
| | |  Visualizza su GitHub Visualizza su GitHub | | |
Questo tutorial utilizza il deep learning per comporre un'immagine nello stile di un'altra immagine (hai mai desiderato di poter dipingere come Picasso o Van Gogh?). Questo è noto come trasferimento di stile neurale e la tecnica è delineata in A Neural Algorithm of Artistic Style (Gatys et al.).
Per una semplice applicazione del trasferimento di stile, consulta questo tutorial per saperne di più su come utilizzare il modello di stilizzazione dell'immagine arbitraria pre-addestrato da TensorFlow Hub o come utilizzare un modello di trasferimento di stile con TensorFlow Lite .
Il trasferimento di stile neurale è una tecnica di ottimizzazione utilizzata per acquisire due immagini, un'immagine del contenuto e un'immagine di riferimento dello stile (come un'opera d'arte di un famoso pittore) e fonderle insieme in modo che l'immagine di output assomigli all'immagine del contenuto, ma "dipinta" nello stile dell'immagine di riferimento dello stile.
Ciò viene implementato ottimizzando l'immagine di output in modo che corrisponda alle statistiche del contenuto dell'immagine del contenuto e alle statistiche dello stile dell'immagine di riferimento dello stile. Queste statistiche vengono estratte dalle immagini utilizzando una rete convoluzionale.
Ad esempio, prendiamo un'immagine di questo cane e della Composizione 7 di Wassily Kandinsky:

Yellow Labrador Looking , da Wikimedia Commons di Elf . Licenza CC BY-SA 3.0
{kind=link}

Ora, come sarebbe se Kandinsky decidesse di dipingere l'immagine di questo cane esclusivamente con questo stile? Qualcosa come questo?

Impostare
Importa e configura i moduli
import os
import tensorflow as tf
# Load compressed models from tensorflow_hub
os.environ['TFHUB_MODEL_LOAD_FORMAT'] = 'COMPRESSED'
import IPython.display as display
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['figure.figsize'] = (12, 12)
mpl.rcParams['axes.grid'] = False
import numpy as np
import PIL.Image
import time
import functools
def tensor_to_image(tensor):
tensor = tensor*255
tensor = np.array(tensor, dtype=np.uint8)
if np.ndim(tensor)>3:
assert tensor.shape[0] == 1
tensor = tensor[0]
return PIL.Image.fromarray(tensor)
Scarica le immagini e scegli un'immagine di stile e un'immagine di contenuto:
content_path = tf.keras.utils.get_file('YellowLabradorLooking_new.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg')
style_path = tf.keras.utils.get_file('kandinsky5.jpg','https://storage.googleapis.com/download.tensorflow.org/example_images/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg 196608/195196 [==============================] - 0s 0us/step 204800/195196 [===============================] - 0s 0us/step
Visualizza l'input
Definire una funzione per caricare un'immagine e limitarne la dimensione massima a 512 pixel.
def load_img(path_to_img):
max_dim = 512
img = tf.io.read_file(path_to_img)
img = tf.image.decode_image(img, channels=3)
img = tf.image.convert_image_dtype(img, tf.float32)
shape = tf.cast(tf.shape(img)[:-1], tf.float32)
long_dim = max(shape)
scale = max_dim / long_dim
new_shape = tf.cast(shape * scale, tf.int32)
img = tf.image.resize(img, new_shape)
img = img[tf.newaxis, :]
return img
Crea una semplice funzione per visualizzare un'immagine:
def imshow(image, title=None):
if len(image.shape) > 3:
image = tf.squeeze(image, axis=0)
plt.imshow(image)
if title:
plt.title(title)
content_image = load_img(content_path)
style_image = load_img(style_path)
plt.subplot(1, 2, 1)
imshow(content_image, 'Content Image')
plt.subplot(1, 2, 2)
imshow(style_image, 'Style Image')

Trasferimento di stile veloce tramite TF-Hub
Questo tutorial mostra l'algoritmo di trasferimento dello stile originale, che ottimizza il contenuto dell'immagine in base a uno stile particolare. Prima di entrare nei dettagli, vediamo come fa il modello TensorFlow Hub :
import tensorflow_hub as hub
hub_model = hub.load('https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2')
stylized_image = hub_model(tf.constant(content_image), tf.constant(style_image))[0]
tensor_to_image(stylized_image)
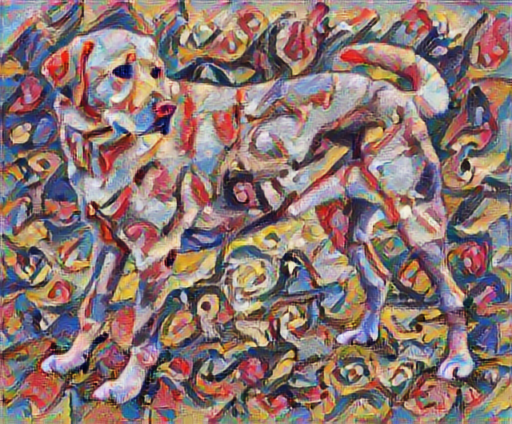
Definire il contenuto e le rappresentazioni dello stile
Utilizzare i livelli intermedi del modello per ottenere le rappresentazioni del contenuto e dello stile dell'immagine. A partire dal livello di input della rete, le prime attivazioni del livello rappresentano caratteristiche di basso livello come bordi e trame. Man mano che avanzi nella rete, gli ultimi livelli rappresentano funzionalità di livello superiore, parti di oggetti come ruote o occhi . In questo caso, stai utilizzando l'architettura di rete VGG19, una rete di classificazione delle immagini pre-addestrata. Questi livelli intermedi sono necessari per definire la rappresentazione del contenuto e dello stile delle immagini. Per un'immagine di input, prova a far corrispondere lo stile corrispondente e le rappresentazioni della destinazione del contenuto in questi livelli intermedi.
Carica un VGG19 e provalo a eseguirlo sulla nostra immagine per assicurarti che sia usato correttamente:
x = tf.keras.applications.vgg19.preprocess_input(content_image*255)
x = tf.image.resize(x, (224, 224))
vgg = tf.keras.applications.VGG19(include_top=True, weights='imagenet')
prediction_probabilities = vgg(x)
prediction_probabilities.shape
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg19/vgg19_weights_tf_dim_ordering_tf_kernels.h5 574717952/574710816 [==============================] - 17s 0us/step 574726144/574710816 [==============================] - 17s 0us/step TensorShape([1, 1000])
predicted_top_5 = tf.keras.applications.vgg19.decode_predictions(prediction_probabilities.numpy())[0]
[(class_name, prob) for (number, class_name, prob) in predicted_top_5]
[('Labrador_retriever', 0.493171),
('golden_retriever', 0.2366529),
('kuvasz', 0.036357544),
('Chesapeake_Bay_retriever', 0.024182785),
('Greater_Swiss_Mountain_dog', 0.0186461)]
Ora carica un VGG19 senza la testata di classificazione ed elenca i nomi dei livelli
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
print()
for layer in vgg.layers:
print(layer.name)
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg19/vgg19_weights_tf_dim_ordering_tf_kernels_notop.h5 80142336/80134624 [==============================] - 2s 0us/step 80150528/80134624 [==============================] - 2s 0us/step input_2 block1_conv1 block1_conv2 block1_pool block2_conv1 block2_conv2 block2_pool block3_conv1 block3_conv2 block3_conv3 block3_conv4 block3_pool block4_conv1 block4_conv2 block4_conv3 block4_conv4 block4_pool block5_conv1 block5_conv2 block5_conv3 block5_conv4 block5_pool
Scegli i livelli intermedi dalla rete per rappresentare lo stile e il contenuto dell'immagine:
content_layers = ['block5_conv2']
style_layers = ['block1_conv1',
'block2_conv1',
'block3_conv1',
'block4_conv1',
'block5_conv1']
num_content_layers = len(content_layers)
num_style_layers = len(style_layers)
Livelli intermedi per stile e contenuto
Allora perché questi output intermedi all'interno della nostra rete di classificazione delle immagini pre-addestrata ci consentono di definire lo stile e le rappresentazioni del contenuto?
Ad alto livello, affinché una rete esegua la classificazione delle immagini (cosa che questa rete è stata addestrata a fare), deve comprendere l'immagine. Ciò richiede l'assunzione dell'immagine grezza come pixel di input e la creazione di una rappresentazione interna che converta i pixel dell'immagine grezza in una comprensione complessa delle caratteristiche presenti all'interno dell'immagine.
Questo è anche un motivo per cui le reti neurali convoluzionali sono in grado di generalizzare bene: sono in grado di catturare le invarianze e le caratteristiche che definiscono all'interno di classi (ad es. gatti contro cani) che sono agnostici al rumore di fondo e ad altri fastidi. Pertanto, da qualche parte tra il punto in cui l'immagine grezza viene inserita nel modello e l'etichetta di classificazione dell'output, il modello funge da estrattore di funzionalità complesse. Accedendo ai livelli intermedi del modello, puoi descrivere il contenuto e lo stile delle immagini di input.
Costruisci il modello
Le reti in tf.keras.applications sono progettate in modo da poter estrarre facilmente i valori del livello intermedio utilizzando l'API funzionale Keras.
Per definire un modello utilizzando l'API funzionale, specificare gli input e gli output:
model = Model(inputs, outputs)
Questa funzione seguente crea un modello VGG19 che restituisce un elenco di output di livello intermedio:
def vgg_layers(layer_names):
""" Creates a vgg model that returns a list of intermediate output values."""
# Load our model. Load pretrained VGG, trained on imagenet data
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
vgg.trainable = False
outputs = [vgg.get_layer(name).output for name in layer_names]
model = tf.keras.Model([vgg.input], outputs)
return model
E per creare il modello:
style_extractor = vgg_layers(style_layers)
style_outputs = style_extractor(style_image*255)
#Look at the statistics of each layer's output
for name, output in zip(style_layers, style_outputs):
print(name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
print()
block1_conv1 shape: (1, 336, 512, 64) min: 0.0 max: 835.5256 mean: 33.97525 block2_conv1 shape: (1, 168, 256, 128) min: 0.0 max: 4625.8857 mean: 199.82687 block3_conv1 shape: (1, 84, 128, 256) min: 0.0 max: 8789.239 mean: 230.78099 block4_conv1 shape: (1, 42, 64, 512) min: 0.0 max: 21566.135 mean: 791.24005 block5_conv1 shape: (1, 21, 32, 512) min: 0.0 max: 3189.2542 mean: 59.179478
Calcola lo stile
Il contenuto di un'immagine è rappresentato dai valori delle mappe delle caratteristiche intermedie.
Si scopre che lo stile di un'immagine può essere descritto dai mezzi e dalle correlazioni tra le diverse mappe delle caratteristiche. Calcola una matrice di Gram che includa queste informazioni prendendo il prodotto esterno del vettore delle caratteristiche con se stesso in ogni posizione e calcolando la media di quel prodotto esterno su tutte le posizioni. Questa matrice di Gram può essere calcolata per uno strato particolare come:
\[G^l_{cd} = \frac{\sum_{ij} F^l_{ijc}(x)F^l_{ijd}(x)}{IJ}\]
Questo può essere implementato in modo conciso utilizzando la funzione tf.linalg.einsum :
def gram_matrix(input_tensor):
result = tf.linalg.einsum('bijc,bijd->bcd', input_tensor, input_tensor)
input_shape = tf.shape(input_tensor)
num_locations = tf.cast(input_shape[1]*input_shape[2], tf.float32)
return result/(num_locations)
Estrai stile e contenuto
Crea un modello che restituisca lo stile e i tensori del contenuto.
class StyleContentModel(tf.keras.models.Model):
def __init__(self, style_layers, content_layers):
super(StyleContentModel, self).__init__()
self.vgg = vgg_layers(style_layers + content_layers)
self.style_layers = style_layers
self.content_layers = content_layers
self.num_style_layers = len(style_layers)
self.vgg.trainable = False
def call(self, inputs):
"Expects float input in [0,1]"
inputs = inputs*255.0
preprocessed_input = tf.keras.applications.vgg19.preprocess_input(inputs)
outputs = self.vgg(preprocessed_input)
style_outputs, content_outputs = (outputs[:self.num_style_layers],
outputs[self.num_style_layers:])
style_outputs = [gram_matrix(style_output)
for style_output in style_outputs]
content_dict = {content_name: value
for content_name, value
in zip(self.content_layers, content_outputs)}
style_dict = {style_name: value
for style_name, value
in zip(self.style_layers, style_outputs)}
return {'content': content_dict, 'style': style_dict}
Quando viene chiamato su un'immagine, questo modello restituisce la gram matrix (stile) degli style_layers e il contenuto dei content_layers :
extractor = StyleContentModel(style_layers, content_layers)
results = extractor(tf.constant(content_image))
print('Styles:')
for name, output in sorted(results['style'].items()):
print(" ", name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
print()
print("Contents:")
for name, output in sorted(results['content'].items()):
print(" ", name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
Styles:
block1_conv1
shape: (1, 64, 64)
min: 0.0055228462
max: 28014.557
mean: 263.79022
block2_conv1
shape: (1, 128, 128)
min: 0.0
max: 61479.496
mean: 9100.949
block3_conv1
shape: (1, 256, 256)
min: 0.0
max: 545623.44
mean: 7660.976
block4_conv1
shape: (1, 512, 512)
min: 0.0
max: 4320502.0
mean: 134288.84
block5_conv1
shape: (1, 512, 512)
min: 0.0
max: 110005.37
mean: 1487.0378
Contents:
block5_conv2
shape: (1, 26, 32, 512)
min: 0.0
max: 2410.8796
mean: 13.764149
Esegui la discesa in pendenza
Con questo estrattore di stile e contenuto, ora puoi implementare l'algoritmo di trasferimento dello stile. Fallo calcolando l'errore quadratico medio per l'output della tua immagine rispetto a ciascun target, quindi prendi la somma ponderata di queste perdite.
Imposta il tuo stile e i valori target dei contenuti:
style_targets = extractor(style_image)['style']
content_targets = extractor(content_image)['content']
Definire una tf.Variable per contenere l'immagine da ottimizzare. Per renderlo veloce, inizializzalo con l'immagine del contenuto (la tf.Variable deve avere la stessa forma dell'immagine del contenuto):
image = tf.Variable(content_image)
Poiché si tratta di un'immagine float, definire una funzione per mantenere i valori dei pixel tra 0 e 1:
def clip_0_1(image):
return tf.clip_by_value(image, clip_value_min=0.0, clip_value_max=1.0)
Crea un ottimizzatore. Il documento raccomanda LBFGS, ma anche Adam funziona bene:
opt = tf.optimizers.Adam(learning_rate=0.02, beta_1=0.99, epsilon=1e-1)
Per ottimizzare questo, utilizzare una combinazione ponderata delle due perdite per ottenere la perdita totale:
style_weight=1e-2
content_weight=1e4
def style_content_loss(outputs):
style_outputs = outputs['style']
content_outputs = outputs['content']
style_loss = tf.add_n([tf.reduce_mean((style_outputs[name]-style_targets[name])**2)
for name in style_outputs.keys()])
style_loss *= style_weight / num_style_layers
content_loss = tf.add_n([tf.reduce_mean((content_outputs[name]-content_targets[name])**2)
for name in content_outputs.keys()])
content_loss *= content_weight / num_content_layers
loss = style_loss + content_loss
return loss
Usa tf.GradientTape per aggiornare l'immagine.
@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
outputs = extractor(image)
loss = style_content_loss(outputs)
grad = tape.gradient(loss, image)
opt.apply_gradients([(grad, image)])
image.assign(clip_0_1(image))
Ora esegui alcuni passaggi per testare:
train_step(image)
train_step(image)
train_step(image)
tensor_to_image(image)

Poiché funziona, esegui un'ottimizzazione più lunga:
import time
start = time.time()
epochs = 10
steps_per_epoch = 100
step = 0
for n in range(epochs):
for m in range(steps_per_epoch):
step += 1
train_step(image)
print(".", end='', flush=True)
display.clear_output(wait=True)
display.display(tensor_to_image(image))
print("Train step: {}".format(step))
end = time.time()
print("Total time: {:.1f}".format(end-start))

Train step: 1000 Total time: 21.3
Perdita totale di variazione
Uno svantaggio di questa implementazione di base è che produce molti artefatti ad alta frequenza. Diminuire questi utilizzando un termine di regolarizzazione esplicito sulle componenti ad alta frequenza dell'immagine. Nel trasferimento di stile, questo è spesso chiamato perdita di variazione totale :
def high_pass_x_y(image):
x_var = image[:, :, 1:, :] - image[:, :, :-1, :]
y_var = image[:, 1:, :, :] - image[:, :-1, :, :]
return x_var, y_var
x_deltas, y_deltas = high_pass_x_y(content_image)
plt.figure(figsize=(14, 10))
plt.subplot(2, 2, 1)
imshow(clip_0_1(2*y_deltas+0.5), "Horizontal Deltas: Original")
plt.subplot(2, 2, 2)
imshow(clip_0_1(2*x_deltas+0.5), "Vertical Deltas: Original")
x_deltas, y_deltas = high_pass_x_y(image)
plt.subplot(2, 2, 3)
imshow(clip_0_1(2*y_deltas+0.5), "Horizontal Deltas: Styled")
plt.subplot(2, 2, 4)
imshow(clip_0_1(2*x_deltas+0.5), "Vertical Deltas: Styled")
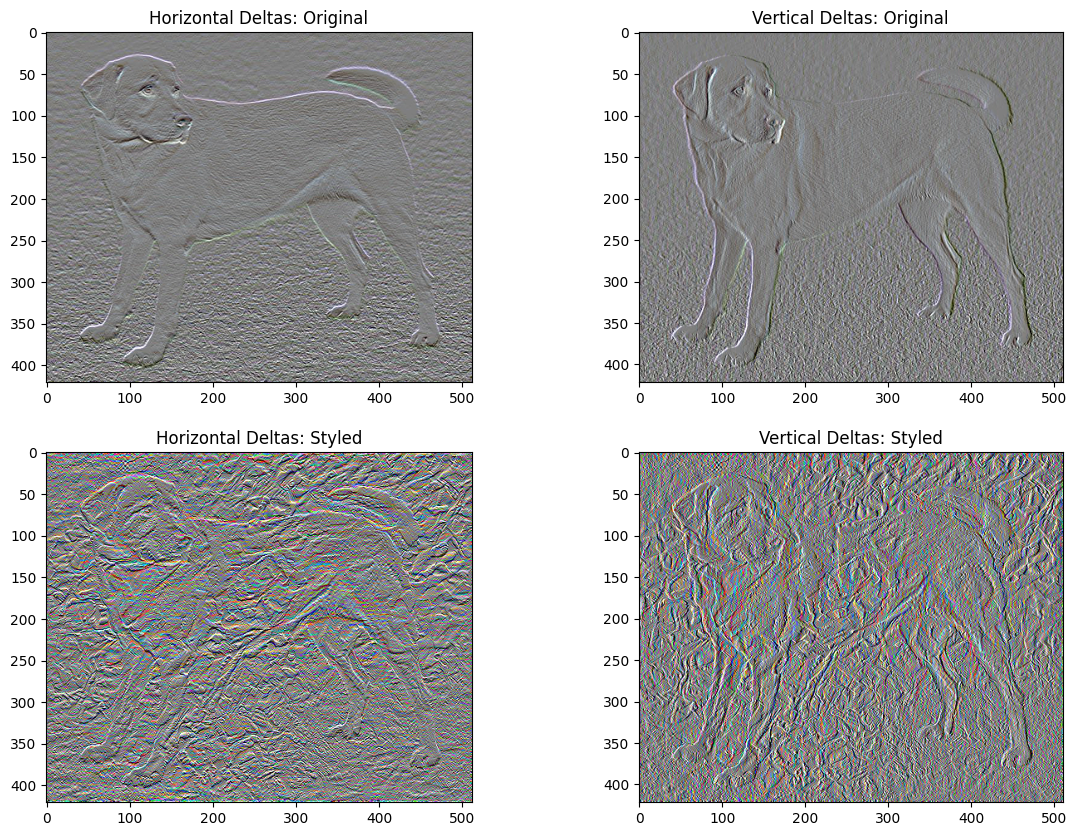
Questo mostra come sono aumentate le componenti ad alta frequenza.
Inoltre, questo componente ad alta frequenza è fondamentalmente un rilevatore di bordi. È possibile ottenere un output simile dal rilevatore di bordi Sobel, ad esempio:
plt.figure(figsize=(14, 10))
sobel = tf.image.sobel_edges(content_image)
plt.subplot(1, 2, 1)
imshow(clip_0_1(sobel[..., 0]/4+0.5), "Horizontal Sobel-edges")
plt.subplot(1, 2, 2)
imshow(clip_0_1(sobel[..., 1]/4+0.5), "Vertical Sobel-edges")
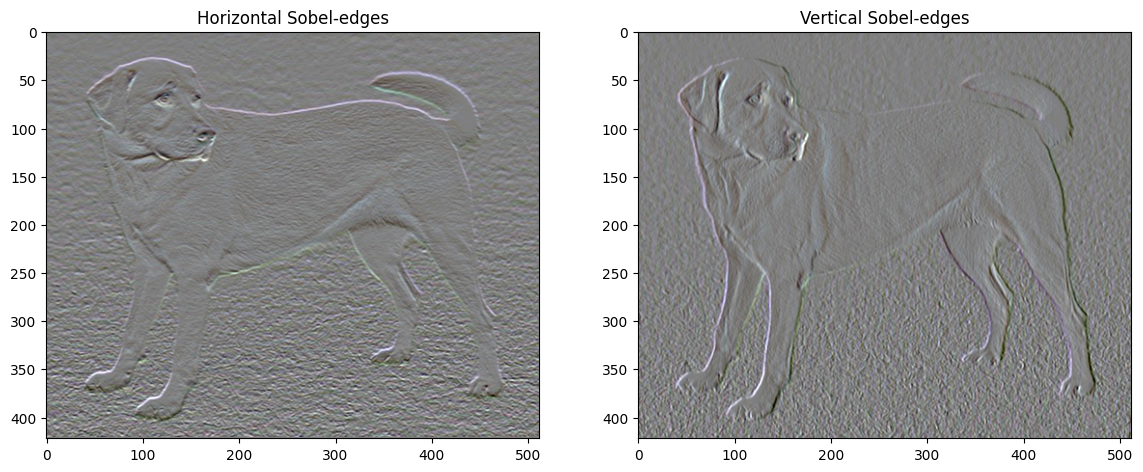
La perdita di regolarizzazione associata a questo è la somma dei quadrati dei valori:
def total_variation_loss(image):
x_deltas, y_deltas = high_pass_x_y(image)
return tf.reduce_sum(tf.abs(x_deltas)) + tf.reduce_sum(tf.abs(y_deltas))
total_variation_loss(image).numpy()
149402.94
Ciò ha dimostrato quello che fa. Ma non è necessario implementarlo da soli, TensorFlow include un'implementazione standard:
tf.image.total_variation(image).numpy()
array([149402.94], dtype=float32)
Eseguire nuovamente l'ottimizzazione
Scegli un peso per total_variation_loss :
total_variation_weight=30
Ora includilo nella funzione train_step :
@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
outputs = extractor(image)
loss = style_content_loss(outputs)
loss += total_variation_weight*tf.image.total_variation(image)
grad = tape.gradient(loss, image)
opt.apply_gradients([(grad, image)])
image.assign(clip_0_1(image))
Reinizializzare la variabile di ottimizzazione:
image = tf.Variable(content_image)
Ed esegui l'ottimizzazione:
import time
start = time.time()
epochs = 10
steps_per_epoch = 100
step = 0
for n in range(epochs):
for m in range(steps_per_epoch):
step += 1
train_step(image)
print(".", end='', flush=True)
display.clear_output(wait=True)
display.display(tensor_to_image(image))
print("Train step: {}".format(step))
end = time.time()
print("Total time: {:.1f}".format(end-start))

Train step: 1000 Total time: 22.4
Infine, salva il risultato:
file_name = 'stylized-image.png'
tensor_to_image(image).save(file_name)
try:
from google.colab import files
except ImportError:
pass
else:
files.download(file_name)
Scopri di più
Questo tutorial mostra l'algoritmo di trasferimento dello stile originale. Per una semplice applicazione del trasferimento di stile, dai un'occhiata a questo tutorial per saperne di più su come utilizzare il modello di trasferimento dello stile di immagine arbitrario da TensorFlow Hub .