
| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
في هذا البرنامج التعليمي ، ستتعلم كيفية تصنيف صور القطط والكلاب باستخدام نقل التعلم من شبكة مدربة مسبقًا.
النموذج المدرَّب مسبقًا عبارة عن شبكة محفوظة تم تدريبها مسبقًا على مجموعة بيانات كبيرة ، عادةً في مهمة تصنيف صور على نطاق واسع. إما أن تستخدم النموذج الذي تم اختباره مسبقًا كما هو أو تستخدم نقل التعلم لتخصيص هذا النموذج لمهمة معينة.
يتمثل الحدس الكامن وراء تعلم النقل لتصنيف الصور في أنه إذا تم تدريب نموذج على مجموعة بيانات كبيرة وعامة بدرجة كافية ، فإن هذا النموذج سيعمل بشكل فعال كنموذج عام للعالم المرئي. يمكنك بعد ذلك الاستفادة من خرائط الميزات المكتسبة هذه دون الحاجة إلى البدء من نقطة الصفر من خلال تدريب نموذج كبير على مجموعة بيانات كبيرة.
في هذا الكمبيوتر الدفتري ، ستجرب طريقتين لتخصيص نموذج تم اختباره مسبقًا:
استخراج الميزات: استخدم التمثيلات التي تعلمتها شبكة سابقة لاستخراج ميزات ذات مغزى من عينات جديدة. يمكنك ببساطة إضافة مصنف جديد ، والذي سيتم تدريبه من البداية ، فوق النموذج الذي تم اختباره مسبقًا بحيث يمكنك إعادة تعيين الغرض من خرائط الميزات التي تم تعلمها مسبقًا لمجموعة البيانات.
لا تحتاج إلى (إعادة) تدريب النموذج بأكمله. تحتوي الشبكة التلافيفية الأساسية بالفعل على ميزات مفيدة بشكل عام لتصنيف الصور. ومع ذلك ، فإن جزء التصنيف النهائي للنموذج المدروس خاص بمهمة التصنيف الأصلية ، وبالتالي فهو خاص بمجموعة الفئات التي تم تدريب النموذج عليها.
الضبط الدقيق: قم بإلغاء تجميد عدد قليل من الطبقات العليا لقاعدة نموذج مجمدة وقم بشكل مشترك بتدريب كل من طبقات المصنف المضافة حديثًا والطبقات الأخيرة من النموذج الأساسي. يتيح لنا ذلك "ضبط" تمثيلات الميزات ذات الترتيب الأعلى في النموذج الأساسي لجعلها أكثر صلة بالمهمة المحددة.
ستتبع سير عمل تعلم الآلة العام.
- افحص واستوعب البيانات
- قم ببناء خط أنابيب إدخال ، في هذه الحالة باستخدام Keras ImageDataGenerator
- يؤلف النموذج
- التحميل في النموذج الأساسي الجاهز (والأوزان الجاهزة)
- رص طبقات التصنيف في الأعلى
- تدريب النموذج
- تقييم النموذج
import matplotlib.pyplot as plt
import numpy as np
import os
import tensorflow as tf
معالجة البيانات
تنزيل البيانات
في هذا البرنامج التعليمي ، ستستخدم مجموعة بيانات تحتوي على عدة آلاف من صور القطط والكلاب. قم بتنزيل واستخراج ملف مضغوط يحتوي على الصور ، ثم قم بإنشاء tf.data.Dataset للتدريب والتحقق من الصحة باستخدام الأداة المساعدة tf.keras.utils.image_dataset_from_directory . يمكنك معرفة المزيد حول تحميل الصور في هذا البرنامج التعليمي .
_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'
path_to_zip = tf.keras.utils.get_file('cats_and_dogs.zip', origin=_URL, extract=True)
PATH = os.path.join(os.path.dirname(path_to_zip), 'cats_and_dogs_filtered')
train_dir = os.path.join(PATH, 'train')
validation_dir = os.path.join(PATH, 'validation')
BATCH_SIZE = 32
IMG_SIZE = (160, 160)
train_dataset = tf.keras.utils.image_dataset_from_directory(train_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
Downloading data from https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip 68608000/68606236 [==============================] - 1s 0us/step 68616192/68606236 [==============================] - 1s 0us/step Found 2000 files belonging to 2 classes.
validation_dataset = tf.keras.utils.image_dataset_from_directory(validation_dir,
shuffle=True,
batch_size=BATCH_SIZE,
image_size=IMG_SIZE)
Found 1000 files belonging to 2 classes.
اعرض الصور التسع الأولى والملصقات من مجموعة التدريب:
class_names = train_dataset.class_names
plt.figure(figsize=(10, 10))
for images, labels in train_dataset.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")

نظرًا لأن مجموعة البيانات الأصلية لا تحتوي على مجموعة اختبار ، فسوف تقوم بإنشاء واحدة. للقيام بذلك ، حدد عدد مجموعات البيانات المتاحة في مجموعة التحقق من الصحة باستخدام tf.data.experimental.cardinality ، ثم انقل 20٪ منها إلى مجموعة اختبار.
val_batches = tf.data.experimental.cardinality(validation_dataset)
test_dataset = validation_dataset.take(val_batches // 5)
validation_dataset = validation_dataset.skip(val_batches // 5)
print('Number of validation batches: %d' % tf.data.experimental.cardinality(validation_dataset))
print('Number of test batches: %d' % tf.data.experimental.cardinality(test_dataset))
Number of validation batches: 26 Number of test batches: 6
تكوين مجموعة البيانات للأداء
استخدم الجلب المسبق المخزن لتحميل الصور من القرص دون أن يصبح الإدخال / الإخراج محظورًا. لمعرفة المزيد حول هذه الطريقة ، راجع دليل أداء البيانات .
AUTOTUNE = tf.data.AUTOTUNE
train_dataset = train_dataset.prefetch(buffer_size=AUTOTUNE)
validation_dataset = validation_dataset.prefetch(buffer_size=AUTOTUNE)
test_dataset = test_dataset.prefetch(buffer_size=AUTOTUNE)
استخدام زيادة البيانات
عندما لا يكون لديك مجموعة بيانات صور كبيرة ، فمن الممارسات الجيدة إدخال تنوع العينة بشكل مصطنع من خلال تطبيق تحويلات عشوائية ، لكنها واقعية ، على صور التدريب ، مثل التدوير والتقليب الأفقي. يساعد هذا في تعريض النموذج لجوانب مختلفة من بيانات التدريب وتقليل فرط التجهيز . يمكنك معرفة المزيد حول زيادة البيانات في هذا البرنامج التعليمي .
data_augmentation = tf.keras.Sequential([
tf.keras.layers.RandomFlip('horizontal'),
tf.keras.layers.RandomRotation(0.2),
])
دعنا نطبق هذه الطبقات بشكل متكرر على نفس الصورة ونرى النتيجة.
for image, _ in train_dataset.take(1):
plt.figure(figsize=(10, 10))
first_image = image[0]
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
augmented_image = data_augmentation(tf.expand_dims(first_image, 0))
plt.imshow(augmented_image[0] / 255)
plt.axis('off')

إعادة قياس قيم البكسل
بعد قليل ، ستقوم بتنزيل tf.keras.applications.MobileNetV2 لاستخدامه كنموذج أساسي. يتوقع هذا النموذج قيم البكسل في [-1, 1] ، ولكن في هذه المرحلة ، تكون قيم البكسل في صورك في [0, 255] . لإعادة بيعها ، استخدم طريقة المعالجة المسبقة المضمنة في النموذج.
preprocess_input = tf.keras.applications.mobilenet_v2.preprocess_input
rescale = tf.keras.layers.Rescaling(1./127.5, offset=-1)
قم بإنشاء النموذج الأساسي من المجموعات المدربة مسبقًا
ستقوم بإنشاء النموذج الأساسي من نموذج MobileNet V2 المطور في Google. تم تدريب هذا مسبقًا على مجموعة بيانات ImageNet ، وهي مجموعة بيانات كبيرة تتكون من 1.4 مليون صورة و 1000 فئة. ImageNet هي مجموعة بيانات تدريب بحثي مع مجموعة متنوعة من الفئات مثل jackfruit syringe . ستساعدنا قاعدة المعرفة هذه في تصنيف القطط والكلاب من مجموعة البيانات الخاصة بنا.
أولاً ، تحتاج إلى اختيار طبقة MobileNet V2 التي ستستخدمها لاستخراج الميزات. طبقة التصنيف الأخيرة (في "الجزء العلوي" ، حيث تنتقل معظم الرسوم البيانية لنماذج التعلم الآلي من أسفل إلى أعلى) ليست مفيدة جدًا. بدلاً من ذلك ، ستتبع الممارسة الشائعة للاعتماد على الطبقة الأخيرة قبل عملية التسوية. تسمى هذه الطبقة "طبقة عنق الزجاجة". تحتفظ ميزات طبقة عنق الزجاجة بمزيد من العمومية مقارنةً بالطبقة النهائية / العلوية.
أولاً ، قم بإنشاء نموذج MobileNet V2 محمّل مسبقًا بأوزان مدربة على ImageNet. من خلال تحديد الوسيطة include_top = False ، فإنك تقوم بتحميل شبكة لا تتضمن طبقات التصنيف في الأعلى ، وهو أمر مثالي لاستخراج المعالم.
# Create the base model from the pre-trained model MobileNet V2
IMG_SHAPE = IMG_SIZE + (3,)
base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_160_no_top.h5 9412608/9406464 [==============================] - 0s 0us/step 9420800/9406464 [==============================] - 0s 0us/step
يقوم مستخرج الميزة هذا بتحويل كل صورة 160x160x3 إلى كتلة ميزات 5x5x1280 . دعونا نرى ما يفعله لمجموعة من الصور كمثال:
image_batch, label_batch = next(iter(train_dataset))
feature_batch = base_model(image_batch)
print(feature_batch.shape)
(32, 5, 5, 1280)
ميزة استخراج
في هذه الخطوة ، ستقوم بتجميد القاعدة التلافيفية التي تم إنشاؤها من الخطوة السابقة واستخدامها كمستخرج ميزة. بالإضافة إلى ذلك ، يمكنك إضافة مصنف فوقه وتدريب المصنف عالي المستوى.
تجميد القاعدة التلافيفية
من المهم تجميد القاعدة التلافيفية قبل تجميع النموذج وتدريبه. التجميد (عن طريق ضبط layer.trainable = False) يمنع الأوزان في طبقة معينة من التحديث أثناء التدريب. يحتوي trainable V2 على العديد من الطبقات ، لذا فإن تعيين علامة التدريب الخاصة بالنموذج بالكامل على False سيؤدي إلى تجميدها جميعًا.
base_model.trainable = False
ملاحظة مهمة حول طبقات BatchNormalization
تحتوي العديد من النماذج على طبقات tf.keras.layers.BatchNormalization . هذه الطبقة هي حالة خاصة ويجب اتخاذ الاحتياطات في سياق الضبط الدقيق ، كما هو موضح لاحقًا في هذا البرنامج التعليمي.
عند تعيين layer.trainable = False ، ستعمل طبقة BatchNormalization في وضع الاستنتاج ، ولن تقوم بتحديث إحصائيات المتوسط والتباين.
عندما تقوم بإلغاء تجميد نموذج يحتوي على طبقات BatchNormalization من أجل إجراء ضبط دقيق ، يجب أن تحتفظ بطبقات BatchNormalization في وضع الاستدلال بتمرير training = False عند استدعاء النموذج الأساسي. وإلا فإن التحديثات المطبقة على الأوزان غير القابلة للتدريب ستدمر ما تعلمه النموذج.
لمزيد من التفاصيل ، راجع دليل تعلم النقل .
# Let's take a look at the base model architecture
base_model.summary()
Model: "mobilenetv2_1.00_160"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 160, 160, 3 0 []
)]
Conv1 (Conv2D) (None, 80, 80, 32) 864 ['input_1[0][0]']
bn_Conv1 (BatchNormalization) (None, 80, 80, 32) 128 ['Conv1[0][0]']
Conv1_relu (ReLU) (None, 80, 80, 32) 0 ['bn_Conv1[0][0]']
expanded_conv_depthwise (Depth (None, 80, 80, 32) 288 ['Conv1_relu[0][0]']
wiseConv2D)
expanded_conv_depthwise_BN (Ba (None, 80, 80, 32) 128 ['expanded_conv_depthwise[0][0]']
tchNormalization)
expanded_conv_depthwise_relu ( (None, 80, 80, 32) 0 ['expanded_conv_depthwise_BN[0][0
ReLU) ]']
expanded_conv_project (Conv2D) (None, 80, 80, 16) 512 ['expanded_conv_depthwise_relu[0]
[0]']
expanded_conv_project_BN (Batc (None, 80, 80, 16) 64 ['expanded_conv_project[0][0]']
hNormalization)
block_1_expand (Conv2D) (None, 80, 80, 96) 1536 ['expanded_conv_project_BN[0][0]'
]
block_1_expand_BN (BatchNormal (None, 80, 80, 96) 384 ['block_1_expand[0][0]']
ization)
block_1_expand_relu (ReLU) (None, 80, 80, 96) 0 ['block_1_expand_BN[0][0]']
block_1_pad (ZeroPadding2D) (None, 81, 81, 96) 0 ['block_1_expand_relu[0][0]']
block_1_depthwise (DepthwiseCo (None, 40, 40, 96) 864 ['block_1_pad[0][0]']
nv2D)
block_1_depthwise_BN (BatchNor (None, 40, 40, 96) 384 ['block_1_depthwise[0][0]']
malization)
block_1_depthwise_relu (ReLU) (None, 40, 40, 96) 0 ['block_1_depthwise_BN[0][0]']
block_1_project (Conv2D) (None, 40, 40, 24) 2304 ['block_1_depthwise_relu[0][0]']
block_1_project_BN (BatchNorma (None, 40, 40, 24) 96 ['block_1_project[0][0]']
lization)
block_2_expand (Conv2D) (None, 40, 40, 144) 3456 ['block_1_project_BN[0][0]']
block_2_expand_BN (BatchNormal (None, 40, 40, 144) 576 ['block_2_expand[0][0]']
ization)
block_2_expand_relu (ReLU) (None, 40, 40, 144) 0 ['block_2_expand_BN[0][0]']
block_2_depthwise (DepthwiseCo (None, 40, 40, 144) 1296 ['block_2_expand_relu[0][0]']
nv2D)
block_2_depthwise_BN (BatchNor (None, 40, 40, 144) 576 ['block_2_depthwise[0][0]']
malization)
block_2_depthwise_relu (ReLU) (None, 40, 40, 144) 0 ['block_2_depthwise_BN[0][0]']
block_2_project (Conv2D) (None, 40, 40, 24) 3456 ['block_2_depthwise_relu[0][0]']
block_2_project_BN (BatchNorma (None, 40, 40, 24) 96 ['block_2_project[0][0]']
lization)
block_2_add (Add) (None, 40, 40, 24) 0 ['block_1_project_BN[0][0]',
'block_2_project_BN[0][0]']
block_3_expand (Conv2D) (None, 40, 40, 144) 3456 ['block_2_add[0][0]']
block_3_expand_BN (BatchNormal (None, 40, 40, 144) 576 ['block_3_expand[0][0]']
ization)
block_3_expand_relu (ReLU) (None, 40, 40, 144) 0 ['block_3_expand_BN[0][0]']
block_3_pad (ZeroPadding2D) (None, 41, 41, 144) 0 ['block_3_expand_relu[0][0]']
block_3_depthwise (DepthwiseCo (None, 20, 20, 144) 1296 ['block_3_pad[0][0]']
nv2D)
block_3_depthwise_BN (BatchNor (None, 20, 20, 144) 576 ['block_3_depthwise[0][0]']
malization)
block_3_depthwise_relu (ReLU) (None, 20, 20, 144) 0 ['block_3_depthwise_BN[0][0]']
block_3_project (Conv2D) (None, 20, 20, 32) 4608 ['block_3_depthwise_relu[0][0]']
block_3_project_BN (BatchNorma (None, 20, 20, 32) 128 ['block_3_project[0][0]']
lization)
block_4_expand (Conv2D) (None, 20, 20, 192) 6144 ['block_3_project_BN[0][0]']
block_4_expand_BN (BatchNormal (None, 20, 20, 192) 768 ['block_4_expand[0][0]']
ization)
block_4_expand_relu (ReLU) (None, 20, 20, 192) 0 ['block_4_expand_BN[0][0]']
block_4_depthwise (DepthwiseCo (None, 20, 20, 192) 1728 ['block_4_expand_relu[0][0]']
nv2D)
block_4_depthwise_BN (BatchNor (None, 20, 20, 192) 768 ['block_4_depthwise[0][0]']
malization)
block_4_depthwise_relu (ReLU) (None, 20, 20, 192) 0 ['block_4_depthwise_BN[0][0]']
block_4_project (Conv2D) (None, 20, 20, 32) 6144 ['block_4_depthwise_relu[0][0]']
block_4_project_BN (BatchNorma (None, 20, 20, 32) 128 ['block_4_project[0][0]']
lization)
block_4_add (Add) (None, 20, 20, 32) 0 ['block_3_project_BN[0][0]',
'block_4_project_BN[0][0]']
block_5_expand (Conv2D) (None, 20, 20, 192) 6144 ['block_4_add[0][0]']
block_5_expand_BN (BatchNormal (None, 20, 20, 192) 768 ['block_5_expand[0][0]']
ization)
block_5_expand_relu (ReLU) (None, 20, 20, 192) 0 ['block_5_expand_BN[0][0]']
block_5_depthwise (DepthwiseCo (None, 20, 20, 192) 1728 ['block_5_expand_relu[0][0]']
nv2D)
block_5_depthwise_BN (BatchNor (None, 20, 20, 192) 768 ['block_5_depthwise[0][0]']
malization)
block_5_depthwise_relu (ReLU) (None, 20, 20, 192) 0 ['block_5_depthwise_BN[0][0]']
block_5_project (Conv2D) (None, 20, 20, 32) 6144 ['block_5_depthwise_relu[0][0]']
block_5_project_BN (BatchNorma (None, 20, 20, 32) 128 ['block_5_project[0][0]']
lization)
block_5_add (Add) (None, 20, 20, 32) 0 ['block_4_add[0][0]',
'block_5_project_BN[0][0]']
block_6_expand (Conv2D) (None, 20, 20, 192) 6144 ['block_5_add[0][0]']
block_6_expand_BN (BatchNormal (None, 20, 20, 192) 768 ['block_6_expand[0][0]']
ization)
block_6_expand_relu (ReLU) (None, 20, 20, 192) 0 ['block_6_expand_BN[0][0]']
block_6_pad (ZeroPadding2D) (None, 21, 21, 192) 0 ['block_6_expand_relu[0][0]']
block_6_depthwise (DepthwiseCo (None, 10, 10, 192) 1728 ['block_6_pad[0][0]']
nv2D)
block_6_depthwise_BN (BatchNor (None, 10, 10, 192) 768 ['block_6_depthwise[0][0]']
malization)
block_6_depthwise_relu (ReLU) (None, 10, 10, 192) 0 ['block_6_depthwise_BN[0][0]']
block_6_project (Conv2D) (None, 10, 10, 64) 12288 ['block_6_depthwise_relu[0][0]']
block_6_project_BN (BatchNorma (None, 10, 10, 64) 256 ['block_6_project[0][0]']
lization)
block_7_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_6_project_BN[0][0]']
block_7_expand_BN (BatchNormal (None, 10, 10, 384) 1536 ['block_7_expand[0][0]']
ization)
block_7_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_7_expand_BN[0][0]']
block_7_depthwise (DepthwiseCo (None, 10, 10, 384) 3456 ['block_7_expand_relu[0][0]']
nv2D)
block_7_depthwise_BN (BatchNor (None, 10, 10, 384) 1536 ['block_7_depthwise[0][0]']
malization)
block_7_depthwise_relu (ReLU) (None, 10, 10, 384) 0 ['block_7_depthwise_BN[0][0]']
block_7_project (Conv2D) (None, 10, 10, 64) 24576 ['block_7_depthwise_relu[0][0]']
block_7_project_BN (BatchNorma (None, 10, 10, 64) 256 ['block_7_project[0][0]']
lization)
block_7_add (Add) (None, 10, 10, 64) 0 ['block_6_project_BN[0][0]',
'block_7_project_BN[0][0]']
block_8_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_7_add[0][0]']
block_8_expand_BN (BatchNormal (None, 10, 10, 384) 1536 ['block_8_expand[0][0]']
ization)
block_8_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_8_expand_BN[0][0]']
block_8_depthwise (DepthwiseCo (None, 10, 10, 384) 3456 ['block_8_expand_relu[0][0]']
nv2D)
block_8_depthwise_BN (BatchNor (None, 10, 10, 384) 1536 ['block_8_depthwise[0][0]']
malization)
block_8_depthwise_relu (ReLU) (None, 10, 10, 384) 0 ['block_8_depthwise_BN[0][0]']
block_8_project (Conv2D) (None, 10, 10, 64) 24576 ['block_8_depthwise_relu[0][0]']
block_8_project_BN (BatchNorma (None, 10, 10, 64) 256 ['block_8_project[0][0]']
lization)
block_8_add (Add) (None, 10, 10, 64) 0 ['block_7_add[0][0]',
'block_8_project_BN[0][0]']
block_9_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_8_add[0][0]']
block_9_expand_BN (BatchNormal (None, 10, 10, 384) 1536 ['block_9_expand[0][0]']
ization)
block_9_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_9_expand_BN[0][0]']
block_9_depthwise (DepthwiseCo (None, 10, 10, 384) 3456 ['block_9_expand_relu[0][0]']
nv2D)
block_9_depthwise_BN (BatchNor (None, 10, 10, 384) 1536 ['block_9_depthwise[0][0]']
malization)
block_9_depthwise_relu (ReLU) (None, 10, 10, 384) 0 ['block_9_depthwise_BN[0][0]']
block_9_project (Conv2D) (None, 10, 10, 64) 24576 ['block_9_depthwise_relu[0][0]']
block_9_project_BN (BatchNorma (None, 10, 10, 64) 256 ['block_9_project[0][0]']
lization)
block_9_add (Add) (None, 10, 10, 64) 0 ['block_8_add[0][0]',
'block_9_project_BN[0][0]']
block_10_expand (Conv2D) (None, 10, 10, 384) 24576 ['block_9_add[0][0]']
block_10_expand_BN (BatchNorma (None, 10, 10, 384) 1536 ['block_10_expand[0][0]']
lization)
block_10_expand_relu (ReLU) (None, 10, 10, 384) 0 ['block_10_expand_BN[0][0]']
block_10_depthwise (DepthwiseC (None, 10, 10, 384) 3456 ['block_10_expand_relu[0][0]']
onv2D)
block_10_depthwise_BN (BatchNo (None, 10, 10, 384) 1536 ['block_10_depthwise[0][0]']
rmalization)
block_10_depthwise_relu (ReLU) (None, 10, 10, 384) 0 ['block_10_depthwise_BN[0][0]']
block_10_project (Conv2D) (None, 10, 10, 96) 36864 ['block_10_depthwise_relu[0][0]']
block_10_project_BN (BatchNorm (None, 10, 10, 96) 384 ['block_10_project[0][0]']
alization)
block_11_expand (Conv2D) (None, 10, 10, 576) 55296 ['block_10_project_BN[0][0]']
block_11_expand_BN (BatchNorma (None, 10, 10, 576) 2304 ['block_11_expand[0][0]']
lization)
block_11_expand_relu (ReLU) (None, 10, 10, 576) 0 ['block_11_expand_BN[0][0]']
block_11_depthwise (DepthwiseC (None, 10, 10, 576) 5184 ['block_11_expand_relu[0][0]']
onv2D)
block_11_depthwise_BN (BatchNo (None, 10, 10, 576) 2304 ['block_11_depthwise[0][0]']
rmalization)
block_11_depthwise_relu (ReLU) (None, 10, 10, 576) 0 ['block_11_depthwise_BN[0][0]']
block_11_project (Conv2D) (None, 10, 10, 96) 55296 ['block_11_depthwise_relu[0][0]']
block_11_project_BN (BatchNorm (None, 10, 10, 96) 384 ['block_11_project[0][0]']
alization)
block_11_add (Add) (None, 10, 10, 96) 0 ['block_10_project_BN[0][0]',
'block_11_project_BN[0][0]']
block_12_expand (Conv2D) (None, 10, 10, 576) 55296 ['block_11_add[0][0]']
block_12_expand_BN (BatchNorma (None, 10, 10, 576) 2304 ['block_12_expand[0][0]']
lization)
block_12_expand_relu (ReLU) (None, 10, 10, 576) 0 ['block_12_expand_BN[0][0]']
block_12_depthwise (DepthwiseC (None, 10, 10, 576) 5184 ['block_12_expand_relu[0][0]']
onv2D)
block_12_depthwise_BN (BatchNo (None, 10, 10, 576) 2304 ['block_12_depthwise[0][0]']
rmalization)
block_12_depthwise_relu (ReLU) (None, 10, 10, 576) 0 ['block_12_depthwise_BN[0][0]']
block_12_project (Conv2D) (None, 10, 10, 96) 55296 ['block_12_depthwise_relu[0][0]']
block_12_project_BN (BatchNorm (None, 10, 10, 96) 384 ['block_12_project[0][0]']
alization)
block_12_add (Add) (None, 10, 10, 96) 0 ['block_11_add[0][0]',
'block_12_project_BN[0][0]']
block_13_expand (Conv2D) (None, 10, 10, 576) 55296 ['block_12_add[0][0]']
block_13_expand_BN (BatchNorma (None, 10, 10, 576) 2304 ['block_13_expand[0][0]']
lization)
block_13_expand_relu (ReLU) (None, 10, 10, 576) 0 ['block_13_expand_BN[0][0]']
block_13_pad (ZeroPadding2D) (None, 11, 11, 576) 0 ['block_13_expand_relu[0][0]']
block_13_depthwise (DepthwiseC (None, 5, 5, 576) 5184 ['block_13_pad[0][0]']
onv2D)
block_13_depthwise_BN (BatchNo (None, 5, 5, 576) 2304 ['block_13_depthwise[0][0]']
rmalization)
block_13_depthwise_relu (ReLU) (None, 5, 5, 576) 0 ['block_13_depthwise_BN[0][0]']
block_13_project (Conv2D) (None, 5, 5, 160) 92160 ['block_13_depthwise_relu[0][0]']
block_13_project_BN (BatchNorm (None, 5, 5, 160) 640 ['block_13_project[0][0]']
alization)
block_14_expand (Conv2D) (None, 5, 5, 960) 153600 ['block_13_project_BN[0][0]']
block_14_expand_BN (BatchNorma (None, 5, 5, 960) 3840 ['block_14_expand[0][0]']
lization)
block_14_expand_relu (ReLU) (None, 5, 5, 960) 0 ['block_14_expand_BN[0][0]']
block_14_depthwise (DepthwiseC (None, 5, 5, 960) 8640 ['block_14_expand_relu[0][0]']
onv2D)
block_14_depthwise_BN (BatchNo (None, 5, 5, 960) 3840 ['block_14_depthwise[0][0]']
rmalization)
block_14_depthwise_relu (ReLU) (None, 5, 5, 960) 0 ['block_14_depthwise_BN[0][0]']
block_14_project (Conv2D) (None, 5, 5, 160) 153600 ['block_14_depthwise_relu[0][0]']
block_14_project_BN (BatchNorm (None, 5, 5, 160) 640 ['block_14_project[0][0]']
alization)
block_14_add (Add) (None, 5, 5, 160) 0 ['block_13_project_BN[0][0]',
'block_14_project_BN[0][0]']
block_15_expand (Conv2D) (None, 5, 5, 960) 153600 ['block_14_add[0][0]']
block_15_expand_BN (BatchNorma (None, 5, 5, 960) 3840 ['block_15_expand[0][0]']
lization)
block_15_expand_relu (ReLU) (None, 5, 5, 960) 0 ['block_15_expand_BN[0][0]']
block_15_depthwise (DepthwiseC (None, 5, 5, 960) 8640 ['block_15_expand_relu[0][0]']
onv2D)
block_15_depthwise_BN (BatchNo (None, 5, 5, 960) 3840 ['block_15_depthwise[0][0]']
rmalization)
block_15_depthwise_relu (ReLU) (None, 5, 5, 960) 0 ['block_15_depthwise_BN[0][0]']
block_15_project (Conv2D) (None, 5, 5, 160) 153600 ['block_15_depthwise_relu[0][0]']
block_15_project_BN (BatchNorm (None, 5, 5, 160) 640 ['block_15_project[0][0]']
alization)
block_15_add (Add) (None, 5, 5, 160) 0 ['block_14_add[0][0]',
'block_15_project_BN[0][0]']
block_16_expand (Conv2D) (None, 5, 5, 960) 153600 ['block_15_add[0][0]']
block_16_expand_BN (BatchNorma (None, 5, 5, 960) 3840 ['block_16_expand[0][0]']
lization)
block_16_expand_relu (ReLU) (None, 5, 5, 960) 0 ['block_16_expand_BN[0][0]']
block_16_depthwise (DepthwiseC (None, 5, 5, 960) 8640 ['block_16_expand_relu[0][0]']
onv2D)
block_16_depthwise_BN (BatchNo (None, 5, 5, 960) 3840 ['block_16_depthwise[0][0]']
rmalization)
block_16_depthwise_relu (ReLU) (None, 5, 5, 960) 0 ['block_16_depthwise_BN[0][0]']
block_16_project (Conv2D) (None, 5, 5, 320) 307200 ['block_16_depthwise_relu[0][0]']
block_16_project_BN (BatchNorm (None, 5, 5, 320) 1280 ['block_16_project[0][0]']
alization)
Conv_1 (Conv2D) (None, 5, 5, 1280) 409600 ['block_16_project_BN[0][0]']
Conv_1_bn (BatchNormalization) (None, 5, 5, 1280) 5120 ['Conv_1[0][0]']
out_relu (ReLU) (None, 5, 5, 1280) 0 ['Conv_1_bn[0][0]']
==================================================================================================
Total params: 2,257,984
Trainable params: 0
Non-trainable params: 2,257,984
__________________________________________________________________________________________________
أضف رئيس التصنيف
لإنشاء تنبؤات من كتلة الميزات ، متوسط فوق المواقع المكانية 5x5 باستخدام طبقة tf.keras.layers.GlobalAveragePooling2D لتحويل الميزات إلى متجه واحد 1280 عنصر لكل صورة.
global_average_layer = tf.keras.layers.GlobalAveragePooling2D()
feature_batch_average = global_average_layer(feature_batch)
print(feature_batch_average.shape)
(32, 1280)
قم بتطبيق طبقة tf.keras.layers.Dense لتحويل هذه الميزات إلى توقع واحد لكل صورة. لا تحتاج إلى وظيفة التنشيط هنا لأنه سيتم التعامل مع هذا التوقع logit أو قيمة تنبؤ أولية. تتنبأ الأرقام الموجبة بالفئة 1 ، وتتنبأ الأرقام السالبة بالفئة 0.
prediction_layer = tf.keras.layers.Dense(1)
prediction_batch = prediction_layer(feature_batch_average)
print(prediction_batch.shape)
(32, 1)
قم ببناء نموذج من خلال ربط طبقات زيادة البيانات وإعادة القياس ونموذج القاعدة وطبقات مستخرج الميزات معًا باستخدام base_model Functional API . كما ذكرنا سابقًا ، استخدم training=False لأن نموذجنا يحتوي على طبقة BatchNormalization .
inputs = tf.keras.Input(shape=(160, 160, 3))
x = data_augmentation(inputs)
x = preprocess_input(x)
x = base_model(x, training=False)
x = global_average_layer(x)
x = tf.keras.layers.Dropout(0.2)(x)
outputs = prediction_layer(x)
model = tf.keras.Model(inputs, outputs)
تجميع النموذج
قم بتجميع النموذج قبل التدريب عليه. نظرًا لوجود فئتين ، استخدم tf.keras.losses.BinaryCrossentropy loss مع from_logits=True نظرًا لأن النموذج يوفر ناتجًا خطيًا.
base_learning_rate = 0.0001
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=base_learning_rate),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 160, 160, 3)] 0
sequential (Sequential) (None, 160, 160, 3) 0
tf.math.truediv (TFOpLambda (None, 160, 160, 3) 0
)
tf.math.subtract (TFOpLambd (None, 160, 160, 3) 0
a)
mobilenetv2_1.00_160 (Funct (None, 5, 5, 1280) 2257984
ional)
global_average_pooling2d (G (None, 1280) 0
lobalAveragePooling2D)
dropout (Dropout) (None, 1280) 0
dense (Dense) (None, 1) 1281
=================================================================
Total params: 2,259,265
Trainable params: 1,281
Non-trainable params: 2,257,984
_________________________________________________________________
تم تجميد 2.5 مليون متغير في MobileNet ، ولكن هناك 1.2 ألف معلمة قابلة للتدريب في الطبقة الكثيفة. وهي مقسمة بين كائنين tf.Variable هما الأوزان والتحيزات.
len(model.trainable_variables)
2
تدريب النموذج
بعد التدريب لمدة 10 فترات ، يجب أن ترى دقة تصل إلى 94٪ في مجموعة التحقق من الصحة.
initial_epochs = 10
loss0, accuracy0 = model.evaluate(validation_dataset)
26/26 [==============================] - 2s 16ms/step - loss: 0.7428 - accuracy: 0.5186
print("initial loss: {:.2f}".format(loss0))
print("initial accuracy: {:.2f}".format(accuracy0))
initial loss: 0.74 initial accuracy: 0.52
history = model.fit(train_dataset,
epochs=initial_epochs,
validation_data=validation_dataset)
Epoch 1/10 63/63 [==============================] - 4s 23ms/step - loss: 0.6804 - accuracy: 0.5680 - val_loss: 0.4981 - val_accuracy: 0.7054 Epoch 2/10 63/63 [==============================] - 1s 22ms/step - loss: 0.5044 - accuracy: 0.7170 - val_loss: 0.3598 - val_accuracy: 0.8144 Epoch 3/10 63/63 [==============================] - 1s 21ms/step - loss: 0.4109 - accuracy: 0.7845 - val_loss: 0.2810 - val_accuracy: 0.8861 Epoch 4/10 63/63 [==============================] - 1s 21ms/step - loss: 0.3285 - accuracy: 0.8445 - val_loss: 0.2256 - val_accuracy: 0.9208 Epoch 5/10 63/63 [==============================] - 1s 21ms/step - loss: 0.3108 - accuracy: 0.8555 - val_loss: 0.1986 - val_accuracy: 0.9307 Epoch 6/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2659 - accuracy: 0.8855 - val_loss: 0.1703 - val_accuracy: 0.9418 Epoch 7/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2459 - accuracy: 0.8935 - val_loss: 0.1495 - val_accuracy: 0.9517 Epoch 8/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2315 - accuracy: 0.8950 - val_loss: 0.1454 - val_accuracy: 0.9542 Epoch 9/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2204 - accuracy: 0.9030 - val_loss: 0.1326 - val_accuracy: 0.9592 Epoch 10/10 63/63 [==============================] - 1s 21ms/step - loss: 0.2180 - accuracy: 0.9115 - val_loss: 0.1215 - val_accuracy: 0.9604
منحنيات التعلم
دعنا نلقي نظرة على منحنيات التعلم الخاصة بالتدريب ودقة / خسارة التحقق من الصحة عند استخدام النموذج الأساسي MobileNetV2 كمستخرج ميزة ثابتة.
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.ylim([min(plt.ylim()),1])
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.ylim([0,1.0])
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
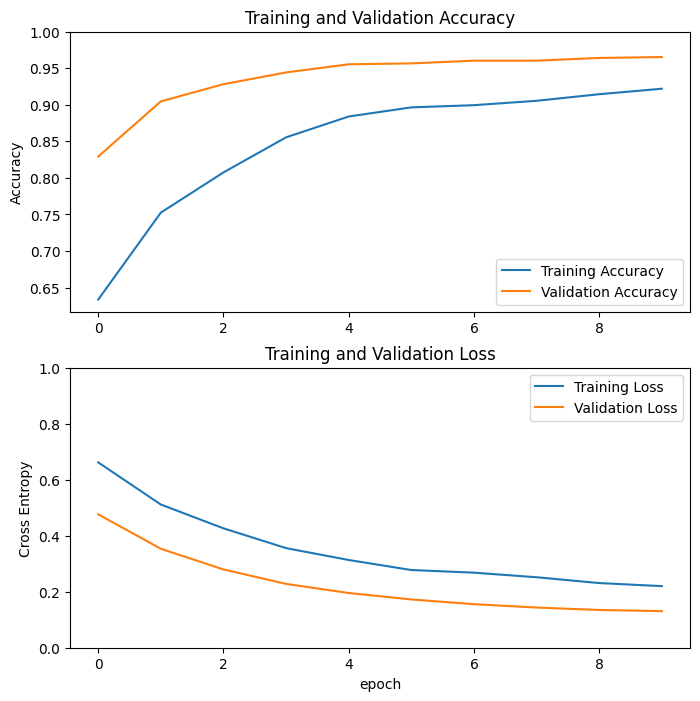
إلى حد أقل ، يرجع ذلك أيضًا إلى أن مقاييس التدريب تشير إلى متوسط فترة ما ، بينما يتم تقييم مقاييس التحقق من الصحة بعد هذه الحقبة ، لذلك ترى مقاييس التحقق نموذجًا تم تدريبه لفترة أطول قليلاً.
الكون المثالى
في تجربة استخراج الميزات ، كنت تقوم فقط بتدريب بضع طبقات أعلى نموذج أساسي لـ MobileNetV2. لم يتم تحديث أوزان الشبكة المدربة مسبقًا أثناء التدريب.
تتمثل إحدى طرق زيادة الأداء بشكل أكبر في التدريب (أو "الضبط الدقيق") لأوزان الطبقات العليا للنموذج المدرب مسبقًا جنبًا إلى جنب مع تدريب المصنف الذي أضفته. ستجبر عملية التدريب على ضبط الأوزان من خرائط المعالم العامة إلى الميزات المرتبطة على وجه التحديد بمجموعة البيانات.
أيضًا ، يجب أن تحاول ضبط عدد صغير من الطبقات العليا بدلاً من طراز MobileNet بالكامل. في معظم الشبكات التلافيفية ، كلما كانت الطبقة أعلى ، كلما كانت أكثر تخصصًا. تتعلم الطبقات القليلة الأولى ميزات بسيطة جدًا وعامة تُعمم على جميع أنواع الصور تقريبًا. كلما تقدمت إلى مستوى أعلى ، أصبحت الميزات أكثر تحديدًا لمجموعة البيانات التي تم تدريب النموذج عليها. الهدف من الضبط الدقيق هو تكييف هذه الميزات المتخصصة للعمل مع مجموعة البيانات الجديدة ، بدلاً من الكتابة فوق التعلم العام.
قم بإلغاء تجميد الطبقات العليا من النموذج
كل ما عليك فعله هو إلغاء تجميد base_model وتعيين الطبقات السفلية لتكون غير قابلة للتدريب. بعد ذلك ، يجب إعادة ترجمة النموذج (ضروري حتى تصبح هذه التغييرات سارية المفعول) ، واستئناف التدريب.
base_model.trainable = True
# Let's take a look to see how many layers are in the base model
print("Number of layers in the base model: ", len(base_model.layers))
# Fine-tune from this layer onwards
fine_tune_at = 100
# Freeze all the layers before the `fine_tune_at` layer
for layer in base_model.layers[:fine_tune_at]:
layer.trainable = False
Number of layers in the base model: 154
تجميع النموذج
نظرًا لأنك تقوم بتدريب نموذج أكبر بكثير وترغب في إعادة تكييف الأوزان المعدة مسبقًا ، فمن المهم استخدام معدل تعلم أقل في هذه المرحلة. خلاف ذلك ، يمكن أن يزيد النموذج الخاص بك بسرعة كبيرة.
model.compile(loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
optimizer = tf.keras.optimizers.RMSprop(learning_rate=base_learning_rate/10),
metrics=['accuracy'])
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) [(None, 160, 160, 3)] 0
sequential (Sequential) (None, 160, 160, 3) 0
tf.math.truediv (TFOpLambda (None, 160, 160, 3) 0
)
tf.math.subtract (TFOpLambd (None, 160, 160, 3) 0
a)
mobilenetv2_1.00_160 (Funct (None, 5, 5, 1280) 2257984
ional)
global_average_pooling2d (G (None, 1280) 0
lobalAveragePooling2D)
dropout (Dropout) (None, 1280) 0
dense (Dense) (None, 1) 1281
=================================================================
Total params: 2,259,265
Trainable params: 1,862,721
Non-trainable params: 396,544
_________________________________________________________________
len(model.trainable_variables)
56
استمر في تدريب النموذج
إذا كنت قد تدربت على التقارب في وقت سابق ، فستعمل هذه الخطوة على تحسين الدقة ببضع نقاط مئوية.
fine_tune_epochs = 10
total_epochs = initial_epochs + fine_tune_epochs
history_fine = model.fit(train_dataset,
epochs=total_epochs,
initial_epoch=history.epoch[-1],
validation_data=validation_dataset)
Epoch 10/20 63/63 [==============================] - 7s 40ms/step - loss: 0.1545 - accuracy: 0.9335 - val_loss: 0.0531 - val_accuracy: 0.9864 Epoch 11/20 63/63 [==============================] - 2s 28ms/step - loss: 0.1161 - accuracy: 0.9540 - val_loss: 0.0500 - val_accuracy: 0.9814 Epoch 12/20 63/63 [==============================] - 2s 28ms/step - loss: 0.1125 - accuracy: 0.9525 - val_loss: 0.0379 - val_accuracy: 0.9876 Epoch 13/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0891 - accuracy: 0.9625 - val_loss: 0.0472 - val_accuracy: 0.9889 Epoch 14/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0844 - accuracy: 0.9680 - val_loss: 0.0478 - val_accuracy: 0.9889 Epoch 15/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0857 - accuracy: 0.9645 - val_loss: 0.0354 - val_accuracy: 0.9839 Epoch 16/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0785 - accuracy: 0.9690 - val_loss: 0.0449 - val_accuracy: 0.9864 Epoch 17/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0669 - accuracy: 0.9740 - val_loss: 0.0375 - val_accuracy: 0.9839 Epoch 18/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0701 - accuracy: 0.9695 - val_loss: 0.0324 - val_accuracy: 0.9864 Epoch 19/20 63/63 [==============================] - 2s 28ms/step - loss: 0.0636 - accuracy: 0.9760 - val_loss: 0.0465 - val_accuracy: 0.9790 Epoch 20/20 63/63 [==============================] - 2s 29ms/step - loss: 0.0585 - accuracy: 0.9765 - val_loss: 0.0392 - val_accuracy: 0.9851
دعنا نلقي نظرة على منحنيات التعلم الخاصة بالتدريب ودقة / خسارة التحقق من الصحة عند ضبط الطبقات القليلة الأخيرة من نموذج MobileNetV2 الأساسي وتدريب المصنف فوقه. خسارة التحقق من الصحة أعلى بكثير من خسارة التدريب ، لذلك قد تحصل على بعض التجهيز الزائد.
قد تحصل أيضًا على بعض التجهيز الإضافي نظرًا لأن مجموعة التدريب الجديدة صغيرة نسبيًا وتشبه مجموعات بيانات MobileNetV2 الأصلية.
بعد الضبط الدقيق ، تصل دقة النموذج تقريبًا إلى 98٪ في مجموعة التحقق من الصحة.
acc += history_fine.history['accuracy']
val_acc += history_fine.history['val_accuracy']
loss += history_fine.history['loss']
val_loss += history_fine.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.ylim([0.8, 1])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.ylim([0, 1.0])
plt.plot([initial_epochs-1,initial_epochs-1],
plt.ylim(), label='Start Fine Tuning')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
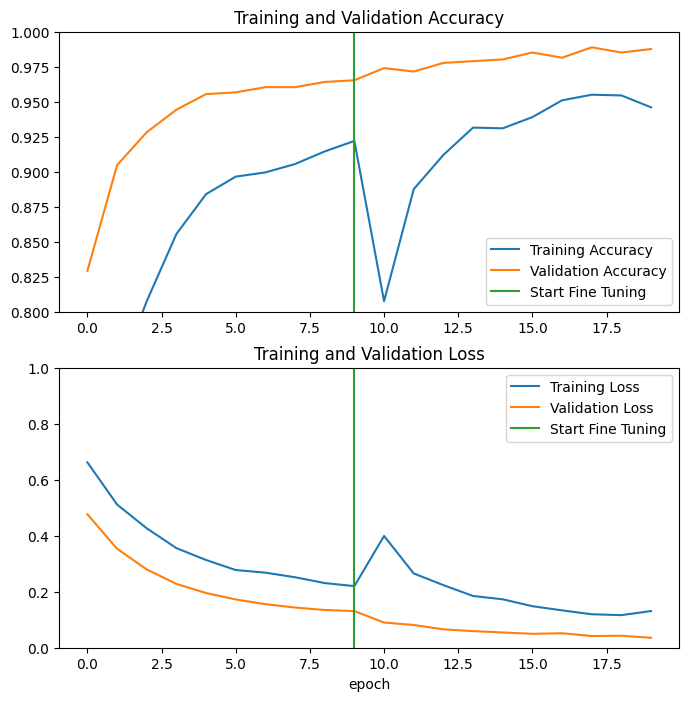
التقييم والتنبؤ
أخيرًا ، يمكنك التحقق من أداء النموذج على البيانات الجديدة باستخدام مجموعة الاختبار.
loss, accuracy = model.evaluate(test_dataset)
print('Test accuracy :', accuracy)
6/6 [==============================] - 0s 13ms/step - loss: 0.0281 - accuracy: 0.9948 Test accuracy : 0.9947916865348816
والآن أنت مستعد تمامًا لاستخدام هذا النموذج للتنبؤ بما إذا كان حيوانك الأليف قطة أم كلبًا.
# Retrieve a batch of images from the test set
image_batch, label_batch = test_dataset.as_numpy_iterator().next()
predictions = model.predict_on_batch(image_batch).flatten()
# Apply a sigmoid since our model returns logits
predictions = tf.nn.sigmoid(predictions)
predictions = tf.where(predictions < 0.5, 0, 1)
print('Predictions:\n', predictions.numpy())
print('Labels:\n', label_batch)
plt.figure(figsize=(10, 10))
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(image_batch[i].astype("uint8"))
plt.title(class_names[predictions[i]])
plt.axis("off")
Predictions: [0 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 0 0 0 1 0 1 0 0 1 1 1 0 0 0 1 0] Labels: [0 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 0 0 0 1 0 1 0 0 1 1 1 0 0 0 1 0]

ملخص
استخدام نموذج مُدرَّب مسبقًا لاستخراج الميزات : عند العمل مع مجموعة بيانات صغيرة ، من الشائع الاستفادة من الميزات التي تعلمها نموذج مُدرب على مجموعة بيانات أكبر في نفس المجال. يتم ذلك عن طريق إنشاء نموذج تم تدريبه مسبقًا وإضافة مصنف متصل بالكامل في الأعلى. يتم "تجميد" النموذج المدرب مسبقًا ويتم تحديث أوزان المصنف فقط أثناء التدريب. في هذه الحالة ، استخرجت القاعدة التلافيفية جميع الميزات المرتبطة بكل صورة وقمت للتو بتدريب المصنف الذي يحدد فئة الصورة بالنظر إلى مجموعة الميزات المستخرجة.
صقل نموذج تم تدريبه مسبقًا : لزيادة تحسين الأداء ، قد يرغب المرء في إعادة توظيف طبقات المستوى الأعلى من النماذج المدربة مسبقًا على مجموعة البيانات الجديدة عن طريق الضبط الدقيق. في هذه الحالة ، قمت بضبط الأوزان الخاصة بك بحيث تعلم نموذجك ميزات عالية المستوى خاصة بمجموعة البيانات. يوصى عادةً باستخدام هذه التقنية عندما تكون مجموعة بيانات التدريب كبيرة وتشبه إلى حد بعيد مجموعة البيانات الأصلية التي تم تدريب النموذج المدرب مسبقًا عليها.
لمعرفة المزيد ، قم بزيارة دليل نقل التعلم .
# MIT License
#
# Copyright (c) 2017 François Chollet # IGNORE_COPYRIGHT: cleared by OSS licensing
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.