
| | |  Kaynağı GitHub'da görüntüleyin Kaynağı GitHub'da görüntüleyin | |
Bu not defteri, CycleGAN olarak da bilinen Döngü Tutarlı Karşıt Ağlar Kullanılarak Eşlenmemiş Görüntüden Görüntüye Çeviri bölümünde açıklandığı gibi, koşullu GAN'lar kullanılarak eşleştirilmemiş görüntüden görüntüye çeviriyi gösterir. Makale, herhangi bir eşleştirilmiş eğitim örneğinin yokluğunda, bir görüntü alanının özelliklerini yakalayabilecek ve bu özelliklerin başka bir görüntü alanına nasıl çevrilebileceğini bulabilecek bir yöntem önermektedir.
Bu not defteri, Pix2Pix eğitiminde öğrenebileceğiniz Pix2Pix'e aşina olduğunuzu varsayar. CycleGAN'ın kodu benzerdir, ana fark ek bir kayıp işlevi ve eşleştirilmemiş eğitim verilerinin kullanılmasıdır.
CycleGAN, eşleştirilmiş verilere ihtiyaç duymadan eğitimi etkinleştirmek için bir döngü tutarlılığı kaybı kullanır. Başka bir deyişle, kaynak ve hedef etki alanı arasında bire bir eşleme olmadan bir etki alanından diğerine çeviri yapabilir.
Bu, fotoğraf geliştirme, görüntü renklendirme, stil aktarımı vb. gibi birçok ilginç görevi gerçekleştirme olasılığını açar. Tek ihtiyacınız olan kaynak ve hedef veri kümesidir (ki bu yalnızca bir görüntü dizinidir).


Giriş işlem hattını ayarlayın
Oluşturucu ve ayırıcının içe aktarılmasını sağlayan tensorflow_examples paketini kurun.
pip install git+https://github.com/tensorflow/examples.git
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.models.pix2pix import pix2pix
import os
import time
import matplotlib.pyplot as plt
from IPython.display import clear_output
AUTOTUNE = tf.data.AUTOTUNE
Giriş Hattı
Bu öğretici, at görüntülerinden zebra görüntülerine çevirmek için bir model eğitiyor. Bu veri setine ve benzerlerine buradan ulaşabilirsiniz .
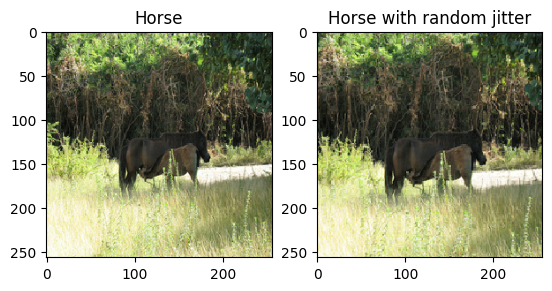
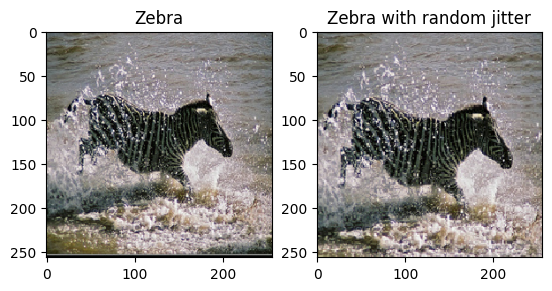
Makalede belirtildiği gibi, eğitim veri kümesine rastgele titreşim ve yansıtma uygulayın. Bunlar, fazla takmayı önleyen görüntü büyütme tekniklerinden bazılarıdır.
Bu, pix2pix'te yapılana benzer
- Rastgele titremede, görüntü
286 x 286olarak yeniden boyutlandırılır ve ardından rastgele256 x 256olarak kırpılır. - Rastgele yansıtmada, görüntü rasgele yatay olarak, yani soldan sağa çevrilir.
dataset, metadata = tfds.load('cycle_gan/horse2zebra',
with_info=True, as_supervised=True)
train_horses, train_zebras = dataset['trainA'], dataset['trainB']
test_horses, test_zebras = dataset['testA'], dataset['testB']
BUFFER_SIZE = 1000
BATCH_SIZE = 1
IMG_WIDTH = 256
IMG_HEIGHT = 256
def random_crop(image):
cropped_image = tf.image.random_crop(
image, size=[IMG_HEIGHT, IMG_WIDTH, 3])
return cropped_image
# normalizing the images to [-1, 1]
def normalize(image):
image = tf.cast(image, tf.float32)
image = (image / 127.5) - 1
return image
def random_jitter(image):
# resizing to 286 x 286 x 3
image = tf.image.resize(image, [286, 286],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
# randomly cropping to 256 x 256 x 3
image = random_crop(image)
# random mirroring
image = tf.image.random_flip_left_right(image)
return image
def preprocess_image_train(image, label):
image = random_jitter(image)
image = normalize(image)
return image
def preprocess_image_test(image, label):
image = normalize(image)
return image
train_horses = train_horses.cache().map(
preprocess_image_train, num_parallel_calls=AUTOTUNE).shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
train_zebras = train_zebras.cache().map(
preprocess_image_train, num_parallel_calls=AUTOTUNE).shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
test_horses = test_horses.map(
preprocess_image_test, num_parallel_calls=AUTOTUNE).cache().shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
test_zebras = test_zebras.map(
preprocess_image_test, num_parallel_calls=AUTOTUNE).cache().shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
sample_horse = next(iter(train_horses))
sample_zebra = next(iter(train_zebras))
2022-01-26 02:38:15.762422: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead. 2022-01-26 02:38:19.927846: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
plt.subplot(121)
plt.title('Horse')
plt.imshow(sample_horse[0] * 0.5 + 0.5)
plt.subplot(122)
plt.title('Horse with random jitter')
plt.imshow(random_jitter(sample_horse[0]) * 0.5 + 0.5)
<matplotlib.image.AxesImage at 0x7f7cf83e0050>
plt.subplot(121)
plt.title('Zebra')
plt.imshow(sample_zebra[0] * 0.5 + 0.5)
plt.subplot(122)
plt.title('Zebra with random jitter')
plt.imshow(random_jitter(sample_zebra[0]) * 0.5 + 0.5)
<matplotlib.image.AxesImage at 0x7f7cf8139490>
Pix2Pix modellerini içe aktarın ve yeniden kullanın
Yüklü tensorflow_examples paketi aracılığıyla Pix2Pix'te kullanılan oluşturucu ve ayırıcıyı içe aktarın.
Bu öğreticide kullanılan model mimarisi, pix2pix'te kullanılana çok benzer. Farklılıklardan bazıları şunlardır:
- Cyclegan, toplu normalleştirme yerine örnek normalleştirmeyi kullanır.
- CycleGAN belgesi , değiştirilmiş bir
resnettabanlı üreteç kullanır. Bu öğretici, basitlik için değiştirilmiş birunetoluşturucu kullanıyor.
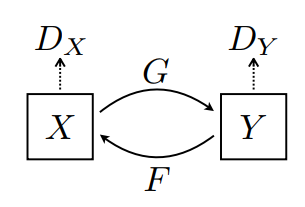
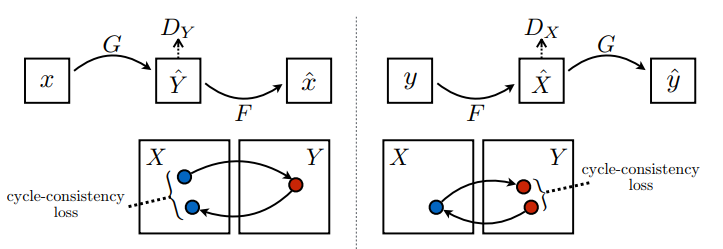
Burada 2 üreteç (G ve F) ve 2 ayrımcı (X ve Y) eğitilmektedir.
- Jeneratör
G,XgörüntüsünüYgörüntüsüne dönüştürmeyi öğrenir. \((G: X -> Y)\) - Üretici
F,YgörüntüsünüXgörüntüsüne dönüştürmeyi öğrenir. \((F: Y -> X)\) - Discriminator
D_X,Xgörüntüsü ile oluşturulanXgörüntüsü arasında ayrım yapmayı öğrenir (F(Y)). - Discriminator
D_Y,Ygörüntüsü ile oluşturulanYgörüntüsü (G(X)) arasında ayrım yapmayı öğrenir.
OUTPUT_CHANNELS = 3
generator_g = pix2pix.unet_generator(OUTPUT_CHANNELS, norm_type='instancenorm')
generator_f = pix2pix.unet_generator(OUTPUT_CHANNELS, norm_type='instancenorm')
discriminator_x = pix2pix.discriminator(norm_type='instancenorm', target=False)
discriminator_y = pix2pix.discriminator(norm_type='instancenorm', target=False)
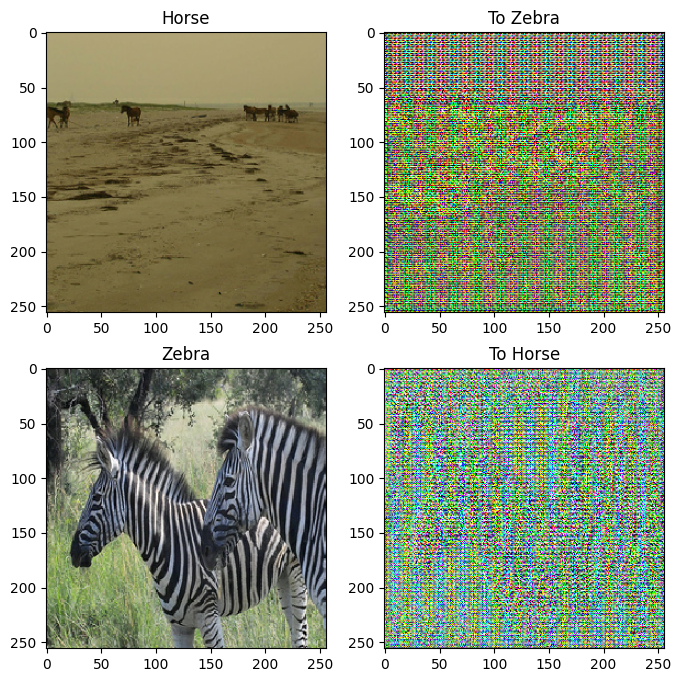
to_zebra = generator_g(sample_horse)
to_horse = generator_f(sample_zebra)
plt.figure(figsize=(8, 8))
contrast = 8
imgs = [sample_horse, to_zebra, sample_zebra, to_horse]
title = ['Horse', 'To Zebra', 'Zebra', 'To Horse']
for i in range(len(imgs)):
plt.subplot(2, 2, i+1)
plt.title(title[i])
if i % 2 == 0:
plt.imshow(imgs[i][0] * 0.5 + 0.5)
else:
plt.imshow(imgs[i][0] * 0.5 * contrast + 0.5)
plt.show()
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
plt.figure(figsize=(8, 8))
plt.subplot(121)
plt.title('Is a real zebra?')
plt.imshow(discriminator_y(sample_zebra)[0, ..., -1], cmap='RdBu_r')
plt.subplot(122)
plt.title('Is a real horse?')
plt.imshow(discriminator_x(sample_horse)[0, ..., -1], cmap='RdBu_r')
plt.show()
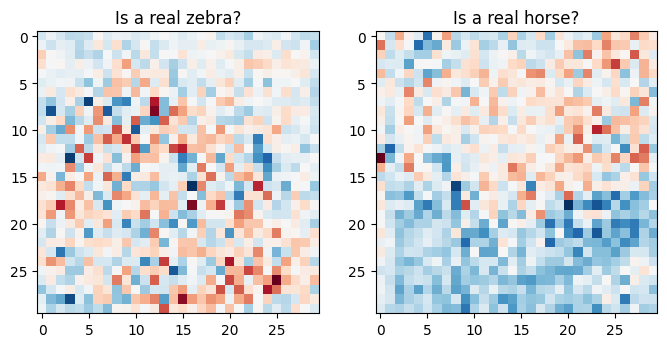
kayıp fonksiyonları
CycleGAN'da üzerinde çalışılacak eşleştirilmiş veri yoktur, dolayısıyla x girişinin ve hedef y çiftinin eğitim sırasında anlamlı olduğunun garantisi yoktur. Bu nedenle, ağın doğru eşlemeyi öğrenmesini sağlamak için yazarlar döngü tutarlılığı kaybını önermektedir.
Diskriminatör kaybı ve üreteç kaybı, pix2pix'te kullanılanlara benzer.
LAMBDA = 10
loss_obj = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def discriminator_loss(real, generated):
real_loss = loss_obj(tf.ones_like(real), real)
generated_loss = loss_obj(tf.zeros_like(generated), generated)
total_disc_loss = real_loss + generated_loss
return total_disc_loss * 0.5
def generator_loss(generated):
return loss_obj(tf.ones_like(generated), generated)
Döngü tutarlılığı, sonucun orijinal girdiye yakın olması gerektiği anlamına gelir. Örneğin, bir cümleyi İngilizce'den Fransızca'ya çevirir ve sonra tekrar Fransızca'dan İngilizce'ye çevirirse, sonuçta ortaya çıkan cümle orijinal cümle ile aynı olmalıdır.
Döngü tutarlılık kaybında,
- Görüntü \(X\) , oluşturulan l10n- \(G\) görüntüsünü veren \(\hat{Y}\)oluşturucu aracılığıyla geçirilir.
- Oluşturulan görüntü \(\hat{Y}\) , döngülü görüntü \(\hat{X}\)-placeholder8 veren \(F\) -placeholder7 oluşturucu aracılığıyla geçirilir.
- Ortalama mutlak hata, \(X\) tutucu9 ile \(\hat{X}\)-yer tutucu10 arasında hesaplanır.
\[forward\ cycle\ consistency\ loss: X -> G(X) -> F(G(X)) \sim \hat{X}\]
\[backward\ cycle\ consistency\ loss: Y -> F(Y) -> G(F(Y)) \sim \hat{Y}\]
def calc_cycle_loss(real_image, cycled_image):
loss1 = tf.reduce_mean(tf.abs(real_image - cycled_image))
return LAMBDA * loss1
Yukarıda gösterildiği gibi, \(G\) tutucu14 görüntüsünü \(X\) \(Y\)çevirmekten sorumludur. Kimlik kaybı, l10n-placeholder16 görüntüsünü \(Y\) oluşturucuya \(G\), bunun gerçek görüntüyü \(Y\) veya l10n- \(Y\)görüntüsüne yakın bir şey vermesi gerektiğini söylüyor.
Bir at üzerinde zebradan ata modelini veya bir zebrada attan zebraya modelini çalıştırırsanız, görüntü zaten hedef sınıfı içerdiğinden görüntüyü fazla değiştirmemelidir.
\[Identity\ loss = |G(Y) - Y| + |F(X) - X|\]
def identity_loss(real_image, same_image):
loss = tf.reduce_mean(tf.abs(real_image - same_image))
return LAMBDA * 0.5 * loss
Tüm oluşturucular ve ayırıcılar için optimize edicileri başlatın.
generator_g_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
generator_f_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_x_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_y_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
kontrol noktaları
checkpoint_path = "./checkpoints/train"
ckpt = tf.train.Checkpoint(generator_g=generator_g,
generator_f=generator_f,
discriminator_x=discriminator_x,
discriminator_y=discriminator_y,
generator_g_optimizer=generator_g_optimizer,
generator_f_optimizer=generator_f_optimizer,
discriminator_x_optimizer=discriminator_x_optimizer,
discriminator_y_optimizer=discriminator_y_optimizer)
ckpt_manager = tf.train.CheckpointManager(ckpt, checkpoint_path, max_to_keep=5)
# if a checkpoint exists, restore the latest checkpoint.
if ckpt_manager.latest_checkpoint:
ckpt.restore(ckpt_manager.latest_checkpoint)
print ('Latest checkpoint restored!!')
Eğitim
EPOCHS = 40
def generate_images(model, test_input):
prediction = model(test_input)
plt.figure(figsize=(12, 12))
display_list = [test_input[0], prediction[0]]
title = ['Input Image', 'Predicted Image']
for i in range(2):
plt.subplot(1, 2, i+1)
plt.title(title[i])
# getting the pixel values between [0, 1] to plot it.
plt.imshow(display_list[i] * 0.5 + 0.5)
plt.axis('off')
plt.show()
Eğitim döngüsü karmaşık görünse de dört temel adımdan oluşur:
- Tahminleri alın.
- Kaybı hesaplayın.
- Geri yayılımı kullanarak gradyanları hesaplayın.
- Degradeleri optimize ediciye uygulayın.
@tf.function
def train_step(real_x, real_y):
# persistent is set to True because the tape is used more than
# once to calculate the gradients.
with tf.GradientTape(persistent=True) as tape:
# Generator G translates X -> Y
# Generator F translates Y -> X.
fake_y = generator_g(real_x, training=True)
cycled_x = generator_f(fake_y, training=True)
fake_x = generator_f(real_y, training=True)
cycled_y = generator_g(fake_x, training=True)
# same_x and same_y are used for identity loss.
same_x = generator_f(real_x, training=True)
same_y = generator_g(real_y, training=True)
disc_real_x = discriminator_x(real_x, training=True)
disc_real_y = discriminator_y(real_y, training=True)
disc_fake_x = discriminator_x(fake_x, training=True)
disc_fake_y = discriminator_y(fake_y, training=True)
# calculate the loss
gen_g_loss = generator_loss(disc_fake_y)
gen_f_loss = generator_loss(disc_fake_x)
total_cycle_loss = calc_cycle_loss(real_x, cycled_x) + calc_cycle_loss(real_y, cycled_y)
# Total generator loss = adversarial loss + cycle loss
total_gen_g_loss = gen_g_loss + total_cycle_loss + identity_loss(real_y, same_y)
total_gen_f_loss = gen_f_loss + total_cycle_loss + identity_loss(real_x, same_x)
disc_x_loss = discriminator_loss(disc_real_x, disc_fake_x)
disc_y_loss = discriminator_loss(disc_real_y, disc_fake_y)
# Calculate the gradients for generator and discriminator
generator_g_gradients = tape.gradient(total_gen_g_loss,
generator_g.trainable_variables)
generator_f_gradients = tape.gradient(total_gen_f_loss,
generator_f.trainable_variables)
discriminator_x_gradients = tape.gradient(disc_x_loss,
discriminator_x.trainable_variables)
discriminator_y_gradients = tape.gradient(disc_y_loss,
discriminator_y.trainable_variables)
# Apply the gradients to the optimizer
generator_g_optimizer.apply_gradients(zip(generator_g_gradients,
generator_g.trainable_variables))
generator_f_optimizer.apply_gradients(zip(generator_f_gradients,
generator_f.trainable_variables))
discriminator_x_optimizer.apply_gradients(zip(discriminator_x_gradients,
discriminator_x.trainable_variables))
discriminator_y_optimizer.apply_gradients(zip(discriminator_y_gradients,
discriminator_y.trainable_variables))
for epoch in range(EPOCHS):
start = time.time()
n = 0
for image_x, image_y in tf.data.Dataset.zip((train_horses, train_zebras)):
train_step(image_x, image_y)
if n % 10 == 0:
print ('.', end='')
n += 1
clear_output(wait=True)
# Using a consistent image (sample_horse) so that the progress of the model
# is clearly visible.
generate_images(generator_g, sample_horse)
if (epoch + 1) % 5 == 0:
ckpt_save_path = ckpt_manager.save()
print ('Saving checkpoint for epoch {} at {}'.format(epoch+1,
ckpt_save_path))
print ('Time taken for epoch {} is {} sec\n'.format(epoch + 1,
time.time()-start))

Saving checkpoint for epoch 40 at ./checkpoints/train/ckpt-8 Time taken for epoch 40 is 166.64579939842224 sec
Test veri kümesini kullanarak oluştur
# Run the trained model on the test dataset
for inp in test_horses.take(5):
generate_images(generator_g, inp)





Sonraki adımlar
Bu eğitim, Pix2Pix eğitiminde uygulanan jeneratör ve ayrımcıdan başlayarak CycleGAN'ın nasıl uygulanacağını göstermiştir. Sonraki adım olarak, TensorFlow Datasets'ten farklı bir veri kümesi kullanmayı deneyebilirsiniz.
Ayrıca sonuçları iyileştirmek için daha fazla sayıda çağ için eğitim alabilir veya burada kullanılan U-Net oluşturucu yerine kağıtta kullanılan değiştirilmiş ResNet oluşturucuyu uygulayabilirsiniz.