
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
В этом руководстве вы узнаете, как классифицировать изображения кошек и собак с помощью трансферного обучения из предварительно обученной сети.
Предварительно обученная модель — это сохраненная сеть, которая ранее была обучена на большом наборе данных, как правило, на крупномасштабной задаче классификации изображений. Вы либо используете предварительно обученную модель как есть, либо используете трансферное обучение, чтобы настроить эту модель для данной задачи.
Интуиция, лежащая в основе трансферного обучения для классификации изображений, заключается в том, что если модель обучается на большом и достаточно общем наборе данных, эта модель будет эффективно служить общей моделью визуального мира. Затем вы можете воспользоваться этими изученными картами объектов, не начав с нуля, обучая большую модель на большом наборе данных.
В этой записной книжке вы попробуете два способа настройки предварительно обученной модели:
Извлечение признаков: используйте представления, изученные предыдущей сетью, для извлечения значимых признаков из новых образцов. Вы просто добавляете новый классификатор, который будет обучаться с нуля, поверх предварительно обученной модели, чтобы вы могли повторно использовать карты объектов, изученные ранее, для набора данных.
Вам не нужно (повторно) обучать всю модель. Базовая сверточная сеть уже содержит функции, которые обычно полезны для классификации изображений. Однако окончательная классификационная часть предварительно обученной модели специфична для исходной задачи классификации, а затем специфична для набора классов, на которых была обучена модель.
Тонкая настройка: разморозьте несколько верхних слоев замороженной базовой модели и совместно обучите как недавно добавленные слои классификатора, так и последние слои базовой модели. Это позволяет нам «точно настроить» представления функций более высокого порядка в базовой модели, чтобы сделать их более подходящими для конкретной задачи.
Вы будете следовать общему рабочему процессу машинного обучения.
- Изучите и поймите данные
- Создайте конвейер ввода, в данном случае с помощью Keras ImageDataGenerator.
- Составьте модель
- Нагрузить предварительно обученную базовую модель (и предварительно обученные веса)
- Сложите классификационные слои сверху
- Обучите модель
- Оценить модель
import matplotlib.pyplot as plt
import numpy as np
import os
import tensorflow as tf
Предварительная обработка данных
Загрузка данных
В этом уроке вы будете использовать набор данных, содержащий несколько тысяч изображений кошек и собак. Загрузите и распакуйте zip-файл, содержащий изображения, затем создайте tf.data.Dataset для обучения и проверки с помощью утилиты tf.keras.utils.image_dataset_from_directory . Вы можете узнать больше о загрузке изображений в этом руководстве .
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
path_to_zip = tf.keras.utils.get_file('cats_and_dogs.zip', origin=_URL, extract=True)
PATH = os.path.join(os.path.dirname(path_to_zip), 'cats_and_dogs_filtered')
train_dir = os.path.join(PATH, 'train')
validation_dir = os.path.join(PATH, 'validation')
BATCH_SIZE = 32
IMG_SIZE = (160, 160)
train_dataset = tf.keras.utils.image_dataset_from_directory(train_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
Downloading data from https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip 68608000/68606236 [==============================] - 1s 0us/step 68616192/68606236 [==============================] - 1s 0us/step Found 2000 files belonging to 2 classes.
validation_dataset = tf.keras.utils.image_dataset_from_directory(validation_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
Found 1000 files belonging to 2 classes.
Покажите первые девять изображений и меток из обучающего набора:
class_names = train_dataset.class_names
plt.figure(figsize=(10, 10))
for images, labels in train_dataset.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")

Поскольку исходный набор данных не содержит тестового набора, вы его создадите. Для этого определите, сколько пакетов данных доступно в проверочном наборе, используя tf.data.experimental.cardinality , а затем переместите 20% из них в тестовый набор.
val_batches = tf.data.experimental.cardinality(validation_dataset)
test_dataset = validation_dataset.take(val_batches // 5)
validation_dataset = validation_dataset.skip(val_batches // 5)
print('Number of validation batches: %d' % tf.data.experimental.cardinality(validation_dataset))
print('Number of test batches: %d' % tf.data.experimental.cardinality(test_dataset))
Number of validation batches: 26 Number of test batches: 6
Настройте набор данных для производительности
Используйте буферизованную предварительную выборку для загрузки изображений с диска без блокировки ввода-вывода. Чтобы узнать больше об этом методе, см. руководство по производительности данных .
AUTOTUNE = tf.data.AUTOTUNE
train_dataset = train_dataset.prefetch(buffer_size=AUTOTUNE)
validation_dataset = validation_dataset.prefetch(buffer_size=AUTOTUNE)
test_dataset = test_dataset.prefetch(buffer_size=AUTOTUNE)
Используйте увеличение данных
Если у вас нет большого набора данных изображений, хорошей практикой является искусственное введение разнообразия выборок путем применения к обучающим изображениям случайных, но реалистичных преобразований, таких как вращение и горизонтальное отражение. Это помогает подвергнуть модель воздействию различных аспектов обучающих данных и уменьшить переоснащение . Вы можете узнать больше об увеличении данных в этом руководстве .
data_augmentation = tf.keras.Sequential([
tf.keras.layers.RandomFlip('horizontal'),
tf.keras.layers.RandomRotation(0.2),
])
Давайте повторно применим эти слои к одному и тому же изображению и посмотрим на результат.
for image, _ in train_dataset.take(1):
plt.figure(figsize=(10, 10))
first_image = image[0]
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
augmented_image = data_augmentation(tf.expand_dims(first_image, 0))
plt.imshow(augmented_image[0] / 255)
plt.axis('off')

Изменение масштаба значений пикселей
Через мгновение вы загрузите tf.keras.applications.MobileNetV2 для использования в качестве базовой модели. Эта модель ожидает значения пикселей в [-1, 1] , но на данный момент значения пикселей в ваших изображениях находятся в [0, 255] . Чтобы масштабировать их, используйте метод предварительной обработки, включенный в модель.
preprocess_input = tf.keras.applications.mobilenet_v2.preprocess_input
rescale = tf.keras.layers.Rescaling(1./127.5, offset=-1)
Создайте базовую модель из предварительно обученных консетей
Вы создадите базовую модель на основе модели MobileNet V2 , разработанной в Google. Это предварительно обучено на наборе данных ImageNet, большом наборе данных, состоящем из 1,4 млн изображений и 1000 классов. ImageNet — это набор данных для обучения исследованию с широким спектром категорий, таких как jackfruit и syringe . Эта база знаний поможет нам классифицировать кошек и собак из нашего конкретного набора данных.
Во-первых, вам нужно выбрать, какой уровень MobileNet V2 вы будете использовать для извлечения признаков. Самый последний слой классификации («сверху», поскольку большинство диаграмм моделей машинного обучения идут снизу вверх) не очень полезен. Вместо этого вы будете следовать общепринятой практике, чтобы полагаться на самый последний слой перед операцией выравнивания. Этот слой называется «слоем узкого места». Функции слоя узкого места сохраняют большую общность по сравнению с конечным/верхним слоем.
Во-первых, создайте экземпляр модели MobileNet V2 с предварительно загруженными весами, обученными в ImageNet. Указав аргумент include_top=False , вы загружаете сеть, которая не включает слои классификации вверху, что идеально подходит для извлечения признаков.
# Create the base model from the pre-trained model MobileNet V2
IMG_SHAPE = IMG_SIZE + (3,)
base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_160_no_top.h5 9412608/9406464 [==============================] - 0s 0us/step 9420800/9406464 [==============================] - 0s 0us/step
Этот экстрактор функций преобразует каждое изображение 160x160x3 в блок функций 5x5x1280 . Давайте посмотрим, что он делает с примером пакета изображений:
image_batch, label_batch = next(iter(train_dataset))
feature_batch = base_model(image_batch)
print(feature_batch.shape)
(32, 5, 5, 1280)
Извлечение признаков
На этом шаге вы заморозите базу свертки, созданную на предыдущем шаге, и будете использовать ее в качестве экстрактора признаков. Кроме того, вы добавляете классификатор поверх него и обучаете классификатор верхнего уровня.
Заморозить сверточную базу
Важно заморозить базу свертки перед компиляцией и обучением модели. Замораживание (путем установки layer.trainable = False) предотвращает обновление весов в данном слое во время обучения. MobileNet V2 имеет много слоев, поэтому установка флага trainable всей модели в значение False заморозит их все.
base_model.trainable = False
Важное примечание о слоях BatchNormalization
Многие модели содержат слои tf.keras.layers.BatchNormalization . Этот слой является особым случаем, и в контексте тонкой настройки следует соблюдать меры предосторожности, как показано далее в этом руководстве.
Когда вы устанавливаете layer.trainable = False , слой BatchNormalization будет работать в режиме вывода и не будет обновлять статистику среднего значения и дисперсии.
Когда вы размораживаете модель, содержащую слои BatchNormalization, для тонкой настройки, вы должны оставить слои BatchNormalization в режиме вывода, передав training = False при вызове базовой модели. В противном случае обновления, примененные к необучаемым весам, разрушат то, чему научилась модель.
Дополнительные сведения см. в учебном руководстве по переносу.
# Let's take a look at the base model architecture
base_model.summary()
Model: "mobilenetv2_1.00_160"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 160, 160, 3 0 []
)]
Conv1 (Conv2D) (None, 80, 80, 32) 864 ['input_1[0][0]']
bn_Conv1 (BatchNormalization) (None, 80, 80, 32) 128 ['Conv1[0][0]']
Conv1_relu (ReLU) (None, 80, 80, 32) 0 ['bn_Conv1[0][0]']
expanded_conv_depthwise (Depth (None, 80, 80, 32) 288 ['Conv1_relu[0][0]']
wiseConv2D)
expanded_conv_depthwise_BN (Ba (None, 80, 80, 32) 128 ['expanded_conv_depthwise[0][0]']
tchNormalization)
expanded_conv_depthwise_relu ( (None, 80, 80, 32) 0 ['expanded_conv_depthwise_BN[0][0
ReLU) ]']
expanded_conv_project (Conv2D) (None, 80, 80, 16) 512 ['expanded_conv_depthwise_relu[0]
[0]']
expanded_conv_project_BN (Batc (None, 80, 80, 16) 64 ['expanded_conv_project[0][0]']
hNormalization)
block_1_expand (Conv2D) (None, 80, 80, 96) 1536 ['expanded_conv_project_BN[0][0]'
]
block_1_expand_BN (BatchNormal (None, 80, 80, 96) 384 ['block_1_expand[0][0]']
ization)
block_1_expand_relu (ReLU) (None, 80, 80, 96) 0 ['block_1_expand_BN[0][0]']
block_1_pad (ZeroPadding2D) (None, 81, 81, 96) 0 ['block_1_expand_relu[0][0]']
block_1_depthwise (DepthwiseCo (None, 40, 40, 96) 864 ['block_1_pad[0][0]']
nv2D)
block_1_depthwise_BN (BatchNor (None, 40, 40, 96) 384 ['block_1_depthwise[0][0]']
malization)
block_1_depthwise_relu (ReLU) (None, 40, 40, 96) 0 ['block_1_depthwise_BN[0][0]']
block_1_project (Conv2D) (None, 40, 40, 24) 2304 ['block_1_depthwise_relu[0][0]']
block_1_project_BN (BatchNorma (None, 40, 40, 24) 96 ['block_1_project[0][0]']
lization)
block_2_expand (Conv2D) (None, 40, 40, 144) 3456 ['block_1_project_BN[0][0]']
block_2_expand_BN (BatchNormal (None, 40, 40, 144) 576 ['block_2_expand[0][0]']
ization)
block_2_expand_relu (ReLU) (None, 40, 40, 144) 0 ['block_2_expand_BN[0][0]']
block_2_depthwise (DepthwiseCo (None, 40, 40, 144) 1296 ['block_2_expand_relu[0][0]']
nv2D)
block_2_depthwise_BN (BatchNor (None, 40, 40, 144) 576 ['block_2_depthwise[0][0]']
malization)
block_2_depthwise_relu (ReLU) (None, 40, 40, 144) 0 ['block_2_depthwise_BN[0][0]']
block_2_project (Conv2D) (None, 40, 40, 24) 3456 ['block_2_depthwise_relu[0][0]']
block_2_project_BN (BatchNorma (None, 40, 40, 24) 96 ['block_2_project[0][0]']
lization)
block_2_add (Add) (None, 40, 40, 24) 0 ['block_1_project_BN[0][0]',
'block_2_project_BN[0][0]']
block_3_expand (Conv2D) (None, 40, 40, 144) 3456 ['block_2_add[0][0]']
block_3_expand_BN (BatchNormal (None, 40, 40, 144) 576 ['block_3_expand[0][0]']
ization)
block_3_expand_relu (ReLU) (None, 40, 40, 144) 0 ['block_3_expand_BN[0][0]']
block_3_pad (ZeroPadding2D) (None, 41, 41, 144) 0 ['block_3_expand_relu[0][0]']
block_3_depthwise (DepthwiseCo (None, 20, 20, 144) 1296 ['block_3_pad[0][0]']
nv2D)
block_3_depthwise_BN (BatchNor (None, 20, 20, 144) 576 ['block_3_depthwise[0][0]']
malization)
block_3_depthwise_relu (ReLU) (None, 20, 20, 144) 0 ['block_3_depthwise_BN[0][0]']
block_3_project (Conv2D) (None, 20, 20, 32) 4608 ['block_3_depthwise_relu[0][0]']
block_3_project_BN (BatchNorma (None, 20, 20, 32) 128 ['block_3_project[0][0]']
lization)
block_4_expand (Conv2D) (None, 20, 20, 192) 6144 ['block_3_project_BN[0][0]']
block_4_expand_BN (BatchNormal (None, 20, 20, 192) 768 ['block_4_expand[0][0]']
ization)
block_4_expand_relu (ReLU) (None, 20, 20, 192) 0 ['block_4_expand_BN[0][0]']
block_4_depthwise (DepthwiseCo (None, 20, 20, 192) 1728 ['block_4_expand_relu[0][0]']
nv2D)
block_4_depthwise_BN (BatchNor (None, 20, 20, 192) 768 ['block_4_depthwise[0][0]']
malization)
block_4_depthwise_relu (ReLU) (None, 20, 20, 192) 0 ['block_4_depthwise_BN[0][0]']
block_4_project (Conv2D) (None, 20, 20, 32) 6144 ['block_4_depthwise_relu[0][0]']
block_4_project_BN (BatchNorma (None, 20, 20, 32) 128 ['block_4_project[0][0]']
lization)
block_4_add (Add) (None, 20, 20, 32) 0 ['block_3_project_BN[0][0]',
'block_4_project_BN[0][0]']
block_5_expand (Conv2D) (None, 20, 20, 192) 6144 ['block_4_add[0][0]']
block_5_expand_BN (BatchNormal (None, 20, 20, 192) 768 ['block_5_expand[0][0]']
ization)
block_5_expand_relu (ReLU) (None, 20, 20, 192) 0 ['block_5_expand_BN[0][0]']
block_5_depthwise (DepthwiseCo (None, 20, 20, 192) 1728 ['block_5_expand_relu[0][0]']
nv2D)
block_5_depthwise_BN (BatchNor (None, 20, 20, 192) 768 ['block_5_depthwise[0][0]']
malization)
block_5_depthwise_relu (ReLU) (None, 20, 20, 192) 0 ['block_5_depthwise_BN[0][0]']
block_5_project (Conv2D) (None, 20, 20, 32) 6144 ['block_5_depthwise_relu[0][0]']
block_5_project_BN (BatchNorma (None, 20, 20, 32) 128 ['block_5_project[0][0]']
lization)
block_5_add (Add) (None, 20, 20, 32) 0 ['block_4_add[0][0]',
'block_5_project_BN[0][0]']
block_6_expand (Conv2D) (None, 20, 20, 192) 6144 ['block_5_add[0][0]']
block_6_expand_BN (BatchNormal (None, 20, 20, 192) 768 ['block_6_expand[0][0]']
ization)
block_6_expand_relu (ReLU) (None, 20, 20, 192) 0 ['block_6_expand_BN[0][0]']
block_6_pad (ZeroPadding2D) (None, 21, 21, 192) 0 ['block_6_expand_relu[0][0]']
block_6_depthwise (DepthwiseCo (None, 10, 10, 192) 1728 ['block_6_pad[0][0]']
nv2D)
block_6_depthwise_BN (BatchNor (None, 10, 10, 192) 768 ['block_6_depthwise[0][0]']
malization)
block_6_depthwise_relu (ReLU) (None, 10, 10, 192) 0 ['block_6_depthwise_BN[0][0]']
block_6_project (Conv2D) (None, 10, 10, 64) 12288 ['block_6_depthwise_relu[0][0]']
block_6_project_BN (BatchNorma (None, 10, 10, 64) 256 ['block_6_project[0][0]']
lization)
block_7_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_6_project_BN[0][0]']
block_7_expand_BN (BatchNormal (None, 10, 10, 384) 1536 ['block_7_expand[0][0]']
ization)
block_7_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_7_expand_BN[0][0]']
block_7_depthwise (DepthwiseCo (None, 10, 10, 384) 3456 ['block_7_expand_relu[0][0]']
nv2D)
block_7_depthwise_BN (BatchNor (None, 10, 10, 384) 1536 ['block_7_depthwise[0][0]']
malization)
block_7_depthwise_relu (ReLU) (None, 10, 10, 384) 0 ['block_7_depthwise_BN[0][0]']
block_7_project (Conv2D) (None, 10, 10, 64) 24576 ['block_7_depthwise_relu[0][0]']
block_7_project_BN (BatchNorma (None, 10, 10, 64) 256 ['block_7_project[0][0]']
lization)
block_7_add (Add) (None, 10, 10, 64) 0 ['block_6_project_BN[0][0]',
'block_7_project_BN[0][0]']
block_8_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_7_add[0][0]']
block_8_expand_BN (BatchNormal (None, 10, 10, 384) 1536 ['block_8_expand[0][0]']
ization)
block_8_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_8_expand_BN[0][0]']
block_8_depthwise (DepthwiseCo (None, 10, 10, 384) 3456 ['block_8_expand_relu[0][0]']
nv2D)
block_8_depthwise_BN (BatchNor (None, 10, 10, 384) 1536 ['block_8_depthwise[0][0]']
malization)
block_8_depthwise_relu (ReLU) (None, 10, 10, 384) 0 ['block_8_depthwise_BN[0][0]']
block_8_project (Conv2D) (None, 10, 10, 64) 24576 ['block_8_depthwise_relu[0][0]']
block_8_project_BN (BatchNorma (None, 10, 10, 64) 256 ['block_8_project[0][0]']
lization)
block_8_add (Add) (None, 10, 10, 64) 0 ['block_7_add[0][0]',
'block_8_project_BN[0][0]']
block_9_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_8_add[0][0]']
block_9_expand_BN (BatchNormal (None, 10, 10, 384) 1536 ['block_9_expand[0][0]']
ization)
block_9_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_9_expand_BN[0][0]']
block_9_depthwise (DepthwiseCo (None, 10, 10, 384) 3456 ['block_9_expand_relu[0][0]']
nv2D)
block_9_depthwise_BN (BatchNor (None, 10, 10, 384) 1536 ['block_9_depthwise[0][0]']
malization)
block_9_depthwise_relu (ReLU) (None, 10, 10, 384) 0 ['block_9_depthwise_BN[0][0]']
block_9_project (Conv2D) (None, 10, 10, 64) 24576 ['block_9_depthwise_relu[0][0]']
block_9_project_BN (BatchNorma (None, 10, 10, 64) 256 ['block_9_project[0][0]']
lization)
block_9_add (Add) (None, 10, 10, 64) 0 ['block_8_add[0][0]',
'block_9_project_BN[0][0]']
block_10_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_9_add[0][0]']
block_10_expand_BN (BatchNorma (None, 10, 10, 384) 1536 ['block_10_expand[0][0]']
lization)
block_10_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_10_expand_BN[0][0]']
block_10_depthwise (DepthwiseC (None, 10, 10, 384) 3456 ['block_10_expand_relu[0][0]']
onv2D)
block_10_depthwise_BN (BatchNo (None, 10, 10, 384) 1536 ['block_10_depthwise[0][0]']
rmalization)
block_10_depthwise_relu (ReLU) (None, 10, 10, 384) 0 ['block_10_depthwise_BN[0][0]']
block_10_project (Conv2D) (None, 10, 10, 96) 36864 ['block_10_depthwise_relu[0][0]']
block_10_project_BN (BatchNorm (None, 10, 10, 96) 384 ['block_10_project[0][0]']
alization)
block_11_expand (Conv2D) (None, 10, 10, 576) 55296 ['block_10_project_BN[0][0]']
block_11_expand_BN (BatchNorma (None, 10, 10, 576) 2304 ['block_11_expand[0][0]']
lization)
block_11_expand_relu (ReLU) (None, 10, 10, 576) 0 ['block_11_expand_BN[0][0]']
block_11_depthwise (DepthwiseC (None, 10, 10, 576) 5184 ['block_11_expand_relu[0][0]']
onv2D)
block_11_depthwise_BN (BatchNo (None, 10, 10, 576) 2304 ['block_11_depthwise[0][0]']
rmalization)
block_11_depthwise_relu (ReLU) (None, 10, 10, 576) 0 ['block_11_depthwise_BN[0][0]']
block_11_project (Conv2D) (None, 10, 10, 96) 55296 ['block_11_depthwise_relu[0][0]']
block_11_project_BN (BatchNorm (None, 10, 10, 96) 384 ['block_11_project[0][0]']
alization)
block_11_add (Add) (None, 10, 10, 96) 0 ['block_10_project_BN[0][0]',
'block_11_project_BN[0][0]']
block_12_expand (Conv2D) (None, 10, 10, 576) 55296 ['block_11_add[0][0]']
block_12_expand_BN (BatchNorma (None, 10, 10, 576) 2304 ['block_12_expand[0][0]']
lization)
block_12_expand_relu (ReLU) (None, 10, 10, 576) 0 ['block_12_expand_BN[0][0]']
block_12_depthwise (DepthwiseC (None, 10, 10, 576) 5184 ['block_12_expand_relu[0][0]']
onv2D)
block_12_depthwise_BN (BatchNo (None, 10, 10, 576) 2304 ['block_12_depthwise[0][0]']
rmalization)
block_12_depthwise_relu (ReLU) (None, 10, 10, 576) 0 ['block_12_depthwise_BN[0][0]']
block_12_project (Conv2D) (None, 10, 10, 96) 55296 ['block_12_depthwise_relu[0][0]']
block_12_project_BN (BatchNorm (None, 10, 10, 96) 384 ['block_12_project[0][0]']
alization)
block_12_add (Add) (None, 10, 10, 96) 0 ['block_11_add[0][0]',
'block_12_project_BN[0][0]']
block_13_expand (Conv2D) (None, 10, 10, 576) 55296 ['block_12_add[0][0]']
block_13_expand_BN (BatchNorma (None, 10, 10, 576) 2304 ['block_13_expand[0][0]']
lization)
block_13_expand_relu (ReLU) (None, 10, 10, 576) 0 ['block_13_expand_BN[0][0]']
block_13_pad (ZeroPadding2D) (None, 11, 11, 576) 0 ['block_13_expand_relu[0][0]']
block_13_depthwise (DepthwiseC (None, 5, 5, 576) 5184 ['block_13_pad[0][0]']
onv2D)
block_13_depthwise_BN (BatchNo (None, 5, 5, 576) 2304 ['block_13_depthwise[0][0]']
rmalization)
block_13_depthwise_relu (ReLU) (None, 5, 5, 576) 0 ['block_13_depthwise_BN[0][0]']
block_13_project (Conv2D) (None, 5, 5, 160) 92160 ['block_13_depthwise_relu[0][0]']
block_13_project_BN (BatchNorm (None, 5, 5, 160) 640 ['block_13_project[0][0]']
alization)
block_14_expand (Conv2D) (None, 5, 5, 960) 153600 ['block_13_project_BN[0][0]']
block_14_expand_BN (BatchNorma (None, 5, 5, 960) 3840 ['block_14_expand[0][0]']
lization)
block_14_expand_relu (ReLU) (None, 5, 5, 960) 0 ['block_14_expand_BN[0][0]']
block_14_depthwise (DepthwiseC (None, 5, 5, 960) 8640 ['block_14_expand_relu[0][0]']
onv2D)
block_14_depthwise_BN (BatchNo (None, 5, 5, 960) 3840 ['block_14_depthwise[0][0]']
rmalization)
block_14_depthwise_relu (ReLU) (None, 5, 5, 960) 0 ['block_14_depthwise_BN[0][0]']
block_14_project (Conv2D) (None, 5, 5, 160) 153600 ['block_14_depthwise_relu[0][0]']
block_14_project_BN (BatchNorm (None, 5, 5, 160) 640 ['block_14_project[0][0]']
alization)
block_14_add (Add) (None, 5, 5, 160) 0 ['block_13_project_BN[0][0]',
'block_14_project_BN[0][0]']
block_15_expand (Conv2D) (None, 5, 5, 960) 153600 ['block_14_add[0][0]']
block_15_expand_BN (BatchNorma (None, 5, 5, 960) 3840 ['block_15_expand[0][0]']
lization)
block_15_expand_relu (ReLU) (None, 5, 5, 960) 0 ['block_15_expand_BN[0][0]']
block_15_depthwise (DepthwiseC (None, 5, 5, 960) 8640 ['block_15_expand_relu[0][0]']
onv2D)
block_15_depthwise_BN (BatchNo (None, 5, 5, 960) 3840 ['block_15_depthwise[0][0]']
rmalization)
block_15_depthwise_relu (ReLU) (None, 5, 5, 960) 0 ['block_15_depthwise_BN[0][0]']
block_15_project (Conv2D) (None, 5, 5, 160) 153600 ['block_15_depthwise_relu[0][0]']
block_15_project_BN (BatchNorm (None, 5, 5, 160) 640 ['block_15_project[0][0]']
alization)
block_15_add (Add) (None, 5, 5, 160) 0 ['block_14_add[0][0]',
'block_15_project_BN[0][0]']
block_16_expand (Conv2D) (None, 5, 5, 960) 153600 ['block_15_add[0][0]']
block_16_expand_BN (BatchNorma (None, 5, 5, 960) 3840 ['block_16_expand[0][0]']
lization)
block_16_expand_relu (ReLU) (None, 5, 5, 960) 0 ['block_16_expand_BN[0][0]']
block_16_depthwise (DepthwiseC (None, 5, 5, 960) 8640 ['block_16_expand_relu[0][0]']
onv2D)
block_16_depthwise_BN (BatchNo (None, 5, 5, 960) 3840 ['block_16_depthwise[0][0]']
rmalization)
block_16_depthwise_relu (ReLU) (None, 5, 5, 960) 0 ['block_16_depthwise_BN[0][0]']
block_16_project (Conv2D) (None, 5, 5, 320) 307200 ['block_16_depthwise_relu[0][0]']
block_16_project_BN (BatchNorm (None, 5, 5, 320) 1280 ['block_16_project[0][0]']
alization)
Conv_1 (Conv2D) (None, 5, 5, 1280) 409600 ['block_16_project_BN[0][0]']
Conv_1_bn (BatchNormalization) (None, 5, 5, 1280) 5120 ['Conv_1[0][0]']
out_relu (ReLU) (None, 5, 5, 1280) 0 ['Conv_1_bn[0][0]']
==================================================================================================
Total params: 2,257,984
Trainable params: 0
Non-trainable params: 2,257,984
__________________________________________________________________________________________________
Добавить заголовок классификации
Чтобы сгенерировать прогнозы из блока функций, усредните пространственные пространственные местоположения 5x5 , используя слой tf.keras.layers.GlobalAveragePooling2D , чтобы преобразовать функции в один вектор из 1280 элементов для каждого изображения.
global_average_layer = tf.keras.layers.GlobalAveragePooling2D()
feature_batch_average = global_average_layer(feature_batch)
print(feature_batch_average.shape)
(32, 1280)
Примените слой tf.keras.layers.Dense , чтобы преобразовать эти функции в один прогноз для каждого изображения. Здесь вам не нужна функция активации, потому что этот прогноз будет рассматриваться как logit или необработанное значение прогноза. Положительные числа предсказывают класс 1, отрицательные числа предсказывают класс 0.
prediction_layer = tf.keras.layers.Dense(1)
prediction_batch = prediction_layer(feature_batch_average)
print(prediction_batch.shape)
(32, 1)
Создайте модель, объединив вместе слои увеличения данных, масштабирования, base_model и извлечения признаков с помощью функционального API Keras. Как упоминалось ранее, используйте training=False , так как наша модель содержит слой BatchNormalization .
inputs = tf.keras.Input(shape=(160, 160, 3))
x = data_augmentation(inputs)
x = preprocess_input(x)
x = base_model(x, training=False)
x = global_average_layer(x)
x = tf.keras.layers.Dropout(0.2)(x)
outputs = prediction_layer(x)
model = tf.keras.Model(inputs, outputs)
Скомпилируйте модель
Скомпилируйте модель перед ее обучением. Поскольку есть два класса, используйте потери tf.keras.losses.BinaryCrossentropy с from_logits=True , поскольку модель обеспечивает линейный вывод.
base_learning_rate = 0.0001
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=base_learning_rate),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 160, 160, 3)] 0
sequential (Sequential) (None, 160, 160, 3) 0
tf.math.truediv (TFOpLambda (None, 160, 160, 3) 0
)
tf.math.subtract (TFOpLambd (None, 160, 160, 3) 0
a)
mobilenetv2_1.00_160 (Funct (None, 5, 5, 1280) 2257984
ional)
global_average_pooling2d (G (None, 1280) 0
lobalAveragePooling2D)
dropout (Dropout) (None, 1280) 0
dense (Dense) (None, 1) 1281
=================================================================
Total params: 2,259,265
Trainable params: 1,281
Non-trainable params: 2,257,984
_________________________________________________________________
2,5 миллиона параметров в MobileNet заморожены, но в плотном слое есть 1,2 тысячи обучаемых параметров. Они разделены между двумя объектами tf.Variable , весами и смещениями.
len(model.trainable_variables)
2
Обучите модель
После обучения в течение 10 эпох вы должны увидеть точность ~ 94% на проверочном наборе.
initial_epochs = 10
loss0, accuracy0 = model.evaluate(validation_dataset)
26/26 [==============================] - 2s 16ms/step - loss: 0.7428 - accuracy: 0.5186
print("initial loss: {:.2f}".format(loss0))
print("initial accuracy: {:.2f}".format(accuracy0))
initial loss: 0.74 initial accuracy: 0.52
history = model.fit(train_dataset,
epochs=initial_epochs,
validation_data=validation_dataset)
Epoch 1/10 63/63 [==============================] - 4s 23ms/step - loss: 0.6804 - accuracy: 0.5680 - val_loss: 0.4981 - val_accuracy: 0.7054 Epoch 2/10 63/63 [==============================] - 1s 22ms/step - loss: 0.5044 - accuracy: 0.7170 - val_loss: 0.3598 - val_accuracy: 0.8144 Epoch 3/10 63/63 [==============================] - 1s 21ms/step - loss: 0.4109 - accuracy: 0.7845 - val_loss: 0.2810 - val_accuracy: 0.8861 Epoch 4/10 63/63 [==============================] - 1s 21ms/step - loss: 0.3285 - accuracy: 0.8445 - val_loss: 0.2256 - val_accuracy: 0.9208 Epoch 5/10 63/63 [==============================] - 1s 21ms/step - loss: 0.3108 - accuracy: 0.8555 - val_loss: 0.1986 - val_accuracy: 0.9307 Epoch 6/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2659 - accuracy: 0.8855 - val_loss: 0.1703 - val_accuracy: 0.9418 Epoch 7/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2459 - accuracy: 0.8935 - val_loss: 0.1495 - val_accuracy: 0.9517 Epoch 8/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2315 - accuracy: 0.8950 - val_loss: 0.1454 - val_accuracy: 0.9542 Epoch 9/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2204 - accuracy: 0.9030 - val_loss: 0.1326 - val_accuracy: 0.9592 Epoch 10/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2180 - accuracy: 0.9115 - val_loss: 0.1215 - val_accuracy: 0.9604
Кривые обучения
Давайте взглянем на кривые обучения точности/потери при обучении и проверке при использовании базовой модели MobileNetV2 в качестве экстрактора с фиксированными функциями.
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.ylim([min(plt.ylim()),1])
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.ylim([0,1.0])
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
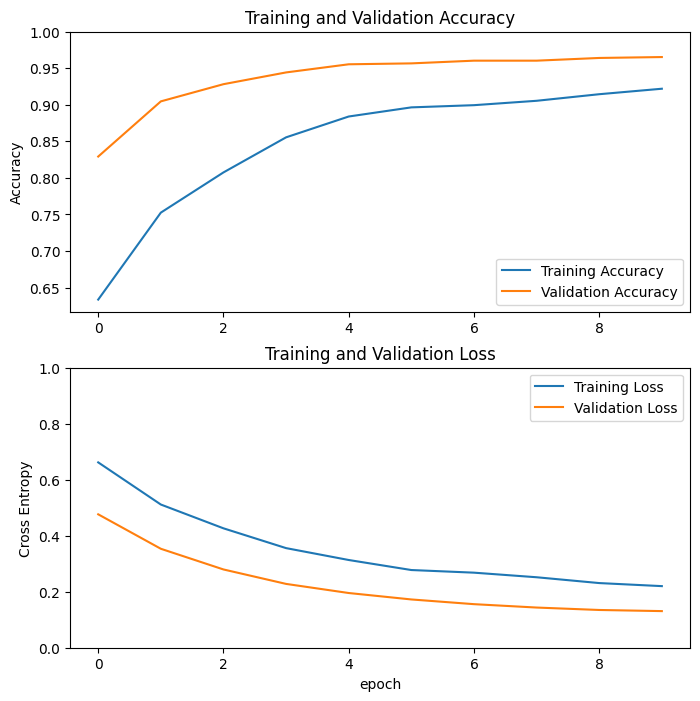
В меньшей степени это также связано с тем, что метрики обучения сообщают среднее значение для эпохи, в то время как метрики проверки оцениваются после эпохи, поэтому метрики проверки видят модель, которая обучалась немного дольше.
Тонкая настройка
В эксперименте по извлечению признаков вы обучали только несколько слоев поверх базовой модели MobileNetV2. Веса предварительно обученной сети не обновлялись во время обучения.
Одним из способов еще большего повышения производительности является обучение (или «точная настройка») весов верхних слоев предварительно обученной модели наряду с обучением добавленного вами классификатора. В процессе обучения веса должны быть настроены с общих карт объектов на функции, связанные конкретно с набором данных.
Кроме того, вам следует попытаться настроить небольшое количество верхних слоев, а не всю модель MobileNet. В большинстве сверточных сетей чем выше уровень, тем более он специализирован. Первые несколько слоев изучают очень простые и общие функции, которые применимы практически ко всем типам изображений. По мере того, как вы поднимаетесь выше, функции становятся все более специфичными для набора данных, на котором была обучена модель. Цель тонкой настройки — адаптировать эти специализированные функции для работы с новым набором данных, а не перезаписывать общее обучение.
Разморозить верхние слои модели
Все, что вам нужно сделать, это разморозить base_model и сделать нижние слои необучаемыми. Затем следует перекомпилировать модель (необходимо, чтобы эти изменения вступили в силу) и возобновить обучение.
base_model.trainable = True
# Let's take a look to see how many layers are in the base model
print("Number of layers in the base model: ", len(base_model.layers))
# Fine-tune from this layer onwards
fine_tune_at = 100
# Freeze all the layers before the `fine_tune_at` layer
for layer in base_model.layers[:fine_tune_at]:
layer.trainable = False
Number of layers in the base model: 154
Скомпилируйте модель
Поскольку вы тренируете гораздо большую модель и хотите повторно адаптировать предварительно обученные веса, на этом этапе важно использовать более низкую скорость обучения. В противном случае ваша модель может очень быстро переобучиться.
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer = tf.keras.optimizers.RMSprop(learning_rate=base_learning_rate/10),
metrics=['accuracy'])
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 160, 160, 3)] 0
sequential (Sequential) (None, 160, 160, 3) 0
tf.math.truediv (TFOpLambda (None, 160, 160, 3) 0
)
tf.math.subtract (TFOpLambd (None, 160, 160, 3) 0
a)
mobilenetv2_1.00_160 (Funct (None, 5, 5, 1280) 2257984
ional)
global_average_pooling2d (G (None, 1280) 0
lobalAveragePooling2D)
dropout (Dropout) (None, 1280) 0
dense (Dense) (None, 1) 1281
=================================================================
Total params: 2,259,265
Trainable params: 1,862,721
Non-trainable params: 396,544
_________________________________________________________________
len(model.trainable_variables)
56
Продолжить обучение модели
Если вы тренировались конвергенции ранее, этот шаг улучшит вашу точность на несколько процентных пунктов.
fine_tune_epochs = 10
total_epochs = initial_epochs + fine_tune_epochs
history_fine = model.fit(train_dataset,
epochs=total_epochs,
initial_epoch=history.epoch[-1],
validation_data=validation_dataset)
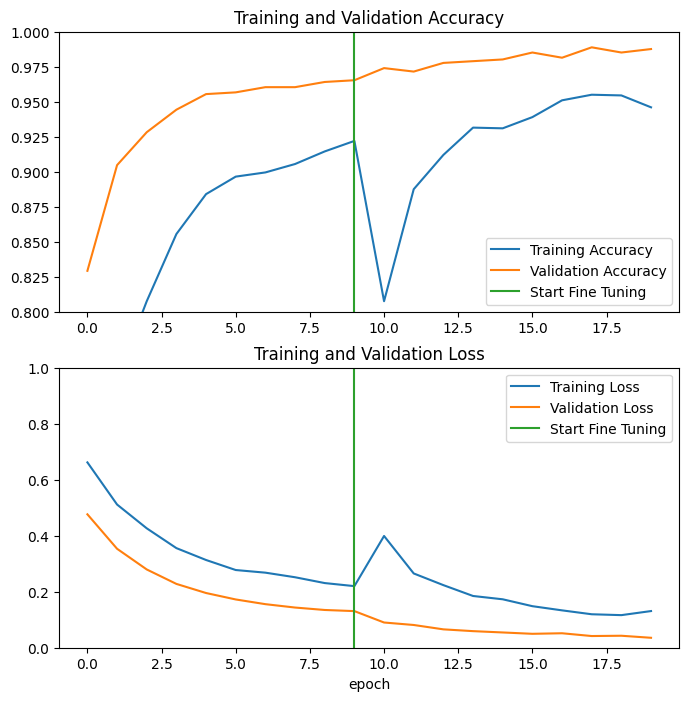
Epoch 10/20 63/63 [==============================] - 7s 40ms/step - loss: 0.1545 - accuracy: 0.9335 - val_loss: 0.0531 - val_accuracy: 0.9864 Epoch 11/20 63/63 [==============================] - 2s 28ms/step - loss: 0.1161 - accuracy: 0.9540 - val_loss: 0.0500 - val_accuracy: 0.9814 Epoch 12/20 63/63 [==============================] - 2s 28ms/step - loss: 0.1125 - accuracy: 0.9525 - val_loss: 0.0379 - val_accuracy: 0.9876 Epoch 13/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0891 - accuracy: 0.9625 - val_loss: 0.0472 - val_accuracy: 0.9889 Epoch 14/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0844 - accuracy: 0.9680 - val_loss: 0.0478 - val_accuracy: 0.9889 Epoch 15/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0857 - accuracy: 0.9645 - val_loss: 0.0354 - val_accuracy: 0.9839 Epoch 16/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0785 - accuracy: 0.9690 - val_loss: 0.0449 - val_accuracy: 0.9864 Epoch 17/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0669 - accuracy: 0.9740 - val_loss: 0.0375 - val_accuracy: 0.9839 Epoch 18/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0701 - accuracy: 0.9695 - val_loss: 0.0324 - val_accuracy: 0.9864 Epoch 19/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0636 - accuracy: 0.9760 - val_loss: 0.0465 - val_accuracy: 0.9790 Epoch 20/20 63/63 [==============================] - 2s 29ms/step - loss: 0.0585 - accuracy: 0.9765 - val_loss: 0.0392 - val_accuracy: 0.9851
Давайте посмотрим на кривые обучения точности/потери обучения и проверки при точной настройке последних нескольких слоев базовой модели MobileNetV2 и обучении классификатора поверх нее. Потери при проверке намного выше, чем потери при обучении, поэтому вы можете получить некоторое переоснащение.
Вы также можете получить некоторое переоснащение, поскольку новый обучающий набор относительно мал и похож на исходные наборы данных MobileNetV2.
После тонкой настройки модель достигает почти 98% точности на проверочном наборе.
acc += history_fine.history['accuracy']
val_acc += history_fine.history['val_accuracy']
loss += history_fine.history['loss']
val_loss += history_fine.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.ylim([0.8, 1])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.ylim([0, 1.0])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
Оценка и прогноз
Наконец, вы можете проверить производительность модели на новых данных, используя тестовый набор.
loss, accuracy = model.evaluate(test_dataset)
print('Test accuracy :', accuracy)
6/6 [==============================] - 0s 13ms/step - loss: 0.0281 - accuracy: 0.9948 Test accuracy : 0.9947916865348816
И теперь вы готовы использовать эту модель, чтобы предсказать, является ли ваш питомец кошкой или собакой.
# Retrieve a batch of images from the test set
image_batch, label_batch = test_dataset.as_numpy_iterator().next()
predictions = model.predict_on_batch(image_batch).flatten()
# Apply a sigmoid since our model returns logits
predictions = tf.nn.sigmoid(predictions)
predictions = tf.where(predictions < 0.5, 0, 1)
print('Predictions:\n', predictions.numpy())
print('Labels:\n', label_batch)
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image_batch[i].astype("uint8"))
plt.title(class_names[predictions[i]])
plt.axis("off")
Predictions: [0 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 0 0 0 1 0 1 0 0 1 1 1 0 0 0 1 0] Labels: [0 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 0 0 0 1 0 1 0 0 1 1 1 0 0 0 1 0]

Резюме
Использование предварительно обученной модели для извлечения признаков . При работе с небольшим набором данных обычной практикой является использование функций, изученных моделью, обученной на большом наборе данных в той же области. Это делается путем создания экземпляра предварительно обученной модели и добавления полносвязного классификатора сверху. Предварительно обученная модель «замораживается», и во время обучения обновляются только веса классификатора. В этом случае сверточная база извлекла все функции, связанные с каждым изображением, и вы только что обучили классификатор, который определяет класс изображения с учетом этого набора извлеченных функций.
Тонкая настройка предварительно обученной модели . Для дальнейшего повышения производительности может потребоваться переназначить слои верхнего уровня предварительно обученных моделей для нового набора данных посредством тонкой настройки. В этом случае вы настроили свои веса так, чтобы ваша модель изучила высокоуровневые функции, характерные для набора данных. Этот метод обычно рекомендуется, когда обучающий набор данных большой и очень похож на исходный набор данных, на котором обучалась предварительно обученная модель.
Чтобы узнать больше, посетите учебное пособие по переносу.
# MIT License
#
# Copyright (c) 2017 François Chollet # IGNORE_COPYRIGHT: cleared by OSS licensing
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.