
| | |  Visualizza l'origine su GitHub Visualizza l'origine su GitHub | |
Questo tutorial si concentra sull'attività di segmentazione delle immagini, utilizzando un U-Net modificato.
Che cos'è la segmentazione dell'immagine?
In un'attività di classificazione delle immagini, la rete assegna un'etichetta (o classe) a ciascuna immagine di input. Tuttavia, supponiamo di voler conoscere la forma di quell'oggetto, quale pixel appartiene a quale oggetto, ecc. In questo caso vorrai assegnare una classe a ciascun pixel dell'immagine. Questa attività è nota come segmentazione. Un modello di segmentazione restituisce informazioni molto più dettagliate sull'immagine. La segmentazione dell'immagine ha molte applicazioni nell'imaging medico, nelle auto a guida autonoma e nell'imaging satellitare, solo per citarne alcuni.
Questo tutorial utilizza l' Oxford-IIIT Pet Dataset ( Parchi et al, 2012 ). Il set di dati è costituito da immagini di 37 razze di animali domestici, con 200 immagini per razza (~100 ciascuna nelle divisioni di addestramento e test). Ogni immagine include le etichette corrispondenti e le maschere pixel-wise. Le maschere sono etichette di classe per ogni pixel. Ad ogni pixel viene assegnata una delle tre categorie:
- Classe 1: Pixel appartenenti all'animale.
- Classe 2: pixel confinante con l'animale.
- Classe 3: nessuno dei precedenti/un pixel circostante.
pip install git+https://github.com/tensorflow/examples.git
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.models.pix2pix import pix2pix
from IPython.display import clear_output
import matplotlib.pyplot as plt
Scarica il set di dati Oxford-IIIT Pets
Il set di dati è disponibile da TensorFlow Datasets . Le maschere di segmentazione sono incluse nella versione 3+.
dataset, info = tfds.load('oxford_iiit_pet:3.*.*', with_info=True)
Inoltre, i valori del colore dell'immagine vengono normalizzati nell'intervallo [0,1] . Infine, come accennato in precedenza, i pixel nella maschera di segmentazione sono etichettati come {1, 2, 3}. Per comodità, sottrai 1 dalla maschera di segmentazione, ottenendo etichette che sono: {0, 1, 2}.
def normalize(input_image, input_mask):
input_image = tf.cast(input_image, tf.float32) / 255.0
input_mask -= 1
return input_image, input_mask
def load_image(datapoint):
input_image = tf.image.resize(datapoint['image'], (128, 128))
input_mask = tf.image.resize(datapoint['segmentation_mask'], (128, 128))
input_image, input_mask = normalize(input_image, input_mask)
return input_image, input_mask
Il set di dati contiene già le divisioni di addestramento e test richieste, quindi continua a utilizzare le stesse divisioni.
TRAIN_LENGTH = info.splits['train'].num_examples
BATCH_SIZE = 64
BUFFER_SIZE = 1000
STEPS_PER_EPOCH = TRAIN_LENGTH // BATCH_SIZE
train_images = dataset['train'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
test_images = dataset['test'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
La classe seguente esegue un semplice aumento capovolgendo casualmente un'immagine. Vai al tutorial sull'aumento delle immagini per saperne di più.
class Augment(tf.keras.layers.Layer):
def __init__(self, seed=42):
super().__init__()
# both use the same seed, so they'll make the same random changes.
self.augment_inputs = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
self.augment_labels = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
def call(self, inputs, labels):
inputs = self.augment_inputs(inputs)
labels = self.augment_labels(labels)
return inputs, labels
Costruisci la pipeline di input, applicando l'Augmentation dopo aver raggruppato gli input.
train_batches = (
train_images
.cache()
.shuffle(BUFFER_SIZE)
.batch(BATCH_SIZE)
.repeat()
.map(Augment())
.prefetch(buffer_size=tf.data.AUTOTUNE))
test_batches = test_images.batch(BATCH_SIZE)
Visualizza un esempio di immagine e la maschera corrispondente dal set di dati.
def display(display_list):
plt.figure(figsize=(15, 15))
title = ['Input Image', 'True Mask', 'Predicted Mask']
for i in range(len(display_list)):
plt.subplot(1, len(display_list), i+1)
plt.title(title[i])
plt.imshow(tf.keras.utils.array_to_img(display_list[i]))
plt.axis('off')
plt.show()
for images, masks in train_batches.take(2):
sample_image, sample_mask = images[0], masks[0]
display([sample_image, sample_mask])
Corrupt JPEG data: 240 extraneous bytes before marker 0xd9 Corrupt JPEG data: premature end of data segment


2022-01-26 05:14:45.972101: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
Definisci il modello
Il modello qui utilizzato è un U-Net modificato. Una U-Net è composta da un encoder (downsampler) e un decoder (upsampler). Per apprendere funzionalità robuste e ridurre il numero di parametri addestrabili, utilizzerai un modello preaddestrato - MobileNetV2 - come codificatore. Per il decoder, utilizzerai il blocco upsample, che è già implementato nell'esempio pix2pix nel repository TensorFlow Examples. (Dai un'occhiata a pix2pix: traduzione da immagine a immagine con un tutorial GAN condizionale in un taccuino.)
Come accennato, l'encoder sarà un modello MobileNetV2 preaddestrato, preparato e pronto per l'uso in tf.keras.applications . L'encoder è costituito da output specifici dai livelli intermedi nel modello. Si noti che l'encoder non verrà addestrato durante il processo di addestramento.
base_model = tf.keras.applications.MobileNetV2(input_shape=[128, 128, 3], include_top=False)
# Use the activations of these layers
layer_names = [
'block_1_expand_relu', # 64x64
'block_3_expand_relu', # 32x32
'block_6_expand_relu', # 16x16
'block_13_expand_relu', # 8x8
'block_16_project', # 4x4
]
base_model_outputs = [base_model.get_layer(name).output for name in layer_names]
# Create the feature extraction model
down_stack = tf.keras.Model(inputs=base_model.input, outputs=base_model_outputs)
down_stack.trainable = False
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_128_no_top.h5 9412608/9406464 [==============================] - 0s 0us/step 9420800/9406464 [==============================] - 0s 0us/step
Il decoder/upsampler è semplicemente una serie di blocchi di upsample implementati negli esempi di TensorFlow.
up_stack = [
pix2pix.upsample(512, 3), # 4x4 -> 8x8
pix2pix.upsample(256, 3), # 8x8 -> 16x16
pix2pix.upsample(128, 3), # 16x16 -> 32x32
pix2pix.upsample(64, 3), # 32x32 -> 64x64
]
def unet_model(output_channels:int):
inputs = tf.keras.layers.Input(shape=[128, 128, 3])
# Downsampling through the model
skips = down_stack(inputs)
x = skips[-1]
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
concat = tf.keras.layers.Concatenate()
x = concat([x, skip])
# This is the last layer of the model
last = tf.keras.layers.Conv2DTranspose(
filters=output_channels, kernel_size=3, strides=2,
padding='same') #64x64 -> 128x128
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
Nota che il numero di filtri sull'ultimo livello è impostato sul numero di output_channels . Questo sarà un canale di output per classe.
Allena il modello
Ora, tutto ciò che resta da fare è compilare e addestrare il modello.
Poiché si tratta di un problema di classificazione multiclasse, utilizzare la funzione di perdita tf.keras.losses.CategoricalCrossentropy con l'argomento from_logits impostato su True , poiché le etichette sono numeri interi scalari anziché vettori di punteggi per ogni pixel di ogni classe.
Quando si esegue l'inferenza, l'etichetta assegnata al pixel è il canale con il valore più alto. Questo è ciò che sta facendo la funzione create_mask .
OUTPUT_CLASSES = 3
model = unet_model(output_channels=OUTPUT_CLASSES)
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Dai una rapida occhiata all'architettura del modello risultante:
tf.keras.utils.plot_model(model, show_shapes=True)

Prova il modello per verificare cosa prevede prima dell'allenamento.
def create_mask(pred_mask):
pred_mask = tf.argmax(pred_mask, axis=-1)
pred_mask = pred_mask[..., tf.newaxis]
return pred_mask[0]
def show_predictions(dataset=None, num=1):
if dataset:
for image, mask in dataset.take(num):
pred_mask = model.predict(image)
display([image[0], mask[0], create_mask(pred_mask)])
else:
display([sample_image, sample_mask,
create_mask(model.predict(sample_image[tf.newaxis, ...]))])
show_predictions()

Il callback definito di seguito viene utilizzato per osservare come il modello migliora durante l'addestramento.
class DisplayCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
clear_output(wait=True)
show_predictions()
print ('\nSample Prediction after epoch {}\n'.format(epoch+1))
EPOCHS = 20
VAL_SUBSPLITS = 5
VALIDATION_STEPS = info.splits['test'].num_examples//BATCH_SIZE//VAL_SUBSPLITS
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
validation_steps=VALIDATION_STEPS,
validation_data=test_batches,
callbacks=[DisplayCallback()])

Sample Prediction after epoch 20 57/57 [==============================] - 4s 62ms/step - loss: 0.1838 - accuracy: 0.9187 - val_loss: 0.2797 - val_accuracy: 0.8955
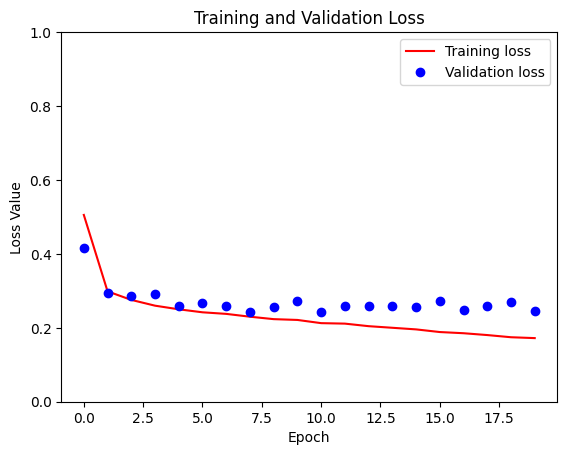
loss = model_history.history['loss']
val_loss = model_history.history['val_loss']
plt.figure()
plt.plot(model_history.epoch, loss, 'r', label='Training loss')
plt.plot(model_history.epoch, val_loss, 'bo', label='Validation loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss Value')
plt.ylim([0, 1])
plt.legend()
plt.show()
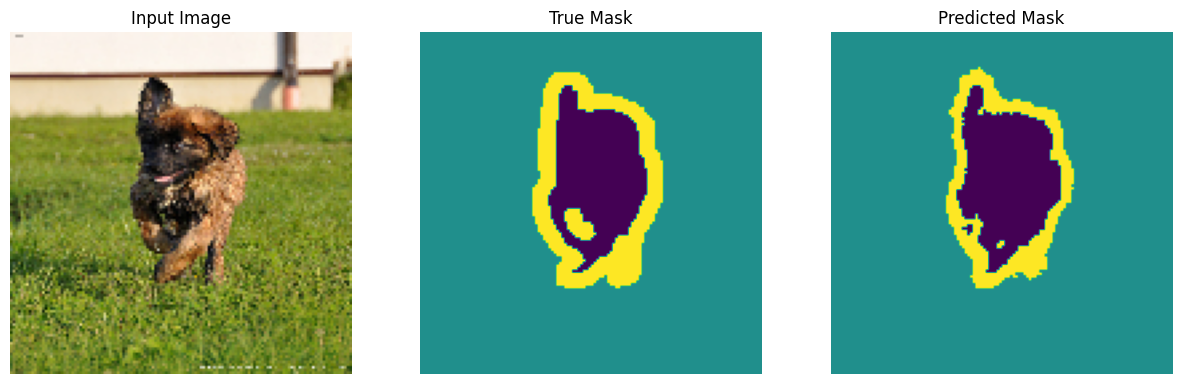
Fare previsioni
Ora, fai alcune previsioni. Nell'interesse di risparmiare tempo, il numero di epoche è stato mantenuto basso, ma è possibile impostarlo su un valore più alto per ottenere risultati più accurati.
show_predictions(test_batches, 3)


Facoltativo: classi sbilanciate e pesi delle classi
I set di dati di segmentazione semantica possono essere altamente sbilanciati, il che significa che i pixel di una particolare classe possono essere presenti più all'interno delle immagini rispetto a quelli di altre classi. Poiché i problemi di segmentazione possono essere trattati come problemi di classificazione per pixel, è possibile affrontare il problema dello squilibrio valutando la funzione di perdita per tenerne conto. È un modo semplice ed elegante per affrontare questo problema. Fare riferimento al tutorial Classificazione sui dati sbilanciati per saperne di più.
Per evitare ambiguità , Model.fit non supporta l'argomento class_weight per input con 3+ dimensioni.
try:
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
class_weight = {0:2.0, 1:2.0, 2:1.0})
assert False
except Exception as e:
print(f"Expected {type(e).__name__}: {e}")
Expected ValueError: `class_weight` not supported for 3+ dimensional targets.
Quindi, in questo caso devi implementare tu stesso la ponderazione. Lo farai utilizzando pesi campione: oltre alle coppie (data, label) , Model.fit accetta anche triple (data, label, sample_weight) .
Model.fit propaga il sample_weight alle perdite e alle metriche, che accettano anche un argomento sample_weight . Il peso del campione viene moltiplicato per il valore del campione prima della fase di riduzione. Per esempio:
label = [0,0]
prediction = [[-3., 0], [-3, 0]]
sample_weight = [1, 10]
loss = tf.losses.SparseCategoricalCrossentropy(from_logits=True,
reduction=tf.losses.Reduction.NONE)
loss(label, prediction, sample_weight).numpy()
array([ 3.0485873, 30.485874 ], dtype=float32)
Quindi, per creare pesi campione per questo tutorial è necessaria una funzione che prenda una coppia (data, label) e restituisca una tripla (data, label, sample_weight) . Dove sample_weight è un'immagine a 1 canale contenente il peso della classe per ogni pixel.
L'implementazione più semplice possibile consiste nell'usare l'etichetta come indice in un elenco class_weight :
def add_sample_weights(image, label):
# The weights for each class, with the constraint that:
# sum(class_weights) == 1.0
class_weights = tf.constant([2.0, 2.0, 1.0])
class_weights = class_weights/tf.reduce_sum(class_weights)
# Create an image of `sample_weights` by using the label at each pixel as an
# index into the `class weights` .
sample_weights = tf.gather(class_weights, indices=tf.cast(label, tf.int32))
return image, label, sample_weights
Gli elementi del set di dati risultanti contengono 3 immagini ciascuno:
train_batches.map(add_sample_weights).element_spec
(TensorSpec(shape=(None, 128, 128, 3), dtype=tf.float32, name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, name=None))
Ora puoi addestrare un modello su questo set di dati ponderato:
weighted_model = unet_model(OUTPUT_CLASSES)
weighted_model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
weighted_model.fit(
train_batches.map(add_sample_weights),
epochs=1,
steps_per_epoch=10)
10/10 [==============================] - 3s 44ms/step - loss: 0.3099 - accuracy: 0.6063 <keras.callbacks.History at 0x7fa75d0f3e50>
Prossimi passi
Ora che hai compreso cos'è la segmentazione dell'immagine e come funziona, puoi provare questo tutorial con diversi output di livello intermedio o anche diversi modelli pre-addestrati. Puoi anche sfidare te stesso provando la sfida di mascheramento dell'immagine Carvana ospitata su Kaggle .
Potresti anche voler vedere l' API di rilevamento degli oggetti Tensorflow per un altro modello che puoi riqualificare sui tuoi dati. I modelli preaddestrati sono disponibili su TensorFlow Hub