
| | |  צפה במקור ב-GitHub צפה במקור ב-GitHub | |
מחברת זו מדגים תרגום תמונה לתמונה ללא התאמה באמצעות GAN's מותנה, כמתואר בתרגום תמונה-תמונה ללא התאמה באמצעות Cycle-Consistent Adversarial Networks , הידוע גם בשם CycleGAN. המאמר מציע שיטה שיכולה ללכוד את המאפיינים של תחום תמונה אחד ולהבין כיצד ניתן לתרגם את המאפיינים הללו לתחום תמונה אחר, כל זאת בהיעדר דוגמאות להכשרה זוגיות.
מחברת זו מניחה שאתה מכיר את Pix2Pix, עליו תוכל ללמוד במדריך Pix2Pix . הקוד של CycleGAN דומה, ההבדל העיקרי הוא פונקציית אובדן נוספת, ושימוש בנתוני אימון לא מזווגים.
CycleGAN משתמש באובדן עקביות במחזור כדי לאפשר אימון ללא צורך בנתונים מותאמים. במילים אחרות, הוא יכול לתרגם מתחום אחד לאחר ללא מיפוי אחד לאחד בין תחום המקור לתחום היעד.
זה פותח את האפשרות לבצע הרבה משימות מעניינות כמו שיפור תמונות, צביעת תמונה, העברת סגנון וכו'. כל מה שאתה צריך זה את המקור ואת מערך הנתונים של היעד (שהוא פשוט ספריית תמונות).


הגדר את צינור הקלט
התקן את חבילת tensorflow_examples המאפשרת ייבוא של המחולל והמאפיין.
pip install git+https://github.com/tensorflow/examples.git
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.models.pix2pix import pix2pix
import os
import time
import matplotlib.pyplot as plt
from IPython.display import clear_output
AUTOTUNE = tf.data.AUTOTUNE
צינור קלט
הדרכה זו מכשירה מודל לתרגם מתמונות של סוסים, לתמונות של זברות. אתה יכול למצוא את מערך הנתונים הזה ודומים כאן .
כפי שהוזכר במאמר , החל ריצוד ושיקוף אקראי על מערך ההדרכה. אלו הן חלק מטכניקות הגדלת התמונה המונעות התאמה יתר.
זה דומה למה שנעשה ב- pix2pix
- בריצוד אקראי, גודל התמונה משתנה ל
286 x 286ולאחר מכן נחתך באקראי ל256 x 256. - בשיקוף אקראי, התמונה מתהפכת באופן אקראי אופקית כלומר משמאל לימין.
dataset, metadata = tfds.load('cycle_gan/horse2zebra',
with_info=True, as_supervised=True)
train_horses, train_zebras = dataset['trainA'], dataset['trainB']
test_horses, test_zebras = dataset['testA'], dataset['testB']
BUFFER_SIZE = 1000
BATCH_SIZE = 1
IMG_WIDTH = 256
IMG_HEIGHT = 256
def random_crop(image):
cropped_image = tf.image.random_crop(
image, size=[IMG_HEIGHT, IMG_WIDTH, 3])
return cropped_image
# normalizing the images to [-1, 1]
def normalize(image):
image = tf.cast(image, tf.float32)
image = (image / 127.5) - 1
return image
def random_jitter(image):
# resizing to 286 x 286 x 3
image = tf.image.resize(image, [286, 286],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
# randomly cropping to 256 x 256 x 3
image = random_crop(image)
# random mirroring
image = tf.image.random_flip_left_right(image)
return image
def preprocess_image_train(image, label):
image = random_jitter(image)
image = normalize(image)
return image
def preprocess_image_test(image, label):
image = normalize(image)
return image
train_horses = train_horses.cache().map(
preprocess_image_train, num_parallel_calls=AUTOTUNE).shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
train_zebras = train_zebras.cache().map(
preprocess_image_train, num_parallel_calls=AUTOTUNE).shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
test_horses = test_horses.map(
preprocess_image_test, num_parallel_calls=AUTOTUNE).cache().shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
test_zebras = test_zebras.map(
preprocess_image_test, num_parallel_calls=AUTOTUNE).cache().shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
sample_horse = next(iter(train_horses))
sample_zebra = next(iter(train_zebras))
2022-01-26 02:38:15.762422: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead. 2022-01-26 02:38:19.927846: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
plt.subplot(121)
plt.title('Horse')
plt.imshow(sample_horse[0] * 0.5 + 0.5)
plt.subplot(122)
plt.title('Horse with random jitter')
plt.imshow(random_jitter(sample_horse[0]) * 0.5 + 0.5)
<matplotlib.image.AxesImage at 0x7f7cf83e0050>
plt.subplot(121)
plt.title('Zebra')
plt.imshow(sample_zebra[0] * 0.5 + 0.5)
plt.subplot(122)
plt.title('Zebra with random jitter')
plt.imshow(random_jitter(sample_zebra[0]) * 0.5 + 0.5)
<matplotlib.image.AxesImage at 0x7f7cf8139490>
יבוא ועשה שימוש חוזר בדגמי Pix2Pix
ייבא את המחולל והמאפיין בשימוש ב- Pix2Pix באמצעות חבילת tensorflow_examples המותקנת.
ארכיטקטורת המודל המשמשת במדריך זה דומה מאוד למה שהיה בשימוש ב- pix2pix . חלק מההבדלים הם:
- Cyclegan משתמש בנורמליזציה של מופעים במקום בנורמליזציה אצווה .
- נייר CycleGAN
resnetמבוסס רשת שונה. מדריך זה משתמש במחוללunetשונה למען הפשטות.
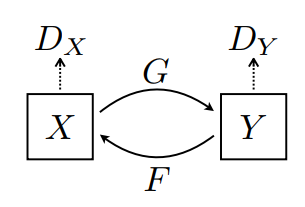
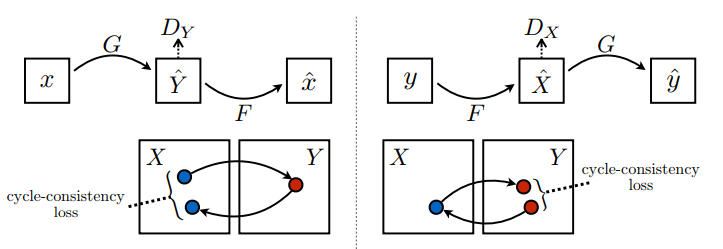
יש כאן 2 גנרטורים (G ו-F) ו-2 מפלים (X ו-Y).
- מחולל
Gלומד להפוך תמונהXלתמונהY\((G: X -> Y)\) - מחולל
Fלומד להפוך תמונהYלתמונהX\((F: Y -> X)\) - המפלה
D_Xלומדת להבדיל בין תמונהXלתמונהXשנוצרה (F(Y)). - המפלה
D_Yלומדת להבדיל בין תמונהYלתמונהYשנוצרה (G(X)).
OUTPUT_CHANNELS = 3
generator_g = pix2pix.unet_generator(OUTPUT_CHANNELS, norm_type='instancenorm')
generator_f = pix2pix.unet_generator(OUTPUT_CHANNELS, norm_type='instancenorm')
discriminator_x = pix2pix.discriminator(norm_type='instancenorm', target=False)
discriminator_y = pix2pix.discriminator(norm_type='instancenorm', target=False)
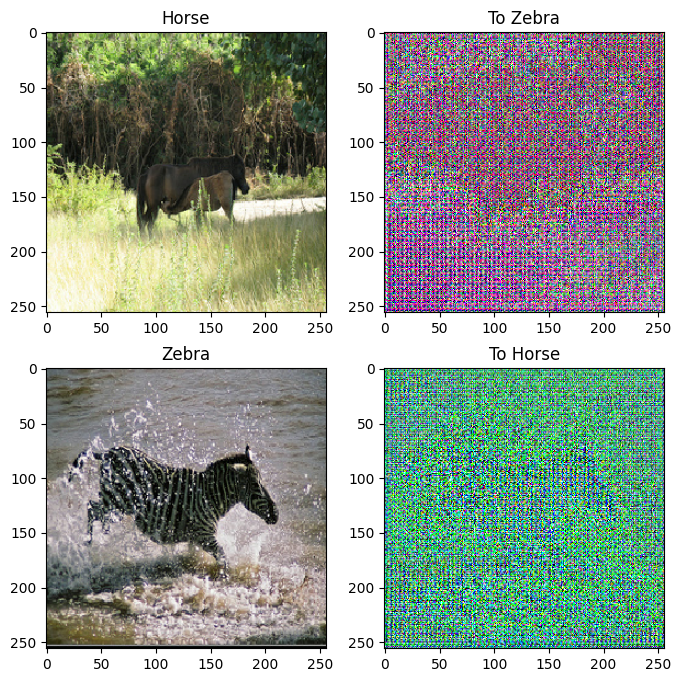
to_zebra = generator_g(sample_horse)
to_horse = generator_f(sample_zebra)
plt.figure(figsize=(8, 8))
contrast = 8
imgs = [sample_horse, to_zebra, sample_zebra, to_horse]
title = ['Horse', 'To Zebra', 'Zebra', 'To Horse']
for i in range(len(imgs)):
plt.subplot(2, 2, i+1)
plt.title(title[i])
if i % 2 == 0:
plt.imshow(imgs[i][0] * 0.5 + 0.5)
else:
plt.imshow(imgs[i][0] * 0.5 * contrast + 0.5)
plt.show()
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
plt.figure(figsize=(8, 8))
plt.subplot(121)
plt.title('Is a real zebra?')
plt.imshow(discriminator_y(sample_zebra)[0, ..., -1], cmap='RdBu_r')
plt.subplot(122)
plt.title('Is a real horse?')
plt.imshow(discriminator_x(sample_horse)[0, ..., -1], cmap='RdBu_r')
plt.show()
פונקציות הפסד
ב-CycleGAN, אין נתונים מזווגים להתאמן עליהם, ולכן אין ערובה לכך שהקלט x וזוג היעד y הם בעלי משמעות במהלך האימון. לפיכך, על מנת לאכוף שהרשת תלמד את המיפוי הנכון, הכותבים מציעים את אובדן עקביות המחזור.
אובדן המפלה ואובדן המחולל דומים לאלו המשמשים ב- pix2pix .
LAMBDA = 10
loss_obj = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def discriminator_loss(real, generated):
real_loss = loss_obj(tf.ones_like(real), real)
generated_loss = loss_obj(tf.zeros_like(generated), generated)
total_disc_loss = real_loss + generated_loss
return total_disc_loss * 0.5
def generator_loss(generated):
return loss_obj(tf.ones_like(generated), generated)
עקביות מחזור פירושה שהתוצאה צריכה להיות קרובה לקלט המקורי. לדוגמה, אם מתרגמים משפט מאנגלית לצרפתית, ואז מתרגמים אותו בחזרה מצרפתית לאנגלית, אז המשפט המתקבל צריך להיות זהה למשפט המקורי.
באובדן עקביות במחזור,
- תמונה \(X\) מועברת דרך המחולל \(G\) שמניב תמונה שנוצרה \(\hat{Y}\).
- תמונה שנוצרה \(\hat{Y}\) מועברת דרך המחולל \(F\) שמייצר תמונה \(\hat{X}\).
- שגיאה מוחלטת ממוצעת מחושבת בין \(X\) ל- \(\hat{X}\).
\[forward\ cycle\ consistency\ loss: X -> G(X) -> F(G(X)) \sim \hat{X}\]
\[backward\ cycle\ consistency\ loss: Y -> F(Y) -> G(F(Y)) \sim \hat{Y}\]
def calc_cycle_loss(real_image, cycled_image):
loss1 = tf.reduce_mean(tf.abs(real_image - cycled_image))
return LAMBDA * loss1
כפי שמוצג לעיל, המחולל \(G\) אחראי לתרגום תמונה \(X\) לתמונה \(Y\). אובדן זהות אומר שאם הזנת תמונה \(Y\) למחולל \(G\), זה אמור להניב את התמונה האמיתית \(Y\) או משהו שקרוב לתמונה \(Y\).
אם אתה מריץ את המודל של זברה לסוס על סוס או את המודל של סוס לזברה על זברה, זה לא צריך לשנות את התמונה הרבה מכיוון שהתמונה כבר מכילה את מחלקת היעד.
\[Identity\ loss = |G(Y) - Y| + |F(X) - X|\]
def identity_loss(real_image, same_image):
loss = tf.reduce_mean(tf.abs(real_image - same_image))
return LAMBDA * 0.5 * loss
אתחל את המיטובים עבור כל המחוללים והמפלים.
generator_g_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
generator_f_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_x_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_y_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
מחסומים
checkpoint_path = "./checkpoints/train"
ckpt = tf.train.Checkpoint(generator_g=generator_g,
generator_f=generator_f,
discriminator_x=discriminator_x,
discriminator_y=discriminator_y,
generator_g_optimizer=generator_g_optimizer,
generator_f_optimizer=generator_f_optimizer,
discriminator_x_optimizer=discriminator_x_optimizer,
discriminator_y_optimizer=discriminator_y_optimizer)
ckpt_manager = tf.train.CheckpointManager(ckpt, checkpoint_path, max_to_keep=5)
# if a checkpoint exists, restore the latest checkpoint.
if ckpt_manager.latest_checkpoint:
ckpt.restore(ckpt_manager.latest_checkpoint)
print ('Latest checkpoint restored!!')
הַדְרָכָה
EPOCHS = 40
def generate_images(model, test_input):
prediction = model(test_input)
plt.figure(figsize=(12, 12))
display_list = [test_input[0], prediction[0]]
title = ['Input Image', 'Predicted Image']
for i in range(2):
plt.subplot(1, 2, i+1)
plt.title(title[i])
# getting the pixel values between [0, 1] to plot it.
plt.imshow(display_list[i] * 0.5 + 0.5)
plt.axis('off')
plt.show()
למרות שלולאת האימון נראית מסובכת, היא מורכבת מארבעה שלבים בסיסיים:
- קבלו את התחזיות.
- חשב את ההפסד.
- חשב את השיפועים באמצעות התפשטות לאחור.
- החל את ההדרגות על כלי האופטימיזציה.
@tf.function
def train_step(real_x, real_y):
# persistent is set to True because the tape is used more than
# once to calculate the gradients.
with tf.GradientTape(persistent=True) as tape:
# Generator G translates X -> Y
# Generator F translates Y -> X.
fake_y = generator_g(real_x, training=True)
cycled_x = generator_f(fake_y, training=True)
fake_x = generator_f(real_y, training=True)
cycled_y = generator_g(fake_x, training=True)
# same_x and same_y are used for identity loss.
same_x = generator_f(real_x, training=True)
same_y = generator_g(real_y, training=True)
disc_real_x = discriminator_x(real_x, training=True)
disc_real_y = discriminator_y(real_y, training=True)
disc_fake_x = discriminator_x(fake_x, training=True)
disc_fake_y = discriminator_y(fake_y, training=True)
# calculate the loss
gen_g_loss = generator_loss(disc_fake_y)
gen_f_loss = generator_loss(disc_fake_x)
total_cycle_loss = calc_cycle_loss(real_x, cycled_x) + calc_cycle_loss(real_y, cycled_y)
# Total generator loss = adversarial loss + cycle loss
total_gen_g_loss = gen_g_loss + total_cycle_loss + identity_loss(real_y, same_y)
total_gen_f_loss = gen_f_loss + total_cycle_loss + identity_loss(real_x, same_x)
disc_x_loss = discriminator_loss(disc_real_x, disc_fake_x)
disc_y_loss = discriminator_loss(disc_real_y, disc_fake_y)
# Calculate the gradients for generator and discriminator
generator_g_gradients = tape.gradient(total_gen_g_loss,
generator_g.trainable_variables)
generator_f_gradients = tape.gradient(total_gen_f_loss,
generator_f.trainable_variables)
discriminator_x_gradients = tape.gradient(disc_x_loss,
discriminator_x.trainable_variables)
discriminator_y_gradients = tape.gradient(disc_y_loss,
discriminator_y.trainable_variables)
# Apply the gradients to the optimizer
generator_g_optimizer.apply_gradients(zip(generator_g_gradients,
generator_g.trainable_variables))
generator_f_optimizer.apply_gradients(zip(generator_f_gradients,
generator_f.trainable_variables))
discriminator_x_optimizer.apply_gradients(zip(discriminator_x_gradients,
discriminator_x.trainable_variables))
discriminator_y_optimizer.apply_gradients(zip(discriminator_y_gradients,
discriminator_y.trainable_variables))
for epoch in range(EPOCHS):
start = time.time()
n = 0
for image_x, image_y in tf.data.Dataset.zip((train_horses, train_zebras)):
train_step(image_x, image_y)
if n % 10 == 0:
print ('.', end='')
n += 1
clear_output(wait=True)
# Using a consistent image (sample_horse) so that the progress of the model
# is clearly visible.
generate_images(generator_g, sample_horse)
if (epoch + 1) % 5 == 0:
ckpt_save_path = ckpt_manager.save()
print ('Saving checkpoint for epoch {} at {}'.format(epoch+1,
ckpt_save_path))
print ('Time taken for epoch {} is {} sec\n'.format(epoch + 1,
time.time()-start))

Saving checkpoint for epoch 40 at ./checkpoints/train/ckpt-8 Time taken for epoch 40 is 166.64579939842224 sec
צור באמצעות מערך נתונים לבדיקה
# Run the trained model on the test dataset
for inp in test_horses.take(5):
generate_images(generator_g, inp)





הצעדים הבאים
מדריך זה הראה כיצד ליישם את CycleGAN החל מהמחולל והאבחנה המיושמים במדריך Pix2Pix . כשלב הבא, תוכל לנסות להשתמש במערך נתונים אחר מ- TensorFlow Datasets .
אתה יכול גם להתאמן למספר גדול יותר של עידנים כדי לשפר את התוצאות, או שאתה יכול ליישם את מחולל ה-ResNet המשונה המשמש בעיתון במקום מחולל U-Net המשמש כאן.