
| | |  Visualizza l'origine su GitHub Visualizza l'origine su GitHub | |
In questo tutorial imparerai come classificare le immagini di cani e gatti utilizzando il transfer learning da una rete pre-addestrata.
Un modello pre-addestrato è una rete salvata che è stata precedentemente addestrata su un set di dati di grandi dimensioni, in genere su un'attività di classificazione delle immagini su larga scala. Puoi utilizzare il modello preaddestrato così com'è o utilizzare l'apprendimento del trasferimento per personalizzare questo modello per una determinata attività.
L'intuizione alla base dell'apprendimento del trasferimento per la classificazione delle immagini è che se un modello viene addestrato su un set di dati sufficientemente ampio e generale, questo modello fungerà effettivamente da modello generico del mondo visivo. È quindi possibile sfruttare queste mappe delle funzionalità apprese senza dover iniziare da zero addestrando un modello di grandi dimensioni su un set di dati di grandi dimensioni.
In questo quaderno proverai due modi per personalizzare un modello preaddestrato:
Estrazione delle funzionalità: utilizza le rappresentazioni apprese da una rete precedente per estrarre funzionalità significative da nuovi campioni. Aggiungi semplicemente un nuovo classificatore, che verrà addestrato da zero, in cima al modello preaddestrato in modo da poter riutilizzare le mappe delle caratteristiche apprese in precedenza per il set di dati.
Non è necessario (ri)addestrare l'intero modello. La rete convoluzionale di base contiene già caratteristiche che sono generalmente utili per classificare le immagini. Tuttavia, la parte finale della classificazione del modello preaddestrato è specifica per l'attività di classificazione originale e successivamente specifica per l'insieme di classi su cui il modello è stato addestrato.
Messa a punto: sblocca alcuni degli strati superiori di una base del modello congelata e allena insieme sia i livelli di classificazione appena aggiunti che gli ultimi livelli del modello base. Ciò ci consente di "mettere a punto" le rappresentazioni delle caratteristiche di ordine superiore nel modello di base per renderle più pertinenti per l'attività specifica.
Seguirai il flusso di lavoro generale di machine learning.
- Esaminare e comprendere i dati
- Crea una pipeline di input, in questo caso usando Keras ImageDataGenerator
- Componi il modello
- Carico nel modello base preaddestrato (e pesi preaddestrati)
- Impila i livelli di classificazione in cima
- Allena il modello
- Valuta il modello
import matplotlib.pyplot as plt
import numpy as np
import os
import tensorflow as tf
Preelaborazione dei dati
Download dei dati
In questo tutorial utilizzerai un set di dati contenente diverse migliaia di immagini di cani e gatti. Scarica ed estrai un file zip contenente le immagini, quindi crea un tf.data.Dataset per l'addestramento e la convalida utilizzando l'utilità tf.keras.utils.image_dataset_from_directory . Puoi saperne di più sul caricamento delle immagini in questo tutorial .
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
path_to_zip = tf.keras.utils.get_file('cats_and_dogs.zip', origin=_URL, extract=True)
PATH = os.path.join(os.path.dirname(path_to_zip), 'cats_and_dogs_filtered')
train_dir = os.path.join(PATH, 'train')
validation_dir = os.path.join(PATH, 'validation')
BATCH_SIZE = 32
IMG_SIZE = (160, 160)
train_dataset = tf.keras.utils.image_dataset_from_directory(train_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
Downloading data from https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip 68608000/68606236 [==============================] - 1s 0us/step 68616192/68606236 [==============================] - 1s 0us/step Found 2000 files belonging to 2 classes.
validation_dataset = tf.keras.utils.image_dataset_from_directory(validation_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
Found 1000 files belonging to 2 classes.
Mostra le prime nove immagini ed etichette del set di formazione:
class_names = train_dataset.class_names
plt.figure(figsize=(10, 10))
for images, labels in train_dataset.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")

Poiché il set di dati originale non contiene un set di test, ne creerai uno. Per fare ciò, determina quanti batch di dati sono disponibili nel set di convalida utilizzando tf.data.experimental.cardinality , quindi sposta il 20% di essi in un set di test.
val_batches = tf.data.experimental.cardinality(validation_dataset)
test_dataset = validation_dataset.take(val_batches // 5)
validation_dataset = validation_dataset.skip(val_batches // 5)
print('Number of validation batches: %d' % tf.data.experimental.cardinality(validation_dataset))
print('Number of test batches: %d' % tf.data.experimental.cardinality(test_dataset))
Number of validation batches: 26 Number of test batches: 6
Configura il set di dati per le prestazioni
Utilizzare il precaricamento con buffer per caricare le immagini dal disco senza che l'I/O si blocchi. Per ulteriori informazioni su questo metodo, vedere la guida alle prestazioni dei dati .
AUTOTUNE = tf.data.AUTOTUNE
train_dataset = train_dataset.prefetch(buffer_size=AUTOTUNE)
validation_dataset = validation_dataset.prefetch(buffer_size=AUTOTUNE)
test_dataset = test_dataset.prefetch(buffer_size=AUTOTUNE)
Usa l'aumento dei dati
Quando non si dispone di un set di dati di immagini di grandi dimensioni, è consigliabile introdurre artificialmente la diversità del campione applicando trasformazioni casuali, ma realistiche, alle immagini di addestramento, ad esempio rotazione e capovolgimento orizzontale. Ciò consente di esporre il modello a diversi aspetti dei dati di addestramento e di ridurre l' overfitting . Puoi saperne di più sull'aumento dei dati in questo tutorial .
data_augmentation = tf.keras.Sequential([
tf.keras.layers.RandomFlip('horizontal'),
tf.keras.layers.RandomRotation(0.2),
])
Applichiamo ripetutamente questi livelli alla stessa immagine e vediamo il risultato.
for image, _ in train_dataset.take(1):
plt.figure(figsize=(10, 10))
first_image = image[0]
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
augmented_image = data_augmentation(tf.expand_dims(first_image, 0))
plt.imshow(augmented_image[0] / 255)
plt.axis('off')

Ridimensiona i valori dei pixel
In un attimo scaricherai tf.keras.applications.MobileNetV2 per usarlo come modello base. Questo modello prevede valori di pixel in [-1, 1] , ma a questo punto i valori di pixel nelle tue immagini sono in [0, 255] . Per ridimensionarli, utilizzare il metodo di preelaborazione incluso nel modello.
preprocess_input = tf.keras.applications.mobilenet_v2.preprocess_input
rescale = tf.keras.layers.Rescaling(1./127.5, offset=-1)
Crea il modello base dalle convnet pre-addestrate
Creerai il modello base dal modello MobileNet V2 sviluppato da Google. Questo è pre-addestrato sul set di dati ImageNet, un set di dati di grandi dimensioni composto da 1,4 milioni di immagini e 1000 classi. ImageNet è un set di dati di formazione alla ricerca con un'ampia varietà di categorie come jackfruit e syringe . Questa base di conoscenze ci aiuterà a classificare cani e gatti dal nostro set di dati specifico.
Innanzitutto, devi scegliere quale livello di MobileNet V2 utilizzerai per l'estrazione delle funzionalità. L'ultimo livello di classificazione (in "alto", poiché la maggior parte dei diagrammi dei modelli di apprendimento automatico va dal basso verso l'alto) non è molto utile. Invece, seguirai la pratica comune di dipendere dall'ultimo strato prima dell'operazione di appiattimento. Questo strato è chiamato "strato collo di bottiglia". Le caratteristiche dello strato collo di bottiglia mantengono una maggiore generalità rispetto allo strato finale/superiore.
Innanzitutto, crea un'istanza di un modello MobileNet V2 precaricato con pesi addestrati su ImageNet. Specificando l'argomento include_top=False , carichi una rete che non include i livelli di classificazione nella parte superiore, il che è l'ideale per l'estrazione di funzionalità.
# Create the base model from the pre-trained model MobileNet V2
IMG_SHAPE = IMG_SIZE + (3,)
base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_160_no_top.h5 9412608/9406464 [==============================] - 0s 0us/step 9420800/9406464 [==============================] - 0s 0us/step
Questo estrattore di funzionalità converte ogni immagine 160x160x3 in un blocco di funzionalità 5x5x1280 . Vediamo cosa fa a un batch di immagini di esempio:
image_batch, label_batch = next(iter(train_dataset))
feature_batch = base_model(image_batch)
print(feature_batch.shape)
(32, 5, 5, 1280)
Estrazione delle caratteristiche
In questo passaggio, congelerai la base convoluzionale creata dal passaggio precedente e la utilizzerai come estrattore di funzionalità. Inoltre, aggiungi un classificatore sopra di esso e addestra il classificatore di livello superiore.
Congela la base convoluzionale
È importante bloccare la base convoluzionale prima di compilare e addestrare il modello. Il congelamento (impostando layer.trainable = False) impedisce l'aggiornamento dei pesi in un determinato livello durante l'allenamento. trainable V2 ha molti livelli, quindi l'impostazione del flag addestrabile dell'intero modello su False li bloccherà tutti.
base_model.trainable = False
Nota importante sui livelli di Normalizzazione in batch
Molti modelli contengono livelli tf.keras.layers.BatchNormalization . Questo livello è un caso speciale e le precauzioni dovrebbero essere prese nel contesto della messa a punto, come mostrato più avanti in questo tutorial.
Quando si imposta layer.trainable = False , il livello BatchNormalization verrà eseguito in modalità di inferenza e non aggiornerà le statistiche di media e varianza.
Quando sblocchi un modello che contiene livelli BatchNormalization per eseguire la messa a punto, dovresti mantenere i livelli BatchNormalization in modalità di inferenza passando training = False quando si chiama il modello di base. In caso contrario, gli aggiornamenti applicati ai pesi non addestrabili distruggeranno ciò che il modello ha appreso.
Per maggiori dettagli, consulta la guida all'apprendimento Trasferimento .
# Let's take a look at the base model architecture
base_model.summary()
Model: "mobilenetv2_1.00_160"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 160, 160, 3 0 []
)]
Conv1 (Conv2D) (None, 80, 80, 32) 864 ['input_1[0][0]']
bn_Conv1 (BatchNormalization) (None, 80, 80, 32) 128 ['Conv1[0][0]']
Conv1_relu (ReLU) (None, 80, 80, 32) 0 ['bn_Conv1[0][0]']
expanded_conv_depthwise (Depth (None, 80, 80, 32) 288 ['Conv1_relu[0][0]']
wiseConv2D)
expanded_conv_depthwise_BN (Ba (None, 80, 80, 32) 128 ['expanded_conv_depthwise[0][0]']
tchNormalization)
expanded_conv_depthwise_relu ( (None, 80, 80, 32) 0 ['expanded_conv_depthwise_BN[0][0
ReLU) ]']
expanded_conv_project (Conv2D) (None, 80, 80, 16) 512 ['expanded_conv_depthwise_relu[0]
[0]']
expanded_conv_project_BN (Batc (None, 80, 80, 16) 64 ['expanded_conv_project[0][0]']
hNormalization)
block_1_expand (Conv2D) (None, 80, 80, 96) 1536 ['expanded_conv_project_BN[0][0]'
]
block_1_expand_BN (BatchNormal (None, 80, 80, 96) 384 ['block_1_expand[0][0]']
ization)
block_1_expand_relu (ReLU) (None, 80, 80, 96) 0 ['block_1_expand_BN[0][0]']
block_1_pad (ZeroPadding2D) (None, 81, 81, 96) 0 ['block_1_expand_relu[0][0]']
block_1_depthwise (DepthwiseCo (None, 40, 40, 96) 864 ['block_1_pad[0][0]']
nv2D)
block_1_depthwise_BN (BatchNor (None, 40, 40, 96) 384 ['block_1_depthwise[0][0]']
malization)
block_1_depthwise_relu (ReLU) (None, 40, 40, 96) 0 ['block_1_depthwise_BN[0][0]']
block_1_project (Conv2D) (None, 40, 40, 24) 2304 ['block_1_depthwise_relu[0][0]']
block_1_project_BN (BatchNorma (None, 40, 40, 24) 96 ['block_1_project[0][0]']
lization)
block_2_expand (Conv2D) (None, 40, 40, 144) 3456 ['block_1_project_BN[0][0]']
block_2_expand_BN (BatchNormal (None, 40, 40, 144) 576 ['block_2_expand[0][0]']
ization)
block_2_expand_relu (ReLU) (None, 40, 40, 144) 0 ['block_2_expand_BN[0][0]']
block_2_depthwise (DepthwiseCo (None, 40, 40, 144) 1296 ['block_2_expand_relu[0][0]']
nv2D)
block_2_depthwise_BN (BatchNor (None, 40, 40, 144) 576 ['block_2_depthwise[0][0]']
malization)
block_2_depthwise_relu (ReLU) (None, 40, 40, 144) 0 ['block_2_depthwise_BN[0][0]']
block_2_project (Conv2D) (None, 40, 40, 24) 3456 ['block_2_depthwise_relu[0][0]']
block_2_project_BN (BatchNorma (None, 40, 40, 24) 96 ['block_2_project[0][0]']
lization)
block_2_add (Add) (None, 40, 40, 24) 0 ['block_1_project_BN[0][0]',
'block_2_project_BN[0][0]']
block_3_expand (Conv2D) (None, 40, 40, 144) 3456 ['block_2_add[0][0]']
block_3_expand_BN (BatchNormal (None, 40, 40, 144) 576 ['block_3_expand[0][0]']
ization)
block_3_expand_relu (ReLU) (None, 40, 40, 144) 0 ['block_3_expand_BN[0][0]']
block_3_pad (ZeroPadding2D) (None, 41, 41, 144) 0 ['block_3_expand_relu[0][0]']
block_3_depthwise (DepthwiseCo (None, 20, 20, 144) 1296 ['block_3_pad[0][0]']
nv2D)
block_3_depthwise_BN (BatchNor (None, 20, 20, 144) 576 ['block_3_depthwise[0][0]']
malization)
block_3_depthwise_relu (ReLU) (None, 20, 20, 144) 0 ['block_3_depthwise_BN[0][0]']
block_3_project (Conv2D) (None, 20, 20, 32) 4608 ['block_3_depthwise_relu[0][0]']
block_3_project_BN (BatchNorma (None, 20, 20, 32) 128 ['block_3_project[0][0]']
lization)
block_4_expand (Conv2D) (None, 20, 20, 192) 6144 ['block_3_project_BN[0][0]']
block_4_expand_BN (BatchNormal (None, 20, 20, 192) 768 ['block_4_expand[0][0]']
ization)
block_4_expand_relu (ReLU) (None, 20, 20, 192) 0 ['block_4_expand_BN[0][0]']
block_4_depthwise (DepthwiseCo (None, 20, 20, 192) 1728 ['block_4_expand_relu[0][0]']
nv2D)
block_4_depthwise_BN (BatchNor (None, 20, 20, 192) 768 ['block_4_depthwise[0][0]']
malization)
block_4_depthwise_relu (ReLU) (None, 20, 20, 192) 0 ['block_4_depthwise_BN[0][0]']
block_4_project (Conv2D) (None, 20, 20, 32) 6144 ['block_4_depthwise_relu[0][0]']
block_4_project_BN (BatchNorma (None, 20, 20, 32) 128 ['block_4_project[0][0]']
lization)
block_4_add (Add) (None, 20, 20, 32) 0 ['block_3_project_BN[0][0]',
'block_4_project_BN[0][0]']
block_5_expand (Conv2D) (None, 20, 20, 192) 6144 ['block_4_add[0][0]']
block_5_expand_BN (BatchNormal (None, 20, 20, 192) 768 ['block_5_expand[0][0]']
ization)
block_5_expand_relu (ReLU) (None, 20, 20, 192) 0 ['block_5_expand_BN[0][0]']
block_5_depthwise (DepthwiseCo (None, 20, 20, 192) 1728 ['block_5_expand_relu[0][0]']
nv2D)
block_5_depthwise_BN (BatchNor (None, 20, 20, 192) 768 ['block_5_depthwise[0][0]']
malization)
block_5_depthwise_relu (ReLU) (None, 20, 20, 192) 0 ['block_5_depthwise_BN[0][0]']
block_5_project (Conv2D) (None, 20, 20, 32) 6144 ['block_5_depthwise_relu[0][0]']
block_5_project_BN (BatchNorma (None, 20, 20, 32) 128 ['block_5_project[0][0]']
lization)
block_5_add (Add) (None, 20, 20, 32) 0 ['block_4_add[0][0]',
'block_5_project_BN[0][0]']
block_6_expand (Conv2D) (None, 20, 20, 192) 6144 ['block_5_add[0][0]']
block_6_expand_BN (BatchNormal (None, 20, 20, 192) 768 ['block_6_expand[0][0]']
ization)
block_6_expand_relu (ReLU) (None, 20, 20, 192) 0 ['block_6_expand_BN[0][0]']
block_6_pad (ZeroPadding2D) (None, 21, 21, 192) 0 ['block_6_expand_relu[0][0]']
block_6_depthwise (DepthwiseCo (None, 10, 10, 192) 1728 ['block_6_pad[0][0]']
nv2D)
block_6_depthwise_BN (BatchNor (None, 10, 10, 192) 768 ['block_6_depthwise[0][0]']
malization)
block_6_depthwise_relu (ReLU) (None, 10, 10, 192) 0 ['block_6_depthwise_BN[0][0]']
block_6_project (Conv2D) (None, 10, 10, 64) 12288 ['block_6_depthwise_relu[0][0]']
block_6_project_BN (BatchNorma (None, 10, 10, 64) 256 ['block_6_project[0][0]']
lization)
block_7_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_6_project_BN[0][0]']
block_7_expand_BN (BatchNormal (None, 10, 10, 384) 1536 ['block_7_expand[0][0]']
ization)
block_7_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_7_expand_BN[0][0]']
block_7_depthwise (DepthwiseCo (None, 10, 10, 384) 3456 ['block_7_expand_relu[0][0]']
nv2D)
block_7_depthwise_BN (BatchNor (None, 10, 10, 384) 1536 ['block_7_depthwise[0][0]']
malization)
block_7_depthwise_relu (ReLU) (None, 10, 10, 384) 0 ['block_7_depthwise_BN[0][0]']
block_7_project (Conv2D) (None, 10, 10, 64) 24576 ['block_7_depthwise_relu[0][0]']
block_7_project_BN (BatchNorma (None, 10, 10, 64) 256 ['block_7_project[0][0]']
lization)
block_7_add (Add) (None, 10, 10, 64) 0 ['block_6_project_BN[0][0]',
'block_7_project_BN[0][0]']
block_8_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_7_add[0][0]']
block_8_expand_BN (BatchNormal (None, 10, 10, 384) 1536 ['block_8_expand[0][0]']
ization)
block_8_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_8_expand_BN[0][0]']
block_8_depthwise (DepthwiseCo (None, 10, 10, 384) 3456 ['block_8_expand_relu[0][0]']
nv2D)
block_8_depthwise_BN (BatchNor (None, 10, 10, 384) 1536 ['block_8_depthwise[0][0]']
malization)
block_8_depthwise_relu (ReLU) (None, 10, 10, 384) 0 ['block_8_depthwise_BN[0][0]']
block_8_project (Conv2D) (None, 10, 10, 64) 24576 ['block_8_depthwise_relu[0][0]']
block_8_project_BN (BatchNorma (None, 10, 10, 64) 256 ['block_8_project[0][0]']
lization)
block_8_add (Add) (None, 10, 10, 64) 0 ['block_7_add[0][0]',
'block_8_project_BN[0][0]']
block_9_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_8_add[0][0]']
block_9_expand_BN (BatchNormal (None, 10, 10, 384) 1536 ['block_9_expand[0][0]']
ization)
block_9_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_9_expand_BN[0][0]']
block_9_depthwise (DepthwiseCo (None, 10, 10, 384) 3456 ['block_9_expand_relu[0][0]']
nv2D)
block_9_depthwise_BN (BatchNor (None, 10, 10, 384) 1536 ['block_9_depthwise[0][0]']
malization)
block_9_depthwise_relu (ReLU) (None, 10, 10, 384) 0 ['block_9_depthwise_BN[0][0]']
block_9_project (Conv2D) (None, 10, 10, 64) 24576 ['block_9_depthwise_relu[0][0]']
block_9_project_BN (BatchNorma (None, 10, 10, 64) 256 ['block_9_project[0][0]']
lization)
block_9_add (Add) (None, 10, 10, 64) 0 ['block_8_add[0][0]',
'block_9_project_BN[0][0]']
block_10_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_9_add[0][0]']
block_10_expand_BN (BatchNorma (None, 10, 10, 384) 1536 ['block_10_expand[0][0]']
lization)
block_10_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_10_expand_BN[0][0]']
block_10_depthwise (DepthwiseC (None, 10, 10, 384) 3456 ['block_10_expand_relu[0][0]']
onv2D)
block_10_depthwise_BN (BatchNo (None, 10, 10, 384) 1536 ['block_10_depthwise[0][0]']
rmalization)
block_10_depthwise_relu (ReLU) (None, 10, 10, 384) 0 ['block_10_depthwise_BN[0][0]']
block_10_project (Conv2D) (None, 10, 10, 96) 36864 ['block_10_depthwise_relu[0][0]']
block_10_project_BN (BatchNorm (None, 10, 10, 96) 384 ['block_10_project[0][0]']
alization)
block_11_expand (Conv2D) (None, 10, 10, 576) 55296 ['block_10_project_BN[0][0]']
block_11_expand_BN (BatchNorma (None, 10, 10, 576) 2304 ['block_11_expand[0][0]']
lization)
block_11_expand_relu (ReLU) (None, 10, 10, 576) 0 ['block_11_expand_BN[0][0]']
block_11_depthwise (DepthwiseC (None, 10, 10, 576) 5184 ['block_11_expand_relu[0][0]']
onv2D)
block_11_depthwise_BN (BatchNo (None, 10, 10, 576) 2304 ['block_11_depthwise[0][0]']
rmalization)
block_11_depthwise_relu (ReLU) (None, 10, 10, 576) 0 ['block_11_depthwise_BN[0][0]']
block_11_project (Conv2D) (None, 10, 10, 96) 55296 ['block_11_depthwise_relu[0][0]']
block_11_project_BN (BatchNorm (None, 10, 10, 96) 384 ['block_11_project[0][0]']
alization)
block_11_add (Add) (None, 10, 10, 96) 0 ['block_10_project_BN[0][0]',
'block_11_project_BN[0][0]']
block_12_expand (Conv2D) (None, 10, 10, 576) 55296 ['block_11_add[0][0]']
block_12_expand_BN (BatchNorma (None, 10, 10, 576) 2304 ['block_12_expand[0][0]']
lization)
block_12_expand_relu (ReLU) (None, 10, 10, 576) 0 ['block_12_expand_BN[0][0]']
block_12_depthwise (DepthwiseC (None, 10, 10, 576) 5184 ['block_12_expand_relu[0][0]']
onv2D)
block_12_depthwise_BN (BatchNo (None, 10, 10, 576) 2304 ['block_12_depthwise[0][0]']
rmalization)
block_12_depthwise_relu (ReLU) (None, 10, 10, 576) 0 ['block_12_depthwise_BN[0][0]']
block_12_project (Conv2D) (None, 10, 10, 96) 55296 ['block_12_depthwise_relu[0][0]']
block_12_project_BN (BatchNorm (None, 10, 10, 96) 384 ['block_12_project[0][0]']
alization)
block_12_add (Add) (None, 10, 10, 96) 0 ['block_11_add[0][0]',
'block_12_project_BN[0][0]']
block_13_expand (Conv2D) (None, 10, 10, 576) 55296 ['block_12_add[0][0]']
block_13_expand_BN (BatchNorma (None, 10, 10, 576) 2304 ['block_13_expand[0][0]']
lization)
block_13_expand_relu (ReLU) (None, 10, 10, 576) 0 ['block_13_expand_BN[0][0]']
block_13_pad (ZeroPadding2D) (None, 11, 11, 576) 0 ['block_13_expand_relu[0][0]']
block_13_depthwise (DepthwiseC (None, 5, 5, 576) 5184 ['block_13_pad[0][0]']
onv2D)
block_13_depthwise_BN (BatchNo (None, 5, 5, 576) 2304 ['block_13_depthwise[0][0]']
rmalization)
block_13_depthwise_relu (ReLU) (None, 5, 5, 576) 0 ['block_13_depthwise_BN[0][0]']
block_13_project (Conv2D) (None, 5, 5, 160) 92160 ['block_13_depthwise_relu[0][0]']
block_13_project_BN (BatchNorm (None, 5, 5, 160) 640 ['block_13_project[0][0]']
alization)
block_14_expand (Conv2D) (None, 5, 5, 960) 153600 ['block_13_project_BN[0][0]']
block_14_expand_BN (BatchNorma (None, 5, 5, 960) 3840 ['block_14_expand[0][0]']
lization)
block_14_expand_relu (ReLU) (None, 5, 5, 960) 0 ['block_14_expand_BN[0][0]']
block_14_depthwise (DepthwiseC (None, 5, 5, 960) 8640 ['block_14_expand_relu[0][0]']
onv2D)
block_14_depthwise_BN (BatchNo (None, 5, 5, 960) 3840 ['block_14_depthwise[0][0]']
rmalization)
block_14_depthwise_relu (ReLU) (None, 5, 5, 960) 0 ['block_14_depthwise_BN[0][0]']
block_14_project (Conv2D) (None, 5, 5, 160) 153600 ['block_14_depthwise_relu[0][0]']
block_14_project_BN (BatchNorm (None, 5, 5, 160) 640 ['block_14_project[0][0]']
alization)
block_14_add (Add) (None, 5, 5, 160) 0 ['block_13_project_BN[0][0]',
'block_14_project_BN[0][0]']
block_15_expand (Conv2D) (None, 5, 5, 960) 153600 ['block_14_add[0][0]']
block_15_expand_BN (BatchNorma (None, 5, 5, 960) 3840 ['block_15_expand[0][0]']
lization)
block_15_expand_relu (ReLU) (None, 5, 5, 960) 0 ['block_15_expand_BN[0][0]']
block_15_depthwise (DepthwiseC (None, 5, 5, 960) 8640 ['block_15_expand_relu[0][0]']
onv2D)
block_15_depthwise_BN (BatchNo (None, 5, 5, 960) 3840 ['block_15_depthwise[0][0]']
rmalization)
block_15_depthwise_relu (ReLU) (None, 5, 5, 960) 0 ['block_15_depthwise_BN[0][0]']
block_15_project (Conv2D) (None, 5, 5, 160) 153600 ['block_15_depthwise_relu[0][0]']
block_15_project_BN (BatchNorm (None, 5, 5, 160) 640 ['block_15_project[0][0]']
alization)
block_15_add (Add) (None, 5, 5, 160) 0 ['block_14_add[0][0]',
'block_15_project_BN[0][0]']
block_16_expand (Conv2D) (None, 5, 5, 960) 153600 ['block_15_add[0][0]']
block_16_expand_BN (BatchNorma (None, 5, 5, 960) 3840 ['block_16_expand[0][0]']
lization)
block_16_expand_relu (ReLU) (None, 5, 5, 960) 0 ['block_16_expand_BN[0][0]']
block_16_depthwise (DepthwiseC (None, 5, 5, 960) 8640 ['block_16_expand_relu[0][0]']
onv2D)
block_16_depthwise_BN (BatchNo (None, 5, 5, 960) 3840 ['block_16_depthwise[0][0]']
rmalization)
block_16_depthwise_relu (ReLU) (None, 5, 5, 960) 0 ['block_16_depthwise_BN[0][0]']
block_16_project (Conv2D) (None, 5, 5, 320) 307200 ['block_16_depthwise_relu[0][0]']
block_16_project_BN (BatchNorm (None, 5, 5, 320) 1280 ['block_16_project[0][0]']
alization)
Conv_1 (Conv2D) (None, 5, 5, 1280) 409600 ['block_16_project_BN[0][0]']
Conv_1_bn (BatchNormalization) (None, 5, 5, 1280) 5120 ['Conv_1[0][0]']
out_relu (ReLU) (None, 5, 5, 1280) 0 ['Conv_1_bn[0][0]']
==================================================================================================
Total params: 2,257,984
Trainable params: 0
Non-trainable params: 2,257,984
__________________________________________________________________________________________________
Aggiungi una testata di classificazione
Per generare previsioni dal blocco di funzionalità, fare una media sulle posizioni spaziali 5x5 spaziali, utilizzando un livello tf.keras.layers.GlobalAveragePooling2D per convertire le funzionalità in un singolo vettore di 1280 elementi per immagine.
global_average_layer = tf.keras.layers.GlobalAveragePooling2D()
feature_batch_average = global_average_layer(feature_batch)
print(feature_batch_average.shape)
(32, 1280)
Applicare un livello tf.keras.layers.Dense per convertire queste caratteristiche in un'unica previsione per immagine. Non è necessaria una funzione di attivazione qui perché questa previsione verrà considerata come logit o come valore di previsione non elaborato. I numeri positivi predicono la classe 1, i numeri negativi predicono la classe 0.
prediction_layer = tf.keras.layers.Dense(1)
prediction_batch = prediction_layer(feature_batch_average)
print(prediction_batch.shape)
(32, 1)
Crea un modello concatenando insieme i livelli di data augmentation, rescaling, base_model e feature extractor utilizzando l' API funzionale Keras . Come accennato in precedenza, usa training=False poiché il nostro modello contiene un livello BatchNormalization .
inputs = tf.keras.Input(shape=(160, 160, 3))
x = data_augmentation(inputs)
x = preprocess_input(x)
x = base_model(x, training=False)
x = global_average_layer(x)
x = tf.keras.layers.Dropout(0.2)(x)
outputs = prediction_layer(x)
model = tf.keras.Model(inputs, outputs)
Compila il modello
Compila il modello prima di addestrarlo. Poiché ci sono due classi, usa la perdita tf.keras.losses.BinaryCrossentropy con from_logits=True poiché il modello fornisce un output lineare.
base_learning_rate = 0.0001
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=base_learning_rate),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 160, 160, 3)] 0
sequential (Sequential) (None, 160, 160, 3) 0
tf.math.truediv (TFOpLambda (None, 160, 160, 3) 0
)
tf.math.subtract (TFOpLambd (None, 160, 160, 3) 0
a)
mobilenetv2_1.00_160 (Funct (None, 5, 5, 1280) 2257984
ional)
global_average_pooling2d (G (None, 1280) 0
lobalAveragePooling2D)
dropout (Dropout) (None, 1280) 0
dense (Dense) (None, 1) 1281
=================================================================
Total params: 2,259,265
Trainable params: 1,281
Non-trainable params: 2,257,984
_________________________________________________________________
I 2,5 milioni di parametri in MobileNet sono congelati, ma ci sono 1,2 mila parametri addestrabili nel livello Dense. Questi sono divisi tra due oggetti tf.Variable , i pesi e le distorsioni.
len(model.trainable_variables)
2
Allena il modello
Dopo l'allenamento per 10 epoche, dovresti vedere una precisione del 94% circa sul set di convalida.
initial_epochs = 10
loss0, accuracy0 = model.evaluate(validation_dataset)
26/26 [==============================] - 2s 16ms/step - loss: 0.7428 - accuracy: 0.5186
print("initial loss: {:.2f}".format(loss0))
print("initial accuracy: {:.2f}".format(accuracy0))
initial loss: 0.74 initial accuracy: 0.52
history = model.fit(train_dataset,
epochs=initial_epochs,
validation_data=validation_dataset)
Epoch 1/10 63/63 [==============================] - 4s 23ms/step - loss: 0.6804 - accuracy: 0.5680 - val_loss: 0.4981 - val_accuracy: 0.7054 Epoch 2/10 63/63 [==============================] - 1s 22ms/step - loss: 0.5044 - accuracy: 0.7170 - val_loss: 0.3598 - val_accuracy: 0.8144 Epoch 3/10 63/63 [==============================] - 1s 21ms/step - loss: 0.4109 - accuracy: 0.7845 - val_loss: 0.2810 - val_accuracy: 0.8861 Epoch 4/10 63/63 [==============================] - 1s 21ms/step - loss: 0.3285 - accuracy: 0.8445 - val_loss: 0.2256 - val_accuracy: 0.9208 Epoch 5/10 63/63 [==============================] - 1s 21ms/step - loss: 0.3108 - accuracy: 0.8555 - val_loss: 0.1986 - val_accuracy: 0.9307 Epoch 6/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2659 - accuracy: 0.8855 - val_loss: 0.1703 - val_accuracy: 0.9418 Epoch 7/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2459 - accuracy: 0.8935 - val_loss: 0.1495 - val_accuracy: 0.9517 Epoch 8/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2315 - accuracy: 0.8950 - val_loss: 0.1454 - val_accuracy: 0.9542 Epoch 9/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2204 - accuracy: 0.9030 - val_loss: 0.1326 - val_accuracy: 0.9592 Epoch 10/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2180 - accuracy: 0.9115 - val_loss: 0.1215 - val_accuracy: 0.9604
Curve di apprendimento
Diamo un'occhiata alle curve di apprendimento dell'accuratezza/perdita di formazione e convalida quando si utilizza il modello base MobileNetV2 come estrattore di funzionalità fisse.
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.ylim([min(plt.ylim()),1])
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.ylim([0,1.0])
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
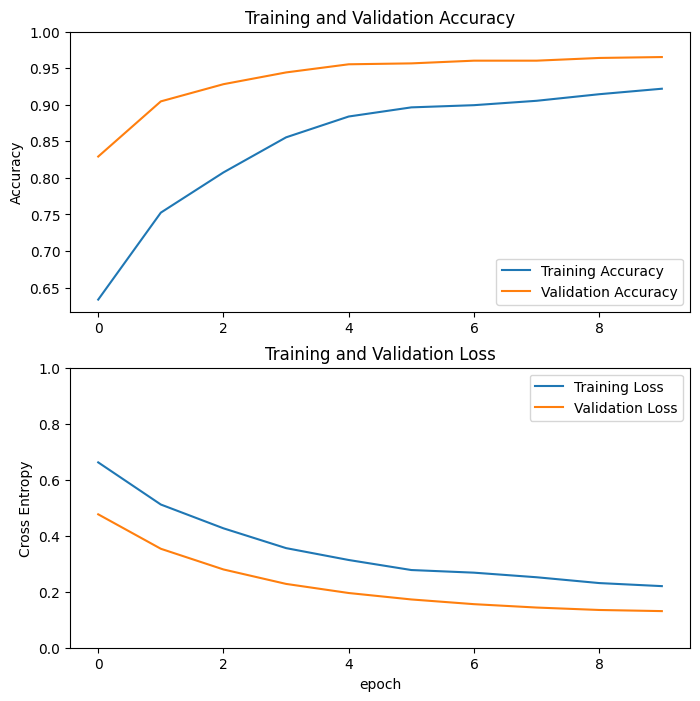
In misura minore, è anche perché le metriche di addestramento riportano la media per un'epoca, mentre le metriche di convalida vengono valutate dopo l'epoca, quindi le metriche di convalida vedono un modello che è stato addestrato leggermente più a lungo.
Ritocchi
Nell'esperimento di estrazione delle funzionalità, stavi addestrando solo alcuni livelli su un modello base MobileNetV2. I pesi della rete pre-addestrata non sono stati aggiornati durante la formazione.
Un modo per aumentare ulteriormente le prestazioni è allenare (o "mettere a punto") i pesi degli strati superiori del modello pre-allenato insieme all'allenamento del classificatore che hai aggiunto. Il processo di addestramento forzerà l'ottimizzazione dei pesi da mappe di funzionalità generiche a funzionalità associate in modo specifico al set di dati.
Inoltre, dovresti provare a mettere a punto un numero limitato di livelli superiori anziché l'intero modello MobileNet. Nella maggior parte delle reti convoluzionali, più alto è un livello, più specializzato è. I primi livelli apprendono caratteristiche molto semplici e generiche che si generalizzano a quasi tutti i tipi di immagini. Man mano che si sale più in alto, le funzionalità sono sempre più specifiche del set di dati su cui è stato addestrato il modello. L'obiettivo della messa a punto è adattare queste funzionalità specializzate per funzionare con il nuovo set di dati, piuttosto che sovrascrivere l'apprendimento generico.
Sblocca gli strati superiori del modello
Tutto quello che devi fare è sbloccare base_model e impostare gli strati inferiori in modo che non siano addestrabili. Quindi, dovresti ricompilare il modello (necessario affinché queste modifiche abbiano effetto) e riprendere la formazione.
base_model.trainable = True
# Let's take a look to see how many layers are in the base model
print("Number of layers in the base model: ", len(base_model.layers))
# Fine-tune from this layer onwards
fine_tune_at = 100
# Freeze all the layers before the `fine_tune_at` layer
for layer in base_model.layers[:fine_tune_at]:
layer.trainable = False
Number of layers in the base model: 154
Compila il modello
Poiché si sta allenando un modello molto più grande e si desidera riadattare i pesi pre-addestrati, è importante utilizzare un tasso di apprendimento inferiore in questa fase. In caso contrario, il tuo modello potrebbe adattarsi molto rapidamente.
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer = tf.keras.optimizers.RMSprop(learning_rate=base_learning_rate/10),
metrics=['accuracy'])
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 160, 160, 3)] 0
sequential (Sequential) (None, 160, 160, 3) 0
tf.math.truediv (TFOpLambda (None, 160, 160, 3) 0
)
tf.math.subtract (TFOpLambd (None, 160, 160, 3) 0
a)
mobilenetv2_1.00_160 (Funct (None, 5, 5, 1280) 2257984
ional)
global_average_pooling2d (G (None, 1280) 0
lobalAveragePooling2D)
dropout (Dropout) (None, 1280) 0
dense (Dense) (None, 1) 1281
=================================================================
Total params: 2,259,265
Trainable params: 1,862,721
Non-trainable params: 396,544
_________________________________________________________________
len(model.trainable_variables)
56
Continua ad addestrare il modello
Se ti sei allenato in precedenza alla convergenza, questo passaggio migliorerà la tua precisione di alcuni punti percentuali.
fine_tune_epochs = 10
total_epochs = initial_epochs + fine_tune_epochs
history_fine = model.fit(train_dataset,
epochs=total_epochs,
initial_epoch=history.epoch[-1],
validation_data=validation_dataset)
Epoch 10/20 63/63 [==============================] - 7s 40ms/step - loss: 0.1545 - accuracy: 0.9335 - val_loss: 0.0531 - val_accuracy: 0.9864 Epoch 11/20 63/63 [==============================] - 2s 28ms/step - loss: 0.1161 - accuracy: 0.9540 - val_loss: 0.0500 - val_accuracy: 0.9814 Epoch 12/20 63/63 [==============================] - 2s 28ms/step - loss: 0.1125 - accuracy: 0.9525 - val_loss: 0.0379 - val_accuracy: 0.9876 Epoch 13/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0891 - accuracy: 0.9625 - val_loss: 0.0472 - val_accuracy: 0.9889 Epoch 14/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0844 - accuracy: 0.9680 - val_loss: 0.0478 - val_accuracy: 0.9889 Epoch 15/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0857 - accuracy: 0.9645 - val_loss: 0.0354 - val_accuracy: 0.9839 Epoch 16/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0785 - accuracy: 0.9690 - val_loss: 0.0449 - val_accuracy: 0.9864 Epoch 17/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0669 - accuracy: 0.9740 - val_loss: 0.0375 - val_accuracy: 0.9839 Epoch 18/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0701 - accuracy: 0.9695 - val_loss: 0.0324 - val_accuracy: 0.9864 Epoch 19/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0636 - accuracy: 0.9760 - val_loss: 0.0465 - val_accuracy: 0.9790 Epoch 20/20 63/63 [==============================] - 2s 29ms/step - loss: 0.0585 - accuracy: 0.9765 - val_loss: 0.0392 - val_accuracy: 0.9851
Diamo un'occhiata alle curve di apprendimento dell'accuratezza/perdita di formazione e convalida durante la messa a punto degli ultimi livelli del modello base MobileNetV2 e il training del classificatore su di esso. La perdita di convalida è molto più alta della perdita di allenamento, quindi potresti avere un po' di overfitting.
È inoltre possibile che il nuovo set di addestramento sia relativamente piccolo e simile ai set di dati MobileNetV2 originali.
Dopo la messa a punto, il modello raggiunge quasi il 98% di precisione sul set di convalida.
acc += history_fine.history['accuracy']
val_acc += history_fine.history['val_accuracy']
loss += history_fine.history['loss']
val_loss += history_fine.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.ylim([0.8, 1])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.ylim([0, 1.0])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
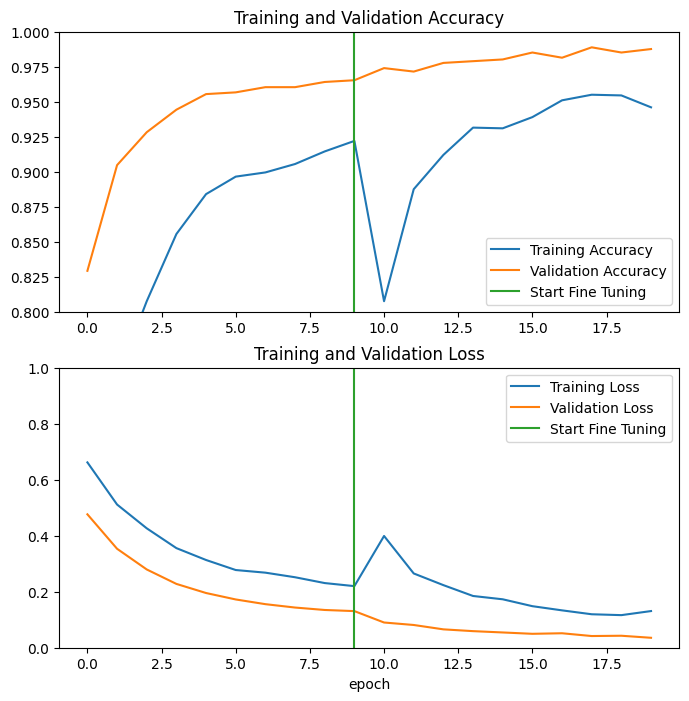
Valutazione e previsione
Infine è possibile verificare le prestazioni del modello su nuovi dati utilizzando il set di test.
loss, accuracy = model.evaluate(test_dataset)
print('Test accuracy :', accuracy)
6/6 [==============================] - 0s 13ms/step - loss: 0.0281 - accuracy: 0.9948 Test accuracy : 0.9947916865348816
E ora sei pronto per utilizzare questo modello per prevedere se il tuo animale domestico è un gatto o un cane.
# Retrieve a batch of images from the test set
image_batch, label_batch = test_dataset.as_numpy_iterator().next()
predictions = model.predict_on_batch(image_batch).flatten()
# Apply a sigmoid since our model returns logits
predictions = tf.nn.sigmoid(predictions)
predictions = tf.where(predictions < 0.5, 0, 1)
print('Predictions:\n', predictions.numpy())
print('Labels:\n', label_batch)
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image_batch[i].astype("uint8"))
plt.title(class_names[predictions[i]])
plt.axis("off")
Predictions: [0 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 0 0 0 1 0 1 0 0 1 1 1 0 0 0 1 0] Labels: [0 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 0 0 0 1 0 1 0 0 1 1 1 0 0 0 1 0]

Riepilogo
Utilizzo di un modello pre-addestrato per l'estrazione di funzionalità : quando si lavora con un piccolo set di dati, è pratica comune sfruttare le funzionalità apprese da un modello addestrato su un set di dati più grande nello stesso dominio. Questo viene fatto istanziando il modello pre-addestrato e aggiungendo un classificatore completamente connesso in cima. Il modello pre-allenato viene "congelato" e solo i pesi del classificatore vengono aggiornati durante l'allenamento. In questo caso, la base convoluzionale ha estratto tutte le funzionalità associate a ciascuna immagine e hai appena addestrato un classificatore che determina la classe dell'immagine in base a quell'insieme di funzionalità estratte.
Ottimizzazione di un modello pre-addestrato : per migliorare ulteriormente le prestazioni, si potrebbe voler riutilizzare i livelli di livello superiore dei modelli pre-addestrati nel nuovo set di dati tramite l'ottimizzazione. In questo caso, hai ottimizzato i tuoi pesi in modo tale che il tuo modello apprendesse funzionalità di alto livello specifiche per il set di dati. Questa tecnica è in genere consigliata quando il set di dati di addestramento è di grandi dimensioni e molto simile al set di dati originale su cui è stato eseguito il training del modello pre-addestrato.
Per saperne di più, visita la guida all'apprendimento Transfer .
# MIT License
#
# Copyright (c) 2017 François Chollet # IGNORE_COPYRIGHT: cleared by OSS licensing
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.