
| | |  Посмотреть на GitHub Посмотреть на GitHub | | |
В этом уроке используется глубокое обучение для компоновки одного изображения в стиле другого изображения (вы когда-нибудь хотели рисовать, как Пикассо или Ван Гог?). Это известно как передача нейронного стиля, и эта техника описана в книге «Нейронный алгоритм художественного стиля» (Gatys et al.).
Для простого применения передачи стиля ознакомьтесь с этим руководством , чтобы узнать больше о том, как использовать предварительно обученную модель произвольной стилизации изображений из TensorFlow Hub или как использовать модель передачи стиля с TensorFlow Lite .
Нейронный перенос стиля — это метод оптимизации, используемый для получения двух изображений — изображения контента и эталонного изображения стиля (например, произведения искусства известного художника) — и их смешивания вместе, чтобы выходное изображение выглядело как изображение контента, но «нарисовано». в стиле эталонного изображения стиля.
Это реализуется путем оптимизации выходного изображения для соответствия статистике содержимого изображения содержимого и статистике стиля эталонного изображения стиля. Эта статистика извлекается из изображений с помощью сверточной сети.
Для примера возьмем изображение этой собаки и Композицию 7 Василия Кандинского:

Желтый лабрадор смотрит с Викисклада от Elf . Лицензия CC BY-SA 3.0
{kind=link}

Как бы это выглядело, если бы Кандинский решил написать картину этой Собаки исключительно в этом стиле? Что-то вроде этого?

Настраивать
Импорт и настройка модулей
import os
import tensorflow as tf
# Load compressed models from tensorflow_hub
os.environ['TFHUB_MODEL_LOAD_FORMAT'] = 'COMPRESSED'
import IPython.display as display
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['figure.figsize'] = (12, 12)
mpl.rcParams['axes.grid'] = False
import numpy as np
import PIL.Image
import time
import functools
def tensor_to_image(tensor):
tensor = tensor*255
tensor = np.array(tensor, dtype=np.uint8)
if np.ndim(tensor)>3:
assert tensor.shape[0] == 1
tensor = tensor[0]
return PIL.Image.fromarray(tensor)
Загрузите изображения и выберите изображение стиля и изображение содержимого:
content_path = tf.keras.utils.get_file('YellowLabradorLooking_new.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg')
style_path = tf.keras.utils.get_file('kandinsky5.jpg','https://storage.googleapis.com/download.tensorflow.org/example_images/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg 196608/195196 [==============================] - 0s 0us/step 204800/195196 [===============================] - 0s 0us/step
Визуализируйте ввод
Определите функцию для загрузки изображения и ограничьте его максимальный размер до 512 пикселей.
def load_img(path_to_img):
max_dim = 512
img = tf.io.read_file(path_to_img)
img = tf.image.decode_image(img, channels=3)
img = tf.image.convert_image_dtype(img, tf.float32)
shape = tf.cast(tf.shape(img)[:-1], tf.float32)
long_dim = max(shape)
scale = max_dim / long_dim
new_shape = tf.cast(shape * scale, tf.int32)
img = tf.image.resize(img, new_shape)
img = img[tf.newaxis, :]
return img
Создайте простую функцию для отображения изображения:
def imshow(image, title=None):
if len(image.shape) > 3:
image = tf.squeeze(image, axis=0)
plt.imshow(image)
if title:
plt.title(title)
content_image = load_img(content_path)
style_image = load_img(style_path)
plt.subplot(1, 2, 1)
imshow(content_image, 'Content Image')
plt.subplot(1, 2, 2)
imshow(style_image, 'Style Image')

Быстрая передача стилей с помощью TF-Hub
В этом руководстве демонстрируется оригинальный алгоритм переноса стилей, оптимизирующий содержимое изображения в соответствии с определенным стилем. Прежде чем углубляться в детали, давайте посмотрим, как это делает модель TensorFlow Hub :
import tensorflow_hub as hub
hub_model = hub.load('https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2')
stylized_image = hub_model(tf.constant(content_image), tf.constant(style_image))[0]
tensor_to_image(stylized_image)
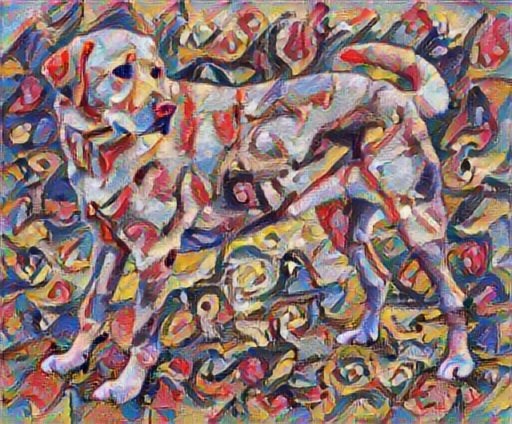
Определение содержимого и представлений стилей
Используйте промежуточные слои модели, чтобы получить представление содержимого и стиля изображения. Начиная с входного слоя сети, первые несколько активаций слоя представляют низкоуровневые функции, такие как края и текстуры. Когда вы проходите через сеть, последние несколько слоев представляют функции более высокого уровня — части объекта, такие как колеса или глаза . В этом случае вы используете сетевую архитектуру VGG19, предварительно обученную сеть классификации изображений. Эти промежуточные слои необходимы для определения представления содержимого и стиля изображений. Для входного изображения попытайтесь сопоставить соответствующий стиль и целевые представления контента на этих промежуточных слоях.
Загрузите VGG19 и протестируйте его на нашем образе, чтобы убедиться, что он используется правильно:
x = tf.keras.applications.vgg19.preprocess_input(content_image*255)
x = tf.image.resize(x, (224, 224))
vgg = tf.keras.applications.VGG19(include_top=True, weights='imagenet')
prediction_probabilities = vgg(x)
prediction_probabilities.shape
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg19/vgg19_weights_tf_dim_ordering_tf_kernels.h5 574717952/574710816 [==============================] - 17s 0us/step 574726144/574710816 [==============================] - 17s 0us/step TensorShape([1, 1000])
predicted_top_5 = tf.keras.applications.vgg19.decode_predictions(prediction_probabilities.numpy())[0]
[(class_name, prob) for (number, class_name, prob) in predicted_top_5]
[('Labrador_retriever', 0.493171),
('golden_retriever', 0.2366529),
('kuvasz', 0.036357544),
('Chesapeake_Bay_retriever', 0.024182785),
('Greater_Swiss_Mountain_dog', 0.0186461)]
Теперь загрузите VGG19 без заголовка классификации и перечислите имена слоев.
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
print()
for layer in vgg.layers:
print(layer.name)
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg19/vgg19_weights_tf_dim_ordering_tf_kernels_notop.h5 80142336/80134624 [==============================] - 2s 0us/step 80150528/80134624 [==============================] - 2s 0us/step input_2 block1_conv1 block1_conv2 block1_pool block2_conv1 block2_conv2 block2_pool block3_conv1 block3_conv2 block3_conv3 block3_conv4 block3_pool block4_conv1 block4_conv2 block4_conv3 block4_conv4 block4_pool block5_conv1 block5_conv2 block5_conv3 block5_conv4 block5_pool
Выберите промежуточные слои из сети, чтобы представить стиль и содержание изображения:
content_layers = ['block5_conv2']
style_layers = ['block1_conv1',
'block2_conv1',
'block3_conv1',
'block4_conv1',
'block5_conv1']
num_content_layers = len(content_layers)
num_style_layers = len(style_layers)
Промежуточные слои для стиля и контента
Так почему же эти промежуточные результаты в нашей предварительно обученной сети классификации изображений позволяют нам определять представления стиля и контента?
На высоком уровне, чтобы сеть могла выполнять классификацию изображений (для чего эта сеть была обучена), она должна понимать изображение. Для этого необходимо взять необработанное изображение в качестве входных пикселей и построить внутреннее представление, которое преобразует необработанные пиксели изображения в сложное представление о функциях, присутствующих в изображении.
Это также является причиной того, что сверточные нейронные сети способны хорошо обобщать: они способны улавливать инвариантности и определяющие признаки внутри классов (например, кошек и собак), которые не зависят от фонового шума и других помех. Таким образом, где-то между тем, где необработанное изображение загружается в модель, и выходной классификационной меткой, модель служит экстрактором сложных признаков. Получая доступ к промежуточным слоям модели, вы можете описывать содержимое и стиль входных изображений.
Построить модель
Сети в tf.keras.applications спроектированы таким образом, что вы можете легко извлекать значения промежуточного уровня с помощью функционального API Keras.
Чтобы определить модель с помощью функционального API, укажите входы и выходы:
model = Model(inputs, outputs)
Следующая функция строит модель VGG19, которая возвращает список выходных данных промежуточного уровня:
def vgg_layers(layer_names):
""" Creates a vgg model that returns a list of intermediate output values."""
# Load our model. Load pretrained VGG, trained on imagenet data
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
vgg.trainable = False
outputs = [vgg.get_layer(name).output for name in layer_names]
model = tf.keras.Model([vgg.input], outputs)
return model
И для создания модели:
style_extractor = vgg_layers(style_layers)
style_outputs = style_extractor(style_image*255)
#Look at the statistics of each layer's output
for name, output in zip(style_layers, style_outputs):
print(name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
print()
block1_conv1 shape: (1, 336, 512, 64) min: 0.0 max: 835.5256 mean: 33.97525 block2_conv1 shape: (1, 168, 256, 128) min: 0.0 max: 4625.8857 mean: 199.82687 block3_conv1 shape: (1, 84, 128, 256) min: 0.0 max: 8789.239 mean: 230.78099 block4_conv1 shape: (1, 42, 64, 512) min: 0.0 max: 21566.135 mean: 791.24005 block5_conv1 shape: (1, 21, 32, 512) min: 0.0 max: 3189.2542 mean: 59.179478
Рассчитать стиль
Содержание изображения представлено значениями промежуточных карт признаков.
Оказывается, стиль изображения можно описать средствами и корреляциями между различными картами признаков. Вычислите матрицу Грама, которая включает эту информацию, взяв внешнее произведение вектора признаков с самим собой в каждом местоположении и усреднив это внешнее произведение по всем местоположениям. Эта матрица Грама может быть рассчитана для конкретного слоя как:
\[G^l_{cd} = \frac{\sum_{ij} F^l_{ijc}(x)F^l_{ijd}(x)}{IJ}\]
Это можно легко реализовать с помощью функции tf.linalg.einsum :
def gram_matrix(input_tensor):
result = tf.linalg.einsum('bijc,bijd->bcd', input_tensor, input_tensor)
input_shape = tf.shape(input_tensor)
num_locations = tf.cast(input_shape[1]*input_shape[2], tf.float32)
return result/(num_locations)
Извлечь стиль и содержимое
Создайте модель, которая возвращает тензоры стиля и содержимого.
class StyleContentModel(tf.keras.models.Model):
def __init__(self, style_layers, content_layers):
super(StyleContentModel, self).__init__()
self.vgg = vgg_layers(style_layers + content_layers)
self.style_layers = style_layers
self.content_layers = content_layers
self.num_style_layers = len(style_layers)
self.vgg.trainable = False
def call(self, inputs):
"Expects float input in [0,1]"
inputs = inputs*255.0
preprocessed_input = tf.keras.applications.vgg19.preprocess_input(inputs)
outputs = self.vgg(preprocessed_input)
style_outputs, content_outputs = (outputs[:self.num_style_layers],
outputs[self.num_style_layers:])
style_outputs = [gram_matrix(style_output)
for style_output in style_outputs]
content_dict = {content_name: value
for content_name, value
in zip(self.content_layers, content_outputs)}
style_dict = {style_name: value
for style_name, value
in zip(self.style_layers, style_outputs)}
return {'content': content_dict, 'style': style_dict}
При вызове изображения эта модель возвращает матрицу грамм (стиль) style_layers и содержимое content_layers :
extractor = StyleContentModel(style_layers, content_layers)
results = extractor(tf.constant(content_image))
print('Styles:')
for name, output in sorted(results['style'].items()):
print(" ", name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
print()
print("Contents:")
for name, output in sorted(results['content'].items()):
print(" ", name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
Styles:
block1_conv1
shape: (1, 64, 64)
min: 0.0055228462
max: 28014.557
mean: 263.79022
block2_conv1
shape: (1, 128, 128)
min: 0.0
max: 61479.496
mean: 9100.949
block3_conv1
shape: (1, 256, 256)
min: 0.0
max: 545623.44
mean: 7660.976
block4_conv1
shape: (1, 512, 512)
min: 0.0
max: 4320502.0
mean: 134288.84
block5_conv1
shape: (1, 512, 512)
min: 0.0
max: 110005.37
mean: 1487.0378
Contents:
block5_conv2
shape: (1, 26, 32, 512)
min: 0.0
max: 2410.8796
mean: 13.764149
Пробежать градиентный спуск
С помощью этого средства извлечения стилей и содержимого теперь можно реализовать алгоритм передачи стилей. Сделайте это, рассчитав среднеквадратичную ошибку для вывода вашего изображения относительно каждой цели, а затем возьмите взвешенную сумму этих потерь.
Установите целевые значения стиля и содержания:
style_targets = extractor(style_image)['style']
content_targets = extractor(content_image)['content']
Определите tf.Variable , чтобы содержать изображение для оптимизации. Чтобы сделать это быстро, инициализируйте его изображением содержимого ( tf.Variable должна иметь ту же форму, что и изображение содержимого):
image = tf.Variable(content_image)
Поскольку это изображение с плавающей запятой, определите функцию, которая будет поддерживать значения пикселей в диапазоне от 0 до 1:
def clip_0_1(image):
return tf.clip_by_value(image, clip_value_min=0.0, clip_value_max=1.0)
Создайте оптимизатор. В документе рекомендуется LBFGS, но Adam тоже работает нормально:
opt = tf.optimizers.Adam(learning_rate=0.02, beta_1=0.99, epsilon=1e-1)
Чтобы оптимизировать это, используйте взвешенную комбинацию двух потерь, чтобы получить общую потерю:
style_weight=1e-2
content_weight=1e4
def style_content_loss(outputs):
style_outputs = outputs['style']
content_outputs = outputs['content']
style_loss = tf.add_n([tf.reduce_mean((style_outputs[name]-style_targets[name])**2)
for name in style_outputs.keys()])
style_loss *= style_weight / num_style_layers
content_loss = tf.add_n([tf.reduce_mean((content_outputs[name]-content_targets[name])**2)
for name in content_outputs.keys()])
content_loss *= content_weight / num_content_layers
loss = style_loss + content_loss
return loss
Используйте tf.GradientTape для обновления изображения.
@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
outputs = extractor(image)
loss = style_content_loss(outputs)
grad = tape.gradient(loss, image)
opt.apply_gradients([(grad, image)])
image.assign(clip_0_1(image))
Теперь выполните несколько шагов для проверки:
train_step(image)
train_step(image)
train_step(image)
tensor_to_image(image)

Поскольку он работает, выполните более длительную оптимизацию:
import time
start = time.time()
epochs = 10
steps_per_epoch = 100
step = 0
for n in range(epochs):
for m in range(steps_per_epoch):
step += 1
train_step(image)
print(".", end='', flush=True)
display.clear_output(wait=True)
display.display(tensor_to_image(image))
print("Train step: {}".format(step))
end = time.time()
print("Total time: {:.1f}".format(end-start))

Train step: 1000 Total time: 21.3
Общая потеря вариации
Недостатком этой базовой реализации является то, что она создает много высокочастотных артефактов. Уменьшите их, используя явный член регуляризации высокочастотных компонентов изображения. При переносе стиля это часто называют общей потерей вариации :
def high_pass_x_y(image):
x_var = image[:, :, 1:, :] - image[:, :, :-1, :]
y_var = image[:, 1:, :, :] - image[:, :-1, :, :]
return x_var, y_var
x_deltas, y_deltas = high_pass_x_y(content_image)
plt.figure(figsize=(14, 10))
plt.subplot(2, 2, 1)
imshow(clip_0_1(2*y_deltas+0.5), "Horizontal Deltas: Original")
plt.subplot(2, 2, 2)
imshow(clip_0_1(2*x_deltas+0.5), "Vertical Deltas: Original")
x_deltas, y_deltas = high_pass_x_y(image)
plt.subplot(2, 2, 3)
imshow(clip_0_1(2*y_deltas+0.5), "Horizontal Deltas: Styled")
plt.subplot(2, 2, 4)
imshow(clip_0_1(2*x_deltas+0.5), "Vertical Deltas: Styled")
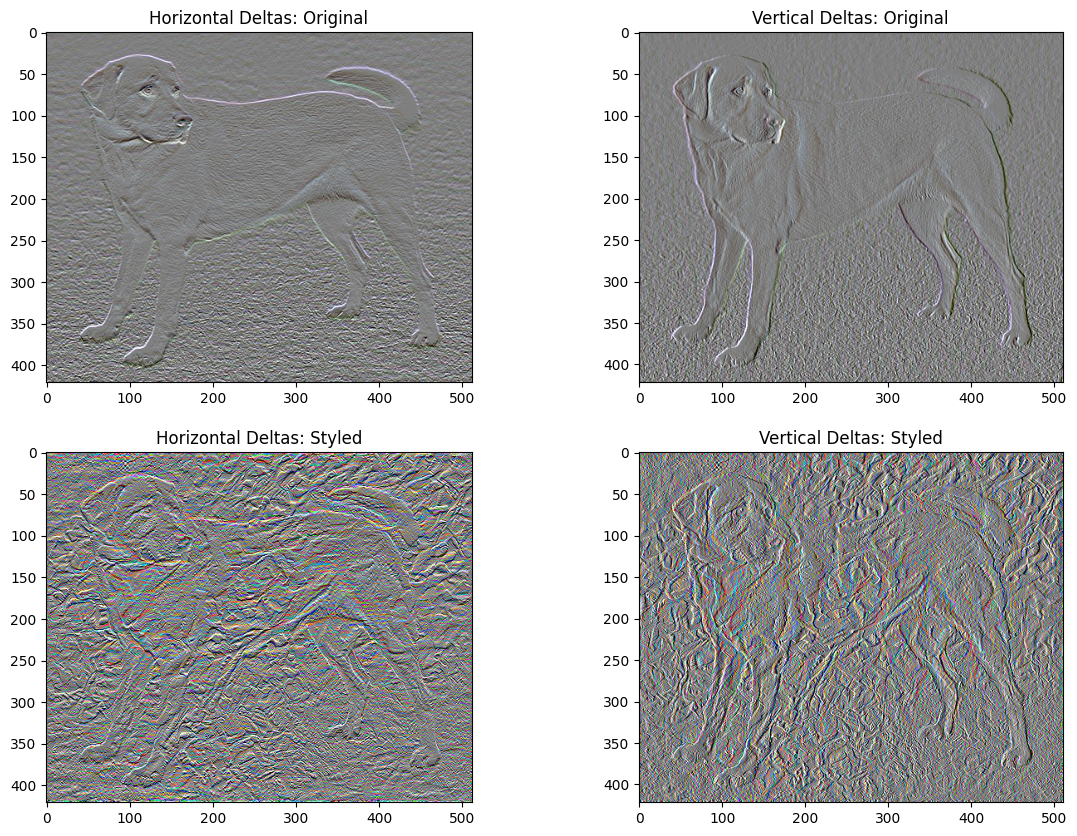
Это показывает, как увеличились высокочастотные компоненты.
Кроме того, этот высокочастотный компонент в основном является детектором фронта. Вы можете получить аналогичный вывод от детектора границ Собеля, например:
plt.figure(figsize=(14, 10))
sobel = tf.image.sobel_edges(content_image)
plt.subplot(1, 2, 1)
imshow(clip_0_1(sobel[..., 0]/4+0.5), "Horizontal Sobel-edges")
plt.subplot(1, 2, 2)
imshow(clip_0_1(sobel[..., 1]/4+0.5), "Vertical Sobel-edges")
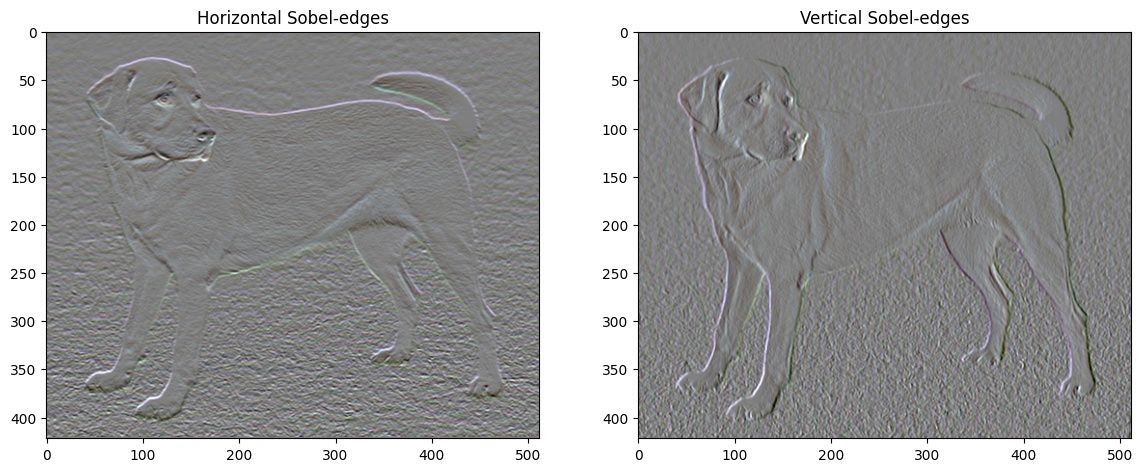
Потери регуляризации, связанные с этим, представляют собой сумму квадратов значений:
def total_variation_loss(image):
x_deltas, y_deltas = high_pass_x_y(image)
return tf.reduce_sum(tf.abs(x_deltas)) + tf.reduce_sum(tf.abs(y_deltas))
total_variation_loss(image).numpy()
149402.94
Это продемонстрировало, что он делает. Но нет необходимости реализовывать его самостоятельно, TensorFlow включает стандартную реализацию:
tf.image.total_variation(image).numpy()
array([149402.94], dtype=float32)
Перезапустите оптимизацию
Выберите вес для total_variation_loss :
total_variation_weight=30
Теперь включите его в функцию train_step :
@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
outputs = extractor(image)
loss = style_content_loss(outputs)
loss += total_variation_weight*tf.image.total_variation(image)
grad = tape.gradient(loss, image)
opt.apply_gradients([(grad, image)])
image.assign(clip_0_1(image))
Повторно инициализируйте переменную оптимизации:
image = tf.Variable(content_image)
И запускаем оптимизацию:
import time
start = time.time()
epochs = 10
steps_per_epoch = 100
step = 0
for n in range(epochs):
for m in range(steps_per_epoch):
step += 1
train_step(image)
print(".", end='', flush=True)
display.clear_output(wait=True)
display.display(tensor_to_image(image))
print("Train step: {}".format(step))
end = time.time()
print("Total time: {:.1f}".format(end-start))

Train step: 1000 Total time: 22.4
Наконец, сохраните результат:
file_name = 'stylized-image.png'
tensor_to_image(image).save(file_name)
try:
from google.colab import files
except ImportError:
pass
else:
files.download(file_name)
Выучить больше
В этом руководстве демонстрируется оригинальный алгоритм переноса стилей. Для простого применения передачи стиля ознакомьтесь с этим руководством , чтобы узнать больше о том, как использовать произвольную модель передачи стиля изображения от TensorFlow Hub .