
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
यह ट्यूटोरियल दर्शाता है कि डीप कन्वेन्शनल जनरेटिव एडवरसैरियल नेटवर्क (DCGAN) का उपयोग करके हस्तलिखित अंकों की छवियां कैसे उत्पन्न की जाती हैं। कोड को tf.GradientTape प्रशिक्षण लूप के साथ Keras अनुक्रमिक API का उपयोग करके लिखा गया है।
जीएएन क्या हैं?
जनरेटिव एडवरसैरियल नेटवर्क (जीएएन) आज कंप्यूटर विज्ञान में सबसे दिलचस्प विचारों में से एक है। दो मॉडलों को एक साथ एक प्रतिकूल प्रक्रिया द्वारा प्रशिक्षित किया जाता है। एक जनरेटर ("कलाकार") वास्तविक दिखने वाली छवियां बनाना सीखता है, जबकि एक विवेचक ("कला समीक्षक") नकली के अलावा वास्तविक छवियों को बताना सीखता है।
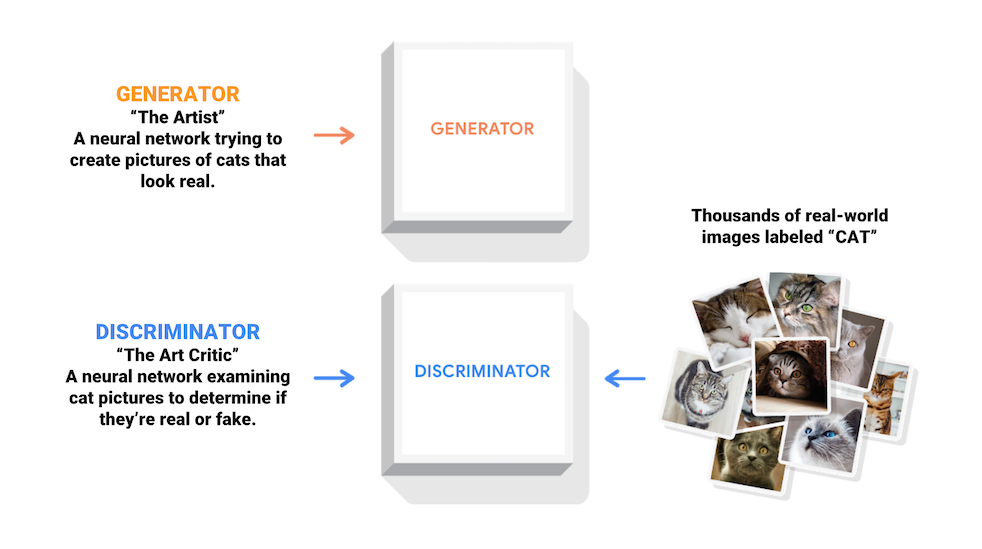
प्रशिक्षण के दौरान, जनरेटर वास्तविक दिखने वाली छवियों को बनाने में उत्तरोत्तर बेहतर होता जाता है, जबकि विवेचक उन्हें अलग बताने में बेहतर हो जाता है। प्रक्रिया संतुलन तक पहुँच जाती है जब विवेचक वास्तविक छवियों को नकली से अलग नहीं कर सकता है।
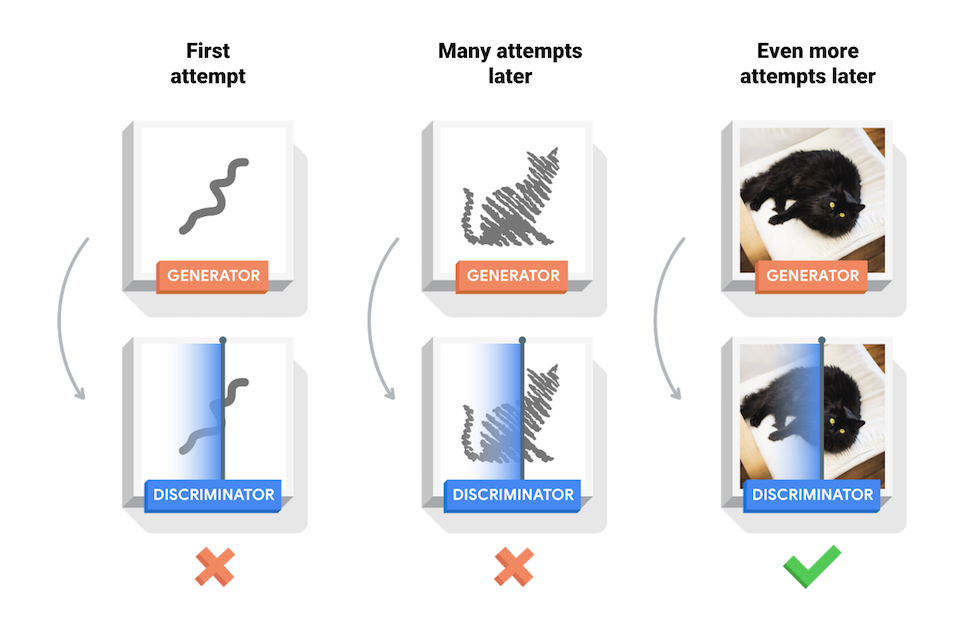
यह नोटबुक MNIST डेटासेट पर इस प्रक्रिया को प्रदर्शित करती है। निम्नलिखित एनीमेशन जनरेटर द्वारा निर्मित छवियों की एक श्रृंखला दिखाता है क्योंकि इसे 50 युगों के लिए प्रशिक्षित किया गया था। छवियां यादृच्छिक शोर के रूप में शुरू होती हैं, और समय के साथ हाथ से लिखे अंकों के समान होती जाती हैं।

GAN के बारे में अधिक जानने के लिए, MIT का इंट्रो टू डीप लर्निंग कोर्स देखें।
सेट अप
import tensorflow as tf
tf.__version__
'2.8.0-rc1'
# To generate GIFspip install imageiopip install git+https://github.com/tensorflow/docs
import glob
import imageio
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
from tensorflow.keras import layers
import time
from IPython import display
डेटासेट लोड करें और तैयार करें
आप जनरेटर और विवेचक को प्रशिक्षित करने के लिए MNIST डेटासेट का उपयोग करेंगे। जनरेटर MNIST डेटा के सदृश हस्तलिखित अंक उत्पन्न करेगा।
(train_images, train_labels), (_, _) = tf.keras.datasets.mnist.load_data()
train_images = train_images.reshape(train_images.shape[0], 28, 28, 1).astype('float32')
train_images = (train_images - 127.5) / 127.5 # Normalize the images to [-1, 1]
BUFFER_SIZE = 60000
BATCH_SIZE = 256
# Batch and shuffle the data
train_dataset = tf.data.Dataset.from_tensor_slices(train_images).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
मॉडल बनाएं
जनरेटर और विवेचक दोनों को केरस अनुक्रमिक एपीआई का उपयोग करके परिभाषित किया गया है।
जेनरेटर
जनरेटर tf.keras.layers.Conv2Dएक बीज (यादृच्छिक शोर) से एक छवि बनाने के लिए ट्रांसपोज़ ( tf.keras.layers.Conv2DTranspose ) परतों का उपयोग करता है। एक Dense परत से शुरू करें जो इस बीज को इनपुट के रूप में लेती है, फिर कई बार अपनमूना करें जब तक कि आप वांछित छवि आकार 28x28x1 तक नहीं पहुंच जाते। प्रत्येक परत के लिए tf.keras.layers.LeakyReLU सक्रियण पर ध्यान दें, आउटपुट परत को छोड़कर जो tanh का उपयोग करती है।
def make_generator_model():
model = tf.keras.Sequential()
model.add(layers.Dense(7*7*256, use_bias=False, input_shape=(100,)))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Reshape((7, 7, 256)))
assert model.output_shape == (None, 7, 7, 256) # Note: None is the batch size
model.add(layers.Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False))
assert model.output_shape == (None, 7, 7, 128)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False))
assert model.output_shape == (None, 14, 14, 64)
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
assert model.output_shape == (None, 28, 28, 1)
return model
छवि बनाने के लिए (अभी तक अप्रशिक्षित) जनरेटर का उपयोग करें।
generator = make_generator_model()
noise = tf.random.normal([1, 100])
generated_image = generator(noise, training=False)
plt.imshow(generated_image[0, :, :, 0], cmap='gray')
<matplotlib.image.AxesImage at 0x7f6fe7a04b90>

भेदभाव करने वाला
विभेदक एक सीएनएन-आधारित छवि क्लासिफायरियर है।
def make_discriminator_model():
model = tf.keras.Sequential()
model.add(layers.Conv2D(64, (5, 5), strides=(2, 2), padding='same',
input_shape=[28, 28, 1]))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Conv2D(128, (5, 5), strides=(2, 2), padding='same'))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Flatten())
model.add(layers.Dense(1))
return model
उत्पन्न छवियों को वास्तविक या नकली के रूप में वर्गीकृत करने के लिए (अभी तक अप्रशिक्षित) विभेदक का उपयोग करें। मॉडल को वास्तविक छवियों के लिए सकारात्मक मूल्यों और नकली छवियों के लिए नकारात्मक मूल्यों को आउटपुट करने के लिए प्रशिक्षित किया जाएगा।
discriminator = make_discriminator_model()
decision = discriminator(generated_image)
print (decision)
tf.Tensor([[-0.00339105]], shape=(1, 1), dtype=float32)
नुकसान और अनुकूलक को परिभाषित करें
दोनों मॉडलों के लिए हानि कार्यों और अनुकूलकों को परिभाषित करें।
# This method returns a helper function to compute cross entropy loss
cross_entropy = tf.keras.losses.BinaryCrossentropy(from_logits=True)
भेदभाव करने वाला नुकसान
यह विधि यह निर्धारित करती है कि विवेचक वास्तविक छवियों को नकली से कितनी अच्छी तरह अलग करने में सक्षम है। यह वास्तविक छवियों पर विवेचक की भविष्यवाणियों की तुलना 1s की एक सरणी से करता है, और विवेचक की भविष्यवाणियों की नकली (उत्पन्न) छवियों पर 0s की एक सरणी से तुलना करता है।
def discriminator_loss(real_output, fake_output):
real_loss = cross_entropy(tf.ones_like(real_output), real_output)
fake_loss = cross_entropy(tf.zeros_like(fake_output), fake_output)
total_loss = real_loss + fake_loss
return total_loss
जनरेटर का नुकसान
जनरेटर का नुकसान यह निर्धारित करता है कि यह विवेचक को कितनी अच्छी तरह बरगलाने में सक्षम था। सहज रूप से, यदि जनरेटर अच्छा प्रदर्शन कर रहा है, तो विवेचक नकली छवियों को वास्तविक (या 1) के रूप में वर्गीकृत करेगा। यहां, उत्पन्न छवियों पर भेदभाव करने वालों के निर्णयों की तुलना 1s की एक सरणी से करें।
def generator_loss(fake_output):
return cross_entropy(tf.ones_like(fake_output), fake_output)
डिस्क्रिमिनेटर और जेनरेटर ऑप्टिमाइज़र अलग-अलग हैं क्योंकि आप दो नेटवर्क को अलग-अलग प्रशिक्षित करेंगे।
generator_optimizer = tf.keras.optimizers.Adam(1e-4)
discriminator_optimizer = tf.keras.optimizers.Adam(1e-4)
चौकियों को बचाएं
यह नोटबुक यह भी दर्शाती है कि मॉडलों को कैसे सहेजना और पुनर्स्थापित करना है, जो लंबे समय तक चलने वाले प्रशिक्षण कार्य में बाधा आने की स्थिति में मददगार हो सकता है।
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,
discriminator_optimizer=discriminator_optimizer,
generator=generator,
discriminator=discriminator)
प्रशिक्षण लूप को परिभाषित करें
EPOCHS = 50
noise_dim = 100
num_examples_to_generate = 16
# You will reuse this seed overtime (so it's easier)
# to visualize progress in the animated GIF)
seed = tf.random.normal([num_examples_to_generate, noise_dim])
प्रशिक्षण लूप जनरेटर के इनपुट के रूप में एक यादृच्छिक बीज प्राप्त करने के साथ शुरू होता है। उस बीज का उपयोग छवि बनाने के लिए किया जाता है। फिर विवेचक का उपयोग वास्तविक छवियों (प्रशिक्षण सेट से खींची गई) और नकली छवियों (जनरेटर द्वारा निर्मित) को वर्गीकृत करने के लिए किया जाता है। इन मॉडलों में से प्रत्येक के लिए नुकसान की गणना की जाती है, और जनरेटर और डिस्क्रिमिनेटर को अपडेट करने के लिए ग्रेडिएंट का उपयोग किया जाता है।
# Notice the use of `tf.function`
# This annotation causes the function to be "compiled".
@tf.function
def train_step(images):
noise = tf.random.normal([BATCH_SIZE, noise_dim])
with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:
generated_images = generator(noise, training=True)
real_output = discriminator(images, training=True)
fake_output = discriminator(generated_images, training=True)
gen_loss = generator_loss(fake_output)
disc_loss = discriminator_loss(real_output, fake_output)
gradients_of_generator = gen_tape.gradient(gen_loss, generator.trainable_variables)
gradients_of_discriminator = disc_tape.gradient(disc_loss, discriminator.trainable_variables)
generator_optimizer.apply_gradients(zip(gradients_of_generator, generator.trainable_variables))
discriminator_optimizer.apply_gradients(zip(gradients_of_discriminator, discriminator.trainable_variables))
def train(dataset, epochs):
for epoch in range(epochs):
start = time.time()
for image_batch in dataset:
train_step(image_batch)
# Produce images for the GIF as you go
display.clear_output(wait=True)
generate_and_save_images(generator,
epoch + 1,
seed)
# Save the model every 15 epochs
if (epoch + 1) % 15 == 0:
checkpoint.save(file_prefix = checkpoint_prefix)
print ('Time for epoch {} is {} sec'.format(epoch + 1, time.time()-start))
# Generate after the final epoch
display.clear_output(wait=True)
generate_and_save_images(generator,
epochs,
seed)
छवियां बनाएं और सहेजें
def generate_and_save_images(model, epoch, test_input):
# Notice `training` is set to False.
# This is so all layers run in inference mode (batchnorm).
predictions = model(test_input, training=False)
fig = plt.figure(figsize=(4, 4))
for i in range(predictions.shape[0]):
plt.subplot(4, 4, i+1)
plt.imshow(predictions[i, :, :, 0] * 127.5 + 127.5, cmap='gray')
plt.axis('off')
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
मॉडल को प्रशिक्षित करें
जनरेटर और डिस्क्रिमिनेटर को एक साथ प्रशिक्षित करने के लिए ऊपर परिभाषित train() विधि को कॉल करें। ध्यान दें, GAN को प्रशिक्षित करना मुश्किल हो सकता है। यह महत्वपूर्ण है कि जनरेटर और विवेचक एक-दूसरे पर हावी न हों (उदाहरण के लिए, कि वे समान दर से प्रशिक्षण लेते हैं)।
प्रशिक्षण की शुरुआत में, उत्पन्न छवियां यादृच्छिक शोर की तरह दिखती हैं। जैसे-जैसे प्रशिक्षण आगे बढ़ेगा, उत्पन्न अंक तेजी से वास्तविक दिखाई देंगे। लगभग 50 युगों के बाद, वे MNIST अंकों के समान होते हैं। Colab पर डिफ़ॉल्ट सेटिंग के साथ इसमें लगभग एक मिनट / युग लग सकता है।
train(train_dataset, EPOCHS)

नवीनतम चेकपॉइंट को पुनर्स्थापित करें।
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))
<tensorflow.python.training.tracking.util.CheckpointLoadStatus at 0x7f6ee8136950>
जीआईएफ बनाएं
# Display a single image using the epoch number
def display_image(epoch_no):
return PIL.Image.open('image_at_epoch_{:04d}.png'.format(epoch_no))
display_image(EPOCHS)

प्रशिक्षण के दौरान सहेजी गई छवियों का उपयोग करके एनिमेटेड imageio बनाने के लिए इमेजियो का उपयोग करें।
anim_file = 'dcgan.gif'
with imageio.get_writer(anim_file, mode='I') as writer:
filenames = glob.glob('image*.png')
filenames = sorted(filenames)
for filename in filenames:
image = imageio.imread(filename)
writer.append_data(image)
image = imageio.imread(filename)
writer.append_data(image)
import tensorflow_docs.vis.embed as embed
embed.embed_file(anim_file)

अगले कदम
इस ट्यूटोरियल ने GAN को लिखने और प्रशिक्षित करने के लिए आवश्यक पूरा कोड दिखाया है। अगले चरण के रूप में, आप एक अलग डेटासेट के साथ प्रयोग करना पसंद कर सकते हैं, उदाहरण के लिए कागल पर उपलब्ध लार्ज-स्केल सेलेब फेस एट्रीब्यूट्स (सेलेबा) डेटासेट। GAN के बारे में अधिक जानने के लिए NIPS 2016 ट्यूटोरियल: जनरेटिव एडवरसैरियल नेटवर्क देखें।