
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
यह ट्यूटोरियल संशोधित यू-नेट का उपयोग करते हुए छवि विभाजन के कार्य पर केंद्रित है।
छवि विभाजन क्या है?
एक छवि वर्गीकरण कार्य में नेटवर्क प्रत्येक इनपुट छवि को एक लेबल (या वर्ग) प्रदान करता है। हालाँकि, मान लीजिए कि आप उस वस्तु का आकार जानना चाहते हैं, कौन सा पिक्सेल किस वस्तु का है, आदि। इस स्थिति में आप छवि के प्रत्येक पिक्सेल को एक वर्ग निर्दिष्ट करना चाहेंगे। इस कार्य को विभाजन के रूप में जाना जाता है। एक सेगमेंटेशन मॉडल छवि के बारे में अधिक विस्तृत जानकारी देता है। छवि विभाजन में चिकित्सा इमेजिंग, सेल्फ-ड्राइविंग कारों और उपग्रह इमेजिंग में कुछ नाम रखने के लिए कई अनुप्रयोग हैं।
यह ट्यूटोरियल ऑक्सफोर्ड-आईआईआईटी पेट डेटासेट ( पार्खी एट अल, 2012 ) का उपयोग करता है। डेटासेट में 37 पालतू नस्लों की छवियां होती हैं, प्रति नस्ल 200 छवियां (~ 100 प्रत्येक प्रशिक्षण और परीक्षण विभाजन में)। प्रत्येक छवि में संबंधित लेबल और पिक्सेल-वार मास्क शामिल होते हैं। मास्क प्रत्येक पिक्सेल के लिए क्लास-लेबल होते हैं। प्रत्येक पिक्सेल को तीन श्रेणियों में से एक दिया जाता है:
- कक्षा 1: पालतू जानवर से संबंधित पिक्सेल।
- कक्षा 2: पालतू जानवर की सीमा पर पिक्सेल।
- कक्षा 3: उपरोक्त में से कोई नहीं/आसपास का पिक्सेल।
pip install git+https://github.com/tensorflow/examples.git
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.models.pix2pix import pix2pix
from IPython.display import clear_output
import matplotlib.pyplot as plt
ऑक्सफोर्ड-आईआईआईटी पेट्स डेटासेट डाउनलोड करें
डेटासेट TensorFlow Datasets से उपलब्ध है । विभाजन मास्क संस्करण 3+ में शामिल हैं।
dataset, info = tfds.load('oxford_iiit_pet:3.*.*', with_info=True)
इसके अलावा, छवि रंग मान [0,1] श्रेणी में सामान्यीकृत होते हैं। अंत में, जैसा कि ऊपर उल्लेख किया गया है कि सेगमेंटेशन मास्क में पिक्सेल या तो {1, 2, 3} लेबल किए गए हैं। सुविधा के लिए, सेगमेंटेशन मास्क से 1 घटाएं, जिसके परिणामस्वरूप लेबल हैं: {0, 1, 2}।
def normalize(input_image, input_mask):
input_image = tf.cast(input_image, tf.float32) / 255.0
input_mask -= 1
return input_image, input_mask
def load_image(datapoint):
input_image = tf.image.resize(datapoint['image'], (128, 128))
input_mask = tf.image.resize(datapoint['segmentation_mask'], (128, 128))
input_image, input_mask = normalize(input_image, input_mask)
return input_image, input_mask
डेटासेट में पहले से ही आवश्यक प्रशिक्षण और परीक्षण विभाजन शामिल हैं, इसलिए समान विभाजन का उपयोग करना जारी रखें।
TRAIN_LENGTH = info.splits['train'].num_examples
BATCH_SIZE = 64
BUFFER_SIZE = 1000
STEPS_PER_EPOCH = TRAIN_LENGTH // BATCH_SIZE
train_images = dataset['train'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
test_images = dataset['test'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
निम्न वर्ग एक छवि को बेतरतीब ढंग से फ़्लिप करके एक साधारण वृद्धि करता है। अधिक जानने के लिए छवि वृद्धि ट्यूटोरियल पर जाएं।
class Augment(tf.keras.layers.Layer):
def __init__(self, seed=42):
super().__init__()
# both use the same seed, so they'll make the same random changes.
self.augment_inputs = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
self.augment_labels = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
def call(self, inputs, labels):
inputs = self.augment_inputs(inputs)
labels = self.augment_labels(labels)
return inputs, labels
इनपुट की बैचिंग के बाद ऑग्मेंटेशन लागू करते हुए इनपुट पाइपलाइन का निर्माण करें।
train_batches = (
train_images
.cache()
.shuffle(BUFFER_SIZE)
.batch(BATCH_SIZE)
.repeat()
.map(Augment())
.prefetch(buffer_size=tf.data.AUTOTUNE))
test_batches = test_images.batch(BATCH_SIZE)
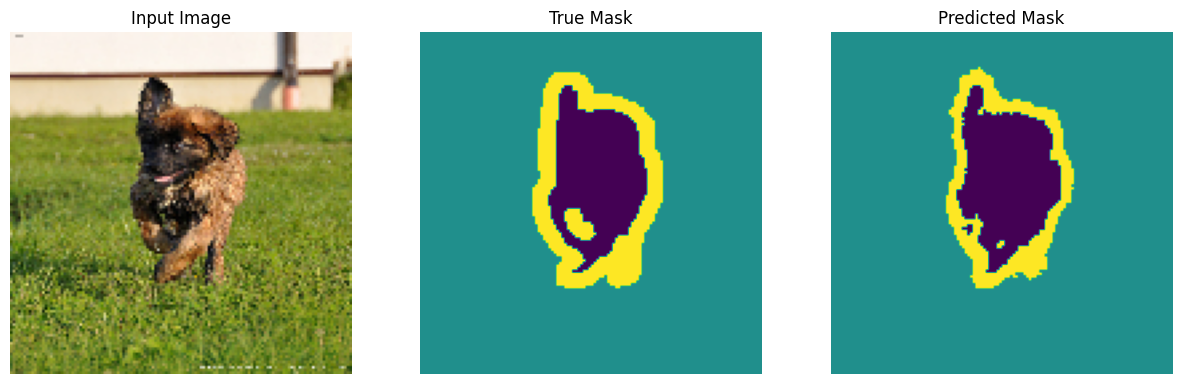
डेटासेट से एक छवि उदाहरण और उसके संबंधित मास्क की कल्पना करें।
def display(display_list):
plt.figure(figsize=(15, 15))
title = ['Input Image', 'True Mask', 'Predicted Mask']
for i in range(len(display_list)):
plt.subplot(1, len(display_list), i+1)
plt.title(title[i])
plt.imshow(tf.keras.utils.array_to_img(display_list[i]))
plt.axis('off')
plt.show()
for images, masks in train_batches.take(2):
sample_image, sample_mask = images[0], masks[0]
display([sample_image, sample_mask])
Corrupt JPEG data: 240 extraneous bytes before marker 0xd9 Corrupt JPEG data: premature end of data segment


2022-01-26 05:14:45.972101: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
मॉडल को परिभाषित करें
यहां इस्तेमाल किया जा रहा मॉडल एक संशोधित यू-नेट है। यू-नेट में एक एनकोडर (डाउनसैंपलर) और डिकोडर (अपसैंपलर) होते हैं। मजबूत विशेषताओं को सीखने और प्रशिक्षित करने योग्य मापदंडों की संख्या को कम करने के लिए, आप एन्कोडर के रूप में एक पूर्व-प्रशिक्षित मॉडल - MobileNetV2 - का उपयोग करेंगे। डिकोडर के लिए, आप upsample ब्लॉक का उपयोग करेंगे, जो पहले से ही TensorFlow उदाहरण रेपो में pix2pix उदाहरण में लागू किया गया है। ( pix2pix देखें: एक नोटबुक में सशर्त GAN ट्यूटोरियल के साथ इमेज-टू-इमेज अनुवाद ।)
जैसा कि उल्लेख किया गया है, एन्कोडर एक पूर्व-प्रशिक्षित MobileNetV2 मॉडल होगा जो tf.keras.applications में उपयोग के लिए तैयार और तैयार है। एन्कोडर में मॉडल में मध्यवर्ती परतों से विशिष्ट आउटपुट होते हैं। ध्यान दें कि प्रशिक्षण प्रक्रिया के दौरान एन्कोडर को प्रशिक्षित नहीं किया जाएगा।
base_model = tf.keras.applications.MobileNetV2(input_shape=[128, 128, 3], include_top=False)
# Use the activations of these layers
layer_names = [
'block_1_expand_relu', # 64x64
'block_3_expand_relu', # 32x32
'block_6_expand_relu', # 16x16
'block_13_expand_relu', # 8x8
'block_16_project', # 4x4
]
base_model_outputs = [base_model.get_layer(name).output for name in layer_names]
# Create the feature extraction model
down_stack = tf.keras.Model(inputs=base_model.input, outputs=base_model_outputs)
down_stack.trainable = False
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_128_no_top.h5 9412608/9406464 [==============================] - 0s 0us/step 9420800/9406464 [==============================] - 0s 0us/step
डिकोडर/अपसैंपलर केवल TensorFlow उदाहरणों में कार्यान्वित अपसैंपल ब्लॉकों की एक श्रृंखला है।
up_stack = [
pix2pix.upsample(512, 3), # 4x4 -> 8x8
pix2pix.upsample(256, 3), # 8x8 -> 16x16
pix2pix.upsample(128, 3), # 16x16 -> 32x32
pix2pix.upsample(64, 3), # 32x32 -> 64x64
]
def unet_model(output_channels:int):
inputs = tf.keras.layers.Input(shape=[128, 128, 3])
# Downsampling through the model
skips = down_stack(inputs)
x = skips[-1]
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
concat = tf.keras.layers.Concatenate()
x = concat([x, skip])
# This is the last layer of the model
last = tf.keras.layers.Conv2DTranspose(
filters=output_channels, kernel_size=3, strides=2,
padding='same') #64x64 -> 128x128
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
ध्यान दें कि अंतिम परत पर फ़िल्टर की संख्या output_channels की संख्या पर सेट है। यह प्रति वर्ग एक आउटपुट चैनल होगा।
मॉडल को प्रशिक्षित करें
अब, केवल मॉडल को संकलित और प्रशिक्षित करना बाकी है।
चूंकि यह एक बहुवर्गीय वर्गीकरण समस्या है, इसलिए tf.keras.losses.CategoricalCrossentropy loss function का उपयोग from_logits तर्क के साथ True पर सेट करें, क्योंकि लेबल प्रत्येक वर्ग के प्रत्येक पिक्सेल के लिए स्कोर के वैक्टर के बजाय स्केलर पूर्णांक होते हैं।
अनुमान चलाते समय, पिक्सेल को असाइन किया गया लेबल उच्चतम मान वाला चैनल होता है। यह वही है जो create_mask फ़ंक्शन कर रहा है।
OUTPUT_CLASSES = 3
model = unet_model(output_channels=OUTPUT_CLASSES)
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
परिणामी मॉडल आर्किटेक्चर पर एक त्वरित नज़र डालें:
tf.keras.utils.plot_model(model, show_shapes=True)

प्रशिक्षण से पहले यह जांचने के लिए मॉडल का परीक्षण करें कि यह क्या भविष्यवाणी करता है।
def create_mask(pred_mask):
pred_mask = tf.argmax(pred_mask, axis=-1)
pred_mask = pred_mask[..., tf.newaxis]
return pred_mask[0]
def show_predictions(dataset=None, num=1):
if dataset:
for image, mask in dataset.take(num):
pred_mask = model.predict(image)
display([image[0], mask[0], create_mask(pred_mask)])
else:
display([sample_image, sample_mask,
create_mask(model.predict(sample_image[tf.newaxis, ...]))])
show_predictions()

नीचे परिभाषित कॉलबैक का उपयोग यह देखने के लिए किया जाता है कि प्रशिक्षण के दौरान मॉडल कैसे सुधार करता है।
class DisplayCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
clear_output(wait=True)
show_predictions()
print ('\nSample Prediction after epoch {}\n'.format(epoch+1))
EPOCHS = 20
VAL_SUBSPLITS = 5
VALIDATION_STEPS = info.splits['test'].num_examples//BATCH_SIZE//VAL_SUBSPLITS
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
validation_steps=VALIDATION_STEPS,
validation_data=test_batches,
callbacks=[DisplayCallback()])

Sample Prediction after epoch 20 57/57 [==============================] - 4s 62ms/step - loss: 0.1838 - accuracy: 0.9187 - val_loss: 0.2797 - val_accuracy: 0.8955
loss = model_history.history['loss']
val_loss = model_history.history['val_loss']
plt.figure()
plt.plot(model_history.epoch, loss, 'r', label='Training loss')
plt.plot(model_history.epoch, val_loss, 'bo', label='Validation loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss Value')
plt.ylim([0, 1])
plt.legend()
plt.show()
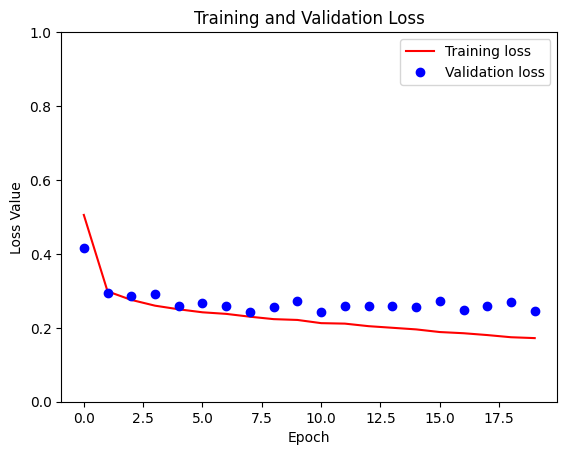
अंदाजा लगाओ
अब कुछ भविष्यवाणियां करें। समय बचाने के हित में, युगों की संख्या कम रखी गई थी, लेकिन अधिक सटीक परिणाम प्राप्त करने के लिए आप इसे उच्चतर सेट कर सकते हैं।
show_predictions(test_batches, 3)


वैकल्पिक: असंतुलित वर्ग और वर्ग भार
सिमेंटिक सेगमेंटेशन डेटासेट अत्यधिक असंतुलित हो सकते हैं जिसका अर्थ है कि विशेष वर्ग पिक्सेल अन्य वर्गों की तुलना में छवियों के अंदर अधिक मौजूद हो सकते हैं। चूंकि सेगमेंटेशन समस्याओं को प्रति-पिक्सेल वर्गीकरण समस्याओं के रूप में माना जा सकता है, आप इसके लिए नुकसान फ़ंक्शन को तौलकर असंतुलन की समस्या से निपट सकते हैं। यह इस समस्या से निपटने का एक सरल और सुरुचिपूर्ण तरीका है। अधिक जानने के लिए असंतुलित डेटा ट्यूटोरियल पर वर्गीकरण देखें।
अस्पष्टता से बचने के लिए, Model.fit 3+ आयामों वाले इनपुट के लिए class_weight तर्क का समर्थन नहीं करता है।
try:
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
class_weight = {0:2.0, 1:2.0, 2:1.0})
assert False
except Exception as e:
print(f"Expected {type(e).__name__}: {e}")
Expected ValueError: `class_weight` not supported for 3+ dimensional targets.
तो, इस मामले में आपको वेटिंग को स्वयं लागू करने की आवश्यकता है। आप इसे नमूना भार का उपयोग करके करेंगे: (data, label) जोड़े के अलावा, Model.fit भी (data, label, sample_weight) ट्रिपल स्वीकार करता है।
Model.fit , sample_weight को नुकसान और मेट्रिक्स के लिए प्रचारित करता है, जो एक sample_weight तर्क को भी स्वीकार करता है। नमूना वजन कमी कदम से पहले नमूने के मूल्य से गुणा किया जाता है। उदाहरण के लिए:
label = [0,0]
prediction = [[-3., 0], [-3, 0]]
sample_weight = [1, 10]
loss = tf.losses.SparseCategoricalCrossentropy(from_logits=True,
reduction=tf.losses.Reduction.NONE)
loss(label, prediction, sample_weight).numpy()
array([ 3.0485873, 30.485874 ], dtype=float32)
तो इस ट्यूटोरियल के लिए नमूना भार बनाने के लिए आपको एक फ़ंक्शन की आवश्यकता है जो एक (data, label) जोड़ी लेता है और एक (data, label, sample_weight) ट्रिपल देता है। जहां sample_weight एक 1-चैनल छवि है जिसमें प्रत्येक पिक्सेल के लिए वर्ग भार होता है।
सबसे आसान संभव कार्यान्वयन एक class_weight सूची में एक सूचकांक के रूप में लेबल का उपयोग करना है:
def add_sample_weights(image, label):
# The weights for each class, with the constraint that:
# sum(class_weights) == 1.0
class_weights = tf.constant([2.0, 2.0, 1.0])
class_weights = class_weights/tf.reduce_sum(class_weights)
# Create an image of `sample_weights` by using the label at each pixel as an
# index into the `class weights` .
sample_weights = tf.gather(class_weights, indices=tf.cast(label, tf.int32))
return image, label, sample_weights
परिणामी डेटासेट तत्वों में प्रत्येक में 3 चित्र होते हैं:
train_batches.map(add_sample_weights).element_spec
(TensorSpec(shape=(None, 128, 128, 3), dtype=tf.float32, name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, name=None))
अब आप इस भारित डेटासेट पर एक मॉडल को प्रशिक्षित कर सकते हैं:
weighted_model = unet_model(OUTPUT_CLASSES)
weighted_model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
weighted_model.fit(
train_batches.map(add_sample_weights),
epochs=1,
steps_per_epoch=10)
10/10 [==============================] - 3s 44ms/step - loss: 0.3099 - accuracy: 0.6063 <keras.callbacks.History at 0x7fa75d0f3e50>
अगले कदम
अब जब आप समझ गए हैं कि इमेज सेगमेंटेशन क्या है और यह कैसे काम करता है, तो आप इस ट्यूटोरियल को विभिन्न इंटरमीडिएट लेयर आउटपुट, या यहां तक कि अलग-अलग प्रीट्रेन्ड मॉडल के साथ आज़मा सकते हैं। कागल पर होस्ट किए गए कैरवाना इमेज मास्किंग चैलेंज को आज़माकर आप खुद को चुनौती भी दे सकते हैं।
आप किसी अन्य मॉडल के लिए Tensorflow ऑब्जेक्ट डिटेक्शन API भी देखना चाह सकते हैं जिसे आप अपने डेटा पर पुनः प्रशिक्षित कर सकते हैं। पूर्व-प्रशिक्षित मॉडल TensorFlow हब पर उपलब्ध हैं