
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
Bu eğitim, değiştirilmiş bir U-Net kullanarak görüntü segmentasyonu görevine odaklanır.
Görüntü segmentasyonu nedir?
Bir görüntü sınıflandırma görevinde ağ, her giriş görüntüsüne bir etiket (veya sınıf) atar. Ancak, o nesnenin şeklini, hangi pikselin hangi nesneye ait olduğunu vb. bilmek istediğinizi varsayalım. Bu durumda görüntünün her pikseline bir sınıf atamak isteyeceksiniz. Bu görev, segmentasyon olarak bilinir. Bir segmentasyon modeli, görüntü hakkında çok daha ayrıntılı bilgi verir. Görüntü bölütleme, tıbbi görüntülemede, sürücüsüz arabalarda ve uydu görüntülemede bunlardan birkaçını saymak gerekirse pek çok uygulamaya sahiptir.
Bu eğitim, Oxford-IIIT Pet Veri Kümesini kullanır ( Parhi ve diğerleri, 2012 ). Veri seti, cins başına 200 resim (eğitim ve test bölümlerinde her biri ~100) olmak üzere 37 evcil hayvan cinsinin resminden oluşur. Her görüntü, karşılık gelen etiketleri ve piksel bazında maskeleri içerir. Maskeler, her piksel için sınıf etiketleridir. Her piksele üç kategoriden biri verilir:
- Sınıf 1: Evcil hayvana ait piksel.
- Sınıf 2: Evcil hayvanı çevreleyen piksel.
- Sınıf 3: Yukarıdakilerin hiçbiri/çevreleyen bir piksel.
pip install git+https://github.com/tensorflow/examples.git
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.models.pix2pix import pix2pix
from IPython.display import clear_output
import matplotlib.pyplot as plt
Oxford-IIIT Pets veri setini indirin
Veri kümesi, TensorFlow Veri Kümeleri'nden edinilebilir . Segmentasyon maskeleri 3+ sürümüne dahil edilmiştir.
dataset, info = tfds.load('oxford_iiit_pet:3.*.*', with_info=True)
Ek olarak, görüntü renk değerleri [0,1] aralığına normalleştirilir. Son olarak, yukarıda belirtildiği gibi, segmentasyon maskesindeki pikseller ya {1, 2, 3} olarak etiketlenir. Kolaylık sağlamak için, segmentasyon maskesinden 1 çıkarın ve şu etiketlerle sonuçlanır: {0, 1, 2}.
def normalize(input_image, input_mask):
input_image = tf.cast(input_image, tf.float32) / 255.0
input_mask -= 1
return input_image, input_mask
def load_image(datapoint):
input_image = tf.image.resize(datapoint['image'], (128, 128))
input_mask = tf.image.resize(datapoint['segmentation_mask'], (128, 128))
input_image, input_mask = normalize(input_image, input_mask)
return input_image, input_mask
Veri kümesi zaten gerekli eğitim ve test bölümlerini içerir, bu nedenle aynı bölümleri kullanmaya devam edin.
TRAIN_LENGTH = info.splits['train'].num_examples
BATCH_SIZE = 64
BUFFER_SIZE = 1000
STEPS_PER_EPOCH = TRAIN_LENGTH // BATCH_SIZE
train_images = dataset['train'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
test_images = dataset['test'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
Aşağıdaki sınıf, bir görüntüyü rastgele çevirerek basit bir büyütme gerçekleştirir. Daha fazla bilgi edinmek için Görüntü büyütme eğitimine gidin.
class Augment(tf.keras.layers.Layer):
def __init__(self, seed=42):
super().__init__()
# both use the same seed, so they'll make the same random changes.
self.augment_inputs = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
self.augment_labels = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
def call(self, inputs, labels):
inputs = self.augment_inputs(inputs)
labels = self.augment_labels(labels)
return inputs, labels
Girdileri grupladıktan sonra Artırmayı uygulayarak girdi ardışık düzenini oluşturun.
train_batches = (
train_images
.cache()
.shuffle(BUFFER_SIZE)
.batch(BATCH_SIZE)
.repeat()
.map(Augment())
.prefetch(buffer_size=tf.data.AUTOTUNE))
test_batches = test_images.batch(BATCH_SIZE)
Veri kümesinden bir görüntü örneğini ve buna karşılık gelen maskesini görselleştirin.
def display(display_list):
plt.figure(figsize=(15, 15))
title = ['Input Image', 'True Mask', 'Predicted Mask']
for i in range(len(display_list)):
plt.subplot(1, len(display_list), i+1)
plt.title(title[i])
plt.imshow(tf.keras.utils.array_to_img(display_list[i]))
plt.axis('off')
plt.show()
for images, masks in train_batches.take(2):
sample_image, sample_mask = images[0], masks[0]
display([sample_image, sample_mask])
Corrupt JPEG data: 240 extraneous bytes before marker 0xd9 Corrupt JPEG data: premature end of data segment


2022-01-26 05:14:45.972101: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
Modeli tanımlayın
Burada kullanılan model değiştirilmiş bir U-Net'tir . Bir U-Net, bir kodlayıcı (alt örnekleyici) ve kod çözücüden (yukarı örnekleyici) oluşur. Sağlam özellikleri öğrenmek ve eğitilebilir parametre sayısını azaltmak için kodlayıcı olarak önceden eğitilmiş bir model - MobileNetV2 - kullanacaksınız. Kod çözücü için, TensorFlow Örnekleri deposundaki pix2pix örneğinde zaten uygulanmış olan örnekleme bloğunu kullanacaksınız. ( Pix2pix'e göz atın: Bir not defterinde koşullu GAN öğreticisiyle görüntüden görüntüye çeviri .)
Belirtildiği gibi, kodlayıcı tf.keras.applications içinde hazırlanmış ve kullanıma hazır önceden eğitilmiş bir tf.keras.applications modeli olacaktır. Kodlayıcı, modeldeki ara katmanlardan belirli çıktılardan oluşur. Kodlayıcının eğitim sürecinde eğitilmeyeceğini unutmayın.
base_model = tf.keras.applications.MobileNetV2(input_shape=[128, 128, 3], include_top=False)
# Use the activations of these layers
layer_names = [
'block_1_expand_relu', # 64x64
'block_3_expand_relu', # 32x32
'block_6_expand_relu', # 16x16
'block_13_expand_relu', # 8x8
'block_16_project', # 4x4
]
base_model_outputs = [base_model.get_layer(name).output for name in layer_names]
# Create the feature extraction model
down_stack = tf.keras.Model(inputs=base_model.input, outputs=base_model_outputs)
down_stack.trainable = False
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_128_no_top.h5 9412608/9406464 [==============================] - 0s 0us/step 9420800/9406464 [==============================] - 0s 0us/step
Kod çözücü/üst örnekleyici, TensorFlow örneklerinde uygulanan basit bir dizi üst örnekleme bloğudur.
up_stack = [
pix2pix.upsample(512, 3), # 4x4 -> 8x8
pix2pix.upsample(256, 3), # 8x8 -> 16x16
pix2pix.upsample(128, 3), # 16x16 -> 32x32
pix2pix.upsample(64, 3), # 32x32 -> 64x64
]
def unet_model(output_channels:int):
inputs = tf.keras.layers.Input(shape=[128, 128, 3])
# Downsampling through the model
skips = down_stack(inputs)
x = skips[-1]
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
concat = tf.keras.layers.Concatenate()
x = concat([x, skip])
# This is the last layer of the model
last = tf.keras.layers.Conv2DTranspose(
filters=output_channels, kernel_size=3, strides=2,
padding='same') #64x64 -> 128x128
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
Son katmandaki filtrelerin sayısının output_channels olarak ayarlandığını unutmayın. Bu, sınıf başına bir çıkış kanalı olacaktır.
Modeli eğit
Şimdi geriye sadece modeli derlemek ve eğitmek kalıyor.
Bu çok sınıflı bir sınıflandırma sorunu olduğundan, etiketler her sınıfın her pikseli için puan vektörleri yerine skaler tam sayılar olduğundan, from_logits bağımsız değişkeni True olarak ayarlanmış tf.keras.losses.CategoricalCrossentropy kayıp işlevini kullanın.
Çıkarım yapılırken piksele atanan etiket en yüksek değere sahip kanaldır. create_mask işlevinin yaptığı budur.
OUTPUT_CLASSES = 3
model = unet_model(output_channels=OUTPUT_CLASSES)
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Ortaya çıkan model mimarisine hızlıca bir göz atın:
tf.keras.utils.plot_model(model, show_shapes=True)

Eğitimden önce neyi tahmin ettiğini kontrol etmek için modeli deneyin.
def create_mask(pred_mask):
pred_mask = tf.argmax(pred_mask, axis=-1)
pred_mask = pred_mask[..., tf.newaxis]
return pred_mask[0]
def show_predictions(dataset=None, num=1):
if dataset:
for image, mask in dataset.take(num):
pred_mask = model.predict(image)
display([image[0], mask[0], create_mask(pred_mask)])
else:
display([sample_image, sample_mask,
create_mask(model.predict(sample_image[tf.newaxis, ...]))])
show_predictions()

Aşağıda tanımlanan geri arama, eğitim sırasında modelin nasıl geliştiğini gözlemlemek için kullanılır.
class DisplayCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
clear_output(wait=True)
show_predictions()
print ('\nSample Prediction after epoch {}\n'.format(epoch+1))
EPOCHS = 20
VAL_SUBSPLITS = 5
VALIDATION_STEPS = info.splits['test'].num_examples//BATCH_SIZE//VAL_SUBSPLITS
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
validation_steps=VALIDATION_STEPS,
validation_data=test_batches,
callbacks=[DisplayCallback()])

Sample Prediction after epoch 20 57/57 [==============================] - 4s 62ms/step - loss: 0.1838 - accuracy: 0.9187 - val_loss: 0.2797 - val_accuracy: 0.8955tutucu26 l10n-yer
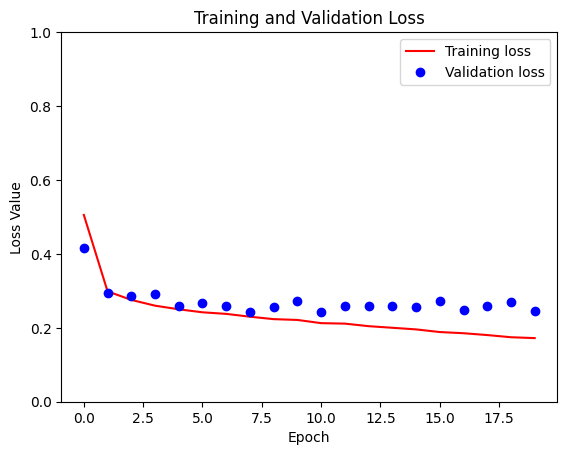
loss = model_history.history['loss']
val_loss = model_history.history['val_loss']
plt.figure()
plt.plot(model_history.epoch, loss, 'r', label='Training loss')
plt.plot(model_history.epoch, val_loss, 'bo', label='Validation loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss Value')
plt.ylim([0, 1])
plt.legend()
plt.show()
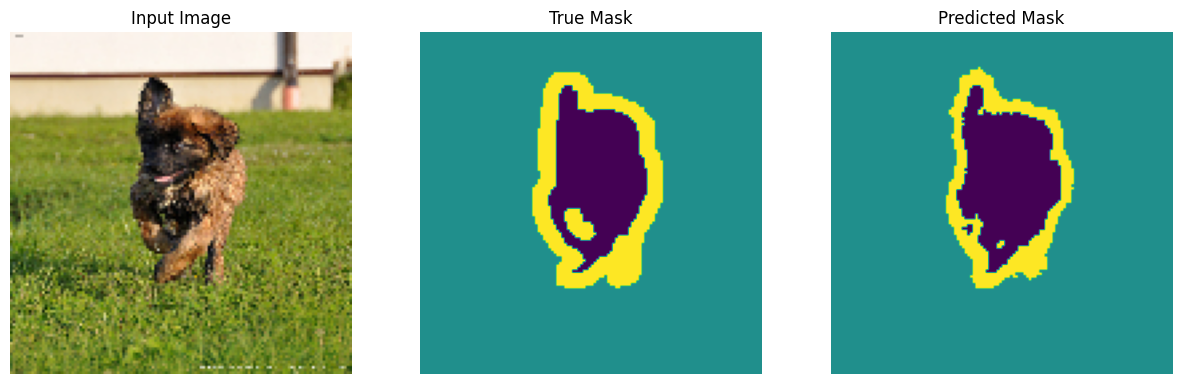
tahminlerde bulunun
Şimdi, bazı tahminlerde bulunun. Zamandan tasarruf amacıyla, dönem sayısı küçük tutulmuştur, ancak daha doğru sonuçlar elde etmek için bunu daha yükseğe ayarlayabilirsiniz.
show_predictions(test_batches, 3)


İsteğe bağlı: Dengesiz sınıflar ve sınıf ağırlıkları
Semantik segmentasyon veri kümeleri oldukça dengesiz olabilir, bu da belirli sınıf piksellerinin diğer sınıflardan daha fazla görüntülerin içinde bulunabileceği anlamına gelir. Segmentasyon sorunları piksel başına sınıflandırma sorunları olarak ele alınabileceğinden, bunu hesaba katmak için kayıp fonksiyonunu tartarak dengesizlik sorununu çözebilirsiniz. Bu sorunla başa çıkmanın basit ve zarif bir yolu. Daha fazla bilgi için Dengesiz verilerle ilgili sınıflandırma eğitimine bakın.
Belirsizliği önlemek için Model.fit , 3+ boyutlu girdiler için class_weight bağımsız değişkenini desteklemez.
try:
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
class_weight = {0:2.0, 1:2.0, 2:1.0})
assert False
except Exception as e:
print(f"Expected {type(e).__name__}: {e}")
Expected ValueError: `class_weight` not supported for 3+ dimensional targets.
Dolayısıyla, bu durumda ağırlıklandırmayı kendiniz uygulamanız gerekir. Bunu numune ağırlıklarını kullanarak yapacaksınız: Model.fit (data, label) çiftlerine ek olarak (veri, etiket, Model.fit (data, label, sample_weight) üçlülerini de kabul eder.
Model.fit , sample_weight , aynı zamanda bir sample_weight bağımsız değişkenini de kabul eden kayıplara ve metriklere yayar. Numune ağırlığı, indirgeme adımından önce numunenin değeri ile çarpılır. Örneğin:
label = [0,0]
prediction = [[-3., 0], [-3, 0]]
sample_weight = [1, 10]
loss = tf.losses.SparseCategoricalCrossentropy(from_logits=True,
reduction=tf.losses.Reduction.NONE)
loss(label, prediction, sample_weight).numpy()
array([ 3.0485873, 30.485874 ], dtype=float32)
Bu öğretici için örnek ağırlıklar yapmak için bir (data, label) çifti alan ve bir (data, label, sample_weight) üçlüsü döndüren bir işleve ihtiyacınız var. sample_weight , her piksel için sınıf ağırlığını içeren 1 kanallı bir görüntü olduğunda.
Mümkün olan en basit uygulama, etiketi bir class_weight listesine bir dizin olarak kullanmaktır:
def add_sample_weights(image, label):
# The weights for each class, with the constraint that:
# sum(class_weights) == 1.0
class_weights = tf.constant([2.0, 2.0, 1.0])
class_weights = class_weights/tf.reduce_sum(class_weights)
# Create an image of `sample_weights` by using the label at each pixel as an
# index into the `class weights` .
sample_weights = tf.gather(class_weights, indices=tf.cast(label, tf.int32))
return image, label, sample_weights
Ortaya çıkan veri kümesi öğelerinin her biri 3 görüntü içerir:
train_batches.map(add_sample_weights).element_spec
(TensorSpec(shape=(None, 128, 128, 3), dtype=tf.float32, name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, name=None))
Artık bu ağırlıklı veri kümesinde bir model eğitebilirsiniz:
weighted_model = unet_model(OUTPUT_CLASSES)
weighted_model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
weighted_model.fit(
train_batches.map(add_sample_weights),
epochs=1,
steps_per_epoch=10)
10/10 [==============================] - 3s 44ms/step - loss: 0.3099 - accuracy: 0.6063 <keras.callbacks.History at 0x7fa75d0f3e50>
Sonraki adımlar
Artık görüntü segmentasyonunun ne olduğunu ve nasıl çalıştığını anladığınıza göre, bu öğreticiyi farklı ara katman çıktıları ve hatta farklı önceden eğitilmiş modeller ile deneyebilirsiniz. Kaggle'da barındırılan Carvana görüntü maskeleme mücadelesini deneyerek de kendinize meydan okuyabilirsiniz.
Kendi verileriniz üzerinde yeniden eğitebileceğiniz başka bir model için Tensorflow Nesne Algılama API'sini de görmek isteyebilirsiniz. TensorFlow Hub'da önceden eğitilmiş modeller mevcuttur