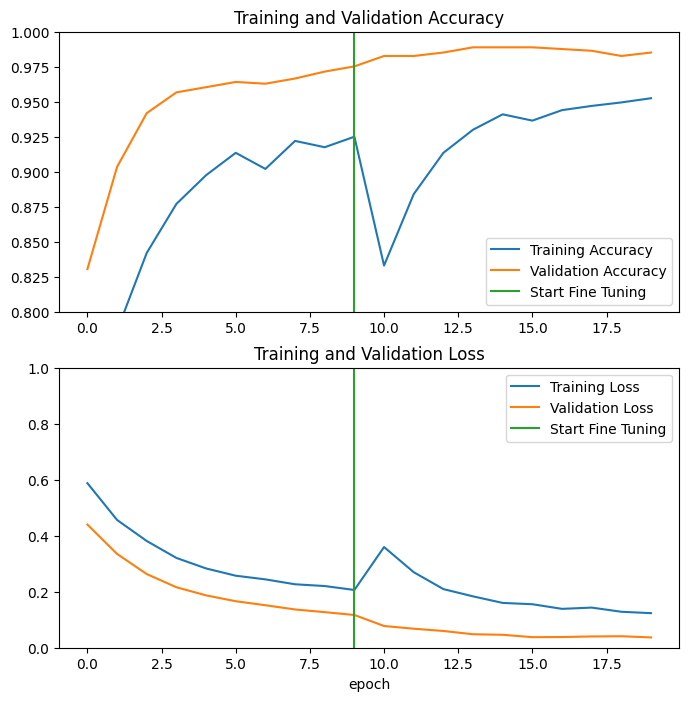
ارزیابی و پیش بینی
در نهایت می توانید با استفاده از مجموعه تست عملکرد مدل را روی داده های جدید تأیید کنید.
loss, accuracy = model.evaluate(test_dataset)
print('Test accuracy :', accuracy)
6/6 [==============================] - 0s 13ms/step - loss: 0.0281 - accuracy: 0.9948 Test accuracy : 0.9947916865348816
و اکنون همه آماده اید که از این مدل برای پیش بینی اینکه حیوان خانگی شما گربه یا سگ است استفاده کنید.
# Retrieve a batch of images from the test set
image_batch, label_batch = test_dataset.as_numpy_iterator().next()
predictions = model.predict_on_batch(image_batch).flatten()
# Apply a sigmoid since our model returns logits
predictions = tf.nn.sigmoid(predictions)
predictions = tf.where(predictions < 0.5, 0, 1)
print('Predictions:\n', predictions.numpy())
print('Labels:\n', label_batch)
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image_batch[i].astype("uint8"))
plt.title(class_names[predictions[i]])
plt.axis("off")
Predictions: [0 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 0 0 0 1 0 1 0 0 1 1 1 0 0 0 1 0] Labels: [0 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 0 0 0 1 0 1 0 0 1 1 1 0 0 0 1 0]

خلاصه
استفاده از یک مدل از پیش آموزشدیده برای استخراج ویژگی : هنگام کار با یک مجموعه داده کوچک، استفاده از ویژگیهای آموختهشده توسط یک مدل آموزشدیده بر روی یک مجموعه داده بزرگتر در همان حوزه، یک روش معمول است. این کار با نمونه سازی مدل از پیش آموزش دیده و افزودن یک طبقه بندی کننده کاملا متصل در بالا انجام می شود. مدل از پیش آموزش دیده "یخ زده" است و فقط وزن های طبقه بندی کننده در طول تمرین به روز می شوند. در این مورد، پایه کانولوشن تمام ویژگیهای مرتبط با هر تصویر را استخراج کرد و شما فقط طبقهبندیکنندهای را آموزش دادید که کلاس تصویر را با توجه به مجموعه ویژگیهای استخراجشده تعیین میکند.
تنظیم دقیق یک مدل از پیش آموزشدیده : برای بهبود بیشتر عملکرد، ممکن است بخواهید لایههای سطح بالای مدلهای از پیش آموزشدیده را از طریق تنظیم دقیق به مجموعه داده جدید تغییر دهید. در این مورد، وزنهای خود را به گونهای تنظیم کردهاید که مدل شما ویژگیهای سطح بالا مخصوص مجموعه داده را یاد بگیرد. این تکنیک معمولاً زمانی توصیه میشود که مجموعه داده آموزشی بزرگ و بسیار شبیه به مجموعه داده اصلی است که مدل از پیش آموزشدیده بر روی آن آموزش داده شده است.
برای کسب اطلاعات بیشتر، به راهنمای یادگیری انتقال مراجعه کنید.
# MIT License
#
# Copyright (c) 2017 François Chollet # IGNORE_COPYRIGHT: cleared by OSS licensing
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.