
| | |  Wyświetl źródło na GitHub Wyświetl źródło na GitHub | |
W tym samouczku przedstawiono uczenie prostej splotowej sieci neuronowej (CNN) w celu klasyfikowania obrazów CIFAR . Ponieważ ten samouczek używa interfejsu API Keras Sequential , tworzenie i trenowanie modelu zajmie tylko kilka linijek kodu.
Importuj przepływ tensora
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
Pobierz i przygotuj zbiór danych CIFAR10
Zestaw danych CIFAR10 zawiera 60 000 kolorowych obrazów w 10 klasach, z 6000 obrazów w każdej klasie. Zbiór danych jest podzielony na 50 000 obrazów treningowych i 10 000 obrazów testowych. Klasy wzajemnie się wykluczają i nie nakładają się na siebie.
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
# Normalize pixel values to be between 0 and 1
train_images, test_images = train_images / 255.0, test_images / 255.0
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz 170500096/170498071 [==============================] - 11s 0us/step 170508288/170498071 [==============================] - 11s 0us/step
Zweryfikuj dane
Aby sprawdzić, czy zestaw danych wygląda poprawnie, wykreślmy pierwszych 25 obrazów z zestawu szkoleniowego i wyświetlmy nazwę klasy pod każdym obrazem:
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i])
# The CIFAR labels happen to be arrays,
# which is why you need the extra index
plt.xlabel(class_names[train_labels[i][0]])
plt.show()

Stwórz bazę konwolucyjną
Poniższe 6 wierszy kodu definiuje splotową podstawę przy użyciu wspólnego wzorca: stos warstw Conv2D i MaxPooling2D .
Jako dane wejściowe CNN przyjmuje tensory kształtu (wysokość_obrazu, szerokość_obrazu, kanały_koloru), ignorując rozmiar partii. Jeśli jesteś nowy w tych wymiarach, color_channels odnosi się do (R,G,B). W tym przykładzie skonfigurujesz CNN do przetwarzania danych wejściowych kształtu (32, 32, 3), który jest formatem obrazów CIFAR. Możesz to zrobić, przekazując argument input_shape do swojej pierwszej warstwy.
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
Pokażmy dotychczasową architekturę Twojego modelu:
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
max_pooling2d (MaxPooling2D (None, 15, 15, 32) 0
)
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
max_pooling2d_1 (MaxPooling (None, 6, 6, 64) 0
2D)
conv2d_2 (Conv2D) (None, 4, 4, 64) 36928
=================================================================
Total params: 56,320
Trainable params: 56,320
Non-trainable params: 0
_________________________________________________________________
Powyżej widać, że wyjściem każdej warstwy Conv2D i MaxPooling2D jest tensor 3D kształtu (wysokość, szerokość, kanały). Wymiary szerokości i wysokości mają tendencję do zmniejszania się w miarę zagłębiania się w sieć. Liczba kanałów wyjściowych dla każdej warstwy Conv2D jest kontrolowana przez pierwszy argument (np. 32 lub 64). Zazwyczaj, gdy zmniejsza się szerokość i wysokość, można sobie pozwolić (obliczeniowo) na dodanie większej liczby kanałów wyjściowych w każdej warstwie Conv2D.
Dodaj gęste warstwy na górze
Aby ukończyć model, wprowadzisz ostatni tensor wyjściowy z podstawy splotu (o kształcie (4, 4, 64)) do jednej lub więcej warstw Dense w celu przeprowadzenia klasyfikacji. Gęste warstwy przyjmują wektory jako dane wejściowe (które są 1D), podczas gdy bieżące wyjście jest tensorem 3D. Najpierw spłaszczysz (lub rozwiniesz) wyjście 3D do 1D, a następnie dodasz jedną lub więcej warstw Dense na wierzchu. CIFAR ma 10 klas wyjściowych, więc używasz ostatniej warstwy Dense z 10 wyjściami.
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10))
Oto pełna architektura Twojego modelu:
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
max_pooling2d (MaxPooling2D (None, 15, 15, 32) 0
)
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
max_pooling2d_1 (MaxPooling (None, 6, 6, 64) 0
2D)
conv2d_2 (Conv2D) (None, 4, 4, 64) 36928
flatten (Flatten) (None, 1024) 0
dense (Dense) (None, 64) 65600
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 122,570
Trainable params: 122,570
Non-trainable params: 0
_________________________________________________________________
Podsumowanie sieci pokazuje, że (4, 4, 64) dane wyjściowe zostały spłaszczone do wektorów kształtu (1024) przed przejściem przez dwie warstwy gęste.
Skompiluj i trenuj model
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))
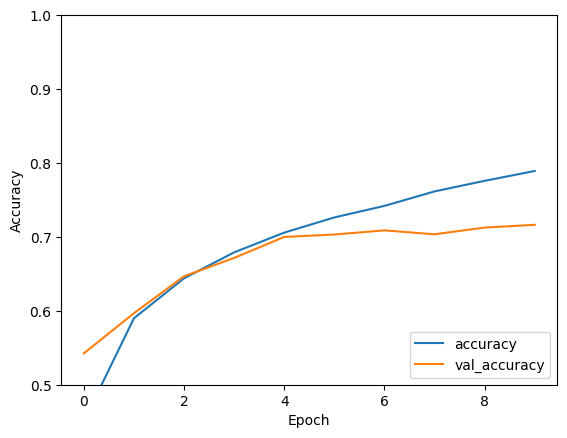
Epoch 1/10 1563/1563 [==============================] - 8s 4ms/step - loss: 1.4971 - accuracy: 0.4553 - val_loss: 1.2659 - val_accuracy: 0.5492 Epoch 2/10 1563/1563 [==============================] - 6s 4ms/step - loss: 1.1424 - accuracy: 0.5966 - val_loss: 1.1025 - val_accuracy: 0.6098 Epoch 3/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.9885 - accuracy: 0.6539 - val_loss: 0.9557 - val_accuracy: 0.6629 Epoch 4/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.8932 - accuracy: 0.6878 - val_loss: 0.8924 - val_accuracy: 0.6935 Epoch 5/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.8222 - accuracy: 0.7130 - val_loss: 0.8679 - val_accuracy: 0.7025 Epoch 6/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.7663 - accuracy: 0.7323 - val_loss: 0.9336 - val_accuracy: 0.6819 Epoch 7/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.7224 - accuracy: 0.7466 - val_loss: 0.8546 - val_accuracy: 0.7086 Epoch 8/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.6726 - accuracy: 0.7611 - val_loss: 0.8777 - val_accuracy: 0.7068 Epoch 9/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.6372 - accuracy: 0.7760 - val_loss: 0.8410 - val_accuracy: 0.7179 Epoch 10/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.6024 - accuracy: 0.7875 - val_loss: 0.8475 - val_accuracy: 0.7192
Oceń model
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
313/313 - 1s - loss: 0.8475 - accuracy: 0.7192 - 634ms/epoch - 2ms/step
print(test_acc)
0.7192000150680542
Twoja prosta CNN osiągnęła dokładność testu ponad 70%. Nieźle jak na kilka linijek kodu! Aby zapoznać się z innym stylem CNN, zapoznaj się z przykładem szybkiego startu TensorFlow 2 dla ekspertów , który używa interfejsu API podklas Keras i tf.GradientTape .