
| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
يوضح هذا البرنامج التعليمي تدريب شبكة عصبية تلافيفية بسيطة (CNN) لتصنيف صور CIFAR . نظرًا لأن هذا البرنامج التعليمي يستخدم Keras Sequential API ، فإن إنشاء نموذجك وتدريبه سيستغرق بضعة أسطر من التعليمات البرمجية.
استيراد TensorFlow
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
قم بتنزيل وإعداد مجموعة بيانات CIFAR10
تحتوي مجموعة بيانات CIFAR10 على 60.000 صورة ملونة في 10 فئات ، مع 6000 صورة في كل فئة. تنقسم مجموعة البيانات إلى 50000 صورة تدريب و 10000 صورة اختبار. الفئات متنافية ولا يوجد تداخل بينها.
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
# Normalize pixel values to be between 0 and 1
train_images, test_images = train_images / 255.0, test_images / 255.0
Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz 170500096/170498071 [==============================] - 11s 0us/step 170508288/170498071 [==============================] - 11s 0us/step
تحقق من البيانات
للتحقق من أن مجموعة البيانات تبدو صحيحة ، دعنا نرسم أول 25 صورة من مجموعة التدريب ونعرض اسم الفصل أسفل كل صورة:
class_names = ['airplane', 'automobile', 'bird', 'cat', 'deer',
'dog', 'frog', 'horse', 'ship', 'truck']
plt.figure(figsize=(10,10))
for i in range(25):
plt.subplot(5,5,i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i])
# The CIFAR labels happen to be arrays,
# which is why you need the extra index
plt.xlabel(class_names[train_labels[i][0]])
plt.show()

أنشئ القاعدة التلافيفية
تحدد الأسطر الستة من الكود أدناه القاعدة التلافيفية باستخدام نمط مشترك: كومة من طبقات Conv2D و MaxPooling2D .
كإدخال ، تأخذ CNN الموترات من الشكل (image_height ، image_width ، color_channels) ، متجاهلة حجم الدُفعة. إذا كنت جديدًا على هذه الأبعاد ، فإن قنوات color_channels تشير إلى (R ، G ، B). في هذا المثال ، ستقوم بتكوين شبكة CNN الخاصة بك لمعالجة مدخلات الشكل (32 ، 32 ، 3) ، وهو تنسيق صور CIFAR. يمكنك القيام بذلك عن طريق تمرير input_shape إلى الطبقة الأولى.
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
دعنا نعرض بنية نموذجك حتى الآن:
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
max_pooling2d (MaxPooling2D (None, 15, 15, 32) 0
)
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
max_pooling2d_1 (MaxPooling (None, 6, 6, 64) 0
2D)
conv2d_2 (Conv2D) (None, 4, 4, 64) 36928
=================================================================
Total params: 56,320
Trainable params: 56,320
Non-trainable params: 0
_________________________________________________________________
أعلاه ، يمكنك أن ترى أن ناتج كل طبقة Conv2D و MaxPooling2D هو موتر ثلاثي الأبعاد للشكل (الارتفاع ، العرض ، القنوات). تميل أبعاد العرض والارتفاع إلى الانكماش كلما تعمقت في الشبكة. يتم التحكم في عدد قنوات الإخراج لكل طبقة Conv2D بواسطة الوسيطة الأولى (على سبيل المثال ، 32 أو 64). عادةً ، مع تقلص العرض والارتفاع ، يمكنك (حسابيًا) إضافة المزيد من قنوات الإخراج في كل طبقة Conv2D.
أضف طبقات كثيفة في الأعلى
لإكمال النموذج ، ستقوم بتغذية آخر موتر الإخراج من القاعدة التلافيفية (للشكل (4 ، 4 ، 64)) في طبقة كثيفة واحدة أو أكثر لإجراء التصنيف. تأخذ الطبقات الكثيفة المتجهات كمدخلات (وهي 1D) ، بينما الإخراج الحالي هو موتر ثلاثي الأبعاد. أولاً ، ستقوم بتسوية (أو إلغاء) الإخراج ثلاثي الأبعاد إلى 1D ، ثم إضافة طبقة كثيفة واحدة أو أكثر في الأعلى. تحتوي CIFAR على 10 فئات إخراج ، لذلك يمكنك استخدام طبقة كثيفة نهائية مع 10 مخرجات.
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10))
ها هي البنية الكاملة لنموذجك:
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 30, 30, 32) 896
max_pooling2d (MaxPooling2D (None, 15, 15, 32) 0
)
conv2d_1 (Conv2D) (None, 13, 13, 64) 18496
max_pooling2d_1 (MaxPooling (None, 6, 6, 64) 0
2D)
conv2d_2 (Conv2D) (None, 4, 4, 64) 36928
flatten (Flatten) (None, 1024) 0
dense (Dense) (None, 64) 65600
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 122,570
Trainable params: 122,570
Non-trainable params: 0
_________________________________________________________________
يوضح ملخص الشبكة أنه تم تسوية النواتج (4 ، 4 ، 64) إلى متجهات الشكل (1024) قبل المرور عبر طبقتين كثيفتين.
تجميع وتدريب النموذج
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
history = model.fit(train_images, train_labels, epochs=10,
validation_data=(test_images, test_labels))
Epoch 1/10 1563/1563 [==============================] - 8s 4ms/step - loss: 1.4971 - accuracy: 0.4553 - val_loss: 1.2659 - val_accuracy: 0.5492 Epoch 2/10 1563/1563 [==============================] - 6s 4ms/step - loss: 1.1424 - accuracy: 0.5966 - val_loss: 1.1025 - val_accuracy: 0.6098 Epoch 3/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.9885 - accuracy: 0.6539 - val_loss: 0.9557 - val_accuracy: 0.6629 Epoch 4/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.8932 - accuracy: 0.6878 - val_loss: 0.8924 - val_accuracy: 0.6935 Epoch 5/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.8222 - accuracy: 0.7130 - val_loss: 0.8679 - val_accuracy: 0.7025 Epoch 6/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.7663 - accuracy: 0.7323 - val_loss: 0.9336 - val_accuracy: 0.6819 Epoch 7/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.7224 - accuracy: 0.7466 - val_loss: 0.8546 - val_accuracy: 0.7086 Epoch 8/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.6726 - accuracy: 0.7611 - val_loss: 0.8777 - val_accuracy: 0.7068 Epoch 9/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.6372 - accuracy: 0.7760 - val_loss: 0.8410 - val_accuracy: 0.7179 Epoch 10/10 1563/1563 [==============================] - 6s 4ms/step - loss: 0.6024 - accuracy: 0.7875 - val_loss: 0.8475 - val_accuracy: 0.7192
قم بتقييم النموذج
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0.5, 1])
plt.legend(loc='lower right')
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
313/313 - 1s - loss: 0.8475 - accuracy: 0.7192 - 634ms/epoch - 2ms/step
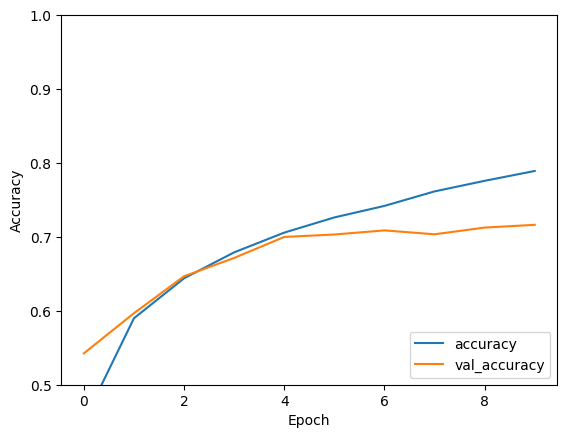
print(test_acc)
0.7192000150680542
لقد حققت شبكة CNN الخاصة بك دقة اختبار تزيد عن 70٪. ليس سيئا لبضعة أسطر من التعليمات البرمجية! للحصول على نمط CNN آخر ، تحقق من TensorFlow 2 Quickstart للحصول على مثال الخبراء الذي يستخدم Keras subclassing API و tf.GradientTape .