
| | |  GitHub-এ উৎস দেখুন GitHub-এ উৎস দেখুন | |
এই টিউটোরিয়ালটি দেখায় কিভাবে পিক্স২পিক্স নামক একটি কন্ডিশনাল জেনারেটিভ অ্যাডভারসারিয়াল নেটওয়ার্ক (cGAN) তৈরি এবং প্রশিক্ষিত করা যায় যা ইনপুট ইমেজ থেকে আউটপুট ইমেজে ম্যাপিং শেখে, যেমনটি Isola et al দ্বারা কন্ডিশনাল অ্যাডভারসারিয়াল নেটওয়ার্কের সাথে ইমেজ-টু-ইমেজ অনুবাদে বর্ণনা করা হয়েছে। (2017)। pix2pix অ্যাপ্লিকেশন নির্দিষ্ট নয়—এটি লেবেল মানচিত্র থেকে ফটো সংশ্লেষণ, কালো এবং সাদা ছবি থেকে রঙিন ছবি তৈরি করা, Google মানচিত্রের ফটোগুলিকে বায়বীয় ছবিতে পরিণত করা এবং এমনকি স্কেচগুলিকে ফটোতে রূপান্তর করা সহ বিস্তৃত কাজের জন্য প্রয়োগ করা যেতে পারে।
এই উদাহরণে, আপনার নেটওয়ার্ক প্রাগের চেক টেকনিক্যাল ইউনিভার্সিটিতে সেন্টার ফর মেশিন পারসেপশন দ্বারা প্রদত্ত CMP ফ্যাকেড ডেটাবেস ব্যবহার করে বিল্ডিং ফ্যাসাডের ছবি তৈরি করবে। এটি সংক্ষিপ্ত রাখতে, আপনি pix2pix লেখকদের দ্বারা তৈরি এই ডেটাসেটের একটি প্রি-প্রসেসড কপি ব্যবহার করবেন।
pix2pix cGAN-এ, আপনি ইনপুট চিত্রের উপর শর্ত রাখেন এবং সংশ্লিষ্ট আউটপুট চিত্রগুলি তৈরি করেন। কন্ডিশনাল জেনারেটিভ অ্যাডভারসারিয়াল নেটে (মির্জা এবং ওসিন্ডারো, 2014) সিজিএএনগুলি প্রথম প্রস্তাবিত হয়েছিল
আপনার নেটওয়ার্কের আর্কিটেকচারে থাকবে:
- U-Net- ভিত্তিক আর্কিটেকচার সহ একটি জেনারেটর।
- একটি বৈষম্যমূলক প্যাচগ্যান ক্লাসিফায়ার দ্বারা প্রতিনিধিত্ব করা হয় ( pix2pix কাগজে প্রস্তাবিত)।
মনে রাখবেন যে প্রতিটি যুগ একটি একক V100 GPU-তে প্রায় 15 সেকেন্ড সময় নিতে পারে।
নিচে ফ্যাকাডেস ডেটাসেটে 200টি যুগের জন্য প্রশিক্ষণের পর pix2pix cGAN দ্বারা উত্পন্ন আউটপুটের কিছু উদাহরণ রয়েছে (80k ধাপ)।


TensorFlow এবং অন্যান্য লাইব্রেরি আমদানি করুন
import tensorflow as tf
import os
import pathlib
import time
import datetime
from matplotlib import pyplot as plt
from IPython import display
ডেটাসেট লোড করুন
CMP Facade ডেটাবেস ডেটা (30MB) ডাউনলোড করুন। অতিরিক্ত ডেটাসেটগুলি এখানে একই বিন্যাসে উপলব্ধ। Colab-এ আপনি ড্রপ-ডাউন মেনু থেকে অন্যান্য ডেটাসেট বেছে নিতে পারেন। উল্লেখ্য যে অন্যান্য কিছু ডেটাসেট উল্লেখযোগ্যভাবে বড় ( edges2handbags 8GB)।
dataset_name = "facades"
_URL = f'http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/{dataset_name}.tar.gz'
path_to_zip = tf.keras.utils.get_file(
fname=f"{dataset_name}.tar.gz",
origin=_URL,
extract=True)
path_to_zip = pathlib.Path(path_to_zip)
PATH = path_to_zip.parent/dataset_name
Downloading data from http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/facades.tar.gz 30171136/30168306 [==============================] - 19s 1us/step 30179328/30168306 [==============================] - 19s 1us/step
list(PATH.parent.iterdir())
[PosixPath('/home/kbuilder/.keras/datasets/facades.tar.gz'),
PosixPath('/home/kbuilder/.keras/datasets/YellowLabradorLooking_new.jpg'),
PosixPath('/home/kbuilder/.keras/datasets/facades'),
PosixPath('/home/kbuilder/.keras/datasets/mnist.npz')]
প্রতিটি আসল চিত্র 256 x 512 আকারের যাতে দুটি 256 x 256 চিত্র থাকে:
sample_image = tf.io.read_file(str(PATH / 'train/1.jpg'))
sample_image = tf.io.decode_jpeg(sample_image)
print(sample_image.shape)
(256, 512, 3)
plt.figure()
plt.imshow(sample_image)
<matplotlib.image.AxesImage at 0x7f35a3653c90>
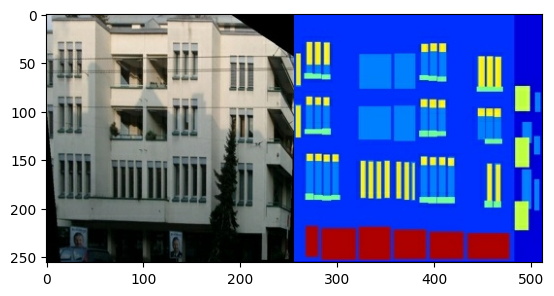
আপনাকে স্থাপত্য লেবেল চিত্রগুলি থেকে বাস্তব বিল্ডিংয়ের সম্মুখের চিত্রগুলিকে আলাদা করতে হবে—যার 256 x 256 আকারের হবে।
একটি ফাংশন সংজ্ঞায়িত করুন যা ইমেজ ফাইল লোড করে এবং দুটি ইমেজ টেনসর আউটপুট করে:
def load(image_file):
# Read and decode an image file to a uint8 tensor
image = tf.io.read_file(image_file)
image = tf.io.decode_jpeg(image)
# Split each image tensor into two tensors:
# - one with a real building facade image
# - one with an architecture label image
w = tf.shape(image)[1]
w = w // 2
input_image = image[:, w:, :]
real_image = image[:, :w, :]
# Convert both images to float32 tensors
input_image = tf.cast(input_image, tf.float32)
real_image = tf.cast(real_image, tf.float32)
return input_image, real_image
ইনপুট (আর্কিটেকচার লেবেল ইমেজ) এবং বাস্তব (বিল্ডিং ফ্যাসাড ফটো) ইমেজের একটি নমুনা প্লট করুন:
inp, re = load(str(PATH / 'train/100.jpg'))
# Casting to int for matplotlib to display the images
plt.figure()
plt.imshow(inp / 255.0)
plt.figure()
plt.imshow(re / 255.0)
<matplotlib.image.AxesImage at 0x7f35981a4910>
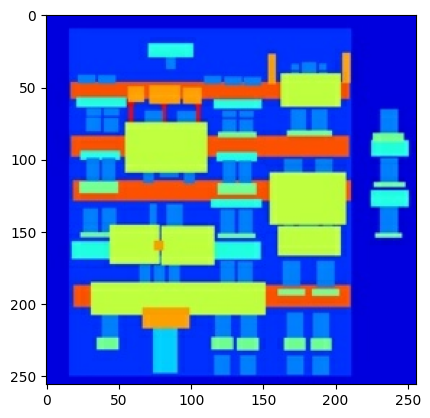
pix2pix পেপারে বর্ণিত হিসাবে, প্রশিক্ষণ সেটটি প্রিপ্রসেস করার জন্য আপনাকে র্যান্ডম জিটারিং এবং মিররিং প্রয়োগ করতে হবে।
বেশ কয়েকটি ফাংশন সংজ্ঞায়িত করুন যা:
- প্রতিটি
256 x 256চিত্রকে একটি বড় উচ্চতা এবং প্রস্থে পুনরায় আকার দিন—286 x 286। - এলোমেলোভাবে এটিকে
256 x 256এ ক্রপ করুন। - এলোমেলোভাবে ছবিটি অনুভূমিকভাবে ফ্লিপ করুন অর্থাৎ বাম থেকে ডানে (এলোমেলো মিররিং)।
- চিত্রগুলিকে
[-1, 1]পরিসরে স্বাভাবিক করুন।
# The facade training set consist of 400 images
BUFFER_SIZE = 400
# The batch size of 1 produced better results for the U-Net in the original pix2pix experiment
BATCH_SIZE = 1
# Each image is 256x256 in size
IMG_WIDTH = 256
IMG_HEIGHT = 256
def resize(input_image, real_image, height, width):
input_image = tf.image.resize(input_image, [height, width],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
real_image = tf.image.resize(real_image, [height, width],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
return input_image, real_image
def random_crop(input_image, real_image):
stacked_image = tf.stack([input_image, real_image], axis=0)
cropped_image = tf.image.random_crop(
stacked_image, size=[2, IMG_HEIGHT, IMG_WIDTH, 3])
return cropped_image[0], cropped_image[1]
# Normalizing the images to [-1, 1]
def normalize(input_image, real_image):
input_image = (input_image / 127.5) - 1
real_image = (real_image / 127.5) - 1
return input_image, real_image
@tf.function()
def random_jitter(input_image, real_image):
# Resizing to 286x286
input_image, real_image = resize(input_image, real_image, 286, 286)
# Random cropping back to 256x256
input_image, real_image = random_crop(input_image, real_image)
if tf.random.uniform(()) > 0.5:
# Random mirroring
input_image = tf.image.flip_left_right(input_image)
real_image = tf.image.flip_left_right(real_image)
return input_image, real_image
আপনি কিছু প্রিপ্রসেসড আউটপুট পরিদর্শন করতে পারেন:
plt.figure(figsize=(6, 6))
for i in range(4):
rj_inp, rj_re = random_jitter(inp, re)
plt.subplot(2, 2, i + 1)
plt.imshow(rj_inp / 255.0)
plt.axis('off')
plt.show()
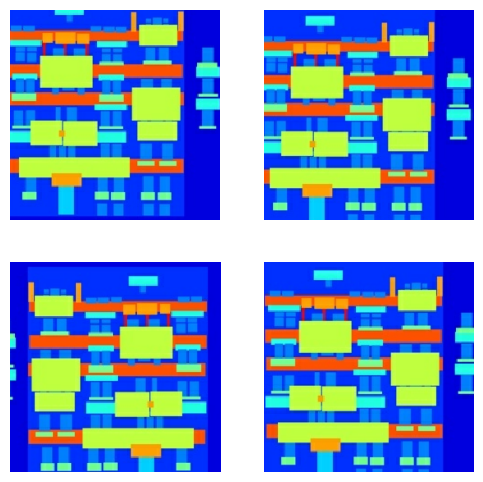
লোডিং এবং প্রিপ্রসেসিং কাজ করে তা পরীক্ষা করে, আসুন কয়েকটি সহায়ক ফাংশন সংজ্ঞায়িত করি যা প্রশিক্ষণ এবং পরীক্ষার সেটগুলিকে লোড এবং প্রিপ্রসেস করে:
def load_image_train(image_file):
input_image, real_image = load(image_file)
input_image, real_image = random_jitter(input_image, real_image)
input_image, real_image = normalize(input_image, real_image)
return input_image, real_image
def load_image_test(image_file):
input_image, real_image = load(image_file)
input_image, real_image = resize(input_image, real_image,
IMG_HEIGHT, IMG_WIDTH)
input_image, real_image = normalize(input_image, real_image)
return input_image, real_image
tf.data দিয়ে একটি ইনপুট পাইপলাইন তৈরি করুন
train_dataset = tf.data.Dataset.list_files(str(PATH / 'train/*.jpg'))
train_dataset = train_dataset.map(load_image_train,
num_parallel_calls=tf.data.AUTOTUNE)
train_dataset = train_dataset.shuffle(BUFFER_SIZE)
train_dataset = train_dataset.batch(BATCH_SIZE)
try:
test_dataset = tf.data.Dataset.list_files(str(PATH / 'test/*.jpg'))
except tf.errors.InvalidArgumentError:
test_dataset = tf.data.Dataset.list_files(str(PATH / 'val/*.jpg'))
test_dataset = test_dataset.map(load_image_test)
test_dataset = test_dataset.batch(BATCH_SIZE)
জেনারেটর তৈরি করুন
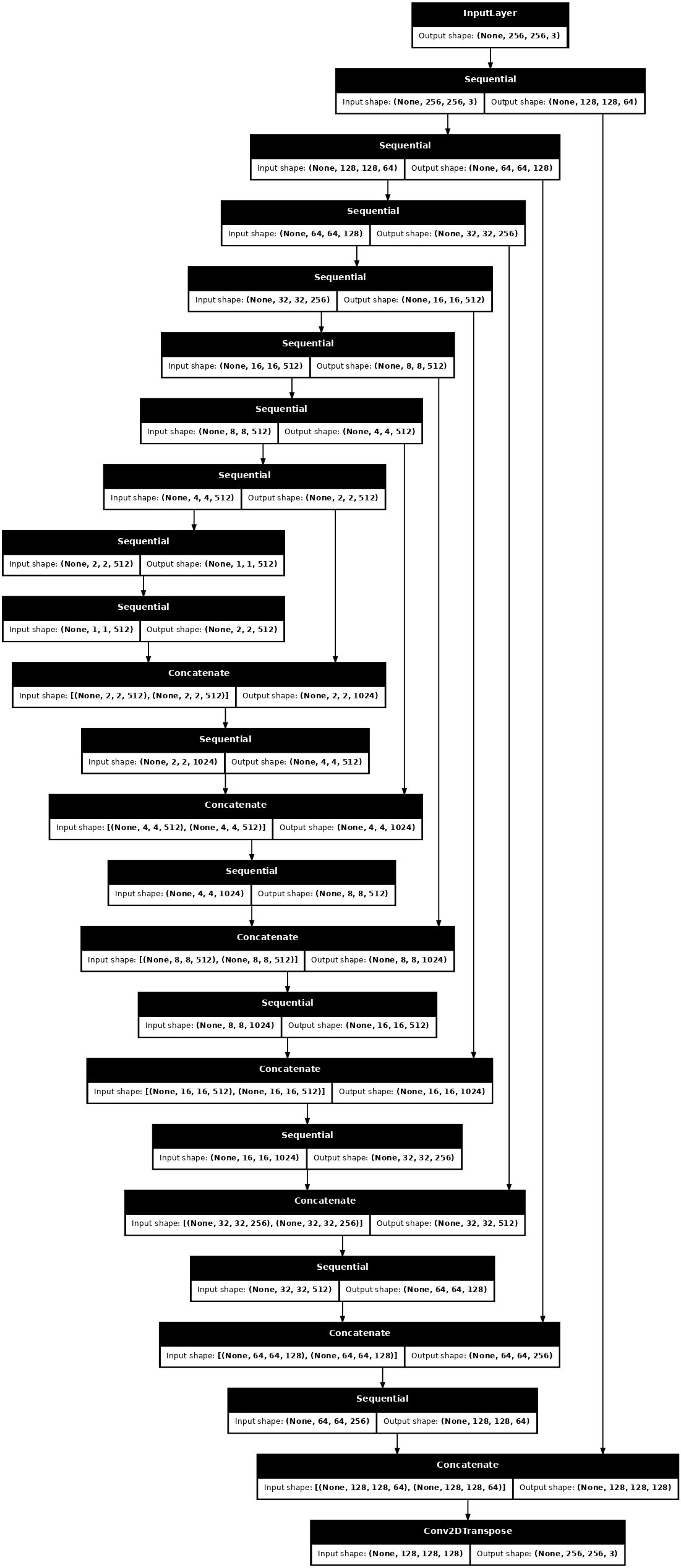
আপনার pix2pix cGAN এর জেনারেটর একটি পরিবর্তিত U-Net । একটি ইউ-নেট একটি এনকোডার (ডাউনস্যাম্পলার) এবং ডিকোডার (আপস্যাম্পলার) নিয়ে গঠিত। (আপনি ইমেজ সেগমেন্টেশন টিউটোরিয়াল এবং U-Net প্রকল্প ওয়েবসাইটে এটি সম্পর্কে আরও জানতে পারেন।)
- এনকোডারের প্রতিটি ব্লক হল: কনভোলিউশন -> ব্যাচ নরমালাইজেশন -> Leaky ReLU
- ডিকোডারের প্রতিটি ব্লক হল: ট্রান্সপোজড কনভোলিউশন -> ব্যাচ নরমালাইজেশন -> ড্রপআউট (প্রথম 3টি ব্লকে প্রযোজ্য) -> ReLU
- এনকোডার এবং ডিকোডারের মধ্যে স্কিপ সংযোগ রয়েছে (যেমন ইউ-নেট)।
ডাউনস্যাম্পলার (এনকোডার) সংজ্ঞায়িত করুন:
OUTPUT_CHANNELS = 3
def downsample(filters, size, apply_batchnorm=True):
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2D(filters, size, strides=2, padding='same',
kernel_initializer=initializer, use_bias=False))
if apply_batchnorm:
result.add(tf.keras.layers.BatchNormalization())
result.add(tf.keras.layers.LeakyReLU())
return result
down_model = downsample(3, 4)
down_result = down_model(tf.expand_dims(inp, 0))
print (down_result.shape)
(1, 128, 128, 3)
আপস্যাম্পলার (ডিকোডার) সংজ্ঞায়িত করুন:
def upsample(filters, size, apply_dropout=False):
initializer = tf.random_normal_initializer(0., 0.02)
result = tf.keras.Sequential()
result.add(
tf.keras.layers.Conv2DTranspose(filters, size, strides=2,
padding='same',
kernel_initializer=initializer,
use_bias=False))
result.add(tf.keras.layers.BatchNormalization())
if apply_dropout:
result.add(tf.keras.layers.Dropout(0.5))
result.add(tf.keras.layers.ReLU())
return result
up_model = upsample(3, 4)
up_result = up_model(down_result)
print (up_result.shape)
(1, 256, 256, 3)
ডাউনস্যাম্পলার এবং আপস্যাম্পলার দিয়ে জেনারেটর সংজ্ঞায়িত করুন:
def Generator():
inputs = tf.keras.layers.Input(shape=[256, 256, 3])
down_stack = [
downsample(64, 4, apply_batchnorm=False), # (batch_size, 128, 128, 64)
downsample(128, 4), # (batch_size, 64, 64, 128)
downsample(256, 4), # (batch_size, 32, 32, 256)
downsample(512, 4), # (batch_size, 16, 16, 512)
downsample(512, 4), # (batch_size, 8, 8, 512)
downsample(512, 4), # (batch_size, 4, 4, 512)
downsample(512, 4), # (batch_size, 2, 2, 512)
downsample(512, 4), # (batch_size, 1, 1, 512)
]
up_stack = [
upsample(512, 4, apply_dropout=True), # (batch_size, 2, 2, 1024)
upsample(512, 4, apply_dropout=True), # (batch_size, 4, 4, 1024)
upsample(512, 4, apply_dropout=True), # (batch_size, 8, 8, 1024)
upsample(512, 4), # (batch_size, 16, 16, 1024)
upsample(256, 4), # (batch_size, 32, 32, 512)
upsample(128, 4), # (batch_size, 64, 64, 256)
upsample(64, 4), # (batch_size, 128, 128, 128)
]
initializer = tf.random_normal_initializer(0., 0.02)
last = tf.keras.layers.Conv2DTranspose(OUTPUT_CHANNELS, 4,
strides=2,
padding='same',
kernel_initializer=initializer,
activation='tanh') # (batch_size, 256, 256, 3)
x = inputs
# Downsampling through the model
skips = []
for down in down_stack:
x = down(x)
skips.append(x)
skips = reversed(skips[:-1])
# Upsampling and establishing the skip connections
for up, skip in zip(up_stack, skips):
x = up(x)
x = tf.keras.layers.Concatenate()([x, skip])
x = last(x)
return tf.keras.Model(inputs=inputs, outputs=x)
জেনারেটর মডেল আর্কিটেকচার কল্পনা করুন:
generator = Generator()
tf.keras.utils.plot_model(generator, show_shapes=True, dpi=64)
জেনারেটর পরীক্ষা করুন:
gen_output = generator(inp[tf.newaxis, ...], training=False)
plt.imshow(gen_output[0, ...])
Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). <matplotlib.image.AxesImage at 0x7f35cfd20610>
জেনারেটরের ক্ষতি সংজ্ঞায়িত করুন
GAN গুলি এমন একটি ক্ষতি শিখে যা ডেটার সাথে খাপ খায়, যখন cGANগুলি একটি কাঠামোগত ক্ষতি শিখে যা একটি সম্ভাব্য কাঠামোকে শাস্তি দেয় যা নেটওয়ার্ক আউটপুট এবং টার্গেট ইমেজ থেকে আলাদা, যেমন pix2pix পেপারে বর্ণিত হয়েছে।
- জেনারেটরের ক্ষতি হল একটি সিগমায়েড ক্রস-এনট্রপি লস জেনারেট করা ছবি এবং একটি অ্যারে ।
- pix2pix পেপারে L1 ক্ষতির কথাও উল্লেখ করা হয়েছে, যা জেনারেট করা ইমেজ এবং টার্গেট ইমেজের মধ্যে একটি MAE (মানে পরম ত্রুটি)।
- এটি তৈরি করা চিত্রটিকে লক্ষ্য চিত্রের মতো কাঠামোগতভাবে অনুরূপ হতে দেয়।
- মোট জেনারেটরের ক্ষতি গণনা করার সূত্রটি হল
gan_loss + LAMBDA * l1_loss, যেখানে LAMBDALAMBDA = 100। এই মানটি কাগজের লেখকদের দ্বারা সিদ্ধান্ত নেওয়া হয়েছিল।
LAMBDA = 100
loss_object = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def generator_loss(disc_generated_output, gen_output, target):
gan_loss = loss_object(tf.ones_like(disc_generated_output), disc_generated_output)
# Mean absolute error
l1_loss = tf.reduce_mean(tf.abs(target - gen_output))
total_gen_loss = gan_loss + (LAMBDA * l1_loss)
return total_gen_loss, gan_loss, l1_loss
জেনারেটরের প্রশিক্ষণ পদ্ধতি নিম্নরূপ:

বৈষম্যকারী গড়ে তুলুন
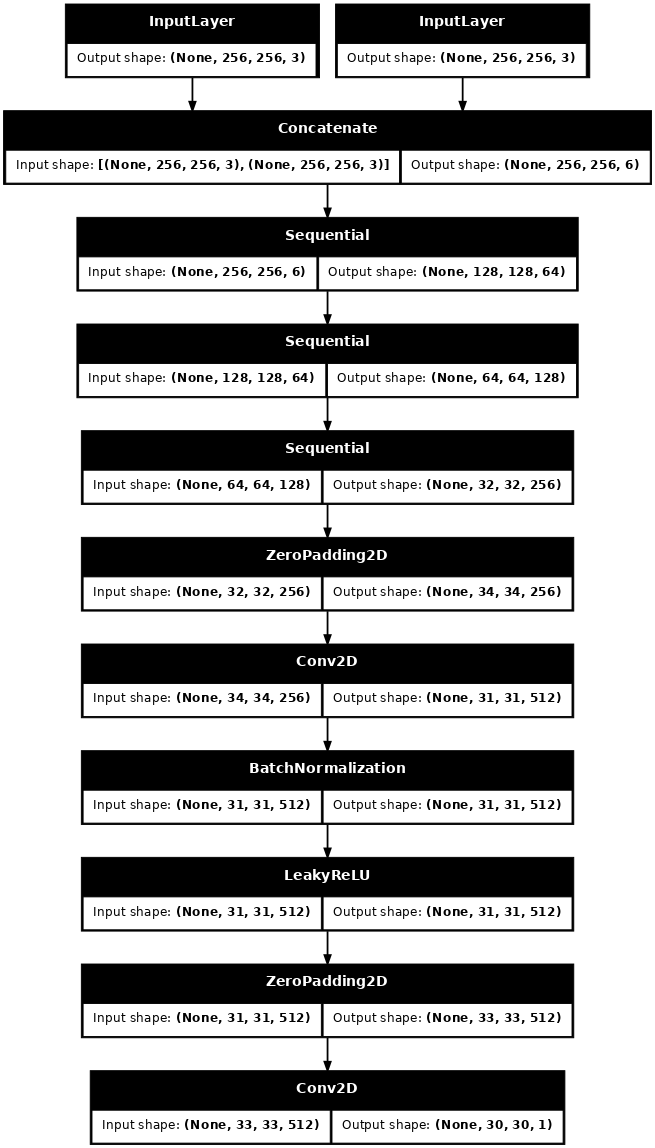
pix2pix cGAN-এ বৈষম্যকারী একটি convolutional PatchGAN ক্লাসিফায়ার-এটি শ্রেণীবদ্ধ করার চেষ্টা করে যে প্রতিটি চিত্র প্যাচ বাস্তব নাকি বাস্তব নয়, যেমন pix2pix কাগজে বর্ণিত হয়েছে।
- ডিসক্রিমিনেটরের প্রতিটি ব্লক হল: কনভোলিউশন -> ব্যাচ নরমালাইজেশন -> লিকি ReLU।
- শেষ লেয়ারের পরে আউটপুটের আকৃতি হল
(batch_size, 30, 30, 1)। - আউটপুটের প্রতিটি
30 x 30চিত্র প্যাচ ইনপুট চিত্রের একটি70 x 70অংশকে শ্রেণিবদ্ধ করে। - বৈষম্যকারী 2টি ইনপুট পায়:
- ইনপুট চিত্র এবং লক্ষ্য চিত্র, যা এটি বাস্তব হিসাবে শ্রেণীবদ্ধ করা উচিত।
- ইনপুট ইমেজ এবং জেনারেট করা ইমেজ (জেনারেটরের আউটপুট), যা এটি জাল হিসাবে শ্রেণীবদ্ধ করা উচিত।
- এই 2টি ইনপুট একসাথে সংযুক্ত করতে
tf.concat([inp, tar], axis=-1)ব্যবহার করুন।
আসুন বৈষম্যকারীকে সংজ্ঞায়িত করি:
def Discriminator():
initializer = tf.random_normal_initializer(0., 0.02)
inp = tf.keras.layers.Input(shape=[256, 256, 3], name='input_image')
tar = tf.keras.layers.Input(shape=[256, 256, 3], name='target_image')
x = tf.keras.layers.concatenate([inp, tar]) # (batch_size, 256, 256, channels*2)
down1 = downsample(64, 4, False)(x) # (batch_size, 128, 128, 64)
down2 = downsample(128, 4)(down1) # (batch_size, 64, 64, 128)
down3 = downsample(256, 4)(down2) # (batch_size, 32, 32, 256)
zero_pad1 = tf.keras.layers.ZeroPadding2D()(down3) # (batch_size, 34, 34, 256)
conv = tf.keras.layers.Conv2D(512, 4, strides=1,
kernel_initializer=initializer,
use_bias=False)(zero_pad1) # (batch_size, 31, 31, 512)
batchnorm1 = tf.keras.layers.BatchNormalization()(conv)
leaky_relu = tf.keras.layers.LeakyReLU()(batchnorm1)
zero_pad2 = tf.keras.layers.ZeroPadding2D()(leaky_relu) # (batch_size, 33, 33, 512)
last = tf.keras.layers.Conv2D(1, 4, strides=1,
kernel_initializer=initializer)(zero_pad2) # (batch_size, 30, 30, 1)
return tf.keras.Model(inputs=[inp, tar], outputs=last)
বৈষম্যকারী মডেল আর্কিটেকচার কল্পনা করুন:
discriminator = Discriminator()
tf.keras.utils.plot_model(discriminator, show_shapes=True, dpi=64)
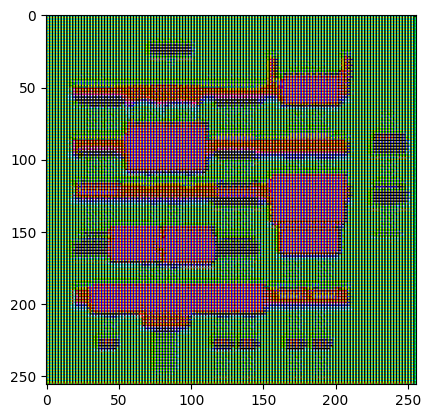
বৈষম্যকারী পরীক্ষা করুন:
disc_out = discriminator([inp[tf.newaxis, ...], gen_output], training=False)
plt.imshow(disc_out[0, ..., -1], vmin=-20, vmax=20, cmap='RdBu_r')
plt.colorbar()
<matplotlib.colorbar.Colorbar at 0x7f35cec82c50>

বৈষম্যকারী ক্ষতি সংজ্ঞায়িত করুন
-
discriminator_lossফাংশনটি 2টি ইনপুট নেয়: বাস্তব ছবি এবং জেনারেট করা ছবি । -
real_lossহল বাস্তব চিত্রের একটি সিগমায়েড ক্রস-এনট্রপি লস এবং একটি অ্যারে (যেহেতু এগুলোই আসল ছবি) । -
generated_lossহল একটি সিগমায়েড ক্রস-এনট্রপি উৎপন্ন চিত্রের ক্ষতি এবং শূন্যের একটি অ্যারে (যেহেতু এইগুলি নকল ছবি) । -
total_lossহলreal_lossএবংgenerated_lossসমষ্টি।
def discriminator_loss(disc_real_output, disc_generated_output):
real_loss = loss_object(tf.ones_like(disc_real_output), disc_real_output)
generated_loss = loss_object(tf.zeros_like(disc_generated_output), disc_generated_output)
total_disc_loss = real_loss + generated_loss
return total_disc_loss
বৈষম্যকারীর জন্য প্রশিক্ষণ পদ্ধতি নীচে দেখানো হয়েছে।
আর্কিটেকচার এবং হাইপারপ্যারামিটার সম্পর্কে আরও জানতে আপনি pix2pix কাগজটি উল্লেখ করতে পারেন।

অপ্টিমাইজার এবং একটি চেকপয়েন্ট-সেভার সংজ্ঞায়িত করুন
generator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
ছবি তৈরি করুন
প্রশিক্ষণের সময় কিছু চিত্র প্লট করার জন্য একটি ফাংশন লিখুন।
- পরীক্ষা সেট থেকে জেনারেটরে ছবি পাস করুন।
- জেনারেটর তখন ইনপুট ইমেজটিকে আউটপুটে অনুবাদ করবে।
- শেষ ধাপে ভবিষ্যদ্বাণী এবং ভয়লা প্লট!
def generate_images(model, test_input, tar):
prediction = model(test_input, training=True)
plt.figure(figsize=(15, 15))
display_list = [test_input[0], tar[0], prediction[0]]
title = ['Input Image', 'Ground Truth', 'Predicted Image']
for i in range(3):
plt.subplot(1, 3, i+1)
plt.title(title[i])
# Getting the pixel values in the [0, 1] range to plot.
plt.imshow(display_list[i] * 0.5 + 0.5)
plt.axis('off')
plt.show()
ফাংশন পরীক্ষা করুন:
for example_input, example_target in test_dataset.take(1):
generate_images(generator, example_input, example_target)

প্রশিক্ষণ
- প্রতিটি উদাহরণের জন্য ইনপুট একটি আউটপুট তৈরি করে।
- বৈষম্যকারী প্রথম ইনপুট হিসাবে
input_imageএবং জেনারেট করা চিত্র গ্রহণ করে। দ্বিতীয় ইনপুট হলinput_imageএবংtarget_image। - এর পরে, জেনারেটর এবং বৈষম্যকারী ক্ষতি গণনা করুন।
- তারপর, জেনারেটর এবং ডিসক্রিমিনেটর ভেরিয়েবল (ইনপুট) উভয়ের সাপেক্ষে ক্ষতির গ্রেডিয়েন্ট গণনা করুন এবং সেগুলি অপ্টিমাইজারে প্রয়োগ করুন।
- অবশেষে, TensorBoard-এ ক্ষতি লগ করুন।
log_dir="logs/"
summary_writer = tf.summary.create_file_writer(
log_dir + "fit/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
@tf.function
def train_step(input_image, target, step):
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
gen_output = generator(input_image, training=True)
disc_real_output = discriminator([input_image, target], training=True)
disc_generated_output = discriminator([input_image, gen_output], training=True)
gen_total_loss, gen_gan_loss, gen_l1_loss = generator_loss(disc_generated_output, gen_output, target)
disc_loss = discriminator_loss(disc_real_output, disc_generated_output)
generator_gradients = gen_tape.gradient(gen_total_loss,
generator.trainable_variables)
discriminator_gradients = disc_tape.gradient(disc_loss,
discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(generator_gradients,
generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(discriminator_gradients,
discriminator.trainable_variables))
with summary_writer.as_default():
tf.summary.scalar('gen_total_loss', gen_total_loss, step=step//1000)
tf.summary.scalar('gen_gan_loss', gen_gan_loss, step=step//1000)
tf.summary.scalar('gen_l1_loss', gen_l1_loss, step=step//1000)
tf.summary.scalar('disc_loss', disc_loss, step=step//1000)
প্রকৃত প্রশিক্ষণ লুপ. যেহেতু এই টিউটোরিয়ালটি একাধিক ডেটাসেট নিয়ে চলতে পারে, এবং ডেটাসেটগুলির আকারে ব্যাপক তারতম্য হয়, প্রশিক্ষণের লুপটি যুগের পরিবর্তে ধাপে কাজ করার জন্য সেটআপ করা হয়।
- ধাপের সংখ্যার উপর পুনরাবৃত্তি করে।
- প্রতি 10 ধাপে একটি বিন্দু (
.) প্রিন্ট করুন। - প্রতি 1k ধাপে: ডিসপ্লেটি সাফ করুন এবং অগ্রগতি দেখানোর জন্য
generate_imagesচালান। - প্রতি 5k ধাপে: একটি চেকপয়েন্ট সংরক্ষণ করুন।
def fit(train_ds, test_ds, steps):
example_input, example_target = next(iter(test_ds.take(1)))
start = time.time()
for step, (input_image, target) in train_ds.repeat().take(steps).enumerate():
if (step) % 1000 == 0:
display.clear_output(wait=True)
if step != 0:
print(f'Time taken for 1000 steps: {time.time()-start:.2f} sec\n')
start = time.time()
generate_images(generator, example_input, example_target)
print(f"Step: {step//1000}k")
train_step(input_image, target, step)
# Training step
if (step+1) % 10 == 0:
print('.', end='', flush=True)
# Save (checkpoint) the model every 5k steps
if (step + 1) % 5000 == 0:
checkpoint.save(file_prefix=checkpoint_prefix)
এই প্রশিক্ষণ লুপ লগগুলি সংরক্ষণ করে যা আপনি প্রশিক্ষণের অগ্রগতি নিরীক্ষণ করতে টেনসরবোর্ডে দেখতে পারেন।
আপনি যদি স্থানীয় মেশিনে কাজ করেন তবে আপনি একটি পৃথক টেনসরবোর্ড প্রক্রিয়া চালু করবেন। একটি নোটবুকে কাজ করার সময়, টেনসরবোর্ডের সাথে নিরীক্ষণ করার জন্য প্রশিক্ষণ শুরু করার আগে দর্শককে চালু করুন।
ভিউয়ার চালু করতে একটি কোড-সেলে নিম্নলিখিতগুলি পেস্ট করুন:
%load_ext tensorboard
%tensorboard --logdir {log_dir}
অবশেষে, প্রশিক্ষণ লুপ চালান:
fit(train_dataset, test_dataset, steps=40000)
Time taken for 1000 steps: 36.53 sec

Step: 39k ....................................................................................................
আপনি যদি TensorBoard ফলাফল সর্বজনীনভাবে ভাগ করতে চান, তাহলে আপনি নিম্নলিখিতটি একটি কোড-সেলে অনুলিপি করে TensorBoard.dev- এ লগগুলি আপলোড করতে পারেন৷
tensorboard dev upload --logdir {log_dir}
আপনি TensorBoard.dev- এ এই নোটবুকের আগের রানের ফলাফল দেখতে পারেন।
TensorBoard.dev হল সবার সাথে ML পরীক্ষা হোস্টিং, ট্র্যাকিং এবং শেয়ার করার জন্য একটি পরিচালিত অভিজ্ঞতা।
এটি একটি <iframe> ব্যবহার করে ইনলাইনও অন্তর্ভুক্ত করতে পারে:
display.IFrame(
src="https://tensorboard.dev/experiment/lZ0C6FONROaUMfjYkVyJqw",
width="100%",
height="1000px")
একটি সাধারণ শ্রেণিবিন্যাস বা রিগ্রেশন মডেলের তুলনায় একটি GAN (বা pix2pix এর মতো একটি cGAN) প্রশিক্ষণের সময় লগগুলি ব্যাখ্যা করা আরও সূক্ষ্ম। যা যা খুঁজতে হবে:
- পরীক্ষা করুন যে জেনারেটর বা বৈষম্যকারী মডেল "জিতেনি"। যদি হয়
gen_gan_lossবাdisc_lossখুব কম হয়, তাহলে এটি একটি সূচক যে এই মডেলটি অন্যটির উপর আধিপত্য বিস্তার করছে এবং আপনি সফলভাবে সম্মিলিত মডেলটিকে প্রশিক্ষণ দিচ্ছেন না। - মান
log(2) = 0.69এই ক্ষতিগুলির জন্য একটি ভাল রেফারেন্স পয়েন্ট, কারণ এটি 2-এর একটি বিভ্রান্তিকর নির্দেশ করে - বৈষম্যকারী, গড়ে, দুটি বিকল্প সম্পর্কে সমানভাবে অনিশ্চিত৷ -
disc_lossএর জন্য,0.69এর নিচে একটি মান মানে বৈষম্যকারী বাস্তব এবং উত্পন্ন চিত্রের মিলিত সেটে এলোমেলো থেকে ভাল করছে। -
gen_gan_lossএর জন্য,0.69এর নিচে একটি মান মানে জেনারেটর বৈষম্যকারীকে বোকা বানানোর চেয়ে এলোমেলো কাজ করছে। - প্রশিক্ষণের অগ্রগতির সাথে সাথে
gen_l1_lossকমে যাওয়া উচিত।
সর্বশেষ চেকপয়েন্ট পুনরুদ্ধার করুন এবং নেটওয়ার্ক পরীক্ষা করুন
ls {checkpoint_dir}
checkpoint ckpt-5.data-00000-of-00001 ckpt-1.data-00000-of-00001 ckpt-5.index ckpt-1.index ckpt-6.data-00000-of-00001 ckpt-2.data-00000-of-00001 ckpt-6.index ckpt-2.index ckpt-7.data-00000-of-00001 ckpt-3.data-00000-of-00001 ckpt-7.index ckpt-3.index ckpt-8.data-00000-of-00001 ckpt-4.data-00000-of-00001 ckpt-8.index ckpt-4.index
# Restoring the latest checkpoint in checkpoint_dir
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
<tensorflow.python.training.tracking.util.CheckpointLoadStatus at 0x7f35cfd6b8d0>
পরীক্ষা সেট ব্যবহার করে কিছু ছবি তৈরি করুন
# Run the trained model on a few examples from the test set
for inp, tar in test_dataset.take(5):
generate_images(generator, inp, tar)




