
| | |  Visualizza l'origine su GitHub Visualizza l'origine su GitHub | |
Questo tutorial mostra come generare immagini di cifre scritte a mano utilizzando una Deep Convolutional Generative Adversarial Network (DCGAN). Il codice viene scritto utilizzando l' API Keras Sequential con un ciclo di addestramento tf.GradientTape .
Cosa sono i GAN?
Le reti generative contraddittorio (GAN) sono una delle idee più interessanti dell'informatica odierna. Due modelli sono addestrati simultaneamente da un processo contraddittorio. Un generatore ("l'artista") impara a creare immagini che sembrano reali, mentre un discriminatore ("il critico d'arte") impara a distinguere le immagini reali dai falsi.
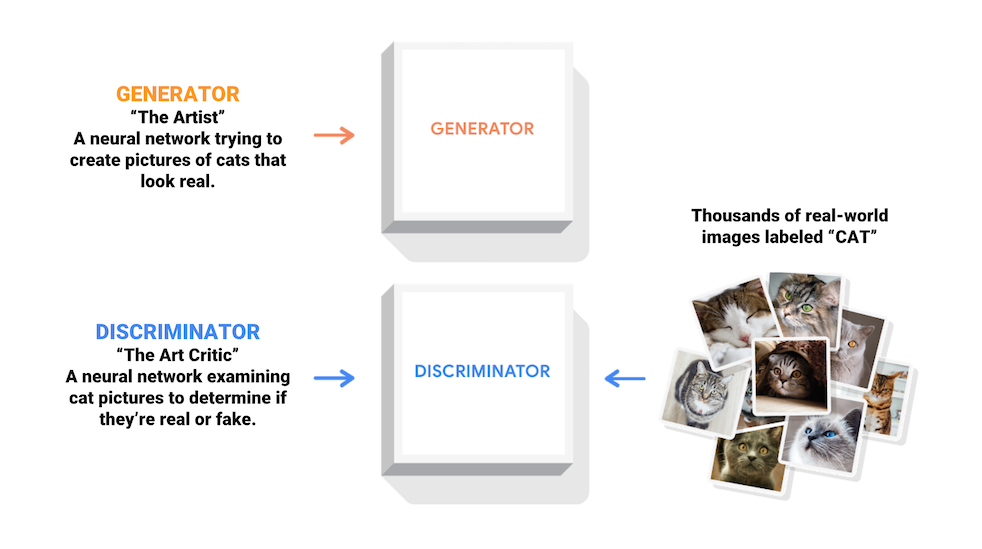
Durante l'allenamento, il generatore diventa progressivamente più bravo a creare immagini che sembrano reali, mentre il discriminatore diventa più bravo a distinguerle. Il processo raggiunge l'equilibrio quando il discriminatore non riesce più a distinguere le immagini reali da quelle false.
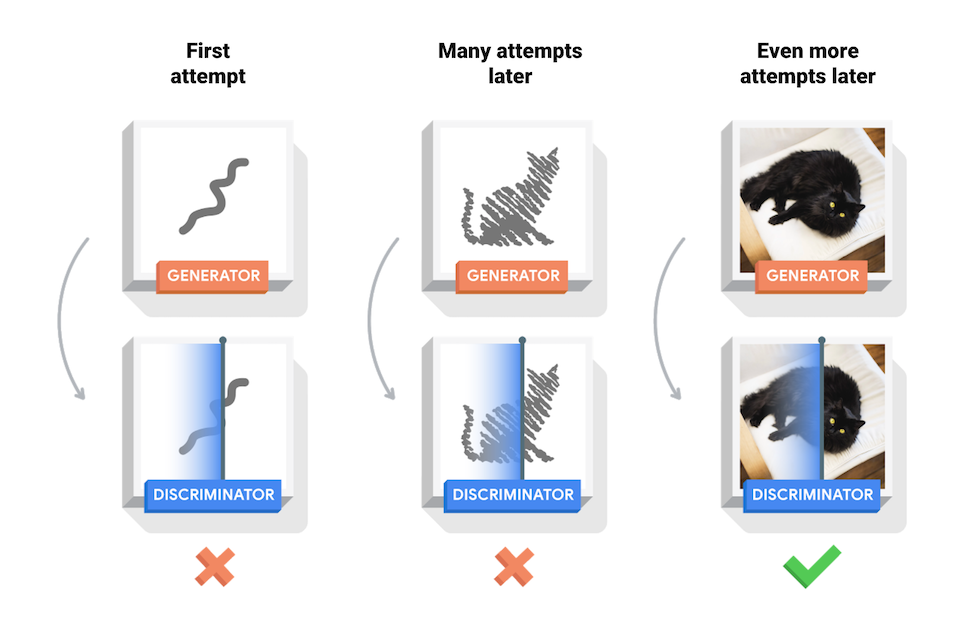
Questo quaderno mostra questo processo sul set di dati MNIST. L'animazione seguente mostra una serie di immagini prodotte dal generatore mentre veniva addestrato per 50 epoche. Le immagini iniziano come rumore casuale e nel tempo assomigliano sempre più a cifre scritte a mano.

Per ulteriori informazioni sui GAN, vedere il corso Intro to Deep Learning del MIT.
Impostare
import tensorflow as tf
tf.__version__
'2.8.0-rc1'
# To generate GIFspip install imageiopip install git+https://github.com/tensorflow/docs
import glob
import imageio
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
from tensorflow.keras import layers
import time
from IPython import display
Carica e prepara il set di dati
Utilizzerai il set di dati MNIST per addestrare il generatore e il discriminatore. Il generatore genererà cifre scritte a mano simili ai dati MNIST.
(train_images, train_labels), (_, _) = tf.keras.datasets.mnist.load_data()
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
train_images = (train_images - 127.5) / 127.5 # Normalize the images to [-1, 1]
BUFFER_SIZE = 60000
BATCH_SIZE = 256
# Batch and shuffle the data
train_dataset = tf.data.Dataset.from_tensor_slices(train_images).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
Crea i modelli
Sia il generatore che il discriminatore sono definiti utilizzando l' API Keras Sequential .
Il generatore
Il generatore utilizza tf.keras.layers.Conv2DTranspose (upsampling) per produrre un'immagine da un seme (rumore casuale). Inizia con un livello Dense che prende questo seme come input, quindi sovracampiona più volte fino a raggiungere la dimensione dell'immagine desiderata di 28x28x1. Notare l'attivazione di tf.keras.layers.LeakyReLU per ogni livello, ad eccezione del livello di output che usa tanh.
def make_generator_model():
model = tf.keras.Sequential()
model.add(layers.Dense(7*7*256, use_bias=False, input_shape=(100,)))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Reshape((7, 7, 256)))
assert model.output_shape == (None, 7, 7, 256) # Note: None is the batch size
model.add(layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False))
assert model.output_shape == (None, 7, 7, 128)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False))
assert model.output_shape == (None, 14, 14, 64)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
assert model.output_shape == (None, 28, 28, 1)
return model
Usa il generatore (non ancora addestrato) per creare un'immagine.
generator = make_generator_model()
noise = tf.random.normal([1, 100])
generated_image = generator(noise, training=False)
plt.imshow(generated_image[0, :, :, 0], cmap='gray')
<matplotlib.image.AxesImage at 0x7f6fe7a04b90>

Il discriminatore
Il discriminatore è un classificatore di immagini basato sulla CNN.
def make_discriminator_model():
model = tf.keras.Sequential()
model.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same',
input_shape=[28, 28, 1]))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Flatten())
model.add(layers.Dense(1))
return model
Usa il discriminatore (non ancora addestrato) per classificare le immagini generate come reali o false. Il modello verrà addestrato per produrre valori positivi per immagini reali e valori negativi per immagini false.
discriminator = make_discriminator_model()
decision = discriminator(generated_image)
print (decision)
tf.Tensor([[-0.00339105]], shape=(1, 1), dtype=float32)
Definire la perdita e gli ottimizzatori
Definisci le funzioni di perdita e gli ottimizzatori per entrambi i modelli.
# This method returns a helper function to compute cross entropy loss
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
Perdita discriminante
Questo metodo quantifica quanto bene il discriminatore è in grado di distinguere le immagini reali da quelle false. Confronta le previsioni del discriminatore su immagini reali con un array di 1 e le previsioni del discriminatore su immagini false (generate) con un array di 0.
def discriminator_loss(real_output, fake_output):
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss
return total_loss
Perdita del generatore
La perdita del generatore quantifica quanto bene è stato in grado di ingannare il discriminatore. Intuitivamente, se il generatore funziona bene, il discriminatore classificherà le immagini false come reali (o 1). Qui, confronta le decisioni dei discriminatori sulle immagini generate con una matrice di 1s.
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)
Il discriminatore e gli ottimizzatori del generatore sono diversi poiché addestrerai due reti separatamente.
generator_optimizer = tf.keras.optimizers.Adam(1e-4)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)
Salva i checkpoint
Questo notebook mostra anche come salvare e ripristinare i modelli, che possono essere utili nel caso in cui un'attività di formazione di lunga durata venga interrotta.
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
Definisci il ciclo di allenamento
EPOCHS = 50
noise_dim = 100
num_examples_to_generate = 16
# You will reuse this seed overtime (so it's easier)
# to visualize progress in the animated GIF)
seed = tf.random.normal([num_examples_to_generate, noise_dim])
Il ciclo di addestramento inizia con il generatore che riceve un seme casuale come input. Quel seme viene utilizzato per produrre un'immagine. Il discriminatore viene quindi utilizzato per classificare le immagini reali (disegnate dal training set) e le immagini false (prodotte dal generatore). La perdita viene calcolata per ciascuno di questi modelli e i gradienti vengono utilizzati per aggiornare il generatore e il discriminatore.
# Notice the use of `tf.function`
# This annotation causes the function to be "compiled".
@tf.function
def train_step(images):
noise = tf.random.normal([BATCH_SIZE, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
def train(dataset, epochs):
for epoch in range(epochs):
start = time.time()
for image_batch in dataset:
train_step(image_batch)
# Produce images for the GIF as you go
display.clear_output(wait=True)
generate_and_save_images(generator,
epoch + 1,
seed)
# Save the model every 15 epochs
if (epoch + 1) % 15 == 0:
checkpoint.save(file_prefix = checkpoint_prefix)
print ('Time for epoch {} is {} sec'.format(epoch + 1, time.time()-start))
# Generate after the final epoch
display.clear_output(wait=True)
generate_and_save_images(generator,
epochs,
seed)
Genera e salva immagini
def generate_and_save_images(model, epoch, test_input):
# Notice `training` is set to False.
# This is so all layers run in inference mode (batchnorm).
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(4, 4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray')
plt.axis('off')
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
Allena il modello
Chiama il metodo train() definito sopra per addestrare il generatore e il discriminatore contemporaneamente. Nota, l'addestramento dei GAN può essere complicato. È importante che il generatore e il discriminatore non si prevalgano a vicenda (ad esempio, che si allenino a una velocità simile).
All'inizio del training, le immagini generate appaiono come rumore casuale. Con il progredire della formazione, le cifre generate appariranno sempre più reali. Dopo circa 50 epoche, assomigliano alle cifre MNIST. Questa operazione potrebbe richiedere circa un minuto/epoca con le impostazioni predefinite su Colab.
train(train_dataset, EPOCHS)

Ripristina l'ultimo checkpoint.
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
<tensorflow.python.training.tracking.util.CheckpointLoadStatus at 0x7f6ee8136950>
Crea una GIF
# Display a single image using the epoch number
def display_image(epoch_no):
return PIL.Image.open('image_at_epoch_{:04d}.png'.format(epoch_no))
display_image(EPOCHS)

Usa imageio per creare una gif animata usando le immagini salvate durante l'allenamento.
anim_file = 'dcgan.gif'
with imageio.get_writer(anim_file, mode='I') as writer:
filenames = glob.glob('image*.png')
filenames = sorted(filenames)
for filename in filenames:
image = imageio.imread(filename)
writer.append_data(image)
image = imageio.imread(filename)
writer.append_data(image)
import tensorflow_docs.vis.embed as embed
embed.embed_file(anim_file)

Prossimi passi
Questo tutorial ha mostrato il codice completo necessario per scrivere e addestrare un GAN. Come passaggio successivo, potresti voler sperimentare un set di dati diverso, ad esempio il set di dati Celeb Faces Attributes (CelebA) su larga scala disponibile su Kaggle . Per saperne di più sui GAN, vedere il Tutorial NIPS 2016: Generative Adversarial Networks .