
| | |  ดูแหล่งที่มาบน GitHub ดูแหล่งที่มาบน GitHub | |
บทช่วยสอนนี้สาธิตการฝึกอบรม Convolutional Neural Network (CNN) อย่างง่าย เพื่อจำแนก รูปภาพ CIFAR เนื่องจากบทช่วยสอนนี้ใช้ Keras Sequential API การสร้างและฝึกโมเดลของคุณจึงใช้โค้ดเพียงไม่กี่บรรทัด
นำเข้า TensorFlow
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
ดาวน์โหลดและเตรียมชุดข้อมูล CIFAR10
ชุดข้อมูล CIFAR10 ประกอบด้วยภาพสี 60,000 ภาพใน 10 คลาส โดยแต่ละคลาสมี 6,000 ภาพ ชุดข้อมูลแบ่งออกเป็นภาพการฝึก 50,000 ภาพและภาพทดสอบ 10,000 ภาพ คลาสเป็นแบบแยกจากกันและไม่มีการทับซ้อนกันระหว่างคลาส
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
# Normalize pixel values to be between 0 and 1
train_images, test_images = train_images / 255.0, test_images / 255.0
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz 170500096/170498071 [==============================] - 11s 0us/step 170508288/170498071 [==============================] - 11s 0us/step
ตรวจสอบข้อมูล
เพื่อตรวจสอบว่าชุดข้อมูลดูถูกต้อง ให้พล็อต 25 ภาพแรกจากชุดการฝึกและแสดงชื่อคลาสด้านล่างแต่ละภาพ:
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i])
# The CIFAR labels happen to be arrays,
# which is why you need the extra index
plt.xlabel(class_names[train_labels[i][0]])
plt.show()

สร้างฐานบิด
โค้ด 6 บรรทัดด้านล่างกำหนดฐานที่บิดเบี้ยวโดยใช้รูปแบบทั่วไป: สแต็กของ เลเยอร์ Conv2D และ MaxPooling2D
เมื่อป้อนข้อมูล CNN จะใช้เทนเซอร์ของรูปร่าง (image_height, image_width, color_channels) โดยไม่สนใจขนาดแบทช์ หากคุณยังใหม่ต่อมิติข้อมูลเหล่านี้ color_channels จะอ้างอิงถึง (R,G,B) ในตัวอย่างนี้ คุณจะกำหนดค่า CNN ของคุณเพื่อประมวลผลอินพุตของรูปร่าง (32, 32, 3) ซึ่งเป็นรูปแบบของภาพ CIFAR คุณสามารถทำได้โดยส่งอาร์กิวเมนต์ input_shape ไปยังเลเยอร์แรกของคุณ
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
มาแสดงสถาปัตยกรรมของแบบจำลองของคุณกัน:
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
max_pooling2d (MaxPooling2D (None, 15, 15, 32) 0
)
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
max_pooling2d_1 (MaxPooling (None, 6, 6, 64) 0
2D)
conv2d_2 (Conv2D) (None, 4, 4, 64) 36928
=================================================================
Total params: 56,320
Trainable params: 56,320
Non-trainable params: 0
_________________________________________________________________
ด้านบน คุณจะเห็นว่าผลลัพธ์ของทุกเลเยอร์ Conv2D และ MaxPooling2D เป็นเทนเซอร์ของรูปร่าง 3 มิติ (ความสูง ความกว้าง ช่อง) ขนาดความกว้างและความสูงมักจะหดตัวเมื่อคุณเข้าไปลึกในเครือข่าย จำนวนช่องสัญญาณเอาต์พุตสำหรับแต่ละเลเยอร์ Conv2D ถูกควบคุมโดยอาร์กิวเมนต์แรก (เช่น 32 หรือ 64) โดยปกติ เมื่อความกว้างและความสูงลดลง คุณสามารถซื้อ (คำนวณ) เพื่อเพิ่มช่องสัญญาณออกในแต่ละเลเยอร์ Conv2D ได้
เพิ่มชั้นหนาแน่นด้านบน
ในการทำให้โมเดลสมบูรณ์ คุณจะต้องป้อนเทนเซอร์เอาต์พุตสุดท้ายจากฐานที่บิดเบี้ยว (ของรูปร่าง (4, 4, 64)) ลงในเลเยอร์หนาแน่นอย่างน้อยหนึ่งชั้นเพื่อทำการจำแนก เลเยอร์หนาแน่นใช้เวกเตอร์เป็นอินพุต (ซึ่งคือ 1D) ในขณะที่เอาต์พุตปัจจุบันเป็น 3D เทนเซอร์ ขั้นแรก คุณจะต้องทำให้แบน (หรือคลี่ออก) เอาต์พุต 3D เป็น 1D จากนั้นเพิ่มเลเยอร์หนาแน่นหนึ่งชั้นขึ้นไปที่ด้านบน CIFAR มี 10 คลาสเอาต์พุต ดังนั้นคุณใช้ Dense เลเยอร์สุดท้ายที่มี 10 เอาต์พุต
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10))
นี่คือสถาปัตยกรรมที่สมบูรณ์ของแบบจำลองของคุณ:
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
max_pooling2d (MaxPooling2D (None, 15, 15, 32) 0
)
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
max_pooling2d_1 (MaxPooling (None, 6, 6, 64) 0
2D)
conv2d_2 (Conv2D) (None, 4, 4, 64) 36928
flatten (Flatten) (None, 1024) 0
dense (Dense) (None, 64) 65600
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 122,570
Trainable params: 122,570
Non-trainable params: 0
_________________________________________________________________
สรุปเครือข่ายแสดงให้เห็นว่าเอาต์พุต (4, 4, 64) ถูกทำให้แบนเป็นเวกเตอร์ที่มีรูปร่าง (1024) ก่อนที่จะผ่านสองชั้นหนาแน่น
รวบรวมและฝึกโมเดล
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))
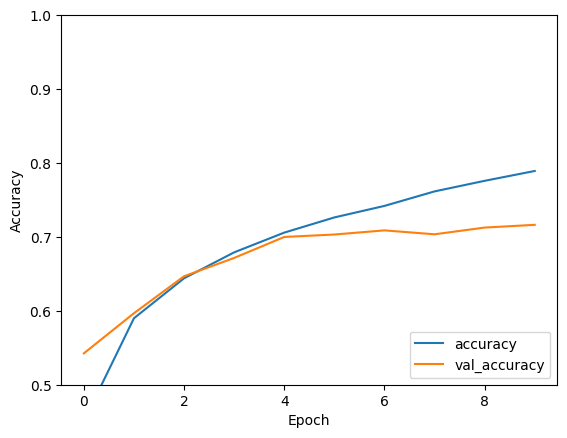
Epoch 1/10 1563/1563 [==============================] - 8s 4ms/step - loss: 1.4971 - accuracy: 0.4553 - val_loss: 1.2659 - val_accuracy: 0.5492 Epoch 2/10 1563/1563 [==============================] - 6s 4ms/step - loss: 1.1424 - accuracy: 0.5966 - val_loss: 1.1025 - val_accuracy: 0.6098 Epoch 3/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.9885 - accuracy: 0.6539 - val_loss: 0.9557 - val_accuracy: 0.6629 Epoch 4/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.8932 - accuracy: 0.6878 - val_loss: 0.8924 - val_accuracy: 0.6935 Epoch 5/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.8222 - accuracy: 0.7130 - val_loss: 0.8679 - val_accuracy: 0.7025 Epoch 6/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.7663 - accuracy: 0.7323 - val_loss: 0.9336 - val_accuracy: 0.6819 Epoch 7/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.7224 - accuracy: 0.7466 - val_loss: 0.8546 - val_accuracy: 0.7086 Epoch 8/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.6726 - accuracy: 0.7611 - val_loss: 0.8777 - val_accuracy: 0.7068 Epoch 9/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.6372 - accuracy: 0.7760 - val_loss: 0.8410 - val_accuracy: 0.7179 Epoch 10/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.6024 - accuracy: 0.7875 - val_loss: 0.8475 - val_accuracy: 0.7192
ประเมินแบบจำลอง
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
313/313 - 1s - loss: 0.8475 - accuracy: 0.7192 - 634ms/epoch - 2ms/step
print(test_acc)
0.7192000150680542
CNN แบบง่ายของคุณได้รับความแม่นยำในการทดสอบมากกว่า 70% ไม่เลวสำหรับโค้ดสองสามบรรทัด! สำหรับรูปแบบ CNN อื่น ให้ลองดู TensorFlow 2 quickstart สำหรับตัวอย่างผู้เชี่ยวชาญ ที่ใช้ Keras subclassing API และ tf.GradientTape