
| | |  ดูแหล่งที่มาบน GitHub ดูแหล่งที่มาบน GitHub | |
ในบทช่วยสอนนี้ คุณจะได้เรียนรู้วิธีจำแนกรูปภาพของแมวและสุนัขโดยใช้การเรียนรู้แบบโอนย้ายจากเครือข่ายที่ผ่านการฝึกอบรมมาแล้ว
โมเดลที่ได้รับการฝึกอบรมล่วงหน้าคือเครือข่ายที่บันทึกไว้ซึ่งได้รับการฝึกอบรมมาก่อนหน้านี้ในชุดข้อมูลขนาดใหญ่ โดยทั่วไปแล้วจะเป็นการจัดประเภทรูปภาพขนาดใหญ่ คุณใช้โมเดลที่ฝึกไว้ล่วงหน้าตามที่เป็นอยู่หรือใช้การเรียนรู้แบบถ่ายโอนเพื่อปรับแต่งโมเดลนี้ให้เข้ากับงานที่กำหนด
สัญชาตญาณเบื้องหลังการเรียนรู้การถ่ายโอนสำหรับการจัดประเภทรูปภาพคือ ถ้าแบบจำลองได้รับการฝึกอบรมในชุดข้อมูลที่มีขนาดใหญ่และทั่วไปเพียงพอ โมเดลนี้จะทำหน้าที่เป็นแบบจำลองทั่วไปของโลกภาพได้อย่างมีประสิทธิภาพ จากนั้น คุณสามารถใช้ประโยชน์จากแมปคุณลักษณะที่เรียนรู้เหล่านี้ได้โดยไม่ต้องเริ่มต้นใหม่โดยการฝึกโมเดลขนาดใหญ่บนชุดข้อมูลขนาดใหญ่
ในสมุดบันทึกนี้ คุณจะลองใช้สองวิธีในการปรับแต่งแบบจำลองล่วงหน้า:
การแยกคุณลักษณะ: ใช้การแทนค่าที่เรียนรู้โดยเครือข่ายก่อนหน้านี้เพื่อดึงคุณลักษณะที่มีความหมายจากตัวอย่างใหม่ คุณเพียงแค่เพิ่มตัวแยกประเภทใหม่ ซึ่งจะได้รับการฝึกตั้งแต่เริ่มต้น ที่ด้านบนของโมเดลที่ได้รับการฝึกมาล่วงหน้า เพื่อให้คุณสามารถปรับใช้ฟีเจอร์แมปที่เรียนรู้ก่อนหน้านี้สำหรับชุดข้อมูลได้
คุณไม่จำเป็นต้อง (ซ้ำ) ฝึกโมเดลทั้งหมด เครือข่าย Convolutional พื้นฐานมีคุณลักษณะที่เป็นประโยชน์โดยทั่วไปสำหรับการจัดประเภทรูปภาพอยู่แล้ว อย่างไรก็ตาม ส่วนการจำแนกขั้นสุดท้ายของแบบจำลองสำเร็จรูปนั้นจำเพาะกับงานการจำแนกประเภทดั้งเดิม และต่อมาก็เจาะจงกับชุดของชั้นเรียนที่แบบจำลองได้รับการฝึกอบรม
การปรับละเอียด: ยกเลิกการตรึงเลเยอร์บนสุดบางชั้นของฐานโมเดลที่ตรึงไว้ และร่วมกันฝึกทั้งเลเยอร์ลักษณนามที่เพิ่มใหม่และเลเยอร์สุดท้ายของโมเดลฐาน ซึ่งช่วยให้เราสามารถ "ปรับแต่ง" การนำเสนอคุณลักษณะที่มีลำดับสูงกว่าในแบบจำลองพื้นฐาน เพื่อให้มีความเกี่ยวข้องกับงานเฉพาะมากขึ้น
คุณจะทำตามเวิร์กโฟลว์แมชชีนเลิร์นนิงทั่วไป
- ตรวจสอบและทำความเข้าใจข้อมูล
- สร้างไพพ์ไลน์อินพุต ในกรณีนี้โดยใช้ Keras ImageDataGenerator
- เขียนแบบ
- โหลดในแบบจำลองพื้นฐานที่ฝึกไว้ล่วงหน้า (และตุ้มน้ำหนักที่ฝึกไว้ล่วงหน้า)
- วางชั้นการจำแนกไว้ด้านบน
- ฝึกโมเดล
- ประเมินแบบจำลอง
import matplotlib.pyplot as plt
import numpy as np
import os
import tensorflow as tf
การประมวลผลข้อมูลล่วงหน้า
ดาวน์โหลดข้อมูล
ในบทช่วยสอนนี้ คุณจะใช้ชุดข้อมูลที่มีภาพแมวและสุนัขหลายพันภาพ ดาวน์โหลดและแตกไฟล์ zip ที่มีรูปภาพ จากนั้นสร้าง tf.data.Dataset สำหรับการฝึกอบรมและการตรวจสอบโดยใช้ยูทิลิตี้ tf.keras.utils.image_dataset_from_directory คุณสามารถเรียนรู้เพิ่มเติมเกี่ยวกับการโหลดรูปภาพในบทช่วย สอน นี้
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
path_to_zip = tf.keras.utils.get_file('cats_and_dogs.zip', origin=_URL, extract=True)
PATH = os.path.join(os.path.dirname(path_to_zip), 'cats_and_dogs_filtered')
train_dir = os.path.join(PATH, 'train')
validation_dir = os.path.join(PATH, 'validation')
BATCH_SIZE = 32
IMG_SIZE = (160, 160)
train_dataset = tf.keras.utils.image_dataset_from_directory(train_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
Downloading data from https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip 68608000/68606236 [==============================] - 1s 0us/step 68616192/68606236 [==============================] - 1s 0us/step Found 2000 files belonging to 2 classes.
validation_dataset = tf.keras.utils.image_dataset_from_directory(validation_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
Found 1000 files belonging to 2 classes.
แสดงภาพเก้าภาพแรกและป้ายกำกับจากชุดการฝึก:
class_names = train_dataset.class_names
plt.figure(figsize=(10, 10))
for images, labels in train_dataset.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")

เนื่องจากชุดข้อมูลดั้งเดิมไม่มีชุดทดสอบ คุณจะต้องสร้างชุดทดสอบขึ้นมา ในการดำเนินการดังกล่าว ให้กำหนดจำนวนชุดข้อมูลที่มีอยู่ในชุดการตรวจสอบความถูกต้องโดยใช้ tf.data.experimental.cardinality จากนั้นย้าย 20% ของข้อมูลทั้งหมดไปยังชุดทดสอบ
val_batches = tf.data.experimental.cardinality(validation_dataset)
test_dataset = validation_dataset.take(val_batches // 5)
validation_dataset = validation_dataset.skip(val_batches // 5)
print('Number of validation batches: %d' % tf.data.experimental.cardinality(validation_dataset))
print('Number of test batches: %d' % tf.data.experimental.cardinality(test_dataset))
Number of validation batches: 26 Number of test batches: 6
กำหนดค่าชุดข้อมูลสำหรับประสิทธิภาพ
ใช้การดึงข้อมูลล่วงหน้าแบบบัฟเฟอร์เพื่อโหลดอิมเมจจากดิสก์โดยที่ I/O จะไม่ถูกบล็อก หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับวิธีการนี้ โปรดดูคู่มือ ประสิทธิภาพข้อมูล
AUTOTUNE = tf.data.AUTOTUNE
train_dataset = train_dataset.prefetch(buffer_size=AUTOTUNE)
validation_dataset = validation_dataset.prefetch(buffer_size=AUTOTUNE)
test_dataset = test_dataset.prefetch(buffer_size=AUTOTUNE)
ใช้การเสริมข้อมูล
เมื่อคุณไม่มีชุดข้อมูลรูปภาพขนาดใหญ่ เป็นการดีที่จะแนะนำความหลากหลายของตัวอย่างโดยใช้การแปลงแบบสุ่มแต่เหมือนจริงกับรูปภาพการฝึก เช่น การหมุนและการพลิกแนวนอน ซึ่งช่วยให้แบบจำลองได้มองเห็นข้อมูลการฝึกอบรมในด้านต่างๆ และลด การ overfitting คุณสามารถเรียนรู้เพิ่มเติมเกี่ยวกับการเสริมข้อมูลในบทช่วย สอน นี้
data_augmentation = tf.keras.Sequential([
tf.keras.layers.RandomFlip('horizontal'),
tf.keras.layers.RandomRotation(0.2),
])
ลองใช้เลเยอร์เหล่านี้ซ้ำ ๆ กับรูปภาพเดียวกันและดูผลลัพธ์
for image, _ in train_dataset.take(1):
plt.figure(figsize=(10, 10))
first_image = image[0]
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
augmented_image = data_augmentation(tf.expand_dims(first_image, 0))
plt.imshow(augmented_image[0] / 255)
plt.axis('off')

ปรับขนาดค่าพิกเซล
อีกสักครู่ คุณจะดาวน์โหลด tf.keras.applications.MobileNetV2 เพื่อใช้เป็นโมเดลพื้นฐานของคุณ โมเดลนี้คาดหวังค่าพิกเซลใน [-1, 1] แต่ ณ จุดนี้ ค่าพิกเซลในภาพของคุณอยู่ใน [0, 255] หากต้องการปรับขนาดใหม่ ให้ใช้วิธีการประมวลผลล่วงหน้าที่มาพร้อมกับโมเดล
preprocess_input = tf.keras.applications.mobilenet_v2.preprocess_input
rescale = tf.keras.layers.Rescaling(1./127.5, offset=-1)
สร้างโมเดลพื้นฐานจากคอนเน็ตต์ที่ผ่านการฝึกอบรมมาแล้ว
คุณจะต้องสร้างโมเดลพื้นฐานจากโมเดล MobileNet V2 ที่พัฒนาโดย Google นี่เป็นการฝึกอบรมล่วงหน้าบนชุดข้อมูล ImageNet ซึ่งเป็นชุดข้อมูลขนาดใหญ่ที่ประกอบด้วยอิมเมจ 1.4M และ 1,000 คลาส ImageNet เป็นชุดข้อมูลการฝึกอบรมการวิจัยที่มีหมวดหมู่หลากหลาย เช่น jackfruit และ syringe ฐานความรู้นี้จะช่วยเราจำแนกแมวและสุนัขจากชุดข้อมูลเฉพาะของเรา
ขั้นแรก คุณต้องเลือกเลเยอร์ของ MobileNet V2 ที่คุณจะใช้สำหรับการแยกคุณลักษณะ เลเยอร์การจัดหมวดหมู่สุดท้าย (ที่ "บนสุด" เนื่องจากไดอะแกรมของโมเดลการเรียนรู้ของเครื่องส่วนใหญ่เริ่มจากล่างขึ้นบน) ไม่ค่อยมีประโยชน์ แต่คุณจะต้องปฏิบัติตามแนวทางปฏิบัติทั่วไปโดยอาศัยเลเยอร์สุดท้ายก่อนที่จะดำเนินการให้เรียบ ชั้นนี้เรียกว่า "ชั้นคอขวด" คุณสมบัติของเลเยอร์คอขวดยังคงมีลักษณะทั่วไปมากกว่าเมื่อเปรียบเทียบกับเลเยอร์สุดท้าย/บนสุด
ขั้นแรก สร้างตัวอย่างโมเดล MobileNet V2 ที่โหลดไว้ล่วงหน้าด้วยตุ้มน้ำหนักที่ฝึกบน ImageNet โดยการระบุอาร์กิวเมนต์ include_top=False คุณจะโหลดเครือข่ายที่ไม่มีเลเยอร์การจัดหมวดหมู่ที่ด้านบน ซึ่งเหมาะสำหรับการแยกคุณลักษณะ
# Create the base model from the pre-trained model MobileNet V2
IMG_SHAPE = IMG_SIZE + (3,)
base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_160_no_top.h5 9412608/9406464 [==============================] - 0s 0us/step 9420800/9406464 [==============================] - 0s 0us/step
ตัวแยกคุณลักษณะนี้จะแปลงรูปภาพ 160x160x3 แต่ละภาพเป็นบล็อกคุณลักษณะขนาด 5x5x1280 มาดูกันว่ามันทำอะไรกับชุดรูปภาพตัวอย่าง:
image_batch, label_batch = next(iter(train_dataset))
feature_batch = base_model(image_batch)
print(feature_batch.shape)
(32, 5, 5, 1280)
การแยกคุณสมบัติ
ในขั้นตอนนี้ คุณจะตรึงฐานที่บิดเบี้ยวที่สร้างขึ้นจากขั้นตอนก่อนหน้าและเพื่อใช้เป็นตัวแยกคุณลักษณะ นอกจากนี้ คุณเพิ่มตัวแยกประเภทและฝึกตัวแยกประเภทระดับบนสุด
ตรึงฐานบิด
สิ่งสำคัญคือต้องตรึงฐานที่บิดเบี้ยวก่อนที่คุณจะคอมไพล์และฝึกโมเดล การแช่แข็ง (โดยการตั้งค่า layer.trainable = False) ป้องกันไม่ให้มีการอัพเดทน้ำหนักในเลเยอร์ที่กำหนดระหว่างการฝึก MobileNet V2 มีหลายเลเยอร์ ดังนั้นการตั้งค่าแฟ trainable กที่ฝึกได้ของโมเดลทั้งหมดเป็น "เท็จ" จะทำให้เลเยอร์ทั้งหมดหยุดนิ่ง
base_model.trainable = False
หมายเหตุสำคัญเกี่ยวกับเลเยอร์ BatchNormalization
หลายรุ่นมีเลเยอร์ tf.keras.layers.BatchNormalization เลเยอร์นี้เป็นกรณีพิเศษ และควรใช้ความระมัดระวังในบริบทของการปรับแต่ง ดังที่แสดงในบทช่วยสอนนี้ในภายหลัง
เมื่อคุณตั้งค่า layer.trainable = False เลเยอร์ BatchNormalization จะทำงานในโหมดอนุมาน และจะไม่อัปเดตค่าเฉลี่ยและความแปรปรวนของสถิติ
เมื่อคุณเลิกตรึงโมเดลที่มีเลเยอร์ BatchNormalization เพื่อทำการปรับแต่งอย่างละเอียด คุณควรเก็บเลเยอร์ BatchNormalization ในโหมดอนุมานโดยผ่าน training = False เมื่อเรียกใช้โมเดลพื้นฐาน มิฉะนั้น การอัปเดตที่ใช้กับตุ้มน้ำหนักที่ไม่สามารถฝึกได้จะทำลายสิ่งที่โมเดลได้เรียนรู้
สำหรับรายละเอียดเพิ่มเติม โปรดดูที่ คู่มือการโอนย้ายการเรียนรู้
# Let's take a look at the base model architecture
base_model.summary()
Model: "mobilenetv2_1.00_160"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 160, 160, 3 0 []
)]
Conv1 (Conv2D) (None, 80, 80, 32) 864 ['input_1[0][0]']
bn_Conv1 (BatchNormalization) (None, 80, 80, 32) 128 ['Conv1[0][0]']
Conv1_relu (ReLU) (None, 80, 80, 32) 0 ['bn_Conv1[0][0]']
expanded_conv_depthwise (Depth (None, 80, 80, 32) 288 ['Conv1_relu[0][0]']
wiseConv2D)
expanded_conv_depthwise_BN (Ba (None, 80, 80, 32) 128 ['expanded_conv_depthwise[0][0]']
tchNormalization)
expanded_conv_depthwise_relu ( (None, 80, 80, 32) 0 ['expanded_conv_depthwise_BN[0][0
ReLU) ]']
expanded_conv_project (Conv2D) (None, 80, 80, 16) 512 ['expanded_conv_depthwise_relu[0]
[0]']
expanded_conv_project_BN (Batc (None, 80, 80, 16) 64 ['expanded_conv_project[0][0]']
hNormalization)
block_1_expand (Conv2D) (None, 80, 80, 96) 1536 ['expanded_conv_project_BN[0][0]'
]
block_1_expand_BN (BatchNormal (None, 80, 80, 96) 384 ['block_1_expand[0][0]']
ization)
block_1_expand_relu (ReLU) (None, 80, 80, 96) 0 ['block_1_expand_BN[0][0]']
block_1_pad (ZeroPadding2D) (None, 81, 81, 96) 0 ['block_1_expand_relu[0][0]']
block_1_depthwise (DepthwiseCo (None, 40, 40, 96) 864 ['block_1_pad[0][0]']
nv2D)
block_1_depthwise_BN (BatchNor (None, 40, 40, 96) 384 ['block_1_depthwise[0][0]']
malization)
block_1_depthwise_relu (ReLU) (None, 40, 40, 96) 0 ['block_1_depthwise_BN[0][0]']
block_1_project (Conv2D) (None, 40, 40, 24) 2304 ['block_1_depthwise_relu[0][0]']
block_1_project_BN (BatchNorma (None, 40, 40, 24) 96 ['block_1_project[0][0]']
lization)
block_2_expand (Conv2D) (None, 40, 40, 144) 3456 ['block_1_project_BN[0][0]']
block_2_expand_BN (BatchNormal (None, 40, 40, 144) 576 ['block_2_expand[0][0]']
ization)
block_2_expand_relu (ReLU) (None, 40, 40, 144) 0 ['block_2_expand_BN[0][0]']
block_2_depthwise (DepthwiseCo (None, 40, 40, 144) 1296 ['block_2_expand_relu[0][0]']
nv2D)
block_2_depthwise_BN (BatchNor (None, 40, 40, 144) 576 ['block_2_depthwise[0][0]']
malization)
block_2_depthwise_relu (ReLU) (None, 40, 40, 144) 0 ['block_2_depthwise_BN[0][0]']
block_2_project (Conv2D) (None, 40, 40, 24) 3456 ['block_2_depthwise_relu[0][0]']
block_2_project_BN (BatchNorma (None, 40, 40, 24) 96 ['block_2_project[0][0]']
lization)
block_2_add (Add) (None, 40, 40, 24) 0 ['block_1_project_BN[0][0]',
'block_2_project_BN[0][0]']
block_3_expand (Conv2D) (None, 40, 40, 144) 3456 ['block_2_add[0][0]']
block_3_expand_BN (BatchNormal (None, 40, 40, 144) 576 ['block_3_expand[0][0]']
ization)
block_3_expand_relu (ReLU) (None, 40, 40, 144) 0 ['block_3_expand_BN[0][0]']
block_3_pad (ZeroPadding2D) (None, 41, 41, 144) 0 ['block_3_expand_relu[0][0]']
block_3_depthwise (DepthwiseCo (None, 20, 20, 144) 1296 ['block_3_pad[0][0]']
nv2D)
block_3_depthwise_BN (BatchNor (None, 20, 20, 144) 576 ['block_3_depthwise[0][0]']
malization)
block_3_depthwise_relu (ReLU) (None, 20, 20, 144) 0 ['block_3_depthwise_BN[0][0]']
block_3_project (Conv2D) (None, 20, 20, 32) 4608 ['block_3_depthwise_relu[0][0]']
block_3_project_BN (BatchNorma (None, 20, 20, 32) 128 ['block_3_project[0][0]']
lization)
block_4_expand (Conv2D) (None, 20, 20, 192) 6144 ['block_3_project_BN[0][0]']
block_4_expand_BN (BatchNormal (None, 20, 20, 192) 768 ['block_4_expand[0][0]']
ization)
block_4_expand_relu (ReLU) (None, 20, 20, 192) 0 ['block_4_expand_BN[0][0]']
block_4_depthwise (DepthwiseCo (None, 20, 20, 192) 1728 ['block_4_expand_relu[0][0]']
nv2D)
block_4_depthwise_BN (BatchNor (None, 20, 20, 192) 768 ['block_4_depthwise[0][0]']
malization)
block_4_depthwise_relu (ReLU) (None, 20, 20, 192) 0 ['block_4_depthwise_BN[0][0]']
block_4_project (Conv2D) (None, 20, 20, 32) 6144 ['block_4_depthwise_relu[0][0]']
block_4_project_BN (BatchNorma (None, 20, 20, 32) 128 ['block_4_project[0][0]']
lization)
block_4_add (Add) (None, 20, 20, 32) 0 ['block_3_project_BN[0][0]',
'block_4_project_BN[0][0]']
block_5_expand (Conv2D) (None, 20, 20, 192) 6144 ['block_4_add[0][0]']
block_5_expand_BN (BatchNormal (None, 20, 20, 192) 768 ['block_5_expand[0][0]']
ization)
block_5_expand_relu (ReLU) (None, 20, 20, 192) 0 ['block_5_expand_BN[0][0]']
block_5_depthwise (DepthwiseCo (None, 20, 20, 192) 1728 ['block_5_expand_relu[0][0]']
nv2D)
block_5_depthwise_BN (BatchNor (None, 20, 20, 192) 768 ['block_5_depthwise[0][0]']
malization)
block_5_depthwise_relu (ReLU) (None, 20, 20, 192) 0 ['block_5_depthwise_BN[0][0]']
block_5_project (Conv2D) (None, 20, 20, 32) 6144 ['block_5_depthwise_relu[0][0]']
block_5_project_BN (BatchNorma (None, 20, 20, 32) 128 ['block_5_project[0][0]']
lization)
block_5_add (Add) (None, 20, 20, 32) 0 ['block_4_add[0][0]',
'block_5_project_BN[0][0]']
block_6_expand (Conv2D) (None, 20, 20, 192) 6144 ['block_5_add[0][0]']
block_6_expand_BN (BatchNormal (None, 20, 20, 192) 768 ['block_6_expand[0][0]']
ization)
block_6_expand_relu (ReLU) (None, 20, 20, 192) 0 ['block_6_expand_BN[0][0]']
block_6_pad (ZeroPadding2D) (None, 21, 21, 192) 0 ['block_6_expand_relu[0][0]']
block_6_depthwise (DepthwiseCo (None, 10, 10, 192) 1728 ['block_6_pad[0][0]']
nv2D)
block_6_depthwise_BN (BatchNor (None, 10, 10, 192) 768 ['block_6_depthwise[0][0]']
malization)
block_6_depthwise_relu (ReLU) (None, 10, 10, 192) 0 ['block_6_depthwise_BN[0][0]']
block_6_project (Conv2D) (None, 10, 10, 64) 12288 ['block_6_depthwise_relu[0][0]']
block_6_project_BN (BatchNorma (None, 10, 10, 64) 256 ['block_6_project[0][0]']
lization)
block_7_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_6_project_BN[0][0]']
block_7_expand_BN (BatchNormal (None, 10, 10, 384) 1536 ['block_7_expand[0][0]']
ization)
block_7_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_7_expand_BN[0][0]']
block_7_depthwise (DepthwiseCo (None, 10, 10, 384) 3456 ['block_7_expand_relu[0][0]']
nv2D)
block_7_depthwise_BN (BatchNor (None, 10, 10, 384) 1536 ['block_7_depthwise[0][0]']
malization)
block_7_depthwise_relu (ReLU) (None, 10, 10, 384) 0 ['block_7_depthwise_BN[0][0]']
block_7_project (Conv2D) (None, 10, 10, 64) 24576 ['block_7_depthwise_relu[0][0]']
block_7_project_BN (BatchNorma (None, 10, 10, 64) 256 ['block_7_project[0][0]']
lization)
block_7_add (Add) (None, 10, 10, 64) 0 ['block_6_project_BN[0][0]',
'block_7_project_BN[0][0]']
block_8_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_7_add[0][0]']
block_8_expand_BN (BatchNormal (None, 10, 10, 384) 1536 ['block_8_expand[0][0]']
ization)
block_8_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_8_expand_BN[0][0]']
block_8_depthwise (DepthwiseCo (None, 10, 10, 384) 3456 ['block_8_expand_relu[0][0]']
nv2D)
block_8_depthwise_BN (BatchNor (None, 10, 10, 384) 1536 ['block_8_depthwise[0][0]']
malization)
block_8_depthwise_relu (ReLU) (None, 10, 10, 384) 0 ['block_8_depthwise_BN[0][0]']
block_8_project (Conv2D) (None, 10, 10, 64) 24576 ['block_8_depthwise_relu[0][0]']
block_8_project_BN (BatchNorma (None, 10, 10, 64) 256 ['block_8_project[0][0]']
lization)
block_8_add (Add) (None, 10, 10, 64) 0 ['block_7_add[0][0]',
'block_8_project_BN[0][0]']
block_9_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_8_add[0][0]']
block_9_expand_BN (BatchNormal (None, 10, 10, 384) 1536 ['block_9_expand[0][0]']
ization)
block_9_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_9_expand_BN[0][0]']
block_9_depthwise (DepthwiseCo (None, 10, 10, 384) 3456 ['block_9_expand_relu[0][0]']
nv2D)
block_9_depthwise_BN (BatchNor (None, 10, 10, 384) 1536 ['block_9_depthwise[0][0]']
malization)
block_9_depthwise_relu (ReLU) (None, 10, 10, 384) 0 ['block_9_depthwise_BN[0][0]']
block_9_project (Conv2D) (None, 10, 10, 64) 24576 ['block_9_depthwise_relu[0][0]']
block_9_project_BN (BatchNorma (None, 10, 10, 64) 256 ['block_9_project[0][0]']
lization)
block_9_add (Add) (None, 10, 10, 64) 0 ['block_8_add[0][0]',
'block_9_project_BN[0][0]']
block_10_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_9_add[0][0]']
block_10_expand_BN (BatchNorma (None, 10, 10, 384) 1536 ['block_10_expand[0][0]']
lization)
block_10_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_10_expand_BN[0][0]']
block_10_depthwise (DepthwiseC (None, 10, 10, 384) 3456 ['block_10_expand_relu[0][0]']
onv2D)
block_10_depthwise_BN (BatchNo (None, 10, 10, 384) 1536 ['block_10_depthwise[0][0]']
rmalization)
block_10_depthwise_relu (ReLU) (None, 10, 10, 384) 0 ['block_10_depthwise_BN[0][0]']
block_10_project (Conv2D) (None, 10, 10, 96) 36864 ['block_10_depthwise_relu[0][0]']
block_10_project_BN (BatchNorm (None, 10, 10, 96) 384 ['block_10_project[0][0]']
alization)
block_11_expand (Conv2D) (None, 10, 10, 576) 55296 ['block_10_project_BN[0][0]']
block_11_expand_BN (BatchNorma (None, 10, 10, 576) 2304 ['block_11_expand[0][0]']
lization)
block_11_expand_relu (ReLU) (None, 10, 10, 576) 0 ['block_11_expand_BN[0][0]']
block_11_depthwise (DepthwiseC (None, 10, 10, 576) 5184 ['block_11_expand_relu[0][0]']
onv2D)
block_11_depthwise_BN (BatchNo (None, 10, 10, 576) 2304 ['block_11_depthwise[0][0]']
rmalization)
block_11_depthwise_relu (ReLU) (None, 10, 10, 576) 0 ['block_11_depthwise_BN[0][0]']
block_11_project (Conv2D) (None, 10, 10, 96) 55296 ['block_11_depthwise_relu[0][0]']
block_11_project_BN (BatchNorm (None, 10, 10, 96) 384 ['block_11_project[0][0]']
alization)
block_11_add (Add) (None, 10, 10, 96) 0 ['block_10_project_BN[0][0]',
'block_11_project_BN[0][0]']
block_12_expand (Conv2D) (None, 10, 10, 576) 55296 ['block_11_add[0][0]']
block_12_expand_BN (BatchNorma (None, 10, 10, 576) 2304 ['block_12_expand[0][0]']
lization)
block_12_expand_relu (ReLU) (None, 10, 10, 576) 0 ['block_12_expand_BN[0][0]']
block_12_depthwise (DepthwiseC (None, 10, 10, 576) 5184 ['block_12_expand_relu[0][0]']
onv2D)
block_12_depthwise_BN (BatchNo (None, 10, 10, 576) 2304 ['block_12_depthwise[0][0]']
rmalization)
block_12_depthwise_relu (ReLU) (None, 10, 10, 576) 0 ['block_12_depthwise_BN[0][0]']
block_12_project (Conv2D) (None, 10, 10, 96) 55296 ['block_12_depthwise_relu[0][0]']
block_12_project_BN (BatchNorm (None, 10, 10, 96) 384 ['block_12_project[0][0]']
alization)
block_12_add (Add) (None, 10, 10, 96) 0 ['block_11_add[0][0]',
'block_12_project_BN[0][0]']
block_13_expand (Conv2D) (None, 10, 10, 576) 55296 ['block_12_add[0][0]']
block_13_expand_BN (BatchNorma (None, 10, 10, 576) 2304 ['block_13_expand[0][0]']
lization)
block_13_expand_relu (ReLU) (None, 10, 10, 576) 0 ['block_13_expand_BN[0][0]']
block_13_pad (ZeroPadding2D) (None, 11, 11, 576) 0 ['block_13_expand_relu[0][0]']
block_13_depthwise (DepthwiseC (None, 5, 5, 576) 5184 ['block_13_pad[0][0]']
onv2D)
block_13_depthwise_BN (BatchNo (None, 5, 5, 576) 2304 ['block_13_depthwise[0][0]']
rmalization)
block_13_depthwise_relu (ReLU) (None, 5, 5, 576) 0 ['block_13_depthwise_BN[0][0]']
block_13_project (Conv2D) (None, 5, 5, 160) 92160 ['block_13_depthwise_relu[0][0]']
block_13_project_BN (BatchNorm (None, 5, 5, 160) 640 ['block_13_project[0][0]']
alization)
block_14_expand (Conv2D) (None, 5, 5, 960) 153600 ['block_13_project_BN[0][0]']
block_14_expand_BN (BatchNorma (None, 5, 5, 960) 3840 ['block_14_expand[0][0]']
lization)
block_14_expand_relu (ReLU) (None, 5, 5, 960) 0 ['block_14_expand_BN[0][0]']
block_14_depthwise (DepthwiseC (None, 5, 5, 960) 8640 ['block_14_expand_relu[0][0]']
onv2D)
block_14_depthwise_BN (BatchNo (None, 5, 5, 960) 3840 ['block_14_depthwise[0][0]']
rmalization)
block_14_depthwise_relu (ReLU) (None, 5, 5, 960) 0 ['block_14_depthwise_BN[0][0]']
block_14_project (Conv2D) (None, 5, 5, 160) 153600 ['block_14_depthwise_relu[0][0]']
block_14_project_BN (BatchNorm (None, 5, 5, 160) 640 ['block_14_project[0][0]']
alization)
block_14_add (Add) (None, 5, 5, 160) 0 ['block_13_project_BN[0][0]',
'block_14_project_BN[0][0]']
block_15_expand (Conv2D) (None, 5, 5, 960) 153600 ['block_14_add[0][0]']
block_15_expand_BN (BatchNorma (None, 5, 5, 960) 3840 ['block_15_expand[0][0]']
lization)
block_15_expand_relu (ReLU) (None, 5, 5, 960) 0 ['block_15_expand_BN[0][0]']
block_15_depthwise (DepthwiseC (None, 5, 5, 960) 8640 ['block_15_expand_relu[0][0]']
onv2D)
block_15_depthwise_BN (BatchNo (None, 5, 5, 960) 3840 ['block_15_depthwise[0][0]']
rmalization)
block_15_depthwise_relu (ReLU) (None, 5, 5, 960) 0 ['block_15_depthwise_BN[0][0]']
block_15_project (Conv2D) (None, 5, 5, 160) 153600 ['block_15_depthwise_relu[0][0]']
block_15_project_BN (BatchNorm (None, 5, 5, 160) 640 ['block_15_project[0][0]']
alization)
block_15_add (Add) (None, 5, 5, 160) 0 ['block_14_add[0][0]',
'block_15_project_BN[0][0]']
block_16_expand (Conv2D) (None, 5, 5, 960) 153600 ['block_15_add[0][0]']
block_16_expand_BN (BatchNorma (None, 5, 5, 960) 3840 ['block_16_expand[0][0]']
lization)
block_16_expand_relu (ReLU) (None, 5, 5, 960) 0 ['block_16_expand_BN[0][0]']
block_16_depthwise (DepthwiseC (None, 5, 5, 960) 8640 ['block_16_expand_relu[0][0]']
onv2D)
block_16_depthwise_BN (BatchNo (None, 5, 5, 960) 3840 ['block_16_depthwise[0][0]']
rmalization)
block_16_depthwise_relu (ReLU) (None, 5, 5, 960) 0 ['block_16_depthwise_BN[0][0]']
block_16_project (Conv2D) (None, 5, 5, 320) 307200 ['block_16_depthwise_relu[0][0]']
block_16_project_BN (BatchNorm (None, 5, 5, 320) 1280 ['block_16_project[0][0]']
alization)
Conv_1 (Conv2D) (None, 5, 5, 1280) 409600 ['block_16_project_BN[0][0]']
Conv_1_bn (BatchNormalization) (None, 5, 5, 1280) 5120 ['Conv_1[0][0]']
out_relu (ReLU) (None, 5, 5, 1280) 0 ['Conv_1_bn[0][0]']
==================================================================================================
Total params: 2,257,984
Trainable params: 0
Non-trainable params: 2,257,984
__________________________________________________________________________________________________
เพิ่มหัวการจัดประเภท
ในการสร้างการคาดคะเนจากกลุ่มคุณลักษณะ ให้หาค่าเฉลี่ยของตำแหน่งเชิงพื้นที่ 5x5 โดยใช้เลเยอร์ tf.keras.layers.GlobalAveragePooling2D เพื่อแปลงคุณสมบัติเป็นเวกเตอร์องค์ประกอบ 1280 เดียวต่อภาพ
global_average_layer = tf.keras.layers.GlobalAveragePooling2D()
feature_batch_average = global_average_layer(feature_batch)
print(feature_batch_average.shape)
(32, 1280)ตัวยึดตำแหน่ง23
ใช้เลเยอร์ tf.keras.layers.Dense เพื่อแปลงคุณสมบัติเหล่านี้เป็นการคาดคะเนภาพเดียวต่อภาพ คุณไม่จำเป็นต้องมีฟังก์ชันการเปิดใช้งานที่นี่ เนื่องจากการคาดการณ์นี้จะถือเป็น logit หรือค่าการทำนายแบบดิบ ตัวเลขบวกทำนายชั้น 1 ตัวเลขติดลบทำนายชั้น 0
prediction_layer = tf.keras.layers.Dense(1)
prediction_batch = prediction_layer(feature_batch_average)
print(prediction_batch.shape)
(32, 1)
สร้างโมเดลโดยเชื่อมโยงการเพิ่มข้อมูล การปรับขนาด base_model และเลเยอร์ตัวแยกคุณลักษณะโดยใช้ Keras Functional API ตามที่กล่าวไว้ก่อนหน้านี้ ให้ใช้ training=False เนื่องจากโมเดลของเรามีเลเยอร์ BatchNormalization
inputs = tf.keras.Input(shape=(160, 160, 3))
x = data_augmentation(inputs)
x = preprocess_input(x)
x = base_model(x, training=False)
x = global_average_layer(x)
x = tf.keras.layers.Dropout(0.2)(x)
outputs = prediction_layer(x)
model = tf.keras.Model(inputs, outputs)
รวบรวมโมเดล
รวบรวมโมเดลก่อนฝึก เนื่องจากมีสองคลาส ให้ใช้ tf.keras.losses.BinaryCrossentropy loss ด้วย from_logits=True เนื่องจากโมเดลจัดเตรียมเอาต์พุตเชิงเส้น
base_learning_rate = 0.0001
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=base_learning_rate),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 160, 160, 3)] 0
sequential (Sequential) (None, 160, 160, 3) 0
tf.math.truediv (TFOpLambda (None, 160, 160, 3) 0
)
tf.math.subtract (TFOpLambd (None, 160, 160, 3) 0
a)
mobilenetv2_1.00_160 (Funct (None, 5, 5, 1280) 2257984
ional)
global_average_pooling2d (G (None, 1280) 0
lobalAveragePooling2D)
dropout (Dropout) (None, 1280) 0
dense (Dense) (None, 1) 1281
=================================================================
Total params: 2,259,265
Trainable params: 1,281
Non-trainable params: 2,257,984
_________________________________________________________________
พารามิเตอร์ 2.5 ล้านรายการใน MobileNet ถูกระงับ แต่มีพารามิเตอร์ที่ฝึกได้ 1.2 พันรายการในเลเยอร์หนาแน่น สิ่งเหล่านี้ถูกแบ่งระหว่างวัตถุสอง tf.Variable คือน้ำหนักและอคติ
len(model.trainable_variables)
2
ฝึกโมเดล
หลังจากการฝึกอบรมเป็นเวลา 10 ยุค คุณควรเห็นความแม่นยำ ~94% ในชุดการตรวจสอบความถูกต้อง
initial_epochs = 10
loss0, accuracy0 = model.evaluate(validation_dataset)
26/26 [==============================] - 2s 16ms/step - loss: 0.7428 - accuracy: 0.5186
print("initial loss: {:.2f}".format(loss0))
print("initial accuracy: {:.2f}".format(accuracy0))
initial loss: 0.74 initial accuracy: 0.52
history = model.fit(train_dataset,
epochs=initial_epochs,
validation_data=validation_dataset)
Epoch 1/10 63/63 [==============================] - 4s 23ms/step - loss: 0.6804 - accuracy: 0.5680 - val_loss: 0.4981 - val_accuracy: 0.7054 Epoch 2/10 63/63 [==============================] - 1s 22ms/step - loss: 0.5044 - accuracy: 0.7170 - val_loss: 0.3598 - val_accuracy: 0.8144 Epoch 3/10 63/63 [==============================] - 1s 21ms/step - loss: 0.4109 - accuracy: 0.7845 - val_loss: 0.2810 - val_accuracy: 0.8861 Epoch 4/10 63/63 [==============================] - 1s 21ms/step - loss: 0.3285 - accuracy: 0.8445 - val_loss: 0.2256 - val_accuracy: 0.9208 Epoch 5/10 63/63 [==============================] - 1s 21ms/step - loss: 0.3108 - accuracy: 0.8555 - val_loss: 0.1986 - val_accuracy: 0.9307 Epoch 6/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2659 - accuracy: 0.8855 - val_loss: 0.1703 - val_accuracy: 0.9418 Epoch 7/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2459 - accuracy: 0.8935 - val_loss: 0.1495 - val_accuracy: 0.9517 Epoch 8/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2315 - accuracy: 0.8950 - val_loss: 0.1454 - val_accuracy: 0.9542 Epoch 9/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2204 - accuracy: 0.9030 - val_loss: 0.1326 - val_accuracy: 0.9592 Epoch 10/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2180 - accuracy: 0.9115 - val_loss: 0.1215 - val_accuracy: 0.9604
เส้นโค้งการเรียนรู้
มาดูเส้นโค้งการเรียนรู้ของการฝึกและความแม่นยำ/การสูญเสียการตรวจสอบเมื่อใช้โมเดลพื้นฐานของ MobileNetV2 เป็นตัวแยกคุณลักษณะแบบตายตัว
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.ylim([min(plt.ylim()),1])
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.ylim([0,1.0])
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
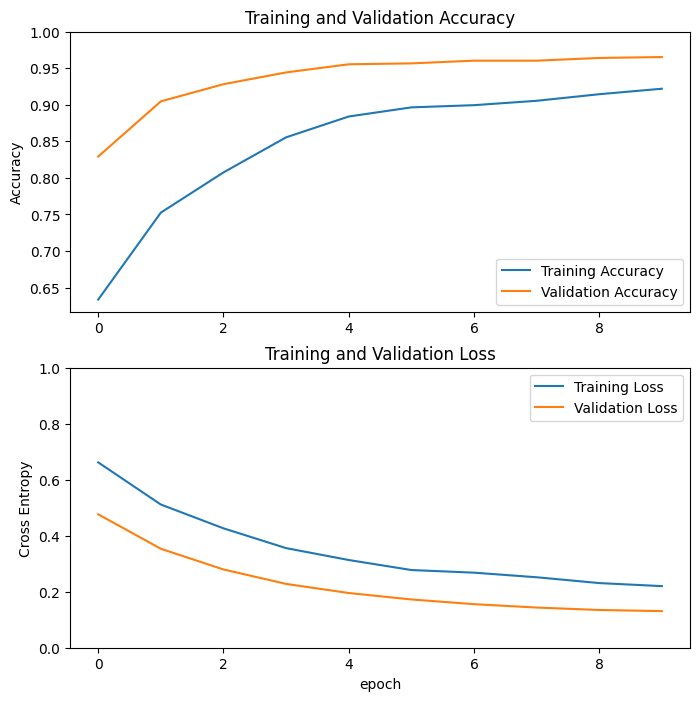
ในระดับที่น้อยกว่า เป็นเพราะตัววัดการฝึกอบรมรายงานค่าเฉลี่ยสำหรับยุคนั้น ในขณะที่ตัววัดการตรวจสอบความถูกต้องจะได้รับการประเมินหลังจากยุคนั้น ดังนั้น ตัววัดการตรวจสอบความถูกต้องจะเห็นแบบจำลองที่ได้รับการฝึกนานกว่าเล็กน้อย
ปรับจูน
ในการทดสอบการแยกคุณลักษณะ คุณฝึกเพียงไม่กี่เลเยอร์บนโมเดลพื้นฐานของ MobileNetV2 น้ำหนักของเครือข่ายที่ฝึกไว้ล่วงหน้า ไม่ได้ รับการอัพเดตระหว่างการฝึก
วิธีหนึ่งในการเพิ่มประสิทธิภาพให้ดียิ่งขึ้นไปอีกคือการฝึก (หรือ "ปรับแต่ง") ตุ้มน้ำหนักของเลเยอร์บนสุดของโมเดลที่ฝึกไว้ล่วงหน้าควบคู่ไปกับการฝึกของตัวแยกประเภทที่คุณเพิ่ม กระบวนการฝึกอบรมจะบังคับให้ปรับน้ำหนักจากแผนที่คุณลักษณะทั่วไปเป็นคุณลักษณะที่เกี่ยวข้องกับชุดข้อมูลโดยเฉพาะ
นอกจากนี้ คุณควรพยายามปรับแต่งเลเยอร์บนสุดจำนวนเล็กน้อยแทนที่จะปรับรุ่น MobileNet ทั้งหมด ในเครือข่ายแบบ Convolutional ส่วนใหญ่ ยิ่งชั้นสูงเท่าไหร่ก็ยิ่งมีความพิเศษมากขึ้นเท่านั้น เลเยอร์สองสามชั้นแรกจะเรียนรู้คุณลักษณะทั่วไปที่เรียบง่ายและทั่วถึง ซึ่งสามารถสรุปได้ทั่วไปกับรูปภาพเกือบทุกประเภท เมื่อคุณสูงขึ้น ฟีเจอร์ต่างๆ จะมีความเฉพาะเจาะจงมากขึ้นสำหรับชุดข้อมูลที่โมเดลได้รับการฝึกอบรม เป้าหมายของการปรับแต่งแบบละเอียดคือการปรับคุณลักษณะเฉพาะเหล่านี้ให้ทำงานกับชุดข้อมูลใหม่ แทนที่จะเขียนทับการเรียนรู้ทั่วไป
ยกเลิกการตรึงชั้นบนสุดของโมเดล
สิ่งที่คุณต้องทำคือยกเลิกการตรึง base_model และตั้งค่าชั้นล่างให้ไม่สามารถฝึกได้ จากนั้น คุณควรคอมไพล์โมเดลใหม่ (จำเป็นสำหรับการเปลี่ยนแปลงเหล่านี้เพื่อให้มีผล) และดำเนินการฝึกต่อ
base_model.trainable = True
# Let's take a look to see how many layers are in the base model
print("Number of layers in the base model: ", len(base_model.layers))
# Fine-tune from this layer onwards
fine_tune_at = 100
# Freeze all the layers before the `fine_tune_at` layer
for layer in base_model.layers[:fine_tune_at]:
layer.trainable = False
Number of layers in the base model: 154
รวบรวมโมเดล
ขณะที่คุณกำลังฝึกโมเดลที่ใหญ่กว่ามากและต้องการอ่านตุ้มน้ำหนักที่ฝึกไว้ล่วงหน้า สิ่งสำคัญคือต้องใช้อัตราการเรียนรู้ที่ต่ำกว่าในขั้นตอนนี้ มิฉะนั้น โมเดลของคุณอาจเกินพอดีอย่างรวดเร็ว
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer = tf.keras.optimizers.RMSprop(learning_rate=base_learning_rate/10),
metrics=['accuracy'])
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 160, 160, 3)] 0
sequential (Sequential) (None, 160, 160, 3) 0
tf.math.truediv (TFOpLambda (None, 160, 160, 3) 0
)
tf.math.subtract (TFOpLambd (None, 160, 160, 3) 0
a)
mobilenetv2_1.00_160 (Funct (None, 5, 5, 1280) 2257984
ional)
global_average_pooling2d (G (None, 1280) 0
lobalAveragePooling2D)
dropout (Dropout) (None, 1280) 0
dense (Dense) (None, 1) 1281
=================================================================
Total params: 2,259,265
Trainable params: 1,862,721
Non-trainable params: 396,544
_________________________________________________________________
len(model.trainable_variables)
56
ฝึกโมเดลต่อไป
หากคุณฝึกฝนการบรรจบกันก่อนหน้านี้ ขั้นตอนนี้จะช่วยปรับปรุงความแม่นยำของคุณสองสามเปอร์เซ็นต์
fine_tune_epochs = 10
total_epochs = initial_epochs + fine_tune_epochs
history_fine = model.fit(train_dataset,
epochs=total_epochs,
initial_epoch=history.epoch[-1],
validation_data=validation_dataset)
Epoch 10/20 63/63 [==============================] - 7s 40ms/step - loss: 0.1545 - accuracy: 0.9335 - val_loss: 0.0531 - val_accuracy: 0.9864 Epoch 11/20 63/63 [==============================] - 2s 28ms/step - loss: 0.1161 - accuracy: 0.9540 - val_loss: 0.0500 - val_accuracy: 0.9814 Epoch 12/20 63/63 [==============================] - 2s 28ms/step - loss: 0.1125 - accuracy: 0.9525 - val_loss: 0.0379 - val_accuracy: 0.9876 Epoch 13/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0891 - accuracy: 0.9625 - val_loss: 0.0472 - val_accuracy: 0.9889 Epoch 14/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0844 - accuracy: 0.9680 - val_loss: 0.0478 - val_accuracy: 0.9889 Epoch 15/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0857 - accuracy: 0.9645 - val_loss: 0.0354 - val_accuracy: 0.9839 Epoch 16/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0785 - accuracy: 0.9690 - val_loss: 0.0449 - val_accuracy: 0.9864 Epoch 17/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0669 - accuracy: 0.9740 - val_loss: 0.0375 - val_accuracy: 0.9839 Epoch 18/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0701 - accuracy: 0.9695 - val_loss: 0.0324 - val_accuracy: 0.9864 Epoch 19/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0636 - accuracy: 0.9760 - val_loss: 0.0465 - val_accuracy: 0.9790 Epoch 20/20 63/63 [==============================] - 2s 29ms/step - loss: 0.0585 - accuracy: 0.9765 - val_loss: 0.0392 - val_accuracy: 0.9851
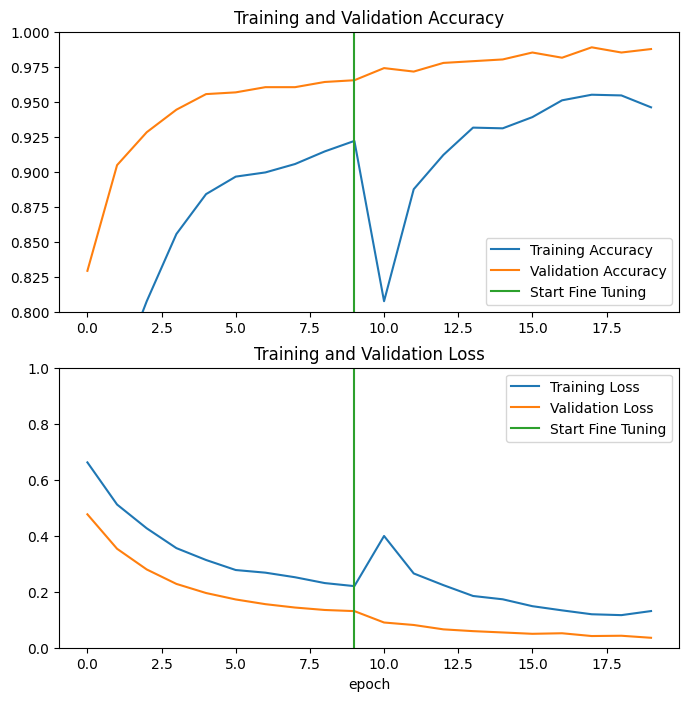
มาดูเส้นโค้งการเรียนรู้ของการฝึกและความแม่นยำ/การสูญเสียการตรวจสอบเมื่อทำการปรับแต่งสองสามเลเยอร์สุดท้ายของโมเดลพื้นฐาน MobileNetV2 และฝึกตัวแยกประเภทที่อยู่ด้านบน การสูญเสียการตรวจสอบจะสูงกว่าการสูญเสียการฝึกอบรมมาก ดังนั้นคุณอาจได้รับการฝึกฝนมากเกินไป
คุณอาจได้รับการตั้งค่ามากเกินไปเนื่องจากชุดการฝึกใหม่มีขนาดค่อนข้างเล็กและคล้ายกับชุดข้อมูล MobileNetV2 ดั้งเดิม
หลังจากปรับแต่งโมเดลอย่างละเอียดแล้ว เกือบถึงความแม่นยำถึง 98% ในชุดการตรวจสอบ
acc += history_fine.history['accuracy']
val_acc += history_fine.history['val_accuracy']
loss += history_fine.history['loss']
val_loss += history_fine.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.ylim([0.8, 1])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.ylim([0, 1.0])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
การประเมินและการทำนาย
ขั้นสุดท้ายคุณสามารถตรวจสอบประสิทธิภาพของแบบจำลองกับข้อมูลใหม่ได้โดยใช้ชุดทดสอบ
loss, accuracy = model.evaluate(test_dataset)
print('Test accuracy :', accuracy)
6/6 [==============================] - 0s 13ms/step - loss: 0.0281 - accuracy: 0.9948 Test accuracy : 0.9947916865348816ตัวยึดตำแหน่ง52
และตอนนี้คุณก็พร้อมแล้วที่จะใช้โมเดลนี้ในการทำนายว่าสัตว์เลี้ยงของคุณคือแมวหรือสุนัข
# Retrieve a batch of images from the test set
image_batch, label_batch = test_dataset.as_numpy_iterator().next()
predictions = model.predict_on_batch(image_batch).flatten()
# Apply a sigmoid since our model returns logits
predictions = tf.nn.sigmoid(predictions)
predictions = tf.where(predictions < 0.5, 0, 1)
print('Predictions:\n', predictions.numpy())
print('Labels:\n', label_batch)
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image_batch[i].astype("uint8"))
plt.title(class_names[predictions[i]])
plt.axis("off")
Predictions: [0 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 0 0 0 1 0 1 0 0 1 1 1 0 0 0 1 0] Labels: [0 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 0 0 0 1 0 1 0 0 1 1 1 0 0 0 1 0]

สรุป
การใช้โมเดลที่ฝึกไว้ล่วงหน้าสำหรับการดึงข้อมูลคุณลักษณะ : เมื่อทำงานกับชุดข้อมูลขนาดเล็ก เป็นเรื่องปกติที่จะใช้ประโยชน์จากคุณลักษณะที่เรียนรู้โดยโมเดลที่ได้รับการฝึกฝนบนชุดข้อมูลขนาดใหญ่กว่าในโดเมนเดียวกัน ซึ่งทำได้โดยการสร้างอินสแตนซ์ของโมเดลที่ฝึกอบรมไว้ล่วงหน้าและเพิ่มตัวแยกประเภทที่เชื่อมต่ออย่างสมบูรณ์ที่ด้านบน โมเดลที่ฝึกไว้ล่วงหน้านั้น "หยุดนิ่ง" และเฉพาะตุ้มน้ำหนักของลักษณนามเท่านั้นที่จะได้รับการอัปเดตระหว่างการฝึก ในกรณีนี้ Convolutional Base จะแยกคุณลักษณะทั้งหมดที่เกี่ยวข้องกับแต่ละภาพ และคุณเพิ่งฝึกตัวแยกประเภทที่กำหนดคลาสของรูปภาพตามชุดของคุณลักษณะที่แยกออกมานั้น
การปรับแต่งโมเดลที่ฝึกไว้ล่วงหน้าอย่างละเอียด : เพื่อปรับปรุงประสิทธิภาพเพิ่มเติม เราอาจต้องการปรับเปลี่ยนเลเยอร์ระดับบนสุดของโมเดลที่ได้รับการฝึกอบรมล่วงหน้าไปยังชุดข้อมูลใหม่ผ่านการปรับแต่งแบบละเอียด ในกรณีนี้ คุณปรับตุ้มน้ำหนักของคุณเพื่อให้โมเดลเรียนรู้คุณลักษณะระดับสูงเฉพาะสำหรับชุดข้อมูล เทคนิคนี้มักจะแนะนำเมื่อชุดข้อมูลการฝึกมีขนาดใหญ่และคล้ายกันมากกับชุดข้อมูลดั้งเดิมที่มีการฝึกแบบจำลองล่วงหน้า
หากต้องการเรียนรู้เพิ่มเติม โปรดไปที่ คู่มือการโอนย้ายการเรียนรู้
# MIT License
#
# Copyright (c) 2017 François Chollet # IGNORE_COPYRIGHT: cleared by OSS licensing
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.