
| | |  عرض على جيثب عرض على جيثب | | |
يستخدم هذا البرنامج التعليمي التعلم العميق لتكوين صورة واحدة بأسلوب صورة أخرى (هل تتمنى أن ترسم مثل بيكاسو أو فان جوخ؟). يُعرف هذا باسم نقل النمط العصبي وقد تم تحديد التقنية في A Neural Algorithm of Artistic Style (Gatys et al.).
للحصول على تطبيق بسيط لنقل النمط ، راجع هذا البرنامج التعليمي لمعرفة المزيد حول كيفية استخدام نموذج Stylization الصورة التعسفي الذي تم اختباره مسبقًا من TensorFlow Hub أو كيفية استخدام نموذج نقل النمط مع TensorFlow Lite .
يُعد نقل النمط العصبي تقنية تحسين تُستخدم لالتقاط صورتين - صورة محتوى وصورة مرجعية للنمط (مثل عمل فني لرسام مشهور) - ودمجهما معًا بحيث تبدو الصورة الناتجة مثل صورة المحتوى ، ولكن "مرسومة" في نمط الصورة المرجعية للنمط.
يتم تنفيذ ذلك عن طريق تحسين صورة الإخراج لمطابقة إحصائيات محتوى صورة المحتوى وإحصائيات النمط للصورة المرجعية للنمط. يتم استخراج هذه الإحصائيات من الصور باستخدام شبكة تلافيفية.
على سبيل المثال ، لنأخذ صورة لهذا الكلب والتكوين 7 لفاسيلي كاندينسكي:

Yellow Labrador looking ، من ويكيميديا كومنز بواسطة Elf . الترخيص CC BY-SA 3.0
{kind=link}

الآن كيف سيبدو الأمر إذا قرر كاندينسكي رسم صورة هذا الكلب حصريًا بهذا الأسلوب؟ شيء من هذا القبيل؟

يثبت
استيراد الوحدات وتكوينها
import os
import tensorflow as tf
# Load compressed models from tensorflow_hub
os.environ['TFHUB_MODEL_LOAD_FORMAT'] = 'COMPRESSED'
import IPython.display as display
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['figure.figsize'] = (12, 12)
mpl.rcParams['axes.grid'] = False
import numpy as np
import PIL.Image
import time
import functools
def tensor_to_image(tensor):
tensor = tensor*255
tensor = np.array(tensor, dtype=np.uint8)
if np.ndim(tensor)>3:
assert tensor.shape[0] == 1
tensor = tensor[0]
return PIL.Image.fromarray(tensor)
تنزيل الصور واختيار نمط الصورة وصورة المحتوى:
content_path = tf.keras.utils.get_file('YellowLabradorLooking_new.jpg', 'https://storage.googleapis.com/download.tensorflow.org/example_images/YellowLabradorLooking_new.jpg')
style_path = tf.keras.utils.get_file('kandinsky5.jpg','https://storage.googleapis.com/download.tensorflow.org/example_images/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg')
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/Vassily_Kandinsky%2C_1913_-_Composition_7.jpg 196608/195196 [==============================] - 0s 0us/step 204800/195196 [===============================] - 0s 0us/step
تصور المدخلات
حدد وظيفة لتحميل صورة وقصر أبعادها القصوى على 512 بكسل.
def load_img(path_to_img):
max_dim = 512
img = tf.io.read_file(path_to_img)
img = tf.image.decode_image(img, channels=3)
img = tf.image.convert_image_dtype(img, tf.float32)
shape = tf.cast(tf.shape(img)[:-1], tf.float32)
long_dim = max(shape)
scale = max_dim / long_dim
new_shape = tf.cast(shape * scale, tf.int32)
img = tf.image.resize(img, new_shape)
img = img[tf.newaxis, :]
return img
قم بإنشاء وظيفة بسيطة لعرض صورة:
def imshow(image, title=None):
if len(image.shape) > 3:
image = tf.squeeze(image, axis=0)
plt.imshow(image)
if title:
plt.title(title)
content_image = load_img(content_path)
style_image = load_img(style_path)
plt.subplot(1, 2, 1)
imshow(content_image, 'Content Image')
plt.subplot(1, 2, 2)
imshow(style_image, 'Style Image')

نقل سريع للنمط باستخدام TF-Hub
يوضح هذا البرنامج التعليمي خوارزمية نقل النمط الأصلية ، والتي تعمل على تحسين محتوى الصورة إلى نمط معين. قبل الدخول في التفاصيل ، دعنا نرى كيف يقوم نموذج TensorFlow Hub بهذا:
import tensorflow_hub as hub
hub_model = hub.load('https://tfhub.dev/google/magenta/arbitrary-image-stylization-v1-256/2')
stylized_image = hub_model(tf.constant(content_image), tf.constant(style_image))[0]
tensor_to_image(stylized_image)

تحديد تمثيلات المحتوى والأسلوب
استخدم الطبقات الوسيطة للنموذج للحصول على المحتوى وتمثيل النمط للصورة. بدءًا من طبقة إدخال الشبكة ، تمثل عمليات تنشيط الطبقة القليلة الأولى ميزات منخفضة المستوى مثل الحواف والأنسجة. أثناء التنقل عبر الشبكة ، تمثل الطبقات القليلة الأخيرة ميزات ذات مستوى أعلى - أجزاء كائن مثل العجلات أو العيون . في هذه الحالة ، فأنت تستخدم بنية شبكة VGG19 ، وهي شبكة مصنفة مسبقًا لتصنيف الصور. هذه الطبقات الوسيطة ضرورية لتحديد تمثيل المحتوى والأسلوب من الصور. بالنسبة لصورة الإدخال ، حاول مطابقة النمط المقابل وتمثيلات هدف المحتوى في هذه الطبقات الوسيطة.
قم بتحميل VGG19 واختبر تشغيله على صورتنا للتأكد من استخدامها بشكل صحيح:
x = tf.keras.applications.vgg19.preprocess_input(content_image*255)
x = tf.image.resize(x, (224, 224))
vgg = tf.keras.applications.VGG19(include_top=True, weights='imagenet')
prediction_probabilities = vgg(x)
prediction_probabilities.shape
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg19/vgg19_weights_tf_dim_ordering_tf_kernels.h5 574717952/574710816 [==============================] - 17s 0us/step 574726144/574710816 [==============================] - 17s 0us/step TensorShape([1, 1000])
predicted_top_5 = tf.keras.applications.vgg19.decode_predictions(prediction_probabilities.numpy())[0]
[(class_name, prob) for (number, class_name, prob) in predicted_top_5]
[('Labrador_retriever', 0.493171),
('golden_retriever', 0.2366529),
('kuvasz', 0.036357544),
('Chesapeake_Bay_retriever', 0.024182785),
('Greater_Swiss_Mountain_dog', 0.0186461)]
الآن قم بتحميل VGG19 بدون رأس التصنيف ، وقم بإدراج أسماء الطبقات
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
print()
for layer in vgg.layers:
print(layer.name)
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg19/vgg19_weights_tf_dim_ordering_tf_kernels_notop.h5 80142336/80134624 [==============================] - 2s 0us/step 80150528/80134624 [==============================] - 2s 0us/step input_2 block1_conv1 block1_conv2 block1_pool block2_conv1 block2_conv2 block2_pool block3_conv1 block3_conv2 block3_conv3 block3_conv4 block3_pool block4_conv1 block4_conv2 block4_conv3 block4_conv4 block4_pool block5_conv1 block5_conv2 block5_conv3 block5_conv4 block5_pool
اختر طبقات وسيطة من الشبكة لتمثيل نمط ومحتوى الصورة:
content_layers = ['block5_conv2']
style_layers = ['block1_conv1',
'block2_conv1',
'block3_conv1',
'block4_conv1',
'block5_conv1']
num_content_layers = len(content_layers)
num_style_layers = len(style_layers)
طبقات وسيطة للأسلوب والمحتوى
فلماذا تسمح لنا هذه المخرجات الوسيطة داخل شبكة تصنيف الصور لدينا بتحديد الأسلوب وتمثيل المحتوى؟
على مستوى عالٍ ، لكي تقوم الشبكة بإجراء تصنيف للصور (وهو ما تم تدريب هذه الشبكة على القيام به) ، يجب أن تفهم الصورة. يتطلب هذا أخذ الصورة الأولية كوحدات بكسل إدخال وبناء تمثيل داخلي يحول بيكسلات الصورة الأولية إلى فهم معقد للميزات الموجودة داخل الصورة.
وهذا أيضًا سبب يجعل الشبكات العصبية التلافيفية قادرة على التعميم جيدًا: فهي قادرة على التقاط الثوابت وتحديد السمات داخل الفئات (مثل القطط مقابل الكلاب) التي لا تعرف ضجيج الخلفية والمضايقات الأخرى. وبالتالي ، في مكان ما بين مكان إدخال الصورة الأولية في النموذج وعلامة تصنيف الإخراج ، يعمل النموذج كمستخرج ميزة معقدة. من خلال الوصول إلى الطبقات الوسيطة للنموذج ، يمكنك وصف محتوى وأسلوب الصور المدخلة.
بناء النموذج
تم تصميم الشبكات في tf.keras.applications بحيث يمكنك بسهولة استخراج قيم الطبقة المتوسطة باستخدام واجهة برمجة تطبيقات Keras الوظيفية.
لتحديد نموذج باستخدام واجهة برمجة التطبيقات الوظيفية ، حدد المدخلات والمخرجات:
model = Model(inputs, outputs)
تعمل هذه الوظيفة التالية على إنشاء نموذج VGG19 يقوم بإرجاع قائمة مخرجات الطبقة المتوسطة:
def vgg_layers(layer_names):
""" Creates a vgg model that returns a list of intermediate output values."""
# Load our model. Load pretrained VGG, trained on imagenet data
vgg = tf.keras.applications.VGG19(include_top=False, weights='imagenet')
vgg.trainable = False
outputs = [vgg.get_layer(name).output for name in layer_names]
model = tf.keras.Model([vgg.input], outputs)
return model
ولإنشاء النموذج:
style_extractor = vgg_layers(style_layers)
style_outputs = style_extractor(style_image*255)
#Look at the statistics of each layer's output
for name, output in zip(style_layers, style_outputs):
print(name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
print()
block1_conv1 shape: (1, 336, 512, 64) min: 0.0 max: 835.5256 mean: 33.97525 block2_conv1 shape: (1, 168, 256, 128) min: 0.0 max: 4625.8857 mean: 199.82687 block3_conv1 shape: (1, 84, 128, 256) min: 0.0 max: 8789.239 mean: 230.78099 block4_conv1 shape: (1, 42, 64, 512) min: 0.0 max: 21566.135 mean: 791.24005 block5_conv1 shape: (1, 21, 32, 512) min: 0.0 max: 3189.2542 mean: 59.179478
حساب النمط
يتم تمثيل محتوى الصورة بقيم خرائط المعالم الوسيطة.
اتضح ، يمكن وصف نمط الصورة بالوسائل والارتباطات عبر خرائط المعالم المختلفة. احسب مصفوفة جرام تتضمن هذه المعلومات عن طريق أخذ المنتج الخارجي لمتجه المعالم مع نفسه في كل موقع ، وحساب متوسط هذا المنتج الخارجي على جميع المواقع. يمكن حساب مصفوفة الجرام هذه لطبقة معينة على النحو التالي:
\[G^l_{cd} = \frac{\sum_{ij} F^l_{ijc}(x)F^l_{ijd}(x)}{IJ}\]
يمكن تنفيذ ذلك بإيجاز باستخدام وظيفة tf.linalg.einsum :
def gram_matrix(input_tensor):
result = tf.linalg.einsum('bijc,bijd->bcd', input_tensor, input_tensor)
input_shape = tf.shape(input_tensor)
num_locations = tf.cast(input_shape[1]*input_shape[2], tf.float32)
return result/(num_locations)
استخراج النمط والمحتوى
قم ببناء نموذج يُرجع النمط وموترات المحتوى.
class StyleContentModel(tf.keras.models.Model):
def __init__(self, style_layers, content_layers):
super(StyleContentModel, self).__init__()
self.vgg = vgg_layers(style_layers + content_layers)
self.style_layers = style_layers
self.content_layers = content_layers
self.num_style_layers = len(style_layers)
self.vgg.trainable = False
def call(self, inputs):
"Expects float input in [0,1]"
inputs = inputs*255.0
preprocessed_input = tf.keras.applications.vgg19.preprocess_input(inputs)
outputs = self.vgg(preprocessed_input)
style_outputs, content_outputs = (outputs[:self.num_style_layers],
outputs[self.num_style_layers:])
style_outputs = [gram_matrix(style_output)
for style_output in style_outputs]
content_dict = {content_name: value
for content_name, value
in zip(self.content_layers, content_outputs)}
style_dict = {style_name: value
for style_name, value
in zip(self.style_layers, style_outputs)}
return {'content': content_dict, 'style': style_dict}
عندما يتم استدعاؤها في صورة ما ، يقوم هذا النموذج بإرجاع مصفوفة غرام (النمط) style_layers ومحتوى content_layers :
extractor = StyleContentModel(style_layers, content_layers)
results = extractor(tf.constant(content_image))
print('Styles:')
for name, output in sorted(results['style'].items()):
print(" ", name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
print()
print("Contents:")
for name, output in sorted(results['content'].items()):
print(" ", name)
print(" shape: ", output.numpy().shape)
print(" min: ", output.numpy().min())
print(" max: ", output.numpy().max())
print(" mean: ", output.numpy().mean())
Styles:
block1_conv1
shape: (1, 64, 64)
min: 0.0055228462
max: 28014.557
mean: 263.79022
block2_conv1
shape: (1, 128, 128)
min: 0.0
max: 61479.496
mean: 9100.949
block3_conv1
shape: (1, 256, 256)
min: 0.0
max: 545623.44
mean: 7660.976
block4_conv1
shape: (1, 512, 512)
min: 0.0
max: 4320502.0
mean: 134288.84
block5_conv1
shape: (1, 512, 512)
min: 0.0
max: 110005.37
mean: 1487.0378
Contents:
block5_conv2
shape: (1, 26, 32, 512)
min: 0.0
max: 2410.8796
mean: 13.764149
قم بتشغيل التدرج اللوني
باستخدام هذا النمط ومستخرج المحتوى ، يمكنك الآن تنفيذ خوارزمية نقل النمط. قم بذلك عن طريق حساب متوسط الخطأ التربيعي لإخراج صورتك بالنسبة لكل هدف ، ثم خذ المجموع المرجح لهذه الخسائر.
قم بتعيين النمط والقيم المستهدفة للمحتوى:
style_targets = extractor(style_image)['style']
content_targets = extractor(content_image)['content']
تحديد tf.Variable لاحتواء الصورة لتحسينها. لجعل هذا سريعًا ، tf.Variable باستخدام صورة المحتوى (يجب أن يكون متغير tf بنفس شكل صورة المحتوى):
image = tf.Variable(content_image)
نظرًا لأن هذه صورة عائمة ، حدد وظيفة للحفاظ على قيم البكسل بين 0 و 1:
def clip_0_1(image):
return tf.clip_by_value(image, clip_value_min=0.0, clip_value_max=1.0)
قم بإنشاء مُحسِّن. توصي الورقة بـ LBFGS ، لكن Adam يعمل بشكل جيد أيضًا:
opt = tf.optimizers.Adam(learning_rate=0.02, beta_1=0.99, epsilon=1e-1)
لتحسين ذلك ، استخدم مزيجًا مرجحًا من الخاسرين للحصول على الخسارة الإجمالية:
style_weight=1e-2
content_weight=1e4
def style_content_loss(outputs):
style_outputs = outputs['style']
content_outputs = outputs['content']
style_loss = tf.add_n([tf.reduce_mean((style_outputs[name]-style_targets[name])**2)
for name in style_outputs.keys()])
style_loss *= style_weight / num_style_layers
content_loss = tf.add_n([tf.reduce_mean((content_outputs[name]-content_targets[name])**2)
for name in content_outputs.keys()])
content_loss *= content_weight / num_content_layers
loss = style_loss + content_loss
return loss
استخدم tf.GradientTape لتحديث الصورة.
@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
outputs = extractor(image)
loss = style_content_loss(outputs)
grad = tape.gradient(loss, image)
opt.apply_gradients([(grad, image)])
image.assign(clip_0_1(image))
قم الآن بتنفيذ بعض الخطوات للاختبار:
train_step(image)
train_step(image)
train_step(image)
tensor_to_image(image)

نظرًا لأنه يعمل ، قم بإجراء تحسين أطول:
import time
start = time.time()
epochs = 10
steps_per_epoch = 100
step = 0
for n in range(epochs):
for m in range(steps_per_epoch):
step += 1
train_step(image)
print(".", end='', flush=True)
display.clear_output(wait=True)
display.display(tensor_to_image(image))
print("Train step: {}".format(step))
end = time.time()
print("Total time: {:.1f}".format(end-start))

Train step: 1000 Total time: 21.3
إجمالي خسارة التباين
أحد الجوانب السلبية لهذا التطبيق الأساسي هو أنه ينتج الكثير من القطع الأثرية عالية التردد. قم بتقليل هذه باستخدام مصطلح تنظيم صريح على المكونات عالية التردد للصورة. في نقل النمط ، يُسمى هذا غالبًا بالخسارة الإجمالية للتباين :
def high_pass_x_y(image):
x_var = image[:, :, 1:, :] - image[:, :, :-1, :]
y_var = image[:, 1:, :, :] - image[:, :-1, :, :]
return x_var, y_var
x_deltas, y_deltas = high_pass_x_y(content_image)
plt.figure(figsize=(14, 10))
plt.subplot(2, 2, 1)
imshow(clip_0_1(2*y_deltas+0.5), "Horizontal Deltas: Original")
plt.subplot(2, 2, 2)
imshow(clip_0_1(2*x_deltas+0.5), "Vertical Deltas: Original")
x_deltas, y_deltas = high_pass_x_y(image)
plt.subplot(2, 2, 3)
imshow(clip_0_1(2*y_deltas+0.5), "Horizontal Deltas: Styled")
plt.subplot(2, 2, 4)
imshow(clip_0_1(2*x_deltas+0.5), "Vertical Deltas: Styled")
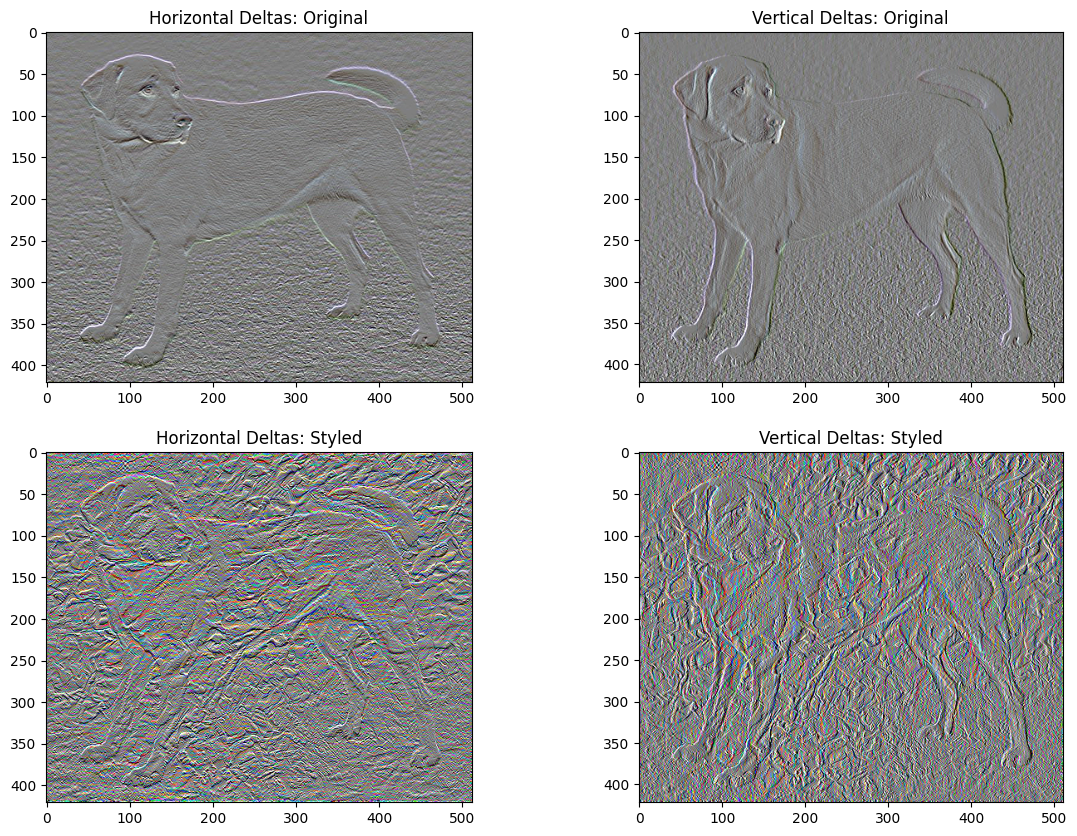
يوضح هذا كيف زادت مكونات التردد العالي.
أيضًا ، هذا المكون عالي التردد هو في الأساس كاشف حافة. يمكنك الحصول على مخرجات مماثلة من كاشف الحواف Sobel ، على سبيل المثال:
plt.figure(figsize=(14, 10))
sobel = tf.image.sobel_edges(content_image)
plt.subplot(1, 2, 1)
imshow(clip_0_1(sobel[..., 0]/4+0.5), "Horizontal Sobel-edges")
plt.subplot(1, 2, 2)
imshow(clip_0_1(sobel[..., 1]/4+0.5), "Vertical Sobel-edges")
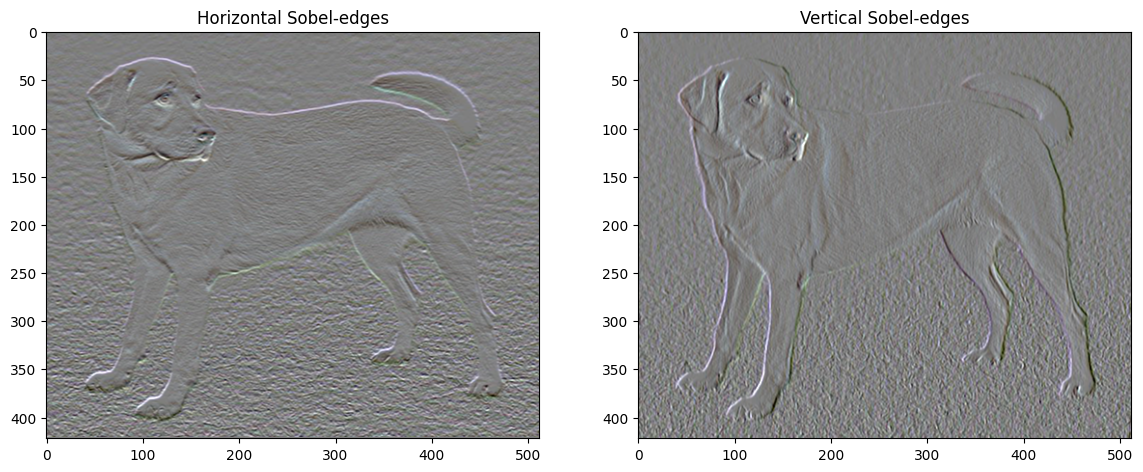
خسارة التنظيم المرتبطة بهذا هي مجموع مربعات القيم:
def total_variation_loss(image):
x_deltas, y_deltas = high_pass_x_y(image)
return tf.reduce_sum(tf.abs(x_deltas)) + tf.reduce_sum(tf.abs(y_deltas))
total_variation_loss(image).numpy()
149402.94
هذا أظهر ما يفعله. ولكن ليست هناك حاجة لتنفيذه بنفسك ، يتضمن TensorFlow تطبيقًا قياسيًا:
tf.image.total_variation(image).numpy()
array([149402.94], dtype=float32)
أعد تشغيل التحسين
اختر وزنًا لـ total_variation_loss :
total_variation_weight=30
قم الآن بتضمينه في وظيفة train_step :
@tf.function()
def train_step(image):
with tf.GradientTape() as tape:
outputs = extractor(image)
loss = style_content_loss(outputs)
loss += total_variation_weight*tf.image.total_variation(image)
grad = tape.gradient(loss, image)
opt.apply_gradients([(grad, image)])
image.assign(clip_0_1(image))
أعد تهيئة متغير التحسين:
image = tf.Variable(content_image)
وقم بتشغيل التحسين:
import time
start = time.time()
epochs = 10
steps_per_epoch = 100
step = 0
for n in range(epochs):
for m in range(steps_per_epoch):
step += 1
train_step(image)
print(".", end='', flush=True)
display.clear_output(wait=True)
display.display(tensor_to_image(image))
print("Train step: {}".format(step))
end = time.time()
print("Total time: {:.1f}".format(end-start))

Train step: 1000 Total time: 22.4
أخيرًا ، احفظ النتيجة:
file_name = 'stylized-image.png'
tensor_to_image(image).save(file_name)
try:
from google.colab import files
except ImportError:
pass
else:
files.download(file_name)
يتعلم أكثر
يوضح هذا البرنامج التعليمي خوارزمية نقل النمط الأصلية. للحصول على تطبيق بسيط لنقل النمط ، راجع هذا البرنامج التعليمي لمعرفة المزيد حول كيفية استخدام نموذج نقل نمط الصورة التعسفي من TensorFlow Hub .