
| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
يركز هذا البرنامج التعليمي على مهمة تجزئة الصورة باستخدام U-Net معدلة.
ما هو تجزئة الصورة؟
في مهمة تصنيف الصور ، تقوم الشبكة بتعيين تسمية (أو فئة) لكل صورة إدخال. ومع ذلك ، لنفترض أنك تريد معرفة شكل هذا الكائن ، وأي بكسل ينتمي إلى أي كائن ، وما إلى ذلك. في هذه الحالة ، سترغب في تعيين فئة لكل بكسل من الصورة. تُعرف هذه المهمة باسم التجزئة. يعرض نموذج التقسيم معلومات أكثر تفصيلاً عن الصورة. تجزئة الصور لها العديد من التطبيقات في التصوير الطبي والسيارات ذاتية القيادة والتصوير عبر الأقمار الصناعية على سبيل المثال لا الحصر.
يستخدم هذا البرنامج التعليمي مجموعة بيانات الحيوانات الأليفة Oxford-IIIT ( Parkhi et al ، 2012 ). تتكون مجموعة البيانات من صور 37 سلالة من الحيوانات الأليفة ، مع 200 صورة لكل سلالة (حوالي 100 صورة لكل منها في قسمي التدريب والاختبار). تتضمن كل صورة الملصقات المقابلة وأقنعة البكسل. الأقنعة عبارة عن تسميات فئة لكل بكسل. يتم إعطاء كل بكسل إحدى الفئات الثلاث:
- الفئة 1: بكسل ينتمي إلى حيوان أليف.
- الفئة 2: بكسل يحد الحيوان الأليف.
- فئة 3: لا شيء مما سبق / بكسل محيط.
pip install git+https://github.com/tensorflow/examples.git
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.models.pix2pix import pix2pix
from IPython.display import clear_output
import matplotlib.pyplot as plt
قم بتنزيل مجموعة بيانات Oxford-IIIT Pets
تتوفر مجموعة البيانات من مجموعات بيانات TensorFlow . تم تضمين أقنعة التجزئة في الإصدار 3+.
dataset, info = tfds.load('oxford_iiit_pet:3.*.*', with_info=True)
بالإضافة إلى ذلك ، يتم تسوية قيم ألوان الصورة إلى النطاق [0,1] . أخيرًا ، كما هو مذكور أعلاه ، يتم تسمية وحدات البكسل الموجودة في قناع التجزئة إما {1 ، 2 ، 3}. للتيسير ، اطرح 1 من قناع التجزئة ، مما ينتج عنه تسميات هي: {0 ، 1 ، 2}.
def normalize(input_image, input_mask):
input_image = tf.cast(input_image, tf.float32) / 255.0
input_mask -= 1
return input_image, input_mask
def load_image(datapoint):
input_image = tf.image.resize(datapoint['image'], (128, 128))
input_mask = tf.image.resize(datapoint['segmentation_mask'], (128, 128))
input_image, input_mask = normalize(input_image, input_mask)
return input_image, input_mask
تحتوي مجموعة البيانات بالفعل على التدريب المطلوب وتقسيم الاختبار ، لذا استمر في استخدام نفس التقسيمات.
TRAIN_LENGTH = info.splits['train'].num_examples
BATCH_SIZE = 64
BUFFER_SIZE = 1000
STEPS_PER_EPOCH = TRAIN_LENGTH // BATCH_SIZE
train_images = dataset['train'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
test_images = dataset['test'].map(load_image, num_parallel_calls=tf.data.AUTOTUNE)
يقوم الفصل التالي بإجراء زيادة بسيطة عن طريق التقليب العشوائي للصورة. انتقل إلى البرنامج التعليمي لتكبير الصورة لمعرفة المزيد.
class Augment(tf.keras.layers.Layer):
def __init__(self, seed=42):
super().__init__()
# both use the same seed, so they'll make the same random changes.
self.augment_inputs = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
self.augment_labels = tf.keras.layers.RandomFlip(mode="horizontal", seed=seed)
def call(self, inputs, labels):
inputs = self.augment_inputs(inputs)
labels = self.augment_labels(labels)
return inputs, labels
قم ببناء خط أنابيب الإدخال ، وتطبيق التعزيز بعد تجميع المدخلات.
train_batches = (
train_images
.cache()
.shuffle(BUFFER_SIZE)
.batch(BATCH_SIZE)
.repeat()
.map(Augment())
.prefetch(buffer_size=tf.data.AUTOTUNE))
test_batches = test_images.batch(BATCH_SIZE)
تصور مثال صورة والقناع المقابل لها من مجموعة البيانات.
def display(display_list):
plt.figure(figsize=(15, 15))
title = ['Input Image', 'True Mask', 'Predicted Mask']
for i in range(len(display_list)):
plt.subplot(1, len(display_list), i+1)
plt.title(title[i])
plt.imshow(tf.keras.utils.array_to_img(display_list[i]))
plt.axis('off')
plt.show()
for images, masks in train_batches.take(2):
sample_image, sample_mask = images[0], masks[0]
display([sample_image, sample_mask])
Corrupt JPEG data: 240 extraneous bytes before marker 0xd9 Corrupt JPEG data: premature end of data segment


2022-01-26 05:14:45.972101: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
حدد النموذج
النموذج المستخدم هنا هو U-Net معدل. يتكون U-Net من جهاز تشفير (جهاز اختزال العينة) ومفكك تشفير (مكثف). من أجل تعلم الميزات القوية وتقليل عدد المعلمات القابلة للتدريب ، ستستخدم نموذجًا تم اختباره مسبقًا - MobileNetV2 - باعتباره المشفر. بالنسبة لوحدة فك التشفير ، ستستخدم كتلة upample ، والتي تم تنفيذها بالفعل في مثال pix2pix في TensorFlow Examples repo. (تحقق من pix2pix: الترجمة من صورة إلى صورة باستخدام برنامج تعليمي شرطي لـ GAN في جهاز كمبيوتر محمول.)
كما ذكرنا ، سيكون المشفر نموذج MobileNetV2 الذي تم اختباره مسبقًا والذي تم إعداده وجاهزًا للاستخدام في tf.keras.applications . يتكون المشفر من مخرجات محددة من الطبقات المتوسطة في النموذج. لاحظ أنه لن يتم تدريب المشفر أثناء عملية التدريب.
base_model = tf.keras.applications.MobileNetV2(input_shape=[128, 128, 3], include_top=False)
# Use the activations of these layers
layer_names = [
'block_1_expand_relu', # 64x64
'block_3_expand_relu', # 32x32
'block_6_expand_relu', # 16x16
'block_13_expand_relu', # 8x8
'block_16_project', # 4x4
]
base_model_outputs = [base_model.get_layer(name).output for name in layer_names]
# Create the feature extraction model
down_stack = tf.keras.Model(inputs=base_model.input, outputs=base_model_outputs)
down_stack.trainable = False
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/mobilenet_v2/mobilenet_v2_weights_tf_dim_ordering_tf_kernels_1.0_128_no_top.h5 9412608/9406464 [==============================] - 0s 0us/step 9420800/9406464 [==============================] - 0s 0us/step
وحدة فك التشفير / مكبس العينات هي ببساطة سلسلة من كتل upample تم تنفيذها في أمثلة TensorFlow.
up_stack = [
pix2pix.upsample(512, 3), # 4x4 -> 8x8
pix2pix.upsample(256, 3), # 8x8 -> 16x16
pix2pix.upsample(128, 3), # 16x16 -> 32x32
pix2pix.upsample(64, 3), # 32x32 -> 64x64
]
def unet_model(output_channels:int):
inputs = tf.keras.layers.Input(shape=[128, 128, 3])
# Downsampling through the model
skips = down_stack(inputs)
x = skips[-1]
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
concat = tf.keras.layers.Concatenate()
x = concat([x, skip])
# This is the last layer of the model
last = tf.keras.layers.Conv2DTranspose(
filters=output_channels, kernel_size=3, strides=2,
padding='same') #64x64 -> 128x128
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
لاحظ أن عدد المرشحات في الطبقة الأخيرة مضبوط على عدد output_channels . ستكون هذه قناة إخراج واحدة لكل فصل.
تدريب النموذج
الآن ، كل ما تبقى للقيام به هو تجميع النموذج وتدريبه.
نظرًا لأن هذه مشكلة تصنيف متعددة الفئات ، استخدم الدالة tf.keras.losses.CategoricalCrossentropy مع تعيين الوسيطة from_logits على True ، نظرًا لأن التسميات هي أعداد صحيحة عددية بدلاً من متجهات الدرجات لكل بكسل من كل فئة.
عند تشغيل الاستدلال ، فإن التسمية المخصصة للبكسل هي القناة ذات القيمة الأعلى. هذا ما تقوم به وظيفة create_mask .
OUTPUT_CLASSES = 3
model = unet_model(output_channels=OUTPUT_CLASSES)
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
ألق نظرة سريعة على بنية النموذج الناتجة:
tf.keras.utils.plot_model(model, show_shapes=True)

جرب النموذج للتحقق مما يتوقعه قبل التدريب.
def create_mask(pred_mask):
pred_mask = tf.argmax(pred_mask, axis=-1)
pred_mask = pred_mask[..., tf.newaxis]
return pred_mask[0]
def show_predictions(dataset=None, num=1):
if dataset:
for image, mask in dataset.take(num):
pred_mask = model.predict(image)
display([image[0], mask[0], create_mask(pred_mask)])
else:
display([sample_image, sample_mask,
create_mask(model.predict(sample_image[tf.newaxis, ...]))])
show_predictions()

يتم استخدام رد الاتصال الموضح أدناه لملاحظة كيفية تحسين النموذج أثناء التدريب.
class DisplayCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs=None):
clear_output(wait=True)
show_predictions()
print ('\nSample Prediction after epoch {}\n'.format(epoch+1))
EPOCHS = 20
VAL_SUBSPLITS = 5
VALIDATION_STEPS = info.splits['test'].num_examples//BATCH_SIZE//VAL_SUBSPLITS
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
validation_steps=VALIDATION_STEPS,
validation_data=test_batches,
callbacks=[DisplayCallback()])

Sample Prediction after epoch 20 57/57 [==============================] - 4s 62ms/step - loss: 0.1838 - accuracy: 0.9187 - val_loss: 0.2797 - val_accuracy: 0.8955
loss = model_history.history['loss']
val_loss = model_history.history['val_loss']
plt.figure()
plt.plot(model_history.epoch, loss, 'r', label='Training loss')
plt.plot(model_history.epoch, val_loss, 'bo', label='Validation loss')
plt.title('Training and Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss Value')
plt.ylim([0, 1])
plt.legend()
plt.show()
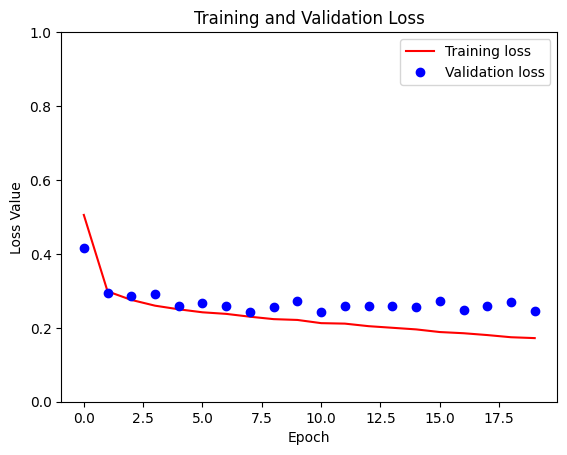
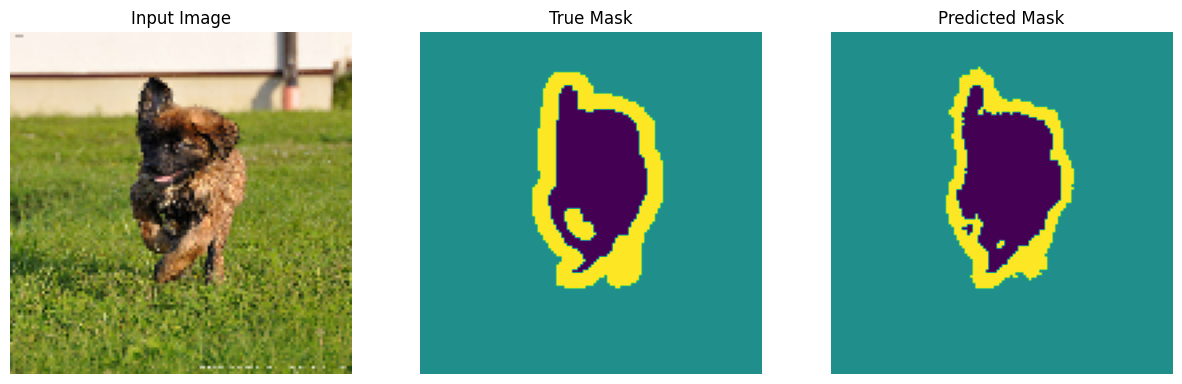
قم بعمل تنبؤات
الآن ، قم ببعض التوقعات. حرصًا على توفير الوقت ، ظل عدد العهود صغيراً ، ولكن يمكنك تعيين هذا على مستوى أعلى لتحقيق نتائج أكثر دقة.
show_predictions(test_batches, 3)


اختياري: فصول غير متوازنة وأوزان صفية
يمكن أن تكون مجموعات بيانات التجزئة الدلالية غير متوازنة بدرجة كبيرة مما يعني أن وحدات البكسل الخاصة بفئة معينة يمكن أن تكون موجودة داخل الصور أكثر من تلك الموجودة في الفئات الأخرى. نظرًا لأنه يمكن معالجة مشاكل التجزئة على أنها مشاكل تصنيف لكل بكسل ، يمكنك التعامل مع مشكلة عدم التوازن عن طريق وزن دالة الخسارة لحساب ذلك. إنها طريقة بسيطة وأنيقة للتعامل مع هذه المشكلة. الرجوع إلى التصنيف على تعليمي البيانات غير المتوازنة لمعرفة المزيد.
لتجنب الغموض ، لا يدعم Model.fit وسيطة class_weight للمدخلات ذات الأبعاد 3+.
try:
model_history = model.fit(train_batches, epochs=EPOCHS,
steps_per_epoch=STEPS_PER_EPOCH,
class_weight = {0:2.0, 1:2.0, 2:1.0})
assert False
except Exception as e:
print(f"Expected {type(e).__name__}: {e}")
Expected ValueError: `class_weight` not supported for 3+ dimensional targets.
لذلك ، في هذه الحالة تحتاج إلى تنفيذ الترجيح بنفسك. ستفعل ذلك باستخدام أوزان العينة: بالإضافة إلى أزواج (data, label) ، يقبل Model.fit أيضًا (data, label, sample_weight) ثلاث مرات.
تنشر Model.fit sample_weight في الخسائر والمقاييس ، والتي تقبل أيضًا وسيطة sample_weight . يُضرب وزن العينة في قيمة العينة قبل خطوة التخفيض. فمثلا:
label = [0,0]
prediction = [[-3., 0], [-3, 0]]
sample_weight = [1, 10]
loss = tf.losses.SparseCategoricalCrossentropy(from_logits=True,
reduction=tf.losses.Reduction.NONE)
loss(label, prediction, sample_weight).numpy()
array([ 3.0485873, 30.485874 ], dtype=float32)
لذلك ، لعمل أوزان نموذجية لهذا البرنامج التعليمي ، تحتاج إلى وظيفة تأخذ زوجًا (data, label) (data, label, sample_weight) ثلاثة (بيانات ، ملصق ، وزن العينة). حيث يكون sample_weight صورة من قناة واحدة تحتوي على وزن الفئة لكل بكسل.
أبسط تطبيق ممكن هو استخدام التسمية كمؤشر في قائمة class_weight :
def add_sample_weights(image, label):
# The weights for each class, with the constraint that:
# sum(class_weights) == 1.0
class_weights = tf.constant([2.0, 2.0, 1.0])
class_weights = class_weights/tf.reduce_sum(class_weights)
# Create an image of `sample_weights` by using the label at each pixel as an
# index into the `class weights` .
sample_weights = tf.gather(class_weights, indices=tf.cast(label, tf.int32))
return image, label, sample_weights
تحتوي عناصر مجموعة البيانات الناتجة على 3 صور لكل منها:
train_batches.map(add_sample_weights).element_spec
(TensorSpec(shape=(None, 128, 128, 3), dtype=tf.float32, name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, name=None), TensorSpec(shape=(None, 128, 128, 1), dtype=tf.float32, name=None))
يمكنك الآن تدريب نموذج على مجموعة البيانات الموزونة هذه:
weighted_model = unet_model(OUTPUT_CLASSES)
weighted_model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
weighted_model.fit(
train_batches.map(add_sample_weights),
epochs=1,
steps_per_epoch=10)
10/10 [==============================] - 3s 44ms/step - loss: 0.3099 - accuracy: 0.6063 <keras.callbacks.History at 0x7fa75d0f3e50>
الخطوات التالية
الآن بعد أن أصبح لديك فهم لما هو تجزئة الصورة وكيف يعمل ، يمكنك تجربة هذا البرنامج التعليمي مع مخرجات مختلفة للطبقة المتوسطة ، أو حتى نماذج مختلفة مسبقًا. يمكنك أيضًا تحدي نفسك من خلال تجربة تحدي إخفاء صورة Carvana المستضاف على Kaggle.
قد ترغب أيضًا في رؤية Tensorflow Object Detection API لطراز آخر يمكنك إعادة تدريبه على بياناتك الخاصة. تتوفر النماذج سابقة التدريب على TensorFlow Hub