
| | |  गिटहब पर देखें गिटहब पर देखें | | |
यह ट्यूटोरियल एक छवि को दूसरी छवि की शैली में बनाने के लिए गहन शिक्षा का उपयोग करता है (क्या आप कभी पिकासो या वैन गॉग की तरह पेंट कर सकते हैं?) इसे न्यूरल स्टाइल ट्रांसफर के रूप में जाना जाता है और तकनीक को ए न्यूरल एल्गोरिथम ऑफ़ आर्टिस्टिक स्टाइल (गैटिस एट अल।) में उल्लिखित किया गया है।
शैली हस्तांतरण के एक सरल अनुप्रयोग के लिए इस ट्यूटोरियल को देखें कि कैसे TensorFlow हब से पूर्व- प्रशिक्षित मनमाना छवि शैलीकरण मॉडल का उपयोग करें या TensorFlow Lite के साथ शैली स्थानांतरण मॉडल का उपयोग कैसे करें।
तंत्रिका शैली स्थानांतरण एक अनुकूलन तकनीक है जिसका उपयोग दो छवियों को लेने के लिए किया जाता है - एक सामग्री छवि और एक शैली संदर्भ छवि (जैसे कि एक प्रसिद्ध चित्रकार द्वारा एक कलाकृति) - और उन्हें एक साथ मिलाएं ताकि आउटपुट छवि सामग्री छवि की तरह दिखे, लेकिन "चित्रित" शैली संदर्भ छवि की शैली में।
यह सामग्री छवि के सामग्री आंकड़ों और शैली संदर्भ छवि के शैली आंकड़ों से मेल खाने के लिए आउटपुट छवि को अनुकूलित करके कार्यान्वित किया जाता है। इन आँकड़ों को एक दृढ़ नेटवर्क का उपयोग करके छवियों से निकाला जाता है।
उदाहरण के लिए, आइए इस कुत्ते और वासिली कैंडिंस्की की रचना 7 की एक छवि लें:

एल्फ द्वारा विकिमीडिया कॉमन्स से येलो लैब्राडोर लुकिंग । लाइसेंस सीसी बाय-एसए 3.0
{kind=link}

अब यह कैसा लगेगा यदि कैंडिंस्की ने इस कुत्ते की तस्वीर को विशेष रूप से इस शैली के साथ चित्रित करने का फैसला किया है? कुछ इस तरह?

सेट अप
मॉड्यूल आयात और कॉन्फ़िगर करें
import os
import tensorflow as tf
# Load compressed models from tensorflow_hub
os.environ['TFHUB_MODEL_LOAD_FORMAT'] = 'COMPRESSED'
import IPython.display as display
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['figure.figsize'] = (12, 12)
mpl.rcParams['axes.grid'] = False
import numpy as np
import PIL.Image
import time
import functools
def tensor_to_image(tensor):
tensor = tensor*255
tensor = np.array(tensor, dtype=np.uint8)
if np.ndim(tensor)>3:
assert tensor.shape[0] == 1
tensor = tensor[0]
return PIL.Image.fromarray(tensor)
चित्र डाउनलोड करें और एक शैली छवि और एक सामग्री छवि चुनें:
content_path = tf.keras.utils.get_file('YellowLabradorLooking_new.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg')
style_path = tf.keras.utils.get_file('kandinsky5.jpg','https://storage.googleapis.com/download.tensorflow.org/example_images/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg 196608/195196 [==============================] - 0s 0us/step 204800/195196 [===============================] - 0s 0us/step
इनपुट की कल्पना करें
एक छवि लोड करने के लिए एक फ़ंक्शन को परिभाषित करें और इसके अधिकतम आयाम को 512 पिक्सेल तक सीमित करें।
def load_img(path_to_img):
max_dim = 512
img = tf.io.read_file(path_to_img)
img = tf.image.decode_image(img, channels=3)
img = tf.image.convert_image_dtype(img, tf.float32)
shape = tf.cast(tf.shape(img)[:-1], tf.float32)
long_dim = max(shape)
scale = max_dim / long_dim
new_shape = tf.cast(shape * scale, tf.int32)
img = tf.image.resize(img, new_shape)
img = img[tf.newaxis, :]
return img
एक छवि प्रदर्शित करने के लिए एक सरल कार्य बनाएँ:
def imshow(image, title=None):
if len(image.shape) > 3:
image = tf.squeeze(image, axis=0)
plt.imshow(image)
if title:
plt.title(title)
content_image = load_img(content_path)
style_image = load_img(style_path)
plt.subplot(1, 2, 1)
imshow(content_image, 'Content Image')
plt.subplot(1, 2, 2)
imshow(style_image, 'Style Image')

TF-Hub का उपयोग करके फास्ट स्टाइल ट्रांसफर
यह ट्यूटोरियल मूल स्टाइल-ट्रांसफर एल्गोरिथम को प्रदर्शित करता है, जो छवि सामग्री को एक विशेष शैली में अनुकूलित करता है। विवरण में जाने से पहले, आइए देखें कि TensorFlow हब मॉडल यह कैसे करता है:
import tensorflow_hub as hub
hub_model = hub.load('https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2')
stylized_image = hub_model(tf.constant(content_image), tf.constant(style_image))[0]
tensor_to_image(stylized_image)
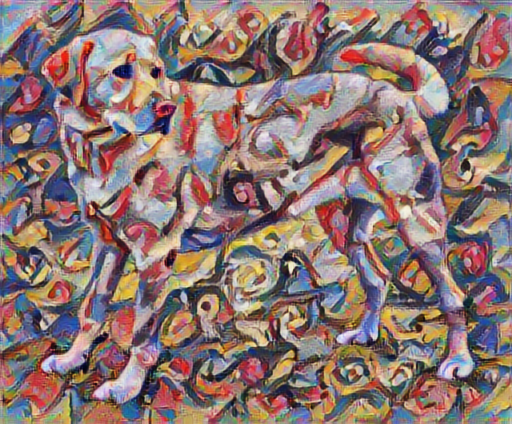
सामग्री और शैली के प्रतिनिधित्व को परिभाषित करें
छवि की सामग्री और शैली का प्रतिनिधित्व प्राप्त करने के लिए मॉडल की मध्यवर्ती परतों का उपयोग करें। नेटवर्क की इनपुट परत से शुरू होकर, पहले कुछ परत सक्रियण किनारों और बनावट जैसी निम्न-स्तरीय सुविधाओं का प्रतिनिधित्व करते हैं। जैसे ही आप नेटवर्क के माध्यम से कदम रखते हैं, अंतिम कुछ परतें उच्च-स्तरीय सुविधाओं का प्रतिनिधित्व करती हैं-वस्तु भाग जैसे पहिये या आंखें । इस मामले में, आप VGG19 नेटवर्क आर्किटेक्चर का उपयोग कर रहे हैं, जो एक पूर्व-प्रशिक्षित छवि वर्गीकरण नेटवर्क है। छवियों से सामग्री और शैली के प्रतिनिधित्व को परिभाषित करने के लिए ये मध्यवर्ती परतें आवश्यक हैं। एक इनपुट छवि के लिए, इन मध्यवर्ती परतों पर संबंधित शैली और सामग्री लक्ष्य अभ्यावेदन से मिलान करने का प्रयास करें।
एक VGG19 लोड करें और यह सुनिश्चित करने के लिए हमारी छवि पर परीक्षण चलाएँ कि यह सही तरीके से उपयोग किया गया है:
x = tf.keras.applications.vgg19.preprocess_input(content_image*255)
x = tf.image.resize(x, (224, 224))
vgg = tf.keras.applications.VGG19(include_top=True, weights='imagenet')
prediction_probabilities = vgg(x)
prediction_probabilities.shape
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg19/vgg19_weights_tf_dim_ordering_tf_kernels.h5 574717952/574710816 [==============================] - 17s 0us/step 574726144/574710816 [==============================] - 17s 0us/step TensorShape([1, 1000])
predicted_top_5 = tf.keras.applications.vgg19.decode_predictions(prediction_probabilities.numpy())[0]
[(class_name, prob) for (number, class_name, prob) in predicted_top_5]
[('Labrador_retriever', 0.493171),
('golden_retriever', 0.2366529),
('kuvasz', 0.036357544),
('Chesapeake_Bay_retriever', 0.024182785),
('Greater_Swiss_Mountain_dog', 0.0186461)]
अब एक VGG19 को बिना वर्गीकरण शीर्ष के लोड करें, और परत के नामों को सूचीबद्ध करें
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
print()
for layer in vgg.layers:
print(layer.name)
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg19/vgg19_weights_tf_dim_ordering_tf_kernels_notop.h5 80142336/80134624 [==============================] - 2s 0us/step 80150528/80134624 [==============================] - 2s 0us/step input_2 block1_conv1 block1_conv2 block1_pool block2_conv1 block2_conv2 block2_pool block3_conv1 block3_conv2 block3_conv3 block3_conv4 block3_pool block4_conv1 block4_conv2 block4_conv3 block4_conv4 block4_pool block5_conv1 block5_conv2 block5_conv3 block5_conv4 block5_pool
छवि की शैली और सामग्री का प्रतिनिधित्व करने के लिए नेटवर्क से मध्यवर्ती परतें चुनें:
content_layers = ['block5_conv2']
style_layers = ['block1_conv1',
'block2_conv1',
'block3_conv1',
'block4_conv1',
'block5_conv1']
num_content_layers = len(content_layers)
num_style_layers = len(style_layers)
शैली और सामग्री के लिए मध्यवर्ती परतें
तो हमारे पूर्व-प्रशिक्षित छवि वर्गीकरण नेटवर्क के भीतर ये मध्यवर्ती आउटपुट हमें शैली और सामग्री प्रतिनिधित्व को परिभाषित करने की अनुमति क्यों देते हैं?
उच्च स्तर पर, नेटवर्क के लिए छवि वर्गीकरण (जिसे करने के लिए इस नेटवर्क को प्रशिक्षित किया गया है) करने के लिए, उसे छवि को समझना चाहिए। इसके लिए कच्ची छवि को इनपुट पिक्सेल के रूप में लेने और एक आंतरिक प्रतिनिधित्व बनाने की आवश्यकता होती है जो कच्ची छवि पिक्सेल को छवि के भीतर मौजूद सुविधाओं की जटिल समझ में परिवर्तित करता है।
यह भी एक कारण है कि क्यों दृढ़ तंत्रिका नेटवर्क अच्छी तरह से सामान्यीकरण करने में सक्षम हैं: वे कक्षाओं के भीतर इनवेरिएंस और परिभाषित सुविधाओं को पकड़ने में सक्षम हैं (उदाहरण के लिए बिल्लियों बनाम कुत्ते) जो पृष्ठभूमि शोर और अन्य उपद्रवों के लिए अज्ञेयवादी हैं। इस प्रकार, कहीं न कहीं जहां कच्ची छवि को मॉडल और आउटपुट वर्गीकरण लेबल में फीड किया जाता है, मॉडल एक जटिल फीचर एक्सट्रैक्टर के रूप में कार्य करता है। मॉडल की मध्यवर्ती परतों तक पहुंच कर, आप इनपुट छवियों की सामग्री और शैली का वर्णन करने में सक्षम हैं।
मॉडल बनाएं
tf.keras.applications में नेटवर्क डिज़ाइन किए गए हैं ताकि आप Keras कार्यात्मक API का उपयोग करके आसानी से मध्यवर्ती परत मान निकाल सकें।
कार्यात्मक एपीआई का उपयोग करके एक मॉडल को परिभाषित करने के लिए, इनपुट और आउटपुट निर्दिष्ट करें:
model = Model(inputs, outputs)
यह निम्न फ़ंक्शन एक VGG19 मॉडल बनाता है जो मध्यवर्ती परत आउटपुट की सूची देता है:
def vgg_layers(layer_names):
""" Creates a vgg model that returns a list of intermediate output values."""
# Load our model. Load pretrained VGG, trained on imagenet data
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
vgg.trainable = False
outputs = [vgg.get_layer(name).output for name in layer_names]
model = tf.keras.Model([vgg.input], outputs)
return model
और मॉडल बनाने के लिए:
style_extractor = vgg_layers(style_layers)
style_outputs = style_extractor(style_image*255)
#Look at the statistics of each layer's output
for name, output in zip(style_layers, style_outputs):
print(name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
print()
block1_conv1 shape: (1, 336, 512, 64) min: 0.0 max: 835.5256 mean: 33.97525 block2_conv1 shape: (1, 168, 256, 128) min: 0.0 max: 4625.8857 mean: 199.82687 block3_conv1 shape: (1, 84, 128, 256) min: 0.0 max: 8789.239 mean: 230.78099 block4_conv1 shape: (1, 42, 64, 512) min: 0.0 max: 21566.135 mean: 791.24005 block5_conv1 shape: (1, 21, 32, 512) min: 0.0 max: 3189.2542 mean: 59.179478
शैली की गणना करें
एक छवि की सामग्री को मध्यवर्ती फीचर मैप्स के मूल्यों द्वारा दर्शाया जाता है।
यह पता चला है, एक छवि की शैली को विभिन्न फीचर मैप्स में साधनों और सहसंबंधों द्वारा वर्णित किया जा सकता है। एक ग्राम मैट्रिक्स की गणना करें जिसमें प्रत्येक स्थान पर फीचर वेक्टर के बाहरी उत्पाद को अपने साथ लेकर और सभी स्थानों पर उस बाहरी उत्पाद का औसत लेकर यह जानकारी शामिल है। इस ग्राम मैट्रिक्स की गणना एक विशेष परत के लिए की जा सकती है:
\[G^l_{cd} = \frac{\sum_{ij} F^l_{ijc}(x)F^l_{ijd}(x)}{IJ}\]
इसे tf.linalg.einsum फ़ंक्शन का उपयोग करके संक्षिप्त रूप से कार्यान्वित किया जा सकता है:
def gram_matrix(input_tensor):
result = tf.linalg.einsum('bijc,bijd->bcd', input_tensor, input_tensor)
input_shape = tf.shape(input_tensor)
num_locations = tf.cast(input_shape[1]*input_shape[2], tf.float32)
return result/(num_locations)
शैली और सामग्री निकालें
एक मॉडल बनाएं जो शैली और सामग्री टेंसर लौटाए।
class StyleContentModel(tf.keras.models.Model):
def __init__(self, style_layers, content_layers):
super(StyleContentModel, self).__init__()
self.vgg = vgg_layers(style_layers + content_layers)
self.style_layers = style_layers
self.content_layers = content_layers
self.num_style_layers = len(style_layers)
self.vgg.trainable = False
def call(self, inputs):
"Expects float input in [0,1]"
inputs = inputs*255.0
preprocessed_input = tf.keras.applications.vgg19.preprocess_input(inputs)
outputs = self.vgg(preprocessed_input)
style_outputs, content_outputs = (outputs[:self.num_style_layers],
outputs[self.num_style_layers:])
style_outputs = [gram_matrix(style_output)
for style_output in style_outputs]
content_dict = {content_name: value
for content_name, value
in zip(self.content_layers, content_outputs)}
style_dict = {style_name: value
for style_name, value
in zip(self.style_layers, style_outputs)}
return {'content': content_dict, 'style': style_dict}
जब किसी छवि पर कॉल किया जाता है, तो यह मॉडल style_layers की ग्राम मैट्रिक्स (शैली) और content_layers की सामग्री लौटाता है:
extractor = StyleContentModel(style_layers, content_layers)
results = extractor(tf.constant(content_image))
print('Styles:')
for name, output in sorted(results['style'].items()):
print(" ", name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
print()
print("Contents:")
for name, output in sorted(results['content'].items()):
print(" ", name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
Styles:
block1_conv1
shape: (1, 64, 64)
min: 0.0055228462
max: 28014.557
mean: 263.79022
block2_conv1
shape: (1, 128, 128)
min: 0.0
max: 61479.496
mean: 9100.949
block3_conv1
shape: (1, 256, 256)
min: 0.0
max: 545623.44
mean: 7660.976
block4_conv1
shape: (1, 512, 512)
min: 0.0
max: 4320502.0
mean: 134288.84
block5_conv1
shape: (1, 512, 512)
min: 0.0
max: 110005.37
mean: 1487.0378
Contents:
block5_conv2
shape: (1, 26, 32, 512)
min: 0.0
max: 2410.8796
mean: 13.764149
ग्रेडिएंट डिसेंट चलाएँ
इस स्टाइल और कंटेंट एक्सट्रैक्टर के साथ, अब आप स्टाइल ट्रांसफर एल्गोरिथम को लागू कर सकते हैं। प्रत्येक लक्ष्य के सापेक्ष अपनी छवि के आउटपुट के लिए माध्य वर्ग त्रुटि की गणना करके ऐसा करें, फिर इन नुकसानों का भारित योग लें।
अपनी शैली और सामग्री लक्ष्य मान सेट करें:
style_targets = extractor(style_image)['style']
content_targets = extractor(content_image)['content']
अनुकूलित करने के लिए छवि को शामिल करने के लिए एक tf.Variable परिभाषित करें। इसे त्वरित बनाने के लिए, इसे सामग्री छवि के साथ प्रारंभ करें ( tf.Variable सामग्री छवि के समान आकार का होना चाहिए):
image = tf.Variable(content_image)
चूंकि यह एक फ्लोट छवि है, पिक्सेल मान 0 और 1 के बीच रखने के लिए एक फ़ंक्शन परिभाषित करें:
def clip_0_1(image):
return tf.clip_by_value(image, clip_value_min=0.0, clip_value_max=1.0)
एक अनुकूलक बनाएँ। पेपर एलबीएफजीएस की सिफारिश करता है, लेकिन Adam भी ठीक काम करता है:
opt = tf.optimizers.Adam(learning_rate=0.02, beta_1=0.99, epsilon=1e-1)
इसे अनुकूलित करने के लिए, कुल हानि प्राप्त करने के लिए दो हानियों के भारित संयोजन का उपयोग करें:
style_weight=1e-2
content_weight=1e4
def style_content_loss(outputs):
style_outputs = outputs['style']
content_outputs = outputs['content']
style_loss = tf.add_n([tf.reduce_mean((style_outputs[name]-style_targets[name])**2)
for name in style_outputs.keys()])
style_loss *= style_weight / num_style_layers
content_loss = tf.add_n([tf.reduce_mean((content_outputs[name]-content_targets[name])**2)
for name in content_outputs.keys()])
content_loss *= content_weight / num_content_layers
loss = style_loss + content_loss
return loss
छवि को अद्यतन करने के लिए tf.GradientTape का उपयोग करें।
@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
outputs = extractor(image)
loss = style_content_loss(outputs)
grad = tape.gradient(loss, image)
opt.apply_gradients([(grad, image)])
image.assign(clip_0_1(image))
अब परीक्षण के लिए कुछ चरण चलाएँ:
train_step(image)
train_step(image)
train_step(image)
tensor_to_image(image)

चूंकि यह काम कर रहा है, इसलिए लंबा अनुकूलन करें:
import time
start = time.time()
epochs = 10
steps_per_epoch = 100
step = 0
for n in range(epochs):
for m in range(steps_per_epoch):
step += 1
train_step(image)
print(".", end='', flush=True)
display.clear_output(wait=True)
display.display(tensor_to_image(image))
print("Train step: {}".format(step))
end = time.time()
print("Total time: {:.1f}".format(end-start))

Train step: 1000 Total time: 21.3
कुल भिन्नता हानि
इस बुनियादी कार्यान्वयन का एक नकारात्मक पहलू यह है कि यह बहुत अधिक उच्च आवृत्ति कलाकृतियों का उत्पादन करता है। छवि के उच्च आवृत्ति घटकों पर एक स्पष्ट नियमितीकरण शब्द का उपयोग करके इन्हें घटाएं। स्टाइल ट्रांसफर में, इसे अक्सर टोटल वेरिएशन लॉस कहा जाता है:
def high_pass_x_y(image):
x_var = image[:, :, 1:, :] - image[:, :, :-1, :]
y_var = image[:, 1:, :, :] - image[:, :-1, :, :]
return x_var, y_var
x_deltas, y_deltas = high_pass_x_y(content_image)
plt.figure(figsize=(14, 10))
plt.subplot(2, 2, 1)
imshow(clip_0_1(2*y_deltas+0.5), "Horizontal Deltas: Original")
plt.subplot(2, 2, 2)
imshow(clip_0_1(2*x_deltas+0.5), "Vertical Deltas: Original")
x_deltas, y_deltas = high_pass_x_y(image)
plt.subplot(2, 2, 3)
imshow(clip_0_1(2*y_deltas+0.5), "Horizontal Deltas: Styled")
plt.subplot(2, 2, 4)
imshow(clip_0_1(2*x_deltas+0.5), "Vertical Deltas: Styled")
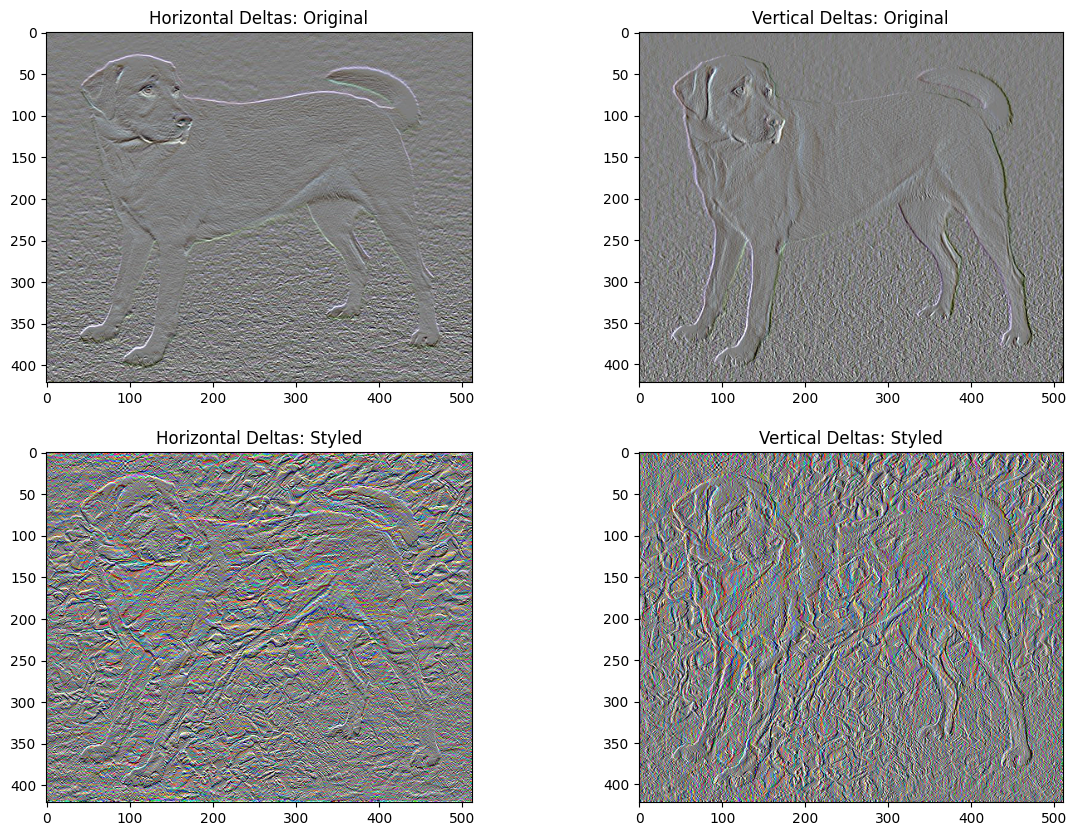
यह दिखाता है कि कैसे उच्च आवृत्ति घटकों में वृद्धि हुई है।
इसके अलावा, यह उच्च आवृत्ति घटक मूल रूप से एक एज-डिटेक्टर है। उदाहरण के लिए, आप सोबेल एज डिटेक्टर से समान आउटपुट प्राप्त कर सकते हैं:
plt.figure(figsize=(14, 10))
sobel = tf.image.sobel_edges(content_image)
plt.subplot(1, 2, 1)
imshow(clip_0_1(sobel[..., 0]/4+0.5), "Horizontal Sobel-edges")
plt.subplot(1, 2, 2)
imshow(clip_0_1(sobel[..., 1]/4+0.5), "Vertical Sobel-edges")
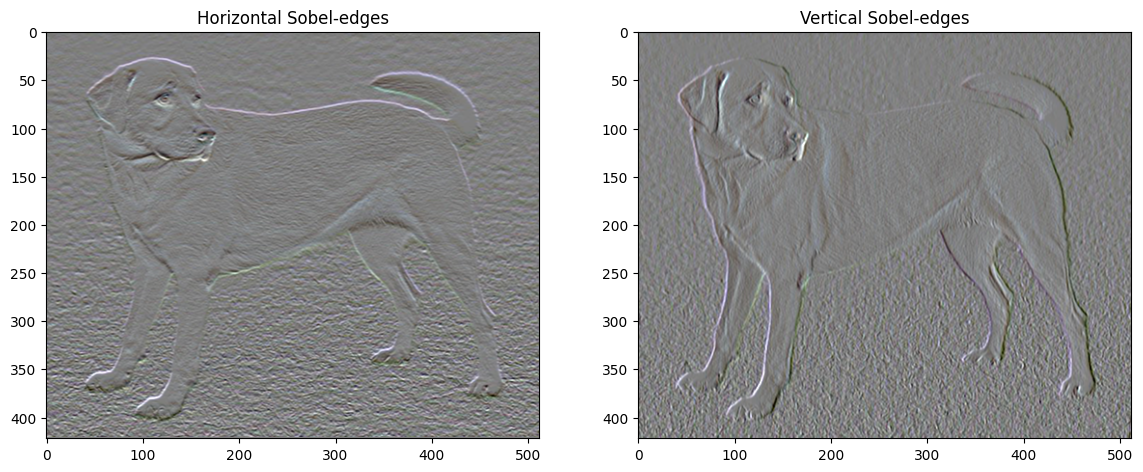
इससे जुड़ा नियमितीकरण नुकसान मूल्यों के वर्गों का योग है:
def total_variation_loss(image):
x_deltas, y_deltas = high_pass_x_y(image)
return tf.reduce_sum(tf.abs(x_deltas)) + tf.reduce_sum(tf.abs(y_deltas))
total_variation_loss(image).numpy()
149402.94
इसने दिखाया कि यह क्या करता है। लेकिन इसे स्वयं लागू करने की कोई आवश्यकता नहीं है, TensorFlow में एक मानक कार्यान्वयन शामिल है:
tf.image.total_variation(image).numpy()
array([149402.94], dtype=float32)
अनुकूलन फिर से चलाएँ
total_variation_loss के लिए वज़न चुनें:
total_variation_weight=30
अब इसे train_step फंक्शन में शामिल करें:
@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
outputs = extractor(image)
loss = style_content_loss(outputs)
loss += total_variation_weight*tf.image.total_variation(image)
grad = tape.gradient(loss, image)
opt.apply_gradients([(grad, image)])
image.assign(clip_0_1(image))
अनुकूलन चर को पुन: प्रारंभ करें:
image = tf.Variable(content_image)
और अनुकूलन चलाएँ:
import time
start = time.time()
epochs = 10
steps_per_epoch = 100
step = 0
for n in range(epochs):
for m in range(steps_per_epoch):
step += 1
train_step(image)
print(".", end='', flush=True)
display.clear_output(wait=True)
display.display(tensor_to_image(image))
print("Train step: {}".format(step))
end = time.time()
print("Total time: {:.1f}".format(end-start))

Train step: 1000 Total time: 22.4
अंत में, परिणाम सहेजें:
file_name = 'stylized-image.png'
tensor_to_image(image).save(file_name)
try:
from google.colab import files
except ImportError:
pass
else:
files.download(file_name)
और अधिक जानें
यह ट्यूटोरियल मूल स्टाइल-ट्रांसफर एल्गोरिथम को प्रदर्शित करता है। स्टाइल ट्रांसफर के एक सरल अनुप्रयोग के लिए TensorFlow हब से मनमानी छवि शैली स्थानांतरण मॉडल का उपयोग करने के तरीके के बारे में अधिक जानने के लिए इस ट्यूटोरियल को देखें।