
| | |  در GitHub مشاهده کنید در GitHub مشاهده کنید | | |
این آموزش از یادگیری عمیق برای نوشتن یک تصویر به سبک تصویر دیگر استفاده می کند (تا حالا ای کاش می توانستید مانند پیکاسو یا ون گوگ نقاشی کنید؟). این به عنوان انتقال سبک عصبی شناخته می شود و این تکنیک در الگوریتم عصبی سبک هنری (گیتس و همکاران) تشریح شده است.
برای استفاده ساده از انتقال سبک، این آموزش را بررسی کنید تا در مورد نحوه استفاده از مدل سبکسازی تصویر دلخواه از TensorFlow Hub یا نحوه استفاده از مدل انتقال سبک با TensorFlow Lite بیشتر بدانید.
انتقال سبک عصبی یک تکنیک بهینهسازی است که برای گرفتن دو تصویر - یک تصویر محتوا و یک تصویر مرجع سبک (مانند یک اثر هنری توسط یک نقاش معروف) - و ترکیب آنها با هم استفاده میشود تا تصویر خروجی شبیه تصویر محتوا به نظر برسد، اما "نقاشی" شده است. به سبک تصویر مرجع سبک.
این امر با بهینه سازی تصویر خروجی برای مطابقت با آمار محتوای تصویر محتوا و آمار سبک تصویر مرجع سبک اجرا می شود. این آمار با استفاده از یک شبکه کانولوشن از تصاویر استخراج شده است.
برای مثال، بیایید تصویری از این سگ و ترکیب 7 واسیلی کاندینسکی بگیریم:

لابرادور زرد به دنبال , از Wikimedia Commons توسط Elf . مجوز CC BY-SA 3.0
{kind=link}

حالا اگر کاندینسکی تصمیم بگیرد تصویر این سگ را منحصراً با این سبک نقاشی کند چگونه به نظر می رسد؟ چیزی مثل این؟

برپایی
وارد کردن و پیکربندی ماژول ها
import os
import tensorflow as tf
# Load compressed models from tensorflow_hub
os.environ['TFHUB_MODEL_LOAD_FORMAT'] = 'COMPRESSED'
import IPython.display as display
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['figure.figsize'] = (12, 12)
mpl.rcParams['axes.grid'] = False
import numpy as np
import PIL.Image
import time
import functools
def tensor_to_image(tensor):
tensor = tensor*255
tensor = np.array(tensor, dtype=np.uint8)
if np.ndim(tensor)>3:
assert tensor.shape[0] == 1
tensor = tensor[0]
return PIL.Image.fromarray(tensor)
تصاویر را دانلود کنید و یک تصویر سبک و یک تصویر محتوا را انتخاب کنید:
content_path = tf.keras.utils.get_file('YellowLabradorLooking_new.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg')
style_path = tf.keras.utils.get_file('kandinsky5.jpg','https://storage.googleapis.com/download.tensorflow.org/example_images/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg 196608/195196 [==============================] - 0s 0us/step 204800/195196 [===============================] - 0s 0us/step
ورودی را تجسم کنید
یک تابع برای بارگذاری یک تصویر و محدود کردن حداکثر ابعاد آن به 512 پیکسل تعریف کنید.
def load_img(path_to_img):
max_dim = 512
img = tf.io.read_file(path_to_img)
img = tf.image.decode_image(img, channels=3)
img = tf.image.convert_image_dtype(img, tf.float32)
shape = tf.cast(tf.shape(img)[:-1], tf.float32)
long_dim = max(shape)
scale = max_dim / long_dim
new_shape = tf.cast(shape * scale, tf.int32)
img = tf.image.resize(img, new_shape)
img = img[tf.newaxis, :]
return img
یک تابع ساده برای نمایش تصویر ایجاد کنید:
def imshow(image, title=None):
if len(image.shape) > 3:
image = tf.squeeze(image, axis=0)
plt.imshow(image)
if title:
plt.title(title)
content_image = load_img(content_path)
style_image = load_img(style_path)
plt.subplot(1, 2, 1)
imshow(content_image, 'Content Image')
plt.subplot(1, 2, 2)
imshow(style_image, 'Style Image')

انتقال سریع سبک با استفاده از TF-Hub
این آموزش الگوریتم اصلی انتقال سبک را نشان می دهد که محتوای تصویر را به یک سبک خاص بهینه می کند. قبل از پرداختن به جزئیات، بیایید ببینیم که چگونه مدل TensorFlow Hub این کار را انجام می دهد:
import tensorflow_hub as hub
hub_model = hub.load('https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2')
stylized_image = hub_model(tf.constant(content_image), tf.constant(style_image))[0]
tensor_to_image(stylized_image)
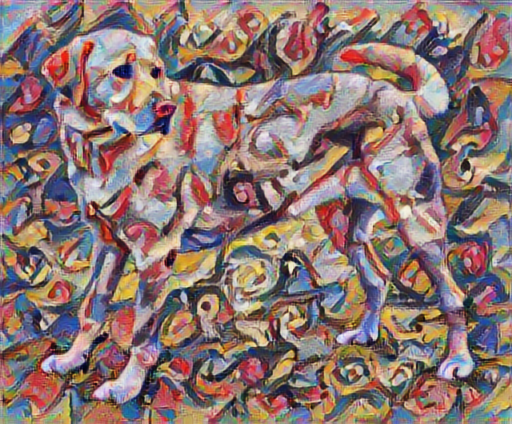
بازنمایی محتوا و سبک را تعریف کنید
از لایه های میانی مدل برای بدست آوردن نمایش محتوا و سبک تصویر استفاده کنید. با شروع از لایه ورودی شبکه، چند فعال سازی لایه اول نشان دهنده ویژگی های سطح پایین مانند لبه ها و بافت ها هستند. همانطور که در شبکه قدم می گذارید، چند لایه نهایی نمایانگر ویژگی های سطح بالاتر هستند - بخش های شی مانند چرخ ها یا چشم ها . در این مورد، شما از معماری شبکه VGG19، یک شبکه طبقه بندی تصاویر از پیش آموزش دیده استفاده می کنید. این لایه های میانی برای تعریف بازنمایی محتوا و سبک از تصاویر ضروری هستند. برای یک تصویر ورودی، سعی کنید سبک مربوطه و نمایش های هدف محتوایی را در این لایه های میانی مطابقت دهید.
یک VGG19 را بارگیری کنید و آن را روی تصویر خود آزمایش کنید تا مطمئن شوید که درست استفاده شده است:
x = tf.keras.applications.vgg19.preprocess_input(content_image*255)
x = tf.image.resize(x, (224, 224))
vgg = tf.keras.applications.VGG19(include_top=True, weights='imagenet')
prediction_probabilities = vgg(x)
prediction_probabilities.shape
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg19/vgg19_weights_tf_dim_ordering_tf_kernels.h5 574717952/574710816 [==============================] - 17s 0us/step 574726144/574710816 [==============================] - 17s 0us/step TensorShape([1, 1000])
predicted_top_5 = tf.keras.applications.vgg19.decode_predictions(prediction_probabilities.numpy())[0]
[(class_name, prob) for (number, class_name, prob) in predicted_top_5]
[('Labrador_retriever', 0.493171),
('golden_retriever', 0.2366529),
('kuvasz', 0.036357544),
('Chesapeake_Bay_retriever', 0.024182785),
('Greater_Swiss_Mountain_dog', 0.0186461)]
اکنون یک VGG19 را بدون سر طبقه بندی بارگذاری کنید و نام لایه ها را فهرست کنید
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
print()
for layer in vgg.layers:
print(layer.name)
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg19/vgg19_weights_tf_dim_ordering_tf_kernels_notop.h5 80142336/80134624 [==============================] - 2s 0us/step 80150528/80134624 [==============================] - 2s 0us/step input_2 block1_conv1 block1_conv2 block1_pool block2_conv1 block2_conv2 block2_pool block3_conv1 block3_conv2 block3_conv3 block3_conv4 block3_pool block4_conv1 block4_conv2 block4_conv3 block4_conv4 block4_pool block5_conv1 block5_conv2 block5_conv3 block5_conv4 block5_pool
لایه های میانی را از شبکه برای نمایش سبک و محتوای تصویر انتخاب کنید:
content_layers = ['block5_conv2']
style_layers = ['block1_conv1',
'block2_conv1',
'block3_conv1',
'block4_conv1',
'block5_conv1']
num_content_layers = len(content_layers)
num_style_layers = len(style_layers)
لایه های میانی برای سبک و محتوا
پس چرا این خروجیهای میانی در شبکه طبقهبندی تصویر از پیش آموزشدیده ما به ما اجازه میدهند تا بازنماییهای سبک و محتوا را تعریف کنیم؟
در سطح بالا، برای اینکه یک شبکه بتواند طبقه بندی تصاویر را انجام دهد (که این شبکه برای انجام آن آموزش دیده است)، باید تصویر را درک کند. این امر مستلزم گرفتن تصویر خام به عنوان پیکسل های ورودی و ساختن یک نمایش داخلی است که پیکسل های تصویر خام را به درک پیچیده ای از ویژگی های موجود در تصویر تبدیل می کند.
همچنین این دلیلی است که چرا شبکههای عصبی کانولوشنال قادر به تعمیم خوبی هستند: آنها میتوانند تغییرناپذیریها و ویژگیهای تعریفکننده در کلاسها (مثلاً گربهها در مقابل سگ) را که نسبت به نویز پسزمینه و سایر مزاحمتها آگنوستیک هستند، ثبت کنند. بنابراین، جایی بین جایی که تصویر خام به مدل وارد می شود و برچسب طبقه بندی خروجی، مدل به عنوان یک استخراج کننده ویژگی پیچیده عمل می کند. با دسترسی به لایههای میانی مدل، میتوانید محتوا و سبک تصاویر ورودی را توصیف کنید.
مدل را بسازید
شبکه های موجود در tf.keras.applications طوری طراحی شده اند که بتوانید مقادیر لایه میانی را با استفاده از API عملکردی Keras به راحتی استخراج کنید.
برای تعریف یک مدل با استفاده از API تابعی، ورودی و خروجی ها را مشخص کنید:
model = Model(inputs, outputs)
این تابع زیر یک مدل VGG19 می سازد که لیستی از خروجی های لایه میانی را برمی گرداند:
def vgg_layers(layer_names):
""" Creates a vgg model that returns a list of intermediate output values."""
# Load our model. Load pretrained VGG, trained on imagenet data
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
vgg.trainable = False
outputs = [vgg.get_layer(name).output for name in layer_names]
model = tf.keras.Model([vgg.input], outputs)
return model
و برای ایجاد مدل:
style_extractor = vgg_layers(style_layers)
style_outputs = style_extractor(style_image*255)
#Look at the statistics of each layer's output
for name, output in zip(style_layers, style_outputs):
print(name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
print()
block1_conv1 shape: (1, 336, 512, 64) min: 0.0 max: 835.5256 mean: 33.97525 block2_conv1 shape: (1, 168, 256, 128) min: 0.0 max: 4625.8857 mean: 199.82687 block3_conv1 shape: (1, 84, 128, 256) min: 0.0 max: 8789.239 mean: 230.78099 block4_conv1 shape: (1, 42, 64, 512) min: 0.0 max: 21566.135 mean: 791.24005 block5_conv1 shape: (1, 21, 32, 512) min: 0.0 max: 3189.2542 mean: 59.179478
محاسبه سبک
محتوای یک تصویر با مقادیر نقشه های ویژگی میانی نشان داده می شود.
به نظر می رسد، سبک یک تصویر را می توان با ابزارها و همبستگی ها در بین نقشه های ویژگی های مختلف توصیف کرد. ماتریس گرمی را که شامل این اطلاعات است، با گرفتن حاصل ضرب بیرونی بردار ویژگی با خود در هر مکان، و میانگین گرفتن آن محصول بیرونی در همه مکانها، محاسبه کنید. این ماتریس گرم را می توان برای یک لایه خاص به صورت زیر محاسبه کرد:
\[G^l_{cd} = \frac{\sum_{ij} F^l_{ijc}(x)F^l_{ijd}(x)}{IJ}\]
این را می توان به طور خلاصه با استفاده از تابع tf.linalg.einsum پیاده سازی کرد:
def gram_matrix(input_tensor):
result = tf.linalg.einsum('bijc,bijd->bcd', input_tensor, input_tensor)
input_shape = tf.shape(input_tensor)
num_locations = tf.cast(input_shape[1]*input_shape[2], tf.float32)
return result/(num_locations)
سبک و محتوا را استخراج کنید
مدلی بسازید که سبک و تانسور محتوا را برمی گرداند.
class StyleContentModel(tf.keras.models.Model):
def __init__(self, style_layers, content_layers):
super(StyleContentModel, self).__init__()
self.vgg = vgg_layers(style_layers + content_layers)
self.style_layers = style_layers
self.content_layers = content_layers
self.num_style_layers = len(style_layers)
self.vgg.trainable = False
def call(self, inputs):
"Expects float input in [0,1]"
inputs = inputs*255.0
preprocessed_input = tf.keras.applications.vgg19.preprocess_input(inputs)
outputs = self.vgg(preprocessed_input)
style_outputs, content_outputs = (outputs[:self.num_style_layers],
outputs[self.num_style_layers:])
style_outputs = [gram_matrix(style_output)
for style_output in style_outputs]
content_dict = {content_name: value
for content_name, value
in zip(self.content_layers, content_outputs)}
style_dict = {style_name: value
for style_name, value
in zip(self.style_layers, style_outputs)}
return {'content': content_dict, 'style': style_dict}
وقتی روی یک تصویر فراخوانی میشود، این مدل ماتریس گرم (سبک) style_layers و محتوای لایههای content را content_layers :
extractor = StyleContentModel(style_layers, content_layers)
results = extractor(tf.constant(content_image))
print('Styles:')
for name, output in sorted(results['style'].items()):
print(" ", name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
print()
print("Contents:")
for name, output in sorted(results['content'].items()):
print(" ", name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
Styles:
block1_conv1
shape: (1, 64, 64)
min: 0.0055228462
max: 28014.557
mean: 263.79022
block2_conv1
shape: (1, 128, 128)
min: 0.0
max: 61479.496
mean: 9100.949
block3_conv1
shape: (1, 256, 256)
min: 0.0
max: 545623.44
mean: 7660.976
block4_conv1
shape: (1, 512, 512)
min: 0.0
max: 4320502.0
mean: 134288.84
block5_conv1
shape: (1, 512, 512)
min: 0.0
max: 110005.37
mean: 1487.0378
Contents:
block5_conv2
shape: (1, 26, 32, 512)
min: 0.0
max: 2410.8796
mean: 13.764149
نزول گرادیان را اجرا کنید
با این استخراج کننده سبک و محتوا، اکنون می توانید الگوریتم انتقال سبک را پیاده سازی کنید. این کار را با محاسبه میانگین مربع خطا برای خروجی تصویر نسبت به هر هدف انجام دهید، سپس مجموع وزنی این تلفات را بگیرید.
مقادیر هدف سبک و محتوای خود را تنظیم کنید:
style_targets = extractor(style_image)['style']
content_targets = extractor(content_image)['content']
یک tf.Variable برای بهینه سازی تصویر تعریف کنید. برای انجام این کار سریع، آن را با تصویر محتوا مقداردهی اولیه کنید ( tf.Variable باید همان شکل تصویر محتوا باشد):
image = tf.Variable(content_image)
از آنجایی که این یک تصویر شناور است، تابعی را برای حفظ مقادیر پیکسل بین 0 و 1 تعریف کنید:
def clip_0_1(image):
return tf.clip_by_value(image, clip_value_min=0.0, clip_value_max=1.0)
یک بهینه ساز ایجاد کنید. مقاله LBFGS را توصیه می کند، اما Adam نیز خوب کار می کند:
opt = tf.optimizers.Adam(learning_rate=0.02, beta_1=0.99, epsilon=1e-1)
برای بهینه سازی این، از ترکیب وزنی از دو ضرر استفاده کنید تا کل ضرر را بدست آورید:
style_weight=1e-2
content_weight=1e4
def style_content_loss(outputs):
style_outputs = outputs['style']
content_outputs = outputs['content']
style_loss = tf.add_n([tf.reduce_mean((style_outputs[name]-style_targets[name])**2)
for name in style_outputs.keys()])
style_loss *= style_weight / num_style_layers
content_loss = tf.add_n([tf.reduce_mean((content_outputs[name]-content_targets[name])**2)
for name in content_outputs.keys()])
content_loss *= content_weight / num_content_layers
loss = style_loss + content_loss
return loss
برای به روز رسانی تصویر از tf.GradientTape استفاده کنید.
@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
outputs = extractor(image)
loss = style_content_loss(outputs)
grad = tape.gradient(loss, image)
opt.apply_gradients([(grad, image)])
image.assign(clip_0_1(image))
اکنون چند مرحله را برای تست انجام دهید:
train_step(image)
train_step(image)
train_step(image)
tensor_to_image(image)

از آنجایی که کار می کند، بهینه سازی طولانی تری انجام دهید:
import time
start = time.time()
epochs = 10
steps_per_epoch = 100
step = 0
for n in range(epochs):
for m in range(steps_per_epoch):
step += 1
train_step(image)
print(".", end='', flush=True)
display.clear_output(wait=True)
display.display(tensor_to_image(image))
print("Train step: {}".format(step))
end = time.time()
print("Total time: {:.1f}".format(end-start))

Train step: 1000 Total time: 21.3
از دست دادن کل تغییرات
یکی از نکات منفی این پیاده سازی اساسی این است که مصنوعات فرکانس بالایی تولید می کند. این موارد را با استفاده از یک عبارت منظم سازی صریح در اجزای فرکانس بالای تصویر کاهش دهید. در انتقال سبک، اغلب به این افت تغییرات کل گفته می شود:
def high_pass_x_y(image):
x_var = image[:, :, 1:, :] - image[:, :, :-1, :]
y_var = image[:, 1:, :, :] - image[:, :-1, :, :]
return x_var, y_var
x_deltas, y_deltas = high_pass_x_y(content_image)
plt.figure(figsize=(14, 10))
plt.subplot(2, 2, 1)
imshow(clip_0_1(2*y_deltas+0.5), "Horizontal Deltas: Original")
plt.subplot(2, 2, 2)
imshow(clip_0_1(2*x_deltas+0.5), "Vertical Deltas: Original")
x_deltas, y_deltas = high_pass_x_y(image)
plt.subplot(2, 2, 3)
imshow(clip_0_1(2*y_deltas+0.5), "Horizontal Deltas: Styled")
plt.subplot(2, 2, 4)
imshow(clip_0_1(2*x_deltas+0.5), "Vertical Deltas: Styled")
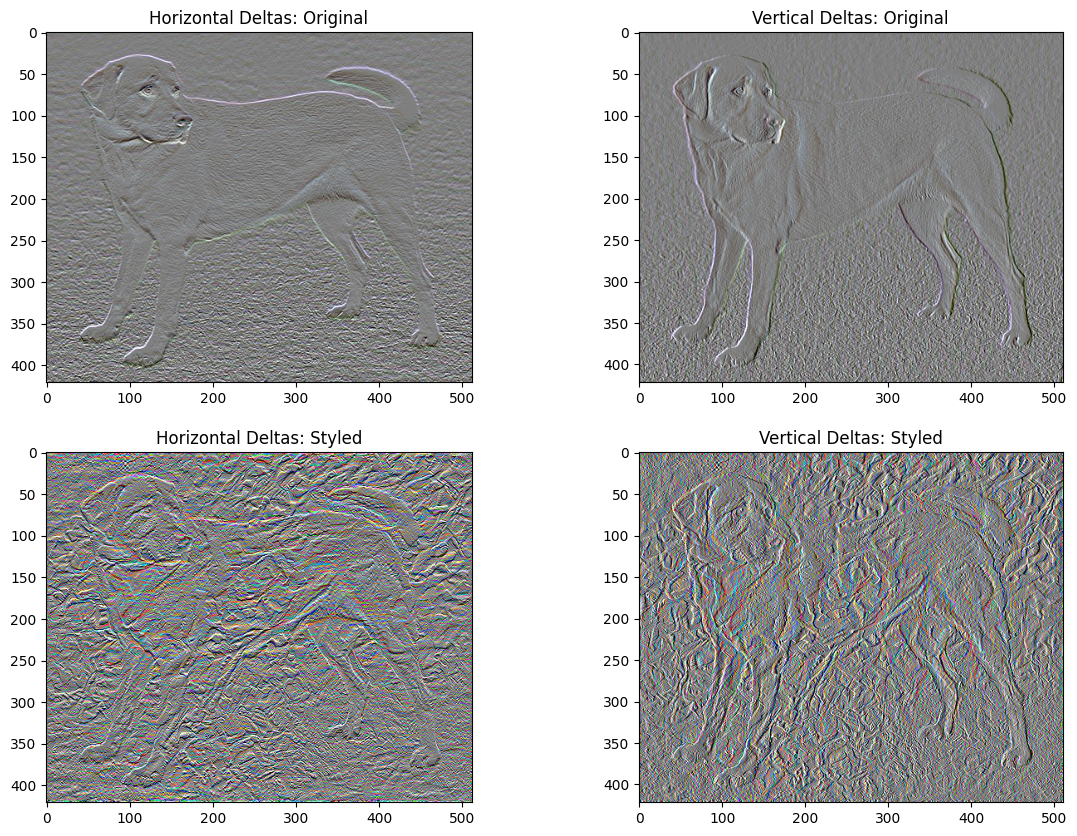
این نشان می دهد که چگونه مولفه های فرکانس بالا افزایش یافته اند.
همچنین، این جزء فرکانس بالا اساسا یک آشکارساز لبه است. می توانید خروجی مشابهی را از آشکارساز لبه Sobel دریافت کنید، به عنوان مثال:
plt.figure(figsize=(14, 10))
sobel = tf.image.sobel_edges(content_image)
plt.subplot(1, 2, 1)
imshow(clip_0_1(sobel[..., 0]/4+0.5), "Horizontal Sobel-edges")
plt.subplot(1, 2, 2)
imshow(clip_0_1(sobel[..., 1]/4+0.5), "Vertical Sobel-edges")
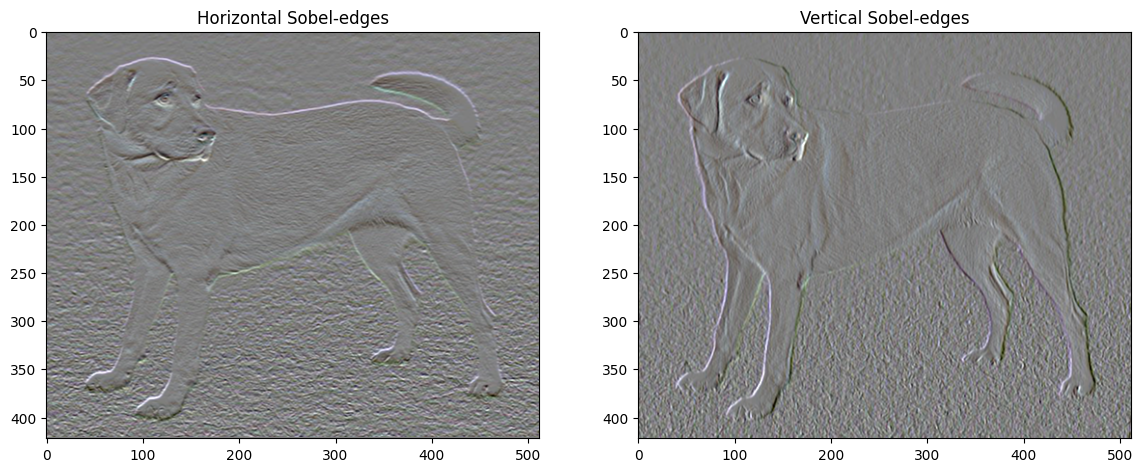
از دست دادن منظم مرتبط با این مجموع مجذور مقادیر است:
def total_variation_loss(image):
x_deltas, y_deltas = high_pass_x_y(image)
return tf.reduce_sum(tf.abs(x_deltas)) + tf.reduce_sum(tf.abs(y_deltas))
total_variation_loss(image).numpy()
149402.94
این نشان داد که چه کاری انجام می دهد. اما نیازی نیست خودتان آن را پیاده سازی کنید، TensorFlow شامل یک پیاده سازی استاندارد است:
tf.image.total_variation(image).numpy()
array([149402.94], dtype=float32)
بهینه سازی را دوباره اجرا کنید
وزنی را برای total_variation_loss انتخاب کنید:
total_variation_weight=30
اکنون آن را در تابع train_step :
@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
outputs = extractor(image)
loss = style_content_loss(outputs)
loss += total_variation_weight*tf.image.total_variation(image)
grad = tape.gradient(loss, image)
opt.apply_gradients([(grad, image)])
image.assign(clip_0_1(image))
متغیر بهینه سازی را مجدداً شروع کنید:
image = tf.Variable(content_image)
و بهینه سازی را اجرا کنید:
import time
start = time.time()
epochs = 10
steps_per_epoch = 100
step = 0
for n in range(epochs):
for m in range(steps_per_epoch):
step += 1
train_step(image)
print(".", end='', flush=True)
display.clear_output(wait=True)
display.display(tensor_to_image(image))
print("Train step: {}".format(step))
end = time.time()
print("Total time: {:.1f}".format(end-start))

Train step: 1000 Total time: 22.4
در نهایت، نتیجه را ذخیره کنید:
file_name = 'stylized-image.png'
tensor_to_image(image).save(file_name)
try:
from google.colab import files
except ImportError:
pass
else:
files.download(file_name)
بیشتر بدانید
این آموزش الگوریتم اصلی انتقال سبک را نشان می دهد. برای کاربرد ساده انتقال سبک، این آموزش را بررسی کنید تا درباره نحوه استفاده از مدل انتقال سبک تصویر دلخواه از TensorFlow Hub بیشتر بدانید.