
| | |  مشاهده منبع در GitHub مشاهده منبع در GitHub | |
این نوت بوک ترجمه جفت نشده تصویر به تصویر را با استفاده از GAN های شرطی نشان می دهد، همانطور که در ترجمه تصویر به تصویر بدون جفت با استفاده از شبکه های متخاصم با چرخه ، که به نام CycleGAN نیز شناخته می شود، توضیح داده شده است. این مقاله روشی را پیشنهاد میکند که میتواند ویژگیهای یک حوزه تصویر را ضبط کند و بفهمد که چگونه این ویژگیها میتوانند به حوزه تصویر دیگری ترجمه شوند، همه در غیاب هر گونه مثال آموزشی جفتی.
این نوت بوک فرض می کند که شما با Pix2Pix آشنا هستید که می توانید در آموزش Pix2Pix با آن آشنا شوید. کد CycleGAN مشابه است، تفاوت اصلی تابع ضرر اضافی و استفاده از داده های آموزشی جفت نشده است.
CycleGAN از کاهش ثبات چرخه برای فعال کردن آموزش بدون نیاز به داده های جفت استفاده می کند. به عبارت دیگر، می تواند از یک دامنه به دامنه دیگر بدون نگاشت یک به یک بین منبع و دامنه مقصد ترجمه کند.
این امکان را برای انجام بسیاری از کارهای جالب مانند بهبود عکس، رنگ آمیزی تصویر، انتقال سبک و غیره باز می کند. تنها چیزی که نیاز دارید منبع و مجموعه داده هدف است (که به سادگی فهرستی از تصاویر است).


خط لوله ورودی را تنظیم کنید
بسته tensorflow_examples را نصب کنید که امکان وارد کردن ژنراتور و تفکیک کننده را فراهم می کند.
pip install git+https://github.com/tensorflow/examples.git
import tensorflow as tf
import tensorflow_datasets as tfds
from tensorflow_examples.models.pix2pix import pix2pix
import os
import time
import matplotlib.pyplot as plt
from IPython.display import clear_output
AUTOTUNE = tf.data.AUTOTUNE
خط لوله ورودی
این آموزش مدلی را آموزش می دهد تا از تصاویر اسب به تصاویر گورخر ترجمه کند. شما می توانید این مجموعه داده و موارد مشابه را در اینجا بیابید.
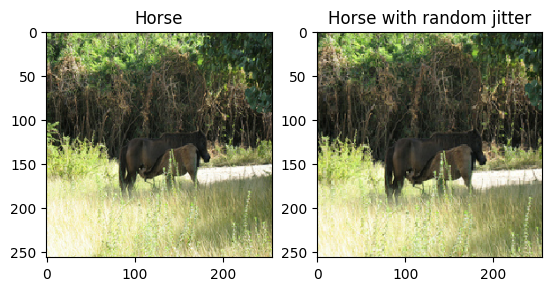
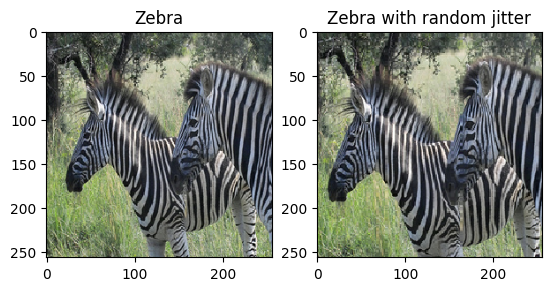
همانطور که در مقاله ذکر شد، لرزش تصادفی و آینه سازی را به مجموعه داده آموزشی اعمال کنید. اینها برخی از تکنیک های تقویت تصویر هستند که از برازش بیش از حد جلوگیری می کنند.
این شبیه کاری است که در pix2pix انجام شد
- در جیترینگ تصادفی، اندازه تصویر به
286 x 286تغییر میکند و سپس بهطور تصادفی به256 x 256برش داده میشود. - در انعکاس تصادفی، تصویر به طور تصادفی به صورت افقی برگردانده می شود، یعنی از چپ به راست.
dataset, metadata = tfds.load('cycle_gan/horse2zebra',
with_info=True, as_supervised=True)
train_horses, train_zebras = dataset['trainA'], dataset['trainB']
test_horses, test_zebras = dataset['testA'], dataset['testB']
BUFFER_SIZE = 1000
BATCH_SIZE = 1
IMG_WIDTH = 256
IMG_HEIGHT = 256
def random_crop(image):
cropped_image = tf.image.random_crop(
image, size=[IMG_HEIGHT, IMG_WIDTH, 3])
return cropped_image
# normalizing the images to [-1, 1]
def normalize(image):
image = tf.cast(image, tf.float32)
image = (image / 127.5) - 1
return image
def random_jitter(image):
# resizing to 286 x 286 x 3
image = tf.image.resize(image, [286, 286],
method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
# randomly cropping to 256 x 256 x 3
image = random_crop(image)
# random mirroring
image = tf.image.random_flip_left_right(image)
return image
def preprocess_image_train(image, label):
image = random_jitter(image)
image = normalize(image)
return image
def preprocess_image_test(image, label):
image = normalize(image)
return image
train_horses = train_horses.cache().map(
preprocess_image_train, num_parallel_calls=AUTOTUNE).shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
train_zebras = train_zebras.cache().map(
preprocess_image_train, num_parallel_calls=AUTOTUNE).shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
test_horses = test_horses.map(
preprocess_image_test, num_parallel_calls=AUTOTUNE).cache().shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
test_zebras = test_zebras.map(
preprocess_image_test, num_parallel_calls=AUTOTUNE).cache().shuffle(
BUFFER_SIZE).batch(BATCH_SIZE)
sample_horse = next(iter(train_horses))
sample_zebra = next(iter(train_zebras))
2022-01-26 02:38:15.762422: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead. 2022-01-26 02:38:19.927846: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.-l10n-
plt.subplot(121)
plt.title('Horse')
plt.imshow(sample_horse[0] * 0.5 + 0.5)
plt.subplot(122)
plt.title('Horse with random jitter')
plt.imshow(random_jitter(sample_horse[0]) * 0.5 + 0.5)
<matplotlib.image.AxesImage at 0x7f7cf83e0050>
plt.subplot(121)
plt.title('Zebra')
plt.imshow(sample_zebra[0] * 0.5 + 0.5)
plt.subplot(122)
plt.title('Zebra with random jitter')
plt.imshow(random_jitter(sample_zebra[0]) * 0.5 + 0.5)
<matplotlib.image.AxesImage at 0x7f7cf8139490>
مدلهای Pix2Pix را وارد کرده و دوباره استفاده کنید
مولد و تمایز مورد استفاده در Pix2Pix را از طریق بسته نصب شده tensorflow_examples وارد کنید.
معماری مدل استفاده شده در این آموزش بسیار شبیه به آنچه در pix2pix استفاده شده است. برخی از تفاوت ها عبارتند از:
- Cyclegan از نرمال سازی نمونه به جای عادی سازی دسته ای استفاده می کند.
- مقاله CycleGAN از یک ژنراتور مبتنی بر
resnetاصلاح شده استفاده می کند. این آموزش از یک ژنراتورunetاصلاح شده برای سادگی استفاده می کند.
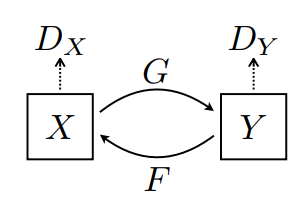
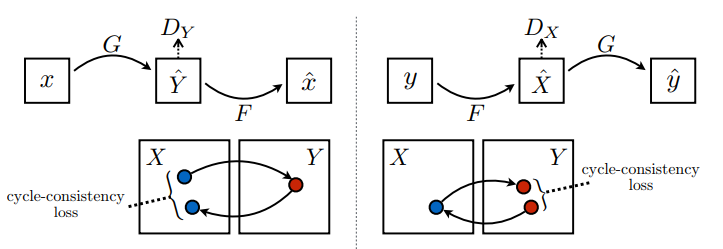
2 ژنراتور (G و F) و 2 تشخیص دهنده (X و Y) در اینجا آموزش می بینند.
- ژنراتور
Gیاد می گیرد که تصویرXرا به تصویرYتبدیل کند. \((G: X -> Y)\) - ژنراتور
Fمی آموزد که تصویرYرا به تصویرXتبدیل کند. \((F: Y -> X)\) -
D_Xیاد می گیرد که بین تصویرXو تصویرX(F(Y)) تفاوت قائل شود. -
D_Yیاد می گیرد که بین تصویرYو تصویرYتولید شده (G(X)تفاوت قائل شود.
OUTPUT_CHANNELS = 3
generator_g = pix2pix.unet_generator(OUTPUT_CHANNELS, norm_type='instancenorm')
generator_f = pix2pix.unet_generator(OUTPUT_CHANNELS, norm_type='instancenorm')
discriminator_x = pix2pix.discriminator(norm_type='instancenorm', target=False)
discriminator_y = pix2pix.discriminator(norm_type='instancenorm', target=False)
to_zebra = generator_g(sample_horse)
to_horse = generator_f(sample_zebra)
plt.figure(figsize=(8, 8))
contrast = 8
imgs = [sample_horse, to_zebra, sample_zebra, to_horse]
title = ['Horse', 'To Zebra', 'Zebra', 'To Horse']
for i in range(len(imgs)):
plt.subplot(2, 2, i+1)
plt.title(title[i])
if i % 2 == 0:
plt.imshow(imgs[i][0] * 0.5 + 0.5)
else:
plt.imshow(imgs[i][0] * 0.5 * contrast + 0.5)
plt.show()
WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers). WARNING:matplotlib.image:Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).
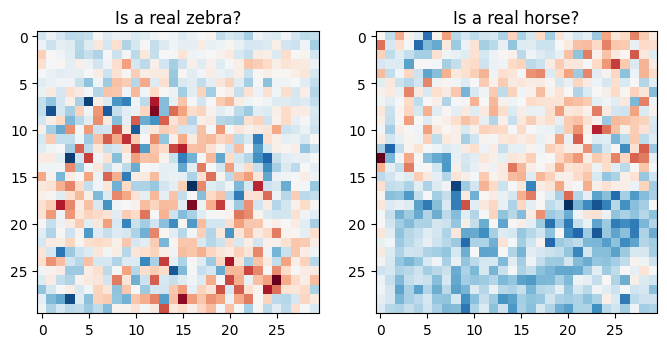
plt.figure(figsize=(8, 8))
plt.subplot(121)
plt.title('Is a real zebra?')
plt.imshow(discriminator_y(sample_zebra)[0, ..., -1], cmap='RdBu_r')
plt.subplot(122)
plt.title('Is a real horse?')
plt.imshow(discriminator_x(sample_horse)[0, ..., -1], cmap='RdBu_r')
plt.show()
توابع از دست دادن
در CycleGAN، هیچ داده جفتی برای آموزش وجود ندارد، از این رو هیچ تضمینی وجود ندارد که ورودی x و جفت هدف y در طول آموزش معنادار باشند. بنابراین برای اینکه شبکه نقشه برداری صحیح را بیاموزد، نویسندگان از دست دادن ثبات چرخه را پیشنهاد می کنند.
از دست دادن تفکیک کننده و از دست دادن ژنراتور مشابه موارد استفاده شده در pix2pix است.
LAMBDA = 10
loss_obj = tf.keras.losses.BinaryCrossentropy(from_logits=True)
def discriminator_loss(real, generated):
real_loss = loss_obj(tf.ones_like(real), real)
generated_loss = loss_obj(tf.zeros_like(generated), generated)
total_disc_loss = real_loss + generated_loss
return total_disc_loss * 0.5
def generator_loss(generated):
return loss_obj(tf.ones_like(generated), generated)
سازگاری چرخه به این معنی است که نتیجه باید نزدیک به ورودی اصلی باشد. به عنوان مثال، اگر یک جمله را از انگلیسی به فرانسوی ترجمه کنید، و سپس آن را از فرانسوی به انگلیسی ترجمه کنید، آنگاه جمله حاصل باید مانند جمله اصلی باشد.
در از دست دادن ثبات چرخه،
- تصویر \(X\) از طریق ژنراتور \(G\) ارسال می شود که تصویر تولید شده \(\hat{Y}\)را به دست می دهد.
- تصویر تولید شده \(\hat{Y}\) از طریق ژنراتور \(F\) می شود که تصویر چرخه ای \(\hat{X}\)ایجاد می کند.
- میانگین خطای مطلق بین \(X\) و \(\hat{X}\)محاسبه می شود.
\[forward\ cycle\ consistency\ loss: X -> G(X) -> F(G(X)) \sim \hat{X}\]
\[backward\ cycle\ consistency\ loss: Y -> F(Y) -> G(F(Y)) \sim \hat{Y}\]
def calc_cycle_loss(real_image, cycled_image):
loss1 = tf.reduce_mean(tf.abs(real_image - cycled_image))
return LAMBDA * loss1
همانطور که در بالا نشان داده شد، مولد \(G\) مسئول ترجمه تصویر \(X\) به تصویر \(Y\)است. از دست دادن هویت میگوید که، اگر تصویر \(Y\) را به ژنراتور \(G\)، باید تصویر واقعی \(Y\) یا چیزی نزدیک به تصویر \(Y\)ایجاد کند.
اگر مدل گورخر به اسب را روی اسب یا مدل اسب به گورخر را روی گورخر اجرا کنید، نباید تصویر را زیاد تغییر دهید زیرا تصویر قبلاً شامل کلاس هدف است.
\[Identity\ loss = |G(Y) - Y| + |F(X) - X|\]
def identity_loss(real_image, same_image):
loss = tf.reduce_mean(tf.abs(real_image - same_image))
return LAMBDA * 0.5 * loss
بهینه سازها را برای همه مولدها و متمایزکننده ها راه اندازی کنید.
generator_g_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
generator_f_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_x_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
discriminator_y_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)
ایست های بازرسی
checkpoint_path = "./checkpoints/train"
ckpt = tf.train.Checkpoint(generator_g=generator_g,
generator_f=generator_f,
discriminator_x=discriminator_x,
discriminator_y=discriminator_y,
generator_g_optimizer=generator_g_optimizer,
generator_f_optimizer=generator_f_optimizer,
discriminator_x_optimizer=discriminator_x_optimizer,
discriminator_y_optimizer=discriminator_y_optimizer)
ckpt_manager = tf.train.CheckpointManager(ckpt, checkpoint_path, max_to_keep=5)
# if a checkpoint exists, restore the latest checkpoint.
if ckpt_manager.latest_checkpoint:
ckpt.restore(ckpt_manager.latest_checkpoint)
print ('Latest checkpoint restored!!')
آموزش
EPOCHS = 40
def generate_images(model, test_input):
prediction = model(test_input)
plt.figure(figsize=(12, 12))
display_list = [test_input[0], prediction[0]]
title = ['Input Image', 'Predicted Image']
for i in range(2):
plt.subplot(1, 2, i+1)
plt.title(title[i])
# getting the pixel values between [0, 1] to plot it.
plt.imshow(display_list[i] * 0.5 + 0.5)
plt.axis('off')
plt.show()
اگرچه حلقه آموزشی پیچیده به نظر می رسد، از چهار مرحله اساسی تشکیل شده است:
- پیش بینی ها را دریافت کنید
- ضرر را محاسبه کنید.
- شیب ها را با استفاده از پس انتشار محاسبه کنید.
- گرادیان ها را روی بهینه ساز اعمال کنید.
@tf.function
def train_step(real_x, real_y):
# persistent is set to True because the tape is used more than
# once to calculate the gradients.
with tf.GradientTape(persistent=True) as tape:
# Generator G translates X -> Y
# Generator F translates Y -> X.
fake_y = generator_g(real_x, training=True)
cycled_x = generator_f(fake_y, training=True)
fake_x = generator_f(real_y, training=True)
cycled_y = generator_g(fake_x, training=True)
# same_x and same_y are used for identity loss.
same_x = generator_f(real_x, training=True)
same_y = generator_g(real_y, training=True)
disc_real_x = discriminator_x(real_x, training=True)
disc_real_y = discriminator_y(real_y, training=True)
disc_fake_x = discriminator_x(fake_x, training=True)
disc_fake_y = discriminator_y(fake_y, training=True)
# calculate the loss
gen_g_loss = generator_loss(disc_fake_y)
gen_f_loss = generator_loss(disc_fake_x)
total_cycle_loss = calc_cycle_loss(real_x, cycled_x) + calc_cycle_loss(real_y, cycled_y)
# Total generator loss = adversarial loss + cycle loss
total_gen_g_loss = gen_g_loss + total_cycle_loss + identity_loss(real_y, same_y)
total_gen_f_loss = gen_f_loss + total_cycle_loss + identity_loss(real_x, same_x)
disc_x_loss = discriminator_loss(disc_real_x, disc_fake_x)
disc_y_loss = discriminator_loss(disc_real_y, disc_fake_y)
# Calculate the gradients for generator and discriminator
generator_g_gradients = tape.gradient(total_gen_g_loss,
generator_g.trainable_variables)
generator_f_gradients = tape.gradient(total_gen_f_loss,
generator_f.trainable_variables)
discriminator_x_gradients = tape.gradient(disc_x_loss,
discriminator_x.trainable_variables)
discriminator_y_gradients = tape.gradient(disc_y_loss,
discriminator_y.trainable_variables)
# Apply the gradients to the optimizer
generator_g_optimizer.apply_gradients(zip(generator_g_gradients,
generator_g.trainable_variables))
generator_f_optimizer.apply_gradients(zip(generator_f_gradients,
generator_f.trainable_variables))
discriminator_x_optimizer.apply_gradients(zip(discriminator_x_gradients,
discriminator_x.trainable_variables))
discriminator_y_optimizer.apply_gradients(zip(discriminator_y_gradients,
discriminator_y.trainable_variables))
for epoch in range(EPOCHS):
start = time.time()
n = 0
for image_x, image_y in tf.data.Dataset.zip((train_horses, train_zebras)):
train_step(image_x, image_y)
if n % 10 == 0:
print ('.', end='')
n += 1
clear_output(wait=True)
# Using a consistent image (sample_horse) so that the progress of the model
# is clearly visible.
generate_images(generator_g, sample_horse)
if (epoch + 1) % 5 == 0:
ckpt_save_path = ckpt_manager.save()
print ('Saving checkpoint for epoch {} at {}'.format(epoch+1,
ckpt_save_path))
print ('Time taken for epoch {} is {} sec\n'.format(epoch + 1,
time.time()-start))

Saving checkpoint for epoch 40 at ./checkpoints/train/ckpt-8 Time taken for epoch 40 is 166.64579939842224 sec
با استفاده از مجموعه داده آزمایشی ایجاد کنید
# Run the trained model on the test dataset
for inp in test_horses.take(5):
generate_images(generator_g, inp)





مراحل بعدی
این آموزش نحوه پیاده سازی CycleGAN را با شروع از مولد و تشخیص دهنده پیاده سازی شده در آموزش Pix2Pix نشان می دهد. به عنوان گام بعدی، می توانید از مجموعه داده متفاوتی از TensorFlow Datasets استفاده کنید.
همچنین میتوانید برای بهبود نتایج، دورههای بیشتری را آموزش دهید، یا میتوانید به جای ژنراتور U-Net که در اینجا استفاده میشود، مولد ResNet اصلاحشده مورد استفاده در مقاله را اجرا کنید.