
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
ওভারভিউ
এই টিউটোরিয়ালটি ডেটা অগমেন্টেশন দেখায়: এলোমেলো (কিন্তু বাস্তবসম্মত) রূপান্তর, যেমন ইমেজ রোটেশন প্রয়োগ করে আপনার প্রশিক্ষণ সেটের বৈচিত্র্য বাড়ানোর একটি কৌশল।
আপনি দুটি উপায়ে ডেটা বৃদ্ধি কীভাবে প্রয়োগ করবেন তা শিখবেন:
- কেরাস প্রিপ্রসেসিং স্তরগুলি ব্যবহার করুন, যেমন
tf.keras.layers.Resizing,tf.keras.layers.Rescaling,tf.keras.layers.RandomFlip, এবংtf.keras.layers.RandomRotation। -
tf.imageপদ্ধতিগুলি ব্যবহার করুন, যেমনtf.image.flip_left_right,tf.image.rgb_to_grayscale,tf.image.adjust_brightness,tf.image.central_crop, এবংtf.image.stateless_random*।
সেটআপ
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow.keras import layers
একটি ডেটাসেট ডাউনলোড করুন
এই টিউটোরিয়ালটি tf_flowers ডেটাসেট ব্যবহার করে। সুবিধার জন্য, টেনসরফ্লো ডেটাসেট ব্যবহার করে ডেটাসেট ডাউনলোড করুন। আপনি যদি ডেটা আমদানির অন্যান্য উপায় সম্পর্কে জানতে চান, লোড ইমেজ টিউটোরিয়ালটি দেখুন।
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
ফুলের ডেটাসেটের পাঁচটি শ্রেণী রয়েছে।
num_classes = metadata.features['label'].num_classes
print(num_classes)
5
আসুন ডেটাসেট থেকে একটি চিত্র পুনরুদ্ধার করি এবং ডেটা বৃদ্ধি প্রদর্শনের জন্য এটি ব্যবহার করি।
get_label_name = metadata.features['label'].int2str
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 05:09:18.712477: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

কেরাস প্রিপ্রসেসিং লেয়ার ব্যবহার করুন
আকার পরিবর্তন এবং পুনরায় স্কেলিং
আপনি কেরাস প্রিপ্রসেসিং স্তরগুলি ব্যবহার করতে পারেন আপনার চিত্রগুলিকে একটি সামঞ্জস্যপূর্ণ আকারে আকারে পরিবর্তন করতে ( tf.keras.layers.Resizing সাথে), এবং পিক্সেলের মান পুনরায় স্কেল করতে ( tf.keras.layers.Rescaling )।
IMG_SIZE = 180
resize_and_rescale = tf.keras.Sequential([
layers.Resizing(IMG_SIZE, IMG_SIZE),
layers.Rescaling(1./255)
])
আপনি একটি ছবিতে এই স্তরগুলি প্রয়োগ করার ফলাফলটি কল্পনা করতে পারেন।
result = resize_and_rescale(image)
_ = plt.imshow(result)
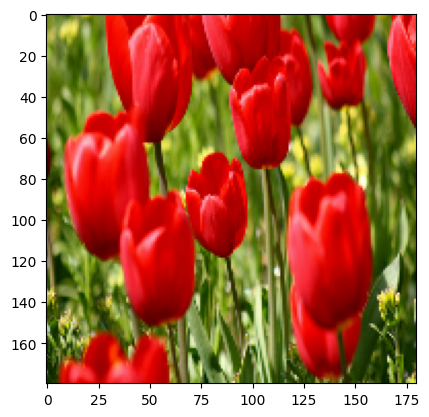
যাচাই করুন যে পিক্সেলগুলি [0, 1] পরিসরে রয়েছে:
print("Min and max pixel values:", result.numpy().min(), result.numpy().max())
Min and max pixel values: 0.0 1.0
তথ্য বৃদ্ধি
আপনি ডেটা বৃদ্ধির জন্য কেরাস প্রিপ্রসেসিং স্তরগুলিও ব্যবহার করতে পারেন, যেমন tf.keras.layers.RandomFlip এবং tf.keras.layers.RandomRotation ।
আসুন কয়েকটি প্রিপ্রসেসিং লেয়ার তৈরি করি এবং একই ছবিতে বারবার প্রয়োগ করি।
data_augmentation = tf.keras.Sequential([
layers.RandomFlip("horizontal_and_vertical"),
layers.RandomRotation(0.2),
])
# Add the image to a batch.
image = tf.expand_dims(image, 0)
plt.figure(figsize=(10, 10))
for i in range(9):
augmented_image = data_augmentation(image)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_image[0])
plt.axis("off")
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).

tf.keras.layers.RandomContrast , tf.keras.layers.RandomCrop , tf.keras.layers.RandomZoom এবং অন্যান্য সহ ডেটা বৃদ্ধির জন্য আপনি বিভিন্ন ধরনের প্রিপ্রসেসিং স্তরগুলি ব্যবহার করতে পারেন৷
কেরাস প্রিপ্রসেসিং স্তরগুলি ব্যবহার করার জন্য দুটি বিকল্প
গুরুত্বপূর্ণ ট্রেড-অফ সহ আপনি এই প্রিপ্রসেসিং স্তরগুলিকে দুটি উপায়ে ব্যবহার করতে পারেন।
বিকল্প 1: প্রিপ্রসেসিং স্তরগুলিকে আপনার মডেলের অংশ করুন
model = tf.keras.Sequential([
# Add the preprocessing layers you created earlier.
resize_and_rescale,
data_augmentation,
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
# Rest of your model.
])
এই ক্ষেত্রে সচেতন হতে দুটি গুরুত্বপূর্ণ পয়েন্ট আছে:
ডেটা অগমেন্টেশন আপনার বাকি লেয়ারের সাথে সিঙ্ক্রোনাসভাবে ডিভাইসে চলবে এবং GPU ত্বরণ থেকে উপকৃত হবে।
আপনি মডেল.
model.saveব্যবহার করে আপনার মডেল রপ্তানি করলে, প্রিপ্রসেসিং স্তরগুলি আপনার বাকি মডেলের সাথে সংরক্ষণ করা হবে। আপনি যদি পরে এই মডেলটি স্থাপন করেন, এটি স্বয়ংক্রিয়ভাবে চিত্রগুলিকে মানক করবে (আপনার স্তরগুলির কনফিগারেশন অনুসারে)। এটি আপনাকে সেই লজিক সার্ভার-সাইডকে পুনরায় প্রয়োগ করার প্রচেষ্টা থেকে বাঁচাতে পারে।
বিকল্প 2: আপনার ডেটাসেটে প্রিপ্রসেসিং স্তরগুলি প্রয়োগ করুন
aug_ds = train_ds.map(
lambda x, y: (resize_and_rescale(x, training=True), y))
এই পদ্ধতির সাথে, আপনি একটি ডেটাসেট তৈরি করতে Dataset.map ব্যবহার করেন যা বর্ধিত চিত্রগুলির ব্যাচ তৈরি করে। এক্ষেত্রে:
- ডেটা অগমেন্টেশন সিপিইউতে অ্যাসিঙ্ক্রোনাসভাবে ঘটবে এবং এটি ব্লকিং নয়। আপনি নিচে দেখানো
Dataset.prefetchব্যবহার করে ডেটা প্রিপ্রসেসিং-এর মাধ্যমে GPU-তে আপনার মডেলের প্রশিক্ষণ ওভারল্যাপ করতে পারেন। - এই ক্ষেত্রে আপনি যখন
Model.saveকল করেন তখন মডেলের সাথে প্রিপ্রসেসিং স্তরগুলি রপ্তানি করা হবে না। এটি সংরক্ষণ করার আগে আপনাকে সেগুলিকে আপনার মডেলের সাথে সংযুক্ত করতে হবে বা সার্ভার-সাইডে পুনরায় প্রয়োগ করতে হবে৷ প্রশিক্ষণের পরে, আপনি রপ্তানির আগে প্রিপ্রসেসিং স্তরগুলি সংযুক্ত করতে পারেন।
আপনি ইমেজ ক্লাসিফিকেশন টিউটোরিয়ালে প্রথম বিকল্পের একটি উদাহরণ খুঁজে পেতে পারেন। এর দ্বিতীয় বিকল্প এখানে প্রদর্শন করা যাক.
ডেটাসেটগুলিতে প্রিপ্রসেসিং স্তরগুলি প্রয়োগ করুন
আপনার আগে তৈরি করা কেরাস প্রিপ্রসেসিং স্তরগুলির সাথে প্রশিক্ষণ, বৈধতা এবং পরীক্ষার ডেটাসেটগুলি কনফিগার করুন। এছাড়াও আপনি I/O ব্লক না হয়ে ডিস্ক থেকে ব্যাচ পেতে সমান্তরাল রিড এবং বাফার করা প্রিফেচিং ব্যবহার করে কর্মক্ষমতার জন্য ডেটাসেটগুলি কনফিগার করবেন। ( tf.data API গাইডের সাহায্যে আরও ভালো পারফরম্যান্সে ডেটাসেট কর্মক্ষমতা সম্পর্কে আরও জানুন।)
batch_size = 32
AUTOTUNE = tf.data.AUTOTUNE
def prepare(ds, shuffle=False, augment=False):
# Resize and rescale all datasets.
ds = ds.map(lambda x, y: (resize_and_rescale(x), y),
num_parallel_calls=AUTOTUNE)
if shuffle:
ds = ds.shuffle(1000)
# Batch all datasets.
ds = ds.batch(batch_size)
# Use data augmentation only on the training set.
if augment:
ds = ds.map(lambda x, y: (data_augmentation(x, training=True), y),
num_parallel_calls=AUTOTUNE)
# Use buffered prefetching on all datasets.
return ds.prefetch(buffer_size=AUTOTUNE)
train_ds = prepare(train_ds, shuffle=True, augment=True)
val_ds = prepare(val_ds)
test_ds = prepare(test_ds)
একটি মডেল প্রশিক্ষণ
সম্পূর্ণতার জন্য, আপনি এখন আপনার তৈরি করা ডেটাসেটগুলি ব্যবহার করে একটি মডেলকে প্রশিক্ষণ দেবেন।
tf.keras.layers.Conv2D ) থাকে যার প্রতিটিতে সর্বোচ্চ পুলিং লেয়ার ( tf.keras.layers.MaxPooling2D ) থাকে। একটি সম্পূর্ণ-সংযুক্ত স্তর রয়েছে ( tf.keras.layers.Dense ) যার উপরে 128টি ইউনিট রয়েছে যা একটি ReLU অ্যাক্টিভেশন ফাংশন ( 'relu' ) দ্বারা সক্রিয় করা হয়েছে। এই মডেলটি সঠিকতার জন্য টিউন করা হয়নি (লক্ষ্য হল আপনাকে মেকানিক্স দেখানো)।
model = tf.keras.Sequential([
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
tf.keras.optimizers.Adam অপ্টিমাইজার এবং tf.keras.losses.SparseCategoricalCrossentropy ক্ষতি ফাংশন চয়ন করুন। প্রতিটি প্রশিক্ষণ যুগের জন্য প্রশিক্ষণ এবং যাচাইকরণের নির্ভুলতা দেখতে, Model.compile এ metrics আর্গুমেন্ট পাস করুন।
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
কয়েক যুগের জন্য ট্রেন:
epochs=5
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
Epoch 1/5 92/92 [==============================] - 13s 110ms/step - loss: 1.2768 - accuracy: 0.4622 - val_loss: 1.0929 - val_accuracy: 0.5640 Epoch 2/5 92/92 [==============================] - 3s 25ms/step - loss: 1.0579 - accuracy: 0.5749 - val_loss: 0.9711 - val_accuracy: 0.6349 Epoch 3/5 92/92 [==============================] - 3s 26ms/step - loss: 0.9677 - accuracy: 0.6291 - val_loss: 0.9764 - val_accuracy: 0.6431 Epoch 4/5 92/92 [==============================] - 3s 25ms/step - loss: 0.9150 - accuracy: 0.6468 - val_loss: 0.8906 - val_accuracy: 0.6431 Epoch 5/5 92/92 [==============================] - 3s 25ms/step - loss: 0.8636 - accuracy: 0.6604 - val_loss: 0.8233 - val_accuracy: 0.6730
loss, acc = model.evaluate(test_ds)
print("Accuracy", acc)
12/12 [==============================] - 5s 14ms/step - loss: 0.7922 - accuracy: 0.6948 Accuracy 0.6948229074478149
কাস্টম ডেটা পরিবর্ধন
আপনি কাস্টম ডেটা অগমেন্টেশন লেয়ারও তৈরি করতে পারেন।
টিউটোরিয়ালের এই বিভাগটি এটি করার দুটি উপায় দেখায়:
- প্রথমে আপনি একটি
tf.keras.layers.Lambdaলেয়ার তৈরি করবেন। সংক্ষিপ্ত কোড লেখার এটি একটি ভাল উপায়। - এর পরে, আপনি সাবক্লাসিংয়ের মাধ্যমে একটি নতুন স্তর লিখবেন, যা আপনাকে আরও নিয়ন্ত্রণ দেয়।
উভয় স্তরই এলোমেলোভাবে একটি চিত্রের রঙগুলিকে উল্টে দেবে, কিছু সম্ভাব্যতা অনুসারে।
def random_invert_img(x, p=0.5):
if tf.random.uniform([]) < p:
x = (255-x)
else:
x
return x
def random_invert(factor=0.5):
return layers.Lambda(lambda x: random_invert_img(x, factor))
random_invert = random_invert()
plt.figure(figsize=(10, 10))
for i in range(9):
augmented_image = random_invert(image)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_image[0].numpy().astype("uint8"))
plt.axis("off")
2022-01-26 05:09:53.045204: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045264: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045312: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045369: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045418: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045467: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.045511: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module 2022-01-26 05:09:53.047630: W tensorflow/compiler/xla/service/gpu/llvm_gpu_backend/gpu_backend_lib.cc:399] target triple not found in the module

পরবর্তী, সাবক্লাসিং দ্বারা একটি কাস্টম স্তর প্রয়োগ করুন:
class RandomInvert(layers.Layer):
def __init__(self, factor=0.5, **kwargs):
super().__init__(**kwargs)
self.factor = factor
def call(self, x):
return random_invert_img(x)
_ = plt.imshow(RandomInvert()(image)[0])

উপরের বিকল্প 1 এবং 2 এ বর্ণিত উভয় স্তরই ব্যবহার করা যেতে পারে।
tf.image ব্যবহার করে
উপরের কেরাস প্রিপ্রসেসিং ইউটিলিটিগুলি সুবিধাজনক। কিন্তু, সূক্ষ্ম নিয়ন্ত্রণের জন্য, আপনি tf.data এবং tf.image ব্যবহার করে আপনার নিজস্ব ডেটা অগমেন্টেশন পাইপলাইন বা স্তরগুলি লিখতে পারেন। (আপনি টেনসরফ্লো অ্যাডঅন ইমেজ: অপারেশন এবং টেনসরফ্লো I/O: কালার স্পেস কনভার্সনগুলিও দেখতে চাইতে পারেন।)
যেহেতু ফুলের ডেটাসেটটি পূর্বে ডেটা বৃদ্ধির সাথে কনফিগার করা হয়েছিল, চলুন নতুন করে শুরু করার জন্য এটি পুনরায় আমদানি করা যাক:
(train_ds, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
এর সাথে কাজ করার জন্য একটি চিত্র পুনরুদ্ধার করুন:
image, label = next(iter(train_ds))
_ = plt.imshow(image)
_ = plt.title(get_label_name(label))
2022-01-26 05:09:59.918847: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.

আসুন মূল এবং বর্ধিত চিত্রগুলিকে পাশাপাশি দেখতে এবং তুলনা করতে নিম্নলিখিত ফাংশনটি ব্যবহার করি:
def visualize(original, augmented):
fig = plt.figure()
plt.subplot(1,2,1)
plt.title('Original image')
plt.imshow(original)
plt.subplot(1,2,2)
plt.title('Augmented image')
plt.imshow(augmented)
তথ্য বৃদ্ধি
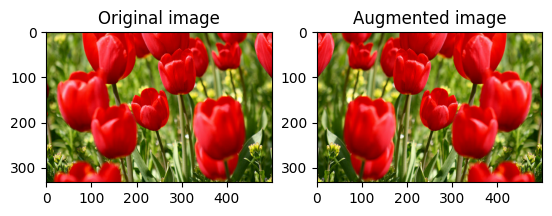
একটি ছবি উল্টান
tf.image.flip_left_right দিয়ে একটি ছবি উল্লম্বভাবে বা অনুভূমিকভাবে ফ্লিপ করুন :
flipped = tf.image.flip_left_right(image)
visualize(image, flipped)
একটি ছবি গ্রেস্কেল করুন
আপনি tf.image.rgb_to_grayscale দিয়ে একটি চিত্রকে গ্রেস্কেল করতে পারেন:
grayscaled = tf.image.rgb_to_grayscale(image)
visualize(image, tf.squeeze(grayscaled))
_ = plt.colorbar()

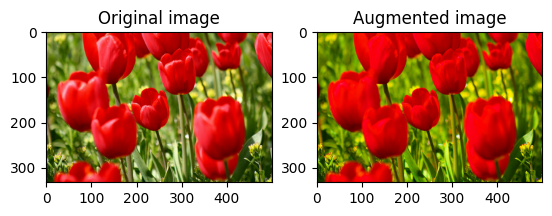
একটি ইমেজ পরিপূর্ণ
একটি স্যাচুরেশন ফ্যাক্টর প্রদান করে tf.image.adjust_saturation সহ একটি চিত্রকে স্যাচুরেট করুন:
saturated = tf.image.adjust_saturation(image, 3)
visualize(image, saturated)
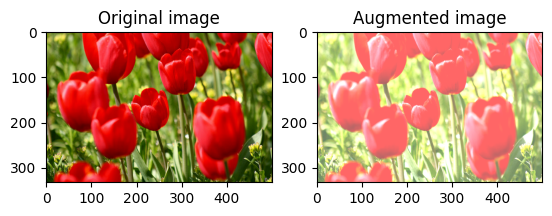
ছবির উজ্জ্বলতা পরিবর্তন করুন
একটি উজ্জ্বলতা ফ্যাক্টর প্রদান করে tf.image.adjust_brightness দিয়ে ছবির উজ্জ্বলতা পরিবর্তন করুন:
bright = tf.image.adjust_brightness(image, 0.4)
visualize(image, bright)
কেন্দ্রে একটি ছবি ক্রপ করুন
tf.image.central_crop ব্যবহার করে ছবিটিকে কেন্দ্র থেকে ছবির অংশ পর্যন্ত ক্রপ করুন:
cropped = tf.image.central_crop(image, central_fraction=0.5)
visualize(image, cropped)
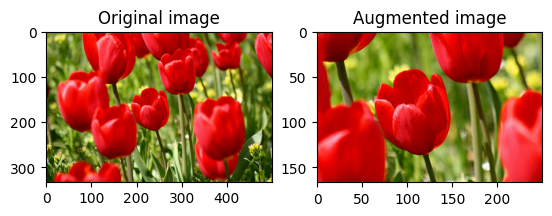
একটি ছবি ঘোরান
tf.image.rot90 দিয়ে একটি চিত্রকে 90 ডিগ্রি ঘোরান:
rotated = tf.image.rot90(image)
visualize(image, rotated)

এলোমেলো রূপান্তর
চিত্রগুলিতে এলোমেলো রূপান্তর প্রয়োগ করা ডেটাসেটটিকে সাধারণীকরণ এবং প্রসারিত করতে আরও সহায়তা করতে পারে। বর্তমান tf.image API এই ধরনের আটটি র্যান্ডম ইমেজ অপারেশন (অপস) প্রদান করে:
-
tf.image.stateless_random_brightness -
tf.image.stateless_random_contrast -
tf.image.stateless_random_crop -
tf.image.stateless_random_flip_left_right -
tf.image.stateless_random_flip_up_down -
tf.image.stateless_random_hue -
tf.image.stateless_random_jpeg_quality -
tf.image.stateless_random_saturation
এই র্যান্ডম ইমেজ অপ্সগুলি সম্পূর্ণরূপে কার্যকরী: আউটপুট শুধুমাত্র ইনপুটের উপর নির্ভর করে। এটি তাদের উচ্চ কার্যক্ষমতা, নির্ধারক ইনপুট পাইপলাইনে ব্যবহার করা সহজ করে তোলে। তারা প্রতিটি ধাপে একটি seed মান ইনপুট করা প্রয়োজন. একই seed দেওয়া হলে, তারা কতবার ডাকা হয়েছে তার থেকে স্বাধীনভাবে একই ফলাফল দেয়।
নিম্নলিখিত বিভাগে, আপনি হবে:
- একটি ইমেজ রূপান্তর করতে র্যান্ডম ইমেজ অপারেশন ব্যবহার করার উদাহরণ দেখুন।
- একটি প্রশিক্ষণ ডেটাসেটে কীভাবে এলোমেলো রূপান্তর প্রয়োগ করতে হয় তা প্রদর্শন করুন।
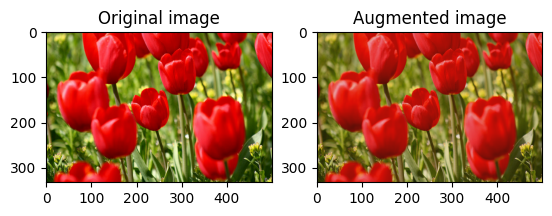
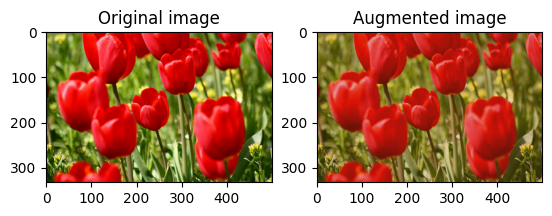
এলোমেলোভাবে ছবির উজ্জ্বলতা পরিবর্তন করুন
একটি উজ্জ্বলতা ফ্যাক্টর এবং seed প্রদান করে tf.image.stateless_random_brightness ব্যবহার করে এলোমেলোভাবে image উজ্জ্বলতা পরিবর্তন করুন। উজ্জ্বলতা ফ্যাক্টরটি [-max_delta, max_delta) পরিসরে এলোমেলোভাবে নির্বাচিত হয় এবং প্রদত্ত seed সাথে যুক্ত।
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_brightness = tf.image.stateless_random_brightness(
image, max_delta=0.95, seed=seed)
visualize(image, stateless_random_brightness)
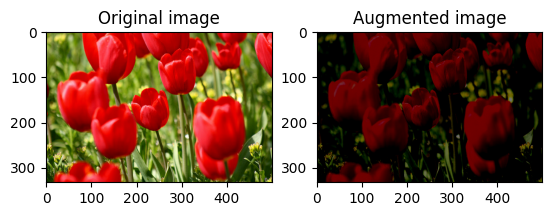
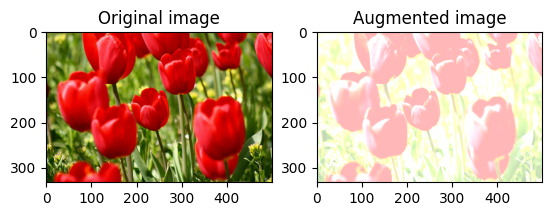
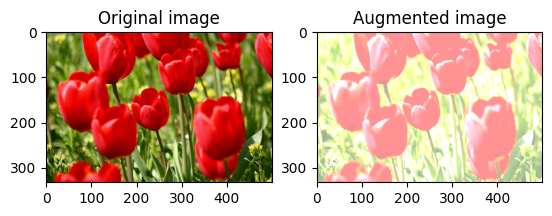
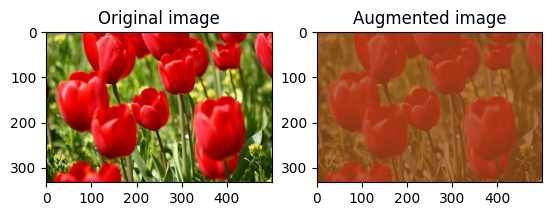
এলোমেলোভাবে চিত্রের বৈসাদৃশ্য পরিবর্তন করুন
tf.image.stateless_random_contrast ব্যবহার করে একটি বৈসাদৃশ্য পরিসীমা এবং seed প্রদান করে এলোমেলোভাবে image বৈসাদৃশ্য পরিবর্তন করুন। বৈসাদৃশ্য পরিসীমা ব্যবধানে [lower, upper] এলোমেলোভাবে নির্বাচিত হয় এবং প্রদত্ত seed সাথে যুক্ত হয়।
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_contrast = tf.image.stateless_random_contrast(
image, lower=0.1, upper=0.9, seed=seed)
visualize(image, stateless_random_contrast)
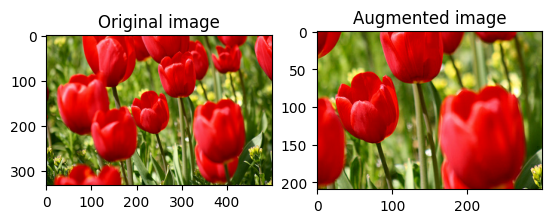
এলোমেলোভাবে একটি ছবি ক্রপ করুন
লক্ষ্য size এবং seed প্রদান করে tf.image.stateless_random_crop ব্যবহার করে এলোমেলোভাবে image ক্রপ করুন। image থেকে যে অংশটি কেটে ফেলা হয় তা এলোমেলোভাবে নির্বাচিত অফসেটে এবং প্রদত্ত seed সাথে যুক্ত।
for i in range(3):
seed = (i, 0) # tuple of size (2,)
stateless_random_crop = tf.image.stateless_random_crop(
image, size=[210, 300, 3], seed=seed)
visualize(image, stateless_random_crop)
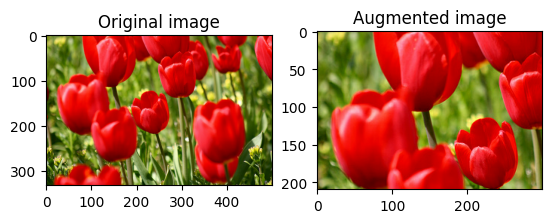
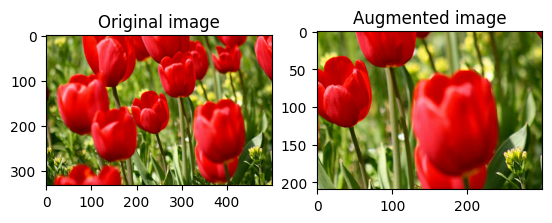
একটি ডেটাসেটে পরিবর্ধন প্রয়োগ করুন
পূর্ববর্তী বিভাগে পরিবর্তন করা হলে প্রথমে ইমেজ ডেটাসেট আবার ডাউনলোড করা যাক।
(train_datasets, val_ds, test_ds), metadata = tfds.load(
'tf_flowers',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
এর পরে, চিত্রগুলির আকার পরিবর্তন এবং পুনরায় স্কেল করার জন্য একটি ইউটিলিটি ফাংশন সংজ্ঞায়িত করুন। এই ফাংশনটি ডেটাসেটে চিত্রের আকার এবং স্কেল একত্রিত করতে ব্যবহার করা হবে:
def resize_and_rescale(image, label):
image = tf.cast(image, tf.float32)
image = tf.image.resize(image, [IMG_SIZE, IMG_SIZE])
image = (image / 255.0)
return image, label
এর আরও সংজ্ঞায়িত করা যাক augment ফাংশন যা চিত্রগুলিতে এলোমেলো রূপান্তর প্রয়োগ করতে পারে। এই ফাংশনটি পরবর্তী ধাপে ডেটাসেটে ব্যবহার করা হবে।
def augment(image_label, seed):
image, label = image_label
image, label = resize_and_rescale(image, label)
image = tf.image.resize_with_crop_or_pad(image, IMG_SIZE + 6, IMG_SIZE + 6)
# Make a new seed.
new_seed = tf.random.experimental.stateless_split(seed, num=1)[0, :]
# Random crop back to the original size.
image = tf.image.stateless_random_crop(
image, size=[IMG_SIZE, IMG_SIZE, 3], seed=seed)
# Random brightness.
image = tf.image.stateless_random_brightness(
image, max_delta=0.5, seed=new_seed)
image = tf.clip_by_value(image, 0, 1)
return image, label
বিকল্প 1: tf.data.experimental.Counter ব্যবহার করা
একটি tf.data.experimental.Counter অবজেক্ট তৈরি করুন (যাকে counter বলি) এবং Dataset.zip (counter, counter) দিয়ে ডেটাসেট। এটি নিশ্চিত করবে যে ডেটাসেটের প্রতিটি চিত্র counter উপর ভিত্তি করে একটি অনন্য মানের (আকৃতির (2,) ) সাথে যুক্ত হয় যা পরে র্যান্ডম রূপান্তরের জন্য seed মান হিসাবে augment ফাংশনে পাস করা যেতে পারে।
# Create a `Counter` object and `Dataset.zip` it together with the training set.
counter = tf.data.experimental.Counter()
train_ds = tf.data.Dataset.zip((train_datasets, (counter, counter)))
প্রশিক্ষণ ডেটাসেটে augment ফাংশন ম্যাপ করুন:
train_ds = (
train_ds
.shuffle(1000)
.map(augment, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
val_ds = (
val_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
test_ds = (
test_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
বিকল্প 2: tf.random.Generator ব্যবহার করা
- একটি প্রাথমিক
seedমান সহ একটিtf.random.Generatorঅবজেক্ট তৈরি করুন। একই জেনারেটর বস্তুতেmake_seedsফাংশন কল করা সর্বদা একটি নতুন, অনন্যseedমান প্রদান করে। - একটি wrapper ফাংশন সংজ্ঞায়িত করুন যেটি: 1)
make_seedsফাংশন কল করে; এবং 2) এলোমেলো রূপান্তরের জন্যaugmentফাংশনে নতুন উৎপন্নseedমান পাস করে।
# Create a generator.
rng = tf.random.Generator.from_seed(123, alg='philox')
# Create a wrapper function for updating seeds.
def f(x, y):
seed = rng.make_seeds(2)[0]
image, label = augment((x, y), seed)
return image, label
প্রশিক্ষণ ডেটাসেটে র্যাপার ফাংশন f ম্যাপ করুন, এবং resize_and_rescale ফাংশন—বৈধকরণ এবং পরীক্ষা সেটে:
train_ds = (
train_datasets
.shuffle(1000)
.map(f, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
val_ds = (
val_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
test_ds = (
test_ds
.map(resize_and_rescale, num_parallel_calls=AUTOTUNE)
.batch(batch_size)
.prefetch(AUTOTUNE)
)
এই ডেটাসেটগুলি এখন পূর্বে দেখানো হিসাবে একটি মডেল প্রশিক্ষণের জন্য ব্যবহার করা যেতে পারে।
পরবর্তী পদক্ষেপ
এই টিউটোরিয়ালটি কেরাস প্রিপ্রসেসিং লেয়ার এবং tf.image ব্যবহার করে ডেটা অগমেন্টেশন প্রদর্শন করেছে।
- আপনার মডেলের মধ্যে প্রিপ্রসেসিং স্তরগুলি কীভাবে অন্তর্ভুক্ত করবেন তা শিখতে, চিত্র শ্রেণিবিন্যাস টিউটোরিয়াল পড়ুন।
- বেসিক টেক্সট ক্লাসিফিকেশন টিউটোরিয়ালে যেমন দেখানো হয়েছে, প্রি-প্রসেসিং স্তরগুলি কীভাবে পাঠ্যকে শ্রেণীবদ্ধ করতে সাহায্য করতে পারে তা শিখতেও আপনি আগ্রহী হতে পারেন।
- আপনি এই নির্দেশিকা থেকে
tf.dataসম্পর্কে আরও জানতে পারেন, এবং আপনি এখানে পারফরম্যান্সের জন্য আপনার ইনপুট পাইপলাইনগুলি কীভাবে কনফিগার করবেন তা শিখতে পারেন।