
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
इस ट्यूटोरियल में, आप सीखेंगे कि पूर्व-प्रशिक्षित नेटवर्क से ट्रांसफर लर्निंग का उपयोग करके बिल्लियों और कुत्तों की छवियों को कैसे वर्गीकृत किया जाए।
एक पूर्व-प्रशिक्षित मॉडल एक सहेजा गया नेटवर्क है जिसे पहले बड़े डेटासेट पर प्रशिक्षित किया गया था, आमतौर पर बड़े पैमाने पर छवि-वर्गीकरण कार्य पर। आप या तो पूर्व-प्रशिक्षित मॉडल का उपयोग करते हैं या किसी दिए गए कार्य के लिए इस मॉडल को अनुकूलित करने के लिए स्थानांतरण सीखने का उपयोग करते हैं।
छवि वर्गीकरण के लिए स्थानांतरण सीखने के पीछे अंतर्ज्ञान यह है कि यदि किसी मॉडल को बड़े और सामान्य पर्याप्त डेटासेट पर प्रशिक्षित किया जाता है, तो यह मॉडल प्रभावी रूप से दृश्य दुनिया के सामान्य मॉडल के रूप में कार्य करेगा। फिर आप बड़े डेटासेट पर एक बड़े मॉडल को प्रशिक्षित करके बिना खरोंच से शुरू किए इन सीखे हुए फीचर मैप्स का लाभ उठा सकते हैं।
इस नोटबुक में, आप एक पूर्व-प्रशिक्षित मॉडल को अनुकूलित करने के दो तरीके आज़माएँगे:
फ़ीचर एक्सट्रैक्शन: नए नमूनों से सार्थक सुविधाओं को निकालने के लिए पिछले नेटवर्क द्वारा सीखे गए अभ्यावेदन का उपयोग करें। आप बस एक नया क्लासिफायरियर जोड़ते हैं, जिसे स्क्रैच से प्रशिक्षित किया जाएगा, पूर्व-प्रशिक्षित मॉडल के शीर्ष पर ताकि आप डेटासेट के लिए पहले सीखे गए फीचर मैप्स का पुन: उपयोग कर सकें।
आपको पूरे मॉडल को (पुनः) प्रशिक्षित करने की आवश्यकता नहीं है। बेस कन्वेन्शनल नेटवर्क में पहले से ही ऐसी विशेषताएं हैं जो चित्रों को वर्गीकृत करने के लिए सामान्य रूप से उपयोगी हैं। हालांकि, पूर्व-प्रशिक्षित मॉडल का अंतिम, वर्गीकरण हिस्सा मूल वर्गीकरण कार्य के लिए विशिष्ट है, और बाद में उन वर्गों के समूह के लिए विशिष्ट है जिन पर मॉडल को प्रशिक्षित किया गया था।
फाइन-ट्यूनिंग: फ्रोजन मॉडल बेस की कुछ शीर्ष परतों को अनफ्रीज करें और नई जोड़ी गई क्लासिफायर लेयर और बेस मॉडल की अंतिम परतों दोनों को संयुक्त रूप से प्रशिक्षित करें। यह हमें विशिष्ट कार्य के लिए उन्हें अधिक प्रासंगिक बनाने के लिए बेस मॉडल में उच्च-क्रम की सुविधा प्रस्तुतियों को "फाइन-ट्यून" करने की अनुमति देता है।
आप सामान्य मशीन लर्निंग वर्कफ़्लो का पालन करेंगे।
- डेटा की जांच करें और समझें
- इस मामले में Keras ImageDataGenerator का उपयोग करके एक इनपुट पाइपलाइन बनाएं
- मॉडल लिखें
- पहले से प्रशिक्षित बेस मॉडल में लोड (और पहले से प्रशिक्षित वजन)
- शीर्ष पर वर्गीकरण परतों को ढेर करें
- मॉडल को प्रशिक्षित करें
- मॉडल का मूल्यांकन करें
import matplotlib.pyplot as plt
import numpy as np
import os
import tensorflow as tf
डेटा प्रीप्रोसेसिंग
डेटा डाउनलोड
इस ट्यूटोरियल में, आप बिल्लियों और कुत्तों की कई हज़ार छवियों वाले डेटासेट का उपयोग करेंगे। छवियों वाली एक ज़िप फ़ाइल डाउनलोड करें और निकालें, फिर tf.keras.utils.image_dataset_from_directory उपयोगिता का उपयोग करके प्रशिक्षण और सत्यापन के लिए एक tf.data.Dataset बनाएं। आप इस ट्यूटोरियल में छवियों को लोड करने के बारे में अधिक जान सकते हैं।
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
path_to_zip = tf.keras.utils.get_file('cats_and_dogs.zip', origin=_URL, extract=True)
PATH = os.path.join(os.path.dirname(path_to_zip), 'cats_and_dogs_filtered')
train_dir = os.path.join(PATH, 'train')
validation_dir = os.path.join(PATH, 'validation')
BATCH_SIZE = 32
IMG_SIZE = (160, 160)
train_dataset = tf.keras.utils.image_dataset_from_directory(train_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
Downloading data from https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip 68608000/68606236 [==============================] - 1s 0us/step 68616192/68606236 [==============================] - 1s 0us/step Found 2000 files belonging to 2 classes.
validation_dataset = tf.keras.utils.image_dataset_from_directory(validation_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
Found 1000 files belonging to 2 classes.
प्रशिक्षण सेट से पहले नौ चित्र और लेबल दिखाएं:
class_names = train_dataset.class_names
plt.figure(figsize=(10, 10))
for images, labels in train_dataset.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")

चूंकि मूल डेटासेट में परीक्षण सेट नहीं है, इसलिए आप एक परीक्षण सेट बनाएंगे। ऐसा करने के लिए, यह निर्धारित करें कि tf.data.experimental.cardinality का उपयोग करके सत्यापन सेट में डेटा के कितने बैच उपलब्ध हैं, फिर उनमें से 20% को परीक्षण सेट पर ले जाएं।
val_batches = tf.data.experimental.cardinality(validation_dataset)
test_dataset = validation_dataset.take(val_batches // 5)
validation_dataset = validation_dataset.skip(val_batches // 5)
print('Number of validation batches: %d' % tf.data.experimental.cardinality(validation_dataset))
print('Number of test batches: %d' % tf.data.experimental.cardinality(test_dataset))
Number of validation batches: 26 Number of test batches: 6
प्रदर्शन के लिए डेटासेट कॉन्फ़िगर करें
I/O अवरोधित हुए बिना डिस्क से छवियों को लोड करने के लिए बफर्ड प्रीफ़ेचिंग का उपयोग करें। इस पद्धति के बारे में अधिक जानने के लिए डेटा प्रदर्शन मार्गदर्शिका देखें।
AUTOTUNE = tf.data.AUTOTUNE
train_dataset = train_dataset.prefetch(buffer_size=AUTOTUNE)
validation_dataset = validation_dataset.prefetch(buffer_size=AUTOTUNE)
test_dataset = test_dataset.prefetch(buffer_size=AUTOTUNE)
डेटा वृद्धि का उपयोग करें
जब आपके पास एक बड़ा छवि डेटासेट नहीं होता है, तो प्रशिक्षण छवियों में यादृच्छिक, फिर भी यथार्थवादी, परिवर्तन जैसे रोटेशन और क्षैतिज फ़्लिपिंग लागू करके नमूना विविधता को कृत्रिम रूप से पेश करना एक अच्छा अभ्यास है। यह मॉडल को प्रशिक्षण डेटा के विभिन्न पहलुओं को उजागर करने और ओवरफिटिंग को कम करने में मदद करता है। आप इस ट्यूटोरियल में डेटा वृद्धि के बारे में अधिक जान सकते हैं।
data_augmentation = tf.keras.Sequential([
tf.keras.layers.RandomFlip('horizontal'),
tf.keras.layers.RandomRotation(0.2),
])
आइए इन परतों को एक ही छवि पर बार-बार लागू करें और परिणाम देखें।
for image, _ in train_dataset.take(1):
plt.figure(figsize=(10, 10))
first_image = image[0]
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
augmented_image = data_augmentation(tf.expand_dims(first_image, 0))
plt.imshow(augmented_image[0] / 255)
plt.axis('off')

पिक्सेल मान पुनर्विक्रय करें
एक पल में, आप अपने आधार मॉडल के रूप में उपयोग के लिए tf.keras.applications.MobileNetV2 डाउनलोड करेंगे। यह मॉडल [-1, 1] में पिक्सेल मानों की अपेक्षा करता है, लेकिन इस समय, आपकी छवियों में पिक्सेल मान [0, 255] में हैं। उन्हें पुनर्विक्रय करने के लिए, मॉडल के साथ शामिल प्रीप्रोसेसिंग विधि का उपयोग करें।
preprocess_input = tf.keras.applications.mobilenet_v2.preprocess_input
rescale = tf.keras.layers.Rescaling(1./127.5, offset=-1)
पूर्व-प्रशिक्षित कान्वेंट से आधार मॉडल बनाएं
आप Google में विकसित MobileNet V2 मॉडल से बेस मॉडल बनाएंगे। यह इमेजनेट डेटासेट पर पूर्व-प्रशिक्षित है, एक बड़ा डेटासेट जिसमें 1.4M चित्र और 1000 वर्ग शामिल हैं। इमेजनेट एक शोध प्रशिक्षण डेटासेट है जिसमें jackfruit और syringe जैसी कई श्रेणियां हैं। ज्ञान का यह आधार हमें अपने विशिष्ट डेटासेट से बिल्लियों और कुत्तों को वर्गीकृत करने में मदद करेगा।
सबसे पहले, आपको फीचर निष्कर्षण के लिए MobileNet V2 की किस परत का उपयोग करना होगा, यह चुनने की आवश्यकता है। अंतिम वर्गीकरण परत ("शीर्ष पर", जैसा कि मशीन लर्निंग मॉडल के अधिकांश आरेख नीचे से ऊपर तक जाते हैं) बहुत उपयोगी नहीं है। इसके बजाय, आप समतल ऑपरेशन से पहले अंतिम परत पर निर्भर रहने के लिए सामान्य अभ्यास का पालन करेंगे। इस परत को "अड़चन परत" कहा जाता है। अंतिम/शीर्ष परत की तुलना में अड़चन परत की विशेषताएं अधिक व्यापकता बनाए रखती हैं।
सबसे पहले, ImageNet पर प्रशिक्षित भार के साथ पहले से लोड किए गए MobileNet V2 मॉडल को इंस्टेंट करें। शामिल_टॉप = गलत तर्क निर्दिष्ट करके, आप एक नेटवर्क लोड करते हैं जिसमें शीर्ष पर वर्गीकरण परतें शामिल नहीं होती हैं, जो सुविधा निष्कर्षण के लिए आदर्श है।
# Create the base model from the pre-trained model MobileNet V2
IMG_SHAPE = IMG_SIZE + (3,)
base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_160_no_top.h5 9412608/9406464 [==============================] - 0s 0us/step 9420800/9406464 [==============================] - 0s 0us/step
यह फीचर एक्सट्रैक्टर प्रत्येक 160x160x3 छवि को सुविधाओं के 5x5x1280 ब्लॉक में परिवर्तित करता है। आइए देखें कि यह छवियों के उदाहरण बैच के लिए क्या करता है:
image_batch, label_batch = next(iter(train_dataset))
feature_batch = base_model(image_batch)
print(feature_batch.shape)
(32, 5, 5, 1280)
सुविधा निकालना
इस चरण में, आप पिछले चरण से बनाए गए दृढ़ आधार को फ्रीज कर देंगे और फीचर एक्सट्रैक्टर के रूप में उपयोग करेंगे। इसके अतिरिक्त, आप इसके ऊपर एक क्लासिफायरियर जोड़ते हैं और टॉप-लेवल क्लासिफायर को प्रशिक्षित करते हैं।
दृढ़ आधार को फ्रीज करें
मॉडल को संकलित और प्रशिक्षित करने से पहले दृढ़ आधार को स्थिर करना महत्वपूर्ण है। फ्रीजिंग (लेयर.ट्रेनेबल = फाल्स सेट करके) किसी दिए गए लेयर में वेट को ट्रेनिंग के दौरान अपडेट होने से रोकता है। MobileNet V2 में कई परतें हैं, इसलिए पूरे मॉडल के trainable ध्वज को False पर सेट करने से वे सभी स्थिर हो जाएंगे।
base_model.trainable = False
बैचसामान्यीकरण परतों के बारे में महत्वपूर्ण नोट
कई मॉडलों में tf.keras.layers.BatchNormalization परतें होती हैं। यह परत एक विशेष मामला है और फाइन-ट्यूनिंग के संदर्भ में सावधानी बरतनी चाहिए, जैसा कि इस ट्यूटोरियल में बाद में दिखाया गया है।
जब आप layer.trainable = False सेट करते हैं, तो BatchNormalization लेयर अनुमान मोड में चलेगी, और इसके माध्य और विचरण के आंकड़ों को अपडेट नहीं करेगी।
जब आप फ़ाइन-ट्यूनिंग करने के लिए बैचनॉर्मलाइज़ेशन लेयर वाले मॉडल को अनफ़्रीज़ करते हैं, तो आपको बेस मॉडल को कॉल करते समय training = False पास करके बैचनॉर्मलाइज़ेशन लेयर्स को इंफ़ेक्शन मोड में रखना चाहिए। अन्यथा, गैर-प्रशिक्षित भारों पर लागू किए गए अपडेट मॉडल द्वारा सीखी गई जानकारी को नष्ट कर देंगे।
अधिक विवरण के लिए, स्थानांतरण शिक्षण मार्गदर्शिका देखें।
# Let's take a look at the base model architecture
base_model.summary()
Model: "mobilenetv2_1.00_160"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 160, 160, 3 0 []
)]
Conv1 (Conv2D) (None, 80, 80, 32) 864 ['input_1[0][0]']
bn_Conv1 (BatchNormalization) (None, 80, 80, 32) 128 ['Conv1[0][0]']
Conv1_relu (ReLU) (None, 80, 80, 32) 0 ['bn_Conv1[0][0]']
expanded_conv_depthwise (Depth (None, 80, 80, 32) 288 ['Conv1_relu[0][0]']
wiseConv2D)
expanded_conv_depthwise_BN (Ba (None, 80, 80, 32) 128 ['expanded_conv_depthwise[0][0]']
tchNormalization)
expanded_conv_depthwise_relu ( (None, 80, 80, 32) 0 ['expanded_conv_depthwise_BN[0][0
ReLU) ]']
expanded_conv_project (Conv2D) (None, 80, 80, 16) 512 ['expanded_conv_depthwise_relu[0]
[0]']
expanded_conv_project_BN (Batc (None, 80, 80, 16) 64 ['expanded_conv_project[0][0]']
hNormalization)
block_1_expand (Conv2D) (None, 80, 80, 96) 1536 ['expanded_conv_project_BN[0][0]'
]
block_1_expand_BN (BatchNormal (None, 80, 80, 96) 384 ['block_1_expand[0][0]']
ization)
block_1_expand_relu (ReLU) (None, 80, 80, 96) 0 ['block_1_expand_BN[0][0]']
block_1_pad (ZeroPadding2D) (None, 81, 81, 96) 0 ['block_1_expand_relu[0][0]']
block_1_depthwise (DepthwiseCo (None, 40, 40, 96) 864 ['block_1_pad[0][0]']
nv2D)
block_1_depthwise_BN (BatchNor (None, 40, 40, 96) 384 ['block_1_depthwise[0][0]']
malization)
block_1_depthwise_relu (ReLU) (None, 40, 40, 96) 0 ['block_1_depthwise_BN[0][0]']
block_1_project (Conv2D) (None, 40, 40, 24) 2304 ['block_1_depthwise_relu[0][0]']
block_1_project_BN (BatchNorma (None, 40, 40, 24) 96 ['block_1_project[0][0]']
lization)
block_2_expand (Conv2D) (None, 40, 40, 144) 3456 ['block_1_project_BN[0][0]']
block_2_expand_BN (BatchNormal (None, 40, 40, 144) 576 ['block_2_expand[0][0]']
ization)
block_2_expand_relu (ReLU) (None, 40, 40, 144) 0 ['block_2_expand_BN[0][0]']
block_2_depthwise (DepthwiseCo (None, 40, 40, 144) 1296 ['block_2_expand_relu[0][0]']
nv2D)
block_2_depthwise_BN (BatchNor (None, 40, 40, 144) 576 ['block_2_depthwise[0][0]']
malization)
block_2_depthwise_relu (ReLU) (None, 40, 40, 144) 0 ['block_2_depthwise_BN[0][0]']
block_2_project (Conv2D) (None, 40, 40, 24) 3456 ['block_2_depthwise_relu[0][0]']
block_2_project_BN (BatchNorma (None, 40, 40, 24) 96 ['block_2_project[0][0]']
lization)
block_2_add (Add) (None, 40, 40, 24) 0 ['block_1_project_BN[0][0]',
'block_2_project_BN[0][0]']
block_3_expand (Conv2D) (None, 40, 40, 144) 3456 ['block_2_add[0][0]']
block_3_expand_BN (BatchNormal (None, 40, 40, 144) 576 ['block_3_expand[0][0]']
ization)
block_3_expand_relu (ReLU) (None, 40, 40, 144) 0 ['block_3_expand_BN[0][0]']
block_3_pad (ZeroPadding2D) (None, 41, 41, 144) 0 ['block_3_expand_relu[0][0]']
block_3_depthwise (DepthwiseCo (None, 20, 20, 144) 1296 ['block_3_pad[0][0]']
nv2D)
block_3_depthwise_BN (BatchNor (None, 20, 20, 144) 576 ['block_3_depthwise[0][0]']
malization)
block_3_depthwise_relu (ReLU) (None, 20, 20, 144) 0 ['block_3_depthwise_BN[0][0]']
block_3_project (Conv2D) (None, 20, 20, 32) 4608 ['block_3_depthwise_relu[0][0]']
block_3_project_BN (BatchNorma (None, 20, 20, 32) 128 ['block_3_project[0][0]']
lization)
block_4_expand (Conv2D) (None, 20, 20, 192) 6144 ['block_3_project_BN[0][0]']
block_4_expand_BN (BatchNormal (None, 20, 20, 192) 768 ['block_4_expand[0][0]']
ization)
block_4_expand_relu (ReLU) (None, 20, 20, 192) 0 ['block_4_expand_BN[0][0]']
block_4_depthwise (DepthwiseCo (None, 20, 20, 192) 1728 ['block_4_expand_relu[0][0]']
nv2D)
block_4_depthwise_BN (BatchNor (None, 20, 20, 192) 768 ['block_4_depthwise[0][0]']
malization)
block_4_depthwise_relu (ReLU) (None, 20, 20, 192) 0 ['block_4_depthwise_BN[0][0]']
block_4_project (Conv2D) (None, 20, 20, 32) 6144 ['block_4_depthwise_relu[0][0]']
block_4_project_BN (BatchNorma (None, 20, 20, 32) 128 ['block_4_project[0][0]']
lization)
block_4_add (Add) (None, 20, 20, 32) 0 ['block_3_project_BN[0][0]',
'block_4_project_BN[0][0]']
block_5_expand (Conv2D) (None, 20, 20, 192) 6144 ['block_4_add[0][0]']
block_5_expand_BN (BatchNormal (None, 20, 20, 192) 768 ['block_5_expand[0][0]']
ization)
block_5_expand_relu (ReLU) (None, 20, 20, 192) 0 ['block_5_expand_BN[0][0]']
block_5_depthwise (DepthwiseCo (None, 20, 20, 192) 1728 ['block_5_expand_relu[0][0]']
nv2D)
block_5_depthwise_BN (BatchNor (None, 20, 20, 192) 768 ['block_5_depthwise[0][0]']
malization)
block_5_depthwise_relu (ReLU) (None, 20, 20, 192) 0 ['block_5_depthwise_BN[0][0]']
block_5_project (Conv2D) (None, 20, 20, 32) 6144 ['block_5_depthwise_relu[0][0]']
block_5_project_BN (BatchNorma (None, 20, 20, 32) 128 ['block_5_project[0][0]']
lization)
block_5_add (Add) (None, 20, 20, 32) 0 ['block_4_add[0][0]',
'block_5_project_BN[0][0]']
block_6_expand (Conv2D) (None, 20, 20, 192) 6144 ['block_5_add[0][0]']
block_6_expand_BN (BatchNormal (None, 20, 20, 192) 768 ['block_6_expand[0][0]']
ization)
block_6_expand_relu (ReLU) (None, 20, 20, 192) 0 ['block_6_expand_BN[0][0]']
block_6_pad (ZeroPadding2D) (None, 21, 21, 192) 0 ['block_6_expand_relu[0][0]']
block_6_depthwise (DepthwiseCo (None, 10, 10, 192) 1728 ['block_6_pad[0][0]']
nv2D)
block_6_depthwise_BN (BatchNor (None, 10, 10, 192) 768 ['block_6_depthwise[0][0]']
malization)
block_6_depthwise_relu (ReLU) (None, 10, 10, 192) 0 ['block_6_depthwise_BN[0][0]']
block_6_project (Conv2D) (None, 10, 10, 64) 12288 ['block_6_depthwise_relu[0][0]']
block_6_project_BN (BatchNorma (None, 10, 10, 64) 256 ['block_6_project[0][0]']
lization)
block_7_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_6_project_BN[0][0]']
block_7_expand_BN (BatchNormal (None, 10, 10, 384) 1536 ['block_7_expand[0][0]']
ization)
block_7_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_7_expand_BN[0][0]']
block_7_depthwise (DepthwiseCo (None, 10, 10, 384) 3456 ['block_7_expand_relu[0][0]']
nv2D)
block_7_depthwise_BN (BatchNor (None, 10, 10, 384) 1536 ['block_7_depthwise[0][0]']
malization)
block_7_depthwise_relu (ReLU) (None, 10, 10, 384) 0 ['block_7_depthwise_BN[0][0]']
block_7_project (Conv2D) (None, 10, 10, 64) 24576 ['block_7_depthwise_relu[0][0]']
block_7_project_BN (BatchNorma (None, 10, 10, 64) 256 ['block_7_project[0][0]']
lization)
block_7_add (Add) (None, 10, 10, 64) 0 ['block_6_project_BN[0][0]',
'block_7_project_BN[0][0]']
block_8_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_7_add[0][0]']
block_8_expand_BN (BatchNormal (None, 10, 10, 384) 1536 ['block_8_expand[0][0]']
ization)
block_8_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_8_expand_BN[0][0]']
block_8_depthwise (DepthwiseCo (None, 10, 10, 384) 3456 ['block_8_expand_relu[0][0]']
nv2D)
block_8_depthwise_BN (BatchNor (None, 10, 10, 384) 1536 ['block_8_depthwise[0][0]']
malization)
block_8_depthwise_relu (ReLU) (None, 10, 10, 384) 0 ['block_8_depthwise_BN[0][0]']
block_8_project (Conv2D) (None, 10, 10, 64) 24576 ['block_8_depthwise_relu[0][0]']
block_8_project_BN (BatchNorma (None, 10, 10, 64) 256 ['block_8_project[0][0]']
lization)
block_8_add (Add) (None, 10, 10, 64) 0 ['block_7_add[0][0]',
'block_8_project_BN[0][0]']
block_9_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_8_add[0][0]']
block_9_expand_BN (BatchNormal (None, 10, 10, 384) 1536 ['block_9_expand[0][0]']
ization)
block_9_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_9_expand_BN[0][0]']
block_9_depthwise (DepthwiseCo (None, 10, 10, 384) 3456 ['block_9_expand_relu[0][0]']
nv2D)
block_9_depthwise_BN (BatchNor (None, 10, 10, 384) 1536 ['block_9_depthwise[0][0]']
malization)
block_9_depthwise_relu (ReLU) (None, 10, 10, 384) 0 ['block_9_depthwise_BN[0][0]']
block_9_project (Conv2D) (None, 10, 10, 64) 24576 ['block_9_depthwise_relu[0][0]']
block_9_project_BN (BatchNorma (None, 10, 10, 64) 256 ['block_9_project[0][0]']
lization)
block_9_add (Add) (None, 10, 10, 64) 0 ['block_8_add[0][0]',
'block_9_project_BN[0][0]']
block_10_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_9_add[0][0]']
block_10_expand_BN (BatchNorma (None, 10, 10, 384) 1536 ['block_10_expand[0][0]']
lization)
block_10_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_10_expand_BN[0][0]']
block_10_depthwise (DepthwiseC (None, 10, 10, 384) 3456 ['block_10_expand_relu[0][0]']
onv2D)
block_10_depthwise_BN (BatchNo (None, 10, 10, 384) 1536 ['block_10_depthwise[0][0]']
rmalization)
block_10_depthwise_relu (ReLU) (None, 10, 10, 384) 0 ['block_10_depthwise_BN[0][0]']
block_10_project (Conv2D) (None, 10, 10, 96) 36864 ['block_10_depthwise_relu[0][0]']
block_10_project_BN (BatchNorm (None, 10, 10, 96) 384 ['block_10_project[0][0]']
alization)
block_11_expand (Conv2D) (None, 10, 10, 576) 55296 ['block_10_project_BN[0][0]']
block_11_expand_BN (BatchNorma (None, 10, 10, 576) 2304 ['block_11_expand[0][0]']
lization)
block_11_expand_relu (ReLU) (None, 10, 10, 576) 0 ['block_11_expand_BN[0][0]']
block_11_depthwise (DepthwiseC (None, 10, 10, 576) 5184 ['block_11_expand_relu[0][0]']
onv2D)
block_11_depthwise_BN (BatchNo (None, 10, 10, 576) 2304 ['block_11_depthwise[0][0]']
rmalization)
block_11_depthwise_relu (ReLU) (None, 10, 10, 576) 0 ['block_11_depthwise_BN[0][0]']
block_11_project (Conv2D) (None, 10, 10, 96) 55296 ['block_11_depthwise_relu[0][0]']
block_11_project_BN (BatchNorm (None, 10, 10, 96) 384 ['block_11_project[0][0]']
alization)
block_11_add (Add) (None, 10, 10, 96) 0 ['block_10_project_BN[0][0]',
'block_11_project_BN[0][0]']
block_12_expand (Conv2D) (None, 10, 10, 576) 55296 ['block_11_add[0][0]']
block_12_expand_BN (BatchNorma (None, 10, 10, 576) 2304 ['block_12_expand[0][0]']
lization)
block_12_expand_relu (ReLU) (None, 10, 10, 576) 0 ['block_12_expand_BN[0][0]']
block_12_depthwise (DepthwiseC (None, 10, 10, 576) 5184 ['block_12_expand_relu[0][0]']
onv2D)
block_12_depthwise_BN (BatchNo (None, 10, 10, 576) 2304 ['block_12_depthwise[0][0]']
rmalization)
block_12_depthwise_relu (ReLU) (None, 10, 10, 576) 0 ['block_12_depthwise_BN[0][0]']
block_12_project (Conv2D) (None, 10, 10, 96) 55296 ['block_12_depthwise_relu[0][0]']
block_12_project_BN (BatchNorm (None, 10, 10, 96) 384 ['block_12_project[0][0]']
alization)
block_12_add (Add) (None, 10, 10, 96) 0 ['block_11_add[0][0]',
'block_12_project_BN[0][0]']
block_13_expand (Conv2D) (None, 10, 10, 576) 55296 ['block_12_add[0][0]']
block_13_expand_BN (BatchNorma (None, 10, 10, 576) 2304 ['block_13_expand[0][0]']
lization)
block_13_expand_relu (ReLU) (None, 10, 10, 576) 0 ['block_13_expand_BN[0][0]']
block_13_pad (ZeroPadding2D) (None, 11, 11, 576) 0 ['block_13_expand_relu[0][0]']
block_13_depthwise (DepthwiseC (None, 5, 5, 576) 5184 ['block_13_pad[0][0]']
onv2D)
block_13_depthwise_BN (BatchNo (None, 5, 5, 576) 2304 ['block_13_depthwise[0][0]']
rmalization)
block_13_depthwise_relu (ReLU) (None, 5, 5, 576) 0 ['block_13_depthwise_BN[0][0]']
block_13_project (Conv2D) (None, 5, 5, 160) 92160 ['block_13_depthwise_relu[0][0]']
block_13_project_BN (BatchNorm (None, 5, 5, 160) 640 ['block_13_project[0][0]']
alization)
block_14_expand (Conv2D) (None, 5, 5, 960) 153600 ['block_13_project_BN[0][0]']
block_14_expand_BN (BatchNorma (None, 5, 5, 960) 3840 ['block_14_expand[0][0]']
lization)
block_14_expand_relu (ReLU) (None, 5, 5, 960) 0 ['block_14_expand_BN[0][0]']
block_14_depthwise (DepthwiseC (None, 5, 5, 960) 8640 ['block_14_expand_relu[0][0]']
onv2D)
block_14_depthwise_BN (BatchNo (None, 5, 5, 960) 3840 ['block_14_depthwise[0][0]']
rmalization)
block_14_depthwise_relu (ReLU) (None, 5, 5, 960) 0 ['block_14_depthwise_BN[0][0]']
block_14_project (Conv2D) (None, 5, 5, 160) 153600 ['block_14_depthwise_relu[0][0]']
block_14_project_BN (BatchNorm (None, 5, 5, 160) 640 ['block_14_project[0][0]']
alization)
block_14_add (Add) (None, 5, 5, 160) 0 ['block_13_project_BN[0][0]',
'block_14_project_BN[0][0]']
block_15_expand (Conv2D) (None, 5, 5, 960) 153600 ['block_14_add[0][0]']
block_15_expand_BN (BatchNorma (None, 5, 5, 960) 3840 ['block_15_expand[0][0]']
lization)
block_15_expand_relu (ReLU) (None, 5, 5, 960) 0 ['block_15_expand_BN[0][0]']
block_15_depthwise (DepthwiseC (None, 5, 5, 960) 8640 ['block_15_expand_relu[0][0]']
onv2D)
block_15_depthwise_BN (BatchNo (None, 5, 5, 960) 3840 ['block_15_depthwise[0][0]']
rmalization)
block_15_depthwise_relu (ReLU) (None, 5, 5, 960) 0 ['block_15_depthwise_BN[0][0]']
block_15_project (Conv2D) (None, 5, 5, 160) 153600 ['block_15_depthwise_relu[0][0]']
block_15_project_BN (BatchNorm (None, 5, 5, 160) 640 ['block_15_project[0][0]']
alization)
block_15_add (Add) (None, 5, 5, 160) 0 ['block_14_add[0][0]',
'block_15_project_BN[0][0]']
block_16_expand (Conv2D) (None, 5, 5, 960) 153600 ['block_15_add[0][0]']
block_16_expand_BN (BatchNorma (None, 5, 5, 960) 3840 ['block_16_expand[0][0]']
lization)
block_16_expand_relu (ReLU) (None, 5, 5, 960) 0 ['block_16_expand_BN[0][0]']
block_16_depthwise (DepthwiseC (None, 5, 5, 960) 8640 ['block_16_expand_relu[0][0]']
onv2D)
block_16_depthwise_BN (BatchNo (None, 5, 5, 960) 3840 ['block_16_depthwise[0][0]']
rmalization)
block_16_depthwise_relu (ReLU) (None, 5, 5, 960) 0 ['block_16_depthwise_BN[0][0]']
block_16_project (Conv2D) (None, 5, 5, 320) 307200 ['block_16_depthwise_relu[0][0]']
block_16_project_BN (BatchNorm (None, 5, 5, 320) 1280 ['block_16_project[0][0]']
alization)
Conv_1 (Conv2D) (None, 5, 5, 1280) 409600 ['block_16_project_BN[0][0]']
Conv_1_bn (BatchNormalization) (None, 5, 5, 1280) 5120 ['Conv_1[0][0]']
out_relu (ReLU) (None, 5, 5, 1280) 0 ['Conv_1_bn[0][0]']
==================================================================================================
Total params: 2,257,984
Trainable params: 0
Non-trainable params: 2,257,984
__________________________________________________________________________________________________
एक वर्गीकरण शीर्ष जोड़ें
सुविधाओं के ब्लॉक से पूर्वानुमान उत्पन्न करने के लिए, स्थानिक 5x5 स्थानिक स्थानों पर औसत, एक tf.keras.layers.GlobalAveragePooling2D परत का उपयोग करके सुविधाओं को प्रति छवि एकल 1280-तत्व वेक्टर में परिवर्तित करने के लिए।
global_average_layer = tf.keras.layers.GlobalAveragePooling2D()
feature_batch_average = global_average_layer(feature_batch)
print(feature_batch_average.shape)
(32, 1280)
इन विशेषताओं को प्रति छवि एकल पूर्वानुमान में बदलने के लिए एक tf.keras.layers.Dense परत लागू करें। आपको यहां एक सक्रियण फ़ंक्शन की आवश्यकता नहीं है क्योंकि इस भविष्यवाणी को एक logit , या एक अपरिष्कृत भविष्यवाणी मान के रूप में माना जाएगा। सकारात्मक संख्याएं कक्षा 1 की भविष्यवाणी करती हैं, नकारात्मक संख्याएं कक्षा 0 की भविष्यवाणी करती हैं।
prediction_layer = tf.keras.layers.Dense(1)
prediction_batch = prediction_layer(feature_batch_average)
print(prediction_batch.shape)
(32, 1)
केरस फंक्शनल एपीआई का उपयोग करके डेटा वृद्धि, पुनर्विक्रय, base_model और फीचर एक्सट्रैक्टर परतों को एक साथ जोड़कर एक मॉडल बनाएं। जैसा कि पहले उल्लेख किया गया है, training=False का उपयोग करें क्योंकि हमारे मॉडल में BatchNormalization परत है।
inputs = tf.keras.Input(shape=(160, 160, 3))
x = data_augmentation(inputs)
x = preprocess_input(x)
x = base_model(x, training=False)
x = global_average_layer(x)
x = tf.keras.layers.Dropout(0.2)(x)
outputs = prediction_layer(x)
model = tf.keras.Model(inputs, outputs)
मॉडल संकलित करें
प्रशिक्षण से पहले मॉडल को संकलित करें। चूंकि दो वर्ग हैं, tf.keras.losses.BinaryCrossentropy loss from_logits=True का उपयोग करें क्योंकि मॉडल एक रैखिक आउटपुट प्रदान करता है।
base_learning_rate = 0.0001
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=base_learning_rate),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 160, 160, 3)] 0
sequential (Sequential) (None, 160, 160, 3) 0
tf.math.truediv (TFOpLambda (None, 160, 160, 3) 0
)
tf.math.subtract (TFOpLambd (None, 160, 160, 3) 0
a)
mobilenetv2_1.00_160 (Funct (None, 5, 5, 1280) 2257984
ional)
global_average_pooling2d (G (None, 1280) 0
lobalAveragePooling2D)
dropout (Dropout) (None, 1280) 0
dense (Dense) (None, 1) 1281
=================================================================
Total params: 2,259,265
Trainable params: 1,281
Non-trainable params: 2,257,984
_________________________________________________________________
MobileNet में 2.5 मिलियन पैरामीटर जमे हुए हैं, लेकिन Dense लेयर में 1.2 हजार प्रशिक्षित करने योग्य पैरामीटर हैं। ये दो tf.Variable . चर वस्तुओं, भार और पूर्वाग्रहों के बीच विभाजित हैं।
len(model.trainable_variables)
2
मॉडल को प्रशिक्षित करें
10 युगों के प्रशिक्षण के बाद, आपको सत्यापन सेट पर ~94% सटीकता देखनी चाहिए।
initial_epochs = 10
loss0, accuracy0 = model.evaluate(validation_dataset)
26/26 [==============================] - 2s 16ms/step - loss: 0.7428 - accuracy: 0.5186
print("initial loss: {:.2f}".format(loss0))
print("initial accuracy: {:.2f}".format(accuracy0))
initial loss: 0.74 initial accuracy: 0.52
history = model.fit(train_dataset,
epochs=initial_epochs,
validation_data=validation_dataset)
Epoch 1/10 63/63 [==============================] - 4s 23ms/step - loss: 0.6804 - accuracy: 0.5680 - val_loss: 0.4981 - val_accuracy: 0.7054 Epoch 2/10 63/63 [==============================] - 1s 22ms/step - loss: 0.5044 - accuracy: 0.7170 - val_loss: 0.3598 - val_accuracy: 0.8144 Epoch 3/10 63/63 [==============================] - 1s 21ms/step - loss: 0.4109 - accuracy: 0.7845 - val_loss: 0.2810 - val_accuracy: 0.8861 Epoch 4/10 63/63 [==============================] - 1s 21ms/step - loss: 0.3285 - accuracy: 0.8445 - val_loss: 0.2256 - val_accuracy: 0.9208 Epoch 5/10 63/63 [==============================] - 1s 21ms/step - loss: 0.3108 - accuracy: 0.8555 - val_loss: 0.1986 - val_accuracy: 0.9307 Epoch 6/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2659 - accuracy: 0.8855 - val_loss: 0.1703 - val_accuracy: 0.9418 Epoch 7/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2459 - accuracy: 0.8935 - val_loss: 0.1495 - val_accuracy: 0.9517 Epoch 8/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2315 - accuracy: 0.8950 - val_loss: 0.1454 - val_accuracy: 0.9542 Epoch 9/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2204 - accuracy: 0.9030 - val_loss: 0.1326 - val_accuracy: 0.9592 Epoch 10/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2180 - accuracy: 0.9115 - val_loss: 0.1215 - val_accuracy: 0.9604
सीखने की अवस्था
आइए MobileNetV2 बेस मॉडल को फिक्स्ड फीचर एक्सट्रैक्टर के रूप में उपयोग करते समय प्रशिक्षण और सत्यापन सटीकता / हानि के सीखने की अवस्था पर एक नज़र डालें।
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.ylim([min(plt.ylim()),1])
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.ylim([0,1.0])
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
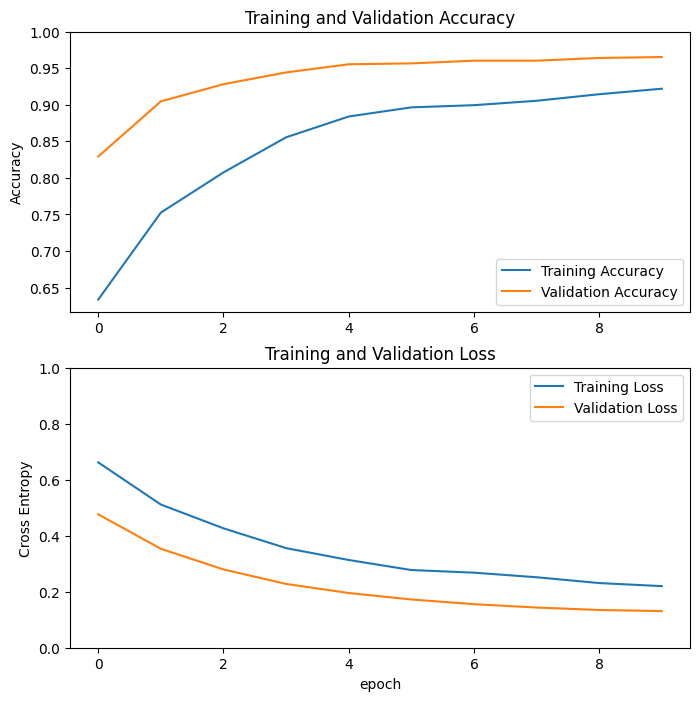
कुछ हद तक, यह इसलिए भी है क्योंकि प्रशिक्षण मेट्रिक्स एक युग के लिए औसत की रिपोर्ट करते हैं, जबकि सत्यापन मेट्रिक्स का मूल्यांकन युग के बाद किया जाता है, इसलिए सत्यापन मेट्रिक्स एक मॉडल को देखते हैं जो थोड़ा लंबा प्रशिक्षित होता है।
फ़ाइन ट्यूनिंग
सुविधा निष्कर्षण प्रयोग में, आप MobileNetV2 बेस मॉडल के शीर्ष पर केवल कुछ परतों को प्रशिक्षित कर रहे थे। प्रशिक्षण के दौरान पूर्व-प्रशिक्षित नेटवर्क के भार को अद्यतन नहीं किया गया था।
प्रदर्शन को और भी बढ़ाने का एक तरीका यह है कि आपके द्वारा जोड़े गए क्लासिफायरियर के प्रशिक्षण के साथ-साथ पूर्व-प्रशिक्षित मॉडल की शीर्ष परतों के भार को प्रशिक्षित (या "फाइन-ट्यून") किया जाए। प्रशिक्षण प्रक्रिया वजन को सामान्य फीचर मैप से विशेष रूप से डेटासेट से जुड़ी सुविधाओं के लिए बाध्य करेगी।
साथ ही, आपको संपूर्ण MobileNet मॉडल के बजाय कुछ शीर्ष परतों को फ़ाइन-ट्यून करने का प्रयास करना चाहिए। अधिकांश दृढ़ नेटवर्क में, एक परत जितनी ऊपर होती है, उतनी ही अधिक विशिष्ट होती है। पहली कुछ परतें बहुत ही सरल और सामान्य विशेषताएं सीखती हैं जो लगभग सभी प्रकार की छवियों को सामान्य बनाती हैं। जैसे-जैसे आप ऊपर जाते हैं, विशेषताएं उस डेटासेट के लिए अधिक विशिष्ट होती जा रही हैं जिस पर मॉडल को प्रशिक्षित किया गया था। फ़ाइन-ट्यूनिंग का लक्ष्य सामान्य शिक्षण को अधिलेखित करने के बजाय नए डेटासेट के साथ काम करने के लिए इन विशिष्ट सुविधाओं को अनुकूलित करना है।
मॉडल की शीर्ष परतों को अनफ्रीज करें
आपको बस base_model को अनफ्रीज करना है और नीचे की परतों को गैर-प्रशिक्षित करने के लिए सेट करना है। फिर, आपको मॉडल को फिर से संकलित करना चाहिए (इन परिवर्तनों को प्रभावी होने के लिए आवश्यक), और प्रशिक्षण फिर से शुरू करना चाहिए।
base_model.trainable = True
# Let's take a look to see how many layers are in the base model
print("Number of layers in the base model: ", len(base_model.layers))
# Fine-tune from this layer onwards
fine_tune_at = 100
# Freeze all the layers before the `fine_tune_at` layer
for layer in base_model.layers[:fine_tune_at]:
layer.trainable = False
Number of layers in the base model: 154
मॉडल संकलित करें
चूंकि आप बहुत बड़े मॉडल का प्रशिक्षण ले रहे हैं और पूर्व-प्रशिक्षित भारों को फिर से अपनाना चाहते हैं, इसलिए इस स्तर पर कम सीखने की दर का उपयोग करना महत्वपूर्ण है। अन्यथा, आपका मॉडल बहुत जल्दी ओवरफिट हो सकता है।
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer = tf.keras.optimizers.RMSprop(learning_rate=base_learning_rate/10),
metrics=['accuracy'])
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 160, 160, 3)] 0
sequential (Sequential) (None, 160, 160, 3) 0
tf.math.truediv (TFOpLambda (None, 160, 160, 3) 0
)
tf.math.subtract (TFOpLambd (None, 160, 160, 3) 0
a)
mobilenetv2_1.00_160 (Funct (None, 5, 5, 1280) 2257984
ional)
global_average_pooling2d (G (None, 1280) 0
lobalAveragePooling2D)
dropout (Dropout) (None, 1280) 0
dense (Dense) (None, 1) 1281
=================================================================
Total params: 2,259,265
Trainable params: 1,862,721
Non-trainable params: 396,544
_________________________________________________________________
len(model.trainable_variables)
56
मॉडल का प्रशिक्षण जारी रखें
यदि आपने पहले अभिसरण के लिए प्रशिक्षित किया है, तो यह कदम आपकी सटीकता में कुछ प्रतिशत अंक सुधार करेगा।
fine_tune_epochs = 10
total_epochs = initial_epochs + fine_tune_epochs
history_fine = model.fit(train_dataset,
epochs=total_epochs,
initial_epoch=history.epoch[-1],
validation_data=validation_dataset)
Epoch 10/20 63/63 [==============================] - 7s 40ms/step - loss: 0.1545 - accuracy: 0.9335 - val_loss: 0.0531 - val_accuracy: 0.9864 Epoch 11/20 63/63 [==============================] - 2s 28ms/step - loss: 0.1161 - accuracy: 0.9540 - val_loss: 0.0500 - val_accuracy: 0.9814 Epoch 12/20 63/63 [==============================] - 2s 28ms/step - loss: 0.1125 - accuracy: 0.9525 - val_loss: 0.0379 - val_accuracy: 0.9876 Epoch 13/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0891 - accuracy: 0.9625 - val_loss: 0.0472 - val_accuracy: 0.9889 Epoch 14/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0844 - accuracy: 0.9680 - val_loss: 0.0478 - val_accuracy: 0.9889 Epoch 15/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0857 - accuracy: 0.9645 - val_loss: 0.0354 - val_accuracy: 0.9839 Epoch 16/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0785 - accuracy: 0.9690 - val_loss: 0.0449 - val_accuracy: 0.9864 Epoch 17/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0669 - accuracy: 0.9740 - val_loss: 0.0375 - val_accuracy: 0.9839 Epoch 18/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0701 - accuracy: 0.9695 - val_loss: 0.0324 - val_accuracy: 0.9864 Epoch 19/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0636 - accuracy: 0.9760 - val_loss: 0.0465 - val_accuracy: 0.9790 Epoch 20/20 63/63 [==============================] - 2s 29ms/step - loss: 0.0585 - accuracy: 0.9765 - val_loss: 0.0392 - val_accuracy: 0.9851
आइए MobileNetV2 बेस मॉडल की अंतिम कुछ परतों को फाइन-ट्यूनिंग करते समय और उसके ऊपर क्लासिफायर को प्रशिक्षित करते समय प्रशिक्षण और सत्यापन सटीकता/नुकसान के सीखने की अवस्थाओं पर एक नज़र डालें। सत्यापन हानि प्रशिक्षण हानि की तुलना में बहुत अधिक है, इसलिए आपको कुछ ओवरफिटिंग मिल सकती है।
आपको कुछ ओवरफिटिंग भी मिल सकती है क्योंकि नया प्रशिक्षण सेट अपेक्षाकृत छोटा है और मूल MobileNetV2 डेटासेट के समान है।
मॉडल को ठीक करने के बाद सत्यापन सेट पर लगभग 98% सटीकता तक पहुंच जाता है।
acc += history_fine.history['accuracy']
val_acc += history_fine.history['val_accuracy']
loss += history_fine.history['loss']
val_loss += history_fine.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.ylim([0.8, 1])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.ylim([0, 1.0])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
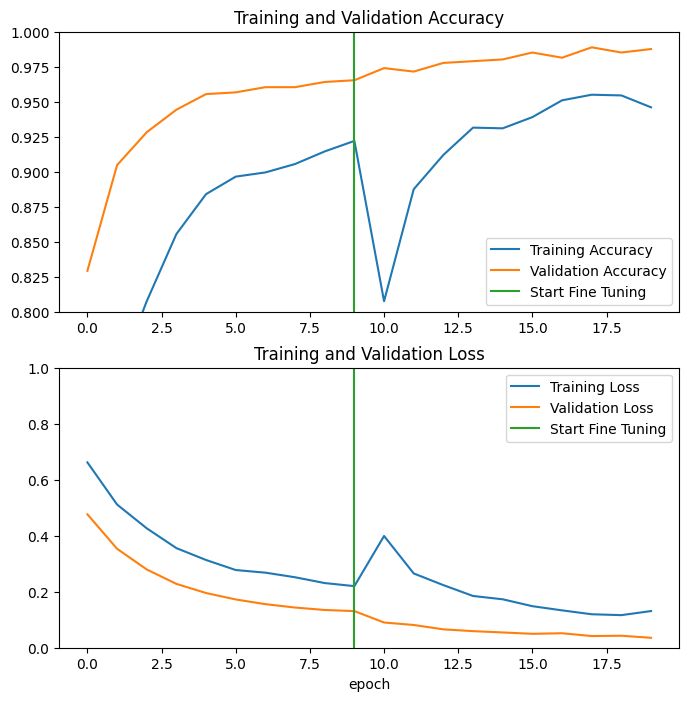
मूल्यांकन और भविष्यवाणी
अंत में आप परीक्षण सेट का उपयोग करके नए डेटा पर मॉडल के प्रदर्शन को सत्यापित कर सकते हैं।
loss, accuracy = model.evaluate(test_dataset)
print('Test accuracy :', accuracy)
6/6 [==============================] - 0s 13ms/step - loss: 0.0281 - accuracy: 0.9948 Test accuracy : 0.9947916865348816
और अब आप यह अनुमान लगाने के लिए इस मॉडल का उपयोग करने के लिए पूरी तरह तैयार हैं कि आपका पालतू बिल्ली है या कुत्ता।
# Retrieve a batch of images from the test set
image_batch, label_batch = test_dataset.as_numpy_iterator().next()
predictions = model.predict_on_batch(image_batch).flatten()
# Apply a sigmoid since our model returns logits
predictions = tf.nn.sigmoid(predictions)
predictions = tf.where(predictions < 0.5, 0, 1)
print('Predictions:\n', predictions.numpy())
print('Labels:\n', label_batch)
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image_batch[i].astype("uint8"))
plt.title(class_names[predictions[i]])
plt.axis("off")
Predictions: [0 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 0 0 0 1 0 1 0 0 1 1 1 0 0 0 1 0] Labels: [0 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 0 0 0 1 0 1 0 0 1 1 1 0 0 0 1 0]

सारांश
फीचर निष्कर्षण के लिए पूर्व-प्रशिक्षित मॉडल का उपयोग करना : छोटे डेटासेट के साथ काम करते समय, एक ही डोमेन में बड़े डेटासेट पर प्रशिक्षित मॉडल द्वारा सीखी गई सुविधाओं का लाभ उठाना एक आम बात है। यह पूर्व-प्रशिक्षित मॉडल को तुरंत चालू करके और शीर्ष पर पूरी तरह से जुड़े क्लासिफायरियर को जोड़कर किया जाता है। पूर्व-प्रशिक्षित मॉडल "जमे हुए" है और प्रशिक्षण के दौरान केवल क्लासिफायरियर के वजन को अपडेट किया जाता है। इस मामले में, दृढ़ आधार ने प्रत्येक छवि से जुड़ी सभी विशेषताओं को निकाला और आपने केवल एक क्लासिफायरियर को प्रशिक्षित किया जो निकाले गए सुविधाओं के सेट को दिए गए छवि वर्ग को निर्धारित करता है।
पूर्व-प्रशिक्षित मॉडल को फाइन-ट्यूनिंग करना : प्रदर्शन को और बेहतर बनाने के लिए, कोई पूर्व-प्रशिक्षित मॉडल की शीर्ष-स्तरीय परतों को फ़ाइन-ट्यूनिंग के माध्यम से नए डेटासेट में पुनर्व्यवस्थित करना चाह सकता है। इस मामले में, आपने अपने वज़न को इस तरह ट्यून किया है कि आपके मॉडल ने डेटासेट के लिए विशिष्ट उच्च-स्तरीय विशेषताओं को सीखा है। इस तकनीक की सिफारिश आमतौर पर तब की जाती है जब प्रशिक्षण डेटासेट बड़ा होता है और मूल डेटासेट के समान होता है जिस पर पूर्व-प्रशिक्षित मॉडल को प्रशिक्षित किया गया था।
अधिक जानने के लिए, ट्रांसफर लर्निंग गाइड पर जाएं।
# MIT License
#
# Copyright (c) 2017 François Chollet # IGNORE_COPYRIGHT: cleared by OSS licensing
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.