
| | |  Zobacz na GitHub Zobacz na GitHub | | |
Ten samouczek wykorzystuje głębokie uczenie, aby skomponować jeden obraz w stylu innego obrazu (czy kiedykolwiek chciałbyś malować jak Picasso lub Van Gogh?). Jest to znane jako transfer stylu neuronowego, a technika ta jest opisana w Algorytmie neuronowym stylu artystycznego (Gatys i in.).
Aby uzyskać proste zastosowanie transferu stylu, zapoznaj się z tym samouczkiem , aby dowiedzieć się więcej o tym, jak korzystać z wstępnie wytrenowanego modelu Arbitrary Image Stylization z TensorFlow Hub lub jak korzystać z modelu transferu stylu z TensorFlow Lite .
Przenoszenie stylów neuronowych to technika optymalizacji używana do robienia dwóch obrazów — obrazu zawartości i obrazu odniesienia stylu (takiego jak grafika słynnego malarza) — i łączenia ich ze sobą, tak aby obraz wyjściowy wyglądał jak obraz zawartości, ale był „pomalowany”. w stylu obrazu odniesienia stylu.
Jest to realizowane przez optymalizację obrazu wyjściowego w celu dopasowania statystyk treści obrazu treści i statystyk stylu obrazu odniesienia stylu. Statystyki te są wyodrębniane z obrazów za pomocą sieci splotowej.
Na przykład weźmy zdjęcie tego psa i Kompozycja 7 Wassily'ego Kandinsky'ego:

Żółty Labrador Patrząc , z Wikimedia Commons autorstwa Elfa . Licencja CC BY-SA 3.0
{kind=link}

A jak by to wyglądało, gdyby Kandinsky zdecydował się namalować obraz tego psa wyłącznie w tym stylu? Coś takiego?

Ustawiać
Importuj i konfiguruj moduły
import os
import tensorflow as tf
# Load compressed models from tensorflow_hub
os.environ['TFHUB_MODEL_LOAD_FORMAT'] = 'COMPRESSED'
import IPython.display as display
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['figure.figsize'] = (12, 12)
mpl.rcParams['axes.grid'] = False
import numpy as np
import PIL.Image
import time
import functools
def tensor_to_image(tensor):
tensor = tensor*255
tensor = np.array(tensor, dtype=np.uint8)
if np.ndim(tensor)>3:
assert tensor.shape[0] == 1
tensor = tensor[0]
return PIL.Image.fromarray(tensor)
Pobierz obrazy i wybierz obraz stylu oraz obraz treści:
content_path = tf.keras.utils.get_file('YellowLabradorLooking_new.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg')
style_path = tf.keras.utils.get_file('kandinsky5.jpg','https://storage.googleapis.com/download.tensorflow.org/example_images/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg 196608/195196 [==============================] - 0s 0us/step 204800/195196 [===============================] - 0s 0us/step
Wizualizuj dane wejściowe
Zdefiniuj funkcję ładowania obrazu i ogranicz jego maksymalny wymiar do 512 pikseli.
def load_img(path_to_img):
max_dim = 512
img = tf.io.read_file(path_to_img)
img = tf.image.decode_image(img, channels=3)
img = tf.image.convert_image_dtype(img, tf.float32)
shape = tf.cast(tf.shape(img)[:-1], tf.float32)
long_dim = max(shape)
scale = max_dim / long_dim
new_shape = tf.cast(shape * scale, tf.int32)
img = tf.image.resize(img, new_shape)
img = img[tf.newaxis, :]
return img
Utwórz prostą funkcję do wyświetlania obrazu:
def imshow(image, title=None):
if len(image.shape) > 3:
image = tf.squeeze(image, axis=0)
plt.imshow(image)
if title:
plt.title(title)
content_image = load_img(content_path)
style_image = load_img(style_path)
plt.subplot(1, 2, 1)
imshow(content_image, 'Content Image')
plt.subplot(1, 2, 2)
imshow(style_image, 'Style Image')

Szybki transfer stylu za pomocą TF-Hub
Ten samouczek przedstawia oryginalny algorytm przenoszenia stylu, który optymalizuje zawartość obrazu do określonego stylu. Zanim przejdziemy do szczegółów, zobaczmy, jak robi to model TensorFlow Hub :
import tensorflow_hub as hub
hub_model = hub.load('https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2')
stylized_image = hub_model(tf.constant(content_image), tf.constant(style_image))[0]
tensor_to_image(stylized_image)
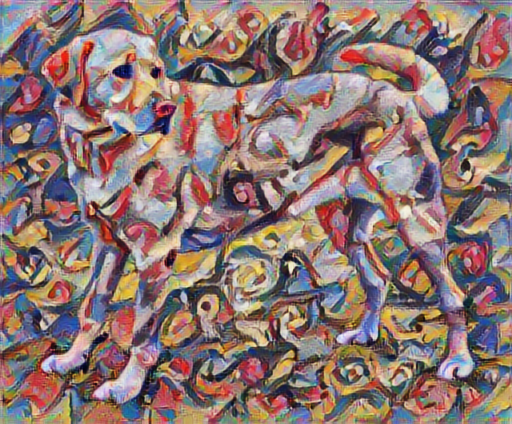
Zdefiniuj reprezentacje treści i stylu
Użyj pośrednich warstw modelu, aby uzyskać reprezentację zawartości i stylu obrazu. Począwszy od warstwy wejściowej sieci, kilka pierwszych aktywacji warstwy reprezentuje funkcje niskiego poziomu, takie jak krawędzie i tekstury. Gdy przechodzisz przez sieć, kilka ostatnich warstw reprezentuje elementy wyższego poziomu — części obiektów, takie jak koła lub oczy . W tym przypadku używasz architektury sieci VGG19, wstępnie wytrenowanej sieci klasyfikacji obrazów. Te warstwy pośrednie są niezbędne do zdefiniowania reprezentacji treści i stylu z obrazów. W przypadku obrazu wejściowego spróbuj dopasować odpowiednie reprezentacje stylu i zawartości docelowej na tych warstwach pośrednich.
Załaduj VGG19 i przetestuj go na naszym obrazie, aby upewnić się, że jest używany poprawnie:
x = tf.keras.applications.vgg19.preprocess_input(content_image*255)
x = tf.image.resize(x, (224, 224))
vgg = tf.keras.applications.VGG19(include_top=True, weights='imagenet')
prediction_probabilities = vgg(x)
prediction_probabilities.shape
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg19/vgg19_weights_tf_dim_ordering_tf_kernels.h5 574717952/574710816 [==============================] - 17s 0us/step 574726144/574710816 [==============================] - 17s 0us/step TensorShape([1, 1000])
predicted_top_5 = tf.keras.applications.vgg19.decode_predictions(prediction_probabilities.numpy())[0]
[(class_name, prob) for (number, class_name, prob) in predicted_top_5]
[('Labrador_retriever', 0.493171),
('golden_retriever', 0.2366529),
('kuvasz', 0.036357544),
('Chesapeake_Bay_retriever', 0.024182785),
('Greater_Swiss_Mountain_dog', 0.0186461)]
Teraz załaduj VGG19 bez głowicy klasyfikacyjnej i wymień nazwy warstw
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
print()
for layer in vgg.layers:
print(layer.name)
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg19/vgg19_weights_tf_dim_ordering_tf_kernels_notop.h5 80142336/80134624 [==============================] - 2s 0us/step 80150528/80134624 [==============================] - 2s 0us/step input_2 block1_conv1 block1_conv2 block1_pool block2_conv1 block2_conv2 block2_pool block3_conv1 block3_conv2 block3_conv3 block3_conv4 block3_pool block4_conv1 block4_conv2 block4_conv3 block4_conv4 block4_pool block5_conv1 block5_conv2 block5_conv3 block5_conv4 block5_pool
Wybierz warstwy pośrednie z sieci, aby przedstawić styl i zawartość obrazu:
content_layers = ['block5_conv2']
style_layers = ['block1_conv1',
'block2_conv1',
'block3_conv1',
'block4_conv1',
'block5_conv1']
num_content_layers = len(content_layers)
num_style_layers = len(style_layers)
Warstwy pośrednie dla stylu i treści
Dlaczego więc te pośrednie dane wyjściowe w naszej wstępnie wyszkolonej sieci klasyfikacji obrazów pozwalają nam zdefiniować reprezentacje stylu i treści?
Na wysokim poziomie, aby sieć mogła dokonać klasyfikacji obrazów (do czego ta sieć została przeszkolona), musi zrozumieć obraz. Wymaga to przyjęcia nieprzetworzonego obrazu jako pikseli wejściowych i zbudowania wewnętrznej reprezentacji, która przekształca nieprzetworzone piksele obrazu w złożone zrozumienie cech obecnych na obrazie.
Jest to również powód, dla którego splotowe sieci neuronowe są w stanie dobrze uogólniać: są w stanie uchwycić niezmienności i cechy definiujące w obrębie klas (np. koty kontra psy), które są agnostyczne wobec szumu tła i innych niedogodności. Dlatego gdzieś pomiędzy miejscem, w którym surowy obraz jest wprowadzany do modelu, a etykietą klasyfikacji wyjściowej, model służy jako złożony ekstraktor cech. Uzyskując dostęp do warstw pośrednich modelu, możesz opisać zawartość i styl obrazów wejściowych.
Zbuduj model
Sieci w tf.keras.applications zostały zaprojektowane tak, aby można było łatwo wyodrębnić wartości warstwy pośredniej za pomocą funkcjonalnego API Keras.
Aby zdefiniować model za pomocą funkcjonalnego API, określ wejścia i wyjścia:
model = Model(inputs, outputs)
Poniższa funkcja buduje model VGG19, który zwraca listę danych wyjściowych warstwy pośredniej:
def vgg_layers(layer_names):
""" Creates a vgg model that returns a list of intermediate output values."""
# Load our model. Load pretrained VGG, trained on imagenet data
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
vgg.trainable = False
outputs = [vgg.get_layer(name).output for name in layer_names]
model = tf.keras.Model([vgg.input], outputs)
return model
A żeby stworzyć model:
style_extractor = vgg_layers(style_layers)
style_outputs = style_extractor(style_image*255)
#Look at the statistics of each layer's output
for name, output in zip(style_layers, style_outputs):
print(name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
print()
block1_conv1 shape: (1, 336, 512, 64) min: 0.0 max: 835.5256 mean: 33.97525 block2_conv1 shape: (1, 168, 256, 128) min: 0.0 max: 4625.8857 mean: 199.82687 block3_conv1 shape: (1, 84, 128, 256) min: 0.0 max: 8789.239 mean: 230.78099 block4_conv1 shape: (1, 42, 64, 512) min: 0.0 max: 21566.135 mean: 791.24005 block5_conv1 shape: (1, 21, 32, 512) min: 0.0 max: 3189.2542 mean: 59.179478
Oblicz styl
Zawartość obrazu jest reprezentowana przez wartości z map cech pośrednich.
Okazuje się, że styl obrazu można opisać za pomocą środków i korelacji na różnych mapach cech. Oblicz macierz grama, która zawiera te informacje, biorąc zewnętrzny iloczyn wektora cech w każdym miejscu i uśredniając ten iloczyn zewnętrzny we wszystkich lokalizacjach. Ta macierz grama może być obliczona dla konkretnej warstwy jako:
\[G^l_{cd} = \frac{\sum_{ij} F^l_{ijc}(x)F^l_{ijd}(x)}{IJ}\]
Można to zwięźle zaimplementować za pomocą funkcji tf.linalg.einsum :
def gram_matrix(input_tensor):
result = tf.linalg.einsum('bijc,bijd->bcd', input_tensor, input_tensor)
input_shape = tf.shape(input_tensor)
num_locations = tf.cast(input_shape[1]*input_shape[2], tf.float32)
return result/(num_locations)
Wyodrębnij styl i treść
Zbuduj model, który zwraca tensory stylu i treści.
class StyleContentModel(tf.keras.models.Model):
def __init__(self, style_layers, content_layers):
super(StyleContentModel, self).__init__()
self.vgg = vgg_layers(style_layers + content_layers)
self.style_layers = style_layers
self.content_layers = content_layers
self.num_style_layers = len(style_layers)
self.vgg.trainable = False
def call(self, inputs):
"Expects float input in [0,1]"
inputs = inputs*255.0
preprocessed_input = tf.keras.applications.vgg19.preprocess_input(inputs)
outputs = self.vgg(preprocessed_input)
style_outputs, content_outputs = (outputs[:self.num_style_layers],
outputs[self.num_style_layers:])
style_outputs = [gram_matrix(style_output)
for style_output in style_outputs]
content_dict = {content_name: value
for content_name, value
in zip(self.content_layers, content_outputs)}
style_dict = {style_name: value
for style_name, value
in zip(self.style_layers, style_outputs)}
return {'content': content_dict, 'style': style_dict}
Po wywołaniu na obrazie, ten model zwraca macierz gramów (styl) style_layers i zawartość content_layers :
extractor = StyleContentModel(style_layers, content_layers)
results = extractor(tf.constant(content_image))
print('Styles:')
for name, output in sorted(results['style'].items()):
print(" ", name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
print()
print("Contents:")
for name, output in sorted(results['content'].items()):
print(" ", name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
Styles:
block1_conv1
shape: (1, 64, 64)
min: 0.0055228462
max: 28014.557
mean: 263.79022
block2_conv1
shape: (1, 128, 128)
min: 0.0
max: 61479.496
mean: 9100.949
block3_conv1
shape: (1, 256, 256)
min: 0.0
max: 545623.44
mean: 7660.976
block4_conv1
shape: (1, 512, 512)
min: 0.0
max: 4320502.0
mean: 134288.84
block5_conv1
shape: (1, 512, 512)
min: 0.0
max: 110005.37
mean: 1487.0378
Contents:
block5_conv2
shape: (1, 26, 32, 512)
min: 0.0
max: 2410.8796
mean: 13.764149
Biegnij w dół pochyłości
Dzięki temu ekstraktorowi stylów i treści możesz teraz zaimplementować algorytm przesyłania stylów. Zrób to, obliczając błąd średniokwadratowy dla wyjścia twojego obrazu w stosunku do każdego celu, a następnie weź ważoną sumę tych strat.
Ustaw swój styl i wartości docelowe treści:
style_targets = extractor(style_image)['style']
content_targets = extractor(content_image)['content']
Zdefiniuj tf.Variable zawierającą obraz do optymalizacji. Aby to zrobić szybko, zainicjuj go za pomocą obrazu zawartości ( tf.Variable musi mieć taki sam kształt jak obraz zawartości):
image = tf.Variable(content_image)
Ponieważ jest to obraz pływający, zdefiniuj funkcję, aby zachować wartości pikseli między 0 a 1:
def clip_0_1(image):
return tf.clip_by_value(image, clip_value_min=0.0, clip_value_max=1.0)
Utwórz optymalizator. Gazeta poleca LBFGS, ale Adam też działa dobrze:
opt = tf.optimizers.Adam(learning_rate=0.02, beta_1=0.99, epsilon=1e-1)
Aby to zoptymalizować, użyj ważonej kombinacji dwóch strat, aby uzyskać całkowitą stratę:
style_weight=1e-2
content_weight=1e4
def style_content_loss(outputs):
style_outputs = outputs['style']
content_outputs = outputs['content']
style_loss = tf.add_n([tf.reduce_mean((style_outputs[name]-style_targets[name])**2)
for name in style_outputs.keys()])
style_loss *= style_weight / num_style_layers
content_loss = tf.add_n([tf.reduce_mean((content_outputs[name]-content_targets[name])**2)
for name in content_outputs.keys()])
content_loss *= content_weight / num_content_layers
loss = style_loss + content_loss
return loss
Użyj tf.GradientTape , aby zaktualizować obraz.
@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
outputs = extractor(image)
loss = style_content_loss(outputs)
grad = tape.gradient(loss, image)
opt.apply_gradients([(grad, image)])
image.assign(clip_0_1(image))
Teraz wykonaj kilka kroków, aby przetestować:
train_step(image)
train_step(image)
train_step(image)
tensor_to_image(image)

Ponieważ działa, przeprowadź dłuższą optymalizację:
import time
start = time.time()
epochs = 10
steps_per_epoch = 100
step = 0
for n in range(epochs):
for m in range(steps_per_epoch):
step += 1
train_step(image)
print(".", end='', flush=True)
display.clear_output(wait=True)
display.display(tensor_to_image(image))
print("Train step: {}".format(step))
end = time.time()
print("Total time: {:.1f}".format(end-start))

Train step: 1000 Total time: 21.3
Całkowita utrata zmienności
Jedną wadą tej podstawowej implementacji jest to, że generuje wiele artefaktów o wysokiej częstotliwości. Zmniejsz je, używając wyraźnego wyrażenia regularyzacji na składowych obrazu o wysokiej częstotliwości. W przeniesieniu stylu często nazywa się to całkowitą utratą zmienności :
def high_pass_x_y(image):
x_var = image[:, :, 1:, :] - image[:, :, :-1, :]
y_var = image[:, 1:, :, :] - image[:, :-1, :, :]
return x_var, y_var
x_deltas, y_deltas = high_pass_x_y(content_image)
plt.figure(figsize=(14, 10))
plt.subplot(2, 2, 1)
imshow(clip_0_1(2*y_deltas+0.5), "Horizontal Deltas: Original")
plt.subplot(2, 2, 2)
imshow(clip_0_1(2*x_deltas+0.5), "Vertical Deltas: Original")
x_deltas, y_deltas = high_pass_x_y(image)
plt.subplot(2, 2, 3)
imshow(clip_0_1(2*y_deltas+0.5), "Horizontal Deltas: Styled")
plt.subplot(2, 2, 4)
imshow(clip_0_1(2*x_deltas+0.5), "Vertical Deltas: Styled")
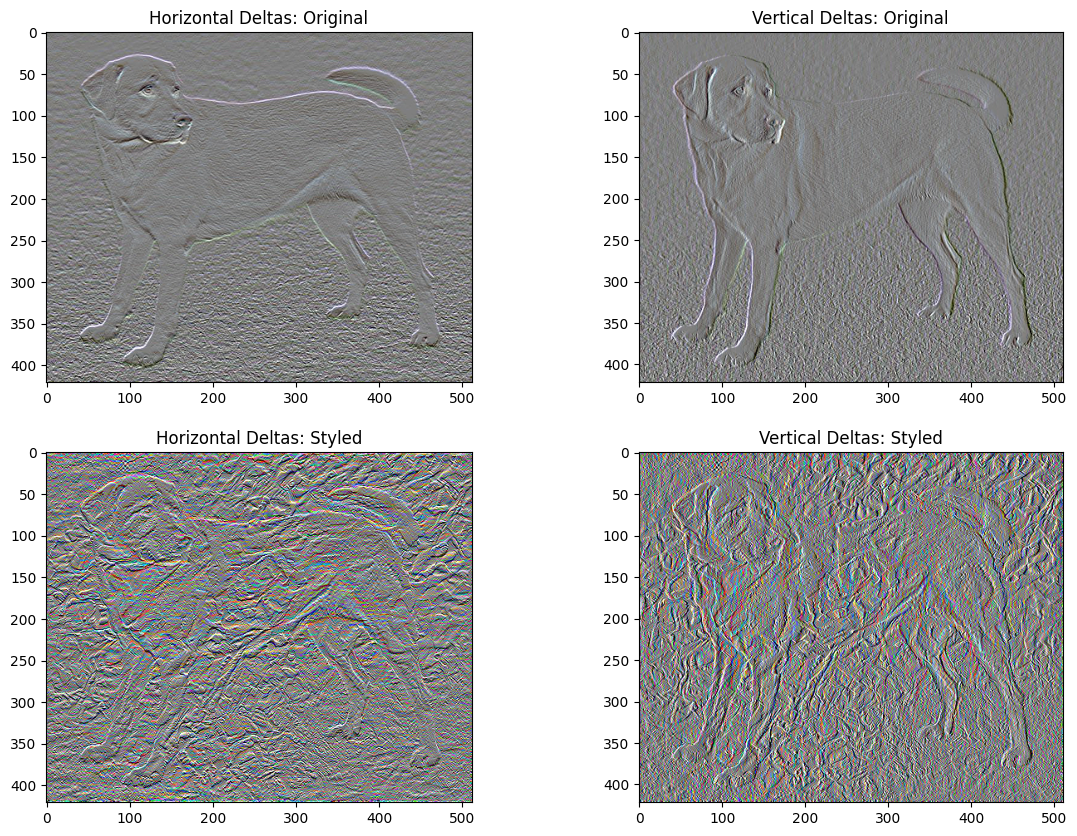
To pokazuje, jak wzrosły komponenty o wysokiej częstotliwości.
Ponadto ten element o wysokiej częstotliwości jest w zasadzie wykrywaczem krawędzi. Podobne wyniki można uzyskać z czujnika krawędzi Sobel, na przykład:
plt.figure(figsize=(14, 10))
sobel = tf.image.sobel_edges(content_image)
plt.subplot(1, 2, 1)
imshow(clip_0_1(sobel[..., 0]/4+0.5), "Horizontal Sobel-edges")
plt.subplot(1, 2, 2)
imshow(clip_0_1(sobel[..., 1]/4+0.5), "Vertical Sobel-edges")
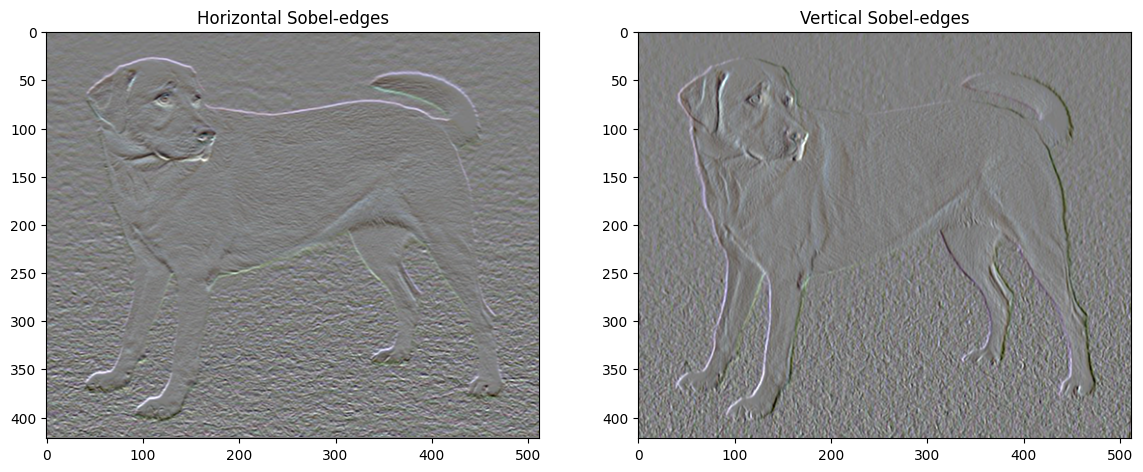
Związana z tym strata regularyzacji jest sumą kwadratów wartości:
def total_variation_loss(image):
x_deltas, y_deltas = high_pass_x_y(image)
return tf.reduce_sum(tf.abs(x_deltas)) + tf.reduce_sum(tf.abs(y_deltas))
total_variation_loss(image).numpy()
149402.94
To pokazało, co robi. Ale nie ma potrzeby samodzielnego wdrażania, TensorFlow zawiera standardową implementację:
tf.image.total_variation(image).numpy()
array([149402.94], dtype=float32)
Ponownie uruchom optymalizację
Wybierz wagę dla total_variation_loss :
total_variation_weight=30
Teraz uwzględnij to w funkcji train_step :
@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
outputs = extractor(image)
loss = style_content_loss(outputs)
loss += total_variation_weight*tf.image.total_variation(image)
grad = tape.gradient(loss, image)
opt.apply_gradients([(grad, image)])
image.assign(clip_0_1(image))
Ponownie zainicjuj zmienną optymalizacji:
image = tf.Variable(content_image)
I uruchom optymalizację:
import time
start = time.time()
epochs = 10
steps_per_epoch = 100
step = 0
for n in range(epochs):
for m in range(steps_per_epoch):
step += 1
train_step(image)
print(".", end='', flush=True)
display.clear_output(wait=True)
display.display(tensor_to_image(image))
print("Train step: {}".format(step))
end = time.time()
print("Total time: {:.1f}".format(end-start))

Train step: 1000 Total time: 22.4
Na koniec zapisz wynik:
file_name = 'stylized-image.png'
tensor_to_image(image).save(file_name)
try:
from google.colab import files
except ImportError:
pass
else:
files.download(file_name)
Ucz się więcej
Ten samouczek przedstawia oryginalny algorytm przenoszenia stylu. Aby uzyskać proste zastosowanie transferu stylu, zapoznaj się z tym samouczkiem , aby dowiedzieć się więcej o tym, jak korzystać z modelu transferu dowolnego stylu obrazu z TensorFlow Hub .