
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
این آموزش بر روی وظیفه تقسیم بندی تصویر با استفاده از U-Net اصلاح شده تمرکز دارد.
تقسیم بندی تصویر چیست؟
در یک کار طبقه بندی تصویر، شبکه یک برچسب (یا کلاس) به هر تصویر ورودی اختصاص می دهد. با این حال، فرض کنید می خواهید شکل آن شی را بدانید، کدام پیکسل متعلق به کدام شی است، و غیره. در این صورت می خواهید به هر پیکسل تصویر یک کلاس اختصاص دهید. این وظیفه به تقسیم بندی معروف است. یک مدل تقسیم بندی اطلاعات بسیار دقیق تری را در مورد تصویر برمی گرداند. بخشبندی تصویر کاربردهای زیادی در تصویربرداری پزشکی، خودروهای خودران و تصویربرداری ماهوارهای دارد.
این آموزش از مجموعه داده های حیوانات خانگی Oxford-IIIT استفاده می کند ( Parkhi et al, 2012 ). مجموعه داده شامل تصاویری از 37 نژاد حیوان خانگی، با 200 تصویر در هر نژاد است (هر کدام 100 تصویر در بخش های آموزشی و آزمایشی). هر تصویر شامل برچسبهای مربوطه و ماسکهای پیکسلی است. ماسک ها برچسب کلاس برای هر پیکسل هستند. به هر پیکسل یکی از سه دسته داده می شود:
- کلاس 1: پیکسل متعلق به حیوان خانگی.
- کلاس 2: پیکسل در حاشیه حیوان خانگی.
- کلاس 3: هیچ یک از موارد فوق/یک پیکسل اطراف.
pip install git+https://github.com/tensorflow/examples.git
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.models.pix2pix import pix2pix
from IPython.display import clear_output
import matplotlib.pyplot as plt
مجموعه داده Oxford-IIIT Pets را دانلود کنید
مجموعه داده از TensorFlow Datasets در دسترس است. ماسک های تقسیم بندی در نسخه 3+ گنجانده شده است.
dataset, info = tfds.load('oxford_iiit_pet:3.*.*', with_info=True)
علاوه بر این، مقادیر رنگ تصویر در محدوده [0,1] نرمال می شوند. در نهایت، همانطور که در بالا ذکر شد، پیکسلها در ماسک تقسیمبندی با یا {1، 2، 3} برچسبگذاری میشوند. برای راحتی کار، 1 را از ماسک تقسیم بندی کم کنید، در نتیجه برچسب هایی به دست می آیند: {0، 1، 2}.
def normalize(input_image, input_mask):
input_image = tf.cast(input_image, tf.float32) / 255.0
input_mask -= 1
return input_image, input_mask
def load_image(datapoint):
input_image = tf.image.resize(datapoint['image'], (128, 128))
input_mask = tf.image.resize(datapoint['segmentation_mask'], (128, 128))
input_image, input_mask = normalize(input_image, input_mask)
return input_image, input_mask
مجموعه داده از قبل شامل تقسیمهای آموزشی و آزمایشی مورد نیاز است، بنابراین به استفاده از تقسیمهای مشابه ادامه دهید.
TRAIN_LENGTH = info.splits['train'].num_examples
BATCH_SIZE = 64
BUFFER_SIZE = 1000
STEPS_PER_EPOCH = TRAIN_LENGTH // BATCH_SIZE
train_images = dataset['train'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
test_images = dataset['test'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
کلاس زیر با چرخاندن تصادفی یک تصویر، یک تقویت ساده را انجام می دهد. برای کسب اطلاعات بیشتر به آموزش تقویت تصویر بروید.
class Augment(tf.keras.layers.Layer):
def __init__(self, seed=42):
super().__init__()
# both use the same seed, so they'll make the same random changes.
self.augment_inputs = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
self.augment_labels = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
def call(self, inputs, labels):
inputs = self.augment_inputs(inputs)
labels = self.augment_labels(labels)
return inputs, labels
خط لوله ورودی را بسازید، پس از دسته بندی ورودی ها، Augmentation را اعمال کنید.
train_batches = (
train_images
.cache()
.shuffle(BUFFER_SIZE)
.batch(BATCH_SIZE)
.repeat()
.map(Augment())
.prefetch(buffer_size=tf.data.AUTOTUNE))
test_batches = test_images.batch(BATCH_SIZE)
یک نمونه تصویر و ماسک مربوط به آن را از مجموعه داده تجسم کنید.
def display(display_list):
plt.figure(figsize=(15, 15))
title = ['Input Image', 'True Mask', 'Predicted Mask']
for i in range(len(display_list)):
plt.subplot(1, len(display_list), i+1)
plt.title(title[i])
plt.imshow(tf.keras.utils.array_to_img(display_list[i]))
plt.axis('off')
plt.show()
for images, masks in train_batches.take(2):
sample_image, sample_mask = images[0], masks[0]
display([sample_image, sample_mask])
Corrupt JPEG data: 240 extraneous bytes before marker 0xd9 Corrupt JPEG data: premature end of data segment


2022-01-26 05:14:45.972101: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
مدل را تعریف کنید
مدل مورد استفاده در اینجا یک U-Net اصلاح شده است. U-Net از یک رمزگذار (downsampler) و رمزگشا (upsampler) تشکیل شده است. به منظور یادگیری ویژگی های قوی و کاهش تعداد پارامترهای قابل آموزش، از یک مدل از پیش آموزش دیده - MobileNetV2 - به عنوان رمزگذار استفاده خواهید کرد. برای رمزگشا، از بلوک upsample استفاده خواهید کرد، که قبلاً در مثال pix2pix در مخزن TensorFlow Examples پیاده سازی شده است. ( pix2pix: ترجمه تصویر به تصویر را با آموزش GAN شرطی در یک نوت بوک بررسی کنید.)
همانطور که گفته شد، رمزگذار یک مدل از پیش آموزش دیده MobileNetV2 خواهد بود که آماده و آماده استفاده در tf.keras.applications است. رمزگذار از خروجی های خاصی از لایه های میانی در مدل تشکیل شده است. توجه داشته باشید که رمزگذار در طول فرآیند آموزش آموزش نمی بیند.
base_model = tf.keras.applications.MobileNetV2(input_shape=[128, 128, 3], include_top=False)
# Use the activations of these layers
layer_names = [
'block_1_expand_relu', # 64x64
'block_3_expand_relu', # 32x32
'block_6_expand_relu', # 16x16
'block_13_expand_relu', # 8x8
'block_16_project', # 4x4
]
base_model_outputs = [base_model.get_layer(name).output for name in layer_names]
# Create the feature extraction model
down_stack = tf.keras.Model(inputs=base_model.input, outputs=base_model_outputs)
down_stack.trainable = False
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_128_no_top.h5 9412608/9406464 [==============================] - 0s 0us/step 9420800/9406464 [==============================] - 0s 0us/step
رمزگشا/نمونهبرگر به سادگی مجموعهای از بلوکهای نمونه بالاست که در نمونههای TensorFlow پیادهسازی شدهاند.
up_stack = [
pix2pix.upsample(512, 3), # 4x4 -> 8x8
pix2pix.upsample(256, 3), # 8x8 -> 16x16
pix2pix.upsample(128, 3), # 16x16 -> 32x32
pix2pix.upsample(64, 3), # 32x32 -> 64x64
]
def unet_model(output_channels:int):
inputs = tf.keras.layers.Input(shape=[128, 128, 3])
# Downsampling through the model
skips = down_stack(inputs)
x = skips[-1]
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
concat = tf.keras.layers.Concatenate()
x = concat([x, skip])
# This is the last layer of the model
last = tf.keras.layers.Conv2DTranspose(
filters=output_channels, kernel_size=3, strides=2,
padding='same') #64x64 -> 128x128
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
توجه داشته باشید که تعداد فیلترهای لایه آخر به تعداد output_channels شده است. این یک کانال خروجی در هر کلاس خواهد بود.
مدل را آموزش دهید
اکنون تنها کاری که باید انجام دهید این است که مدل را کامپایل و آموزش دهید.
از آنجایی که این یک مشکل طبقه بندی چند کلاسه است، از تابع ضرر tf.keras.losses.CategoricalCrossentropy با آرگومان from_logits روی True استفاده کنید، زیرا برچسب ها به جای بردارهای امتیاز برای هر پیکسل از هر کلاس، اعداد صحیح اسکالر هستند.
هنگام اجرای استنتاج، برچسب اختصاص داده شده به پیکسل کانالی است که بالاترین مقدار را دارد. این کاری است که تابع create_mask انجام می دهد.
OUTPUT_CLASSES = 3
model = unet_model(output_channels=OUTPUT_CLASSES)
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
نگاهی گذرا به معماری مدل حاصل کنید:
tf.keras.utils.plot_model(model, show_shapes=True)

مدل را امتحان کنید تا آنچه را که قبل از آموزش پیش بینی می کند بررسی کنید.
def create_mask(pred_mask):
pred_mask = tf.argmax(pred_mask, axis=-1)
pred_mask = pred_mask[..., tf.newaxis]
return pred_mask[0]
def show_predictions(dataset=None, num=1):
if dataset:
for image, mask in dataset.take(num):
pred_mask = model.predict(image)
display([image[0], mask[0], create_mask(pred_mask)])
else:
display([sample_image, sample_mask,
create_mask(model.predict(sample_image[tf.newaxis, ...]))])
show_predictions()

تماس برگشتی تعریف شده در زیر برای مشاهده چگونگی بهبود مدل در حین آموزش استفاده می شود.
class DisplayCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
clear_output(wait=True)
show_predictions()
print ('\nSample Prediction after epoch {}\n'.format(epoch+1))
EPOCHS = 20
VAL_SUBSPLITS = 5
VALIDATION_STEPS = info.splits['test'].num_examples//BATCH_SIZE//VAL_SUBSPLITS
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
validation_steps=VALIDATION_STEPS,
validation_data=test_batches,
callbacks=[DisplayCallback()])

Sample Prediction after epoch 20 57/57 [==============================] - 4s 62ms/step - loss: 0.1838 - accuracy: 0.9187 - val_loss: 0.2797 - val_accuracy: 0.8955
loss = model_history.history['loss']
val_loss = model_history.history['val_loss']
plt.figure()
plt.plot(model_history.epoch, loss, 'r', label='Training loss')
plt.plot(model_history.epoch, val_loss, 'bo', label='Validation loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss Value')
plt.ylim([0, 1])
plt.legend()
plt.show()
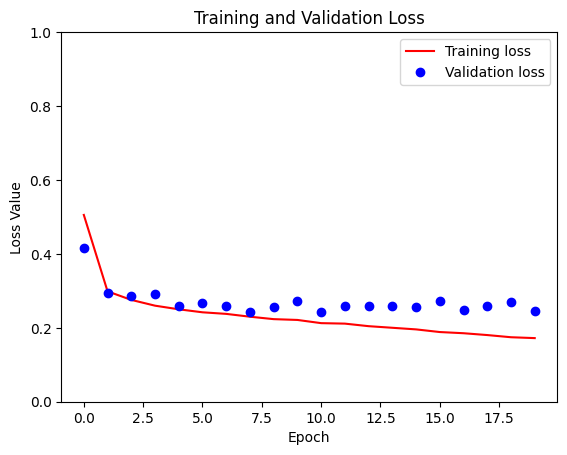
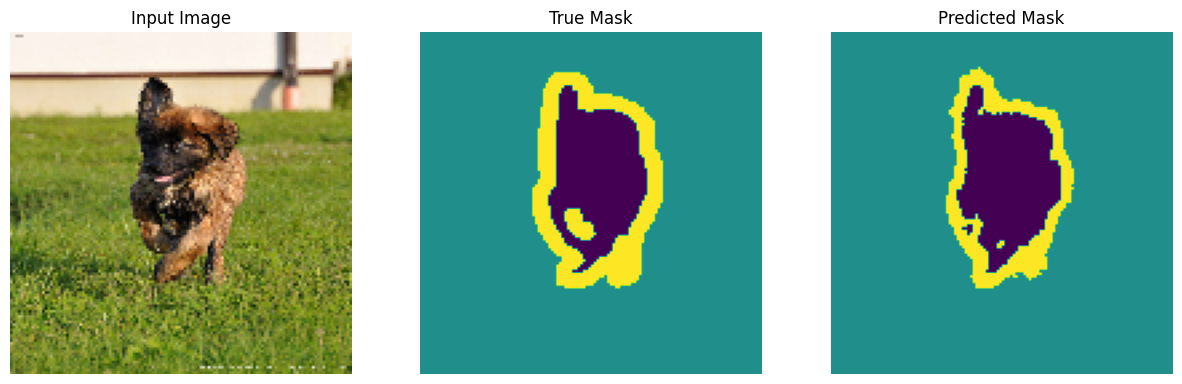
پیش بینی کنید
حالا چند پیشبینی کنید. به منظور صرفه جویی در زمان، تعداد دوره ها کم نگه داشته شد، اما برای دستیابی به نتایج دقیق تر، ممکن است این مقدار را بیشتر تنظیم کنید.
show_predictions(test_batches, 3)


اختیاری: کلاس های نامتعادل و وزن کلاس
مجموعه دادههای تقسیمبندی معنایی میتوانند بسیار نامتعادل باشند، به این معنی که پیکسلهای کلاس خاص میتوانند بیشتر در داخل تصاویر نسبت به کلاسهای دیگر وجود داشته باشند. از آنجایی که مشکلات بخشبندی را میتوان بهعنوان مشکلات طبقهبندی در هر پیکسل در نظر گرفت، میتوانید با مشکل عدم تعادل با وزن کردن تابع تلفات برای محاسبه آن مقابله کنید. این یک راه ساده و زیبا برای مقابله با این مشکل است. برای کسب اطلاعات بیشتر به آموزش طبقه بندی در مورد داده های نامتعادل مراجعه کنید.
برای جلوگیری از ابهام ، Model.fit از آرگومان class_weight برای ورودیهای با ابعاد 3+ پشتیبانی نمیکند.
try:
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
class_weight = {0:2.0, 1:2.0, 2:1.0})
assert False
except Exception as e:
print(f"Expected {type(e).__name__}: {e}")
Expected ValueError: `class_weight` not supported for 3+ dimensional targets.
بنابراین، در این مورد شما باید وزنه را خودتان اجرا کنید. این کار را با استفاده از وزنهای نمونه انجام میدهید: علاوه بر جفتهای (data, label) ، Model.fit (data, label, sample_weight) را نیز میپذیرد.
Model.fit sample_weight را به ضررها و معیارها منتشر می کند، که آرگومان sample_weight را نیز می پذیرند. وزن نمونه قبل از مرحله کاهش در مقدار نمونه ضرب می شود. مثلا:
label = [0,0]
prediction = [[-3., 0], [-3, 0]]
sample_weight = [1, 10]
loss = tf.losses.SparseCategoricalCrossentropy(from_logits=True,
reduction=tf.losses.Reduction.NONE)
loss(label, prediction, sample_weight).numpy()
array([ 3.0485873, 30.485874 ], dtype=float32)
بنابراین برای ساختن وزنهای نمونه برای این آموزش به تابعی نیاز دارید که یک جفت (data, label) را بگیرد و یک سهگانه (data, label, sample_weight) . جایی که sample_weight یک تصویر 1 کانالی است که وزن کلاس برای هر پیکسل را در بر می گیرد.
ساده ترین پیاده سازی ممکن استفاده از برچسب به عنوان یک فهرست در لیست class_weight است:
def add_sample_weights(image, label):
# The weights for each class, with the constraint that:
# sum(class_weights) == 1.0
class_weights = tf.constant([2.0, 2.0, 1.0])
class_weights = class_weights/tf.reduce_sum(class_weights)
# Create an image of `sample_weights` by using the label at each pixel as an
# index into the `class weights` .
sample_weights = tf.gather(class_weights, indices=tf.cast(label, tf.int32))
return image, label, sample_weights
عناصر داده حاصل هر کدام شامل 3 تصویر است:
train_batches.map(add_sample_weights).element_spec
(TensorSpec(shape=(None, 128, 128, 3), dtype=tf.float32, name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, name=None))
اکنون می توانید یک مدل را بر روی این مجموعه داده وزنی آموزش دهید:
weighted_model = unet_model(OUTPUT_CLASSES)
weighted_model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
weighted_model.fit(
train_batches.map(add_sample_weights),
epochs=1,
steps_per_epoch=10)
10/10 [==============================] - 3s 44ms/step - loss: 0.3099 - accuracy: 0.6063 <keras.callbacks.History at 0x7fa75d0f3e50>
مراحل بعدی
اکنون که متوجه شدید تقسیمبندی تصویر چیست و چگونه کار میکند، میتوانید این آموزش را با خروجیهای لایه میانی مختلف یا حتی مدلهای مختلف از پیش آموزش دیده امتحان کنید. همچنین میتوانید با آزمایش چالش پوشاندن تصویر Carvana که در Kaggle میزبانی شده است، خود را به چالش بکشید.
همچنین ممکن است بخواهید Tensorflow Object Detection API را برای مدل دیگری که میتوانید در دادههای خود دوباره آموزش دهید، ببینید. مدل های از پیش آموزش دیده در تنسورفلو هاب موجود هستند