
| | |  GitHub'da görüntüle GitHub'da görüntüle | | |
Bu öğretici, bir görüntüyü başka bir görüntünün tarzında oluşturmak için derin öğrenmeyi kullanır (hiç Picasso veya Van Gogh gibi resim yapabilmeyi dilediniz mi?). Bu, sinirsel stil aktarımı olarak bilinir ve teknik, Sanatsal Tarzın Sinirsel Algoritması'nda (Gatys ve diğerleri) ana hatlarıyla anlatılmıştır.
Stil aktarımının basit bir uygulaması için, TensorFlow Hub'dan önceden eğitilmiş Rastgele Görüntü Stilizasyonu modelinin nasıl kullanılacağı veya TensorFlow Lite ile bir stil aktarım modelinin nasıl kullanılacağı hakkında daha fazla bilgi edinmek için bu eğiticiye göz atın.
Nöral stil aktarımı, içerik görüntüsü ve stil referans görüntüsü (ünlü bir ressamın eseri gibi) olmak üzere iki görüntü almak ve çıktı görüntüsünün içerik görüntüsü gibi görünüp "boyalı" görünmesi için bunları harmanlamak için kullanılan bir optimizasyon tekniğidir. stil referans görüntüsünün tarzında.
Bu, çıktı görüntüsünün, içerik görüntüsünün içerik istatistikleriyle ve stil referans görüntüsünün stil istatistikleriyle eşleşecek şekilde optimize edilmesiyle gerçekleştirilir. Bu istatistikler, evrişimli bir ağ kullanılarak görüntülerden çıkarılır.
Örneğin, bu köpeğin ve Wassily Kandinsky'nin Kompozisyon 7'sinin bir görüntüsünü alalım:

Elf tarafından Wikimedia Commons'tan Sarı Labrador Görünümü. Lisans CC BY-SA 3.0
{kind=link}

Şimdi, Kandinsky bu Köpeğin resmini sadece bu stille boyamaya karar verse nasıl görünürdü? Bunun gibi bir şey mi?

Kurmak
Modülleri içe aktarın ve yapılandırın
import os
import tensorflow as tf
# Load compressed models from tensorflow_hub
os.environ['TFHUB_MODEL_LOAD_FORMAT'] = 'COMPRESSED'
import IPython.display as display
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['figure.figsize'] = (12, 12)
mpl.rcParams['axes.grid'] = False
import numpy as np
import PIL.Image
import time
import functools
def tensor_to_image(tensor):
tensor = tensor*255
tensor = np.array(tensor, dtype=np.uint8)
if np.ndim(tensor)>3:
assert tensor.shape[0] == 1
tensor = tensor[0]
return PIL.Image.fromarray(tensor)
Görselleri indirin ve bir stil görseli ve bir içerik görseli seçin:
content_path = tf.keras.utils.get_file('YellowLabradorLooking_new.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg')
style_path = tf.keras.utils.get_file('kandinsky5.jpg','https://storage.googleapis.com/download.tensorflow.org/example_images/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg 196608/195196 [==============================] - 0s 0us/step 204800/195196 [===============================] - 0s 0us/step
Girişi görselleştirin
Bir görüntüyü yüklemek ve maksimum boyutunu 512 piksel ile sınırlamak için bir işlev tanımlayın.
def load_img(path_to_img):
max_dim = 512
img = tf.io.read_file(path_to_img)
img = tf.image.decode_image(img, channels=3)
img = tf.image.convert_image_dtype(img, tf.float32)
shape = tf.cast(tf.shape(img)[:-1], tf.float32)
long_dim = max(shape)
scale = max_dim / long_dim
new_shape = tf.cast(shape * scale, tf.int32)
img = tf.image.resize(img, new_shape)
img = img[tf.newaxis, :]
return img
Bir resmi görüntülemek için basit bir işlev oluşturun:
def imshow(image, title=None):
if len(image.shape) > 3:
image = tf.squeeze(image, axis=0)
plt.imshow(image)
if title:
plt.title(title)
content_image = load_img(content_path)
style_image = load_img(style_path)
plt.subplot(1, 2, 1)
imshow(content_image, 'Content Image')
plt.subplot(1, 2, 2)
imshow(style_image, 'Style Image')

TF-Hub kullanarak Hızlı Stil Aktarımı
Bu öğretici, görüntü içeriğini belirli bir stile göre optimize eden orijinal stil aktarım algoritmasını gösterir. Ayrıntılara girmeden önce, TensorFlow Hub modelinin bunu nasıl yaptığını görelim:
import tensorflow_hub as hub
hub_model = hub.load('https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2')
stylized_image = hub_model(tf.constant(content_image), tf.constant(style_image))[0]
tensor_to_image(stylized_image)
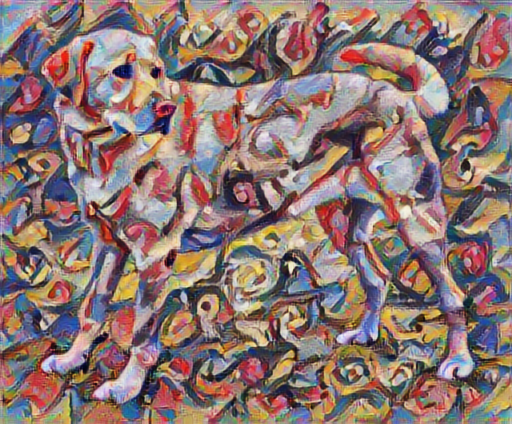
İçerik ve stil temsillerini tanımlayın
Görüntünün içerik ve stil temsillerini elde etmek için modelin ara katmanlarını kullanın. Ağın giriş katmanından başlayarak, ilk birkaç katman aktivasyonu, kenarlar ve dokular gibi düşük seviyeli özellikleri temsil eder. Ağda ilerlerken, son birkaç katman daha yüksek seviyeli özellikleri temsil eder— tekerlekler veya gözler gibi nesne parçaları. Bu durumda, önceden eğitilmiş bir görüntü sınıflandırma ağı olan VGG19 ağ mimarisini kullanıyorsunuz. Bu ara katmanlar, görüntülerden içerik ve stilin temsilini tanımlamak için gereklidir. Bir girdi görüntüsü için, bu ara katmanlarda karşılık gelen stil ve içerik hedefi temsillerini eşleştirmeye çalışın.
Bir VGG19 yükleyin ve doğru kullanıldığından emin olmak için resmimizde test edin:
x = tf.keras.applications.vgg19.preprocess_input(content_image*255)
x = tf.image.resize(x, (224, 224))
vgg = tf.keras.applications.VGG19(include_top=True, weights='imagenet')
prediction_probabilities = vgg(x)
prediction_probabilities.shape
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg19/vgg19_weights_tf_dim_ordering_tf_kernels.h5 574717952/574710816 [==============================] - 17s 0us/step 574726144/574710816 [==============================] - 17s 0us/step TensorShape([1, 1000])yer tutucu12 l10n-yer
predicted_top_5 = tf.keras.applications.vgg19.decode_predictions(prediction_probabilities.numpy())[0]
[(class_name, prob) for (number, class_name, prob) in predicted_top_5]
[('Labrador_retriever', 0.493171),
('golden_retriever', 0.2366529),
('kuvasz', 0.036357544),
('Chesapeake_Bay_retriever', 0.024182785),
('Greater_Swiss_Mountain_dog', 0.0186461)]
Şimdi sınıflandırma başlığı olmadan bir VGG19 yükleyin ve katman adlarını listeleyin
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
print()
for layer in vgg.layers:
print(layer.name)
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg19/vgg19_weights_tf_dim_ordering_tf_kernels_notop.h5 80142336/80134624 [==============================] - 2s 0us/step 80150528/80134624 [==============================] - 2s 0us/step input_2 block1_conv1 block1_conv2 block1_pool block2_conv1 block2_conv2 block2_pool block3_conv1 block3_conv2 block3_conv3 block3_conv4 block3_pool block4_conv1 block4_conv2 block4_conv3 block4_conv4 block4_pool block5_conv1 block5_conv2 block5_conv3 block5_conv4 block5_pool
Görüntünün stilini ve içeriğini temsil etmek için ağdan ara katmanları seçin:
content_layers = ['block5_conv2']
style_layers = ['block1_conv1',
'block2_conv1',
'block3_conv1',
'block4_conv1',
'block5_conv1']
num_content_layers = len(content_layers)
num_style_layers = len(style_layers)
Stil ve içerik için ara katmanlar
Öyleyse neden önceden eğitilmiş görüntü sınıflandırma ağımızdaki bu ara çıktılar, stil ve içerik temsillerini tanımlamamıza izin veriyor?
Yüksek düzeyde, bir ağın görüntü sınıflandırması yapabilmesi için (bu ağın yapmak üzere eğitildiği), görüntüyü anlaması gerekir. Bu, ham görüntüyü girdi pikselleri olarak almayı ve ham görüntü piksellerini görüntü içinde bulunan özelliklerin karmaşık bir anlayışına dönüştüren bir dahili temsil oluşturmayı gerektirir.
Bu aynı zamanda evrişimli sinir ağlarının iyi genelleme yapabilmesinin bir nedenidir: arka plan gürültüsüne ve diğer rahatsızlıklara karşı agnostik olan sınıflar içindeki (örneğin kedilere karşı köpekler) değişmezlikleri ve tanımlayıcı özellikleri yakalayabilirler. Bu nedenle, ham görüntünün modele beslendiği yer ile çıktı sınıflandırma etiketi arasında bir yerde, model karmaşık bir özellik çıkarıcı olarak hizmet eder. Modelin ara katmanlarına erişerek, girdi görüntülerinin içeriğini ve stilini tanımlayabilirsiniz.
Modeli oluşturun
tf.keras.applications içindeki ağlar, tf.keras.applications işlevsel API'sini kullanarak ara katman değerlerini kolayca çıkarabilmeniz için tasarlanmıştır.
İşlevsel API'yi kullanarak bir model tanımlamak için girişleri ve çıkışları belirtin:
model = Model(inputs, outputs)
Aşağıdaki işlev, ara katman çıktılarının bir listesini döndüren bir VGG19 modeli oluşturur:
def vgg_layers(layer_names):
""" Creates a vgg model that returns a list of intermediate output values."""
# Load our model. Load pretrained VGG, trained on imagenet data
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
vgg.trainable = False
outputs = [vgg.get_layer(name).output for name in layer_names]
model = tf.keras.Model([vgg.input], outputs)
return model
Ve modeli oluşturmak için:
style_extractor = vgg_layers(style_layers)
style_outputs = style_extractor(style_image*255)
#Look at the statistics of each layer's output
for name, output in zip(style_layers, style_outputs):
print(name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
print()
block1_conv1 shape: (1, 336, 512, 64) min: 0.0 max: 835.5256 mean: 33.97525 block2_conv1 shape: (1, 168, 256, 128) min: 0.0 max: 4625.8857 mean: 199.82687 block3_conv1 shape: (1, 84, 128, 256) min: 0.0 max: 8789.239 mean: 230.78099 block4_conv1 shape: (1, 42, 64, 512) min: 0.0 max: 21566.135 mean: 791.24005 block5_conv1 shape: (1, 21, 32, 512) min: 0.0 max: 3189.2542 mean: 59.179478
stil hesapla
Bir görüntünün içeriği, ara özellik haritalarının değerleri ile temsil edilir.
Görünüşe göre, bir görüntünün stili, farklı özellik haritaları arasındaki araçlar ve korelasyonlarla tanımlanabilir. Özellik vektörünün dış çarpımını her konumda kendisiyle birlikte alarak ve bu dış çarpımın tüm konumlar üzerinden ortalamasını alarak bu bilgiyi içeren bir Gram matrisi hesaplayın. Bu Gram matrisi belirli bir katman için şu şekilde hesaplanabilir:
\[G^l_{cd} = \frac{\sum_{ij} F^l_{ijc}(x)F^l_{ijd}(x)}{IJ}\]
Bu, tf.linalg.einsum işlevi kullanılarak kısaca uygulanabilir:
def gram_matrix(input_tensor):
result = tf.linalg.einsum('bijc,bijd->bcd', input_tensor, input_tensor)
input_shape = tf.shape(input_tensor)
num_locations = tf.cast(input_shape[1]*input_shape[2], tf.float32)
return result/(num_locations)
Stil ve içerik ayıklayın
Stil ve içerik tensörlerini döndüren bir model oluşturun.
class StyleContentModel(tf.keras.models.Model):
def __init__(self, style_layers, content_layers):
super(StyleContentModel, self).__init__()
self.vgg = vgg_layers(style_layers + content_layers)
self.style_layers = style_layers
self.content_layers = content_layers
self.num_style_layers = len(style_layers)
self.vgg.trainable = False
def call(self, inputs):
"Expects float input in [0,1]"
inputs = inputs*255.0
preprocessed_input = tf.keras.applications.vgg19.preprocess_input(inputs)
outputs = self.vgg(preprocessed_input)
style_outputs, content_outputs = (outputs[:self.num_style_layers],
outputs[self.num_style_layers:])
style_outputs = [gram_matrix(style_output)
for style_output in style_outputs]
content_dict = {content_name: value
for content_name, value
in zip(self.content_layers, content_outputs)}
style_dict = {style_name: value
for style_name, value
in zip(self.style_layers, style_outputs)}
return {'content': content_dict, 'style': style_dict}
Bir görüntüye çağrıldığında, bu model style_layers gram matrisini (stili) ve content_layers içeriğini döndürür:
extractor = StyleContentModel(style_layers, content_layers)
results = extractor(tf.constant(content_image))
print('Styles:')
for name, output in sorted(results['style'].items()):
print(" ", name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
print()
print("Contents:")
for name, output in sorted(results['content'].items()):
print(" ", name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
Styles:
block1_conv1
shape: (1, 64, 64)
min: 0.0055228462
max: 28014.557
mean: 263.79022
block2_conv1
shape: (1, 128, 128)
min: 0.0
max: 61479.496
mean: 9100.949
block3_conv1
shape: (1, 256, 256)
min: 0.0
max: 545623.44
mean: 7660.976
block4_conv1
shape: (1, 512, 512)
min: 0.0
max: 4320502.0
mean: 134288.84
block5_conv1
shape: (1, 512, 512)
min: 0.0
max: 110005.37
mean: 1487.0378
Contents:
block5_conv2
shape: (1, 26, 32, 512)
min: 0.0
max: 2410.8796
mean: 13.764149
Gradyan inişini çalıştır
Bu stil ve içerik çıkarıcı ile artık stil aktarım algoritmasını uygulayabilirsiniz. Bunu, görüntünüzün çıktısının her bir hedefe göre ortalama kare hatasını hesaplayarak yapın, ardından bu kayıpların ağırlıklı toplamını alın.
Stilinizi ve içerik hedef değerlerinizi belirleyin:
style_targets = extractor(style_image)['style']
content_targets = extractor(content_image)['content']
Optimize edilecek görüntüyü içerecek bir tf.Variable tanımlayın. Bunu hızlı hale getirmek için, onu içerik görüntüsüyle başlatın ( tf.Variable , içerik görüntüsüyle aynı şekilde olmalıdır):
image = tf.Variable(content_image)
Bu bir kayan görüntü olduğundan, piksel değerlerini 0 ile 1 arasında tutmak için bir işlev tanımlayın.
def clip_0_1(image):
return tf.clip_by_value(image, clip_value_min=0.0, clip_value_max=1.0)
Bir optimize edici oluşturun. Gazete LBFGS'yi öneriyor, ancak Adam da iyi çalışıyor:
opt = tf.optimizers.Adam(learning_rate=0.02, beta_1=0.99, epsilon=1e-1)
Bunu optimize etmek için, toplam kaybı elde etmek için iki kaybın ağırlıklı bir kombinasyonunu kullanın:
style_weight=1e-2
content_weight=1e4
def style_content_loss(outputs):
style_outputs = outputs['style']
content_outputs = outputs['content']
style_loss = tf.add_n([tf.reduce_mean((style_outputs[name]-style_targets[name])**2)
for name in style_outputs.keys()])
style_loss *= style_weight / num_style_layers
content_loss = tf.add_n([tf.reduce_mean((content_outputs[name]-content_targets[name])**2)
for name in content_outputs.keys()])
content_loss *= content_weight / num_content_layers
loss = style_loss + content_loss
return loss
Görüntüyü güncellemek için tf.GradientTape kullanın.
@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
outputs = extractor(image)
loss = style_content_loss(outputs)
grad = tape.gradient(loss, image)
opt.apply_gradients([(grad, image)])
image.assign(clip_0_1(image))
Şimdi test etmek için birkaç adım çalıştırın:
train_step(image)
train_step(image)
train_step(image)
tensor_to_image(image)

Çalıştığı için daha uzun bir optimizasyon gerçekleştirin:
import time
start = time.time()
epochs = 10
steps_per_epoch = 100
step = 0
for n in range(epochs):
for m in range(steps_per_epoch):
step += 1
train_step(image)
print(".", end='', flush=True)
display.clear_output(wait=True)
display.display(tensor_to_image(image))
print("Train step: {}".format(step))
end = time.time()
print("Total time: {:.1f}".format(end-start))

Train step: 1000 Total time: 21.3
Toplam varyasyon kaybı
Bu temel uygulamanın bir dezavantajı, çok sayıda yüksek frekanslı eser üretmesidir. Görüntünün yüksek frekanslı bileşenleri üzerinde açık bir düzenlileştirme terimi kullanarak bunları azaltın. Stil transferinde buna genellikle toplam varyasyon kaybı denir:
def high_pass_x_y(image):
x_var = image[:, :, 1:, :] - image[:, :, :-1, :]
y_var = image[:, 1:, :, :] - image[:, :-1, :, :]
return x_var, y_var
x_deltas, y_deltas = high_pass_x_y(content_image)
plt.figure(figsize=(14, 10))
plt.subplot(2, 2, 1)
imshow(clip_0_1(2*y_deltas+0.5), "Horizontal Deltas: Original")
plt.subplot(2, 2, 2)
imshow(clip_0_1(2*x_deltas+0.5), "Vertical Deltas: Original")
x_deltas, y_deltas = high_pass_x_y(image)
plt.subplot(2, 2, 3)
imshow(clip_0_1(2*y_deltas+0.5), "Horizontal Deltas: Styled")
plt.subplot(2, 2, 4)
imshow(clip_0_1(2*x_deltas+0.5), "Vertical Deltas: Styled")
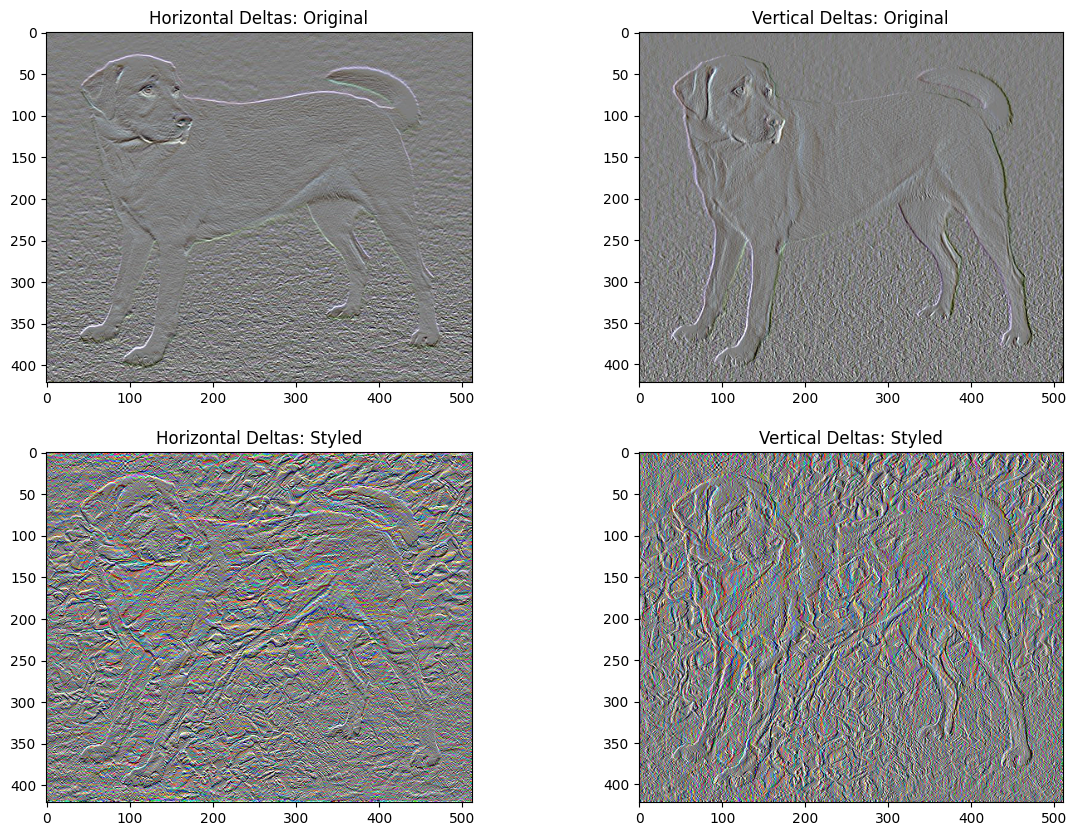
Bu, yüksek frekans bileşenlerinin nasıl arttığını gösterir.
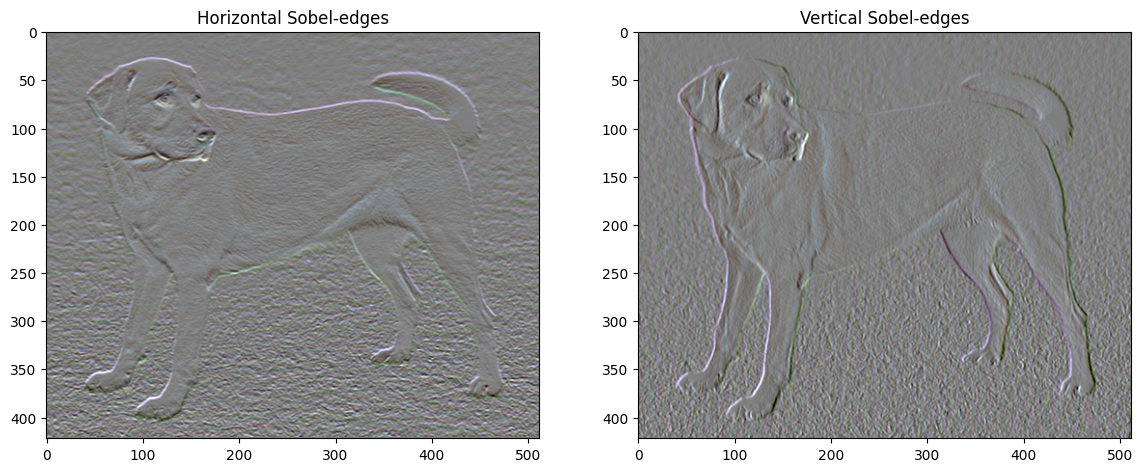
Ayrıca, bu yüksek frekans bileşeni temel olarak bir kenar algılayıcıdır. Sobel kenar dedektöründen benzer çıktılar alabilirsiniz, örneğin:
plt.figure(figsize=(14, 10))
sobel = tf.image.sobel_edges(content_image)
plt.subplot(1, 2, 1)
imshow(clip_0_1(sobel[..., 0]/4+0.5), "Horizontal Sobel-edges")
plt.subplot(1, 2, 2)
imshow(clip_0_1(sobel[..., 1]/4+0.5), "Vertical Sobel-edges")
Bununla ilişkili düzenlileştirme kaybı, değerlerin karelerinin toplamıdır:
def total_variation_loss(image):
x_deltas, y_deltas = high_pass_x_y(image)
return tf.reduce_sum(tf.abs(x_deltas)) + tf.reduce_sum(tf.abs(y_deltas))
total_variation_loss(image).numpy()
149402.94
Bu ne yaptığını gösterdi. Ancak bunu kendiniz uygulamanıza gerek yoktur, TensorFlow standart bir uygulama içerir:
tf.image.total_variation(image).numpy()
array([149402.94], dtype=float32)
Optimizasyonu yeniden çalıştırın
total_variation_loss için bir ağırlık seçin:
total_variation_weight=30
Şimdi onu train_step işlevine dahil edin:
@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
outputs = extractor(image)
loss = style_content_loss(outputs)
loss += total_variation_weight*tf.image.total_variation(image)
grad = tape.gradient(loss, image)
opt.apply_gradients([(grad, image)])
image.assign(clip_0_1(image))
Optimizasyon değişkenini yeniden başlatın:
image = tf.Variable(content_image)
Ve optimizasyonu çalıştırın:
import time
start = time.time()
epochs = 10
steps_per_epoch = 100
step = 0
for n in range(epochs):
for m in range(steps_per_epoch):
step += 1
train_step(image)
print(".", end='', flush=True)
display.clear_output(wait=True)
display.display(tensor_to_image(image))
print("Train step: {}".format(step))
end = time.time()
print("Total time: {:.1f}".format(end-start))

Train step: 1000 Total time: 22.4
Son olarak, sonucu kaydedin:
file_name = 'stylized-image.png'
tensor_to_image(image).save(file_name)
try:
from google.colab import files
except ImportError:
pass
else:
files.download(file_name)
Daha fazla bilgi edin
Bu öğretici, orijinal stil aktarım algoritmasını gösterir. Stil aktarımının basit bir uygulaması için, TensorFlow Hub'dan rastgele görüntü stili aktarım modelinin nasıl kullanılacağı hakkında daha fazla bilgi edinmek için bu eğiticiye göz atın.