
| | |  Посмотреть исходный код на GitHub Посмотреть исходный код на GitHub | |
В этом руководстве показано, как построить и обучить условную генеративно-состязательную сеть (cGAN) под названием pix2pix, которая изучает сопоставление входных изображений с выходными изображениями, как описано в статье Isola et al. Преобразование изображения в изображение с помощью условных состязательных сетей . (2017). pix2pix не зависит от конкретного приложения — его можно применять для широкого круга задач, включая синтез фотографий из карт меток, создание раскрашенных фотографий из черно-белых изображений, преобразование фотографий Google Maps в аэрофотоснимки и даже преобразование эскизов в фотографии.
В этом примере ваша сеть будет генерировать изображения фасадов зданий, используя базу данных фасадов CMP , предоставленную Центром машинного восприятия при Чешском техническом университете в Праге . Короче говоря, вы будете использовать предварительно обработанную копию этого набора данных, созданную авторами pix2pix.
В pix2pix cGAN вы обрабатываете входные изображения и генерируете соответствующие выходные изображения. cGAN были впервые предложены в условно-генеративных состязательных сетях (Mirza and Osindero, 2014).
Архитектура вашей сети будет содержать:
- Генератор с архитектурой на базе U-Net .
- Дискриминатор, представленный свёрточным классификатором PatchGAN (предложен в статье pix2pix ).
Обратите внимание, что каждая эпоха может занимать около 15 секунд на одном графическом процессоре V100.
Ниже приведены некоторые примеры выходных данных, сгенерированных cGAN pix2pix после обучения в течение 200 эпох на наборе данных фасадов (80 000 шагов).


Импорт TensorFlow и других библиотек
import tensorflow as tf
import os
import pathlib
import time
import datetime
from matplotlib import pyplot as plt
from IPython import display
Загрузите набор данных
Загрузите данные базы данных CMP Facade (30 МБ). Дополнительные наборы данных доступны в том же формате здесь . В Colab вы можете выбрать другие наборы данных из раскрывающегося меню. Обратите внимание, что некоторые другие наборы данных значительно больше ( edges2handbags составляет 8 ГБ).
dataset_name = "facades"
_URL = f'http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/{dataset_name}.tar.gz'
path_to_zip = tf.keras.utils.get_file(
fname=f"{dataset_name}.tar.gz",
origin=_URL,
extract=True)
path_to_zip = pathlib.Path(path_to_zip)
PATH = path_to_zip.parent/dataset_name
Downloading data from http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/facades.tar.gz 30171136/30168306 [==============================] - 19s 1us/step 30179328/30168306 [==============================] - 19s 1us/step
list(PATH.parent.iterdir())
[PosixPath('/home/kbuilder/.keras/datasets/facades.tar.gz'),
PosixPath('/home/kbuilder/.keras/datasets/YellowLabradorLooking_new.jpg'),
PosixPath('/home/kbuilder/.keras/datasets/facades'),
PosixPath('/home/kbuilder/.keras/datasets/mnist.npz')]
Каждое исходное изображение имеет размер 256 x 512 и содержит два изображения размером 256 x 256 :
sample_image = tf.io.read_file(str(PATH / 'train/1.jpg'))
sample_image = tf.io.decode_jpeg(sample_image)
print(sample_image.shape)
(256, 512, 3)
plt.figure()
plt.imshow(sample_image)
<matplotlib.image.AxesImage at 0x7f35a3653c90>
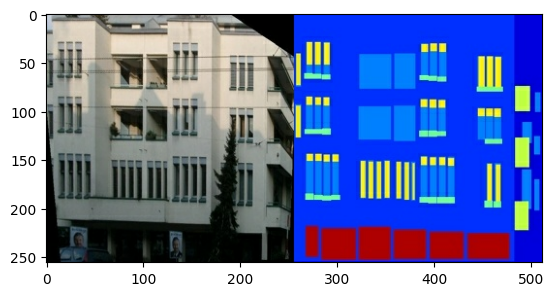
Вам нужно отделить реальные изображения фасадов зданий от изображений архитектурных надписей — все они будут иметь размер 256 x 256 .
Определите функцию, которая загружает файлы изображений и выводит два тензора изображений:
def load(image_file):
# Read and decode an image file to a uint8 tensor
image = tf.io.read_file(image_file)
image = tf.io.decode_jpeg(image)
# Split each image tensor into two tensors:
# - one with a real building facade image
# - one with an architecture label image
w = tf.shape(image)[1]
w = w // 2
input_image = image[:, w:, :]
real_image = image[:, :w, :]
# Convert both images to float32 tensors
input_image = tf.cast(input_image, tf.float32)
real_image = tf.cast(real_image, tf.float32)
return input_image, real_image
Постройте образец входного (изображение архитектурной метки) и реального (фото фасада здания) изображения:
inp, re = load(str(PATH / 'train/100.jpg'))
# Casting to int for matplotlib to display the images
plt.figure()
plt.imshow(inp / 255.0)
plt.figure()
plt.imshow(re / 255.0)
<matplotlib.image.AxesImage at 0x7f35981a4910>
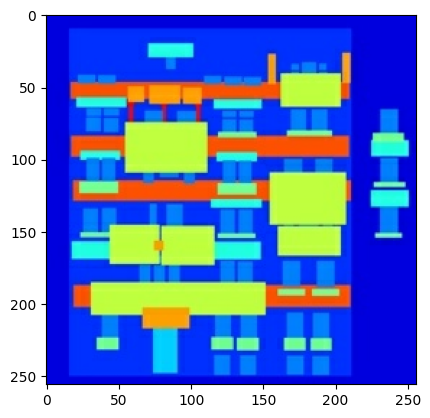
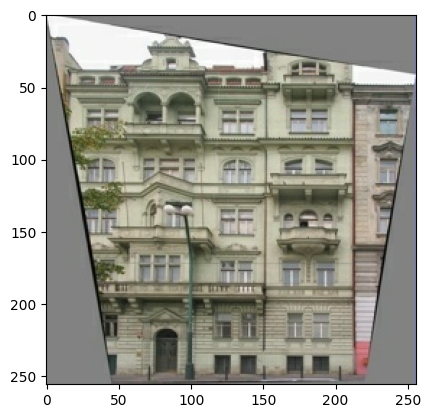
Как описано в статье pix2pix , вам нужно применить случайное дрожание и зеркальное отображение для предварительной обработки обучающего набора.
Определите несколько функций, которые:
- Измените размер каждого изображения
256 x 256на большую высоту и ширину —286 x 286. - Произвольно обрежьте его обратно до
256 x 256. - Произвольное отражение изображения по горизонтали, т.е. слева направо (случайное зеркальное отображение).
- Нормализуйте изображения в диапазоне
[-1, 1].
# The facade training set consist of 400 images
BUFFER_SIZE = 400
# The batch size of 1 produced better results for the U-Net in the original pix2pix experiment
BATCH_SIZE = 1
# Each image is 256x256 in size
IMG_WIDTH = 256
IMG_HEIGHT = 256
def resize(input_image, real_image, height, width):
input_image = tf.image.resize(input_image, [height, width],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
real_image = tf.image.resize(real_image, [height, width],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
return input_image, real_image
def random_crop(input_image, real_image):
stacked_image = tf.stack([input_image, real_image], axis=0)
cropped_image = tf.image.random_crop(
stacked_image, size=[2, IMG_HEIGHT, IMG_WIDTH, 3])
return cropped_image[0], cropped_image[1]
# Normalizing the images to [-1, 1]
def normalize(input_image, real_image):
input_image = (input_image / 127.5) - 1
real_image = (real_image / 127.5) - 1
return input_image, real_image
@tf.function()
def random_jitter(input_image, real_image):
# Resizing to 286x286
input_image, real_image = resize(input_image, real_image, 286, 286)
# Random cropping back to 256x256
input_image, real_image = random_crop(input_image, real_image)
if tf.random.uniform(()) > 0.5:
# Random mirroring
input_image = tf.image.flip_left_right(input_image)
real_image = tf.image.flip_left_right(real_image)
return input_image, real_image
Вы можете проверить часть предварительно обработанного вывода:
plt.figure(figsize=(6, 6))
for i in range(4):
rj_inp, rj_re = random_jitter(inp, re)
plt.subplot(2, 2, i + 1)
plt.imshow(rj_inp / 255.0)
plt.axis('off')
plt.show()
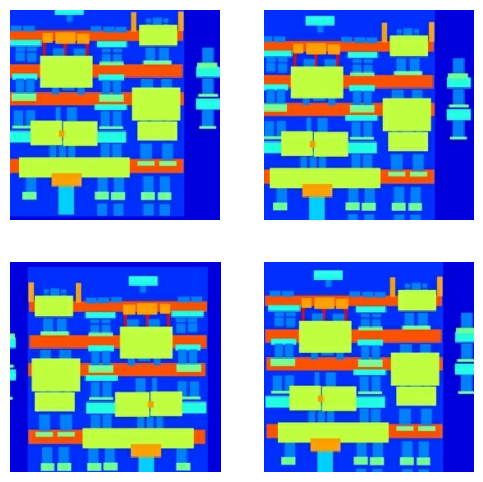
Убедившись, что загрузка и предварительная обработка работают, давайте определим пару вспомогательных функций, которые загружают и предварительно обрабатывают обучающий и тестовый наборы:
def load_image_train(image_file):
input_image, real_image = load(image_file)
input_image, real_image = random_jitter(input_image, real_image)
input_image, real_image = normalize(input_image, real_image)
return input_image, real_image
def load_image_test(image_file):
input_image, real_image = load(image_file)
input_image, real_image = resize(input_image, real_image,
IMG_HEIGHT, IMG_WIDTH)
input_image, real_image = normalize(input_image, real_image)
return input_image, real_image
Создайте конвейер ввода с помощью tf.data
train_dataset = tf.data.Dataset.list_files(str(PATH / 'train/*.jpg'))
train_dataset = train_dataset.map(load_image_train,
num_parallel_calls=tf.data.AUTOTUNE)
train_dataset = train_dataset.shuffle(BUFFER_SIZE)
train_dataset = train_dataset.batch(BATCH_SIZE)
try:
test_dataset = tf.data.Dataset.list_files(str(PATH / 'test/*.jpg'))
except tf.errors.InvalidArgumentError:
test_dataset = tf.data.Dataset.list_files(str(PATH / 'val/*.jpg'))
test_dataset = test_dataset.map(load_image_test)
test_dataset = test_dataset.batch(BATCH_SIZE)
Построить генератор
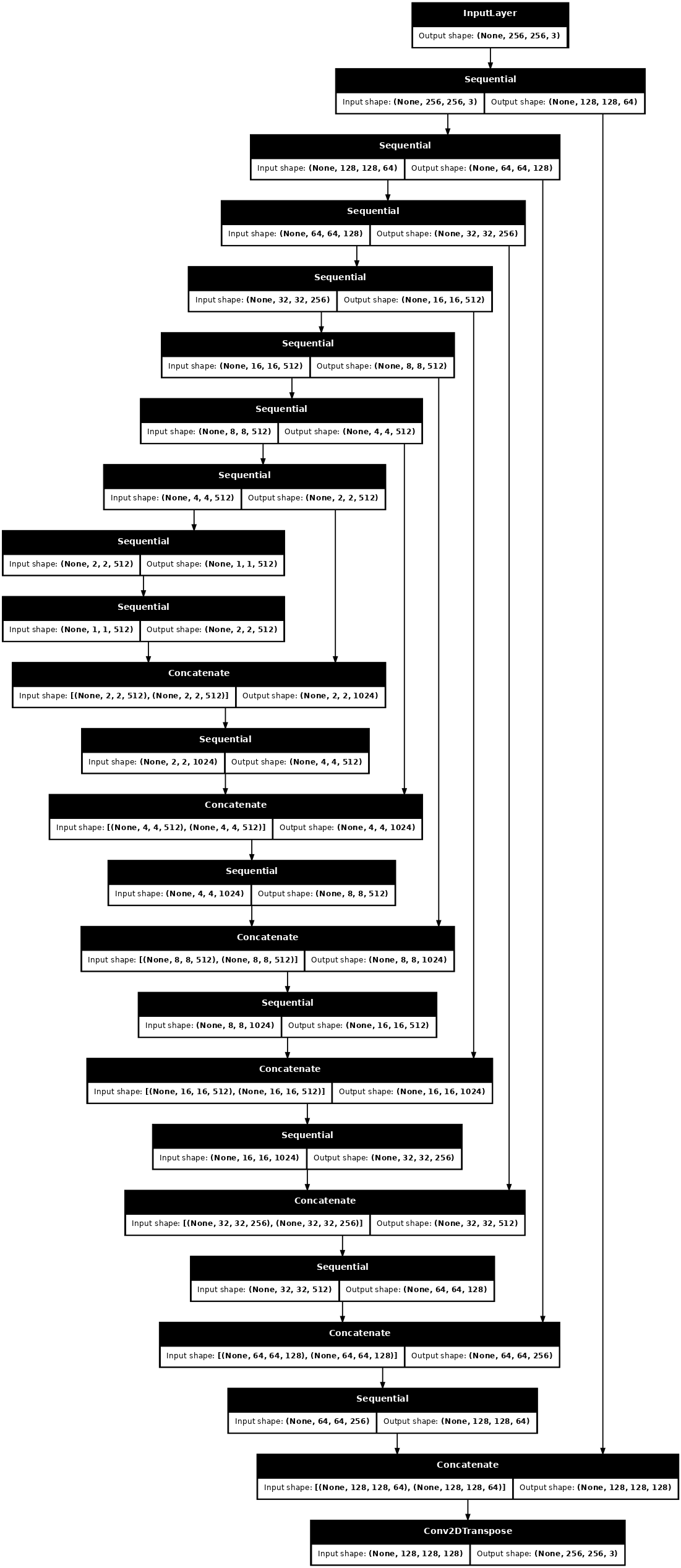
Генератор вашего pix2pix cGAN представляет собой модифицированный U-Net . U-Net состоит из кодера (понижающего дискретизатора) и декодера (апсемплера). (Подробнее об этом можно узнать в туториале по сегментации изображений и на сайте проекта U-Net .)
- Каждый блок в кодировщике: свертка -> нормализация партии -> дырявый ReLU
- Каждый блок в декодере: Транспонированная свертка -> Нормализация партии -> Выпадение (применяется к первым 3 блокам) -> ReLU
- Между энкодером и декодером есть пропускные соединения (как в U-Net).
Определите понижающий дискретизатор (кодер):
OUTPUT_CHANNELS = 3
def downsample(filters, size, apply_batchnorm=True):
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2D(filters, size, strides=2, padding='same',
kernel_initializer=initializer, use_bias=False))
if apply_batchnorm:
result.add(tf.keras.layers.BatchNormalization())
result.add(tf.keras.layers.LeakyReLU())
return result
down_model = downsample(3, 4)
down_result = down_model(tf.expand_dims(inp, 0))
print (down_result.shape)
(1, 128, 128, 3)
Определите повышающий дискретизатор (декодер):
def upsample(filters, size, apply_dropout=False):
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2DTranspose(filters, size, strides=2,
padding='same',
kernel_initializer=initializer,
use_bias=False))
result.add(tf.keras.layers.BatchNormalization())
if apply_dropout:
result.add(tf.keras.layers.Dropout(0.5))
result.add(tf.keras.layers.ReLU())
return result
up_model = upsample(3, 4)
up_result = up_model(down_result)
print (up_result.shape)
(1, 256, 256, 3)
Определите генератор с понижающим дискретизатором и повышающим дискретизатором:
def Generator():
inputs = tf.keras.layers.Input(shape=[256, 256, 3])
down_stack = [
downsample(64, 4, apply_batchnorm=False), # (batch_size, 128, 128, 64)
downsample(128, 4), # (batch_size, 64, 64, 128)
downsample(256, 4), # (batch_size, 32, 32, 256)
downsample(512, 4), # (batch_size, 16, 16, 512)
downsample(512, 4), # (batch_size, 8, 8, 512)
downsample(512, 4), # (batch_size, 4, 4, 512)
downsample(512, 4), # (batch_size, 2, 2, 512)
downsample(512, 4), # (batch_size, 1, 1, 512)
]
up_stack = [
upsample(512, 4, apply_dropout=True), # (batch_size, 2, 2, 1024)
upsample(512, 4, apply_dropout=True), # (batch_size, 4, 4, 1024)
upsample(512, 4, apply_dropout=True), # (batch_size, 8, 8, 1024)
upsample(512, 4), # (batch_size, 16, 16, 1024)
upsample(256, 4), # (batch_size, 32, 32, 512)
upsample(128, 4), # (batch_size, 64, 64, 256)
upsample(64, 4), # (batch_size, 128, 128, 128)
]
initializer = tf.random_normal_initializer(0., 0.02)
last = tf.keras.layers.Conv2DTranspose(OUTPUT_CHANNELS, 4,
strides=2,
padding='same',
kernel_initializer=initializer,
activation='tanh') # (batch_size, 256, 256, 3)
x = inputs
# Downsampling through the model
skips = []
for down in down_stack:
x = down(x)
skips.append(x)
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
x = tf.keras.layers.Concatenate()([x, skip])
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
Визуализируйте архитектуру модели генератора:
generator = Generator()
tf.keras.utils.plot_model(generator, show_shapes=True, dpi=64)
Протестируйте генератор:
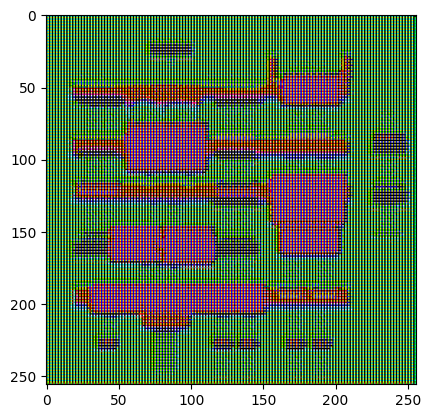
gen_output = generator(inp[tf.newaxis, ...], training=False)
plt.imshow(gen_output[0, ...])
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). <matplotlib.image.AxesImage at 0x7f35cfd20610>
Определите потери генератора
GAN изучают потери, которые адаптируются к данным, в то время как cGAN изучают структурированные потери, которые наказывают возможную структуру, которая отличается от вывода сети и целевого изображения, как описано в статье pix2pix .
- Потеря генератора представляет собой сигмовидную кросс-энтропийную потерю сгенерированных изображений и массива из них .
- В документе pix2pix также упоминается потеря L1, которая представляет собой MAE (средняя абсолютная ошибка) между сгенерированным изображением и целевым изображением.
- Это позволяет сгенерированному изображению стать структурно похожим на целевое изображение.
- Формула для расчета общих потерь генератора:
gan_loss + LAMBDA * l1_loss, гдеLAMBDA = 100. Это значение было определено авторами статьи.
LAMBDA = 100
loss_object = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def generator_loss(disc_generated_output, gen_output, target):
gan_loss = loss_object(tf.ones_like(disc_generated_output), disc_generated_output)
# Mean absolute error
l1_loss = tf.reduce_mean(tf.abs(target - gen_output))
total_gen_loss = gan_loss + (LAMBDA * l1_loss)
return total_gen_loss, gan_loss, l1_loss
Процедура обучения генератора выглядит следующим образом:

Создайте дискриминатор
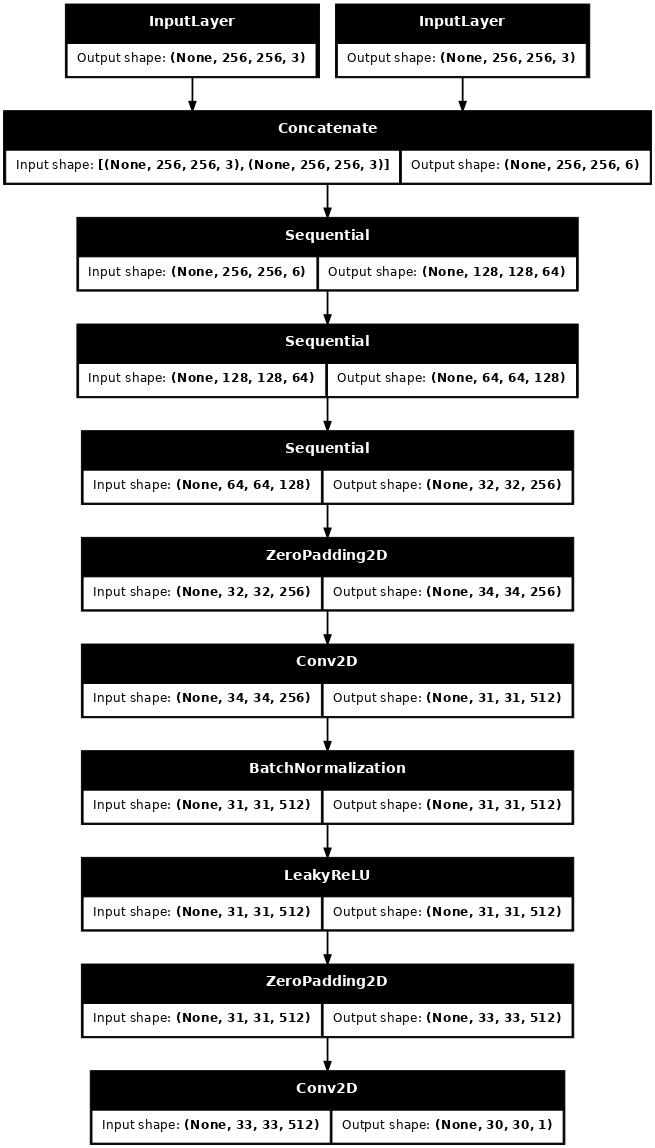
Дискриминатор в pix2pix cGAN представляет собой сверточный классификатор PatchGAN — он пытается классифицировать, является ли каждый фрагмент изображения реальным или нет, как описано в статье pix2pix .
- Каждый блок в дискриминаторе: свертка -> нормализация партии -> дырявый ReLU.
- Форма вывода после последнего слоя
(batch_size, 30, 30, 1). - Каждый фрагмент выходного изображения
30 x 30классифицирует часть входного изображения размером70 x 70. - Дискриминатор получает 2 входа:
- Входное изображение и целевое изображение, которое следует классифицировать как реальное.
- Входное изображение и сгенерированное изображение (выход генератора), которое он должен классифицировать как подделку.
- Используйте
tf.concat([inp, tar], axis=-1), чтобы соединить эти 2 входа вместе.
Определим дискриминатор:
def Discriminator():
initializer = tf.random_normal_initializer(0., 0.02)
inp = tf.keras.layers.Input(shape=[256, 256, 3], name='input_image')
tar = tf.keras.layers.Input(shape=[256, 256, 3], name='target_image')
x = tf.keras.layers.concatenate([inp, tar]) # (batch_size, 256, 256, channels*2)
down1 = downsample(64, 4, False)(x) # (batch_size, 128, 128, 64)
down2 = downsample(128, 4)(down1) # (batch_size, 64, 64, 128)
down3 = downsample(256, 4)(down2) # (batch_size, 32, 32, 256)
zero_pad1 = tf.keras.layers.ZeroPadding2D()(down3) # (batch_size, 34, 34, 256)
conv = tf.keras.layers.Conv2D(512, 4, strides=1,
kernel_initializer=initializer,
use_bias=False)(zero_pad1) # (batch_size, 31, 31, 512)
batchnorm1 = tf.keras.layers.BatchNormalization()(conv)
leaky_relu = tf.keras.layers.LeakyReLU()(batchnorm1)
zero_pad2 = tf.keras.layers.ZeroPadding2D()(leaky_relu) # (batch_size, 33, 33, 512)
last = tf.keras.layers.Conv2D(1, 4, strides=1,
kernel_initializer=initializer)(zero_pad2) # (batch_size, 30, 30, 1)
return tf.keras.Model(inputs=[inp, tar], outputs=last)
Визуализируйте архитектуру модели дискриминатора:
discriminator = Discriminator()
tf.keras.utils.plot_model(discriminator, show_shapes=True, dpi=64)
Протестируйте дискриминатор:
disc_out = discriminator([inp[tf.newaxis, ...], gen_output], training=False)
plt.imshow(disc_out[0, ..., -1], vmin=-20, vmax=20, cmap='RdBu_r')
plt.colorbar()
<matplotlib.colorbar.Colorbar at 0x7f35cec82c50>

Определите потерю дискриминатора
- Функция
discriminator_lossпринимает 2 входа: реальные изображения и сгенерированные изображения . -
real_loss— это сигмовидная кросс-энтропийная потеря реальных изображений и массива единиц (поскольку это настоящие изображения) . -
generated_loss— это сигмовидная кросс-энтропийная потеря сгенерированных изображений и массив нулей (поскольку это поддельные изображения) . -
total_loss— это суммаreal_lossиgenerated_loss.
def discriminator_loss(disc_real_output, disc_generated_output):
real_loss = loss_object(tf.ones_like(disc_real_output), disc_real_output)
generated_loss = loss_object(tf.zeros_like(disc_generated_output), disc_generated_output)
total_disc_loss = real_loss + generated_loss
return total_disc_loss
Процедура обучения дискриминатора показана ниже.
Чтобы узнать больше об архитектуре и гиперпараметрах, вы можете обратиться к документу pix2pix .

Определите оптимизаторы и средство сохранения контрольных точек
generator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
Создание изображений
Напишите функцию для построения изображений во время обучения.
- Передайте изображения из тестового набора в генератор.
- Затем генератор преобразует входное изображение в выходное.
- Последний шаг — построить прогнозы и вуаля !
def generate_images(model, test_input, tar):
prediction = model(test_input, training=True)
plt.figure(figsize=(15, 15))
display_list = [test_input[0], tar[0], prediction[0]]
title = ['Input Image', 'Ground Truth', 'Predicted Image']
for i in range(3):
plt.subplot(1, 3, i+1)
plt.title(title[i])
# Getting the pixel values in the [0, 1] range to plot.
plt.imshow(display_list[i] * 0.5 + 0.5)
plt.axis('off')
plt.show()
Протестируйте функцию:
for example_input, example_target in test_dataset.take(1):
generate_images(generator, example_input, example_target)

Обучение
- Для каждого примера ввод генерирует вывод.
- Дискриминатор получает
input_imageи сгенерированное изображение в качестве первого входа. Второй вход — этоinput_imageиtarget_image. - Затем вычислите потери генератора и дискриминатора.
- Затем вычислите градиенты потерь как для генератора, так и для переменных (входных данных) дискриминатора и примените их к оптимизатору.
- Наконец, зарегистрируйте потери в TensorBoard.
log_dir="logs/"
summary_writer = tf.summary.create_file_writer(
log_dir + "fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
@tf.function
def train_step(input_image, target, step):
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
gen_output = generator(input_image, training=True)
disc_real_output = discriminator([input_image, target], training=True)
disc_generated_output = discriminator([input_image, gen_output], training=True)
gen_total_loss, gen_gan_loss, gen_l1_loss = generator_loss(disc_generated_output, gen_output, target)
disc_loss = discriminator_loss(disc_real_output, disc_generated_output)
generator_gradients = gen_tape.gradient(gen_total_loss,
generator.trainable_variables)
discriminator_gradients = disc_tape.gradient(disc_loss,
discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(generator_gradients,
generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(discriminator_gradients,
discriminator.trainable_variables))
with summary_writer.as_default():
tf.summary.scalar('gen_total_loss', gen_total_loss, step=step//1000)
tf.summary.scalar('gen_gan_loss', gen_gan_loss, step=step//1000)
tf.summary.scalar('gen_l1_loss', gen_l1_loss, step=step//1000)
tf.summary.scalar('disc_loss', disc_loss, step=step//1000)
Собственно тренировочный цикл. Поскольку это руководство может работать с более чем одним набором данных, а наборы данных сильно различаются по размеру, цикл обучения настроен на пошаговую работу, а не на эпохи.
- Итерации по количеству шагов.
- Через каждые 10 шагов выведите точку (
.). - Каждые 1000 шагов: очистите дисплей и запустите
generate_images, чтобы показать прогресс. - Каждые 5к шагов: сохранять контрольную точку.
def fit(train_ds, test_ds, steps):
example_input, example_target = next(iter(test_ds.take(1)))
start = time.time()
for step, (input_image, target) in train_ds.repeat().take(steps).enumerate():
if (step) % 1000 == 0:
display.clear_output(wait=True)
if step != 0:
print(f'Time taken for 1000 steps: {time.time()-start:.2f} sec\n')
start = time.time()
generate_images(generator, example_input, example_target)
print(f"Step: {step//1000}k")
train_step(input_image, target, step)
# Training step
if (step+1) % 10 == 0:
print('.', end='', flush=True)
# Save (checkpoint) the model every 5k steps
if (step + 1) % 5000 == 0:
checkpoint.save(file_prefix=checkpoint_prefix)
Этот цикл обучения сохраняет журналы, которые вы можете просматривать в TensorBoard, чтобы отслеживать ход обучения.
Если вы работаете на локальной машине, вам нужно запустить отдельный процесс TensorBoard. При работе в блокноте запустите просмотрщик перед началом обучения монитору с помощью TensorBoard.
Чтобы запустить просмотрщик, вставьте в ячейку кода следующее:
%load_ext tensorboard
%tensorboard --logdir {log_dir}
Наконец, запустите обучающий цикл:
fit(train_dataset, test_dataset, steps=40000)
Time taken for 1000 steps: 36.53 sec

Step: 39k ....................................................................................................
Если вы хотите опубликовать результаты TensorBoard , вы можете загрузить журналы на TensorBoard.dev , скопировав следующее в ячейку кода.
tensorboard dev upload --logdir {log_dir}
Вы можете просмотреть результаты предыдущего запуска этой записной книжки на TensorBoard.dev .
TensorBoard.dev — это управляемый опыт для размещения, отслеживания и совместного использования экспериментов ML со всеми.
Его также можно включить в строку с помощью <iframe> :
display.IFrame(
src="https://tensorboard.dev/experiment/lZ0C6FONROaUMfjYkVyJqw",
width="100%",
height="1000px")
Интерпретация журналов более тонкая при обучении GAN (или cGAN, например pix2pix) по сравнению с простой моделью классификации или регрессии. Что искать:
- Убедитесь, что ни модель генератора, ни модель дискриминатора не «выиграли». Если либо
gen_gan_lossлибоdisc_lossстановятся очень низкими, это указывает на то, что эта модель доминирует над другой, и вы не успешно обучаете комбинированную модель. - Значение
log(2) = 0.69является хорошей точкой отсчета для этих потерь, поскольку оно указывает на недоумение 2 — дискриминатор в среднем одинаково неуверен в двух вариантах. - Для
disc_lossзначение ниже0.69означает, что дискриминатор работает лучше, чем случайный, в комбинированном наборе реальных и сгенерированных изображений. - Для
gen_gan_lossзначение ниже0.69означает, что генератор лучше, чем случайный, обманывает дискриминатор. - По мере обучения
gen_l1_lossдолжен уменьшаться.
Восстановите последнюю контрольную точку и протестируйте сеть
ls {checkpoint_dir}
checkpoint ckpt-5.data-00000-of-00001 ckpt-1.data-00000-of-00001 ckpt-5.index ckpt-1.index ckpt-6.data-00000-of-00001 ckpt-2.data-00000-of-00001 ckpt-6.index ckpt-2.index ckpt-7.data-00000-of-00001 ckpt-3.data-00000-of-00001 ckpt-7.index ckpt-3.index ckpt-8.data-00000-of-00001 ckpt-4.data-00000-of-00001 ckpt-8.index ckpt-4.index
# Restoring the latest checkpoint in checkpoint_dir
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
<tensorflow.python.training.tracking.util.CheckpointLoadStatus at 0x7f35cfd6b8d0>
Создайте несколько изображений, используя тестовый набор
# Run the trained model on a few examples from the test set
for inp, tar in test_dataset.take(5):
generate_images(generator, inp, tar)




