
| | |  Lihat sumber di GitHub Lihat sumber di GitHub | |
Tutorial ini berfokus pada tugas segmentasi gambar, menggunakan U-Net yang dimodifikasi.
Apa itu segmentasi gambar?
Dalam tugas klasifikasi gambar, jaringan memberikan label (atau kelas) untuk setiap gambar masukan. Namun, misalkan Anda ingin mengetahui bentuk objek itu, piksel mana yang menjadi milik objek mana, dll. Dalam hal ini Anda ingin menetapkan kelas untuk setiap piksel gambar. Tugas ini dikenal sebagai segmentasi. Model segmentasi mengembalikan informasi yang jauh lebih detail tentang gambar. Segmentasi gambar memiliki banyak aplikasi dalam pencitraan medis, mobil self-driving dan pencitraan satelit untuk beberapa nama.
Tutorial ini menggunakan Dataset Hewan Peliharaan Oxford-IIIT ( Parkhi et al, 2012 ). Dataset terdiri dari gambar 37 breed hewan peliharaan, dengan 200 gambar per breed (~100 masing-masing dalam pemisahan pelatihan dan pengujian). Setiap gambar menyertakan label yang sesuai, dan topeng piksel. Masker adalah label kelas untuk setiap piksel. Setiap piksel diberikan salah satu dari tiga kategori:
- Kelas 1: Piksel milik hewan peliharaan.
- Kelas 2: Piksel yang berbatasan dengan hewan peliharaan.
- Kelas 3: Tak satu pun dari piksel di atas/di sekitarnya.
pip install git+https://github.com/tensorflow/examples.git
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.models.pix2pix import pix2pix
from IPython.display import clear_output
import matplotlib.pyplot as plt
Unduh kumpulan data Hewan Peliharaan Oxford-IIIT
Set data tersedia dari TensorFlow Datasets . Topeng segmentasi disertakan dalam versi 3+.
dataset, info = tfds.load('oxford_iiit_pet:3.*.*', with_info=True)
Selain itu, nilai warna gambar dinormalisasi ke kisaran [0,1] . Terakhir, seperti yang disebutkan di atas, piksel dalam topeng segmentasi diberi label {1, 2, 3}. Demi kenyamanan, kurangi 1 dari topeng segmentasi, sehingga menghasilkan label yang : {0, 1, 2}.
def normalize(input_image, input_mask):
input_image = tf.cast(input_image, tf.float32) / 255.0
input_mask -= 1
return input_image, input_mask
def load_image(datapoint):
input_image = tf.image.resize(datapoint['image'], (128, 128))
input_mask = tf.image.resize(datapoint['segmentation_mask'], (128, 128))
input_image, input_mask = normalize(input_image, input_mask)
return input_image, input_mask
Set data sudah berisi pemisahan pelatihan dan pengujian yang diperlukan, jadi terus gunakan pemisahan yang sama.
TRAIN_LENGTH = info.splits['train'].num_examples
BATCH_SIZE = 64
BUFFER_SIZE = 1000
STEPS_PER_EPOCH = TRAIN_LENGTH // BATCH_SIZE
train_images = dataset['train'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
test_images = dataset['test'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
Kelas berikut melakukan augmentasi sederhana dengan membalik gambar secara acak. Buka tutorial Augmentasi gambar untuk mempelajari lebih lanjut.
class Augment(tf.keras.layers.Layer):
def __init__(self, seed=42):
super().__init__()
# both use the same seed, so they'll make the same random changes.
self.augment_inputs = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
self.augment_labels = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
def call(self, inputs, labels):
inputs = self.augment_inputs(inputs)
labels = self.augment_labels(labels)
return inputs, labels
Bangun saluran input, menerapkan Augmentasi setelah mengelompokkan input.
train_batches = (
train_images
.cache()
.shuffle(BUFFER_SIZE)
.batch(BATCH_SIZE)
.repeat()
.map(Augment())
.prefetch(buffer_size=tf.data.AUTOTUNE))
test_batches = test_images.batch(BATCH_SIZE)
Visualisasikan contoh gambar dan topengnya yang sesuai dari kumpulan data.
def display(display_list):
plt.figure(figsize=(15, 15))
title = ['Input Image', 'True Mask', 'Predicted Mask']
for i in range(len(display_list)):
plt.subplot(1, len(display_list), i+1)
plt.title(title[i])
plt.imshow(tf.keras.utils.array_to_img(display_list[i]))
plt.axis('off')
plt.show()
for images, masks in train_batches.take(2):
sample_image, sample_mask = images[0], masks[0]
display([sample_image, sample_mask])
Corrupt JPEG data: 240 extraneous bytes before marker 0xd9 Corrupt JPEG data: premature end of data segment


2022-01-26 05:14:45.972101: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
Tentukan modelnya
Model yang digunakan di sini adalah U-Net yang dimodifikasi. Sebuah U-Net terdiri dari encoder (downsampler) dan decoder (upsampler). Untuk mempelajari fitur-fitur canggih dan mengurangi jumlah parameter yang dapat dilatih, Anda akan menggunakan model yang telah dilatih sebelumnya - MobileNetV2 - sebagai encoder. Untuk dekoder, Anda akan menggunakan blok upsample, yang sudah diimplementasikan dalam contoh pix2pix di repo Contoh TensorFlow. (Lihat pix2pix: Terjemahan gambar-ke-gambar dengan tutorial GAN bersyarat di buku catatan.)
Seperti yang disebutkan, encoder akan menjadi model MobileNetV2 yang telah dilatih sebelumnya yang disiapkan dan siap digunakan di tf.keras.applications . Encoder terdiri dari output spesifik dari lapisan perantara dalam model. Perhatikan bahwa pembuat enkode tidak akan dilatih selama proses pelatihan.
base_model = tf.keras.applications.MobileNetV2(input_shape=[128, 128, 3], include_top=False)
# Use the activations of these layers
layer_names = [
'block_1_expand_relu', # 64x64
'block_3_expand_relu', # 32x32
'block_6_expand_relu', # 16x16
'block_13_expand_relu', # 8x8
'block_16_project', # 4x4
]
base_model_outputs = [base_model.get_layer(name).output for name in layer_names]
# Create the feature extraction model
down_stack = tf.keras.Model(inputs=base_model.input, outputs=base_model_outputs)
down_stack.trainable = False
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_128_no_top.h5 9412608/9406464 [==============================] - 0s 0us/step 9420800/9406464 [==============================] - 0s 0us/step
Decoder/upsampler hanyalah serangkaian blok upsample yang diterapkan dalam contoh TensorFlow.
up_stack = [
pix2pix.upsample(512, 3), # 4x4 -> 8x8
pix2pix.upsample(256, 3), # 8x8 -> 16x16
pix2pix.upsample(128, 3), # 16x16 -> 32x32
pix2pix.upsample(64, 3), # 32x32 -> 64x64
]
def unet_model(output_channels:int):
inputs = tf.keras.layers.Input(shape=[128, 128, 3])
# Downsampling through the model
skips = down_stack(inputs)
x = skips[-1]
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
concat = tf.keras.layers.Concatenate()
x = concat([x, skip])
# This is the last layer of the model
last = tf.keras.layers.Conv2DTranspose(
filters=output_channels, kernel_size=3, strides=2,
padding='same') #64x64 -> 128x128
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
Perhatikan bahwa jumlah filter pada lapisan terakhir diatur ke jumlah output_channels . Ini akan menjadi satu saluran keluaran per kelas.
Latih modelnya
Sekarang, yang tersisa untuk dilakukan adalah mengkompilasi dan melatih model.
Karena ini adalah masalah klasifikasi multikelas, gunakan fungsi kehilangan tf.keras.losses.CategoricalCrossentropy dengan argumen from_logits disetel ke True , karena labelnya adalah bilangan bulat skalar, bukan vektor skor untuk setiap piksel dari setiap kelas.
Saat menjalankan inferensi, label yang ditetapkan ke piksel adalah saluran dengan nilai tertinggi. Inilah yang dilakukan fungsi create_mask .
OUTPUT_CLASSES = 3
model = unet_model(output_channels=OUTPUT_CLASSES)
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Lihat sekilas arsitektur model yang dihasilkan:
tf.keras.utils.plot_model(model, show_shapes=True)

Cobalah model untuk memeriksa apa yang diprediksinya sebelum pelatihan.
def create_mask(pred_mask):
pred_mask = tf.argmax(pred_mask, axis=-1)
pred_mask = pred_mask[..., tf.newaxis]
return pred_mask[0]
def show_predictions(dataset=None, num=1):
if dataset:
for image, mask in dataset.take(num):
pred_mask = model.predict(image)
display([image[0], mask[0], create_mask(pred_mask)])
else:
display([sample_image, sample_mask,
create_mask(model.predict(sample_image[tf.newaxis, ...]))])
show_predictions()

Callback yang didefinisikan di bawah ini digunakan untuk mengamati bagaimana model meningkat saat sedang berlatih.
class DisplayCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
clear_output(wait=True)
show_predictions()
print ('\nSample Prediction after epoch {}\n'.format(epoch+1))
EPOCHS = 20
VAL_SUBSPLITS = 5
VALIDATION_STEPS = info.splits['test'].num_examples//BATCH_SIZE//VAL_SUBSPLITS
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
validation_steps=VALIDATION_STEPS,
validation_data=test_batches,
callbacks=[DisplayCallback()])

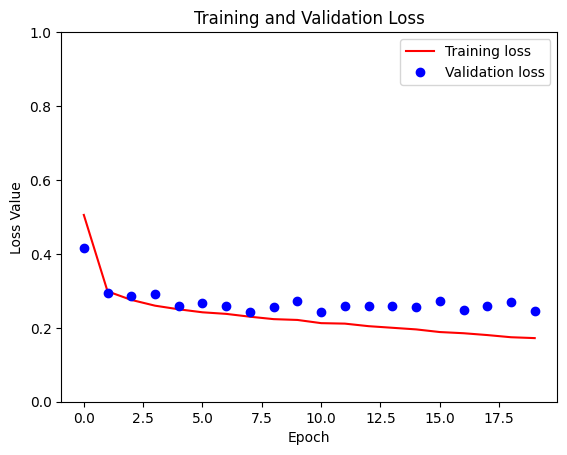
Sample Prediction after epoch 20 57/57 [==============================] - 4s 62ms/step - loss: 0.1838 - accuracy: 0.9187 - val_loss: 0.2797 - val_accuracy: 0.8955
loss = model_history.history['loss']
val_loss = model_history.history['val_loss']
plt.figure()
plt.plot(model_history.epoch, loss, 'r', label='Training loss')
plt.plot(model_history.epoch, val_loss, 'bo', label='Validation loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss Value')
plt.ylim([0, 1])
plt.legend()
plt.show()
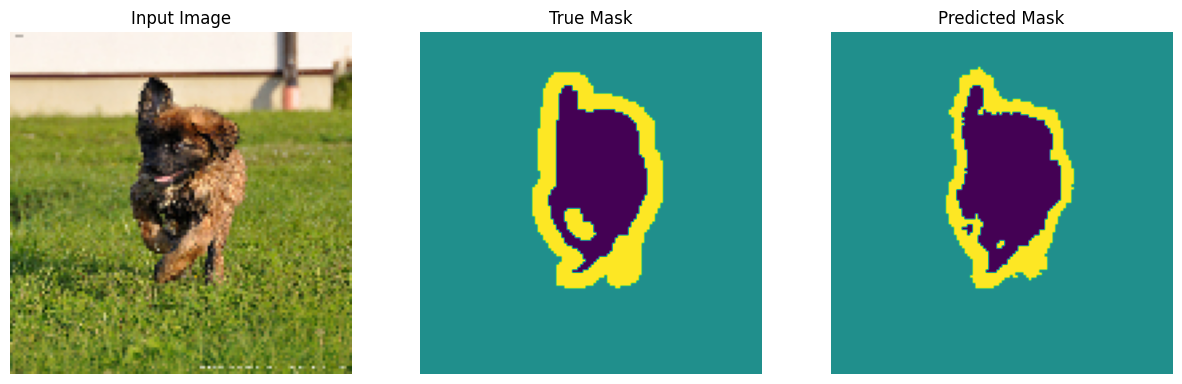
Membuat prediksi
Sekarang, buat beberapa prediksi. Demi menghemat waktu, jumlah epoch tetap kecil, tetapi Anda dapat mengatur ini lebih tinggi untuk mencapai hasil yang lebih akurat.
show_predictions(test_batches, 3)


Opsional: Kelas dan bobot kelas tidak seimbang
Kumpulan data segmentasi semantik bisa sangat tidak seimbang yang berarti bahwa piksel kelas tertentu dapat menampilkan lebih banyak gambar di dalam daripada kelas lainnya. Karena masalah segmentasi dapat diperlakukan sebagai masalah klasifikasi per piksel, Anda dapat menangani masalah ketidakseimbangan dengan menimbang fungsi kerugian untuk memperhitungkan hal ini. Ini adalah cara sederhana dan elegan untuk mengatasi masalah ini. Lihat tutorial Klasifikasi pada data tidak seimbang untuk mempelajari lebih lanjut.
Untuk menghindari ambiguitas , Model.fit tidak mendukung argumen class_weight untuk input dengan 3+ dimensi.
try:
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
class_weight = {0:2.0, 1:2.0, 2:1.0})
assert False
except Exception as e:
print(f"Expected {type(e).__name__}: {e}")
Expected ValueError: `class_weight` not supported for 3+ dimensional targets.
Jadi, dalam hal ini Anda perlu menerapkan pembobotan sendiri. Anda akan melakukannya menggunakan bobot sampel: Selain pasangan (data, label) , Model.fit juga menerima tiga kali lipat (data, label, sample_weight) .
Model.fit menyebarkan sample_weight ke kerugian dan metrik, yang juga menerima argumen sample_weight . Berat sampel dikalikan dengan nilai sampel sebelum langkah reduksi. Sebagai contoh:
label = [0,0]
prediction = [[-3., 0], [-3, 0]]
sample_weight = [1, 10]
loss = tf.losses.SparseCategoricalCrossentropy(from_logits=True,
reduction=tf.losses.Reduction.NONE)
loss(label, prediction, sample_weight).numpy()
array([ 3.0485873, 30.485874 ], dtype=float32)
Jadi untuk membuat bobot sampel untuk tutorial ini, Anda memerlukan fungsi yang mengambil pasangan (data, label) dan mengembalikan triple (data, label, sample_weight) . Dimana sample_weight adalah gambar 1 saluran yang berisi bobot kelas untuk setiap piksel.
Implementasi paling sederhana yang mungkin adalah menggunakan label sebagai indeks ke dalam daftar class_weight :
def add_sample_weights(image, label):
# The weights for each class, with the constraint that:
# sum(class_weights) == 1.0
class_weights = tf.constant([2.0, 2.0, 1.0])
class_weights = class_weights/tf.reduce_sum(class_weights)
# Create an image of `sample_weights` by using the label at each pixel as an
# index into the `class weights` .
sample_weights = tf.gather(class_weights, indices=tf.cast(label, tf.int32))
return image, label, sample_weights
Elemen kumpulan data yang dihasilkan masing-masing berisi 3 gambar:
train_batches.map(add_sample_weights).element_spec
(TensorSpec(shape=(None, 128, 128, 3), dtype=tf.float32, name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, name=None))
Sekarang Anda dapat melatih model pada kumpulan data berbobot ini:
weighted_model = unet_model(OUTPUT_CLASSES)
weighted_model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
weighted_model.fit(
train_batches.map(add_sample_weights),
epochs=1,
steps_per_epoch=10)
10/10 [==============================] - 3s 44ms/step - loss: 0.3099 - accuracy: 0.6063 <keras.callbacks.History at 0x7fa75d0f3e50>
Langkah selanjutnya
Sekarang setelah Anda memahami apa itu segmentasi gambar dan bagaimana cara kerjanya, Anda dapat mencoba tutorial ini dengan output lapisan menengah yang berbeda, atau bahkan model pra-latihan yang berbeda. Anda juga dapat menantang diri sendiri dengan mencoba tantangan penyamaran gambar Carvana yang diselenggarakan di Kaggle.
Anda mungkin juga ingin melihat API Deteksi Objek Tensorflow untuk model lain yang dapat Anda latih ulang pada data Anda sendiri. Model terlatih tersedia di TensorFlow Hub