
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
Este tutorial se enfoca en la tarea de segmentación de imágenes, usando un U-Net modificado.
¿Qué es la segmentación de imágenes?
En una tarea de clasificación de imágenes, la red asigna una etiqueta (o clase) a cada imagen de entrada. Sin embargo, suponga que desea saber la forma de ese objeto, qué píxel pertenece a qué objeto, etc. En este caso, querrá asignar una clase a cada píxel de la imagen. Esta tarea se conoce como segmentación. Un modelo de segmentación devuelve información mucho más detallada sobre la imagen. La segmentación de imágenes tiene muchas aplicaciones en imágenes médicas, automóviles autónomos e imágenes satelitales, por nombrar algunas.
Este tutorial utiliza el conjunto de datos de mascotas Oxford- IIIT ( Parkhi et al, 2012 ). El conjunto de datos consta de imágenes de 37 razas de mascotas, con 200 imágenes por raza (~100 cada una en las divisiones de entrenamiento y prueba). Cada imagen incluye las etiquetas correspondientes y las máscaras de píxeles. Las máscaras son etiquetas de clase para cada píxel. A cada píxel se le asigna una de tres categorías:
- Clase 1: Píxel perteneciente a la mascota.
- Clase 2: Píxel bordeando a la mascota.
- Clase 3: ninguna de las anteriores/un píxel circundante.
pip install git+https://github.com/tensorflow/examples.git
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.models.pix2pix import pix2pix
from IPython.display import clear_output
import matplotlib.pyplot as plt
Descargue el conjunto de datos de Oxford-IIIT Pets
El conjunto de datos está disponible en TensorFlow Datasets . Las máscaras de segmentación están incluidas en la versión 3+.
dataset, info = tfds.load('oxford_iiit_pet:3.*.*', with_info=True)
Además, los valores de color de la imagen se normalizan al rango [0,1] . Finalmente, como se mencionó anteriormente, los píxeles en la máscara de segmentación están etiquetados como {1, 2, 3}. Por conveniencia, reste 1 de la máscara de segmentación, lo que da como resultado etiquetas que son: {0, 1, 2}.
def normalize(input_image, input_mask):
input_image = tf.cast(input_image, tf.float32) / 255.0
input_mask -= 1
return input_image, input_mask
def load_image(datapoint):
input_image = tf.image.resize(datapoint['image'], (128, 128))
input_mask = tf.image.resize(datapoint['segmentation_mask'], (128, 128))
input_image, input_mask = normalize(input_image, input_mask)
return input_image, input_mask
El conjunto de datos ya contiene las divisiones de entrenamiento y prueba requeridas, así que continúe usando las mismas divisiones.
TRAIN_LENGTH = info.splits['train'].num_examples
BATCH_SIZE = 64
BUFFER_SIZE = 1000
STEPS_PER_EPOCH = TRAIN_LENGTH // BATCH_SIZE
train_images = dataset['train'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
test_images = dataset['test'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
La siguiente clase realiza un aumento simple al voltear aleatoriamente una imagen. Vaya al tutorial de aumento de imágenes para obtener más información.
class Augment(tf.keras.layers.Layer):
def __init__(self, seed=42):
super().__init__()
# both use the same seed, so they'll make the same random changes.
self.augment_inputs = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
self.augment_labels = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
def call(self, inputs, labels):
inputs = self.augment_inputs(inputs)
labels = self.augment_labels(labels)
return inputs, labels
Cree la tubería de entrada, aplicando el Aumento después de agrupar las entradas.
train_batches = (
train_images
.cache()
.shuffle(BUFFER_SIZE)
.batch(BATCH_SIZE)
.repeat()
.map(Augment())
.prefetch(buffer_size=tf.data.AUTOTUNE))
test_batches = test_images.batch(BATCH_SIZE)
Visualice un ejemplo de imagen y su máscara correspondiente del conjunto de datos.
def display(display_list):
plt.figure(figsize=(15, 15))
title = ['Input Image', 'True Mask', 'Predicted Mask']
for i in range(len(display_list)):
plt.subplot(1, len(display_list), i+1)
plt.title(title[i])
plt.imshow(tf.keras.utils.array_to_img(display_list[i]))
plt.axis('off')
plt.show()
for images, masks in train_batches.take(2):
sample_image, sample_mask = images[0], masks[0]
display([sample_image, sample_mask])
Corrupt JPEG data: 240 extraneous bytes before marker 0xd9 Corrupt JPEG data: premature end of data segment


2022-01-26 05:14:45.972101: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
Definir el modelo
El modelo que se utiliza aquí es un U-Net modificado. Una U-Net consta de un codificador (disminución de muestreo) y un decodificador (disminución de muestreo). Para aprender características sólidas y reducir la cantidad de parámetros entrenables, utilizará un modelo previamente entrenado, MobileNetV2, como codificador. Para el decodificador, utilizará el bloque upsample, que ya está implementado en el ejemplo de pix2pix en el repositorio de ejemplos de TensorFlow. (Consulte pix2pix: traducción de imagen a imagen con un tutorial GAN condicional en un cuaderno).
Como se mencionó, el codificador será un modelo MobileNetV2 preentrenado que está preparado y listo para usar en tf.keras.applications . El codificador consta de salidas específicas de capas intermedias en el modelo. Tenga en cuenta que el codificador no se entrenará durante el proceso de entrenamiento.
base_model = tf.keras.applications.MobileNetV2(input_shape=[128, 128, 3], include_top=False)
# Use the activations of these layers
layer_names = [
'block_1_expand_relu', # 64x64
'block_3_expand_relu', # 32x32
'block_6_expand_relu', # 16x16
'block_13_expand_relu', # 8x8
'block_16_project', # 4x4
]
base_model_outputs = [base_model.get_layer(name).output for name in layer_names]
# Create the feature extraction model
down_stack = tf.keras.Model(inputs=base_model.input, outputs=base_model_outputs)
down_stack.trainable = False
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_128_no_top.h5 9412608/9406464 [==============================] - 0s 0us/step 9420800/9406464 [==============================] - 0s 0us/step
El decodificador/muestreador ascendente es simplemente una serie de bloques de muestreo ascendente implementados en los ejemplos de TensorFlow.
up_stack = [
pix2pix.upsample(512, 3), # 4x4 -> 8x8
pix2pix.upsample(256, 3), # 8x8 -> 16x16
pix2pix.upsample(128, 3), # 16x16 -> 32x32
pix2pix.upsample(64, 3), # 32x32 -> 64x64
]
def unet_model(output_channels:int):
inputs = tf.keras.layers.Input(shape=[128, 128, 3])
# Downsampling through the model
skips = down_stack(inputs)
x = skips[-1]
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
concat = tf.keras.layers.Concatenate()
x = concat([x, skip])
# This is the last layer of the model
last = tf.keras.layers.Conv2DTranspose(
filters=output_channels, kernel_size=3, strides=2,
padding='same') #64x64 -> 128x128
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
Tenga en cuenta que la cantidad de filtros en la última capa se establece en la cantidad de output_channels de salida. Este será un canal de salida por clase.
entrenar al modelo
Ahora, todo lo que queda por hacer es compilar y entrenar el modelo.
Dado que se trata de un problema de clasificación multiclase, utilice la función de pérdida tf.keras.losses.CategoricalCrossentropy con el argumento from_logits establecido en True , ya que las etiquetas son enteros escalares en lugar de vectores de puntuaciones para cada píxel de cada clase.
Al ejecutar la inferencia, la etiqueta asignada al píxel es el canal con el valor más alto. Esto es lo que está haciendo la función create_mask .
OUTPUT_CLASSES = 3
model = unet_model(output_channels=OUTPUT_CLASSES)
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Eche un vistazo rápido a la arquitectura del modelo resultante:
tf.keras.utils.plot_model(model, show_shapes=True)

Pruebe el modelo para comprobar lo que predice antes del entrenamiento.
def create_mask(pred_mask):
pred_mask = tf.argmax(pred_mask, axis=-1)
pred_mask = pred_mask[..., tf.newaxis]
return pred_mask[0]
def show_predictions(dataset=None, num=1):
if dataset:
for image, mask in dataset.take(num):
pred_mask = model.predict(image)
display([image[0], mask[0], create_mask(pred_mask)])
else:
display([sample_image, sample_mask,
create_mask(model.predict(sample_image[tf.newaxis, ...]))])
show_predictions()

La devolución de llamada definida a continuación se usa para observar cómo mejora el modelo mientras se está entrenando.
class DisplayCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
clear_output(wait=True)
show_predictions()
print ('\nSample Prediction after epoch {}\n'.format(epoch+1))
EPOCHS = 20
VAL_SUBSPLITS = 5
VALIDATION_STEPS = info.splits['test'].num_examples//BATCH_SIZE//VAL_SUBSPLITS
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
validation_steps=VALIDATION_STEPS,
validation_data=test_batches,
callbacks=[DisplayCallback()])

Sample Prediction after epoch 20 57/57 [==============================] - 4s 62ms/step - loss: 0.1838 - accuracy: 0.9187 - val_loss: 0.2797 - val_accuracy: 0.8955
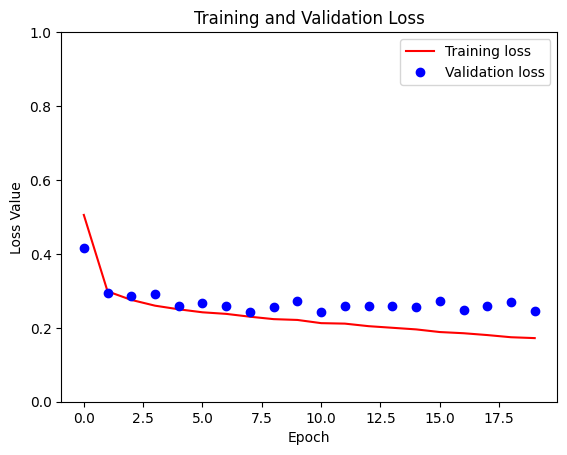
loss = model_history.history['loss']
val_loss = model_history.history['val_loss']
plt.figure()
plt.plot(model_history.epoch, loss, 'r', label='Training loss')
plt.plot(model_history.epoch, val_loss, 'bo', label='Validation loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss Value')
plt.ylim([0, 1])
plt.legend()
plt.show()
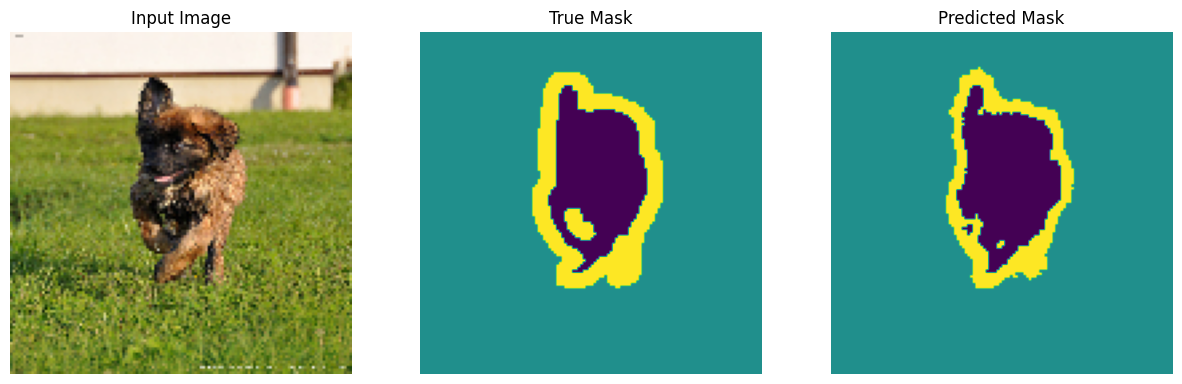
Hacer predicciones
Ahora, haz algunas predicciones. En aras de ahorrar tiempo, el número de épocas se mantuvo pequeño, pero puede configurarlo más alto para lograr resultados más precisos.
show_predictions(test_batches, 3)


Opcional: clases desequilibradas y pesos de clase
Los conjuntos de datos de segmentación semántica pueden estar muy desequilibrados, lo que significa que los píxeles de una clase particular pueden estar presentes más dentro de las imágenes que los de otras clases. Dado que los problemas de segmentación pueden tratarse como problemas de clasificación por píxel, puede tratar el problema del desequilibrio ponderando la función de pérdida para tener en cuenta esto. Es una manera simple y elegante de lidiar con este problema. Consulte el tutorial Clasificación en datos desequilibrados para obtener más información.
Para evitar la ambigüedad , Model.fit no admite el argumento class_weight para entradas con más de 3 dimensiones.
try:
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
class_weight = {0:2.0, 1:2.0, 2:1.0})
assert False
except Exception as e:
print(f"Expected {type(e).__name__}: {e}")
Expected ValueError: `class_weight` not supported for 3+ dimensional targets.
Entonces, en este caso, debe implementar la ponderación usted mismo. Hará esto usando pesos de muestra: además de pares (data, label) , Model.fit también acepta triples (data, label, sample_weight) .
Model.fit propaga sample_weight a las pérdidas y métricas, que también aceptan un argumento sample_weight . El peso de la muestra se multiplica por el valor de la muestra antes del paso de reducción. Por ejemplo:
label = [0,0]
prediction = [[-3., 0], [-3, 0]]
sample_weight = [1, 10]
loss = tf.losses.SparseCategoricalCrossentropy(from_logits=True,
reduction=tf.losses.Reduction.NONE)
loss(label, prediction, sample_weight).numpy()
array([ 3.0485873, 30.485874 ], dtype=float32)
Entonces, para hacer pesos de muestra para este tutorial, necesita una función que tome un par (data, label) y devuelva un triple (data, label, sample_weight) . Donde sample_weight es una imagen de 1 canal que contiene el peso de clase para cada píxel.
La implementación más simple posible es usar la etiqueta como un índice en una lista class_weight :
def add_sample_weights(image, label):
# The weights for each class, with the constraint that:
# sum(class_weights) == 1.0
class_weights = tf.constant([2.0, 2.0, 1.0])
class_weights = class_weights/tf.reduce_sum(class_weights)
# Create an image of `sample_weights` by using the label at each pixel as an
# index into the `class weights` .
sample_weights = tf.gather(class_weights, indices=tf.cast(label, tf.int32))
return image, label, sample_weights
Los elementos del conjunto de datos resultantes contienen 3 imágenes cada uno:
train_batches.map(add_sample_weights).element_spec
(TensorSpec(shape=(None, 128, 128, 3), dtype=tf.float32, name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, name=None))
Ahora puede entrenar un modelo en este conjunto de datos ponderado:
weighted_model = unet_model(OUTPUT_CLASSES)
weighted_model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
weighted_model.fit(
train_batches.map(add_sample_weights),
epochs=1,
steps_per_epoch=10)
10/10 [==============================] - 3s 44ms/step - loss: 0.3099 - accuracy: 0.6063 <keras.callbacks.History at 0x7fa75d0f3e50>
Próximos pasos
Ahora que comprende qué es la segmentación de imágenes y cómo funciona, puede probar este tutorial con diferentes salidas de capa intermedia, o incluso con diferentes modelos preentrenados. También puede desafiarse a sí mismo probando el desafío de enmascaramiento de imágenes de Carvana alojado en Kaggle.
También es posible que desee ver la API de detección de objetos de Tensorflow para otro modelo que pueda volver a entrenar con sus propios datos. Los modelos preentrenados están disponibles en TensorFlow Hub