
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Trong hướng dẫn này, bạn sẽ học cách phân loại hình ảnh của mèo và chó bằng cách sử dụng phương pháp học chuyển giao từ một mạng được đào tạo trước.
Mô hình được đào tạo trước là một mạng đã lưu đã được đào tạo trước đó trên một tập dữ liệu lớn, thường là trong nhiệm vụ phân loại hình ảnh quy mô lớn. Bạn có thể sử dụng mô hình được đào tạo trước như hiện tại hoặc sử dụng học chuyển giao để tùy chỉnh mô hình này cho một nhiệm vụ nhất định.
Trực giác đằng sau việc học truyền để phân loại hình ảnh là nếu một mô hình được đào tạo trên một tập dữ liệu đủ lớn và tổng quát, mô hình này sẽ đóng vai trò như một mô hình chung của thế giới hình ảnh một cách hiệu quả. Sau đó, bạn có thể tận dụng các bản đồ đặc trưng đã học này mà không cần phải bắt đầu lại từ đầu bằng cách đào tạo một mô hình lớn trên một tập dữ liệu lớn.
Trong sổ tay này, bạn sẽ thử hai cách để tùy chỉnh một mô hình được đào tạo trước:
Trích xuất đối tượng: Sử dụng các biểu diễn đã học được bởi mạng trước đó để trích xuất các đối tượng địa lý có ý nghĩa từ các mẫu mới. Bạn chỉ cần thêm một bộ phân loại mới, sẽ được đào tạo từ đầu, bên trên mô hình được đào tạo trước để bạn có thể sử dụng lại các bản đồ đặc trưng đã học trước đó cho tập dữ liệu.
Bạn không cần (lại) đào tạo toàn bộ mô hình. Mạng tích hợp cơ sở đã chứa các tính năng nói chung hữu ích cho việc phân loại ảnh. Tuy nhiên, phần phân loại cuối cùng của mô hình được đào tạo trước là cụ thể cho nhiệm vụ phân loại ban đầu và sau đó cụ thể cho tập hợp các lớp mà mô hình đã được đào tạo.
Tinh chỉnh: Giải phóng một số lớp trên cùng của đế mô hình đã đóng băng và cùng huấn luyện cả các lớp phân loại mới được thêm vào và các lớp cuối cùng của mô hình cơ sở. Điều này cho phép chúng tôi "tinh chỉnh" các đại diện tính năng bậc cao hơn trong mô hình cơ sở để làm cho chúng phù hợp hơn với nhiệm vụ cụ thể.
Bạn sẽ tuân theo quy trình làm việc chung của máy học.
- Kiểm tra và hiểu dữ liệu
- Xây dựng một đường dẫn đầu vào, trong trường hợp này là sử dụng Keras ImageDataGenerator
- Soạn mô hình
- Tải trong mô hình cơ sở được huấn luyện trước (và các trọng lượng được huấn luyện trước)
- Xếp chồng các lớp phân loại lên trên
- Đào tạo mô hình
- Đánh giá mô hình
import matplotlib.pyplot as plt
import numpy as np
import os
import tensorflow as tf
Xử lý trước dữ liệu
Tải xuống dữ liệu
Trong hướng dẫn này, bạn sẽ sử dụng một tập dữ liệu chứa hàng nghìn hình ảnh về chó và mèo. Tải xuống và giải nén tệp zip có chứa hình ảnh, sau đó tạo tf.data.Dataset để đào tạo và xác thực bằng tiện ích tf.keras.utils.image_dataset_from_directory . Bạn có thể tìm hiểu thêm về cách tải hình ảnh trong hướng dẫn này.
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
path_to_zip = tf.keras.utils.get_file('cats_and_dogs.zip', origin=_URL, extract=True)
PATH = os.path.join(os.path.dirname(path_to_zip), 'cats_and_dogs_filtered')
train_dir = os.path.join(PATH, 'train')
validation_dir = os.path.join(PATH, 'validation')
BATCH_SIZE = 32
IMG_SIZE = (160, 160)
train_dataset = tf.keras.utils.image_dataset_from_directory(train_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
Downloading data from https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip 68608000/68606236 [==============================] - 1s 0us/step 68616192/68606236 [==============================] - 1s 0us/step Found 2000 files belonging to 2 classes.
validation_dataset = tf.keras.utils.image_dataset_from_directory(validation_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
Found 1000 files belonging to 2 classes.
Hiển thị chín hình ảnh và nhãn đầu tiên từ bộ đào tạo:
class_names = train_dataset.class_names
plt.figure(figsize=(10, 10))
for images, labels in train_dataset.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")

Vì tập dữ liệu gốc không chứa tập thử nghiệm, bạn sẽ tạo một tập hợp. Để làm như vậy, hãy xác định có bao nhiêu lô dữ liệu có sẵn trong tập hợp xác thực bằng cách sử dụng tf.data.experimental.cardinality , sau đó chuyển 20% trong số chúng vào tập thử nghiệm.
val_batches = tf.data.experimental.cardinality(validation_dataset)
test_dataset = validation_dataset.take(val_batches // 5)
validation_dataset = validation_dataset.skip(val_batches // 5)
print('Number of validation batches: %d' % tf.data.experimental.cardinality(validation_dataset))
print('Number of test batches: %d' % tf.data.experimental.cardinality(test_dataset))
Number of validation batches: 26 Number of test batches: 6
Định cấu hình tập dữ liệu cho hiệu suất
Sử dụng tìm nạp trước có bộ đệm để tải hình ảnh từ đĩa mà không bị chặn I / O. Để tìm hiểu thêm về phương pháp này, hãy xem hướng dẫn về hiệu suất dữ liệu .
AUTOTUNE = tf.data.AUTOTUNE
train_dataset = train_dataset.prefetch(buffer_size=AUTOTUNE)
validation_dataset = validation_dataset.prefetch(buffer_size=AUTOTUNE)
test_dataset = test_dataset.prefetch(buffer_size=AUTOTUNE)
Sử dụng tăng dữ liệu
Khi bạn không có tập dữ liệu hình ảnh lớn, bạn nên áp dụng một cách giả tạo tính đa dạng mẫu bằng cách áp dụng các phép biến đổi ngẫu nhiên, nhưng thực tế cho hình ảnh huấn luyện, chẳng hạn như xoay và lật ngang. Điều này giúp mô hình tiếp xúc với các khía cạnh khác nhau của dữ liệu đào tạo và giảm việc trang bị quá nhiều . Bạn có thể tìm hiểu thêm về tăng dữ liệu trong hướng dẫn này.
data_augmentation = tf.keras.Sequential([
tf.keras.layers.RandomFlip('horizontal'),
tf.keras.layers.RandomRotation(0.2),
])
Hãy liên tục áp dụng các lớp này cho cùng một hình ảnh và xem kết quả.
for image, _ in train_dataset.take(1):
plt.figure(figsize=(10, 10))
first_image = image[0]
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
augmented_image = data_augmentation(tf.expand_dims(first_image, 0))
plt.imshow(augmented_image[0] / 255)
plt.axis('off')

Bán lại giá trị pixel
Trong giây lát, bạn sẽ tải xuống tf.keras.applications.MobileNetV2 để sử dụng làm mô hình cơ sở của mình. Mô hình này mong đợi giá trị pixel trong [-1, 1] , nhưng tại thời điểm này, giá trị pixel trong hình ảnh của bạn ở [0, 255] . Để bán lại chúng, hãy sử dụng phương pháp xử lý trước đi kèm với mô hình.
preprocess_input = tf.keras.applications.mobilenet_v2.preprocess_input
rescale = tf.keras.layers.Rescaling(1./127.5, offset=-1)
Tạo mô hình cơ sở từ các chuyển đổi được đào tạo trước
Bạn sẽ tạo mô hình cơ sở từ mô hình MobileNet V2 được phát triển tại Google. Điều này được đào tạo trước trên tập dữ liệu ImageNet, một tập dữ liệu lớn bao gồm 1,4 triệu hình ảnh và 1000 lớp. ImageNet là một tập dữ liệu đào tạo nghiên cứu với nhiều loại khác nhau như jackfruit và syringe . Cơ sở kiến thức này sẽ giúp chúng tôi phân loại chó và mèo từ tập dữ liệu cụ thể của chúng tôi.
Trước tiên, bạn cần chọn lớp MobileNet V2 bạn sẽ sử dụng để trích xuất tính năng. Lớp phân loại cuối cùng (ở "trên cùng", vì hầu hết các sơ đồ của mô hình học máy đều đi từ dưới lên trên) không hữu ích lắm. Thay vào đó, bạn sẽ làm theo thông lệ phổ biến là phụ thuộc vào chính lớp cuối cùng trước khi thao tác làm phẳng. Lớp này được gọi là "lớp nút cổ chai". Các tính năng của lớp nút cổ chai giữ được tính tổng quát hơn so với lớp cuối cùng / trên cùng.
Đầu tiên, khởi tạo mô hình MobileNet V2 được tải sẵn với các trọng số được đào tạo trên ImageNet. Bằng cách chỉ định đối số include_top = False , bạn tải một mạng không bao gồm các lớp phân loại ở trên cùng, điều này lý tưởng cho việc trích xuất đối tượng địa lý.
# Create the base model from the pre-trained model MobileNet V2
IMG_SHAPE = IMG_SIZE + (3,)
base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_160_no_top.h5 9412608/9406464 [==============================] - 0s 0us/step 9420800/9406464 [==============================] - 0s 0us/step
Trình trích xuất tính năng này chuyển đổi từng hình ảnh 160x160x3 thành một khối tính năng 5x5x1280 . Hãy xem những gì nó làm với một loạt hình ảnh ví dụ:
image_batch, label_batch = next(iter(train_dataset))
feature_batch = base_model(image_batch)
print(feature_batch.shape)
(32, 5, 5, 1280)
Khai thác tính năng
Trong bước này, bạn sẽ đóng băng cơ sở phức hợp được tạo từ bước trước và để sử dụng làm trình trích xuất tính năng. Ngoài ra, bạn thêm một bộ phân loại lên trên nó và đào tạo bộ phân loại cấp cao nhất.
Đóng băng cơ sở phức tạp
Điều quan trọng là phải đóng băng cơ sở phức hợp trước khi bạn biên dịch và đào tạo mô hình. Việc đóng băng (bằng cách đặt layer.trainable = False) ngăn không cho các trọng lượng trong một lớp nhất định được cập nhật trong quá trình luyện tập. trainable V2 có nhiều lớp, vì vậy việc đặt cờ có thể đào tạo của toàn bộ mô hình thành Sai sẽ đóng băng tất cả chúng.
base_model.trainable = False
Lưu ý quan trọng về các lớp BatchNormalization
Nhiều mô hình chứa các lớp tf.keras.layers.BatchNormalization . Lớp này là một trường hợp đặc biệt và nên thực hiện các biện pháp phòng ngừa trong bối cảnh tinh chỉnh, như được trình bày ở phần sau của hướng dẫn này.
Khi bạn đặt layer.trainable = False , lớp BatchNormalization sẽ chạy ở chế độ suy luận và sẽ không cập nhật thống kê trung bình và phương sai của nó.
Khi bạn giải phóng một mô hình có chứa các lớp BatchNormalization để thực hiện tinh chỉnh, bạn nên giữ các lớp BatchNormalization ở chế độ suy luận bằng cách chuyển training = False khi gọi mô hình cơ sở. Nếu không, các cập nhật được áp dụng cho các trọng số không thể đào tạo sẽ phá hủy những gì mô hình đã học được.
Để biết thêm chi tiết, hãy xem hướng dẫn học Chuyển tiếp .
# Let's take a look at the base model architecture
base_model.summary()
Model: "mobilenetv2_1.00_160"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 160, 160, 3 0 []
)]
Conv1 (Conv2D) (None, 80, 80, 32) 864 ['input_1[0][0]']
bn_Conv1 (BatchNormalization) (None, 80, 80, 32) 128 ['Conv1[0][0]']
Conv1_relu (ReLU) (None, 80, 80, 32) 0 ['bn_Conv1[0][0]']
expanded_conv_depthwise (Depth (None, 80, 80, 32) 288 ['Conv1_relu[0][0]']
wiseConv2D)
expanded_conv_depthwise_BN (Ba (None, 80, 80, 32) 128 ['expanded_conv_depthwise[0][0]']
tchNormalization)
expanded_conv_depthwise_relu ( (None, 80, 80, 32) 0 ['expanded_conv_depthwise_BN[0][0
ReLU) ]']
expanded_conv_project (Conv2D) (None, 80, 80, 16) 512 ['expanded_conv_depthwise_relu[0]
[0]']
expanded_conv_project_BN (Batc (None, 80, 80, 16) 64 ['expanded_conv_project[0][0]']
hNormalization)
block_1_expand (Conv2D) (None, 80, 80, 96) 1536 ['expanded_conv_project_BN[0][0]'
]
block_1_expand_BN (BatchNormal (None, 80, 80, 96) 384 ['block_1_expand[0][0]']
ization)
block_1_expand_relu (ReLU) (None, 80, 80, 96) 0 ['block_1_expand_BN[0][0]']
block_1_pad (ZeroPadding2D) (None, 81, 81, 96) 0 ['block_1_expand_relu[0][0]']
block_1_depthwise (DepthwiseCo (None, 40, 40, 96) 864 ['block_1_pad[0][0]']
nv2D)
block_1_depthwise_BN (BatchNor (None, 40, 40, 96) 384 ['block_1_depthwise[0][0]']
malization)
block_1_depthwise_relu (ReLU) (None, 40, 40, 96) 0 ['block_1_depthwise_BN[0][0]']
block_1_project (Conv2D) (None, 40, 40, 24) 2304 ['block_1_depthwise_relu[0][0]']
block_1_project_BN (BatchNorma (None, 40, 40, 24) 96 ['block_1_project[0][0]']
lization)
block_2_expand (Conv2D) (None, 40, 40, 144) 3456 ['block_1_project_BN[0][0]']
block_2_expand_BN (BatchNormal (None, 40, 40, 144) 576 ['block_2_expand[0][0]']
ization)
block_2_expand_relu (ReLU) (None, 40, 40, 144) 0 ['block_2_expand_BN[0][0]']
block_2_depthwise (DepthwiseCo (None, 40, 40, 144) 1296 ['block_2_expand_relu[0][0]']
nv2D)
block_2_depthwise_BN (BatchNor (None, 40, 40, 144) 576 ['block_2_depthwise[0][0]']
malization)
block_2_depthwise_relu (ReLU) (None, 40, 40, 144) 0 ['block_2_depthwise_BN[0][0]']
block_2_project (Conv2D) (None, 40, 40, 24) 3456 ['block_2_depthwise_relu[0][0]']
block_2_project_BN (BatchNorma (None, 40, 40, 24) 96 ['block_2_project[0][0]']
lization)
block_2_add (Add) (None, 40, 40, 24) 0 ['block_1_project_BN[0][0]',
'block_2_project_BN[0][0]']
block_3_expand (Conv2D) (None, 40, 40, 144) 3456 ['block_2_add[0][0]']
block_3_expand_BN (BatchNormal (None, 40, 40, 144) 576 ['block_3_expand[0][0]']
ization)
block_3_expand_relu (ReLU) (None, 40, 40, 144) 0 ['block_3_expand_BN[0][0]']
block_3_pad (ZeroPadding2D) (None, 41, 41, 144) 0 ['block_3_expand_relu[0][0]']
block_3_depthwise (DepthwiseCo (None, 20, 20, 144) 1296 ['block_3_pad[0][0]']
nv2D)
block_3_depthwise_BN (BatchNor (None, 20, 20, 144) 576 ['block_3_depthwise[0][0]']
malization)
block_3_depthwise_relu (ReLU) (None, 20, 20, 144) 0 ['block_3_depthwise_BN[0][0]']
block_3_project (Conv2D) (None, 20, 20, 32) 4608 ['block_3_depthwise_relu[0][0]']
block_3_project_BN (BatchNorma (None, 20, 20, 32) 128 ['block_3_project[0][0]']
lization)
block_4_expand (Conv2D) (None, 20, 20, 192) 6144 ['block_3_project_BN[0][0]']
block_4_expand_BN (BatchNormal (None, 20, 20, 192) 768 ['block_4_expand[0][0]']
ization)
block_4_expand_relu (ReLU) (None, 20, 20, 192) 0 ['block_4_expand_BN[0][0]']
block_4_depthwise (DepthwiseCo (None, 20, 20, 192) 1728 ['block_4_expand_relu[0][0]']
nv2D)
block_4_depthwise_BN (BatchNor (None, 20, 20, 192) 768 ['block_4_depthwise[0][0]']
malization)
block_4_depthwise_relu (ReLU) (None, 20, 20, 192) 0 ['block_4_depthwise_BN[0][0]']
block_4_project (Conv2D) (None, 20, 20, 32) 6144 ['block_4_depthwise_relu[0][0]']
block_4_project_BN (BatchNorma (None, 20, 20, 32) 128 ['block_4_project[0][0]']
lization)
block_4_add (Add) (None, 20, 20, 32) 0 ['block_3_project_BN[0][0]',
'block_4_project_BN[0][0]']
block_5_expand (Conv2D) (None, 20, 20, 192) 6144 ['block_4_add[0][0]']
block_5_expand_BN (BatchNormal (None, 20, 20, 192) 768 ['block_5_expand[0][0]']
ization)
block_5_expand_relu (ReLU) (None, 20, 20, 192) 0 ['block_5_expand_BN[0][0]']
block_5_depthwise (DepthwiseCo (None, 20, 20, 192) 1728 ['block_5_expand_relu[0][0]']
nv2D)
block_5_depthwise_BN (BatchNor (None, 20, 20, 192) 768 ['block_5_depthwise[0][0]']
malization)
block_5_depthwise_relu (ReLU) (None, 20, 20, 192) 0 ['block_5_depthwise_BN[0][0]']
block_5_project (Conv2D) (None, 20, 20, 32) 6144 ['block_5_depthwise_relu[0][0]']
block_5_project_BN (BatchNorma (None, 20, 20, 32) 128 ['block_5_project[0][0]']
lization)
block_5_add (Add) (None, 20, 20, 32) 0 ['block_4_add[0][0]',
'block_5_project_BN[0][0]']
block_6_expand (Conv2D) (None, 20, 20, 192) 6144 ['block_5_add[0][0]']
block_6_expand_BN (BatchNormal (None, 20, 20, 192) 768 ['block_6_expand[0][0]']
ization)
block_6_expand_relu (ReLU) (None, 20, 20, 192) 0 ['block_6_expand_BN[0][0]']
block_6_pad (ZeroPadding2D) (None, 21, 21, 192) 0 ['block_6_expand_relu[0][0]']
block_6_depthwise (DepthwiseCo (None, 10, 10, 192) 1728 ['block_6_pad[0][0]']
nv2D)
block_6_depthwise_BN (BatchNor (None, 10, 10, 192) 768 ['block_6_depthwise[0][0]']
malization)
block_6_depthwise_relu (ReLU) (None, 10, 10, 192) 0 ['block_6_depthwise_BN[0][0]']
block_6_project (Conv2D) (None, 10, 10, 64) 12288 ['block_6_depthwise_relu[0][0]']
block_6_project_BN (BatchNorma (None, 10, 10, 64) 256 ['block_6_project[0][0]']
lization)
block_7_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_6_project_BN[0][0]']
block_7_expand_BN (BatchNormal (None, 10, 10, 384) 1536 ['block_7_expand[0][0]']
ization)
block_7_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_7_expand_BN[0][0]']
block_7_depthwise (DepthwiseCo (None, 10, 10, 384) 3456 ['block_7_expand_relu[0][0]']
nv2D)
block_7_depthwise_BN (BatchNor (None, 10, 10, 384) 1536 ['block_7_depthwise[0][0]']
malization)
block_7_depthwise_relu (ReLU) (None, 10, 10, 384) 0 ['block_7_depthwise_BN[0][0]']
block_7_project (Conv2D) (None, 10, 10, 64) 24576 ['block_7_depthwise_relu[0][0]']
block_7_project_BN (BatchNorma (None, 10, 10, 64) 256 ['block_7_project[0][0]']
lization)
block_7_add (Add) (None, 10, 10, 64) 0 ['block_6_project_BN[0][0]',
'block_7_project_BN[0][0]']
block_8_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_7_add[0][0]']
block_8_expand_BN (BatchNormal (None, 10, 10, 384) 1536 ['block_8_expand[0][0]']
ization)
block_8_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_8_expand_BN[0][0]']
block_8_depthwise (DepthwiseCo (None, 10, 10, 384) 3456 ['block_8_expand_relu[0][0]']
nv2D)
block_8_depthwise_BN (BatchNor (None, 10, 10, 384) 1536 ['block_8_depthwise[0][0]']
malization)
block_8_depthwise_relu (ReLU) (None, 10, 10, 384) 0 ['block_8_depthwise_BN[0][0]']
block_8_project (Conv2D) (None, 10, 10, 64) 24576 ['block_8_depthwise_relu[0][0]']
block_8_project_BN (BatchNorma (None, 10, 10, 64) 256 ['block_8_project[0][0]']
lization)
block_8_add (Add) (None, 10, 10, 64) 0 ['block_7_add[0][0]',
'block_8_project_BN[0][0]']
block_9_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_8_add[0][0]']
block_9_expand_BN (BatchNormal (None, 10, 10, 384) 1536 ['block_9_expand[0][0]']
ization)
block_9_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_9_expand_BN[0][0]']
block_9_depthwise (DepthwiseCo (None, 10, 10, 384) 3456 ['block_9_expand_relu[0][0]']
nv2D)
block_9_depthwise_BN (BatchNor (None, 10, 10, 384) 1536 ['block_9_depthwise[0][0]']
malization)
block_9_depthwise_relu (ReLU) (None, 10, 10, 384) 0 ['block_9_depthwise_BN[0][0]']
block_9_project (Conv2D) (None, 10, 10, 64) 24576 ['block_9_depthwise_relu[0][0]']
block_9_project_BN (BatchNorma (None, 10, 10, 64) 256 ['block_9_project[0][0]']
lization)
block_9_add (Add) (None, 10, 10, 64) 0 ['block_8_add[0][0]',
'block_9_project_BN[0][0]']
block_10_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_9_add[0][0]']
block_10_expand_BN (BatchNorma (None, 10, 10, 384) 1536 ['block_10_expand[0][0]']
lization)
block_10_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_10_expand_BN[0][0]']
block_10_depthwise (DepthwiseC (None, 10, 10, 384) 3456 ['block_10_expand_relu[0][0]']
onv2D)
block_10_depthwise_BN (BatchNo (None, 10, 10, 384) 1536 ['block_10_depthwise[0][0]']
rmalization)
block_10_depthwise_relu (ReLU) (None, 10, 10, 384) 0 ['block_10_depthwise_BN[0][0]']
block_10_project (Conv2D) (None, 10, 10, 96) 36864 ['block_10_depthwise_relu[0][0]']
block_10_project_BN (BatchNorm (None, 10, 10, 96) 384 ['block_10_project[0][0]']
alization)
block_11_expand (Conv2D) (None, 10, 10, 576) 55296 ['block_10_project_BN[0][0]']
block_11_expand_BN (BatchNorma (None, 10, 10, 576) 2304 ['block_11_expand[0][0]']
lization)
block_11_expand_relu (ReLU) (None, 10, 10, 576) 0 ['block_11_expand_BN[0][0]']
block_11_depthwise (DepthwiseC (None, 10, 10, 576) 5184 ['block_11_expand_relu[0][0]']
onv2D)
block_11_depthwise_BN (BatchNo (None, 10, 10, 576) 2304 ['block_11_depthwise[0][0]']
rmalization)
block_11_depthwise_relu (ReLU) (None, 10, 10, 576) 0 ['block_11_depthwise_BN[0][0]']
block_11_project (Conv2D) (None, 10, 10, 96) 55296 ['block_11_depthwise_relu[0][0]']
block_11_project_BN (BatchNorm (None, 10, 10, 96) 384 ['block_11_project[0][0]']
alization)
block_11_add (Add) (None, 10, 10, 96) 0 ['block_10_project_BN[0][0]',
'block_11_project_BN[0][0]']
block_12_expand (Conv2D) (None, 10, 10, 576) 55296 ['block_11_add[0][0]']
block_12_expand_BN (BatchNorma (None, 10, 10, 576) 2304 ['block_12_expand[0][0]']
lization)
block_12_expand_relu (ReLU) (None, 10, 10, 576) 0 ['block_12_expand_BN[0][0]']
block_12_depthwise (DepthwiseC (None, 10, 10, 576) 5184 ['block_12_expand_relu[0][0]']
onv2D)
block_12_depthwise_BN (BatchNo (None, 10, 10, 576) 2304 ['block_12_depthwise[0][0]']
rmalization)
block_12_depthwise_relu (ReLU) (None, 10, 10, 576) 0 ['block_12_depthwise_BN[0][0]']
block_12_project (Conv2D) (None, 10, 10, 96) 55296 ['block_12_depthwise_relu[0][0]']
block_12_project_BN (BatchNorm (None, 10, 10, 96) 384 ['block_12_project[0][0]']
alization)
block_12_add (Add) (None, 10, 10, 96) 0 ['block_11_add[0][0]',
'block_12_project_BN[0][0]']
block_13_expand (Conv2D) (None, 10, 10, 576) 55296 ['block_12_add[0][0]']
block_13_expand_BN (BatchNorma (None, 10, 10, 576) 2304 ['block_13_expand[0][0]']
lization)
block_13_expand_relu (ReLU) (None, 10, 10, 576) 0 ['block_13_expand_BN[0][0]']
block_13_pad (ZeroPadding2D) (None, 11, 11, 576) 0 ['block_13_expand_relu[0][0]']
block_13_depthwise (DepthwiseC (None, 5, 5, 576) 5184 ['block_13_pad[0][0]']
onv2D)
block_13_depthwise_BN (BatchNo (None, 5, 5, 576) 2304 ['block_13_depthwise[0][0]']
rmalization)
block_13_depthwise_relu (ReLU) (None, 5, 5, 576) 0 ['block_13_depthwise_BN[0][0]']
block_13_project (Conv2D) (None, 5, 5, 160) 92160 ['block_13_depthwise_relu[0][0]']
block_13_project_BN (BatchNorm (None, 5, 5, 160) 640 ['block_13_project[0][0]']
alization)
block_14_expand (Conv2D) (None, 5, 5, 960) 153600 ['block_13_project_BN[0][0]']
block_14_expand_BN (BatchNorma (None, 5, 5, 960) 3840 ['block_14_expand[0][0]']
lization)
block_14_expand_relu (ReLU) (None, 5, 5, 960) 0 ['block_14_expand_BN[0][0]']
block_14_depthwise (DepthwiseC (None, 5, 5, 960) 8640 ['block_14_expand_relu[0][0]']
onv2D)
block_14_depthwise_BN (BatchNo (None, 5, 5, 960) 3840 ['block_14_depthwise[0][0]']
rmalization)
block_14_depthwise_relu (ReLU) (None, 5, 5, 960) 0 ['block_14_depthwise_BN[0][0]']
block_14_project (Conv2D) (None, 5, 5, 160) 153600 ['block_14_depthwise_relu[0][0]']
block_14_project_BN (BatchNorm (None, 5, 5, 160) 640 ['block_14_project[0][0]']
alization)
block_14_add (Add) (None, 5, 5, 160) 0 ['block_13_project_BN[0][0]',
'block_14_project_BN[0][0]']
block_15_expand (Conv2D) (None, 5, 5, 960) 153600 ['block_14_add[0][0]']
block_15_expand_BN (BatchNorma (None, 5, 5, 960) 3840 ['block_15_expand[0][0]']
lization)
block_15_expand_relu (ReLU) (None, 5, 5, 960) 0 ['block_15_expand_BN[0][0]']
block_15_depthwise (DepthwiseC (None, 5, 5, 960) 8640 ['block_15_expand_relu[0][0]']
onv2D)
block_15_depthwise_BN (BatchNo (None, 5, 5, 960) 3840 ['block_15_depthwise[0][0]']
rmalization)
block_15_depthwise_relu (ReLU) (None, 5, 5, 960) 0 ['block_15_depthwise_BN[0][0]']
block_15_project (Conv2D) (None, 5, 5, 160) 153600 ['block_15_depthwise_relu[0][0]']
block_15_project_BN (BatchNorm (None, 5, 5, 160) 640 ['block_15_project[0][0]']
alization)
block_15_add (Add) (None, 5, 5, 160) 0 ['block_14_add[0][0]',
'block_15_project_BN[0][0]']
block_16_expand (Conv2D) (None, 5, 5, 960) 153600 ['block_15_add[0][0]']
block_16_expand_BN (BatchNorma (None, 5, 5, 960) 3840 ['block_16_expand[0][0]']
lization)
block_16_expand_relu (ReLU) (None, 5, 5, 960) 0 ['block_16_expand_BN[0][0]']
block_16_depthwise (DepthwiseC (None, 5, 5, 960) 8640 ['block_16_expand_relu[0][0]']
onv2D)
block_16_depthwise_BN (BatchNo (None, 5, 5, 960) 3840 ['block_16_depthwise[0][0]']
rmalization)
block_16_depthwise_relu (ReLU) (None, 5, 5, 960) 0 ['block_16_depthwise_BN[0][0]']
block_16_project (Conv2D) (None, 5, 5, 320) 307200 ['block_16_depthwise_relu[0][0]']
block_16_project_BN (BatchNorm (None, 5, 5, 320) 1280 ['block_16_project[0][0]']
alization)
Conv_1 (Conv2D) (None, 5, 5, 1280) 409600 ['block_16_project_BN[0][0]']
Conv_1_bn (BatchNormalization) (None, 5, 5, 1280) 5120 ['Conv_1[0][0]']
out_relu (ReLU) (None, 5, 5, 1280) 0 ['Conv_1_bn[0][0]']
==================================================================================================
Total params: 2,257,984
Trainable params: 0
Non-trainable params: 2,257,984
__________________________________________________________________________________________________
Thêm đầu phân loại
Để tạo dự đoán từ khối các đối tượng địa lý, hãy tính trung bình trên các vị trí không gian 5x5 không gian, sử dụng lớp tf.keras.layers.GlobalAveragePooling2D để chuyển đổi các đối tượng địa lý thành một vectơ 1280 phần tử duy nhất trên mỗi hình ảnh.
global_average_layer = tf.keras.layers.GlobalAveragePooling2D()
feature_batch_average = global_average_layer(feature_batch)
print(feature_batch_average.shape)
(32, 1280)
Áp dụng lớp tf.keras.layers.Dense để chuyển đổi các tính năng này thành một dự đoán duy nhất cho mỗi hình ảnh. Bạn không cần chức năng kích hoạt ở đây vì dự đoán này sẽ được coi là logit hoặc giá trị dự đoán thô. Số dương dự đoán hạng 1, số âm dự đoán hạng 0.
prediction_layer = tf.keras.layers.Dense(1)
prediction_batch = prediction_layer(feature_batch_average)
print(prediction_batch.shape)
(32, 1)
Xây dựng mô hình bằng cách xâu chuỗi các lớp tăng dữ liệu, thay đổi tỷ lệ, base_model và tính năng với nhau bằng cách sử dụng API chức năng Keras . Như đã đề cập trước đây, hãy sử dụng training=False vì mô hình của chúng tôi chứa một lớp BatchNormalization .
inputs = tf.keras.Input(shape=(160, 160, 3))
x = data_augmentation(inputs)
x = preprocess_input(x)
x = base_model(x, training=False)
x = global_average_layer(x)
x = tf.keras.layers.Dropout(0.2)(x)
outputs = prediction_layer(x)
model = tf.keras.Model(inputs, outputs)
Biên dịch mô hình
Biên dịch mô hình trước khi đào tạo nó. Vì có hai lớp, hãy sử dụng mất mát tf.keras.losses.BinaryCrossentropy với from_logits=True vì mô hình cung cấp đầu ra tuyến tính.
base_learning_rate = 0.0001
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=base_learning_rate),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 160, 160, 3)] 0
sequential (Sequential) (None, 160, 160, 3) 0
tf.math.truediv (TFOpLambda (None, 160, 160, 3) 0
)
tf.math.subtract (TFOpLambd (None, 160, 160, 3) 0
a)
mobilenetv2_1.00_160 (Funct (None, 5, 5, 1280) 2257984
ional)
global_average_pooling2d (G (None, 1280) 0
lobalAveragePooling2D)
dropout (Dropout) (None, 1280) 0
dense (Dense) (None, 1) 1281
=================================================================
Total params: 2,259,265
Trainable params: 1,281
Non-trainable params: 2,257,984
_________________________________________________________________
2,5 triệu tham số trong MobileNet bị đóng băng, nhưng có 1,2 nghìn tham số có thể đào tạo trong lớp dày đặc. Chúng được phân chia giữa hai đối tượng tf.Variable , trọng lượng và độ lệch.
len(model.trainable_variables)
2
Đào tạo mô hình
Sau khi đào tạo trong 10 kỷ nguyên, bạn sẽ thấy độ chính xác ~ 94% trên bộ xác thực.
initial_epochs = 10
loss0, accuracy0 = model.evaluate(validation_dataset)
26/26 [==============================] - 2s 16ms/step - loss: 0.7428 - accuracy: 0.5186
print("initial loss: {:.2f}".format(loss0))
print("initial accuracy: {:.2f}".format(accuracy0))
initial loss: 0.74 initial accuracy: 0.52
history = model.fit(train_dataset,
epochs=initial_epochs,
validation_data=validation_dataset)
Epoch 1/10 63/63 [==============================] - 4s 23ms/step - loss: 0.6804 - accuracy: 0.5680 - val_loss: 0.4981 - val_accuracy: 0.7054 Epoch 2/10 63/63 [==============================] - 1s 22ms/step - loss: 0.5044 - accuracy: 0.7170 - val_loss: 0.3598 - val_accuracy: 0.8144 Epoch 3/10 63/63 [==============================] - 1s 21ms/step - loss: 0.4109 - accuracy: 0.7845 - val_loss: 0.2810 - val_accuracy: 0.8861 Epoch 4/10 63/63 [==============================] - 1s 21ms/step - loss: 0.3285 - accuracy: 0.8445 - val_loss: 0.2256 - val_accuracy: 0.9208 Epoch 5/10 63/63 [==============================] - 1s 21ms/step - loss: 0.3108 - accuracy: 0.8555 - val_loss: 0.1986 - val_accuracy: 0.9307 Epoch 6/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2659 - accuracy: 0.8855 - val_loss: 0.1703 - val_accuracy: 0.9418 Epoch 7/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2459 - accuracy: 0.8935 - val_loss: 0.1495 - val_accuracy: 0.9517 Epoch 8/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2315 - accuracy: 0.8950 - val_loss: 0.1454 - val_accuracy: 0.9542 Epoch 9/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2204 - accuracy: 0.9030 - val_loss: 0.1326 - val_accuracy: 0.9592 Epoch 10/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2180 - accuracy: 0.9115 - val_loss: 0.1215 - val_accuracy: 0.9604
Đường cong học tập
Chúng ta hãy xem xét các đường cong học tập về độ chính xác / mất mát của quá trình đào tạo và xác thực khi sử dụng mô hình cơ sở MobileNetV2 làm trình trích xuất tính năng cố định.
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.ylim([min(plt.ylim()),1])
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.ylim([0,1.0])
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
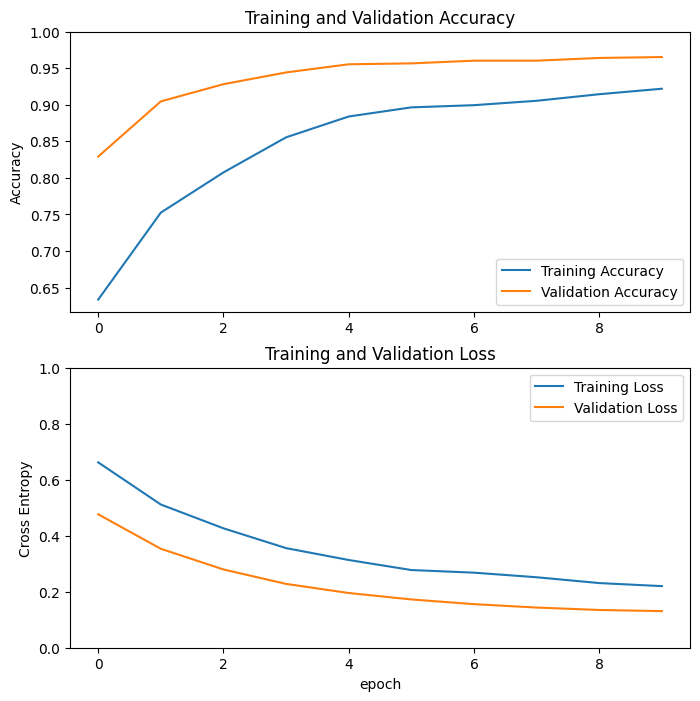
Ở mức độ thấp hơn, đó là vì các chỉ số đào tạo báo cáo mức trung bình cho một kỷ nguyên, trong khi các chỉ số xác thực được đánh giá sau kỷ nguyên đó, vì vậy các chỉ số xác thực sẽ thấy một mô hình đã được đào tạo lâu hơn một chút.
Tinh chỉnh
Trong thử nghiệm trích xuất tính năng, bạn chỉ đào tạo một vài lớp trên đầu mô hình cơ sở MobileNetV2. Trọng số của mạng được đào tạo trước không được cập nhật trong quá trình đào tạo.
Một cách để tăng hiệu suất hơn nữa là đào tạo (hoặc "tinh chỉnh") trọng số của các lớp trên cùng của mô hình được đào tạo trước cùng với việc đào tạo bộ phân loại bạn đã thêm. Quá trình đào tạo sẽ buộc các trọng số phải được điều chỉnh từ bản đồ đối tượng địa lý chung sang đối tượng địa lý được liên kết cụ thể với tập dữ liệu.
Ngoài ra, bạn nên cố gắng tinh chỉnh một số lượng nhỏ các lớp trên cùng thay vì toàn bộ mô hình MobileNet. Trong hầu hết các mạng phức hợp, lớp càng cao thì nó càng chuyên biệt. Một số lớp đầu tiên học các tính năng rất đơn giản và chung chung, khái quát cho hầu hết các loại hình ảnh. Khi bạn đi lên cao hơn, các tính năng ngày càng cụ thể hơn đối với tập dữ liệu mà mô hình được đào tạo trên đó. Mục tiêu của việc tinh chỉnh là để điều chỉnh các tính năng chuyên biệt này để hoạt động với tập dữ liệu mới, thay vì ghi đè lên cách học chung chung.
Bỏ đóng băng các lớp trên cùng của mô hình
Tất cả những gì bạn cần làm là giải base_model và đặt các lớp dưới cùng là không thể đào tạo được. Sau đó, bạn nên biên dịch lại mô hình (cần thiết để những thay đổi này có hiệu lực) và tiếp tục đào tạo.
base_model.trainable = True
# Let's take a look to see how many layers are in the base model
print("Number of layers in the base model: ", len(base_model.layers))
# Fine-tune from this layer onwards
fine_tune_at = 100
# Freeze all the layers before the `fine_tune_at` layer
for layer in base_model.layers[:fine_tune_at]:
layer.trainable = False
Number of layers in the base model: 154
Biên dịch mô hình
Khi bạn đang đào tạo một mô hình lớn hơn nhiều và muốn đọc các trọng số đã được huấn luyện trước, điều quan trọng là phải sử dụng tỷ lệ học tập thấp hơn ở giai đoạn này. Nếu không, mô hình của bạn có thể bị quá tải rất nhanh.
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer = tf.keras.optimizers.RMSprop(learning_rate=base_learning_rate/10),
metrics=['accuracy'])
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 160, 160, 3)] 0
sequential (Sequential) (None, 160, 160, 3) 0
tf.math.truediv (TFOpLambda (None, 160, 160, 3) 0
)
tf.math.subtract (TFOpLambd (None, 160, 160, 3) 0
a)
mobilenetv2_1.00_160 (Funct (None, 5, 5, 1280) 2257984
ional)
global_average_pooling2d (G (None, 1280) 0
lobalAveragePooling2D)
dropout (Dropout) (None, 1280) 0
dense (Dense) (None, 1) 1281
=================================================================
Total params: 2,259,265
Trainable params: 1,862,721
Non-trainable params: 396,544
_________________________________________________________________
len(model.trainable_variables)
56
Tiếp tục đào tạo mô hình
Nếu bạn được đào tạo để hội tụ sớm hơn, bước này sẽ cải thiện độ chính xác của bạn lên một vài điểm phần trăm.
fine_tune_epochs = 10
total_epochs = initial_epochs + fine_tune_epochs
history_fine = model.fit(train_dataset,
epochs=total_epochs,
initial_epoch=history.epoch[-1],
validation_data=validation_dataset)
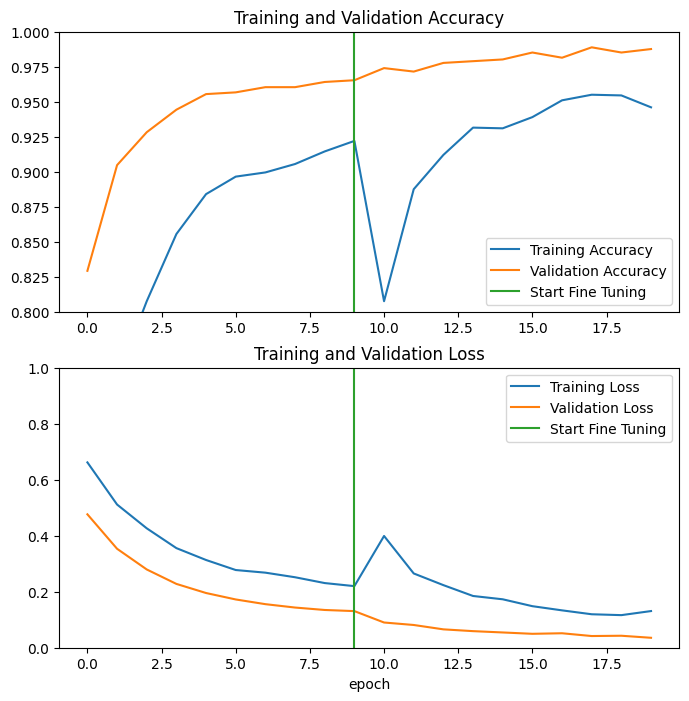
Epoch 10/20 63/63 [==============================] - 7s 40ms/step - loss: 0.1545 - accuracy: 0.9335 - val_loss: 0.0531 - val_accuracy: 0.9864 Epoch 11/20 63/63 [==============================] - 2s 28ms/step - loss: 0.1161 - accuracy: 0.9540 - val_loss: 0.0500 - val_accuracy: 0.9814 Epoch 12/20 63/63 [==============================] - 2s 28ms/step - loss: 0.1125 - accuracy: 0.9525 - val_loss: 0.0379 - val_accuracy: 0.9876 Epoch 13/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0891 - accuracy: 0.9625 - val_loss: 0.0472 - val_accuracy: 0.9889 Epoch 14/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0844 - accuracy: 0.9680 - val_loss: 0.0478 - val_accuracy: 0.9889 Epoch 15/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0857 - accuracy: 0.9645 - val_loss: 0.0354 - val_accuracy: 0.9839 Epoch 16/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0785 - accuracy: 0.9690 - val_loss: 0.0449 - val_accuracy: 0.9864 Epoch 17/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0669 - accuracy: 0.9740 - val_loss: 0.0375 - val_accuracy: 0.9839 Epoch 18/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0701 - accuracy: 0.9695 - val_loss: 0.0324 - val_accuracy: 0.9864 Epoch 19/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0636 - accuracy: 0.9760 - val_loss: 0.0465 - val_accuracy: 0.9790 Epoch 20/20 63/63 [==============================] - 2s 29ms/step - loss: 0.0585 - accuracy: 0.9765 - val_loss: 0.0392 - val_accuracy: 0.9851
Chúng ta hãy xem xét các đường cong học tập về độ chính xác / mất mát của quá trình đào tạo và xác thực khi tinh chỉnh một vài lớp cuối cùng của mô hình cơ sở MobileNetV2 và đào tạo trình phân loại trên đó. Mất xác thực cao hơn nhiều so với mất đào tạo, vì vậy bạn có thể nhận được một số trang bị quá mức.
Bạn cũng có thể nhận được một số trang bị quá mức vì tập hợp đào tạo mới tương đối nhỏ và tương tự như tập dữ liệu MobileNetV2 ban đầu.
Sau khi tinh chỉnh, mô hình gần như đạt độ chính xác 98% trên bộ xác nhận.
acc += history_fine.history['accuracy']
val_acc += history_fine.history['val_accuracy']
loss += history_fine.history['loss']
val_loss += history_fine.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.ylim([0.8, 1])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.ylim([0, 1.0])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
Đánh giá và dự đoán
Cuối cùng, bạn có thể xác minh hiệu suất của mô hình trên dữ liệu mới bằng cách sử dụng bộ thử nghiệm.
loss, accuracy = model.evaluate(test_dataset)
print('Test accuracy :', accuracy)
6/6 [==============================] - 0s 13ms/step - loss: 0.0281 - accuracy: 0.9948 Test accuracy : 0.9947916865348816
Và bây giờ bạn đã sẵn sàng sử dụng mô hình này để dự đoán xem vật nuôi của bạn là mèo hay chó.
# Retrieve a batch of images from the test set
image_batch, label_batch = test_dataset.as_numpy_iterator().next()
predictions = model.predict_on_batch(image_batch).flatten()
# Apply a sigmoid since our model returns logits
predictions = tf.nn.sigmoid(predictions)
predictions = tf.where(predictions < 0.5, 0, 1)
print('Predictions:\n', predictions.numpy())
print('Labels:\n', label_batch)
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image_batch[i].astype("uint8"))
plt.title(class_names[predictions[i]])
plt.axis("off")
Predictions: [0 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 0 0 0 1 0 1 0 0 1 1 1 0 0 0 1 0] Labels: [0 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 0 0 0 1 0 1 0 0 1 1 1 0 0 0 1 0]

Bản tóm tắt
Sử dụng mô hình được đào tạo trước để trích xuất đối tượng địa lý : Khi làm việc với một tập dữ liệu nhỏ, thông thường là tận dụng các tính năng đã học của mô hình được đào tạo trên một tập dữ liệu lớn hơn trong cùng một miền. Điều này được thực hiện bằng cách khởi tạo mô hình được đào tạo trước và thêm một bộ phân loại được kết nối đầy đủ ở trên cùng. Mô hình được đào tạo trước bị "đóng băng" và chỉ các trọng số của bộ phân loại mới được cập nhật trong quá trình đào tạo. Trong trường hợp này, cơ sở tích hợp đã trích xuất tất cả các tính năng được liên kết với mỗi hình ảnh và bạn chỉ cần đào tạo một bộ phân loại xác định lớp hình ảnh cho tập hợp các tính năng được trích xuất đó.
Tinh chỉnh mô hình được đào tạo trước : Để cải thiện hơn nữa hiệu suất, người ta có thể muốn sử dụng lại các lớp cấp cao nhất của các mô hình được đào tạo trước sang tập dữ liệu mới thông qua tinh chỉnh. Trong trường hợp này, bạn đã điều chỉnh trọng số của mình để mô hình của bạn học được các tính năng cấp cao cụ thể cho tập dữ liệu. Kỹ thuật này thường được khuyến nghị khi tập dữ liệu huấn luyện lớn và rất giống với tập dữ liệu gốc mà mô hình huấn luyện trước đã được huấn luyện.
Để tìm hiểu thêm, hãy truy cập hướng dẫn học Chuyển giao .
# MIT License
#
# Copyright (c) 2017 François Chollet # IGNORE_COPYRIGHT: cleared by OSS licensing
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.